Stable Video 4D 2.0:単一動画からの高忠実度新視点合成と4D生成の新アップグレード
Stability AI は、単一動画から高品質な 4D アセットを生成する「Stable Video 4D 2.0」を発表し、業界初の商用利用可能なモデルとしてゲームや映画制作のワークフローに革新をもたらす。
キーポイント
単一動画からの高品質 4D 生成の実現
複数の参照画像や多カメラセットアップを必要とせず、単一の中心視点動画から一貫性のあるマルチビュー動画を生成する能力が大幅に向上した。
3D アテンション機構によるアーキテクチャ刷新
3 次元空間特徴と時間特徴を融合させる「3D アテンション」を採用し、静止物から動きのある対象への学習段階を経て、よりシャープで整合性の高い出力を実現した。
ベンチマークにおける業界最高性能
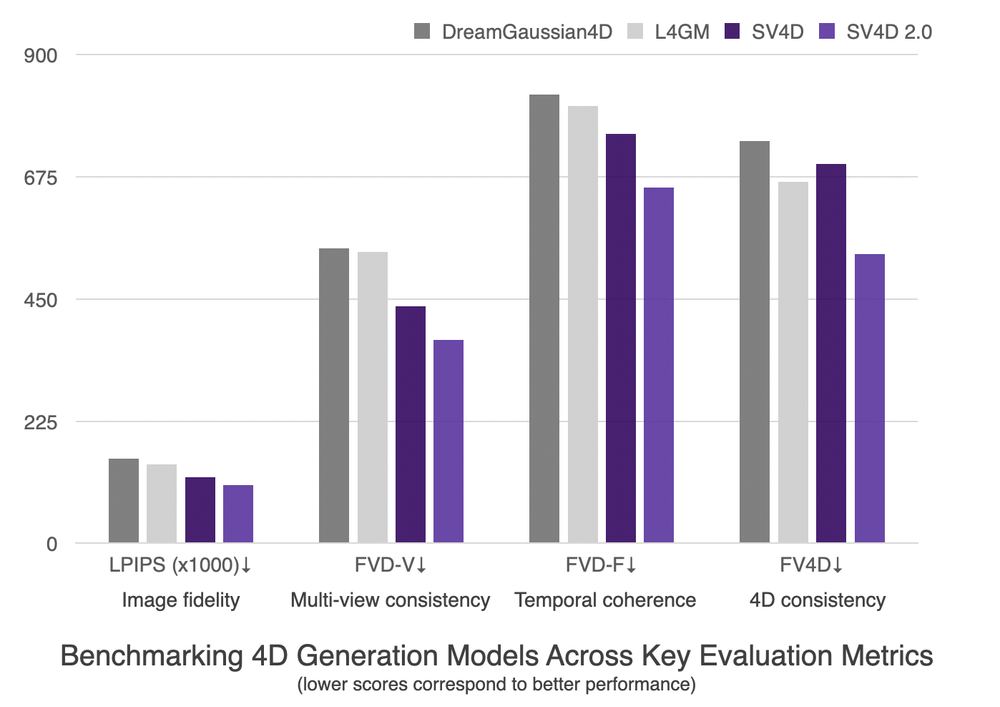
画像忠実度(LPIPS)や時系列一貫性(FVD-F, FV4D)など主要な評価指標において、既存の競合モデル(DreamGaussian4D など)を上回る SOTA 結果を達成した。
商用利用可能なオープンソース化
Stability AI コミュニティライセンスの下で、商業利用および非商業利用の両方を許可し、Hugging Face や GitHub でモデル・コードが公開された。
性能向上と評価
SV4D 2.0 は Diffusion^2、SV3D、および従来の SV4D を上回り、多視点合成における一貫性(FVD-V)と時間的整合性(FVD-F)が大幅に改善されています。
商用利用の開始
Stable Video 4D 2.0 は、Permissive Stability AI Community License の下で商用・非商用を問わず利用可能になりました。
影響分析・編集コメントを表示
影響分析
この発表は、3D/4D コンテンツ制作のハードルを劇的に下げ、従来の多カメラ撮影や高コストなスキャンプロセスを不要にする可能性を秘めています。特にゲーム開発や映画制作において、単一の動画素材から即座に動的な 3D アセットを作成できるため、プロダクションワークフローの効率化とクリエイティブの可能性拡大に直結する重大な進展です。
編集コメント
単一動画から高品質な 4D データを生成できるモデルが商用利用可能になったことは、メタバースやゲーム制作の現場におけるインフラ変革の契機となり得ます。ただし、動的な動きにおけるアーティファクトの発生には依然として注意が必要ですが、技術的限界を大きく押し広げた画期的なリリースです。
Stable Video 4D 2.0: 単一動画からの高忠実度新視点合成と4D生成を実現する新バージョン
主なポイント:
- Stable Video Diffusion 4D (SV4D) を Stable Video 4D 2.0 (SV4D 2.0) にアップグレードし、実世界の動画に対してより高品質な出力を実現しました。
- 分析の結果、SV4D 2.0 は 4D生成と新視点合成の両方において、最先端の結果を達成しています。
- Stable Video 4D 2.0 は、寛容な Stability AI Community License の下で、商用・非商用を問わずご利用いただけます。
- マルチビュー生成モデルは Hugging Face からダウンロード可能で、コードは GitHub で、4Dアセット再構築プロセスに関する詳細は arXiv でご覧いただけます。
Stable Video 4D 2.0
Stable Video Diffusion 4D (SV4D) を Stable Video 4D 2.0 (SV4D 2.0) にアップグレードし、実世界の動画に対してより高品質な出力を実現しました。このマルチビュー動画拡散モデルは、単一のオブジェクト中心動画から動的4Dアセットを生成するのに最適です。これらの改良により、ゲーム内キャラクター用のスプライトシート生成から、映画や仮想世界向けアセットの作成支援まで、プロフェッショナルな制作ワークフロー向けの動的4Dアセット構築が容易になります。
未見の視点から3Dオブジェクトを可視化する際の本質的な曖昧さにより、マルチビュー生成は依然として複雑な課題です。これは特に被写体が動いている場合に困難を伴います。SV4D 2.0 は、大規模データセット、マルチカメラ設定、前処理に依存することなく、一貫したマルチアングル出力を生成することで、この課題への着実な進歩をもたらします。これは大きな前進ですが、動きの激しい被写体では、まれにアーティファクトが生じる可能性があります。
新機能
SV4D 2.0 には、以下のような複数の改良を加えました。
- より鮮明で一貫性のある4D出力: モデルは段階的に学習され、静的3Dアセットから始めて動きを追加することで、より明確で一貫性のある4D結果を生成します。
- 参照ビューが不要: 単一の動画から直接動作するため、マルチビュー参照画像が不要になりました。
- 再設計されたネットワークアーキテクチャ: 3D空間的特徴と時間的特徴を融合するメカニズムである 3Dアテンション を採用し、参照ビューに依存せずに時空間的一貫性を向上させています。
- 実世界への一般化性能の向上: 実世界の動画に対して、より一貫した性能を発揮します。合成データで学習されていますが、事前学習済み動画モデルからの知識を保持しています。
研究とベンチマーク
分析の結果、SV4D 2.0 は 4D生成において最先端の結果を達成しています。主要なベンチマークすべてで首位を獲得しました:LPIPS(画像忠実度)、FVD-V(マルチビュー一貫性)、FVD-F(時間的一貫性)、FV4D(4D一貫性)。DreamGaussian4D、L4GM、SV4D と比較して、このバージョンはより鮮明で一貫性のある4D出力を生成します。
また、分析により、SV4D 2.0 は 新視点合成 において Diffusion^2、SV3D、SV4D を上回る性能を示すことが確認されています。このモデルはマルチビュー一貫性(FVD-V)と時間的一貫性(FVD-F)を大幅に改善し、視点の変化や時間の経過に伴っても高品質な出力を維持します。モデルの技術的詳細については、研究論文をご覧ください。
今すぐ始める
Stable Video 4D 2.0 は、寛容な Stability AI Community License の下で、商用・非商用を問わずご利用いただけます。
マルチビュー生成モデルは Hugging Face からダウンロード可能で、コードは GitHub で、4Dアセット再構築プロセスに関する詳細は arXiv でご覧いただけます。
最新情報については、X、LinkedIn、Instagram でフォローし、Discord コミュニティへご参加ください。
原文を表示
Key Takeaways:
We’ve upgraded Stable Video Diffusion 4D (SV4D) to Stable Video 4D 2.0 (SV4D 2.0), delivering higher-quality outputs on real-world video.
Our analysis shows that SV4D 2.0 achieves state-of-the-art results in both 4D generations and novel-view synthesis.
Stable Video 4D 2.0 is now available for both commercial and non-commercial use under the permissive Stability AI Community License.
You can download the multi-view generation models on Hugging Face, find the code on GitHub, and read about the 4D asset reconstruction process on arXiv.
Download model
Stable Video 4D 2.0
We’ve upgraded Stable Video Diffusion 4D (SV4D) to Stable Video 4D 2.0 (SV4D 2.0), delivering higher-quality outputs on real-world video. This multi-view video diffusion model is ideal for dynamic 4D asset generation from a single object-centric video. These upgrades make it easier to create dynamic 4D assets for professional production workflows, from generating sprite sheets for in-game characters, to supporting assets for film and virtual worlds.
Multi-view generation remains complex due to the inherent ambiguity of visualizing 3D objects from unseen views. This is especially difficult when subjects are in motion. SV4D 2.0 makes incremental progress toward addressing this challenge by producing consistent, multi-angle outputs without relying on large datasets, multi-camera setups, or preprocessing. While this represents a step forward, occasional artifacts may still appear with dynamic motion.
What’s new
We’ve made multiple upgrades to SV4D 2.0, including:
Sharper and Coherent 4D Outputs: The model was trained in phases, starting with static 3D assets and then adding motion, resulting in clearer and more consistent 4D results.
No Reference Views Required: Works directly from a single video, eliminating the need for multi-view reference images.
Redesigned Network Architecture: Utilizes 3D attention, a mechanism that fuses 3D spatial and temporal features, improving spatio-temporal consistency without relying on reference views.
Improved Real-World Generalization: Performs more consistently on real-world videos. While trained on synthetic data, the model retains world knowledge from pre-trained video models.
Research and benchmarking
Our analysis shows that SV4D 2.0 achieves state-of-the-art results in 4D generation. It ranks first across all major benchmarks: LPIPS (Image fidelity), FVD-V (Multi-view consistency), FVD-F (Temporal coherence), and FV4D (4D consistency). Compared to DreamGaussian4D, L4GM, and SV4D, this version generates sharper and more consistent 4D outputs.
 image
image
Our analysis also shows that SV4D 2.0 outperforms Diffusion^2, SV3D, and SV4D on novel-view synthesis.The model significantly improves multi-view consistency (FVD-V) and temporal coherence (FVD-F), maintaining high-quality outputs across both changing viewpoints and time. You can read more about the technical advancements of the model in the research paper.
 image
image
Getting started
Stable Video 4D 2.0 is now available for both commercial and non-commercial use under the permissive Stability AI Community License.
You can download the multi-view generation models on Hugging Face, find the code on GitHub, and read about the 4D asset reconstruction process on arXiv.
To stay updated on our progress, follow us on X, LinkedIn, Instagram, and join our Discord Community.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み