マルチエージェント協調パターン:5つのアプローチと適用タイミング
Claude Blogは、ジェネレーター-ベリファイア、オーケストレーター-サブエージェント、エージェントチーム、メッセージバス、共有状態という5つのマルチエージェント調整パターンと、それぞれの適切な使用場面、トレードオフについて解説している。
キーポイント
5つの主要な調整パターン
記事では、ジェネレーター-ベリファイア、オーケストレーター-サブエージェント、エージェントチーム、メッセージバス、共有状態という5つのマルチエージェント調整パターンを紹介している。
パターン選択の実践的アプローチ
問題に合った最もシンプルなパターンから始め、その限界を観察しながら進化させることを推奨しており、洗練されたものではなく適切なものを選ぶ重要性を強調している。
ジェネレーター-ベリファイアパターンの詳細
最もシンプルで広く展開されているパターンであり、品質が重要で評価基準を明確にできる場合に有効で、コード生成、事実確認、コンプライアンス検証などに適している。
各パターンの適切な使用場面
各パターンには特定の適応領域があり、例えばオーケストレーター-サブエージェントは明確なタスク分解が可能な場合、エージェントチームは並列で独立した長時間実行サブタスクに適している。
検証者の限界
検証者は明確な基準がなければ生成者の出力を無批判に承認する。また、創造的なアプローチの評価が生成と同じくらい難しい場合、検証者は問題を確実に捕捉できない。
オーケストレーターの課題
オーケストレーターは情報のボトルネックとなり、サブエージェント間の依存関係を認識して情報を適切にルーティングする必要があるが、重要な詳細が失われることがある。
エージェントチームの利点
ワーカーエージェントが複数のタスクにわたって存続し、コンテキストとドメイン知識を蓄積することで、パフォーマンスが向上する。
影響分析・編集コメントを表示
影響分析
この記事は、マルチエージェントシステムの実装における重要な実践的ガイダンスを提供しており、AIエージェントの実用的な展開を促進する可能性がある。特に、パターン選択の体系的なアプローチは、開発チームの意思決定を支援し、不適切な設計選択を防ぐのに役立つ。
編集コメント
マルチエージェントシステムの実装における具体的な設計パターンを体系的に整理した実践的なガイドであり、AIエンジニアやアーキテクトにとって有用な参考資料となる。
タイトル: マルチエージェント調整パターン: 5つのアプローチとその使用タイミング
マルチエージェント調整パターン: 5つのアプローチとその使用タイミング
5つのマルチエージェント調整パターン、そのトレードオフ、およびあるパターンから別のパターンへ移行するタイミング。
ProductClaude Code
日付: 2026年4月10日
読了時間: 5分
共有リンクをコピー: https://claude.com/blog/multi-agent-coordination-patterns
以前の投稿では、マルチエージェントシステムが価値を提供する場合と、単一エージェントがより適切な選択となる場合について考察しました。この投稿は、その判断を終え、次にどの調整パターンが自らの課題に適合するかを決める必要があるチームに向けたものです。
私たちは、目の前の課題に適合するものではなく、聞こえが洗練されているという理由でパターンを選択するチームを目にしてきました。私たちは、機能しうる最もシンプルなパターンから始め、それがどこで行き詰まるかを観察し、そこから発展させていくことを推奨します。この投稿では、5つのパターンの仕組みと限界を検証します:
ジェネレーター-ベリファイアー: 明示的な評価基準を持つ、品質が重要な出力向け
オーケストレーター-サブエージェント: 境界が明確なサブタスクによる、明確なタスク分解向け
エージェントチーム: 並列的で独立した、長時間実行されるサブタスク向け
メッセージバス: 拡大するエージェントエコシステムを持つ、イベント駆動型パイプライン向け
共有状態: エージェントが互いの発見を基に構築する協調作業向け
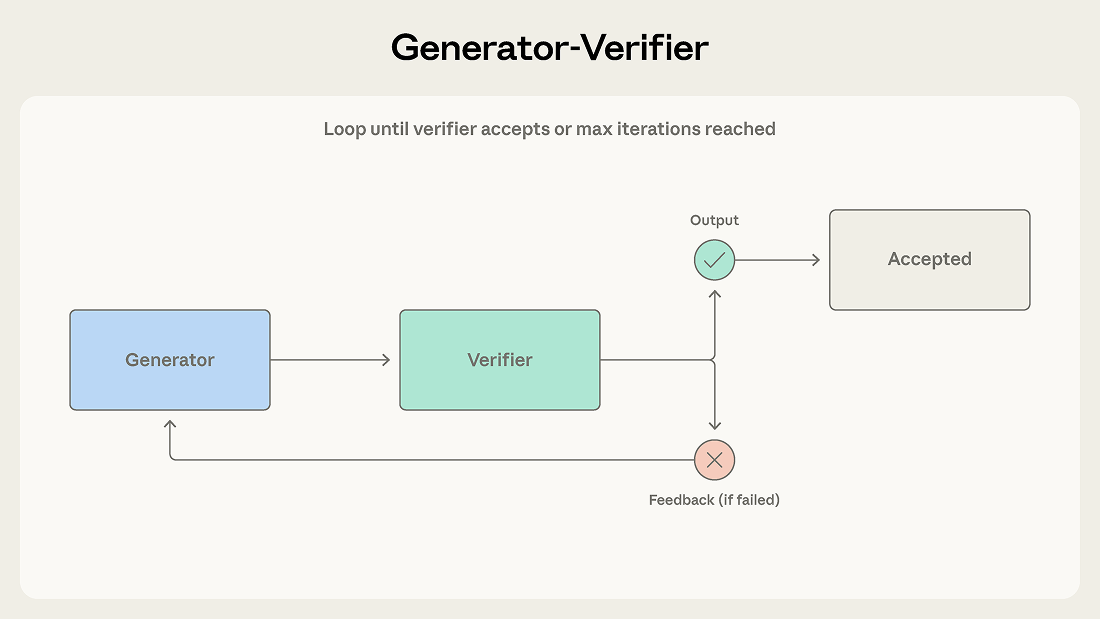
パターン1: ジェネレーター-ベリファイアー
これは最もシンプルなマルチエージェントパターンであり、最も広く導入されているものの一つです。前回の投稿では検証サブエージェントパターンとして紹介しましたが、ここではより広範な「ジェネレーター-ベリファイアー」という枠組みを用います。なぜなら、ジェネレーターは必ずしもオーケストレーターである必要がないからです。
ジェネレーターはタスクを受け取り、初期出力を生成して、それを評価のためにベリファイアーに渡します。ベリファイアーは出力が必要な基準を満たしているかどうかをチェックし、完了として承認するか、フィードバック付きで却下します。却下された場合、そのフィードバックはジェネレーターに戻され、ジェネレーターはそれを使って修正案を生成します。このループは、ベリファイアーが出力を承認するか、最大反復回数に達するまで続きます。
効果的な場面
顧客チケットへのメール返信を生成するサポートシステムを考えてみてください。ジェネレーターは製品ドキュメントとチケットの文脈を使って初期返信を生成します。ベリファイアーはナレッジベースに対する正確性をチェックし、ブランドガイドラインに照らしたトーンを評価し、返信が提起された各課題に対処していることを確認します。チェックに失敗した場合は、誤った価格帯に帰属された機能や未回答のチケット課題など、具体的な問題を指摘するフィードバックとともにジェネレーターに戻されます。
出力品質が重要で、評価基準を明示的に定義できる場合にこのパターンを使用してください。コード生成(1つのエージェントがコードを書き、別のエージェントがテストを作成・実行する)、ファクトチェック、ルーブリックに基づく採点、コンプライアンス検証、誤った出力が追加の生成サイクルよりも高くつくあらゆる領域で有効です。
苦戦する場面
ベリファイアーはその基準の良し悪しに依存します。「出力が良いかどうかのみをチェックする」とだけ指示され、それ以上の基準がないベリファイアーは、ジェネレーターの出力を無条件に承認してしまいます。チームが最もよく失敗するのは、「検証」の意味を定義せずにループを実装することであり、これにより実体のない品質管理の幻想が生み出されます。(この早期勝利問題については前回の投稿で議論しました。)
このパターンはまた、生成と検証が分離可能なスキルであることを前提としています。創造的なアプローチを評価することが、それを生成するのと同じくらい難しい場合、ベリファイアーは問題を確実に捕捉できないかもしれません。
最後に、反復ループが停滞する可能性があります。ジェネレーターがベリファイアーのフィードバックに対処できない場合、システムは収束せずに振動します。フォールバック戦略(人間にエスカレートする、注意点付きで最良の試行結果を返す)を伴う最大反復回数の制限を設けることで、これが無限ループになるのを防ぎます。
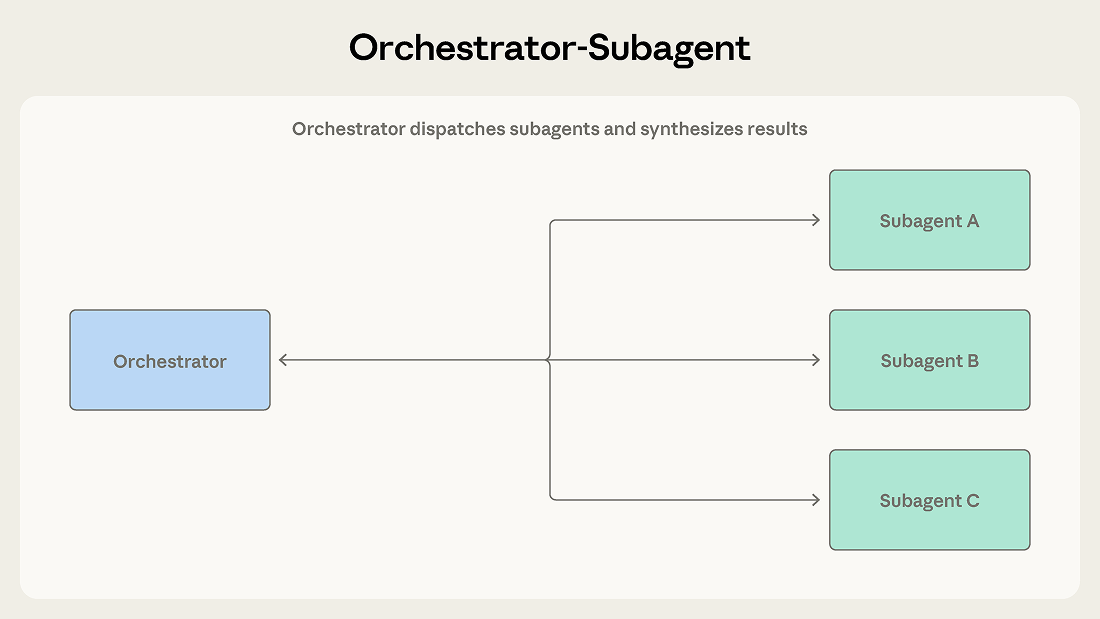
パターン2: オーケストレーター-サブエージェント
階層構造がこのパターンを特徴づけます。1つのエージェントがチームリーダーとして機能し、作業を計画し、タスクを委任し、結果を統合します。サブエージェントは特定の責務を処理し、報告します。
リードエージェントはタスクを受け取り、そのアプローチ方法を決定します。一部のサブタスクを直接処理しながら、他のサブタスクをサブエージェントに割り当てる場合があります。サブエージェントは作業を完了して結果を返し、オーケストレーターはそれらを最終出力に統合します。
Claude Codeはこのパターンを使用しています。メインエージェントは自らコードを書き、ファイルを編集し、コマンドを実行します。大規模なコードベースを検索したり独立した質問を調査する必要が生じた場合には、バックグラウンドでサブエージェントを起動し、結果が返ってくる間も作業を継続します。各サブエージェントは独自のコンテキストウィンドウで動作し、要約された調査結果を返します。これにより、オーケストレーターのコンテキストは主要タスクに集中したまま、探索が並行して進みます。
効果的な場面
自動コードレビューシステムを考えてみてください。プルリクエストが到着すると、システムはセキュリティ脆弱性のチェック、テストカバレッジの検証、コードスタイルの評価、アーキテクチャ一貫性の評価を行う必要があります。各チェックは異なり、異なる文脈を必要とし、明確な出力を生成します。オーケストレーターは各チェックを専門のサブエージェントに割り当て、結果を収集し、統合されたレビューにまとめます。
タスク分解が明確で、サブタスク間の相互依存性が最小限である場合にこのパターンを使用してください。オーケストレーターは全体目標への一貫した視野を維持し、サブエージェントは特定の責務に集中します。
苦戦する場面
オーケストレーターが情報のボトルネックとなります。サブエージェントが別のサブエージェントの作業に関連する何かを発見した場合、その情報はオーケストレーターを経由して戻る必要があります。セキュリティサブエージェントが認証上の欠陥を発見し、それがアーキテクチャサブエージェントの分析に影響する場合、オーケストレーターはこの依存関係を認識し、情報を適切に伝達する必要があります。このような受け渡しが数回行われると、重要な詳細はしばしば失われたり、要約されてしまったりします。
逐次実行はまた、スループットを制限します。明示的に並列化されない限り、サブエージェントは次々に実行されるため、システムは速度向上のメリットなしにマルチエージェントのトークンコストを負うことになります。
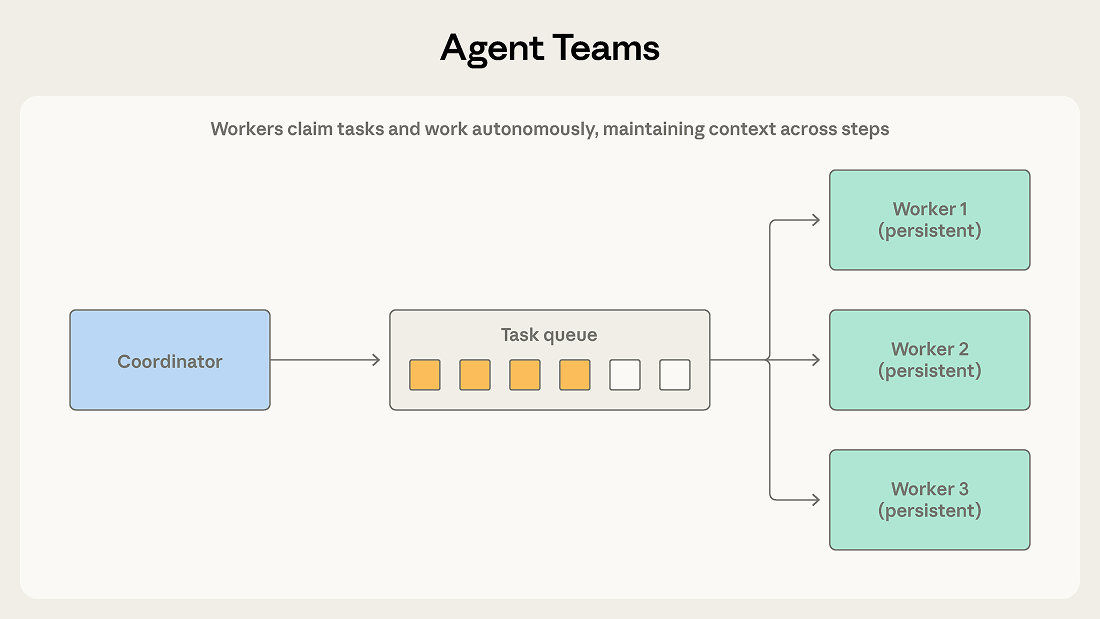
パターン3: エージェントチーム
作業が並列的なサブタスクに分解され、それらが長期間にわたって独立して進められる場合、オーケストレーター-サブエージェントパターンは不必要に制約的になる可能性があります。
コーディネーターは、複数のワーカーエージェントを独立したプロセスとして生成します。チームメンバーは共有キューからタスクを要求し、複数のステップにわたって自律的に作業し、完了を通知します。
オーケストレーター-サブエージェントとの違いは、ワーカーの永続性です。オーケストレーターは単一の境界のあるサブタスクに対してサブエージェントを生成し、サブエージェントは結果を返した後に終了します。チームメンバーは多くの割り当てにわたって存続し、コンテキストとドメイン専門性を蓄積して、時間とともにパフォーマンスを向上させます。コーディネーターは作業を割り当て、結果を収集しますが、タスク間でワーカーをリセットすることはありません。
効果的な場面
大規模なコードベースをあるフレームワークから別のフレームワークへ移行する作業を考えてみてください。チームメンバーは各サービスを独立して移行できます。各サービスには独自の依存関係、テストスイート、デプロイメント構成があります。コーディネーターは各サービスをチームメンバーに割り当て、各チームメンバーは自律的に移行を進めます:依存関係の更新、コード変更、テスト修正、検証。コーディネーターは完了した移行を収集し、システム全体の統合テストを実行します。
サブタスクが独立しており、持続的で多段階の作業から利益を得る場合にこのパターンを使用してください。各チームメンバーは、割り当てごとにゼロから始めるのではなく、そのドメインに関するコンテキストを構築していきます。
苦戦する場面
独立性が重要な要件です。オーケストレーター-サブエージェントではオーケストレーターがサブエージェント間を仲介して情報を伝達できますが、チームメンバーは自律的に動作するため、中間的な発見を容易に共有できません。あるチームメンバーの作業が別のチームメンバーの作業に影響を与える場合、どちらもそれに気づかず、出力が競合する可能性があります。
完了の検知もより困難です。チームメンバーが可変の期間にわたって自律的に作業するため、コーディネーターは、あるチームメンバーが2分で終了し、別のチームメンバーが20分かかるような部分的な完了を処理する必要があります。
共有リソースは両方の問題を悪化させます。複数のチームメンバーが同じコードベース、データベース、またはファイルシステムで作業する場合、2つのチームメンバーが同じファイルを編集したり、互換性のない変更を行ったりする可能性があります。このパターンは、注意深いタスク分割と競合解決メカニズムを必要とします。
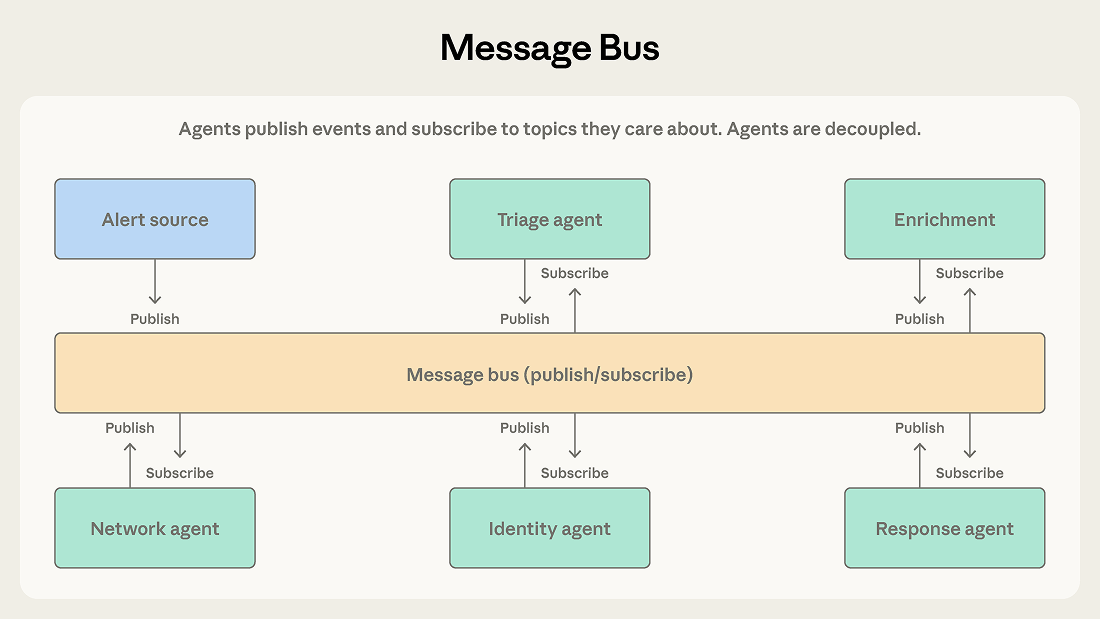
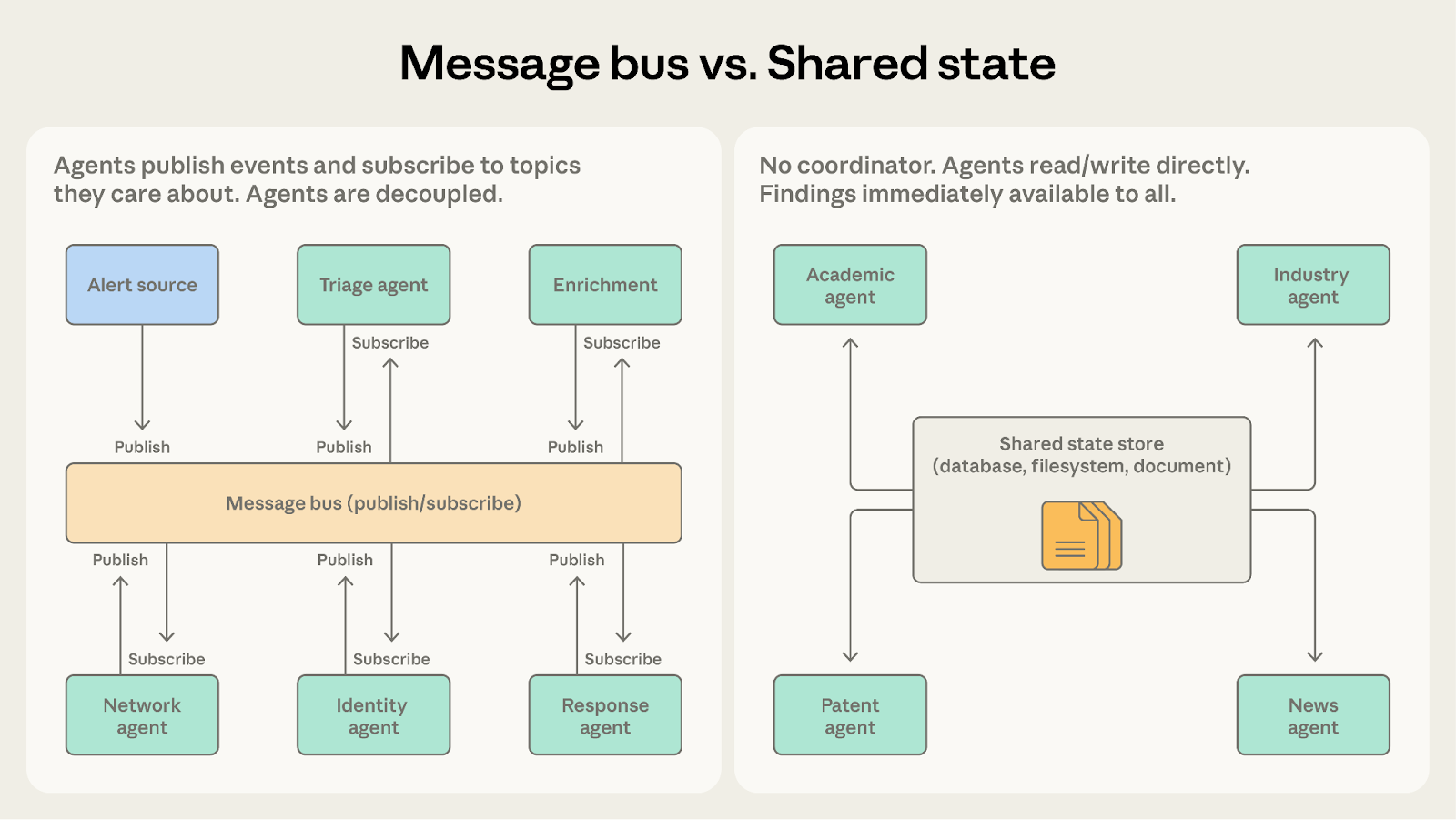
パターン4: メッセージバス
エージェントの数が増え、相互作用パターンが複雑になるにつれて、直接的な調整は管理が難しくなります。メッセージバスは、エージェントがイベントを発行および購読する共有通信レイヤーを導入します。
エージェントは、発行と購読という2つの基本操作を通じて相互作用します。エージェントは関心のあるトピックを購読し、ルーターが一致するメッセージを配信します。新機能を持つ新しいエージェントは、既存の接続を配線し直すことなく、関連する作業の受信を開始できます。
効果的な場面
セキュリティ運用自動化システムは、このパターンが優れる場面を示しています。アラートは複数のソースから到着し、トリアージエージェントが各アラートを重大度とタイプで分類します。高重大度のネットワークアラートはネットワーク調査エージェントに、資格情報関連のアラートはアイデンティティ分析エージェントにルーティングされます。各調査エージェントは、コンテキスト収集エージェントが満たすエンリッチメントリクエストを発行する場合があります。発見は、適切なアクションを決定するレスポンス調整エージェントへと流れていきます。
このパイプラインはメッセージバスに適しています。なぜなら、イベントはある段階から次の段階へ流れ、チームは脅威カテゴリの進化に合わせて新しいエージェントタイプを追加でき、エージェントを独立して開発およびデプロイできるからです。
ワークフローが事前に決められたシーケンスではなくイベントから生じ、エージェントエコシステムが成長する可能性が高いイベント駆動型パイプラインにこのパターンを使用してください。
苦戦する場面
イベント駆動型通信の柔軟性は、トレーシングをより困難にします。アラートが5つのエージェントにわたる一連のイベントを引き起こす場合、何が起こったかを理解するには注意深いロギングと相関付けが必要です。デバッグは、オーケストレーターの逐次的な決定を追跡するよりも困難です。
原文を表示
Multi-agent coordination patterns: Five approaches and when to use them
Five multi-agent coordination patterns, their trade-offs, and when to evolve from one to another.
ProductClaude Code
DateApril 10, 2026
Reading time5min
ShareCopy linkhttps://claude.com/blog/multi-agent-coordination-patterns
In an earlier post, we explored when multi-agent systems provide value and when a single agent is the better choice. This post is for teams that have made that call and now need to decide which coordination pattern fits their problem.
We've seen teams choose patterns based on what sounds sophisticated rather than what fits the problem at hand. We recommend starting with the simplest pattern that could work, watching where it struggles, and evolving from there. This post examines the mechanics and limitations of five patterns:
Generator-verifier, for quality-critical output with explicit evaluation criteria
Orchestrator-subagent, for clear task decomposition with bounded subtasks
Agent teams, for parallel, independent, long-running subtasks
Message bus, for event-driven pipelines with a growing agent ecosystem
Shared-state, for collaborative work where agents build on each other's findings
Pattern 1: Generator-verifier
This is the simplest multi-agent pattern and among the most deployed. We introduced it as the verification subagent pattern in our previous post, and here we use the broader generator-verifier framing because the generator need not be an orchestrator.
A generator receives a task and produces an initial output, which it passes to a verifier for evaluation. The verifier checks whether the output meets the required criteria and either accepts it as complete or rejects it with feedback. If rejected, that feedback is routed back to the generator, which uses it to produce a revised attempt. This loop continues until the verifier accepts the output or the maximum number of iterations is reached.
Where it works well
Consider a support system that generates email responses to customer tickets. The generator produces an initial response using product documentation and ticket context. The verifier checks accuracy against the knowledge base, evaluates tone against brand guidelines, and confirms the response addresses each issue raised. Failed checks return to the generator with feedback that names the exact problem, such as a feature misattributed to the wrong pricing tier or a ticket issue left unanswered.
Use this pattern when output quality is critical and evaluation criteria can be made explicit. It’s effective for code generation (one agent writes code, another writes and runs tests), fact-checking, rubric-based grading, compliance verification, and any domain where an incorrect output costs more than an additional generation cycle.
Where it struggles
The verifier is only as good as its criteria. A verifier told only to check whether output is good, with no further criteria, will rubber-stamp the generator's output. Teams most often fail by implementing the loop without defining what verification means, which creates the illusion of quality control without the substance. (We discussed this early victory problem in the previous post.)
The pattern also assumes generation and verification are separable skills. If evaluating a creative approach is as hard as generating one, the verifier may not reliably catch problems.
Finally, iterative loops can stall. If the generator can't address the verifier's feedback, the system oscillates without converging. A maximum iteration limit with a fallback strategy (escalate to a human, return the best attempt with caveats) prevents this from becoming an infinite loop.
Pattern 2: Orchestrator-subagent
Hierarchy defines this pattern. One agent acts as a team lead that plans work, delegates tasks, and synthesizes results. Subagents handle specific responsibilities and report back.
A lead agent receives a task and determines how to approach it. It may handle some subtasks directly while dispatching others to subagents. Subagents complete their work and return results, which the orchestrator synthesizes into a final output.
Claude Code uses this pattern. The main agent writes code, edits files, and runs commands itself, dispatching subagents in the background when it needs to search a large codebase or investigate independent questions so work continues while results stream back. Each subagent operates in its own context window and returns distilled findings. This keeps the orchestrator's context focused on the primary task while exploration happens in parallel.
Where it works well
Consider an automated code review system. When a pull request arrives, the system needs to check for security vulnerabilities, verify test coverage, assess code style, and evaluate architectural consistency. Each check is distinct, requires different context, and produces a clear output. An orchestrator dispatches each check to a specialized subagent, collects the results, and synthesizes a unified review.
Use this pattern when task decomposition is clear and subtasks have minimal interdependence. The orchestrator maintains a coherent view of the overall goal while subagents stay focused on specific responsibilities.
Where it struggles
The orchestrator becomes an information bottleneck. When a subagent discovers something relevant to another subagent's work, that information has to travel back through the orchestrator. If the security subagent finds an authentication flaw that affects the architecture subagent's analysis, the orchestrator must recognize this dependency and route the information appropriately. After several such handoffs, critical details are often lost or summarized away.
Sequential execution also limits throughput. Unless explicitly parallelized, subagents run one after another, meaning the system incurs multi-agent token costs without the speed benefit.
Pattern 3: Agent teams
When work decomposes into parallel subtasks that can proceed independently for extended periods, orchestrator-subagent can become unnecessarily constraining.
A coordinator spawns multiple worker agents as independent processes. Teammates claim tasks from a shared queue, work on them autonomously across multiple steps, and signal completion.
The difference from orchestrator-subagent is worker persistence. The orchestrator spawns a subagent for one bounded subtask, and the subagent terminates after returning a result. Teammates stay alive across many assignments, accumulating context and domain specialization that improve their performance over time. The coordinator assigns work and collects outcomes but doesn’t reset workers between tasks.
Where it works well
Consider migrating a large codebase from one framework to another. A teammate can migrate each service independently, with its own dependencies, test suite, and deployment configuration. A coordinator assigns each service to a teammate, and each teammate works through the migration autonomously: dependency updates, code changes, test fixes, validation. The coordinator collects completed migrations and runs integration tests across the full system.
Use this pattern when subtasks are independent and benefit from sustained, multi-step work. Each teammate builds up context about its domain rather than starting fresh with each dispatch.
Where it struggles
Independence is the critical requirement. Unlike orchestrator-subagent, where the orchestrator can mediate between subagents and route information, teammates operate autonomously and can't easily share intermediate findings. If one teammate's work affects another's, neither is aware, and their outputs may conflict.
Completion detection is also harder. Since teammates work autonomously for variable durations, the coordinator must handle partial completion where one teammate finishes in two minutes and another takes twenty.
Shared resources compound both problems. When multiple teammates operate on the same codebase, database, or file system, two teammates may edit the same file or make incompatible changes. The pattern requires careful task partitioning and conflict resolution mechanisms.
Pattern 4: Message bus
As agent count increases and interaction patterns grow complex, direct coordination becomes difficult to manage. A message bus introduces a shared communication layer where agents publish and subscribe to events.
Agents interact through two primitives: publish and subscribe. Agents subscribe to the topics they care about, and a router delivers matching messages. New agents with new capabilities can start receiving relevant work without rewiring existing connections.
Where it works well
A security operations automation system demonstrates where this pattern excels. Alerts arrive from multiple sources, and a triage agent classifies each by severity and type, routing high-severity network alerts to a network investigation agent and credential-related alerts to an identity analysis agent. Each investigation agent may publish enrichment requests that a context-gathering agent fulfills. Findings flow to a response coordination agent that determines the appropriate action.
This pipeline suits the message bus because events flow from one stage to the next, teams can add new agent types as threat categories evolve, and teams can develop and deploy agents independently.
Use this pattern for event-driven pipelines where the workflow emerges from events rather than a predetermined sequence, and where the agent ecosystem is likely to grow.
Where it struggles
The flexibility of event-driven communication makes tracing harder. When an alert triggers a cascade of events across five agents, understanding what happened requires careful logging and correlation. Debugging is harder than following an orchestrator's sequential decisions.
Routing accuracy is also critical. If the router misclassifies or drops an event, the system fails silently, handling nothing but never crashing. LLM-based routers provide semantic flexibility but introduce their own failure modes.
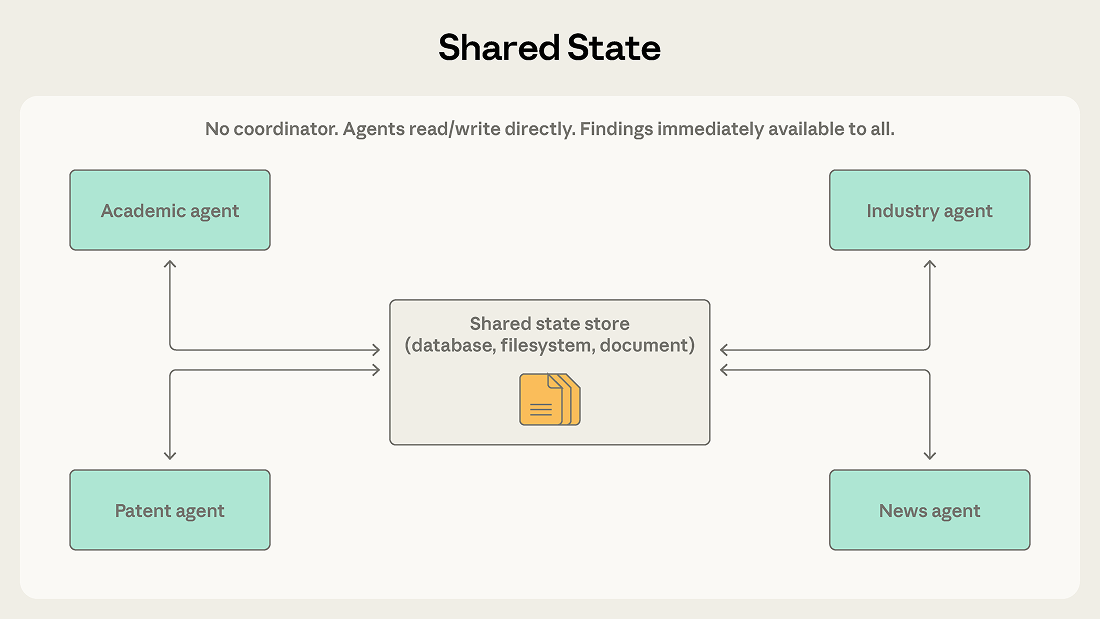
Pattern 5: Shared state
Orchestrators, team leads, and message routers in the previous patterns all centrally manage information flow. Shared state removes the intermediary by letting agents coordinate through a persistent store that all can read and write directly.
Agents operate autonomously, reading from and writing to a shared database, file system, or document. There's no central coordinator. Agents check the store for relevant information, act on what they find, and write their findings back. Work typically begins when an initialization step seeds the store with a question or dataset, and ends when a termination condition is met: a time limit, a convergence threshold, or a designated agent determining the store contains a sufficient answer.
Where it works well
Consider a research synthesis system where multiple agents investigate different aspects of a complex question. One explores academic literature, another analyzes industry reports, a third examines patent filings, a fourth monitors news coverage. Each agent's findings may inform the others' investigations. The academic literature agent might discover a key researcher whose company the industry agent should examine more closely.
With shared state, findings go directly into the store. The industry agent can see the academic agent's discoveries immediately, without waiting for a coordinator to route the information. Agents build on each other’s work, and the shared store becomes an evolving knowledge base.
Shared state also removes the coordinator as a single point of failure. If any one agent stops, the others continue reading and writing. In orchestrator and message-bus systems, a coordinator or router failure halts everything.
Where it struggles
Without explicit coordination, agents may duplicate work or pursue contradictory approaches. Two agents might independently investigate the same lead. Agent interactions produce system behavior rather than top-down design, which makes outcomes less predictable.
The harder failure mode is reactive loops. For example, Agent A writes a finding, Agent B reads it and writes a follow-up, Agent A sees the follow-up and responds. The system keeps burning tokens on work that isn’t converging. Duplicate work and concurrent writes have known engineering fixes (locking, versioning, partitioning). Reactive loops are a behavioral problem and need first-class termination conditions: a time budget, a convergence threshold (no new findings for N cycles), or a designated agent whose job is to decide when the store contains a sufficient answer. Systems that treat termination as an afterthought tend to cycle indefinitely or stop arbitrarily when one agent's context fills.
Choosing and evolving between patterns
The right pattern depends on a handful of structural questions about the system. In our previous post, we argued for context-centric decomposition, which divides work by what context each agent needs rather than by what type of work it does. That principle applies here too. The patterns differ in how they manage context boundaries and information flow.
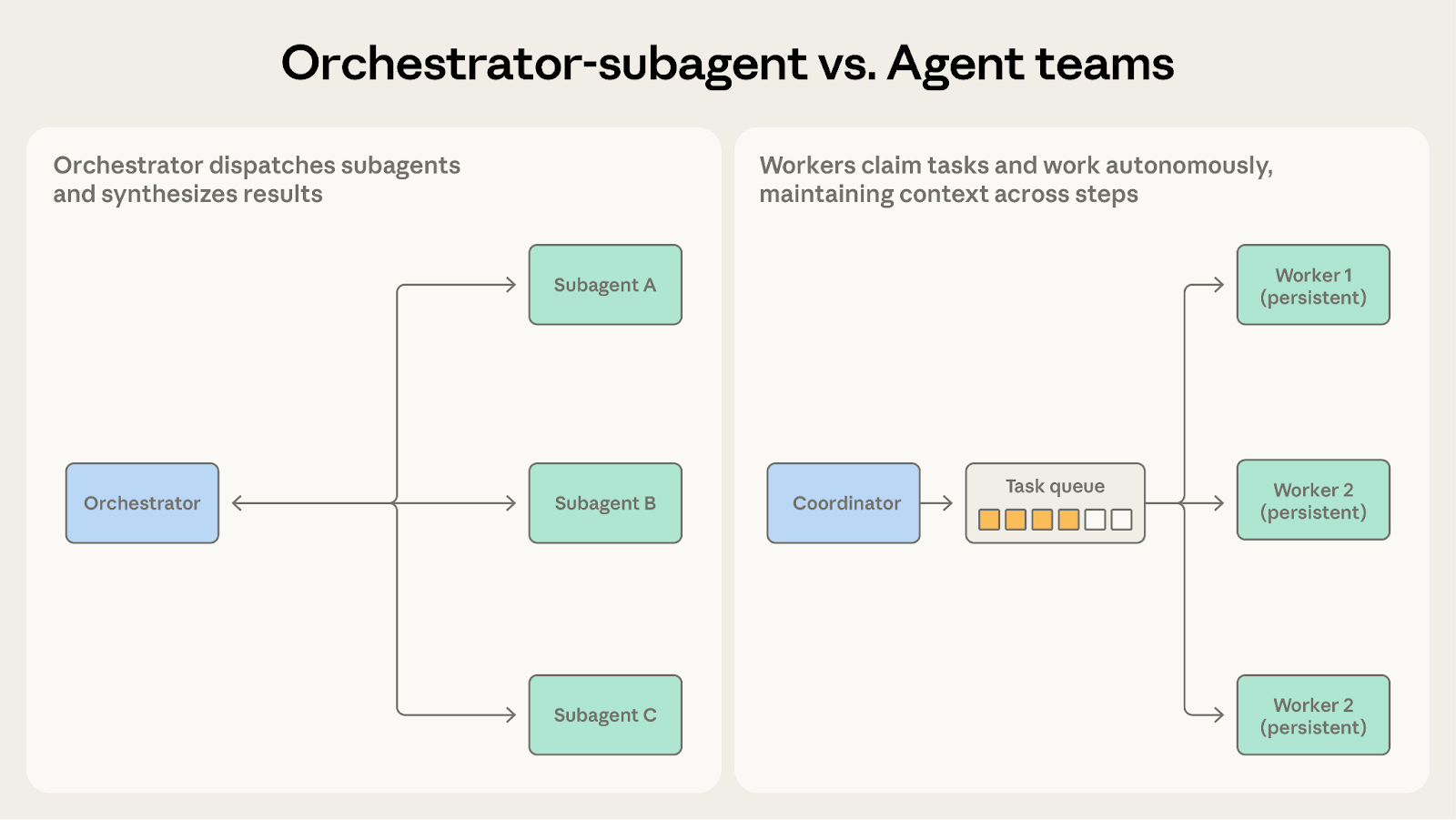
Orchestrator-subagent vs. agent teams
Both involve a coordinator dispatching work to other agents. The question is how long workers need to maintain their context.
Choose orchestrator-subagent when subtasks are short, focused, and produce clear outputs. The code review system works well here because each check runs its analysis, generates a report, and returns within a single bounded invocation. The subagent doesn't need to carry context across multiple cycles.
Choose agent teams when subtasks benefit from sustained, multi-step work. The codebase migration fits here because each teammate develops real familiarity with its assigned service: the dependency graph, test patterns, deployment configuration. That accumulated context improves performance in ways one-shot dispatch can't replicate.
When subagents need to retain state across invocations, agent teams are the better fit.
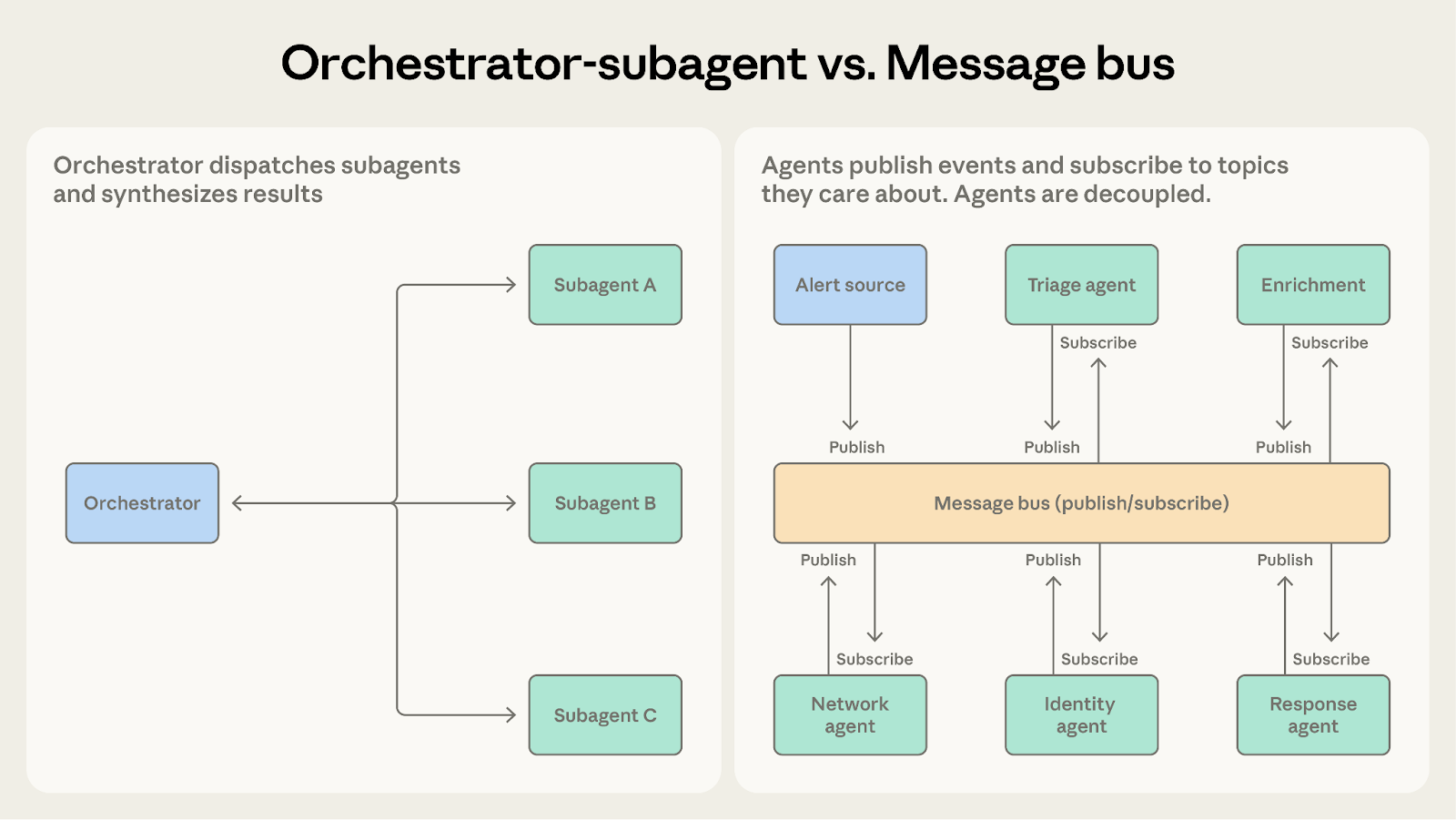
Orchestrator-subagent vs. message bus
Both can handle multi-step workflows. The question is how predictable the workflow structure is.
Choose orchestrator-subagent when the sequence of steps is known in advance. The code review system follows a fixed pipeline: receive a PR, run checks, synthesize results.
Choose message bus when the workflow emerges from events and may vary based on what's discovered. The security operations system can't predict what alerts will arrive or what investigation paths they'll require. New alert types may emerge that need new handling. The message bus accommodates that variability by routing events to capable agents rather than following a predetermined sequence.
As conditional logic accumulates in the orchestrator to handle an expanding variety of cases, the message bus makes that routing explicit and extensible.
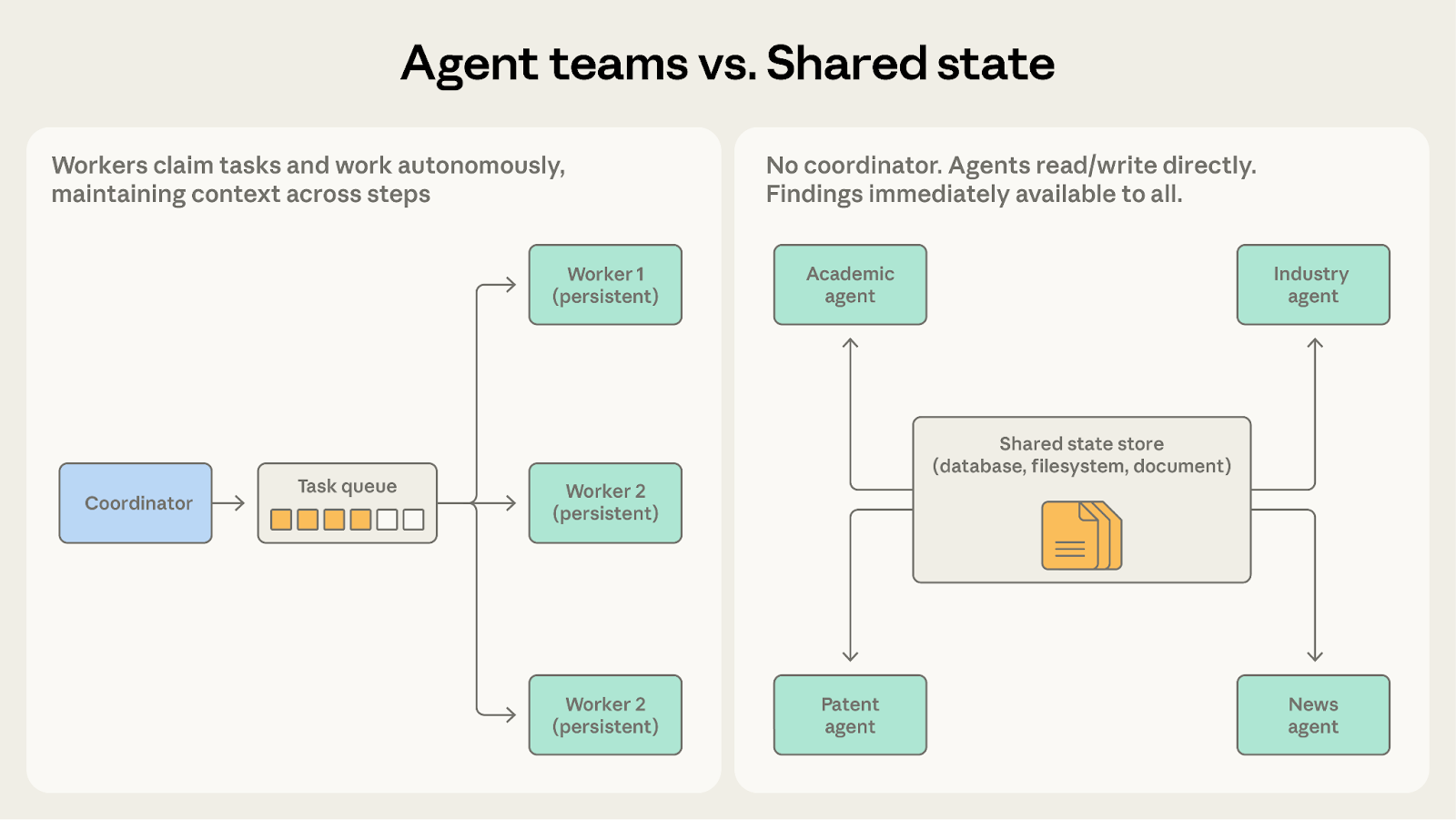
Agent teams vs. shared state
Both involve agents working autonomously. The question is whether agents need each other's findings.
Choose agent teams when agents work on separate partitions that don't interact. The codebase migration fits here because each teammate handles its service and the coordinator combines results at the end.
Choose shared state when agents' work is collaborative and findings should flow between them in real time. The research synthesis system is a better match because the academic agent's discovery of a key researcher immediately becomes relevant to the industry agent's investigation.
Once teammates need to communicate with each other rather than only share final results, shared state makes that more natural.
Message bus vs. shared state
Both support complex multi-agent coordination. The question is whether work flows as discrete events or accumulates into a shared knowledge base.
Choose message bus when agents react to events in a pipeline. The security operations system processes alerts stage by stage, with each event triggering the next before completing. The pattern is efficient at routing events to capable agents.
Choose shared state when agents build on accumulated findings over time. The research synthesis system gathers knowledge continuously. Agents return to the store repeatedly, seeing what others have discovered and adjusting their investigations.
The message bus still has a router, which means a central component decides where events go. Shared state is decentralized. If eliminating single points of failure is a priority, shared state provides that more completely.
If agents in a message bus system are publishing events to share findings rather than trigger actions, shared state is a better fit.
Getting started
Production systems often combine patterns. A common hybrid uses orchestrator-subagent for the overall workflow with shared state for a collaboration-heavy subtask. Another uses message bus for event routing with agent team-style workers handling each event type. These patterns are building blocks, not mutually exclusive choices.
The following table summarizes when each pattern is appropriate.
Quality-critical output, explicit evaluation criteria
Generator-Verifier
Clear task decomposition, bounded subtasks
Orchestrator-Subagent
Parallel workload, independent long-running subtasks
Event-driven pipeline, growing agent ecosystem
Collaborative research, agents share discoveries
No single point of failure required
For most use cases, we recommend starting with orchestrator-subagent. It handles the widest range of problems with the least coordination overhead. Observe where it struggles, then evolve toward other patterns as specific needs become clear.
In upcoming posts, we will examine each pattern in depth with production implementations and case studies. For background on when multi-agent systems are worth the investment, see Building multi-agent systems: when and how to use them.
PrevPrev0/5NextNexteBook
Explore more product news and best practices for teams building with Claude.
Harnessing Claude’s intelligence
AgentsHarnessing Claude’s intelligenceHarnessing Claude’s intelligenceHarnessing Claude’s intelligenceHarnessing Claude’s intelligence  Mar 5, 2026Common workflow patterns for AI agents—and when to use them
Mar 5, 2026Common workflow patterns for AI agents—and when to use them
AgentsCommon workflow patterns for AI agents—and when to use themCommon workflow patterns for AI agents—and when to use themCommon workflow patterns for AI agents—and when to use themCommon workflow patterns for AI agents—and when to use them  Feb 24, 2026Cowork and plugins for finance
Feb 24, 2026Cowork and plugins for finance
Enterprise AICowork and plugins for finance Cowork and plugins for finance Cowork and plugins for finance Cowork and plugins for finance  Feb 24, 2026Cowork and plugins for teams across the enterprise
Feb 24, 2026Cowork and plugins for teams across the enterprise
AgentsCowork and plugins for teams across the enterpriseCowork and plugins for teams across the enterpriseCowork and plugins for teams across the enterpriseCowork and plugins for teams across the enterpriseTransform how your organization operates with Claude
Get the developer newsletter
Product updates, how-tos, community spotlights, and more. Delivered monthly to your inbox.
SubscribeSubscribePlease provide your email address if you'd like to receive our monthly developer newsletter. You can unsubscribe at any time.



関連記事
2026年3月6日 Frontier Red TeamによるClaudeのCVE-2026-2796エクスプロイトのリバースエンジニアリング
Frontier Red Teamが、Claudeの脆弱性CVE-2026-2796を悪用するエクスプロイトをリバースエンジニアリングした。
フロンティア・レッドチーム、Firefoxのセキュリティ向上のためにMozillaと提携
フロンティア・レッドチームは、Firefoxのセキュリティを向上させるため、Mozillaと提携した。
59%のユーザーがより安価なモデルを選択:Sonnet 4.6の詳細解説
Anthropic社がClaude Sonnet 4.6をリリースし、Claude Codeテストで70%のユーザーが前世代モデルより好み、59%がフラッグシップモデルOpus 4.5よりも選択した。コーディング、コンピュータ利用、100万トークンコンテキストなど6次元で全面アップグレードされ、価格は据え置き。