あなたのハネス、あなたのメモリ
LangChain Blogは、エージェント構築の主流である「エージェントハーネス」がメモリ管理と密接に関連しており、クローズドなハーネス使用はデータ主権の喪失とベンダーロックインを招くため、オープンなメモリ管理が重要であると主張している。
キーポイント
エージェントハーネスの台頭と定着
単純なRAGチェーンからLangGraphを用いた複雑フローへ、そして現在はエージェントハーネス(Claude Code, Deep Agentsなど)がエージェント構築の標準的な手法として確立されつつある。
メモリとハーネスの不可分性
エージェントの成否は「記憶(メモリ)」にかかっており、ハーネスはメモリ管理と密接に結びついている。プロプライエタリなAPI背後のクローズドハーネスを使用することは、メモリ管理権を第三者に委譲することを意味する。
ベンダーロックインとオープンソースの必要性
メモリを所有しないことは、強力なベンダーロックインを生む。良いエージェント体験のためには、メモリおよびそれに関連するハーネスはオープンであるべきであり、ユーザーが自身のデータを支配できる環境が必要だと結論付けている。
影響分析・編集コメントを表示
影響分析
この記事は、AIエージェント開発における「データの所有権」という倫理的・技術的課題を提起しており、企業や開発者がプロプライエタリなエージェントツールを選ぶ際のリスク認識を高める。特に、メモリ管理がベンダーロックインの主要因となることを指摘した点は、今後のエージェントエコシステムにおけるオープンソース標準化の流れを後押しする重要な示唆を含んでいる。
編集コメント
LangChain Blog特有の戦略的メッセージが見られるが、プロプライエタリなエージェント環境におけるデータ主権の喪失リスクを指摘した点は、実務者にとって重要な警告である。オープンなメモリ標準の必要性は今後の業界トレンドを予測する上で参考になる。
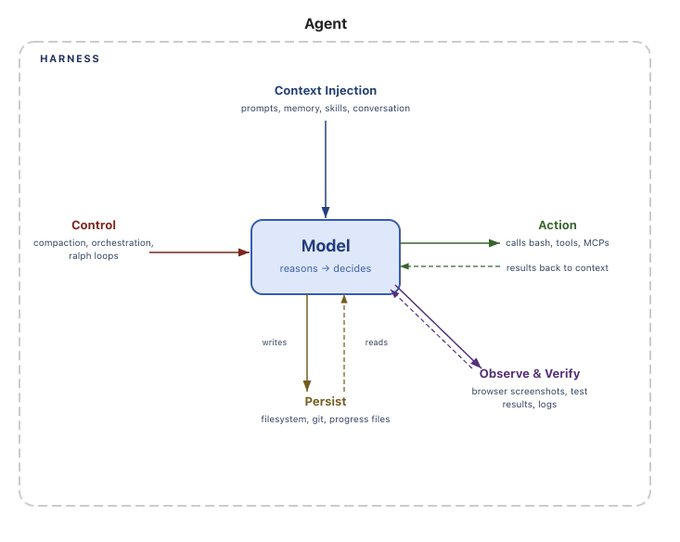
エージェント・ハーネスはエージェント構築の主流な方法となりつつあり、その傾向に終わりは見えない。これらのハーネスはエージェントのメモリと密接に関連している。クローズドなハーネス、特に proprietary API(独自API)の背後にあるものを使用する場合、あなたはエージェントのメモリに関する制御を第三者に委ねることを選んでいることになる。メモリは、質が高く、ユーザーを引き付けるエージェント体験を構築する上で極めて重要である。これは強力なロックイン(乗り換えコスト)を生み出す。メモリ、ひいてはハーネス自体がオープンであるべきであり、そうすることであなたが自身のメモリを所有できるのだ。
エージェント・ハーネスはエージェント構築の方法であり、その傾向に終わりは見えない
エージェントシステムの構築における「最善」の方法は、過去3年で劇的に変化した。ChatGPTが登場した当時、できるのは単純なRAGチェーン(Retrieval-Augmented Generation:検索拡張生成)のみだった(LangChain)。その後、モデルが少し向上し、より複雑なフローを作成できるようになった(LangGraph)。さらにモデルが大幅に改善され、新しいタイプのスケルトンであるエージェント・ハーネスが登場した。
エージェント・ハネスの例としては、Claude Code、Deep Agents、Pi(OpenClawを駆動)、OpenCode、Codex、Letta Codeなどが挙げられ、他にも多数存在します。
エージェント・ハネスは消滅しません。
モデルがインフラ(スキャフォールディング)の多くを吸収していくという見方があることもありますが、それは誤りです。実際に起こっていること(そして今後も続くこと)は、2023年に必要とされていたインフラの多くが不要になったということです。しかし、それは他の種類のインフラに置き換えられたに過ぎません。定義上、エージェントとはツールやその他のデータソースと相互作用する大規模言語モデル(LLM: Large Language Model)のことです。そのような相互作用を可能にするためのシステムが、LLM の周囲に常に存在し続けることになります。その証拠が必要でしょうか?Claude Code のソースコードが流出した際、51万2000行のコードが見つかりました。このコードこそがハネスです。世界で最も優れたモデルを開発しているメーカーでさえ、ハネスに多大な投資を行っています。
Web検索などの機能がOpenAIやAnthropicのAPIに組み込まれている場合、それらは「モデルの一部」ではありません。むしろ、それらのAPIの背後にある軽量なハース(harness)の一部であり、ツール呼び出しを通じてモデルとそれらのWeb検索APIを調整する役割を果たします。
ハースはメモリに紐づく
Sarah Wooders氏は、「メモリはプラグインではない(ハースそのものだ)」という理由について、素晴らしいブログを投稿しており、私もこれに完全に同意します。
時には、メモリが特定のハースとは無関係なスタンドアロンのサービスであるという見方がありますが、現時点ではそれは正しくありません。
ハースの大きな責任の一つはコンテキスト(文脈)とのやり取りです。Sarah氏の言葉によれば、
エージェントハースにメモリをプラグインするよう依頼することは、自動車に運転機能をプラグインするよう依頼することと同じです。コンテキストの管理、ひいてはメモリ管理は、エージェントハースの中核的な機能と責任です。
メモリは単なるコンテキストの一形態です。短期記憶(会話内のメッセージ、大規模なツール呼び出しの結果)はハースによって処理されます。長期記憶(セッションを跨ぐメモリ)の更新と読み取りもハースによって行われます。Sarah氏は、ハースがメモリと結びついている他の多くの方法をリストアップしています:
AGENTS.mdやCLAUDE.mdファイルは、どのようにコンテキストに読み込まれるのでしょうか?エージェントにはスキルメタデータがどのように表示されますか(システムプロンプト内?システムメッセージ内?)。
エージェントは自身のシステム指示を修正できるのでしょうか?コンパクション(圧縮)の過程で何が保持され、何が失われるのでしょうか?インタラクションは保存され、クエリ可能になるのでしょうか?メモリメタデータはエージェントにどのように提示されるのでしょうか?現在の作業ディレクトリはどのように表現されますか?ファイルシステム情報はどの程度公開されるのでしょうか?**
現在、メモリという概念は初期段階にあります。メモリに関する取り組みはまだ非常に早い段階です。率直に言って、長期記憶はMVP(Minimum Viable Product:最小実行可能製品)の一部とならないことが多いことがわかります。まずエージェントを一般的に動作させる必要があり、その後にパーソナライズ化について考えることができます。これは、私たちが業界としてメモリについてまだ模索中であることを意味します。つまり、メモリに関するよく知られた共通の抽象化は存在しません。もしメモリがより一般的になり、ベストプラクティスが発見されれば、専用のメモリシステムが意味をなすようになる可能性もあります。しかし、現時点ではそうではありません。サラが述べたように、「究極的には、ハネスがコンテキストと状態をどのように管理するかが、エージェントメモリの基盤となります。」
ハネスを所有しなければ、メモリも所有できない
ハネスはメモリと密接に関連しています。

クローズドなハーネスを使用する場合、特にそれがAPIの背後にある場合、あなたは自分のメモリを所有していません。
これはいくつかの形で現れます。
やや悪いケース:ステートフルなAPI(OpenAIのResponses APIやAnthropicのサーバー側コンパクションなど)を使用する場合、あなたはそれらのサーバーに状態を保存しています。モデルを切り替えて以前のスレッドを再開したい場合、それはもはや不可能になります。

悪いケース:クローズドなハーネス(内部にClaude Codeを使用するClaude Agent SDKなど、オープンソースではないもの)を使用する場合、このハーネスはあなたにとって不明な方法でメモリと相互作用します。おそらくクライアントサイドにいくつかのアーティファクトを作成しますが、それらの形状はどうなっており、ハーネスはそれらをどのように使用するべきでしょうか?それは不明であり、したがってあるハーネスから別のハーネスへの移譲は不可能です。

しかし、最悪なのは別のケースです。長期メモリを含むハーネス全体がAPIの背後にある場合です。
この状況では、長期メモリを含むメモリに対する所有権や可視性がゼロです。ハーネスが何であるか(つまり、メモリをどのように使用するか)を理解していません。さらに悪いことに、メモリ自体を所有していません!APIを通じて一部の情報が公開される場合もあれば、全く公開されない場合もあります。それに対してあなたは制御を持っていません。

人々が「モデルがハース(harness)のより大きな部分を吸収していく」と言うとき、彼らが本当に意味しているのはこれです。つまり、これらのメモリ関連の部分が、モデルプロバイダーが提供するAPIの背後に配置されるということです。
これは非常に警戒すべきことです。つまり、メモリが単一のプラットフォーム、単一のモデルにロックインされることを意味します。
モデルプロバイダーにはこれを行うための強いインセンティブがあります。そして、彼らはすでにそれを実行し始めています。AnthropicはClaude Managed Agentsをリリースしました。これは、事実上すべてのものをAPIの背後に配置し、自社のプラットフォームにロックインするものです。
ハース全体がAPIの背後にあるわけではありませんが、モデルプロバイダーはより多くの機能をAPIの背後に移動させるインセンティブを持っており、すでにそれを行っています。例えば:Codexはオープンソースですが、OpenAIエコシステム外では使用できない暗号化されたコンパクションサマリー(圧縮要約)を生成します。
なぜ彼らはこれを行っているのでしょうか?メモリは重要であり、モデル単体からは得られないようなロックイン(乗り換えの困難さ)を生み出すからです。
メモリは重要であり、ロックインを生み出す
メモリはまだ初期段階ですが、その重要性が誰にでも明らかです。それは、ユーザーとのインタラクションを通じてエージェントを改善可能にし、データフラインホイール(data flywheel)を構築できる基盤となります。また、各ユーザーにパーソナライズされたエージェントを提供し、彼らの欲求や使用パターンに適応するアジェンティック(agentic)な体験を構築することを可能にします。
メモリがない場合、同じツールにアクセスできる誰にでもエージェントが簡単に複製されてしまいます。
メモリがあることで、ユーザーのインタラクションやPreferences(好み・設定)からなる独自データセットを構築できます。この独自データセットにより、差別化された、かつ高度にインテリジェントな体験を提供することが可能になります。
これまで、モデルプロバイダーの切り替えは比較的容易でした。それらは類似しているか、同一のAPIを持っています。確かにプロンプトを少し変更する必要がありますが、それほど難しいことではありません。
しかし、これはすべてがステートレス(stateless)であるためです。
何らかのステートに関連する要素が存在すると、切り替えははるかに困難になります。なぜなら、このメモリが重要だからです。そして、切り替えると、そのメモリへのアクセスを失ってしまうからです。
話を一つさせてください。私には社内用のメールアシスタントがあります。これは、エンタープライズ対応のOpenClawsを構築するためのノーコードプラットフォームであるFleetのテンプレートの上に構築されています。このプラットフォームにはメモリ機能が内蔵されており、過去数ヶ月にわたってメールアシスタントとやり取りする中で、そのメモリが蓄積されていきました。数週間前、私のエージェントが誤って削除されてしまいました。本当に腹が立ちました!同じテンプレートからエージェントを再生成しようと試みましたが、その体験は大幅に劣るものでした。私の好み、トーン、すべての設定を再度教える必要がありました。
メールエージェントが削除されたプラスの側面として、メモリがいかに強力かつユーザーを縛り付ける(スティッキーな)性質を持っているかを痛感させられました。
オープンメモリ、オープンハネス
メモリは開放されなければならず、エージェント体験を開発する主体が所有すべきです。これにより、実際に制御できる独自のデータセットを構築することができます。
メモリ(そしてそれゆえハネス)はモデルプロバイダーとは分離されているべきです。ユースケースに最適なモデルを試すための選択肢を求めているはずです。モデルプロバイダーは、メモリを通じてロックイン(乗り換えコスト)を生み出すインセンティブを持っています。
これが、私たちがDeep Agentsを構築している理由です。Deep Agents:
- オープンソースである
- モデル非依存(model agnostic)である
- agents.md や skills などのオープンスタンダードを使用する
- メモリ(記憶)の保存用に Mongo、Postgres、Redis などのプラグインを持つ
- LangSmith Deployment を通じてデプロイ可能。セルフホスティングも可能で、あらゆるクラウドに展開できる
- 独自のデータベースをメモリストアとして提供可能
- いかなる標準的なウェブホスティングフレームワークの背後でも動作する
あなたのメモリを所有するためには、オープンハーネス(Open Harness)を使用する必要があります。
今日から Deep Agents をお試しください。
*レビューとご意見をくださった方々に感謝します:*
- 多くの優れた Deep Agents およびメモリ関連の作業を行っている Sydney Runkle 氏
- エージェントハーネスに関する主要な提言者である Viv Trivedy 氏
- ファイナンスエージェントのコンテキストエンジニアリング(context engineering)に関する優れた著作を持つ Nuno Campos 氏
- 状態保持エージェント(stateful agents)の最前線を常に走り続ける Letta の CTO である Sarah Wooders 氏
原文を表示
Agent harnesses are becoming the dominant way to build agents, and they are not going anywhere. These harnesses are intimately tied to agent memory. If you used a closed harness - especially if it’s behind a proprietary API - you are choosing to yield control of your agent’s memory to a third party. Memory is incredibly important to creating good and sticky agentic experiences. This creates incredible lock in. Memory - and therefor harnesses - should be open, so that you own your own memory
Agent Harnesses are how you build agents, and they’re not going anywhere
The “best” way to build agentic systems has changed dramatically over the past three years. When ChatGPT came out, all you could do were simple RAG chains (LangChain). Then the models got a little better, and could create more complex flows (LangGraph). Then they got a lot better, and that gave rise to a new type of scaffolding - agent harnesses.
Examples of agent harnesses include Claude Code, Deep Agents, Pi (powers OpenClaw), OpenCode, Codex, Letta Code, and many more.
Agent harnesses are not going away.
There is sometimes sentiment that models will absorb more and more of the scaffolding. This is not true. What has happened (and will continue to happen) is that a lot of the scaffolding needed in 2023 is no longer needed. But this has been replaced by other types of scaffolding. An agent, by definition, is an LLM interacting with tools and other sources of data. There will always be a system around the LLM to facilitate that type of interaction. Need evidence? When Claude Code’s source code was leaked, there was 512k lines of code. That code is the harness. Even the makers of the best model in the world are investing heavily in harnesses.
When things like web search are built into OpenAI and Anthropic’s APIs - they are not “part of the model”. Rather, they are part of a lightweight harness that sits behind their APIs and orchestrates the model with those web search APIs (via nothing other than tool calling).
Harnesses are tied to memory
Sarah Wooders wrote a great blog on why “memory isn’t a plugin (it’s the harness)”, and I couldn’t agree with it more.
There is sometimes sentiment that memory is a standalone service, separate from any particular harness. At this point in time, that is not true.
A large responsibility of the harness is to interact with context. As Sarah puts it:
Asking to plug memory into an agent harness is like asking to plug driving into a car. Managing context, and therefore memory, is a core capability and responsibility of the agent harness.
Memory is just a form of context. Short term memory (messages in the conversation, large tool call results) are handled by the harness. Long term memory (cross session memory) needs to be updated and read by the harness. Sarah lists out many other ways the harness is tied to memory:
How is the AGENTS.md or CLAUDE.md file loaded into context?How is skill metadata shown to the agents? (in the system prompt? in system messages?)Can the agent modify its own system instructions?What survives compaction, and what's lost?Are interactions stored and made queryable?How is memory metadata presented to the agent?How is the current working directory represented? How much filesystem information is exposed?
Right now, memory as a concept is in it’s infancy. It’s so early for memory. Transparently, we see that long term memory is often not part of the MVP. First you need to get an agent working generally, then you can worry about personalization. This means that we (as an industry) are still figuring out memory. This means there are not well known or common abstractions for memory. If memory does become more known, and as we discover best practices, it is possible that separate memory systems start to make sense. But not at this point in time. Right now, as Sarah said, “ultimately, how the harness manages context and state in general is the foundation for agent memory.”
if you don't own your harness, you don't own your memory
The harness is intimately tied to memory.
If you use a closed harness, especially if its behind an API, you don’t own your memory.
This manifests itself in several ways.
Mildly bad: If you use a stateful API (like OpenAI’s Responses API, or Anthropic’s server side compaction), you are storing state on their server. If you want to swap models and resume previous threads - that is no longer doable.
Bad: If you use a closed harness (like Claude Agent SDK, which uses Claude Code under the hood, which is not open source), this harness interacts with memory in a way that is unknown to you. Maybe it creates some artifacts client side - but what is the shape of those, and how should a harness use those? That is unknown, and therefor non-transferrable from one harness to another.
But worst is something else - when the whole harness, including long term memory is behind an API.
In this situation, you have zero ownership or visibility into memory, including long term memory. You do not know the harness (which means you don’t know how to use the memory). But even worse - you don’t even own the memory! Maybe some parts are exposed via API, maybe no parts are - you have no control over that.
When people say that the “models will absorb more and more of the harness” - this is what they really mean. They mean that these memory related parts will go behind the APIs that model providers offer.
This is incredibly alarming - it means that memory will become locked into a single platform, a single model.
Model providers are incredibly incentivized to do this. And they are starting to. Anthropic launched Claude Managed Agents. This puts literally everything behind an API, locked into their platform.
Even if the whole harness isn’t behind the API, model providers are incentivized to move more and more behind APIs - and are already doing so. For example: even though Codex is an open source, it generates an encrypted compaction summary (that is not usable outside of the OpenAI ecosystem).
Why are they doing this? Because memory is important, and it creates lock in that they don’t get from just the model.
Memory is important, and it creates lock in
Although memory is early, it is clear to everyone that it is important. It is what allows agents to get better as users interact with them, and allows you build up a data flywheel. It is what allows your agent to be personalized to each of your users, and build up an agentic experience that molds to their desires and usage patterns.
Without memory, your agents are easily replicable by anyone who has access to the same tools.
With memory, you build up a proprietary dataset - a dataset of user interactions and preferences. This proprietary dataset allows you to provide a differentiated and increasingly intelligent experience.
It’s been relatively easy to switch model providers to date. They have similar, if not identical, APIs. Sure, you have to change prompts a little bit, but that’s not that hard.
But this is all because they are stateless.
As soon as there is any state associated, its much harder to switch. Because this memory matters. And if you switch, you lose access to it.
Let me tell a story. I have an email assistant internally. It’s built on top of a template in Fleet, our no-code platform for building Enterprise ready OpenClaws. This platform has memory built in, so as I interacted with my email assistant over the past few months it built up memory. A few weeks ago, my agent got deleted by accident. I was pissed! I tried to create an agent from the same template - but the experience was so much worse. I had to reteach it all my preferences, my tone, everything.
The plus side of my email agent deleted - it made me realize how powerful and sticky memory could be.
Open Memory, Open Harnesses
Memory needs to be opened, owned by whomever is developing the agentic experience. It allows you to build up a proprietary dataset that you actually control.
Memory (and therefor harnesses) should be separate from model providers. You should want optionality to try out whatever models are best for your use case. Model providers are incentivized to create lock in via memory.
This is why we are building Deep Agents. Deep Agents:
- Is open source
- Is model agnostic
- Uses open standards like agents.md and skills
- Has plugins to Mongo, Postgres, Redis and others for storing memories
- Is deployablevia LangSmith DeploymentSelf hostable, can be deployed on any cloud
- Can bring your own database to serve as a memory store
- behind any standard web hosting framework
In order to own your memory, you need to be using an Open Harness
Try out Deep Agents today.
*Thank you to a few people for review and thoughts:*
- Sydney Runkle, who is doing a lot of great Deep Agents and memory work
- Viv Trivedy, who is a leading voice on agent harnesses
- Nuno Campos, who has some great writing on context engineering for finance agents
- Sarah Wooders, who is CTO of Letta, a company that has consistently been at the forefront of stateful agents
関連記事
エージェント・ハーネスにおけるメモリ状態の現状(12 分読)
Mem0 が Claude Code や Codex など主要な AI エージェントを調査した結果、すべての実装で境界欠陥が確認され、57-71% のユーザー間データ混在が発生していることが判明しました。
ロックインと予算削減:AIベンダーの締め付けが反撃する
Cレベル経営者は数週間でAIモデルを切り替えられると考えていたが、ベンダーロックインの進行と価格上昇により、その考えは幻想だった。今後はモデル移行が困難になり、コスト増に直面している。
LLMエージェントのための適応型メモリ許可制御
研究者らが、LLMベースのエージェント向けに、長期記憶の内容を制御する適応型メモリ許可制御手法を提案した。これにより、幻覚や陳腐化した事実を含む大量の会話内容の蓄積や、高コストで監査困難な不透明なメモリポリシーへの依存を解決する。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み