オープンソースのモデルプロファイラーでAmazon Bedrock上のモデル選択を簡素化
AWS は生成 AI モデルの選定と比較を効率化するオープンソースツール「Model Profiler」を公開し、散在する情報を一元化して意思決定を加速させる。
キーポイント
モデル選定の複雑性解消
Amazon Bedrock の利用者が直面する、複数プロバイダー間の機能比較や価格・リージョン情報の散在問題を解決し、一元化された検索インターフェースを提供します。
自動化されたデータ収集パイプライン
5 つの AWS API と 2 つの公開 URL からデータを自動収集・処理するサーバーレス基盤により、手動更新なしで最新かつ正確なカタログ情報を維持します。
迅速な導入とデプロイ
このツールは GitHub で公開されており、開発者は 5 分以内のデプロイで自環境に導入し、コスト最適化や移行プロジェクトに即座に活用できます。
影響分析・編集コメントを表示
影響分析
このニュースは、生成 AI の実装フェーズにおいて最も時間がかかる「モデル選定」プロセスに劇的な変化をもたらす可能性があります。開発チームがドキュメントやコンソールを往復する手間を省くことで、プロダクションへの移行期間を短縮し、コストとパフォーマンスの最適化を迅速に行えるようになります。特に大規模な AI 導入が進む企業にとって、意思決定の遅延を防ぐ重要なインフラツールと言えます。
編集コメント
AWS が提供する公式ドキュメントやコンソールを超えた、開発者視点の強力なサードパーティツール(オープンソース)が登場した点は注目すべき展開です。これにより、企業はより客観的なデータに基づいてモデル選定を行い、AI プロジェクトの成功確率を高めることが期待できます。
生成 AI の導入は業界全体で加速しており、Amazon Bedrock は、本番環境対応の AI アプリケーションを構築するためのマネージドサービスを提供しています。Anthropic、OpenAI、Meta、Mistral AI、Cohere、および Amazon などのプロバイダーから 100 以上のファウンデーションモデル(基盤モデル)にアクセスできるため、チームは各ユースケースに適したモデルを選択する柔軟性を有しています。
しかし、選択肢が増えることは複雑さを伴います。機能、価格、地域ごとの利用可否、コンテキストウィンドウの制限、スループットといった観点でモデルを比較することは容易ではありません。これらの情報は、コンソールのページ、ドキュメント、および地域別の API 呼び出しに散在しています。新しいワークロード向けにモデルを検証する組織や、コストとパフォーマンスの最適化を図る場合、あるいは他の AI システムからの移行を検討している場合、この断片的な発見プロセスは実験を遅らせ、本番環境への導入決定を延期させる要因となります。
Amazon Bedrock Model Profiler は、この課題を解決するツールです。このオープンソースツールは、複数の AWS API および外部ソースからモデルのメタデータを収集し、単一の検索可能なインターフェースに統合します。高度なフィルタリング機能、並列比較機能、詳細なモデルカード(モデル情報カード)を活用することで、チームは Amazon Bedrock のカタログ全体を探索でき、さまざまなドキュメントやモデルカードを手動で検索する手間を軽減しながら、データに基づいた根拠のある意思決定を行うことが可能になります。
この記事では、Model Profiler が提供する機能、それが対応する実世界のシナリオ、そして 5 分以内にお使いの環境にデプロイする方法について学びます。
ソリューション概要
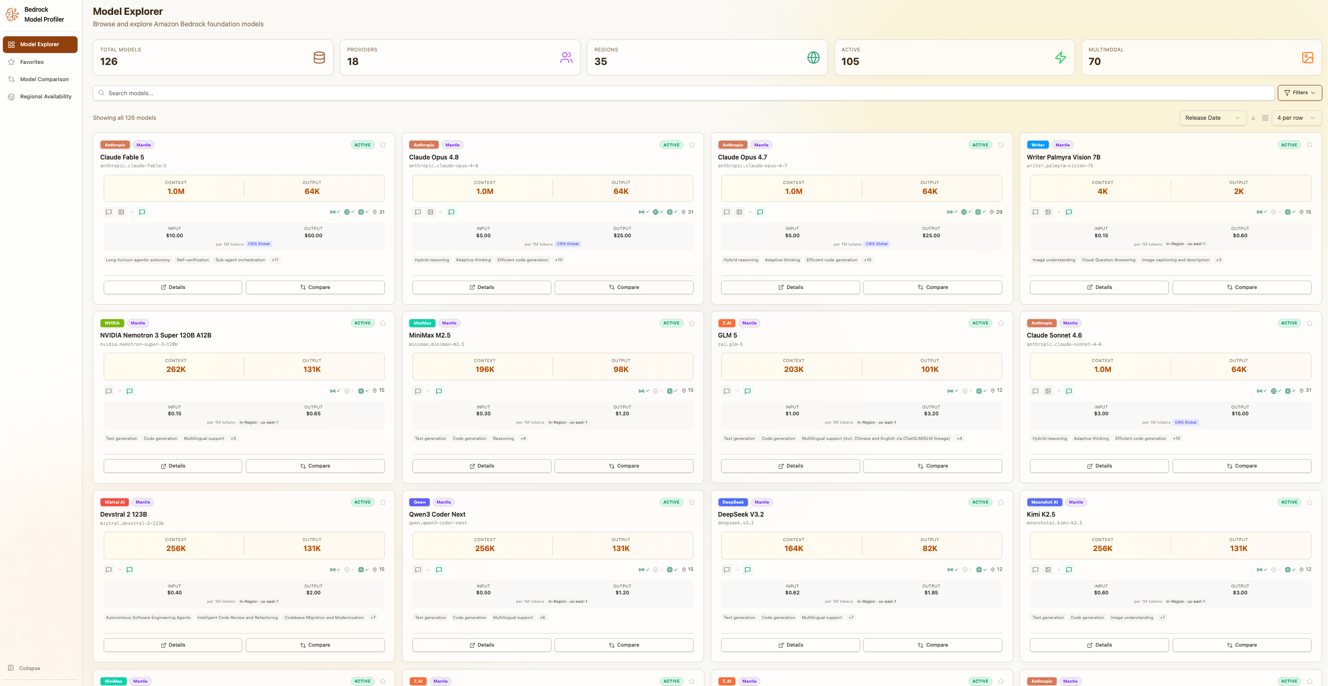
Model Profiler は、Amazon Bedrock で利用可能なすべてのファウンデーションモデルを一度に閲覧、フィルタリング、比較できる Web アプリケーションです。複数のコンソールページやドキュメントサイトを行き来する必要はなく、モデルカード、並列比較、リージョン別の可用性マップ、毎日更新される価格内訳を含む単一のインターフェースが提供されます。
 image
image
Model Explorer インターフェースを表示する Model Profiler
このインターフェースの背後では、7 つの異なるソース(5 つの AWS API と 2 つのパブリック URL)からデータを収集・処理する完全自動化されたサーバーレスパイプラインが稼働しています。これにより、手動介入なしでカタログの正確性が保たれます。
ソース
タイプ
認証
収集データ
Amazon Bedrock ListFoundationModels API
AWS API
IAM (Sigv4)
モデル仕様、機能、モダリティ、および 33 リージョンにわたるリージョン別可用性
AWS Price List API
AWS API
IAM (Sigv4)
オンデマンド、バッチ、リザーブドティアの価格(3 つのサービスコード)
AWS Service Quotas API
AWS API
IAM (Sigv4)
1 分あたりのトークン数 (TPM) リミット、1 分あたりのリクエスト数 (RPM) クォータ、スループット制約
Amazon Bedrock ListInferenceProfiles API
AWS API
IAM (Sigv4)
クロスリージョン推論設定と地理的スコープ
Amazon Bedrock Mantle API
AWS API
IAM (Sigv4)
リージョン横断のMantle推論利用可能性
LiteLLM Model Database
パブリック URL
なし
コンテキストウィンドウサイズや最大出力トークン数を含むトークンスペシフィケーション
AWS Documentation
パブリック URL
なし
モデルのライフサイクルステータス(アクティブ、レガシー、サポート終了)
モデルを評価する際には、主要なクォータ指標を理解することが不可欠です。Tokens-per-minute (TPM) は、1 分あたりに処理できるトークン数を測定します。これはスループットの上限と考えることができ、1,000 トークンは約 750 単語のテキストに相当します。Requests-per-minute (RPM) は、サイズに関係なく実行可能な API コールの回数を制限します。両方のクォータはモデルおよびリージョンによって異なります。
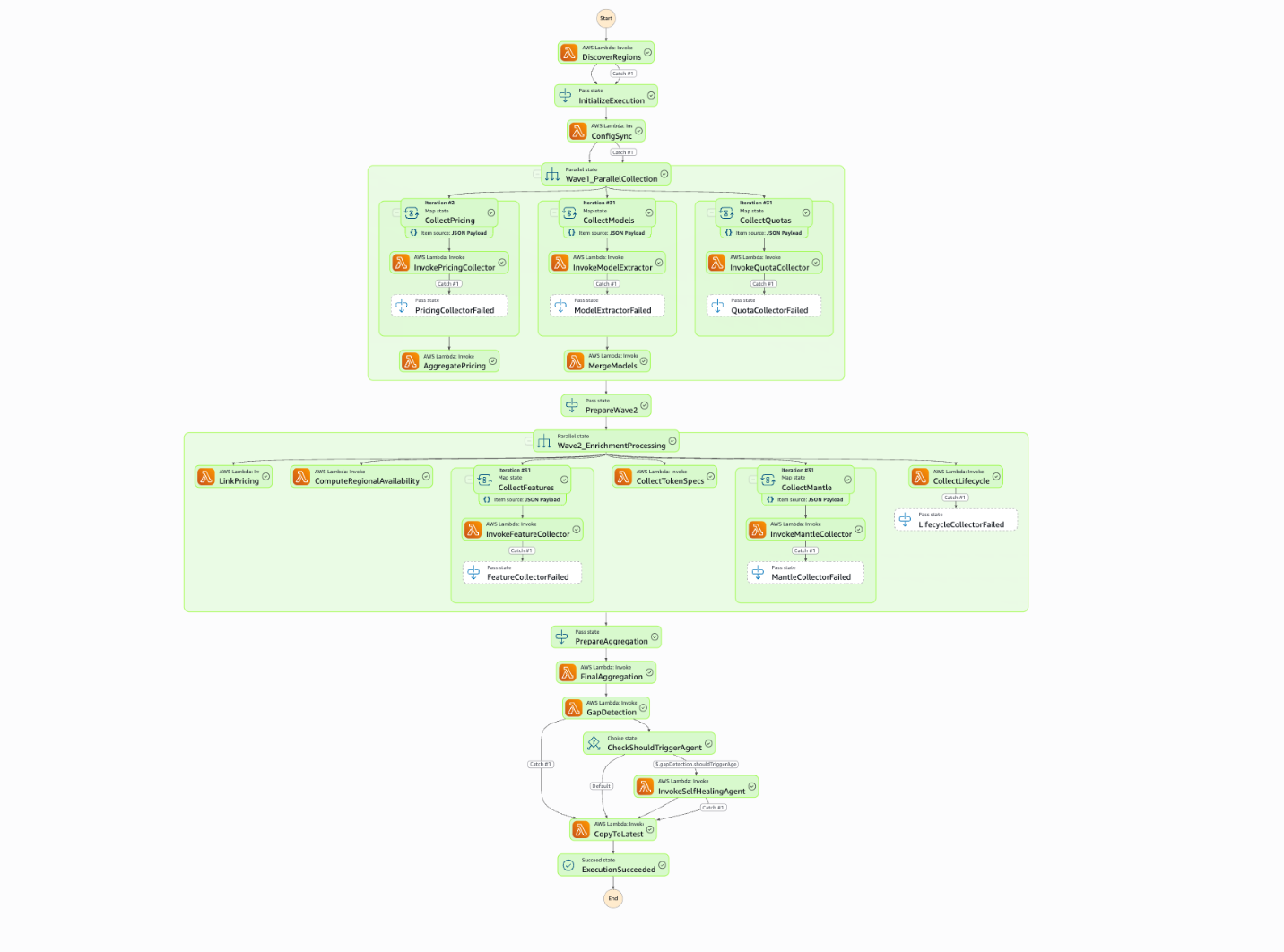
Model Profiler データパイプラインのアーキテクチャ図
Model Profiler は、AWS Step Functions によってオーケストレーションされる完全自動化されたデータパイプラインを実行します。17 の AWS Lambda 関数が 4 つのフェーズにわたってデータを処理し、Lambda 間での S3 キャッシュを活用することで、実行あたりの API 呼び出し数を約 480 から 29 に削減しています。これは 97% のキャッシュヒット率を意味します。Amazon Bedrock を基盤とした自己修復型エージェントシステムがデータギャップを検知し、自動的に安全な設定修正を適用します。パイプライン全体は 8〜12 分で完了し、UTC 時間午前 6 時に毎日実行されます。
スケジュールは、AWS CloudFormation テンプレート内の Amazon EventBridge ルールを通じて構成可能です。要件に応じて cron 式を調整し、異なる時刻や頻度で実行するように設定できます。
フェーズ 0: 初期化
パイプラインはまず、現在 Amazon Bedrock をサポートしている AWS リージョンを動的に発見することから始まります。リージョンリストはハードコードされていないため、新しく起動されたリージョンも自動的に検出されます。その後、実行コンテキスト(S3 パス、キャッシュキー)を初期化し、バックエンドと React フロントエンド間の設定を同期して、手動介入なしで両者の整合性を保ちます。
フェーズ 1:並列コレクション
3 つの独立したコレクションブランチが同時に実行されます。価格情報ブランチは、AWS プライスリスト API を 3 つのサービスコードに対してクエリし、プロバイダーとモデルごとに結果を集約します。モデルブランチは Amazon Bedrock が有効化されているリージョンに展開され、各リージョンで ListFoundationModels を呼び出して結果を重複排除し、単一の正規モデルリストに統合します。クォータブランチは、並列実行により 1 分あたりのトークン数および 1 分あたりのリクエスト数のサービス制限を取得します。
フェーズ 2:並列エンリッチメント
生データ収集が完了すると、6 つのエンリッチメントステップが並行して実行されます。これらは API を再呼び出すのではなくキャッシュされたデータを読み取ることで、価格レコードをモデルに紐付け、リージョンごとの利用可否を計算し、リージョン間推論サポートの有無を判定し、コンテキストウィンドウサイズを取得し、Mantle API への接続を試み、各モデルのライフサイクルステータスを決定します。
フェーズ 3:集約とインテリジェンス
最終的なアグリゲーターは、エンリッチメントデータを 2 つの生産環境対応 JSON ファイルに統合します。1 つ目は bedrock_models.json で、仕様、クォータ、利用可否、ライフサイクルステータスを含む完全なモデルカタログです。2 つ目は bedrock_pricing.json で、プロバイダーとモデル別に整理された価格情報です。両方のファイルは Amazon Simple Storage Service (Amazon S3) にコピーされ、Amazon CloudFront を通じて配信されます。
公開前に、ギャップ検出システムが出力をスキャンし、7 つのデータ品質の問題を検出します。ギャップが設定された閾値を超えると、自己修復エージェントがギャップレポートを分析し、安全な修正を自動的に適用します。変更はバージョン管理されバックアップされ、安全性基準を満たさない提案は自動適用されるのではなく、手動レビューのためにログに記録されます。
デプロイメントオプション
本ソリューションには 2 つのデプロイメントオプションがあります。ローカルモードでは、既存の AWS 認証情報を使用して、すべての処理をお客様のマシン上で実行します。データコレクターを実行し、フロントエンドを開始して、Amazon Bedrock および価格 API への読み取りアクセス権で探索を開始できます。クラウドインフラストラクチャは不要です。
AWS デプロイメントでは、自動化された日次データ更新を行う完全サーバーレスアーキテクチャを提供します。AWS Step Functions ワークフローが AWS Lambda 関数をオーケストレーションし、UTC 時間午前 6 時に毎日新鮮なデータを収集して Amazon S3 に保存し、Amazon CloudFront を通じて提供します。ローカルコレクターは、Lambda コードと同じ変換関数をインポートするため、ローカルで実行する場合でも本番環境で実行する場合でも、出力は同一に保たれます。
主要機能
Model Profiler は、モデルの選択を効率化する 4 つのコア機能を備えています。これには、発見と比較から、地域計画および候補リストの追跡までが含まれます。
Model Explorer
Model Explorer は、Amazon Bedrock のモデルを発見するための出発点です。検索可能でフィルタリング可能なインターフェースで 120 以上のファウンデーションモデルを閲覧できます。プロバイダー(Anthropic, Meta, Amazon, Mistral AI, Cohere およびその他 14 社)や、ビジョン機能、コード生成、関数呼び出し、埋め込みなどの機能、入力・出力モダリティによって結果を絞り込むことができます。モダリティは、モデルが処理できるデータの種類を示します。テキスト専用モデルは書かれたコンテンツのみを扱い、マルチモーダルモデルはテキストと画像を入力として受け付け、テキスト、画像、またはその両方を出力として生成する可能性があります。リージョンフィルタでは、対象のリージョンで利用可能なモデルのみが表示され、ステータスフィルタを使用すると、アクティブなモデルに焦点を当てたり、レガシーオプションを含めたりすることができます。
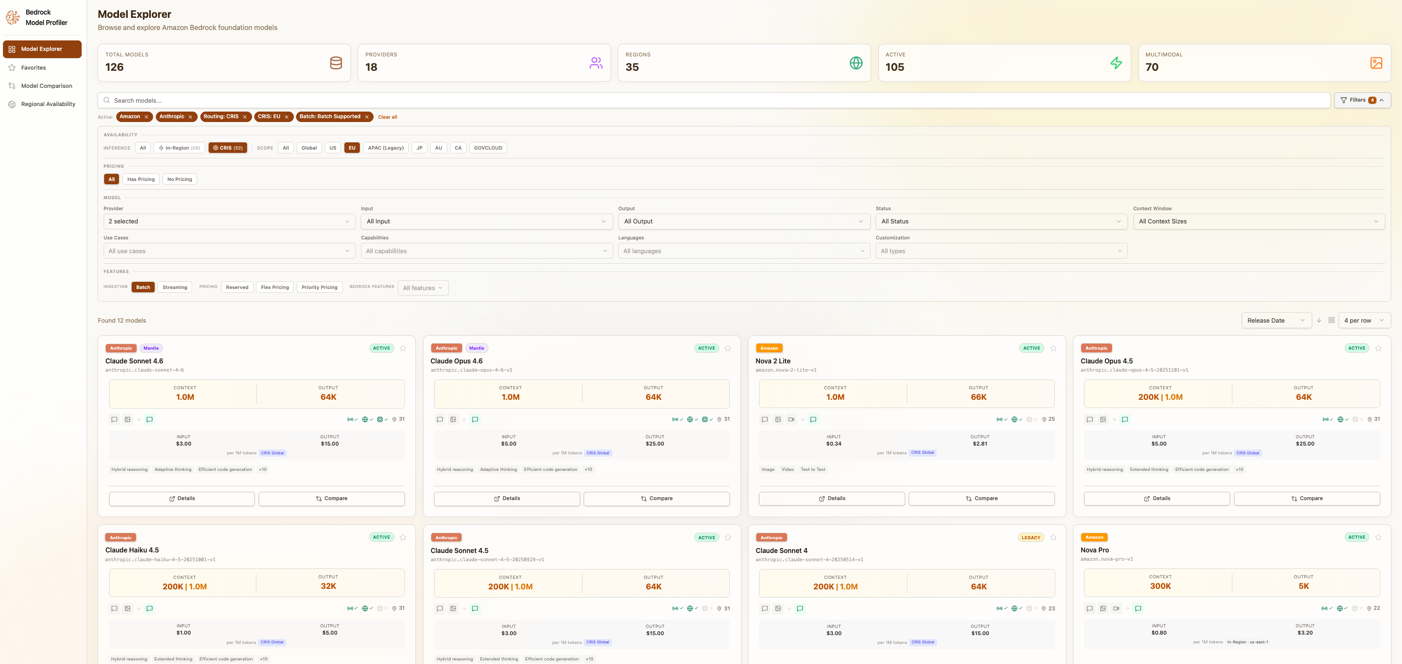
フィルタオプションとモデルカードを表示する Model Explorer のインターフェース
消費オプションのフィルタでは、モデルの利用方法に基づいて結果をさらに絞り込むことができます。Region では、特定の AWS リージョンでオンデマンド推論を提供し、トークン単位の課金を行います。Cross-Region Inference Service (CRIS) は、リクエストをリージョン間でルーティングしてスループットを向上させます。Batch は、非同期で大規模なボリュームを処理し、コストを抑えながら結果を Amazon S3 に配信します。Mantle は、専用容量とカスタム設定を備えた管理された推論エンドポイントを提供します。
エクスプローラーは2つの表示モードをサポートしています。カードビューでは、主要な仕様を一目で確認できる視覚的なブラウジングが可能です。テーブルビューでは、多数のモデル間で密度の高い比較を行うことができます。フルテキスト検索は、モデル名、説明、プロバイダー情報全体を対象に機能します。
すべてのモデルには、利用可能な情報を統合した包括的な詳細表示があります:技術仕様(モダリティ、コンテキストウィンドウ、推論タイプ)、リージョンおよび消費タイプ別の価格内訳、クロスリージョン推論の詳細を含む地域別可用性、各リージョンごとのサービスクォータ(TPM および RPM リミット)、公式ドキュメントおよびプロバイダー情報へのリンクです。
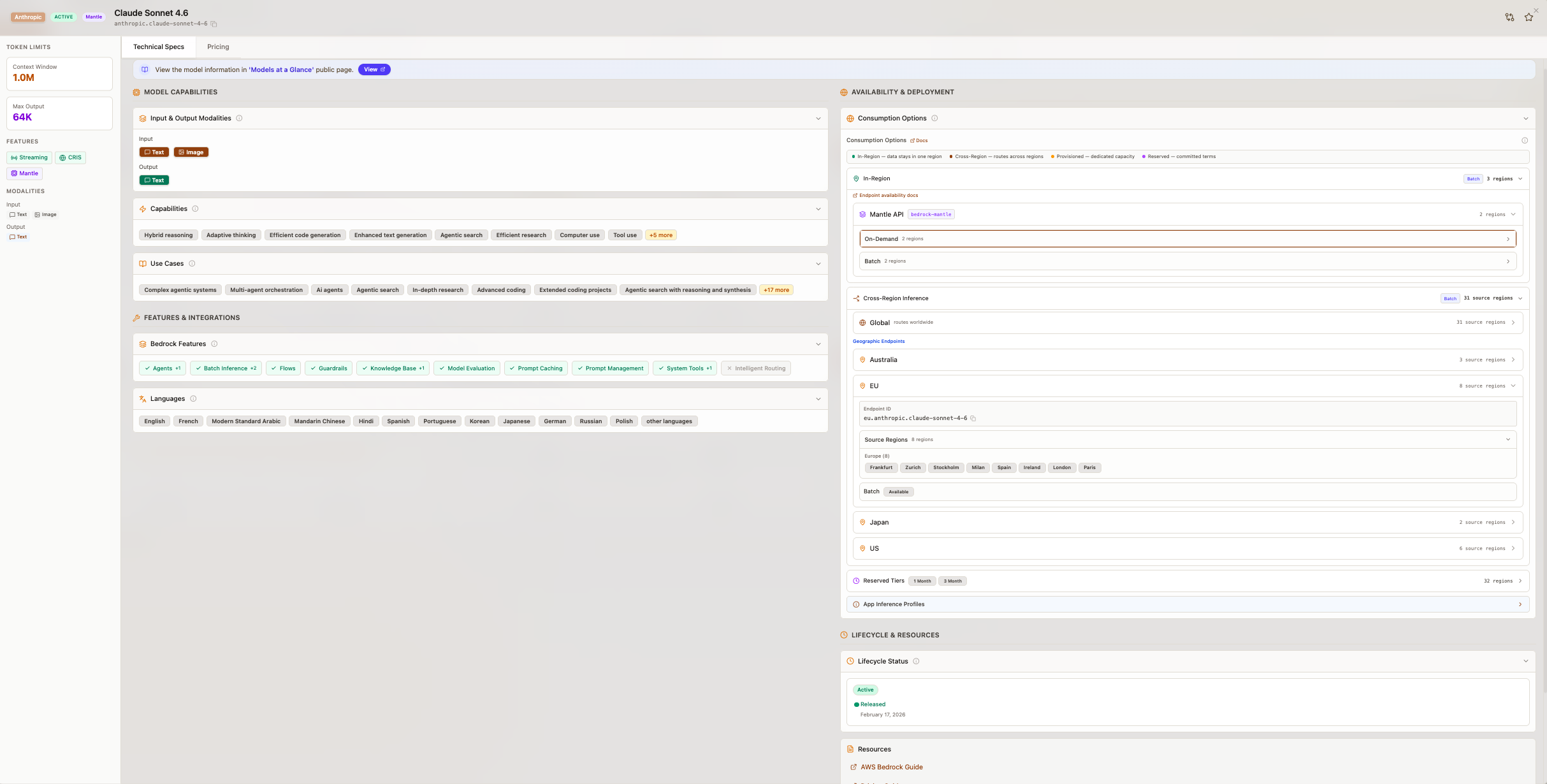
技術仕様情報を表示するモデルカード
モデル比較
候補となるモデルを特定した後、比較ビューでは、重要なすべての次元にわたってそれらを分析することができます。
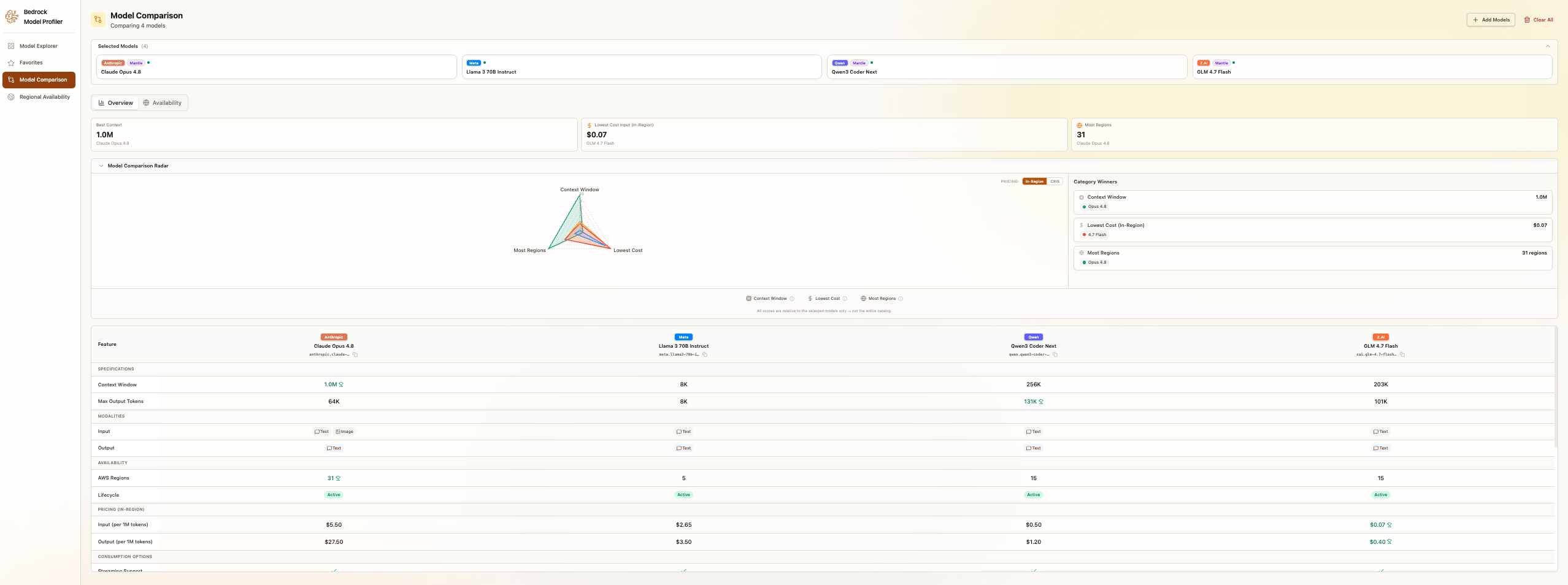
概要と可用性のタブを備えた、4 つのモデルを並べて表示するモデル比較ビュー
最大 25 のモデルを同時に 4 つの次元で比較できます。料金体系には、リージョンごとの入力および出力トークンコストが含まれており、オンデマンド、バッチ、プロビジョニング(予約)の各ティアが用意されています。地域別利用状況では、クロスリージョン推論(Cross-Region Inference: CRIS)サポートを含む各モデルの利用可能地域を示すマップが表示されます。仕様にはコンテキストウィンドウサイズ、最大出力トークン数、および対応機能が含まれます。また、各モデルの機能を横並びで示す機能マトリックスも用意されています。
Amazon Bedrock は、さまざまなワークロードパターンに対応する複数の料金オプションを提供しています。オンデマンドティアには、コミットメント不要のトークン単価制を採用したスタンダード、フレックス、プライオリティの各オプションが含まれます。バッチ料金は、24 時間以内に処理される時間的制約のないジョブ向けに、モデルやモダリティに応じて 30〜50% の割引を提供します。予約(Reserved)ティアは、持続的な高ボリュームワークロード向けに固定 hourly レートで専用容量を提供します。モデル別の詳細な料金については、Amazon Bedrock Pricing ページをご覧ください。
地域別利用状況マトリックス
複数リージョンでの展開を計画するチーム向けに、「地域別利用状況」ビューでは、33 の Amazon Bedrock 対応リージョン全体にわたる包括的なモデル別・リージョン別のマトリックスを提供します。リージョンは地理エリア(NAMER: 北米、EMEA: ヨーロッパ・中東・アフリカ、APAC: アジア太平洋地域、LATAM: ラテンアメリカ)ごとにグループ化されており、各セルにはそのリージョンにおけるモデルの利用形態が表示されます:オンデマンド(In Region)、クロスリージョン推論(CRIS)、または Mantle です。
利用可能なモデルのタイプで行列をフィルタリングすることで、「ヨーロッパで CRIS をサポートしているのはどのモデルか?」や「ap-southeast-2 でオンデマンドで利用可能なのは何か?」といった質問にすばやく回答できます。モデル行を展開すると、推論プロファイル ID、CRIS のソースリージョン、地理的スコープが表示されます。また、行列にはモデルのライフサイクルステータス(アクティブ、レガシー、またはサポート終了)も表示されるため、廃止が近づいているモデルを特定し、事前に移行計画を立てることができます。複数の地域で事業を展開する組織にとって、このビューは、本来であれば数十回の個別 API 呼び出しとライフサイクルドキュメントの手動照合が必要となるものを置き換えるものです。
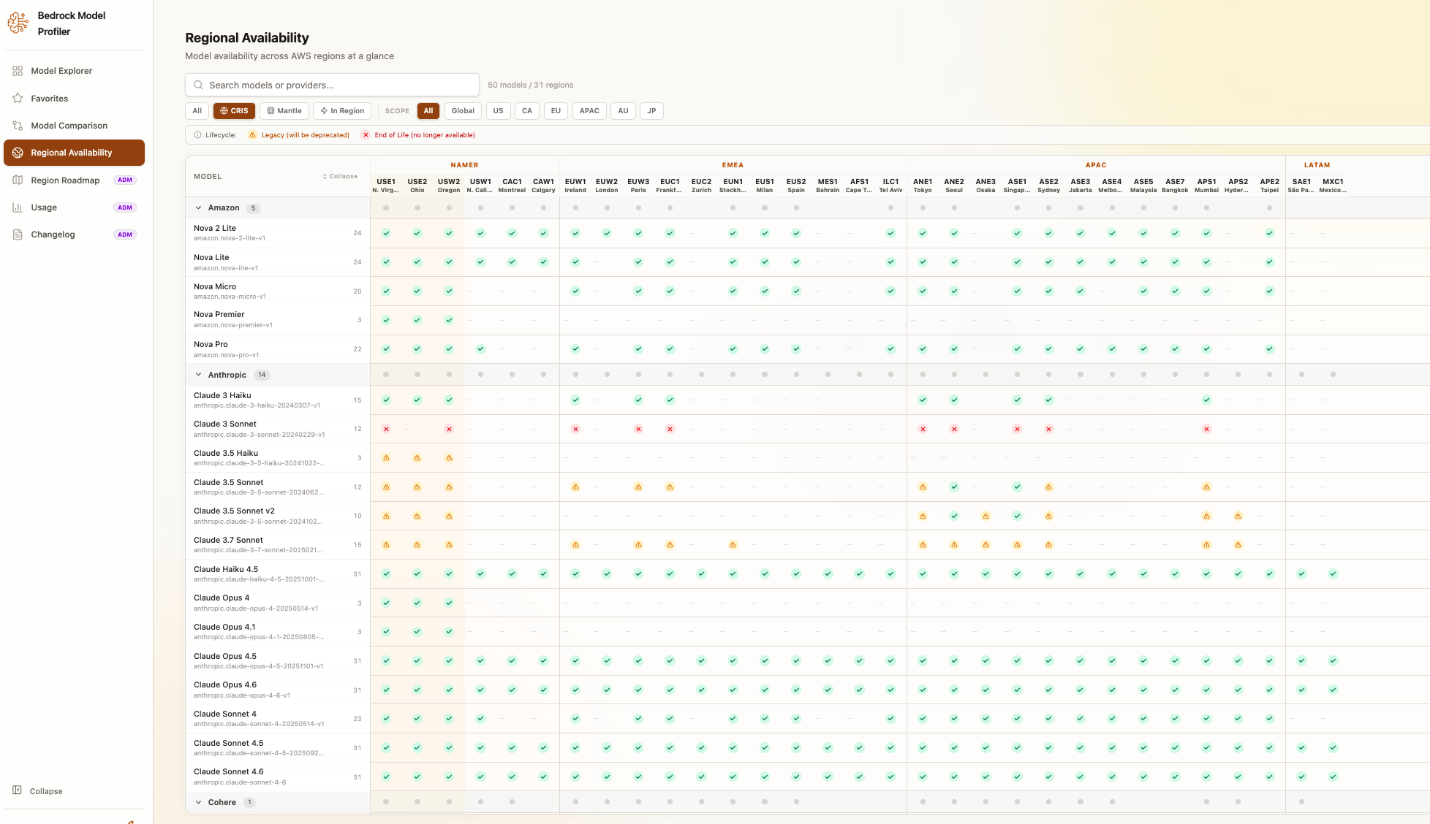
地域別利用可能行列:リージョンごとのモデル利用状況を示し、色分けされたセルでモデルステータスを示す
お気に入り
モデルを検索する際、モデルにスターを付けて「お気に入り」リストに追加できます。これはブラウザセッションを超えて保持される個人的な候補リストです。「お気に入り」タブでは、保存したモデルに限定して、メインエクスプローラーと同じフィルタリング、ソート、詳細表示機能を利用できます。これは評価中に作業対象となる候補モデルのセットを追跡する場合や、チームが最も頻繁に使用するモデルへのクイックアクセスを維持したい場合に役立ちます。
ユースケース
異なるチームが独自の要件に基づいてどのようにモデル選択に取り組むかを探ってみましょう。以下のシナリオには架空の組織が登場します。これらの組織は、実際の AWS の価格およびクォータデータと現実的なワークロードの仮定を組み合わせて使用し、本ソリューションの機能をデモンストレーションしています。
欧州地域におけるコンプライアンスに適合したモデルの選択
Octank Financial Services は、規制遵守のための AI 駆動型ドキュメント分析システムを構築する必要がありました。チームはスキャンされたドキュメントを処理するためにビジョン機能を持つモデルを必要としましたが、データ居住要件を満たすために運用は EU 地域内でのみ行わなければなりませんでした。Amazon Bedrock には数十種類のマルチモーダルモデルが存在し、地域によって価格が異なるため、候補を絞り込むだけでチームは手動調査に 6〜8 時間を要すると見積もっていました。
Model Profiler を使用して、チームは「ビジョン」機能と EU 地域でフィルタリングを行い、即座に条件を満たすモデルを確認しました。Regional Availability matrix(リージョン別可用性マトリクス)を使用して eu-west-1 および eu-central-1 でのオンデマンド利用可能性を確認し、価格を並列比較して最もコスト効果の高いオプションを見つけました。サービスクォータにより、スループットが予測される 1 日あたり 50,000 件のドキュメントレビューに対応できることが確認されました。
その結果、モデル評価にかかっていた時間は推定8時間から25分に短縮されました。また、チームは好みのモデルが eu-west-1 において eu-central-1 よりも18%安価であることを発見し、長い規制文書を複数の呼び出しに分割する必要を解消する、より大きなコンテキストウィンドウを持つ新しいモデルも見つけました。
サードパーティ製AIプロバイダーからの移行
Octank Health社は、サードパーティ製のAIプロバイダーを基盤とした臨床ドキュメンテーションアシスタントを運用しており、AWSとの統合強化とコスト管理のためにAmazon Bedrockへの移行が必要でした。彼らの要件は具体的で、128Kトークン以上のコンテキストウィンドウ、低レイテンシ、および冗長性を確保するために少なくとも3つの米国リージョンでの利用可能性が求められました。現在のプロバイダーの機能を異なるリージョン間で手動でAmazon Bedrockカタログにマッピングするには、複数のドキュメントソースをまたぐ広範な調査が必要でした。
チームは機能フィルターを使用して要件に一致するモデルを検索し、比較ビューを開いて候補間のコンテキストウィンドウ、出力制限、および価格を評価しました。リージョン別可用性ビューにより、米国スコープでのクロスリージョン推論をサポートしているモデルが確認され、アプリケーションの変更なしで自動フェイルオーバーが可能となりました。ライフサイクルステータスのフラグは、レガシー状態に近づいているモデルの選択を避けるのに役立ちました。
評価は 45 分未満で完了しました。チームは、1 トークンあたりのコストを 15% 削減し、コンテキストウィンドウが 200K(以前の 128K の制限から大幅なアップグレード)であるモデルを選択しました。クロスリージョン推論の可用性チェックにより、フェイルオーバー戦略の再構築が必要となるクロスリージョンサポートのないモデルを選定するのを防ぐことができました。
マルチリージョン展開:グローバル展開の計画
Octank Media は、AI 搭載型コンテンツ推薦エンジンを米国から欧州およびアジア太平洋地域へ拡大していました。アーキテクチャにコミットする前に、現在のモデルが対象リージョンで利用可能かを確認し、各リージョンでサポートされている消費オプションを理解し、サービスクォータが予測されるトラフィックを処理できるかを検証する必要がありました。
リージョン別可用性マトリックスにより、チームは「In Region(リージョン内)」「CRIS(クロスリージョン推論サービス)」「Mantle」というカテゴリ別に分類された 33 の全リージョンにわたるモデルの単一のビューを取得しました。APAC および EMEA リージョンでフィルタリングした結果、モデルがどこでどのように利用可能かが明確になりました。ライフサイクルステータス列により、対象リージョンでモデルがアクティブであり、今後の廃止予定がないことが確認されました。リージョン間のクォータ比較により、ap-northeast-1 が展開前にクォータ増額リクエストが必要な潜在的なボトルネックであることが特定されました。
マルチリージョンの適合性分析は 20 分で完了しました。以前はこの作業を AWS コマンドラインインターフェース(AWS CLI)を通じて個別のリージョンにクエリを送り、ドキュメントと照合する必要がありました。本番環境前に東京でのクォータ制約を特定できたことで障害を防ぎ、欧州における CRIS の可用性を確認したことで、トラフィック急増時の信頼できるフォールバック戦略が確立されました。
前提条件
Model Profiler をデプロイする前に、以下の準備が整っていることを確認してください。
ローカルでのデプロイの場合:
- Python 3.11 以降。
- Node.js 18 以降。
- 以下のサービスに対する読み取りアクセス権限を持つ AWS クレデンシャルの構成:
原文を表示
Generative AI adoption is accelerating across industries, and Amazon Bedrock provides a managed service for building production-ready AI applications. With access to more than 100 foundation models from providers such as Anthropic, OpenAI, Meta, Mistral AI, Cohere, and Amazon, teams have the flexibility to choose the right model for each use case.
But choice comes with complexity. Comparing models across capabilities, pricing, regional availability, context window limits and throughput isn’t straightforward. That information is scattered across console pages, documentation, and regional API calls. For organizations evaluating models for new workloads, optimizing cost and performance, or migrating from other AI systems, this fragmented discovery process slows experimentation and delays production decisions.
The Amazon Bedrock Model Profiler addresses this gap. This open source tool aggregates model metadata from multiple AWS APIs and external sources into a single, searchable interface. With advanced filtering, side-by-side comparisons, and detailed model cards, teams can explore the full Amazon Bedrock catalog and make informed, data-driven decisions by easing the manual search effort across various documents and model cards.
In this post, you’ll learn what the Model Profiler provides, the real-world scenarios it supports, and how to deploy it in your own environment in under five minutes.
Solution overview
The Model Profiler is a web application that lets you browse, filter, and compare every foundation model available on Amazon Bedrock in one place. Instead of navigating multiple console pages and documentation sites, you get a single interface with model cards, side-by-side comparisons, regional availability maps, and pricing breakdowns updated daily.
Model Profiler showing the Model Explorer interface
Behind the interface, a fully automated serverless pipeline collects and processes data from seven distinct sources: five AWS APIs and two public URLs. This keeps the catalog accurate without manual intervention.
Source
Type
Auth
Data Collected
Amazon Bedrock ListFoundationModels API
AWS API
IAM (Sigv4)
Model specifications, capabilities, modalities, and regional availability across 33 regions
AWS Price List API
AWS API
IAM (Sigv4)
On-demand, batch, and reserved-tier pricing across three service codes
AWS Service Quotas API
AWS API
IAM (Sigv4)
Tokens-per-minute (TPM) limits, requests-per-minute (RPM) quotas, and throughput constraints
Amazon Bedrock ListInferenceProfiles API
AWS API
IAM (Sigv4)
Cross-region inference configurations and geographic scopes
Amazon Bedrock Mantle API
AWS API
IAM (Sigv4)
Mantle inference availability across regions
LiteLLM Model Database
Public URL
None
Token specifications including context window sizes and max output tokens
AWS Documentation
Public URL
None
Model lifecycle status (active, legacy, end-of-life)
Understanding key quota metrics is essential when evaluating models. Tokens-per-minute (TPM) measures how many tokens you can process per minute. Think of it as your throughput ceiling, where 1,000 tokens equals roughly 750 words of text. Requests-per-minute (RPM) limits how many API calls you can make regardless of size. Both quotas vary by model and Region.
Architecture diagram of the Model Profiler data pipeline
The Model Profiler runs a fully automated data pipeline orchestrated by AWS Step Functions. Seventeen AWS Lambda functions process data across four phases, using inter-Lambda S3 caching to reduce API calls from approximately 480 to 29 per execution. That represents a 97% cache hit rate. A self-healing agentic system powered by Amazon Bedrock detects data gaps and automatically applies safe configuration fixes. The entire pipeline completes in 8–12 minutes and runs daily at 6 AM UTC.
The schedule is configurable through the Amazon EventBridge rule in the AWS CloudFormation template. You can adjust the cron expression to run at a different time or frequency based on your requirements.
Phase 0: Initialization
The pipeline begins by dynamically discovering which AWS regions currently support Amazon Bedrock. No Region list is hardcoded, so newly launched regions are picked up automatically. It then initializes the execution context (S3 paths, cache keys) and synchronizes configuration between the backend and the React front end, making sure both sides stay consistent without manual intervention.
Phase 1: Parallel collection
Three independent collection branches run simultaneously. The Pricing branch queries the AWS Price List API across three service codes and aggregates results by provider and model. The Models branch fans out to Amazon Bedrock-enabled regions, calling ListFoundationModels in each and deduplicating results into a single canonical model list. The Quotas branch gathers tokens-per-minute and requests-per-minute service limits in parallel.
Phase 2: Parallel enrichment
Once raw data is collected, six enrichment steps run concurrently, reading from the cached data rather than re-calling APIs, to link pricing records to models, compute regional availability, determine cross-region inference support, fetch context window sizes, probe the Mantle API, and determine each model’s lifecycle status.
Phase 3: Aggregation and intelligence
The final aggregator merges the enrichment data into two production-ready JSON files: bedrock_models.json (the full model catalog with specifications, quotas, availability, and lifecycle status) and bedrock_pricing.json (pricing organized by provider and model). Both files are copied to Amazon Simple Storage Service (Amazon S3) and served through Amazon CloudFront.
Before publication, a gap detection system scans the output for seven types of data quality issues. When gaps exceed configured thresholds, a self-healing agent analyzes the gap report and automatically applies safe fixes. Changes are versioned and backed up, and suggestions that do not meet safety criteria are logged for manual review rather than auto-applied.
Deployment options
The solution offers two deployment options. Local mode runs entirely on your machine using your existing AWS credentials. Run the data collector, start the frontend, and begin exploring with read access to Amazon Bedrock and Pricing APIs. No cloud infrastructure is needed.
AWS deployment provides a fully serverless architecture with automated daily data refresh. An AWS Step Functions workflow orchestrates AWS Lambda functions that collect fresh data every day at 6 AM UTC, storing results in Amazon S3 and serving them through Amazon CloudFront. The local collector imports the same transformation functions as the Lambda code, maintaining identical output whether you run locally or in production.
Key features
The Model Profiler provides four core capabilities that streamline model selection: from discovery and comparison to regional planning and tracking your shortlist.
Model Explorer
The Model Explorer is your starting point for discovering Amazon Bedrock models. Browse 120+ foundation models in a searchable, filterable interface. You can narrow results by provider (Anthropic, Meta, Amazon, Mistral AI, Cohere, and 14 others), by capabilities such as vision, code generation, function calling, or embeddings, and by input and output modalities. Modalities describe the types of data a model can process: a text-only model handles written content, while a multimodal model might accept text and images as input and generate text, images, or both as output. Region filters show only models available in your target regions, and a status filter lets you focus on active models or include legacy options.
Model Explorer interface showing filter options and model cards
A consumption options filter lets you refine results by how you want to use a model. In Region provides on-demand inference in a specific AWS Region with per-token pricing. Cross-Region Inference Service (CRIS) routes requests across regions for higher throughput. Batch processes large volumes asynchronously at lower cost, with results delivered to Amazon S3. Mantle provides managed inference endpoints with dedicated capacity and custom configurations.
The explorer supports two view modes. Card view provides visual browsing with key specifications at a glance. Table view enables dense comparison across many models. Full-text search works across model names, descriptions, and provider information.
Every model has a comprehensive detail view consolidating the available information: technical specifications (modalities, context windows, inference types), pricing breakdowns by Region and consumption type, regional availability with cross-region inference details, service quotas per Region (TPM and RPM limits), and links to official documentation and provider information.
Model card displaying technical specifications information
Model Comparison
Once you have identified candidate models, the comparison view lets you analyze them across every dimension that matters.
Model Comparison view showing four models side-by-side with tabs for Overview and Availability
Compare up to 25 models simultaneously across four dimensions. Pricing covers input and output token costs across regions, with on-demand, batch, and provisioned tiers. Regional availability shows maps of where each model is available, including cross-region inference support. Specifications include context window sizes, maximum output tokens, and supported features. A capabilities matrix shows what each model supports side by side.
Amazon Bedrock offers multiple pricing options to match different workload patterns. On-demand tiers include standard, flex, and priority options with per-token pricing and no commitment. Batch pricing provides discounts ranging from 30-50% depending on the model and modality for non-time-sensitive jobs processed within 24 hours. Reserved tier provides dedicated capacity at a fixed hourly rate for sustained high-volume workloads. For detailed pricing by model, see the Amazon Bedrock Pricing page.
Regional Availability Matrix
For teams planning multi-region deployments, the Regional Availability view provides a comprehensive model-by-region matrix across all 33 Amazon Bedrock-enabled regions. Regions are grouped by geographic area (NAMER, EMEA, APAC, LATAM), and each cell shows how a model is available in that region: on-demand (In Region), Cross-Region Inference (CRIS), or Mantle.
You can filter the matrix by availability type to quickly answer questions like “which models support CRIS in Europe?” or “what is available on-demand in ap-southeast-2?” Expanding a model row reveals inference profile IDs, CRIS source regions, and geographic scopes. The matrix also surfaces model lifecycle status (active, legacy, or end-of-life), so you can identify models approaching deprecation and plan migrations in advance. For organizations operating across multiple geographies, this view replaces what would otherwise require dozens of individual API calls and manual cross-referencing of lifecycle documentation.
Regional Availability matrix showing model availability per region, with color-coded cells indicating model status
Favorites
As you explore models, you can star models to add them to your Favorites list, a personal shortlist that persists across browser sessions. The Favorites tab provides the same filtering, sorting, and detail views as the main explorer, scoped to just your saved models. This is useful for tracking a working set of candidate models during an evaluation, or for keeping quick access to the models your team uses most.
Use cases
Let’s explore how different teams approach model selection based on their unique requirements. The following scenarios feature fictional organizations. They use real AWS pricing and quota data combined with realistic workload assumptions to demonstrate the solution’s capabilities.
Selecting compliance-aligned models across European regions
Octank Financial Services needed to build an AI-powered document analysis system for regulatory compliance. The team required models with vision capabilities to process scanned documents, but operations had to remain exclusively within EU regions to meet data residency requirements. With dozens of multimodal models on Amazon Bedrock and pricing that varies across regions, the team estimated 6 to 8 hours of manual research just to shortlist candidates.
Using the Model Profiler, the team filtered by “vision” capability and EU regions to immediately see qualifying models. They used the Regional Availability matrix to confirm on-demand availability in eu-west-1 and eu-central-1, then compared pricing side by side to find the most cost-effective option. Service quotas confirmed that throughput would meet their projected 50,000 daily document reviews.
The result: model evaluation dropped from an estimated 8 hours to 25 minutes. The team also discovered that their preferred model was 18% cheaper in eu-west-1 than eu-central-1, and found a newer model with a larger context window that alleviated the need to split long regulatory documents across multiple calls.
Migrating from a third-party AI provider
Octank Health operated a clinical documentation assistant built on a third-party AI provider and needed to migrate to Amazon Bedrock for tighter AWS integration and cost control. Their requirements were specific: a context window of 128K tokens or more, low latency, and availability in at least three US regions for redundancy. Mapping their current provider’s capabilities to the Amazon Bedrock catalog manually across the different regions required extensive research across multiple documentation sources.
The team used capability filters to find models matching their requirements, then opened the comparison view to evaluate context windows, output limits, and pricing across candidates. The Regional Availability view confirmed which models supported cross-region inference with US scope, giving them automatic failover without application changes. Lifecycle status flags helped them avoid a model that was approaching legacy status.
The evaluation completed in under 45 minutes. The team selected a model with a 200K context window (a significant upgrade from their previous 128K limit) at 15% lower cost per token. The cross-region inference availability check helped prevent them from choosing a model without cross-region support, which would have required rearchitecting their failover strategy.
Multi-region deployment: Planning global expansion
Octank Media was expanding their AI-powered content recommendation engine from the US to Europe and Asia-Pacific. Before committing to an architecture, they needed to confirm their current model’s availability in target regions, understand which consumption options were supported in each, and verify that service quotas could handle projected traffic.
The Regional Availability matrix gave the team a single view of their model across all 33 regions, broken down by In Region, CRIS, and Mantle. Filtering by APAC and EMEA regions revealed exactly where their model was available and how. The lifecycle status column confirmed the model was active in the target regions with no upcoming deprecation. Quota comparison across regions identified ap-northeast-1 as a potential bottleneck requiring a quota increase request before launch.
The multi-region feasibility analysis completed in 20 minutes. Previously, the same work required querying individual regions through the AWS Command Line Interface (AWS CLI) and cross-referencing documentation. Identifying the quota constraint in Tokyo before production helped prevent an outage and confirming CRIS availability in Europe established a reliable fallback strategy for traffic spikes.
Prerequisites
Before deploying the Model Profiler, confirm you have the following in place.
For local deployment:
- Python 3.11 or later.
- Node.js 18 or later.
- AWS credentials configured with read access to the following services:
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み