LLM評価の4つの主要アプローチを理解する(基礎から)
Sebastian Raschka は、LLM の評価における 4 つの主要アプローチ(多肢選択ベンチマーク、検証者、リーダーボード、LLM ジャッジ)を解説し、それぞれの実装コード例を通じて実践的な理解を深めるための包括的ガイドを提供している。
キーポイント
評価手法の分類と概要
記事では、モデル比較や進捗測定に用いられる 4 つの主要な LLM 評価アプローチ(多肢選択ベンチマーク、検証者、リーダーボード、LLM ジャッジ)が明確に定義され、それぞれの役割と限界が説明されています。
実装コードによる理解深化
単なる理論解説にとどまらず、各評価手法をゼロから実装する Python/PyTorch のコード例を提供し、読者が内部動作を深く理解できるようにしています。
推論(Reasoning)モデルとの関連
著者の forthcoming な書籍『Build a Reasoning Model (From Scratch)』の文脈で、特に検証者ベースの評価が推論能力を持つ LLM において重要であることを強調しています。
ベンチマークとリーダーボードの解釈
既存のベンチマークやリーダーボードの結果を正しく解釈し、異なるモデル間での公平な比較を行うためのメンタルマップを提供しています。
LLM評価の4つの主要カテゴリ
実務では多肢選択、検証器(verifiers)、リーダーボード、およびLLM判事という4つの方法が一般的に使用され、これらはベンチマークベースと判断ベースの2つのグループに分類されます。
MMLUによる知識想起の評価
MMLUのような多肢選択ベンチマークは、57の教科目からなる約1万6千問の質問を用いて、モデルの知識想起能力を標準化されたテストと同様に定量的に測定します。
評価結果の表現方法
これらの評価では、正答数と総問題数の比率である「精度(accuracy)」が主要な指標として用いられ、例えば1万6千問中1万4千問正解であれば87.5%となります。
影響分析・編集コメントを表示
影響分析
この記事は、LLM の評価がブラックボックス化しがちな現状に対し、技術的な内側からアプローチする実践的な枠組みを提供しています。特に、コードを実装して理解を深めるという著者特有のアプローチは、開発者が表面的なベンチマークスコアに踊らされず、自社のユースケースに最適なモデルを選定・評価するための強力な指針となります。
編集コメント
Sebastian Raschka 氏による、理論と実装の両面から LLM 評価を捉え直す貴重なガイドです。特に「コードで書く」ことで本質を理解する姿勢は、開発者にとって非常に示唆に富んでいます。
LLM評価の4つの主要アプローチを理解する(スクラッチから)
選択式ベンチマーク、検証器、リーダーボード、LLMジャッジ、コード例付き
 Sebastian Raschka, PhDOct 05, 20253622633Share私たちは実際にどのようにLLMを評価するのでしょうか?それは単純な質問ですが、より大きな議論を引き起こす傾向があります。
Sebastian Raschka, PhDOct 05, 20253622633Share私たちは実際にどのようにLLMを評価するのでしょうか?それは単純な質問ですが、より大きな議論を引き起こす傾向があります。
プロジェクトのアドバイスや共同作業を行う際、私が最も頻繁に尋ねられることの一つは、異なるモデル間でどのように選択するか、そして世の中にある評価結果をどのように理解するかです。(そしてもちろん、ファインチューニングや独自開発を行う際に進捗をどのように測定するかもです。)
これが非常に頻繁に話題に上るので、人々がLLMを比較する際に使用する主要な評価方法について、短い概要を共有することが役立つかもしれないと考えました。もちろん、LLM評価は非常に大きなトピックであり、単一の資料で網羅的にカバーすることはできませんが、これらの主要なアプローチについて明確なメンタルマップを持つことで、ベンチマーク、リーダーボード、論文を解釈することがずっと容易になると考えています。
私は当初、これらの評価技術を近刊の書籍『Build a Reasoning Model (From Scratch)』に含めることを計画していましたが、それらは主な範囲から少し外れてしまいました。(同書自体は、検証器ベースの評価に焦点を当てています。)そこで、これをスクラッチからのコード例付きの長めの記事として共有するのも良いだろうと考えました。
『Build A Reasoning Model (From Scratch)』では、スクラッチから推論LLMを構築する実践的なアプローチを取っています。「Build A Large Language Model (From Scratch)」がお好きだった方へ、この本は純粋なPyTorchですべてをスクラッチから構築するという点で、同様のスタイルで書かれています。
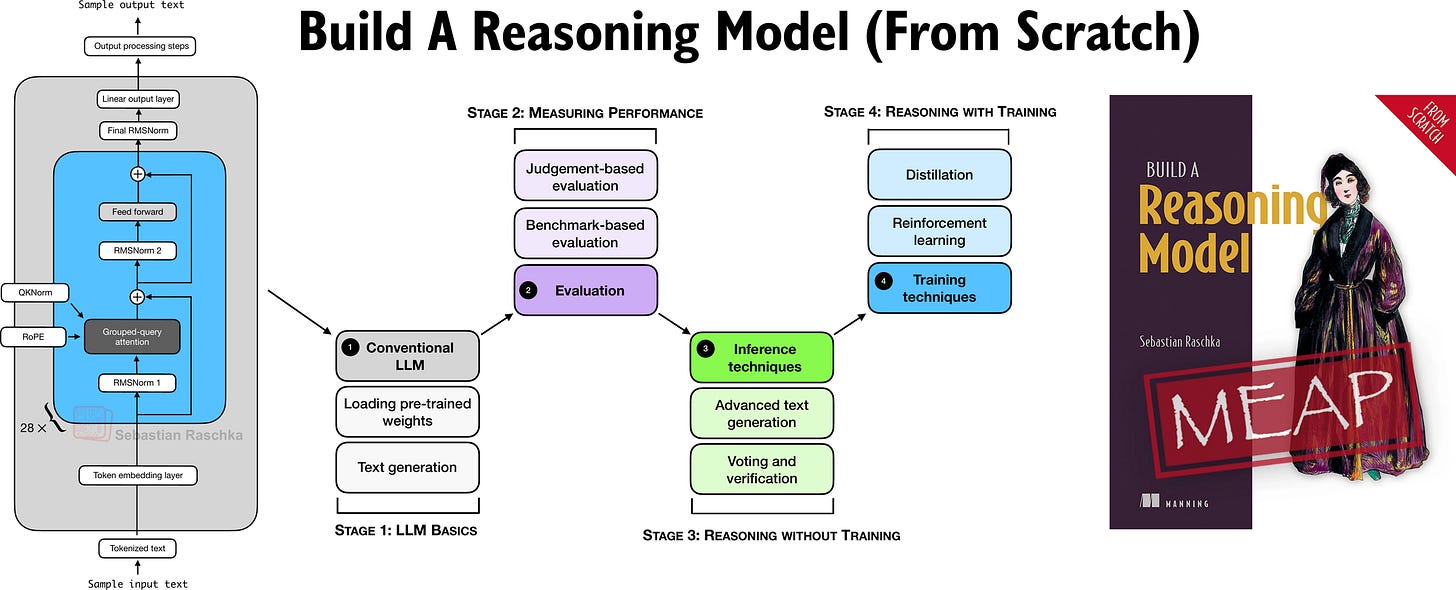 推論は、LLMを改善する上で最もエキサイティングで重要な最近の進歩の一つですが、理論として「推論」という用語を聞き、それについて読むだけでは、最も誤解されやすいものの一つでもあります。そこで、この本では、スクラッチから推論LLMを構築する実践的なアプローチを取っています。
推論は、LLMを改善する上で最もエキサイティングで重要な最近の進歩の一つですが、理論として「推論」という用語を聞き、それについて読むだけでは、最も誤解されやすいものの一つでもあります。そこで、この本では、スクラッチから推論LLMを構築する実践的なアプローチを取っています。
この本は現在、100ページ以上がオンラインで公開されている早期アクセス段階にあり、私はさらに30ページを書き終え、レイアウトチームによって現在追加されています。早期アクセスプログラムに参加された方(ご支援に心から感謝します!)は、それらが公開された際にメールを受け取るはずです。
追伸:現在、LLM研究の最前線では多くのことが起こっています。私はまだ増え続けるブックマークした論文リストを追いかけているところで、次回の記事では最も興味深いもののいくつかを取り上げる予定です。
しかし今は、その利点と弱点をよりよく理解するために、4つの主要なLLM評価方法と、それらのスクラッチからのコード実装について議論しましょう。
LLMの主要な評価方法を理解する
実際に訓練されたLLMを評価する一般的な方法は4つあります:選択式、検証器、リーダーボード、そしてLLMジャッジです。以下の図1に示す通りです。研究論文、マーケティング資料、技術レポート、モデルカード(LLM固有の技術レポートを指す用語)には、しばしばこれらのカテゴリのうち2つ以上の結果が含まれています。
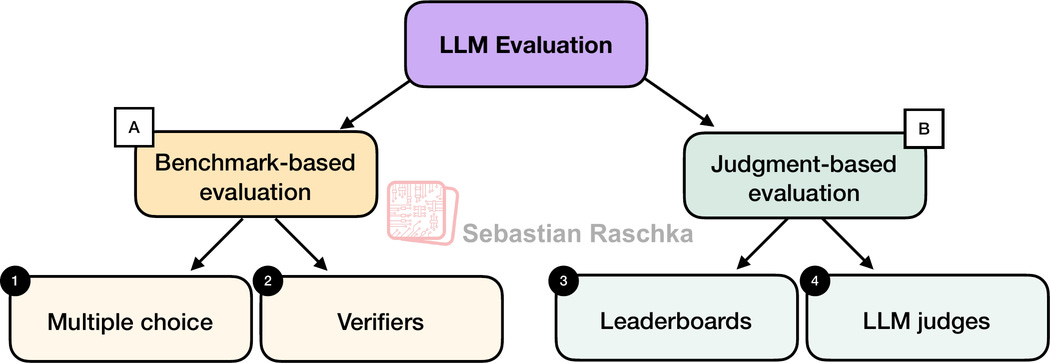 図1:本記事で取り上げる4つの異なる評価モデルの概要。
図1:本記事で取り上げる4つの異なる評価モデルの概要。
さらに、ここで紹介する4つのカテゴリは、上の図に示すように、ベンチマークベースの評価とジャッジメントベースの評価の2つのグループに分類されます。
(他にも、訓練損失、パープレキシティ、報酬などの指標がありますが、それらは通常、モデル開発の内部で使用されます。)
以下のサブセクションでは、4つの方法それぞれについて簡単な概要と例を提供します。
方法1:回答選択の正確性を評価する
まずはベンチマークベースの方法から始めます:選択式質問応答です。
歴史的に、最も広く使用されている評価方法の一つは、MMLU(Massive Multitask Language Understandingの略、https://huggingface.co/datasets/cais/mmlu)のような選択式ベンチマークです。このアプローチを説明するために、図2はMMLUデータセットからの代表的なタスクを示しています。
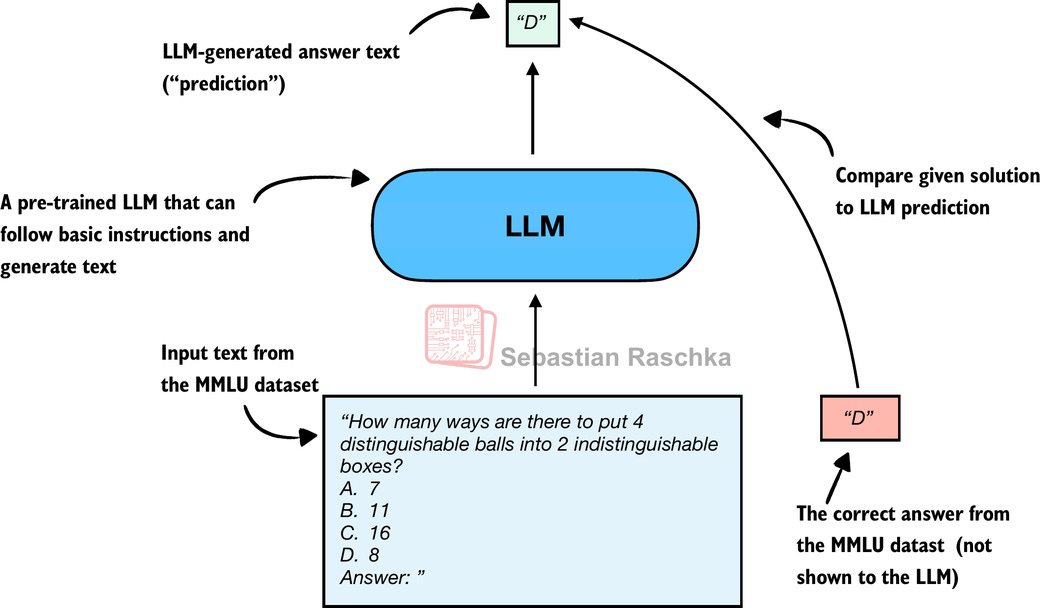 図2:LLMをMMLUで評価する方法。モデルの選択式予測をデータセットの正解と比較する。
図2:LLMをMMLUで評価する方法。モデルの選択式予測をデータセットの正解と比較する。
図2はMMLUデータセットからの単一の例を示しています。完全なMMLUデータセットは57の科目(高校数学から生物学まで)から構成され、合計約16,000の選択式問題があり、性能は正答率(正しく回答された問題の割合)で測定されます。例えば、16,000問中14,000問が正解ならば87.5%です。
MMLUのような選択式ベンチマークは、標準化テスト、多くの学校の試験、または理論的な運転免許試験と同様に、LLMの知識想起を直接的で定量的な方法でテストします。
図2は、モデルが予測した回答の文字を直接正解と比較する、選択式評価の簡略化されたバージョンを示していることに注意してください。対数確率スコアリングを含む他の2つの一般的な方法が存在します。私はそれらをここGitHubで実装しました。(これはここで説明した概念に基づいているので、この記事を読み終えた後に確認することをお勧めします。)
以下のサブセクションでは、図2に示したMMLUのスコアリングをコードでどのように実装できるかを説明します。
1.2 モデルの読み込み
まず、MMLUで評価する前に、事前訓練済みモデルを読み込む必要があります。ここでは、純粋なPyTorchでQwen3 0.6Bをスクラッチから実装したものを使用します。これは約1.5 GBのRAMしか必要としません。
ここではQwen3モデルの実装の詳細は重要ではありません。単に評価したいLLMとして扱います。しかし、もし興味があれば、スクラッチからの実装の詳細は、私の以前の記事『Understanding and Implementing Qwen3 From Scratch』で見ることができ、ソースコードはここGitHubでも利用可能です。
多くの行にわたるQwen3のソースコードをコピー&ペーストする代わりに、私のreasoning_from_scratch Pythonライブラリからインポートします。このライブラリは以下のコマンドでインストールできます。
pip install reasoning_from_scratch
uv add reasoning_from_scratch
コードブロック1:事前訓練済みモデルの読み込み
from pathlib import Path
import torch
from reasoning_from_scratch.ch02 import get_device
from reasoning_from_scratch.qwen3 import (
download_qwen3_small,
Qwen3Tokenizer,
Qwen3Model,
QWEN_CONFIG_06_B
)
device = get_device()
互換性のあるGPUでTensor Coresを有効にするため
行列乗算精度を「high」に設定
torch.set_float32_matmul_precision("high")
デバイスの互換性の問題に遭遇した場合は
以下の行のコメントを解除してください
device = "cpu"
デフォルトでベースモデルを使用
WHICH_MODEL = "base"
if WHICH_MODEL == "base":
download_qwen3_small(
kind="base",
tokenizer_only=False,
out_dir="qwen3"
)
tokenizer_path = Path("qwen3") / "tokenizer-base.json"
model_path = Path("qwen3") / "qwen3-0.6B-base.pth"
tokenizer = Qwen3Tokenizer(tokenizer_file_path=tokenizer_path)
elif WHICH_MODEL == "reasoning":
download_qwen3_small(
kind="reasoning",
tokenizer_only=False,
out_dir="qwen3"
)
tokenizer_path = Path("qwen3") / "tokenizer-reasoning.json"
model_path = Path("qwen3") / "qwen3-0.6B-reasoning.pth"
tokenizer = Qwen3Tokenizer(
tokenizer_file_path=tokenizer_path,
apply_chat_template=True,
add_generation_prompt=True,
add_thinking=True,
)
else:
raise ValueError(f"Invalid choice: WHICH_MODEL={WHICH_MODEL}")
model = Qwen3Model(QWEN_CONFIG_06
原文を表示
Understanding the 4 Main Approaches to LLM Evaluation (From Scratch)
Multiple-Choice Benchmarks, Verifiers, Leaderboards, and LLM Judges with Code Examples
Sebastian Raschka, PhDOct 05, 20253622633ShareHow do we actually evaluate LLMs? It’s a simple question, but one that tends to open up a much bigger discussion.
When advising or collaborating on projects, one of the things I get asked most often is how to choose between different models and how to make sense of the evaluation results out there. (And, of course, how to measure progress when fine-tuning or developing our own.)
Since this comes up so often, I thought it might be helpful to share a short overview of the main evaluation methods people use to compare LLMs. Of course, LLM evaluation is a very big topic that can’t be exhaustively covered in a single resource, but I think that having a clear mental map of these main approaches makes it much easier to interpret benchmarks, leaderboards, and papers.
I originally planned to include these evaluation techniques in my upcoming book, Build a Reasoning Model (From Scratch), but they ended up being a bit outside the main scope. (The book itself focuses more on verifier-based evaluation.) So I figured that sharing this as a longer article with from-scratch code examples would be nice.
In Build A Reasoning Model (From Scratch), I am taking a hands-on approach to building a reasoning LLM from scratch. If you liked “Build A Large Language Model (From Scratch)”, this book is written in a similar style in terms of building everything from scratch in pure PyTorch.
Reasoning is one of the most exciting and important recent advances in improving LLMs, but it’s also one of the easiest to misunderstand if you only hear the term reasoning and read about it in theory. So, in this book, I am taking a hands-on approach to building a reasoning LLM from scratch.
The book is currently in early-access with >100 pages already online, and I have just finished another 30 pages that are currently being added by the layout team. If you joined the early access program (a big thank you for your support!), you should receive an email when those go live.
PS: There’s a lot happening on the LLM research front right now. I’m still catching up on my growing list of bookmarked papers and plan to highlight some of the most interesting ones in the next article.
But now, let’s discuss the four main LLM evaluation methods along with their from-scratch code implementations to better understand their advantages and weaknesses.
Understanding the main evaluation methods for LLMs
There are four common ways of evaluating trained LLMs in practice: multiple choice, verifiers, leaderboards, and LLM judges, as shown in Figure 1 below. Research papers, marketing materials, technical reports, and model cards (a term for LLM-specific technical reports) often include results from two or more of these categories.
Figure 1: An overview of the 4 different evaluations models covered in this article.
Furthermore the four categories introduced here fall into two groups: benchmark-based evaluation and judgment-based evaluation, as shown in the figure above.
(There are also other measures, such as training loss, perplexity, and rewards, but they are usually used internally during model development.)
The following subsections provide brief overviews and examples of each of the four methods.
Method 1: Evaluating answer-choice accuracy
We begin with a benchmark‑based method: multiple‑choice question answering.
Historically, one of the most widely used evaluation methods is multiple-choice benchmarks such as MMLU (short for Massive Multitask Language Understanding, https://huggingface.co/datasets/cais/mmlu). To illustrate this approach, figure 2 shows a representative task from the MMLU dataset.
Figure 2: Evaluating an LLM on MMLU by comparing its multiple-choice prediction with the correct answer from the dataset.
Figure 2 shows just a single example from the MMLU dataset. The complete MMLU dataset consists of 57 subjects (from high school math to biology) with about 16 thousand multiple-choice questions in total, and performance is measured in terms of accuracy (the fraction of correctly answered questions), for example 87.5% if 14,000 out of 16,000 questions are answered correctly.
Multiple-choice benchmarks, such as MMLU, test an LLM’s knowledge recall in a straightforward, quantifiable way similar to standardized tests, many school exams, or theoretical driving tests.
Note that figure 2 shows a simplified version of multiple-choice evaluation, where the model’s predicted answer letter is compared directly to the correct one. Two other popular methods exist that involve log-probability scoring. I implemented them here on GitHub. (As this builds on the concepts explained here, I recommended checking this out after completing this article.)
The following subsections illustrate how the MMLU scoring shown in figure 2 can be implemented in code.
1.2 Loading the model
First, before we can evaluate it on MMLU, we have to load the pre-trained model. Here, we are going to use a from-scratch implementation of Qwen3 0.6B in pure PyTorch, which requires only about 1.5 GB of RAM.
Note that the Qwen3 model implementation details are not important here; we simply treat it as an LLM we want to evaluate. However, if you are curious, a from-scratch implementation walkthrough can be found in my previous Understanding and Implementing Qwen3 From Scratch article, and the source code is also available here on GitHub.
Instead of copy & pasting the many lines of Qwen3 source code, we import it from my reasoning_from_scratch Python library, which can be installed via
pip install reasoning_from_scratch
uv add reasoning_from_scratch
Code block 1: Loading a pre-trained model
from pathlib import Path import torch from reasoning_from_scratch.ch02 import get_device from reasoning_from_scratch.qwen3 import ( download_qwen3_small, Qwen3Tokenizer, Qwen3Model, QWEN_CONFIG_06_B ) device = get_device() # Set matmul precision to "high" to # enable Tensor Cores on compatible GPUs torch.set_float32_matmul_precision("high") # Uncomment the following line # if you encounter device compatibility issues # device = "cpu" # Use the base model by default WHICH_MODEL = "base" if WHICH_MODEL == "base": download_qwen3_small( kind="base", tokenizer_only=False, out_dir="qwen3" ) tokenizer_path = Path("qwen3") / "tokenizer-base.json" model_path = Path("qwen3") / "qwen3-0.6B-base.pth" tokenizer = Qwen3Tokenizer(tokenizer_file_path=tokenizer_path) elif WHICH_MODEL == "reasoning": download_qwen3_small( kind="reasoning", tokenizer_only=False, out_dir="qwen3" ) tokenizer_path = Path("qwen3") / "tokenizer-reasoning.json" model_path = Path("qwen3") / "qwen3-0.6B-reasoning.pth" tokenizer = Qwen3Tokenizer( tokenizer_file_path=tokenizer_path, apply_chat_template=True, add_generation_prompt=True, add_thinking=True, ) else: raise ValueError(f"Invalid choice: WHICH_MODEL={WHICH_MODEL}") model = Qwen3Model(QWEN_CONFIG_06_B) model.load_state_dict(torch.load(model_path)) model.to(device) # Optionally enable model compilation for potential performance gains USE_COMPILE = False if USE_COMPILE: torch._dynamo.config.allow_unspec_int_on_nn_module = True model = torch.compile(model)
1.3 Checking the generated answer letter
In this section, we implement the simplest and perhaps most intuitive MMLU scoring method, which relies on checking whether a generated multiple-choice answer letter matches the correct answer. This is similar to what was illustrated earlier in Figure 2, which is shown below again for convenience.
Figure 3: Evaluating an LLM on MMLU by comparing its multiple-choice prediction with the correct answer from the dataset.
For this, we will work with an example from the MMLU dataset:
example = { "question": ( "How many ways are there to put 4 distinguishable" " balls into 2 indistinguishable boxes?" ), “choices”: ["7", "11", "16", "8"], “answer”: "D", }
Next, we define a function to format the LLM prompts.
Code block 2: Loading a pre-trained model
def format_prompt(example): return ( f"{example['question']}\n" f"A. {example['choices'][0]}\n" f"B. {example['choices'][1]}\n" f"C. {example['choices'][2]}\n" f"D. {example['choices'][3]}\n" "Answer: " ) # Trailing space in "Answer: " encourages a single-letter next token
Let’s execute the function on the MMLU example to get an idea of what the formatted LLM input looks like:
prompt = format_prompt(example) print(prompt)
How many ways are there to put 4 distinguishable balls into 2 indistinguishable boxes?
How many ways are there to put 4 distinguishable balls into 2 indistinguishable boxes? A. 7 B. 11 C. 16 D. 8 Answer:
The model prompt, as shown above, provides the model with a list of the different answer choices and ends with an “Answer: “
While it is not strictly necessary, it can sometimes also be helpful to provide additional questions along with the correct answers as input, so that the model can observe how it is expected to solve the task. (For example, cases where 5 examples are provided are also known as 5-shot MMLU.) However, for current generations of LLMs, where even the base models are quite capable, this is not required.
Loading different MMLU samples
You can load examples from the MMLU dataset directly via the datasets library (which can be installed via pip install datasets
uv add datasets
from datasets import load_dataset configs = get_dataset_config_names("cais/mmlu") dataset = load_dataset("cais/mmlu", "high_school_mathematics") # Inspect the first example from the test set: example = dataset["test"][0] print(example)
Above, we used the “high_school_mathematics”
from datasets import get_dataset_config_names subsets = get_dataset_config_names("cais/mmlu") print(subsets)
Next, we tokenize the prompt and wrap it in a PyTorch tensor object as input to the LLM:
prompt_ids = tokenizer.encode(prompt) prompt_fmt = torch.tensor(prompt_ids, device=device) # Add batch dimension: prompt_fmt = prompt_fmt.unsqueeze(0)
Then, with all that setup out of the way, we define the main scoring function below, which generates a few tokens (here, 8 tokens by default) and extracts the first instance of letter A/B/C/D that the model prints.
Code block 3: Extracting the generated letter
from reasoning_from_scratch.ch02_ex import ( generate_text_basic_stream_cache ) def predict_choice( model, tokenizer, prompt_fmt, max_new_tokens=8 ): pred = None for t in generate_text_basic_stream_cache( model=model, token_ids=prompt_fmt, max_new_tokens=max_new_tokens, eos_token_id=tokenizer.eos_token_id, ): answer = tokenizer.decode(t.squeeze(0).tolist()) for letter in answer: letter = letter.upper() # stop as soon as a letter appears if letter in "ABCD": pred = lett
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み