MySQL WorkbenchのVISUAL EXPLAINでインデックスの挙動を確認する方法
MySQL WorkbenchのVISUAL EXPLAIN機能を使い、インデックスの動作を視覚的に確認する方法を解説。データベースのパフォーマンス最適化に役立つ。
キーポイント
MySQL WorkbenchのVISUAL EXPLAIN機能はSQLのEXPLAINを視覚化し、インデックスの効果を直感的に理解できる
複合インデックスは指定したカラム順にソートされ、先頭カラムからの条件で効率的に使用できる
カバリングインデックス(クエリに必要な全カラムをインデックスに含める)を使用するとデータ行へのアクセスが不要になり高速化できる
インデックスはテーブルサイズや検索結果の割合によって使用判断が変わり、必ずしも常に有効ではない
影響分析・編集コメントを表示
影響分析
この記事はデータベースパフォーマンスチューニングの実践的な手法を提供しており、特に開発現場でのSQL最適化教育に役立つ内容となっている。VISUAL EXPLAINの視覚的アプローチは初心者にも理解しやすく、データベース運用の効率化に貢献できる。
編集コメント
2018年の記事の移管版だが、データベース最適化の基本原則は現在でも有効。VISUAL EXPLAINの活用は開発者の学習曲線を短縮する効果的な方法。
この記事は、合併前の旧ブログに掲載していた記事(初出:2018 年 8 月 20 日)を、現在のブログへ移管したものです。現時点の情報に合わせ、表記やリンクの調整を行っています。
開発 3 センターでサーバサイドの開発を行っている大原(@kory1202)です。私の部署では LINE ポイントの開発を行っています。
先日、あるテーブルからデータを抽出するコードを書いていたら先輩に「こういうインデックスが必要だよね。」と言われてインデックスについて知識が浅いことに気づかされました。そこで今回はインデックスについて MySQL Workbench の VISUAL EXPLAIN を使いながら勉強した内容を記事にしました。VISUAL EXPLAIN は SQL の EXPLAIN(説明)を図で表示してくれるので、直感的にどの部分が悪いのか、インデックスを導入した時にどの処理が改善されるのかが直感的に分かるので非常にオススメです。
今回は MySQL 5.6 の InnoDB について話します。実験に使った OS は macOS High Sierra 10.13.4 です。以下目次。
インデックスの基礎 インデックスの構造
MySQL Workbench と VISUAL EXPLAIN VISUAL EXPLAIN 実行方法
VISUAL EXPLAIN の色とテーブル図形のテキストの説明ちょっとだけ
VISUAL EXPLAIN でインデックスの挙動を確かめる(本題) インデックスなし(簡単に VISUAL EXPLAIN の見方)
WHERE の条件にインデックス
ORDER BY の条件にインデックス
GROUP BY の条件にインデックス
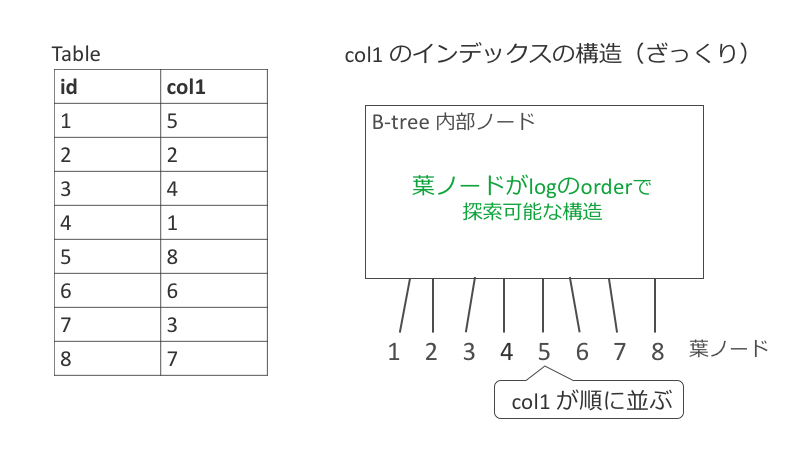
MySQL 5.6 リファレンスマニュアル / InnoDB インデックスの物理構造にある通り、B-trees(B 木)の構造になっています。この記事は B-tree の構造の詳細には触れないので、本当にざっくりとしたイメージを以下に載せます。
葉ノードはインデックスで指定したカラムの昇順にソートされていて、実際の行がどこに保存されているかのデータを保持しています。WHERE col1 = 3
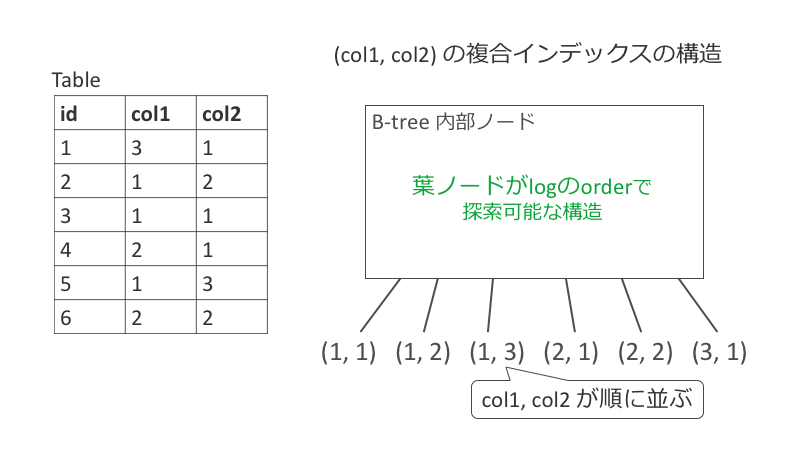
複合インデックスの場合は以下の図のように、指定したカラムの順(ここでは col1 col2 の順)にソートされます。そのため、WHERE col1 <= 2
WHERE col1 <= 2 AND col2 >= 2
WHERE col1 = 1 AND col2 >= 2
MySQL 5.6 リファレンスマニュアル / 8.3.1 MySQL のインデックスの使用の仕組み から辿って読めば、どういう時に使われるか、使えるかについて分かります。
WHERE ・ ORDER BY ・ GROUP BY を素早く実行するために使われる
原則として、1 つのテーブルからは 1 つのインデックスしか使用されません。
テーブル内の行が長く、検索結果の行数が少ない場合に利用されます。
フルテーブルスキャンはディスクシーク回数が最小となるため、クエリの大半にアクセスする場合はインデックスを使用するよりも高速です。
10 行未満や短い行数のテーブルではフルテーブルスキャンが行われます。
「全テーブルの 30% を超えるデータが検索結果に含まれる場合はインデックスは使われない」と言われてきましたが、MySQL5.6 のドキュメントを確認すると、テーブルサイズ、行数、I/O ブロックサイズなどの要因からインデックスを使用するか否かが決定されているようです。
複合インデックス(Composite Index)は単一カラムインデックスの代わりにも使用できます。
(col1, col2, col3) の 3 カラムで構成されるインデックスがある場合、(col1)、(col1, col2)、(col1, col2, col3) に対してそれぞれインデックスを利用可能です(前述したインデックスの構造の節で説明した通りです)。
データ行を参照せずに値のみを取得できるインデックス(カバリングインデックス:Covering Index)を使用すると高速化が図れます。
クエリが必要とする全てのカラムをインデックスが含んでいる場合、例えば column1 と column2 がインデックスに含まれている状態で以下のクエリを実行すると、インデックスから全ての値が得られるため、データ行にアクセスする必要がありません。
SELECT column1 FROM tbl_name WHERE column2 = 1;
一方、以下のクエリはデータ行へのアクセスが必要となります。
SELECT * FROM tbl_name WHERE column2 = 1;
インデックスが設定されたカラムに対して MAX() や MIN() 値を見つける際にも利用されます。
複数のインデックスから選択する場合は、最小数の行を処理できるインデックスが使用されます。
別テーブルと JOIN(結合)して使用する際、カラムの型とサイズが一致しているとインデックスが効率的に利用できます。
MySQL Workbench と VISUAL EXPLAIN
MySQL Workbench は MySQL の GUI クライアントです。インデックスを試しながら試行錯誤する際に、GUI でインデックスの追加・削除を行えたり、ER 図も作成できたりと、非常に便利です。
そして何より、VISUAL EXPLAIN が利用できます!
ここから「ダウンロードはこちら」ボタンをクリックした先でダウンロード可能です。
VISUAL EXPLAIN の実行方法
SQL 文をクエリ入力欄に記述し、左上にある虫眼鏡マークをクリックするか、メニューの Query > Explain Current Statement を選択します。
または Cmd + Option + x を押します。
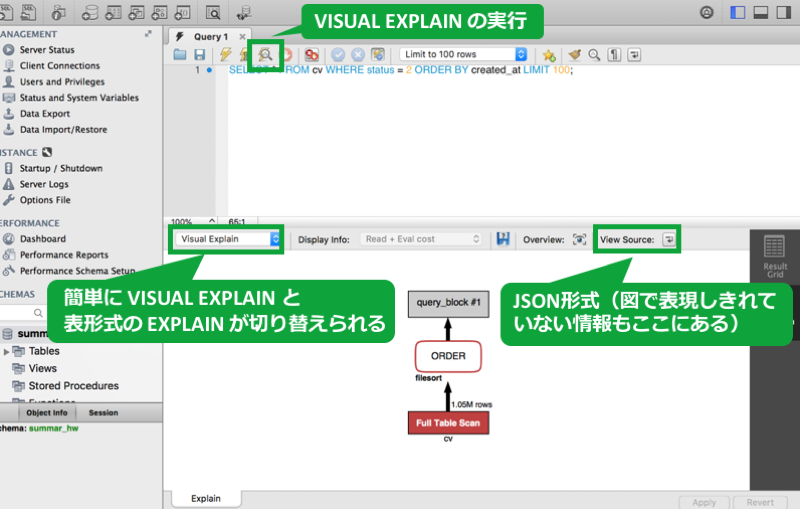
EXPLAIN の結果を見たい場合は、図に示した画面中央左の select タグを変更するだけで表示が切り替わるため便利です。また、画面中央右の View Source ボタンを押すことで、JSON 形式で VISUAL EXPLAIN の元の情報を確認できるので、これも非常に便利です。
VISUAL EXPLAIN の色とテーブル図形のテキストの説明(ちょっとだけ)
カラフルな四角いオブジェクトは、テーブルに対してどのようにアクセスするかを示しています。青からコストが低く、赤がコストが高いことを示しています。下2つの赤い index と ALL はインデックスを考えるなどしてチューニングしようとよく言われてるやつですね。
EXPLAIN における type

Single row: constant(単一行:定数)

Unique Key Lookup(一意キー検索)

Non-Unique Key Lookup(非一意キー検索)

Fulltext Index Search(全文インデックス検索)

Index Range Scan(インデックス範囲スキャン)

Full Index Scan(インデックス全体スキャン)

Full Table Scan(テーブル全体スキャン)
Lookup: where col = 1 のような等価比較
VISUAL EXPLAIN でインデックスの挙動を確かめる(本題)
本題です。青→赤の順にコストが大きいことだけ分かっていれば、詳細に見方を覚えなくても使えます。
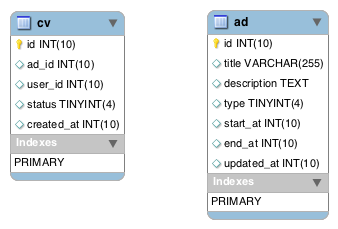
今回使うのは下の2つのテーブルです。どのユーザがコンバージョンしたかを持っておく cv テーブルと、それが紐付く広告の ad テーブルです。 今回実験のためにざっくり作成したデータについて下に列挙します。
インデックスは簡略化のため、現時点では PRIMARY KEY のみです。
cv は約 100 万件、ad は約 4000 件です。
cv の status と ad の type はそれぞれ 10 種類あり、偏りはありません。
時刻を保存するカラムは UNIX TIME で、ここ一ヶ月のデータを格納しています。ER 図はせっかくなので MySQL Workbench で出力しました。Workbench は外部キーを貼っておけば自動的にリレーションが図に描かれますが(公式)、今回は説明を簡単にするために PRIMARY KEY のみにしたので下図のようになっています。
インデックスなし(簡単に VISUAL EXPLAIN の見方)
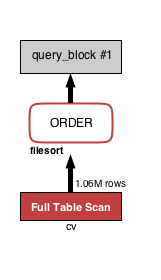
SELECT * FROM cv WHERE status = 2 ORDER BY created_at LIMIT 100;
このクエリに対して VISUAL EXPLAIN を実行すると以下の画像が出ます。
比較用:上の VISUAL EXPLAIN に対する EXPLAIN

矢印の通り読み、cv テーブルの全テーブルをスキャンして得る 100 万行を ORDER BY でソートして結果を得ていることが分かります。真っ赤ですね。100 万行もスキャンして WHERE の条件にマッチする行を探して、全体をソートして 100 件を返しているので重い処理になっています。インデックスを貼る必要があります。
WHERE の条件にインデックス
上記 SQL の為にインデックスを追加していきます。まずは WHERE の条件である status にインデックスを貼ります。インデックスによって status = 2 の行だけを取ってくるのが簡単になります。
ALTER TABLE cv ADD INDEX idx_status (status);
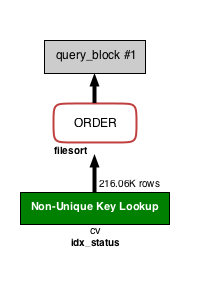

cv テーブルが緑色になりました。約 21 万件が取得されてソートされるため、先ほどの 100 万件と比べるとかなり軽くなりそうです。この 21 万件という数字は MySQL の予測値ですが、実際には status = 2 のレコードは約 10 万件です。status に偏りがあり大半が status = 2 の場合、インデックスを使わない方が高速であると判断され、フルテーブルスキャン(Full Table Scan)になる可能性があります(インデックスの使われ方の節を参照)。そのような場合は ORDER BY 句にインデックスを適用しましょう。
補足:WHERE 条件におけるインデックスの利用
status に偏りがあり大半が status = 2 の場合、インデックスを使わない方が高速であると判断されフルテーブルスキャンになる可能性があります
上の記述を検証するために実験を行いました。大半どころか、レコード数が 100 万件ある cv テーブルの全レコードを status = 2 に設定し、ANALYZE TABLE cv; を実行しました。
SELECT * FROM cv WHERE status = 2;
ORDER BY 条件におけるインデックスの利用
(上で適用したインデックスは DROP 済み)
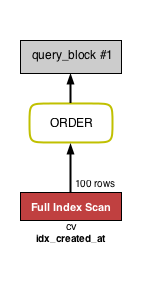
ALTER TABLE cv ADD INDEX idx_created_at (created_at);
比較用:上記の VISUAL EXPLAIN に対する EXPLAIN

今度は ORDER BY 句が黄緑色になりました。テーブル側ではフルインデックススキャン(Full Index Scan)となっています。どのような処理が行われているかというと、created_at のインデックスから順番にレコードを取り出し、status = 2 であるかどうかを確認していきます。そして LIMIT で指定された数だけ status = 2 のレコードが見つかった時点で探索を終了できます(created_at について既にソート済みであるため)。そのため、テーブルから取得されるレコード数の予測は 100 行となっています。status = 2 のレコードが早く見つかるのが理想ですが、逆に最後の方まで見つからない場合はインデックスをすべて読み込まなければなりません。status = 2 がレアなケースではこの状況に陥るため、status にインデックスを適用して WHERE 句で取得されるレコード数を減らすのが良さそうです(数が少なければソートのコストも低くなります)。この辺りの詳細については、『雑な MySQL パフォーマンスチューニング』という記事が分かりやすかったです。
WHERE の条件と ORDER BY の条件のどちらにインデックスを貼るのが良いかは、status の偏りなどを見てつけるのが良いと思います。 または、idx_status
GROUP BY の条件にインデックス
(上で貼ったインデックスは DROP)
SELECT ad_id, COUNT(*) FROM cv WHERE status = 2 GROUP BY ad_id;
ad_id ごとの cv の数を確認するクエリです。インデックス無しでは下図のように真っ赤になります。
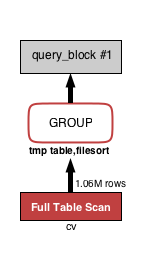
比較用:上の VISUAL EXPLAIN に対する EXPLAIN

GROUP BY の条件である ad_id にインデックスを貼ると下図のように GROUP BY が黄緑になりました。
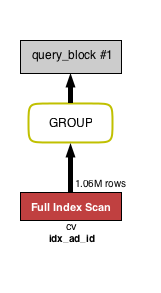
比較用:上の VISUAL EXPLAIN に対する EXPLAIN

上図と下図を見比べると、 GROUP の下にあった tmp table, filesort
インデックスがまさに一時テーブルの役割を果たすので、この処理が必要なくなってることをこの図が表しています。
GROUP BY の処理は早くなりますが、テーブルへのアクセスは Full Index Scan となっていて重いので WHERE の条件の方にインデックスを貼ることを検討した方が良さそうです。
(上で貼ったインデックスは DROP)
ALTER TABLE cv ADD INDEX idx_status_created_at (status, created_at);
この複合インデックスをつけて再び以下の SQL を VISUAL EXPLAIN します。
SELECT * FROM cv WHERE status = 2 ORDER BY created_at LIMIT 100;
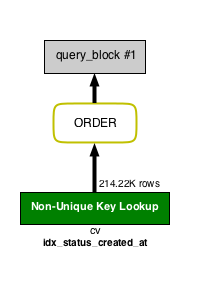
比較用:上の VISUAL EXPLAIN に対する EXPLAIN

テーブルへのアクセスも ORDER も緑になっていて良い感じです。表形式の EXPLAIN と比較すると VISUAL EXPLAIN は一目でどの部分が改善したのかが分かります。
(上で貼ったインデックスは DROP)
一週間前からカウントして、コンバージョン数が多い順に ad テーブルのレコードを並べたい場合のクエリについて見ます。細かい条件として cv の status は 1、ad の type は 2 のデータを抽出したいです。
SELECT ad.id, COUNT(DISTINCT cv.user_id) as cv_count FROM ad INNER JOIN cv ON cv.ad_id = ad.id AND cv.status = 1 AND cv.created_at >= UNIX_TIMESTAMP(CURDATE() - INTERVAL 7 DAY) WHERE ad.type = 2 AND ad.end_at >= UNIX_TIMESTAMP(CURDATE() - INTERVAL 7 DAY) GROUP BY ad.id ORDER BY cv_count DESC LIMIT 100 ;
上のクエリを VISUAL EXPLAIN すると下のような画像になりました。
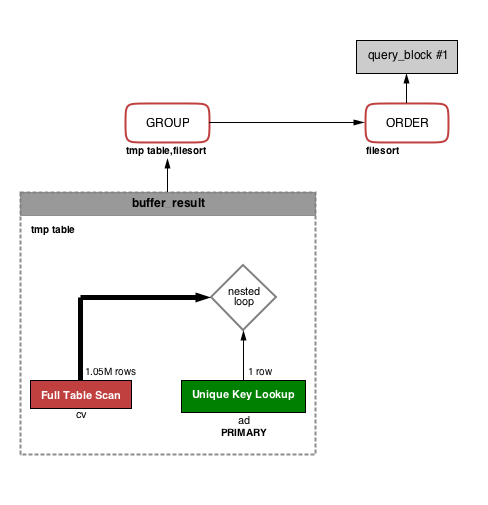
比較用:上の VISUAL EXPLAIN に対する EXPLAIN

複雑になりましたが、VISUAL EXPLAIN は左下から右上へと処理が流れるように図が描かれているようなので、左下から見ていけば良さそうです。この図から分かることについて列挙しておきます。
JOIN が nested loop で処理されている(nested loop についてはここでは詳細に触れませんが以下参考:実例で学ぶ、JOIN (NLJ) が遅くなる理屈と対処法 / MySQL 5.6 リファレンスマニュアル / Nested Loop 結合アルゴリズム)
駆動表の行 1 行に対して、内部表を 1 行ずつスキャンして結合条件にマッチするものを取り出しています。
cv テーブルから読み取られた行に対して、対応する ad テーブルの行が PRIMARY KEY を使って読み取られている(cv テーブルが外側のループ(駆動表・外部表)、ad テーブルが内側のループ(内部表))
buffer_result と記述されている一時テーブルが作られる
この一時テーブルを使って GROUP BY
(以下インデックスをどのように貼るか試行錯誤していますが、これは私の試行錯誤を記述しているに過ぎず、必ずこうしなければいけないとか、こうするべきとかを示すものではない事をご了承ください。一例として見ていただけると嬉しいです。)
まずこの図を見ると cv テーブルの Full Table Scan をやめさせたい気持ちになります。また、ad テーブルは緑で PRIMARY KEY を使用しているので放っておいても良いような気持ちになりますが、PRIMARY KEY は ad と cv を結合する為に使えているのであって ad 自体を type や end_at で絞り込む際にインデックスを使えていないので、この type や end_at の絞り込みは遅いはずです。それなので ad の方にもインデックスを作って様子を見てみます。以下のようなインデックスをつけて何が使われるか確認してみました。
cv テーブル idx_status_created_at: (status, created_at) cv テーブルを絞り込む条件につけた
idx_ad_id_status_created_at: (ad_id, status, created_at) cv に関する条件順につけた
adテーブル idx_type_end_at: (type, end_at) ad テーブルを絞り込む条件につけた
この状態で VISUAL EXPLAIN を実行すると以下のようになりました。
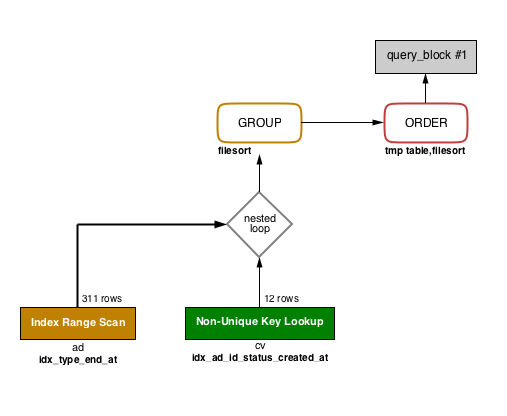
比較用:上の VISUAL EXPLAIN に対する EXPLAIN

色々変わってスッキリしました。ad と cv の位置が入れ替わりました。図から分かる事を列挙します。
ad テーブルが駆動表となり、type や end_at の条件を絞るためにインデックス idx_type_end_at が使われる
cv テーブルの idx_ad_id_status_created_at を使って ad テーブルの対応する行を読み取っている cv に関する status や created_at の条件をこのインデックスで絞れているかは分からない
一時テーブル buffer_result が消え、GROUP BY の tmp table も消えました(GROUP BY は色もオレンジになった)
一時テーブル buffer_result が消える理由は、GROUP BY の条件が駆動表(二重ループの外側)の ad.id であるため、あらかじめソートしてからループを回せば GROUP BY の条件にインデックスの節で説明した一時テーブルが不要になるためだと考えられます(参考:実例で学ぶ、JOIN (NLJ) が遅くなる理屈と対処法 / 高速化が難しい JOIN SQL)。内部表で GROUP BY をすると一時テーブルが必須となります。実際、インデックスを貼る前の状態(cv が駆動表の状態)で、GROUP BY を内部表の ad.id ではなく cv.ad_id とすると一時テーブルは出てきません。
さて、複合インデックスを使用しましたが、その一部しか使われていないようであれば単一のインデックスを貼ったほうが良い(例えば cv テーブルのインデックスが ad テーブルとの対応を取るためのみ、つまり a
原文を表示
この記事は、合併前の旧ブログに掲載していた記事(初出:2018年8月20日)を、現在のブログへ移管したものです。現時点の情報に合わせ、表記やリンクの調整を行っています。
開発3センターでサーバサイドの開発を行っている大原(@kory1202)です。 私の部署ではLINEポイントの開発を行っています。
先日、あるテーブルからデータを抽出するコードを書いていたら先輩に「こういうインデックスが必要だよね。」と言われてインデックスについて知識が浅いことに気づかされました。そこで今回はインデックスについて MySQL Workbench の VISUAL EXPLAIN を使いながら勉強した内容を記事にしました。 VISUAL EXPLAIN は SQL の EXPLAIN を図で表示してくれるので、直感的にどの部分が悪いのか、インデックスを導入した時にどの処理が改善されるのかが直感的に分かるので非常にオススメです。
今回は MySQL 5.6 の InnoDB について話します。実験に使った OS は macOS High Sierra 10.13.4 です。以下目次。
インデックスの基礎 インデックスの構造
MySQL Workbench と VISUAL EXPLAIN VISUAL EXPLAIN 実行方法
VISUAL EXPLAIN の色とテーブル図形のテキストの説明ちょっとだけ
VISUAL EXPLAIN でインデックスの挙動を確かめる(本題) インデックスなし(簡単に VISUAL EXPLAIN の見方)
WHERE の条件にインデックス
ORDER BY の条件にインデックス
GROUP BY の条件にインデックス
MySQL 5.6 リファレンスマニュアル / InnoDB インデックスの物理構造��にある通り、B-treesの構造になっています。 この記事はB-treeの構造の詳細には触れないので、本当にざっくりとしたイメージを以下に載せます。
葉ノードはインデックスで指定したカラムの昇順にソートされていて、実際の行がどこに保存されているかのデータを保持しています。 WHERE col1 = 3
複合インデックスの場合は以下の図のように、指定したカラムの順(ここでは col1 col2 の順)にソートされます。そのため、 WHERE col1 <= 2
WHERE col1 <= 2 AND col2 >= 2
WHERE col1 = 1 AND col2 >= 2
MySQL 5.6 リファレンスマニュアル / 8.3.1 MySQL のインデックスの使用の仕組み から辿って読めば、どういう時に使われるか、使えるかについて分かります。
WHERE ・ ORDER BY ・ GROUP BY を素早く実行するために使われる
原則1つのテーブルから1つのインデックスが使われる
テーブル内の行が長く、検索結果の行が少数である場合に使われる
フルテーブルスキャンはディスクシークが最小になるのでクエリの大半にアクセスする場合はインデックスを使うよりも高速。
10行未満や短い行数のテーブルではフルテーブルスキャン
全テーブルの30%超が検索結果にわたる場合はインデックスは使われない、と言われてましたが MySQL5.6 のドキュメントを見ると、テーブルサイズ、行数、I/Oブロックサイズなどの要因からインデックスを使用するか否か決めているようです
複合インデックスは単一カラムインデックスの代わりにも使える
(col1, col2, col3) の3カラムインデックスがある場合、(col1)、(col1, col2)、(col1, col2, col3) に対してインデックスを使える (上のインデックスの構造の節で説明した通りです)
データ行を参照しないで値を取得できるインデックス (カバリングインデックス) を使うと高速
クエリが必要とする全てのカラムをインデックスが含んでいる場合。 例えば column1 と column2 がインデックスに含まれている場合で以下のクエリを叩くとインデックスから全ての値が得られるので、データ行を見に行かずにすみます。
SELECT column1 FROM tbl_name WHERE column2 = 1;
以下のクエリはデータ行を見にいく必要があります。
SELECT * FROM tbl_name WHERE column2 = 1;
インデックスが設定されたカラムに対して MAX() ・ MIN() 値を見つけるために使われる
複数のインデックスから選択する場合は最小数の行を見つけるインデックスを使用
別テーブルと JOIN して使う際、カラムが同じ型とサイズだとインデックスが効率よく使える
MySQL Workbench と VISUAL EXPLAIN
MySQL Workbench は、MySQLのGUIクライアントです。 インデックスを色々試行錯誤するときに GUI でインデックスを追加・削除したり、ER図も書けたりと、かなり便利です。
そして何より VISUAL EXPLAIN ができます!
ここ から「ダウンロードはこちら」ボタンをクリックした先でダウンロードできます。
VISUAL EXPLAIN 実行方法
SQL 文をクエリ入力欄に書き、左上の方にある虫眼鏡マークかメニューの Query > Explain Current Statement
Cmd + Option + x
EXPLAIN の結果を見たい場合は図に示した画面中央左の select タグを変更するだけで表示が切り替わるので便利です。 また、画面中央右の View Source ボタンを押すことで、 JSON 形式で VISUAL EXPLAIN の元の情報が確認できるので、これも便利です。
VISUAL EXPLAIN の色とテーブル図形のテキストの説明ちょっとだけ
カラフルな四角いオブジェクトは、テーブルに対してどのようにアクセスするかを示しています。 青からコストが低く、赤がコストが高いことを示しています。 下2つの赤い index と ALL はインデックスを考えるなどしてチューニングしようとよく言われてるやつですね。
EXPLAINにおけるtype
Single row: constant
Unique Key Lookup
Non-Unique Key Lookup
Fulltext Index Search
Index Range Scan
Full Index Scan
Full Table Scan
Lookup: where col = 1 のような等価比較
VISUAL EXPLAIN でインデックスの挙動を確かめる(本題)
本題です。青→赤の順にコストが大きいことだけ分かっていれば、詳細に見方を覚えなくても使えます。
今回使うのは下の2つのテーブルです。どのユーザがコンバージョンしたかを持っておく cv テーブルと、それが紐付く広告の ad テーブルです。 今回実験のためにざっくり作成したデータについて下に列挙します。
インデックスは簡単のためこの時点で PRIMARY KEY のみ
cv は約100万件、 ad は約4000件
cv の status と ad の type はそれぞれ10種類で偏りなし
時刻を保存するカラムは UNIX TIME でここ一ヶ月のデータを格納ER 図はせっかくなので MySQL Workbench で出力しました。 Workbench は外部キーを貼っておけば自動的にリレーションが図に描かれますが(公式、今回は説明を簡単にする為に PRIMARY KEY のみにしたので下図のようになっています。
インデックスなし(簡単に VISUAL EXPLAIN の見方)
SELECT * FROM cv WHERE status = 2 ORDER BY created_at LIMIT 100;
このクエリに対して VISUAL EXPLAIN を実行すると以下の画像が出ます。
比較用:上の VISUAL EXPLAIN に対する EXPLAIN
矢印の通り読み、 cv テーブルの全テーブルをスキャンして得る100万行を ORDER BY でソートして結果を得ていることが分かります。 真っ赤ですね。100万行もスキャンして WHERE の条件にマッチする行を探して、全体をソートして100件を返しているので重い処理になっています。 インデックスを貼る必�要があります。
WHERE の条件にインデックス
上記 SQL の為にインデックスを追加していきます。 まずは WHERE の条件である status にインデックスを貼ります。 インデックスによって status = 2 の行だけを取ってくるのが簡単になります。
ALTER TABLE cv ADD INDEX idx_status (status);
比較用:上の VISUAL EXPLAIN に対する EXPLAIN
cv テーブルが緑になりました。約21万件が取得されてソートされるので、先ほどの100万件と比べてかなり軽くなりそうです。 21万件という数字は MySQL の予測であって、実際 status = 2 のレコードは10万件程度です。 status に偏りがあって大半が status = 2 だとするとインデックスを使わない方が高速と判断されて Full Table Scan になりそうです(インデックスの使われ方の節参照)。そういう場合は ORDER BY の方にインデックスを貼りましょう。
補足:WHERE の条件にインデックス
status に偏りがあって大半が status = 2 だとするとインデックスを使わない方が高速と判断されて Full Table Scan になりそうです
上の記述を確かめるために実験をしましたが、大半どころかレコード数が100万件の cv テーブルの全レコードを status = 2 にして、 ANALYZE TABLE cv;
SELECT * FROM cv WHERE status = 2;
ORDER BY の条件にインデックス
(上で貼ったインデックスは DROP)
ALTER TABLE cv ADD INDEX idx_created_at (created_at);
比較用:上の VISUAL EXPLAIN に対する EXPLAIN
今度は ORDER が黄緑になりました。テーブルの方は Full Index Scan となっています。 どういう処理が走っているかというと、 created_at のインデックスから順番にレコードを取り出し status = 2 であるかどうかを確認していきます。そして LIMIT の数だけ status = 2 のレコードが見つかった時点で探索を終了できます(created_at についてソート済みなので)。 それなのでテーブルから取得されるレコードの数も予測が100行となっています。status = 2 のレコードが早く見つかれば良いですが、逆に最後の方まで見つからなければインデックスを全部読まなければ�なりません。 status = 2 がレアな場合はこの状況になってしまうので、 status にインデックスを貼って WHERE で取得されるレコードの数を減らすのが良さそうです(数が少なければソートのコストも低い)。 この辺りの話は雑なMySQLパフォーマンスチューニングが分かりやすかったです。
WHERE の条件と ORDER BY の条件のどちらにインデックスを貼るのが良いかは、 status の偏りなどを見てつけるのが良いと思います。 または、 idx_status
GROUP BY の条件にインデックス
(上で貼ったインデックスは DROP)
SELECT ad_id, COUNT(*) FROM cv WHERE status = 2 GROUP BY ad_id;
ad_id ごとの cv の数を確認するクエリです。インデックス無しでは下図のように真っ赤になります。
比較用:上の VISUAL EXPLAIN に対する EXPLAIN
GROUP BY の条件である ad_id にインデックスを貼ると下図のように GROUP BY が黄緑になりました。
比較用:上の VISUAL EXPLAIN に対する EXPLAIN
上図と下図を見比べると、 GROUP の下にあった tmp table, filesort
インデックスがまさに一時テーブルの役割を果たすので、この処理が必要なくなってることをこの図が表しています。
GROUP BY の処理は早くなりますが、テーブルへのアクセスは Full Index Scan となっていて重いので WHERE の条件の方にインデックスを貼ることを検討した方が良さそうです。
(上で貼ったインデックスは DROP)
ALTER TABLE cv ADD INDEX idx_status_created_at (status, created_at);
この複合インデックスをつけて再び以下の SQL を VISUAL EXPLAIN します。
SELECT * FROM cv WHERE status = 2 ORDER BY created_at LIMIT 100;
比較用:上の VISUAL EXPLAIN に対する EXPLAIN
テーブルへのアクセスも ORDER も緑になっていて良い感じです。 表形式の EXPLAIN と比較すると VISUAL EXPLAIN は一目でどの部分が改善したのかが分かります。
(上で貼ったインデックスは DROP)
一週間前からカウントして、コンバージョン数が多い順に ad テーブルのレコードを並べたい場合のクエリについて見ます。 細かい条件として cv の status は1、 ad の type は2のデータを抽出したいです。
SELECT ad.id, COUNT(DISTINCT cv.user_id) as cv_count FROM ad INNER JOIN cv ON cv.ad_id = ad.id AND cv.status = 1 AND cv.created_at >= UNIX_TIMESTAMP(CURDATE() - INTERVAL 7 DAY) WHERE ad.type = 2 AND ad.end_at >= UNIX_TIMESTAMP(CURDATE() - INTERVAL 7 DAY) GROUP BY ad.id ORDER BY cv_count DESC LIMIT 100 ;
上のクエリを VISUAL EXPLAIN すると下のような画像になりました。
比較用:上の VISUAL EXPLAIN に対する EXPLAIN
複雑になりましたが、 VISUAL EXPLAIN は左下から右上へと処理が流れるように図が描かれているようなので、左下から見ていけば良さそうです。 この図から分かることについて列挙しておきます。
JOIN が nested loop で処理されている nested loop についてはここでは詳細に触れませんが以下参考 実例で学ぶ、JOIN (NLJ) が遅くなる理屈と対処法
MySQL 5.6 リファレンスマニュアル / Nested Loop 結合アルゴリズム)
駆動表の行1行に対して、内部表を1行ずつスキャンして結合条件にマッチするものを取り出しています
cv テーブルから読み取られた行に対して、対応する ad テーブルの行が PRIMARY KEY を使って読み取られている cv テーブルが外側のループ(駆動表・外部表)
ad テーブルが内側のループ(内部表)
buffer_result と記述されている一時テーブルが作られる
この一時テーブルを使って GROUP BY
(以下インデックスをどのように貼るか試行錯誤していますが、これは私の試行錯誤を記述しているに過ぎず、必ずこうしなければいけないとか、こうするべきとかを示すものではない事をご了承ください。一例として見ていただけると嬉しいです。)
まずこの図を見ると cv テーブルの Full Table Scan をやめさせたい気持ちになります。 また、 ad テーブルは緑で PRIMARY KEY を使用しているので放っておいても良いような気持ちになりますが、 PRIMARY KEY は ad と cv を結合する為に使えているのであって ad 自体を type や end_at で絞り込む際にインデックスを使えていないので、この type や end_at の絞り込みは遅いはずです。 それなので ad の方にもインデックスを作って様子を見てみます。 以下のようなインデックスをつけて何が使われるか確認してみました。
cv テーブル idx_status_created_at: (status, created_at) cv テーブルを絞り込む条件につけた
idx_ad_id_status_created_at: (ad_id, status, created_at) cv に関する条件順につけた
adテーブル idx_type_end_at: (type, end_at) ad テーブルを絞り込む条件につけた
この状態で VISUAL EXPLAIN を実行すると以下のようになりました。
比較用:上の VISUAL EXPLAIN に対する EXPLAIN
色々変わってスッキリしました。 ad と cv の位置が入れ替わりました。 図から分かる事を列挙します。
ad テーブルが駆動表となり、 type や end_at の条件を絞るためにインデ��ックス idx_type_end_at が使われる
cv テーブルの idx_ad_id_status_created_at を使って ad テーブルの対応する行を読み取っている cv に関する status や created_at の条件をこのインデックスで絞れているかは分からない
一時テーブル buffer_result が消え、 GROUP BY の tmp table も消えました(GROUP BY は色もオレンジになった)
一時テーブル buffer_result が消える理由は、 GROUP BY の条件が駆動表(二重ループの外側)の ad.id であるため、あらかじめソートしてからループを回せば GROUP BY の条件にインデックスの節で説明した一時テーブルが不要になるためだと考えられます(参考:実例で学ぶ、JOIN (NLJ) が遅くなる理屈と対処法 / 高速化が難しいJOIN SQL)。 内部表で GROUP BY をすると一時テーブルが必須となります。実際、インデックスを貼る前の状態(cv が駆動表の状態)で、 GROUP BY を内部表の ad.id ではなく cv.ad_id とすると一時テーブルは出てきません。
さて、複合インデックスを使用しましたが、その一部しか使われていないようであれば単一のインデックスを貼ったほうが良い(例えば cv テーブルのインデックスが ad テーブルとの対応を取るためのみ、つまり a
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み