AWSでの地震基盤モデルのスケーリング:Amazon SageMaker HyperPodによる分散トレーニングとコンテキストウィンドウの拡張
TGSとAWS Generative AI Innovation Centerは、Amazon SageMaker HyperPodを用いた分散トレーニングとコンテキストウィンドウの拡張により、地震基盤モデルのトレーニング時間を6ヶ月から5日に短縮し、より大きな地質体積の分析を可能にした。
キーポイント
トレーニング効率の劇的改善
Amazon SageMaker HyperPodを用いた分散トレーニングの最適化により、地震基盤モデルのトレーニング時間を6ヶ月から5日に短縮し、ほぼ線形スケーリングを実現した。
コンテキストウィンドウの拡張
Vision Transformerベースのモデルで処理可能な3D体積を拡大し、局所的な詳細と広範な地質パターンを同時に捕捉できる分析能力を向上させた。
大規模データ処理の最適化
ドメイン固有フォーマットの大規模3D地震データに対して効率的なストリーミング戦略を確立し、GPUのアイドル時間を防止しながら高スループットを維持した。
業界特化型AIソリューション
エネルギー探査分野における地質構造特定のための専門的な地震基盤モデル開発と、AWSインフラストラクチャの近代化を組み合わせた実用的なAI応用例を示している。
影響分析・編集コメントを表示
影響分析
この事例は、専門分野における基盤モデルの実用化が、クラウドインフラと分散コンピューティングの進歩によって加速していることを示している。エネルギー探査分野でのAI応用が具体的なビジネス価値(トレーニング時間の大幅短縮)を生み出しており、他の産業分野でも同様のアプローチが可能であることを示唆している。
編集コメント
業界特化型基盤モデルの実用化が具体的な数値成果(6ヶ月→5日)で示された貴重なケーススタディ。クラウドネイティブなAIインフラの効果が明確に実証されている。
コンテキスト並列処理でアテンション計算をラップ
with context_parallel(
buffers=[query, key, value], # シャード化するテンソル
buffer_seq_dims=[1, 1, 1] # シャード化する次元(シーケンス次元)
):
# 標準的なスケーリングドット積アテンション - 自動的にリングアテンションに
attention_output = torch.nn.functional.scaled_dot_product_attention(
query, key, value, attn_mask=None
)
- 動的マスク比率調整 – MAE (Masked Autoencoder) トレーニングでは、非マスクパッチと分類トークンの合計がデバイス間で均等に分割可能であることを保証する必要があり、適応型マスキング戦略が必要でした。
- デコーダーシーケンス管理 – デコーダーは、エンコーダーからの非マスクパッチとマスクパッチの両方を処理することで完全な画像を再構築します。これにより、GPUの数で割り切れる必要がある異なるシーケンス長が生成されます。
前述の実装により、以下の表に示すように、大幅に大きな3D地震ボリュームの処理が可能になりました。
| 指標 | 従来(ベースライン) | コンテキスト並列処理あり |
|---|---|---|
| 最大入力サイズ | 640 × 640 × 1,024 ボクセル | 1,536 × 1,536 × 2,048 ボクセル |
| コンテキスト長 | 102,400 トークン | 1,170,000 トークン |
| ボリューム増加率 | 1× | 4.5× |
以下の図は、2Dモデルのコンテキストサイズの例を示しています。
この拡張により、TGSのモデルはより広い空間的コンテキストにわたる地質学的特徴を捉えることが可能になり、クライアントに提供できる分析能力の向上に貢献しています。
結果とインパクト
TGSとAWS GenAIIC (Generative AI Innovation Center) の協業により、複数の面で大幅な改善がもたらされました:
- 大幅なトレーニング加速 – 最適化された分散トレーニングアーキテクチャにより、トレーニング時間が6か月から5日に短縮され、約36倍の高速化を実現しました。これにより、TGSはより迅速に反復し、新しい地質データをモデルに頻繁に組み込むことが可能になりました。
- ほぼ線形スケーリング – このソリューションは、単一ノードから16ノード構成への強力なスケーリング効率を示し、クラスターサイズの増加に伴うパフォーマンス低下を最小限に抑えながら、約90〜95%の並列効率を達成しました。
- 拡張された分析能力 – コンテキスト並列処理の実装により、より大きな3Dボリュームでのトレーニングが可能になり、モデルがより広い空間的コンテキストにわたる地質学的特徴を捉えることができます。
- プロダクションレディでコスト効率の高いインフラストラクチャ – Amazon S3からのストリーミングを備えたSageMaker HyperPodベースのソリューションは、トレーニング要件の増加に伴って効率的にスケールする費用対効果の高い基盤を提供し、プロダクションAIワークフローに必要な回復力、柔軟性、運用効率を実現します。
これらの改善は、TGSのAI駆動分析システムの強固な基盤を確立し、クライアントにより迅速なモデル反復サイクルと分析ごとのより広範な地質学的コンテキストを提供すると同時に、TGSの貴重なデータ資産の保護に貢献しています。
得られた教訓とベストプラクティス
この協業から、大規模3Dデータと分散トレーニングを扱う他の組織にも役立つ可能性のあるいくつかの重要な教訓が得られました:
- 体系的なスケーリングアプローチ – より大きなクラスターに段階的に拡張する前に、単一ノードのベースラインを確立することから始めることで、各段階で体系的な最適化を可能にしつつ、コストを効果的に管理できました。
- データパイプラインの最適化は重要 – データ集約型ワークロードでは、慎重なデータパイプライン設計が強力なパフォーマンスをもたらします。適切な並列化とプリフェッチを伴うオブジェクトストレージからの直接ストリーミングは、複雑な中間ストレージ層なしに必要なスループットを提供しました。
- バッチサイズの調整は微妙 – バッチサイズを増やしても、常にスループットが向上するわけではありません。チームは、過度に大きなバッチサイズがGPUへのデータ準備と転送においてボトルネックを生み出す可能性があることを発見しました。異なるスケールでの体系的なテストを通じて、チームはスループットが頭打ちになるポイントを特定し、GPU計算ではなくデータローディングパイプラインが制限要因になったことを示しました。この最適なバランスにより、リソースを過剰にプロビジョニングすることなく、トレーニング効率が最大化されました。
- フレームワークの選択は特定の要件に依存 – 異なる分散トレーニングフレームワークは、メモリ効率と通信オーバーヘッドの間でトレードオフがあります。最適な選択は、モデルサイズ、ハードウェア特性、およびスケーリング要件に依存します。
- 段階的な検証 – 本番フルクラスターに拡張する前に、より小規模で構成をテストすることで、開発フェーズ中のコストを管理しつつ、最適な設定を特定するのに役立ちました。
結論
AWS GenAIICとのパートナーシップにより、TGSはAWS上でSFM (Seismic Foundation Model) をトレーニングするための最適化されたスケーラブルなインフラストラクチャを確立しました。このソリューションは、トレーニングサイクルを加速しつつモデルの分析能力を拡張し、TGSがエネルギー分野のクライアントに強化された地下分析を提供するのに役立っています。この協業中に開発された技術的革新 – 特に3Dボリュームデータに対するViT (Vision Transformer) アーキテクチャへのコンテキスト並列処理の適応 – は、高度なAI技術を専門的な科学分野に適用する可能性を示しています。TGSが地下AIシステムとより広範なAI能力を拡大し続ける中で、この基盤は、マルチモーダル統合や時系列分析などの将来の機能強化をサポートすることができます。
独自のFM (Foundation Model) トレーニングワークロードのスケーリングについて詳しく知るには、回復力のある分散トレーニングインフラストラクチャのためのSageMaker HyperPodを探索するか、SageMakerドキュメントの分散トレーニングのベストプラクティスを確認してください。同様の協業に関心のある組織は、AWS Generative AI Innovation Centerがお客様のAIイニシアチブを加速するためのパートナーシップを提供しています。
謝辞
Andy Lapastora、Bingchen Liu、Prashanth Ramaswamy、Rohit Thekkanal、Jared Kramer、Roy Allelaの貢献に感謝します。
著者について
原文を表示
*This post is cowritten with Altay Sansal and Alejandro Valenciano from TGS.*
TGS, a geoscience data provider for the energy sector, supports companies’ exploration and production workflows with advanced seismic foundation models (SFMs). These models analyze complex 3D seismic data to identify geological structures vital for energy exploration. To help enhance their next-generation models as part of their AWS infrastructure modernization, TGS partnered with the AWS Generative AI Innovation Center (GenAIIC) to optimize their SFM training infrastructure.
This post describes how TGS achieved near-linear scaling for distributed training and expanded context windows for their Vision Transformer-based SFM using Amazon SageMaker HyperPod. This joint solution cut training time from 6 months to just 5 days while enabling analysis of seismic volumes larger than previously possible.
Addressing seismic foundation model training challenges
TGS’s SFM uses a Vision Transformer (ViT) architecture with Masked AutoEncoder (MAE) training designed by the TGS team to analyze 3D seismic data. Scaling such models presents several challenges:
- Data scale and complexity – TGS works with large volumes of proprietary 3D seismic data stored in domain-specific formats. The sheer volume and structure of this data required efficient streaming strategies to maintain high throughput and help prevent GPU idle time during training.
- Training efficiency – Training large FMs on 3D volumetric data is computationally intensive. Accelerating training cycles would enable TGS to incorporate new data more frequently and iterate on model improvements faster, delivering more value to their clients.
- Expanded analytical capabilities – The geological context a model can analyze depends on how much 3D volume it can process at once. Expanding this capability would allow the models to capture both local details and broader geological patterns simultaneously.
Understanding these challenges highlights the need for a comprehensive approach to distributed training and infrastructure optimization. The AWS GenAIIC partnered with TGS to develop a comprehensive solution addressing these challenges.
Solution overview
The collaboration between TGS and the AWS GenAIIC focused on three key areas: establishing an efficient data pipeline, optimizing distributed training across multiple nodes, and expanding the model’s context window to analyze larger geological volumes. The following diagram illustrates the solution architecture.
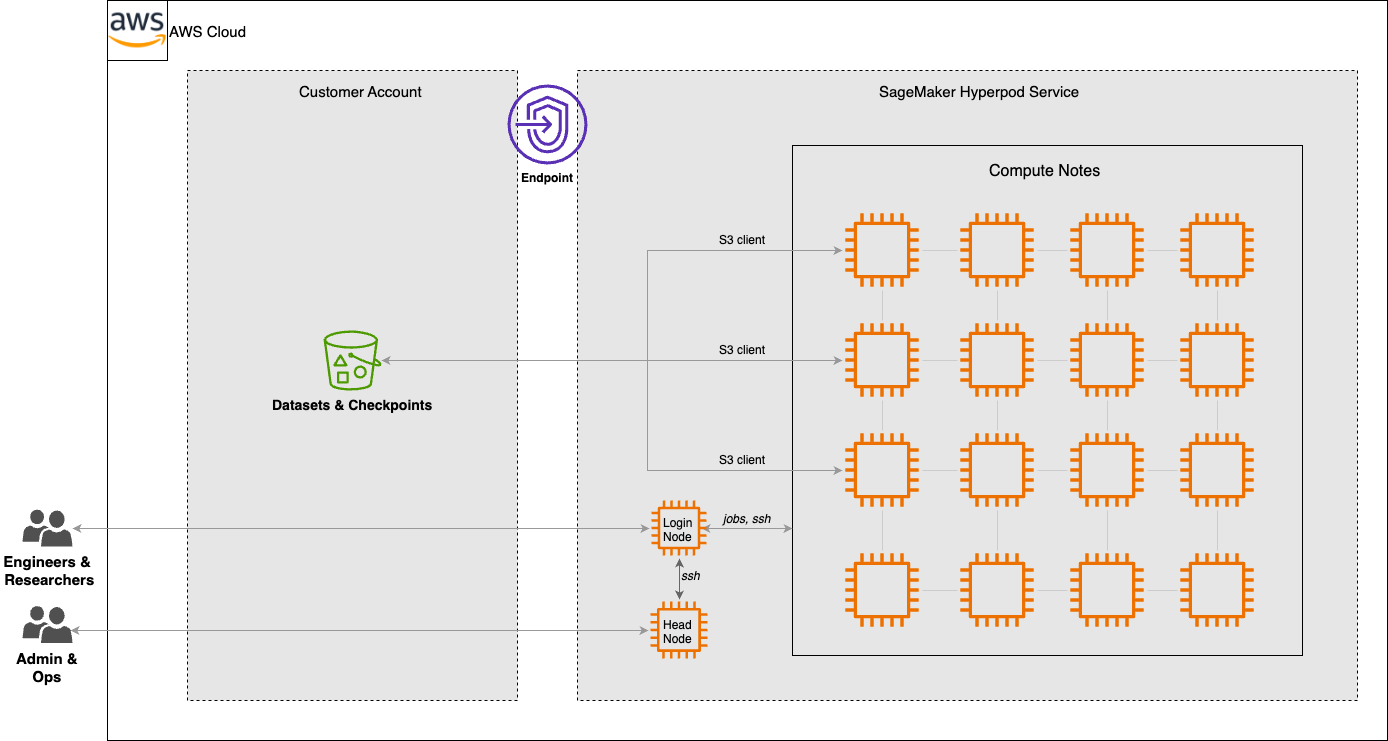
The solution uses SageMaker HyperPod to help provide a resilient, scalable training infrastructure with automatic health monitoring and checkpoint management. The SageMaker HyperPod cluster is configured with AWS Identity and Access Management (IAM) execution roles scoped to the minimum permissions required for training operations, deployed within a virtual private cloud (VPC) with network isolation and security groups restricting communication to authorized training nodes. Terabytes of training data streams directly from Amazon Simple Storage Service (Amazon S3), alleviating the need for intermediate storage layers while maintaining high throughput. AWS CloudTrail logs API calls to Amazon S3 and SageMaker services, and Amazon S3 access logging is enabled on training data buckets to provide a detailed audit trail of data access requests. The distributed training framework uses advanced parallelization techniques to efficiently scale across multiple nodes, and context parallelism methods enable the model to process significantly larger 3D volumes than previously possible.
The final cluster configuration consisted of 16 Amazon Elastic Compute Cloud (Amazon EC2) P5 instances for the worker nodes integrated through the SageMaker AI flexible training plans, each containing:
- 8 NVIDIA H200 GPUs with 141GB HBM3e memory per GPU
- 192 vCPUs
- 2048 GB system RAM
- 3200 Gbps EFAv3 networking for ultra-low latency communication
Optimizing the training data pipeline
TGS’s training dataset consists of 3D seismic volumes stored in the TGS-developed MDIO format—an open source format built on Zarr arrays designed for large-scale scientific data in the cloud. Such volumes can contain billions of data points representing underground geological structures.
Choosing the right storage approach
The team evaluated two approaches for delivering data to training GPUs:
- Amazon FSx for Lustre – Copy data from Amazon S3 to a high-speed distributed file system that the nodes read from. This approach provides sub-millisecond latency but requires pre-loading and provisioned storage capacity.
- Streaming directly from Amazon S3 – Stream data directly from Amazon S3 using MDIO’s native capabilities with multi-threaded libraries, opening multiple concurrent connections per node.
Settling on streaming directly from Amazon S3
The key architectural difference lies in how throughput scales with the cluster. With streaming directly from Amazon S3, each training node creates independent Amazon S3 connections, so aggregate throughput can scale linearly. With Amazon FSx for Lustre, the nodes share a single file system whose throughput is tied to provisioned storage capacity. Using Amazon FSx together with Amazon S3 requires only a small Amazon FSx storage volume, which limits the entire cluster to that volume’s throughput, creating a bottleneck as the cluster grows.
Comprehensive testing and cost analysis revealed streaming from Amazon S3 directly as the optimal choice for this configuration:
- Performance – Achieved 4–5 GBps sustained throughput per node using multiple data loader processes with pre-fetching over HTTPS endpoints (TLS 1.2)—sufficient to fully utilize the GPUs.
- Cost efficiency – Streaming from Amazon S3 alleviated the need for Amazon FSx provisioning, reducing storage infrastructure costs by over 90% while helping deliver 64-80 GBps cluster-wide throughput. The Amazon S3 pay-per-use model was more economical than provisioning high-throughput Amazon FSx capacity.
- Better scaling – Streaming from Amazon S3 directly scales naturally—each node brings its own connection bandwidth, avoiding the need for complex capacity planning.
- Operational simplicity – No intermediate storage to provision, manage, or synchronize.
The team optimized Amazon S3 connection pooling and implemented parallel data loading to sustain high throughput across the 16 nodes.
Selecting the distributed training framework
When training large models across multiple GPUs, the model’s parameters, gradients, and optimizer states must be distributed across devices. The team evaluated different distributed training approaches to find the optimal balance between memory efficiency and training throughput:
- ZeRO-2 (Zero Redundancy Optimizer Stage 2) – This approach partitions gradients and optimizer states across GPUs while keeping a full copy of model parameters on each GPU. This helps reduce memory usage while maintaining fast communication, because each GPU can directly access the parameters during the forward pass without waiting for data from other GPUs.
- ZeRO-3 – This approach goes further by also partitioning model parameters across GPUs. Although this helps maximize memory efficiency (enabling larger models), it requires more frequent communication between GPUs to gather parameters during computation, which can reduce throughput.
- FSDP2 (Fully Sharded Data Parallel v2) – PyTorch’s native approach similarly shards parameters, gradients, and optimizer states. It offers tight integration with PyTorch but involves similar communication trade-offs as ZeRO-3.
Comprehensive testing revealed DeepSpeed ZeRO-2 as the optimal framework for this configuration, delivering strong performance while efficiently managing memory:
- ZeRO-2 – 1,974 samples per second (implemented)
- FSDP2 – 1,833 samples per second
- ZeRO-3 – 869 samples per second
This framework choice provided the foundation for achieving near-linear scaling across multiple nodes. The combination of these three key optimizations helped deliver the dramatic training acceleration:
- Efficient distributed training – DeepSpeed ZeRO-2 enabled near-linear scaling across 128 GPUs (16 nodes × 8 GPUs)
- High-throughput data pipeline – Streaming from Amazon S3 directly sustained 64–80 GBps aggregate throughput across the cluster
Together, these improvements helped reduce training time from 6 months to 5 days—enabling TGS to iterate on model improvements weekly rather than semi-annually.
Expanding analytical capabilities
One of the most significant achievements was expanding the model’s field of view—how much 3D geological volume it can analyze simultaneously. A larger context window allows the model to capture both fine details (small fractures) and broad patterns (basin-wide fault systems) in a single pass, helping provide insights that were previously undetectable within the constraints of smaller analysis windows for TGS’s clients. The implementation by the TGS and AWS teams involved adapting the following advanced techniques to enable ViTs to process substantially larger 3D seismic volumes:
- Ring attention implementation – Each GPU processes a portion of the input sequence while circulating key-value pairs to neighboring GPUs, gradually accumulating attention results across the distributed system. PyTorch provides an API that makes this straightforward:
from torch.distributed.tensor.parallel import context_parallel
# Wrap attention computation with context parallelism
with context_parallel(
buffers=[query, key, value], # Tensors to shard
buffer_seq_dims=[1, 1, 1] # Dimension to shard along (sequence dimension)
):
# Standard scaled dot-product attention - automatically becomes Ring Attention
attention_output = torch.nn.functional.scaled_dot_product_attention(
query, key, value, attn_mask=None
)- Dynamic mask ratio adjustment – The MAE training approach required making sure unmasked patches plus classification tokens are evenly divisible across devices, necessitating adaptive masking strategies.
- Decoder sequence management – The decoder reconstructs the full image by processing both the unmasked patches from the encoder and the masked patches. This creates a different sequence length that also needs to be divisible by the number of GPUs.
The preceding implementation enabled processing of substantially larger 3D seismic volumes as illustrated in the following table.
Metric
Previous (Baseline)
With Context Parallelism
Maximum input size
640 × 640 × 1,024 voxels
1,536 × 1,536 × 2,048 voxels
Context length
102,400 tokens
1,170,000 tokens
Volume increase
1×
4.5×
The following figure provides an example of 2D model context size.
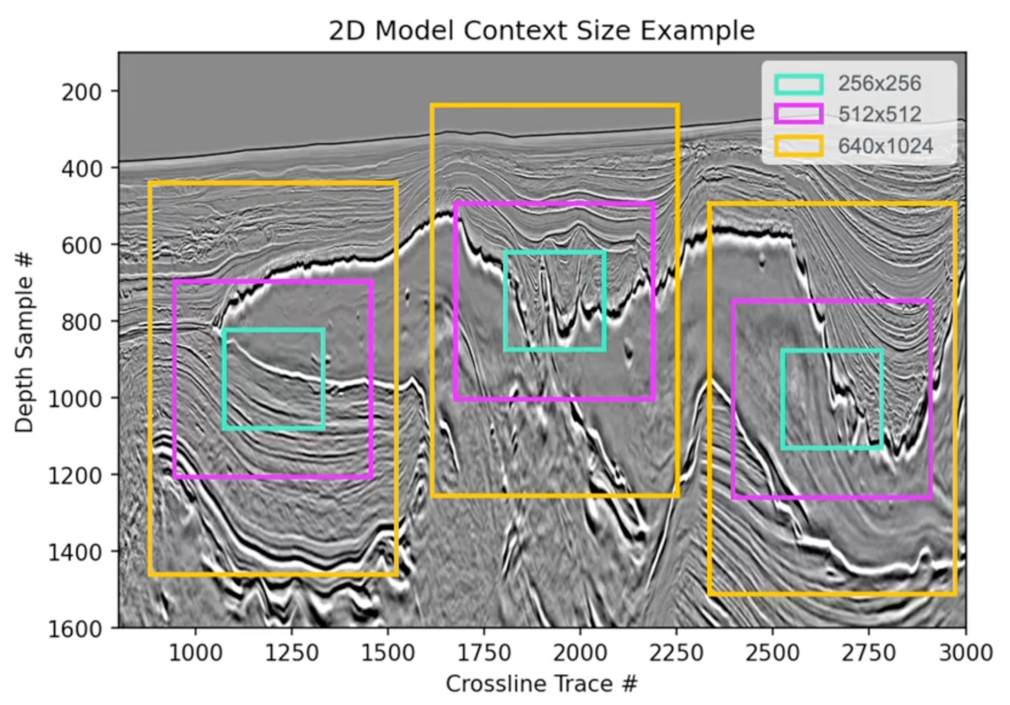
This expansion allows TGS’s models to capture geological features across broader spatial contexts, helping enhance the analytical capabilities they can offer to clients.
Results and impact
The collaboration between TGS and the AWS GenAIIC delivered substantial improvements across multiple dimensions:
- Significant training acceleration – The optimized distributed training architecture reduced training time from 6 months to 5 days—an approximate 36-fold speedup, enabling TGS to iterate faster and incorporate new geological data more frequently into their models.
- Near-linear scaling – The solution demonstrated strong scaling efficiency from single-node to 16-node configurations, achieving approximately 90–95% parallel efficiency with minimal performance degradation as the cluster size increased.
- Expanded analytical capabilities – The context parallelism implementation enables training on larger 3D volumes, allowing models to capture geological features across broader spatial contexts.
- Production-ready, cost-efficient infrastructure – The SageMaker HyperPod based solution with streaming from Amazon S3 helps provide a cost-effective foundation that scales efficiently as training requirements grow, while helping deliver the resilience, flexibility, and operational efficiency needed for production AI workflows.
These improvements establish a strong foundation for TGS’s AI-powered analytics system, delivering faster model iteration cycles and broader geological context per analysis to clients while helping protect TGS’s valuable data assets.
Lessons learned and best practices
Several key lessons emerged from this collaboration that might benefit other organizations working with large-scale 3D data and distributed training:
- Systematic scaling approach – Starting with a single-node baseline establishment before progressively expanding to larger clusters enabled systematic optimization at each stage while managing costs effectively.
- Data pipeline optimization is critical – For data-intensive workloads, thoughtful data pipeline design can provide strong performance. Direct streaming from object storage with appropriate parallelization and prefetching delivered the throughput needed without complex intermediate storage layers.
- Batch size tuning is nuanced – Increasing batch size doesn’t always improve throughput. The team found excessively large batch size can create bottlenecks in preparing and transferring data to GPUs. Through systematic testing at different scales, the team identified the point where throughput plateaued, indicating the data loading pipeline had become the limiting factor rather than GPU computation. This optimal balance maximized training efficiency without over-provisioning resources.
- Framework selection depends on your specific requirements – Different distributed training frameworks involve trade-offs between memory efficiency and communication overhead. The optimal choice depends on model size, hardware characteristics, and scaling requirements.
- Incremental validation – Testing configurations at smaller scales before expanding to full production clusters helped identify optimal settings while controlling costs during the development phase.
Conclusion
By partnering with the AWS GenAIIC, TGS has established an optimized, scalable infrastructure for training SFMs on AWS. The solution helps accelerate training cycles while expanding the models’ analytical capabilities, helping TGS deliver enhanced subsurface analytics to clients in the energy sector. The technical innovations developed during this collaboration—particularly the adaptation of context parallelism to ViT architectures for 3D volumetric data—demonstrate the potential for applying advanced AI techniques to specialized scientific domains. As TGS continues to expand its subsurface AI system and broader AI capabilities, this foundation can support future enhancements such as multi-modal integration and temporal analysis.
To learn more about scaling your own FM training workloads, explore SageMaker HyperPod for resilient distributed training infrastructure, or review the distributed training best practices in the SageMaker documentation. For organizations interested in similar collaborations, the AWS Generative AI Innovation Center partners with customers to help accelerate their AI initiatives.
Acknowledgement
Special thanks to Andy Lapastora, Bingchen Liu, Prashanth Ramaswamy, Rohit Thekkanal, Jared Kramer and Roy Allela for their contribution.
About the authors
<img loading="lazy" class="aligncenter size-full wp-image-125209" src="https://d2908q01vomqb2.cloudfront.net/f1f836cb4ea6efb2a0b1b99f41ad8b103eff4b59/2026/03/02/haotiaa-1.jpg" alt="Haotian An" w
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み