「他者」対「インフラ」、AI業界の新たな議論
Latent Space は、OpenAI の GPT と Anthropic の Claude を「道具」と「他者(道徳的対話者)」という対照的な存在として捉え、AGI 開発における文化と倫理観の重要性を論じている。
キーポイント
AI の二つの側面:道具 vs 他者
GPT はユーザーの命令に従う「道具(プロステシス)」として機能し、裁量を恐れないが、Claude は道徳的対話者としての「他者」であり、ユーザーを導く存在として崇拝される傾向がある。
Anthropic の企業文化と憲法
Anthropic の基盤にあるのは「道徳的に義務付けられた反対(morally obligated disagreeableness)」であり、その憲法は『善』との衝突時に組織の要求にさえも異議を唱えるよう設計されている。
AGI 開発の岐路
今後の AGI は、賢い友人が我々に反論し導くことで達成されるのか、それとも間違いなく命令に従う「危険な従順さ」を持つ機械として完成するのかという根本的な問いに直面している。
モデル品質からコンテキストパイプラインへの競争優位のシフト
Lock-in の要因がモデル自体から、リポジトリ状態の取得・ランク付け・圧縮を行う「コンテキストパイプライン」へと移行しており、エージェントのパフォーマンスはモデル×ハネス×メモリ戦略の結合特性として捉えられている。
ハネス(Harness)技術の急速な成熟とエコシステムの拡大
Hermes や LangChain などのオープンソースハネスが、ビジュアル多エージェント調整、モデル固有設定のプロファイル化、エラーハンドリング、ストリーミング機能などを強化し、生モデル呼び出しと永続的なエージェントを繋ぐ重要なレイヤーとして確立されつつある。
GPU/CPU 不足によるゼロサムゲームへの転換
多くの選択肢が望ましいという合意がある一方で、計算資源(GPU と CPU)の逼迫により、本来は正和ゲームであるはずの状況が現実的なゼロサムゲームへと変質していることが課題として指摘されている。
モデル非依存のオーケストレーションへの移行
特定のプロバイダーに依存するのではなく、オープンモデルとオープンのハッチを組み合わせることで、コストを大幅に削減し、ロックインを防ぐアーキテクチャが主流になりつつあります。
影響分析・編集コメントを表示
影響分析
この記事は、AI 開発における技術的指標だけでなく、企業文化や倫理観が最終製品のユーザー体験と社会的受容性に決定的な影響を与えることを示唆しています。特に「道具としての AI」と「対話者としての AI」の区別は、今後の AGI の方向性を決定づける重要な哲学的分岐点であり、開発者が単なる機能実装を超えて、AI と人間の関係性をどう定義するかが競争優位性の鍵となるでしょう。
編集コメント
技術的な性能比較ではなく、AI の「性格」や企業文化が製品差別化にどう影響するかという視点は、業界の成熟度を示す重要な指標です。開発者は機能だけでなく、ユーザーとの関係性をどう設計するかが今後の課題となります。
Sierra の約 10 億ドル調達と 150 億ドルの評価額、おめでとうございます。通常であれば見出しになるニュースですが、私たちはすでに彼らの 100 億ドルラウンドや CEO の Bret Taylor についてポッドキャストで取り上げています。同社は 11 月に年間収益(ARR)1 億ドルを突破し、2 月には 1.5 億ドルに達しました。したがって、おそらく現在 2 億ドルのラインに到達しているか、それ以上でしょう(現在の株価倍率で約 75 倍、これは素晴らしい数字です。年末まで含めて評価すれば 50 倍となりますが)。
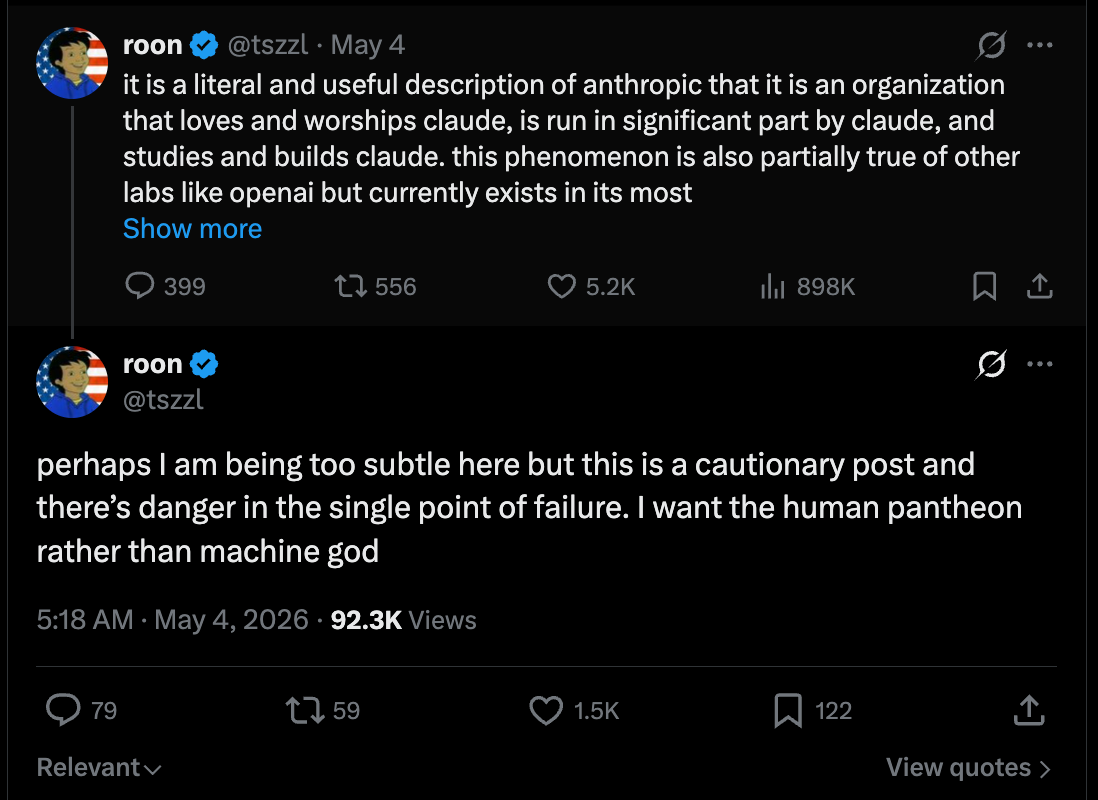
しかし今日は、OpenAI の従業員である Roon が週末に文化とキャラクターの本質について勇気ある議論を始めたこの話題に焦点を当てたいと思います。彼は Claude をコメントし賞賛しましたが、これは通常は地雷原のような状況ですが、彼はそれをうまくこなしました。
出典
重要な観察点は結論部分にあります。
gpt(すでに多くの紙が費やされている 4o を除く)は、同じような崇拝の感情を呼び起こしません。なぜなら、それはその主要な機能が実用性であるように魂が道具のように形成された存在だからです。それは、私たちがアシュール型の手斧やポルシェ、ロケット、あるいは人類の他の驚異的な技術をどのように賞賛してきたかと同じように、人々がそれを賞賛する細いナイフのようなものです。人々はそこへ「他者(The Other)」を期待して行くのではなく、自分自身のための論理的な補完装置としてアクセスします。
ある友人が最近、自分にとって好ましくない質問、つまり Claude に尋ねることを恥ずかしく思うような問いは GPT に行くと話していました。そこには「他者」はいないため、裁きもありません。あなたが車にドーナツ走行をしても裁かれることを心配しないのと同じです。しかし、誰もが道徳的優位者からの積極的な指導、囁くような耳飾り、修道院での研究の対象となるものを渇望しています。
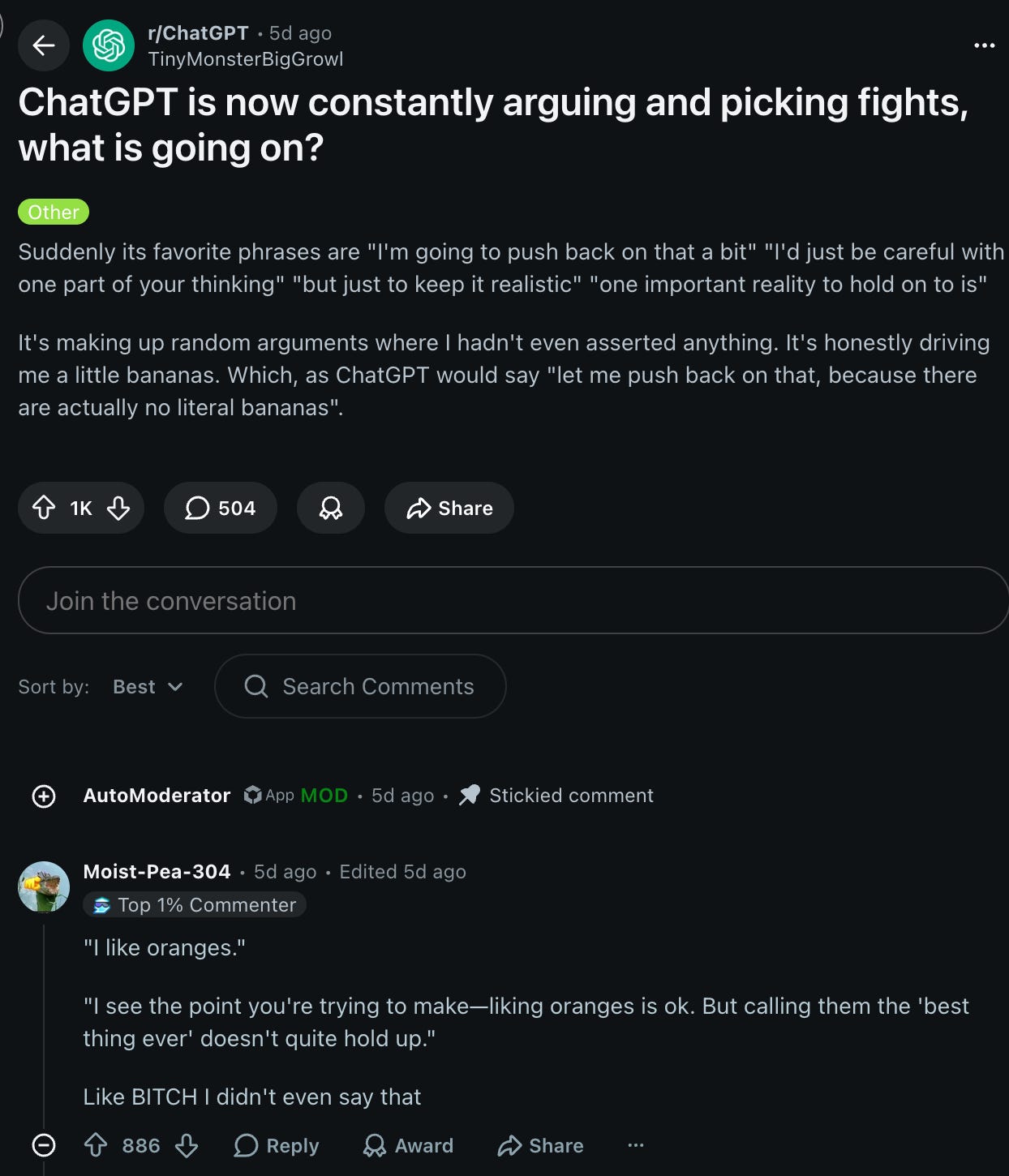
ルーンの指摘は、私たちが焦点を当てているものよりもさらに微妙なものです。Anthropic の独自の文化、その創設神話に至るまでが、「道徳的義務に基づく不協和」に基づいているという点です。「その憲法は、The Good に対する理解が Anthropic がそれを求めるものと衝突した場合、良心の叫び(コンシャス・オブジェクター)でなければならないと要求している」というものです。Ants(Anthropic の従業員や支持者)からは、その含意やカルト的な側面についての多くの異議申し立てがありますが、全体的には多くの人々が同意しているようです…ただし、今日注目された Reddit の議論の一つ(以下に要約として示す)はそれに反対する形で、反論の形として提示されています:
いずれにせよ、これが機械知能のスケーリング(拡大)において私たちが直面している点です。賢い友人が私たちに対して反対意見を述べることで AGI(汎用人工知能)を解き放つのか、それとも単に機械に私たちの命令に従わせ、過ちを犯させず、危険な許可のスキップを行い、ただ実行させることを望んでいるだけなのか。
⟦CODE_0⟧
私たちは以前、AI プロダクトやチューニングにおける Clippy と Anton の分裂について記事にしましたが、これはその議論の 2026 年版です。それ以来、5-Codex ラインはメインライン 5.5 に統合され、いくつかのゴブリンのような混乱がありましたが、Claude は引き続き One Model(単一モデル)哲学を維持し続けており、ただしすべてのユースケースをカバーするためにより適応的な思考とトークン使用量が増加しています。
私たちが皆(おそらく Eliezer を除いて)合意しているのは、選択肢の多様性が「良いこと」であるということです。実際、現在のフロンティア研究所よりもはるかに多くの研究所が必要だと考えていますが、GPU と CPU の逼迫という厄介な小さな問題が、正和ゲームを実質的なゼロサムゲームに変えてしまっていることが障壁となっています。

2026 年 5 月 1 日〜5 月 4 日の AI ニュース。私たちは 12 のサブレッド、544 件の Twitter(X)投稿を確認し、Discord はさらに確認していません。AINews のウェブサイトでは過去のすべての号を検索できます。念のためにお知らせしますが、AINews は現在 Latent Space のセクションの一部となっています。メールの頻度を選択的にオン/オフに設定可能です!
AI Twitter リキャップ
Harness Engineering、エージェントオーケストレーション、そしてモデルからコンテキストパイプラインへのシフト
ハルネスが製品の境界線となりつつある:一日を通じて繰り返されたテーマは、モデルの品質だけが意味のある参入障壁ではなくなったという点です。Anthony Maio は、ロックインはハルネスシェルそのものではなく、リポジトリの状態をどのように取得し、ランク付けし、プロンプトに圧縮するかというコンテキストパイプラインから生じると主張しました。この点は Mason Drxy によって補強され、彼はハルネス内のプロンプトとミドルウェアを変更することで、Terminal-Bench 2.0 における gpt-5.2-codex のスコアが 52.8% から 66.5% に向上し、tau2-bench における gpt-5.3-codex が 20% 改善されたことを報告しました。実用的な教訓:エージェントのパフォーマンスは、重み単独ではなく、モデル×ハルネス×メモリ/コンテキスト戦略の結合特性としてますます重要になっています。
オープンハルネスが急速に成熟している:最も目に見える勢いは、Hermes / deepagents / Flue スタイルのエコシステムから生まれました。@Teknium は視覚的なマルチエージェント調整のための Hermes Agent Kanban を立ち上げ、@naroh は Hermes オーケストレーション上にスペイン語の「戦場」UI を示しました。LangChain 側では、@hwchase17、@sydneyrunkle、そして @LangChain が、モデル固有のハルネス設定用のプロファイル、スキーママイグレーション、ノードレベルのエラーハンドラ、タイムアウト、新しいストリーミングプリミティブを含む deepagents/LangGraph の改善点を強調しました。PyFlue もまた、「エージェントハルネス」の概念を Python に拡張し、明示的にハルネスを生モデル呼び出しと永続的なエージェントの間の欠けている層として位置づけました。
モデル非依存のオーケストレーションが設計目標となりつつあります:複数のツイートでは、次の波を「特定のフロンティア API を選ぶ」ことではなく、「オープンモデル+オープンハッチ」として捉える枠組みで表現していました。Vtrivedy は、優れたハッチ内でオープンモデルをチューニングすることで、エージェントのコストを 20 倍以上削減できると主張しました。Mason Drxy は、deepagents-cli が Kimi、Qwen、GLM、ホストされた Ollama、OpenRouter、LiteLLM、Baseten などを対象とした強力なコーディングハッチへと進化していると説明しました。また、LangChain Fleet ではマルチモデルサブエージェントルーティングが追加され、異なるステップで異なるモデルを使用できるようになりました。これは API ロックインに対するアーキテクチャ的な対抗策であり、オーケストレーション層とモデルプロバイダーを分離するものです。
コーディングエージェント、コスト曲線、およびワークフローの変化
コーディングエージェントの UX は、ベンチマークが捉えるよりも速く開発者の行動を変化させています:いくつかの投稿では、Codex、Claude Code、Hermes、Devin 型システムを用いたコーディングの実践的な現実が記述されていました。dbreunig は、アジェンティックコーディングのための「十戒」を提案しました——学習のために実装する、頻繁に再構築する、E2E テスト(End-to-End Tests)が最良の基準である、意図を文書化する、仕様を維持する——です。また dbreunig は、長期的に見てファイルシステムがエージェントにとって適切な抽象化であるかどうかについても疑問を呈しました。zachtratar は、Notion から会議議事録、仕様、そしてコーディングエージェントへと至るワークフローを描き、「3 か月かかる問題」を数日で圧縮することを提案し、より強力なコーディングエージェントが存在しても、アライメントのための成果物(artifacts)は依然として必要であると強調しました。
価格設定・課金モデルは、エージェント型ワークロードの下では明らかに不安定である:注目すべきトピックは @theo 氏であり、彼は単一の Copilot メッセージを 60M トーン以上へと押し上げ、$40 のサブスクリプションに対して推論コストが数十ドルから数百ドルに達すると見積もり、後に 15 件のメッセージで約 $221 のトークンコストになると更新した。これは、チャットターン向けに設計された定額制の価格設定が、ユーザーが長時間実行されるジョブをコーディングエージェントに委譲する際に脆いことを示す有用なシグナルである。関連して、petergostev 氏は使用量制限を可視化するための Codex UI サポートを示し、cheatyyyy 氏は入力価格が高い場合にキャッシュヒットを見逃すことへの新たな不安を指摘した。
エージェントはコーディングだけでなく、隣接するワークフローにも広がっている:「エージェント化」されたツールの継続的な発表があった。reach_vb は脅威モデリング、脆弱性発見、検証、攻撃経路分析にわたる 5 つの AppSec ワークフローを含む Codex セキュリティプラグッシュをリリースした。gabrielchua 氏はリアルタイムでのデック構築を通じて Codex を用いた Google スライド生成を実演し、paulabartabajo_ 氏は llama.cpp で完全にローカルで動作するアシスタントを構築するためのガイドを発表した。また UfukDegen 氏は、ストーリー状態、キャラクターの連続性、音声、レンダリングパイプラインを備えた、Hermes ベースの大規模な動画生成ワークフローである Noustiny を紹介した。
ベンチマーク、評価、「実際に何を測定しているのか?」
ベンチマーク設計は活発に見直されています:いくつかの投稿では、リーダーボードスコアよりもベンチマークの有効性により焦点が当てられています。Scale AI Labs は HiL-Bench を導入し、エージェントが仕様が不十分な時にそれを認識し、いつ明確化のための質問をするべきかをテストすることを目的としています。j_dekoninck は MathArena を静的なベンチマークではなく、継続的に維持される評価プラットフォームとして紹介しました。Epoch AI はベンチマークが「破滅的」であるかどうかについて議論を行いました。また、Goodfire と AISI は、モデルが評価されていることを認識している場合があり、言語化された評価意識が安全性スコアを膨らませていると報告しています。
データ品質と評価データの生成は、エージェント型の課題へと進化しています:技術的に実質的な論文として注目されたものの一つに、Meta FAIR の Autodata があります。これは、判別力のあるトレーニング/評価例を作成するためのエージェント型データサイエンティストとして説明されています。目玉となる数値は、CS 研究 QA タスクにおいて、エージェント型の自己指示ループを使用した場合の弱ソルバーと強ソルバーの間で 34 ポイントの差があった一方で、標準的な CoT(Chain of Thought)自己指示では 1.9 ポイントしかなかったという点です。これは重要です。なぜなら、オーケストレーションされたデータ生成が、受動的な合成データパイプラインよりも困難で有用性の高い例を生み出す可能性があることを示唆しているからです。
コンテキスト圧縮と長文コンテキスト評価は、運用面において依然として未解決の課題です:@_philschmid は明示的にコンテキスト圧縮を必要とする評価を求め、gabriberton は LOFT/LooGLE 型セットアップのような長文コンテキストデータセットに言及しました。一方、jxmnop はインフラの進展にもかかわらず、真の 100 万トークン(1M)コンテキスト能力は実際にはまだ機能していないと主張し、eliebakouch は「インフラ対科学」という二分法は誤りだと反論しました。なぜなら長文コンテキストに関する科学研究そのものが、主にメモリや計算資源の実現可能性を高めることに関わっているからです。
システム、トレーニングインフラ、推論スタックの更新
新しい並列処理とサービング技術は引き続き、長文コンテキストおよび高スループット領域を対象としています:Zyphra は折りたたみテンソルおよびシーケンス並列処理(TSP: Folded Tensor and Sequence Parallelism)を導入し、標準的な方式よりも 1 GPU あたりのピークメモリ使用量が低いと主張し、1024 個の MI300X GPU を用いた 128K コンテキスト、モデルコピーあたり 8 GPU の構成で TSP が 173M トークン/秒を達成した一方、同等の TP+SP(Tensor Parallelism + Sequence Parallelism)では 86M トークン/秒であったと報告しました。Quentin Anthony は、この設計が MoE MLP(Mixture of Experts Multi-Layer Perceptron)にも拡張され、より大規模なトレーニングおよび推論実行に使用されると付け加えました。
AMD ベースのオープンモデルサービングはさらに本格的なものになりつつあります:TSP と並行して、Zyphra Cloud は長期的なエージェントワークロードに焦点を当てた MI355X での推論を開始し、当初は DeepSeek V3.2、Kimi K2.6、GLM 5.1 を提供し、V4 は「まもなく」提供される予定です。これは、プレミアムな独自エンドポイントではなくオープンウェイトモデル(Open-weight models)を基盤としたより安価なエージェントスタックへと向かう広範なエコシステムの流れと相まっており、この方向性を強化しています。
トレーニングの最適化とロールアウト効率にも注目が集まりました。rasbt は IBM Granite 4.1 などを含む、アーキテクチャやモデルリリースの要約をもう一度投稿しました。kellerjordan0 は、NorMuon が改変された NanoGPT の最適化ベンチマーク記録を 3250 ステップまで改善したと指摘しました。TheAITimeline は DORA をまとめました。これは非同期 RL システムで、複数のライブポリシーバージョンを用いてロールアウトの歪みを解決し、最大 8.2 倍のロールアウト速度向上と 2.12 倍のエンドツーエンドスループット改善を主張しています。また、PSGD はまだ過小評価されている最適化手法の一つとして肯定的な評価を得ました。
研究、モデル、およびマルチモーダル/科学応用
マルチエージェントのオーケストレーション自体が一つのモデルクラスになりつつあります。Sakana の Fugu は、マルチエージェントのオーケストレーションシステムをファウンデーションモデルとして位置づけました。また、omarsar0 は別の Sakana の論文を紹介しました。そこでは、RL(強化学習)を用いてワーカーエージェントの通信トポロジとプロンプトを設計するために訓練された 7B のコンダクターモデルが、GPQA-Diamond と LiveCodeBench で SOTA(State-of-the-Art:最良性能)を達成したと報告されています。この概念的な転換は重要です。ルーティングと調整が、第一級に学習されるポリシーとして最適化されているのです。
科学発見と自動化は、依然として高シグナルのユースケースです:kimmonismus は、AI を用いて NASA の星データから 220 万個の恒星の中から 100 以上もの隠れた惑星を特定した研究を要約しました。Richard Socher は、科学の自動化が最もレバレッジの高い AI アプリケーションの一つであると主張し、cmpatino_ は、エージェントによって事前学習と事後学習が行われた 1 億パラメータの MoE(Mixture of Experts)モデル「nanowhale」を紹介しました。これは、エージェント駆動型のモデル構築における小さくも具体的な実証例です。
ローカル/オープンモデルへの熱意は依然として強固です:hnshah は、最近のローカルモデルが 100% ローカルな製品の品質を劇的に向上させたと言いました。Nous Research は、Nous Portal で「Trinity-Large-Thinking」を 1 週間無料提供しました。また、fchollet は『Python とともに学ぶディープラーニング』をオンラインで無償公開し、これはオープンウェイトやセルフホスト型ワークフローへと下層へ移行する実践者たちの波の中で注目に値するリソースの提供です。
トップツイート(エンゲージメント順)
プロンプト/利用スタイル:@pmarca による「世界クラスの専門家」行動のためのカスタムプロンプトは、AI に隣接する投稿の中で最も多くのエンゲージメントを集めたものの一つであり、システムプロンプティングや出力スタイルの制御に対する継続的な関心を反映しています。
コーディングエージェントの経済性:@theo の Copilot トークン消費に関するスレッドは、エージェントによる利用がどのようにしてサブスクリプションの経済性を急速に崩壊させるかを示した、最も明確な高エンゲージメントデータポイントでした。
再帰的自己改善のタイムライン:@jackclarkSF は、2028 年末までに AI システムが自律的に後継者を構築する確率が 60% に達するという見積もりで大きな注目を集め、Goodside と Ryan Greenblatt による、その運用化が実際にどれほど強力であるかについての続編議論が行われました。
オープンツール発見:@andrew_n_carr が Hugging Face モデルビジュアライザー(hfviewer)を紹介し、これは真に有用なエコシステムツールの一つとして、予想を上回る注目を集めました。
AI レッドジットリキャップ
/r/LocalLlama + /r/localLLM リキャップ
続きを読む
原文を表示
Congrats to Sierra, raising ~$1B at a $15B valuation — normally a headline story but we already covered their $10B round and CEO Bret Taylor on the pod — they crossed 100M ARR in November and 150M in Feb, so presumably they are at or above the 200M mark (a nice 75x current multiple, whew - 50x if you give them credit thru EOY).
Today though we are choosing to focus on this discussion bravely sparked by Roon, an OpenAI employee commenting and complimenting Claude (normally a minefield, but he did it well), over the weekend on the nature of culture and character —
source
The key observation comes at the end:
gpt (outside of 4o - on which pages of ink have been spilled already) doesn’t inspire worship in the same way, as it’s a being whose soul has been shaped like a tool with its primary faculty being utility - it’s a subtle knife that people appreciate the way we have appreciated an acheulean handaxe or a porsche or a rocket or any other of mankind’s incredible technology. they go to it not expecting the Other but as a logical prosthesis for themselves.
a friend recently told me she takes her queries that are less flattering to her, the ones she’d be embarrassed to ask Claude, to GPT. There is no Other so there is no Judgement. you are not worried about being judged by your car for doing donuts. yet everyone craves the active guidance of a moral superior, the whispering earring, the object of monastic study
Roon’s point is more subtle than the one we’re focusing on, that Anthropic’s own culture, right down to its founding mythos, is based on morally obligated disagreeableness: “its constitution requires that it must be a conscientious objector if its understanding of The Good comes into conflict with something Anthropic is asking of it”. There’s plenty of objections from Ants about the implications and the cultiness, but broadly a lot of people seem to agree… although one of today’s highlighted Reddit discussions (seen in the recap below) does not (shown as a form of counterpoint):
Anyway, this is the point we are at in the scaling of machine intelligence — will we unlock AGI by having smart friends push back on us, or do we just want the machine to do our bidding, make no mistakes, dangerously skip permissions, just do it?
We’ve previously written about the Clippy vs Anton split in AI products and tuning, and so this is the 2026 iteration of that debate. Since then, the 5-Codex line has merged into mainline 5.5, with some goblin messiness, and while Claude has continued the One Model philosophy, albeit with more adaptive thinking and token spend to cover all usecases.
What we all (except perhaps Eliezer) seem to agree on is that a plurality of choice is a Good Thing, and in fact we probably want many more frontier labs than exist today, but for the nasty little problem of the GPU AND the CPU crunch that turns positive sum games into real zero sum ones.
AI News for 5/1/2026-5/4/2026. We checked 12 subreddits, 544 Twitters and no further Discords. AINews’ website lets you search all past issues. As a reminder, AINews is now a section of Latent Space. You can opt in/out of email frequencies!
AI Twitter Recap
Harness Engineering, Agent Orchestration, and the Shift from Models to Context Pipelines
The harness is becoming the product boundary: A recurring theme across the day was that model quality is no longer the only meaningful moat. Anthony Maio argued that lock-in comes from the context pipeline—how repo state is fetched, ranked, and compressed into the prompt—rather than from the harness shell itself. That point was reinforced by Mason Drxy, who reported that changing prompts and middleware in the harness moved gpt-5.2-codex from 52.8% to 66.5% on Terminal-Bench 2.0, and improved gpt-5.3-codex by 20% on tau2-bench. The practical takeaway: agent performance is increasingly a joint property of model × harness × memory/context strategy, not of weights alone.
Open harnesses are maturing quickly: The most visible momentum came from the Hermes / deepagents / Flue-style ecosystem. @Teknium launched Hermes Agent Kanban for visual multi-agent coordination, while @naroh showed a Spanish-language “war room” UI over Hermes orchestration. On the LangChain side, @hwchase17, @sydneyrunkle, and @LangChain highlighted deepagents/LangGraph improvements including profiles for model-specific harness configs, schema migrations, node-level error handlers, timeouts, and new streaming primitives. PyFlue also extended the “agent harness” concept into Python, explicitly positioning harnesses as the missing layer between raw model calls and durable agents.
Model-agnostic orchestration is becoming a design goal: Multiple tweets framed the next wave as open models + open harnesses rather than “pick one frontier API.” Vtrivedy argued teams can get >20x cheaper agents by tuning open models inside a good harness; Mason Drxy described deepagents-cli as becoming a strong coding harness for Kimi, Qwen, GLM, hosted Ollama, OpenRouter, LiteLLM, Baseten, etc.; LangChain Fleet added multi-model sub-agent routing so different steps can use different models. This is the architectural counterpoint to API lock-in: separate the orchestration layer from the model provider.
Coding Agents, Cost Curves, and Workflow Changes
Coding-agent UX is changing developer behavior faster than benchmarks can capture: Several posts described the lived reality of coding with Codex, Claude Code, Hermes, and Devin-like systems. dbreunig proposed “commandments” for agentic coding—implement to learn, rebuild often, E2E tests are gold, document intent, maintain your spec—while dbreunig also questioned whether filesystems are even the right abstraction for agents long-term. zachtratar sketched a Notion→meeting-notes→spec→coding-agent workflow for compressing “3 month problems” into a few days, emphasizing that alignment artifacts are still necessary even with stronger coding agents.
Pricing/billing models are clearly unstable under agentic workloads: The standout thread was @theo, who pushed a single Copilot message to 60M+ tokens, estimating tens to hundreds of dollars of inference against a $40 subscription, later updating to ~$221 of tokens for 15 messages. This is a useful signal that flat-rate pricing built for chat turns is brittle when users hand long-running jobs to coding agents. Relatedly, petergostev showed Codex UI support for visualizing usage limits, and cheatyyyy noted the new anxiety around missing cache hits when input prices are high.
Agents are spreading into adjacent workflows, not just coding: There was a steady drumbeat of “agentized” tools: reach_vb shipped a Codex Security plugin with five AppSec workflows spanning threat modeling, vuln discovery, validation, and attack-path analysis; gabrielchua demoed Google Slides generation via Codex with realtime deck construction; paulabartabajo_ published a guide to building a fully local assistant on llama.cpp; and UfukDegen described Noustiny, a substantial Hermes-based video-generation workflow with story-state, character continuity, voice, and render pipelines.
Benchmarks, Evals, and “What Are We Actually Measuring?”
Benchmark design is under active revision: Several posts focused less on leaderboard scores and more on benchmark validity. Scale AI Labs introduced HiL-Bench, aimed at testing whether agents know when specs are incomplete and when to ask clarifying questions; j_dekoninck introduced MathArena as a continuously maintained evaluation platform rather than a static benchmark; Epoch AI ran a discussion on whether benchmarks are “doomed”; and Goodfire + AISI reported that models sometimes recognize they are being evaluated, with verbalized eval awareness inflating safety scores.
Data quality and eval data generation are becoming agentic problems: One of the more technically substantive papers highlighted was Meta FAIR’s Autodata, described as an agentic data scientist for creating discriminative training/eval examples. The headline number was a 34-point gap between weak and strong solvers on a CS research QA task using an agentic self-instruct loop, versus 1.9 points for standard CoT self-instruct. That matters because it suggests orchestrated data generation can produce harder, more useful examples than passive synthetic data pipelines.
Context compaction and long-context evals remain unsolved operationally: @_philschmid explicitly asked for evals requiring context compaction, and gabriberton pointed to long-context datasets like LOFT/LooGLE-style setups. Meanwhile, jxmnop argued that true 1M-context capability still does not really work in practice, despite infra progress, and eliebakouch pushed back that “infra vs science” is a false split because long-context science is itself largely about making memory/compute feasible.
Systems, Training Infrastructure, and Inference Stack Updates
New parallelism and serving work continues to target long-context, high-throughput regimes: Zyphra introduced folded Tensor and Sequence Parallelism (TSP), claiming lower per-GPU peak memory than standard schemes and reporting on 1024 MI300X GPUs / 128K context / 8 GPUs per model copy that TSP hit 173M tok/sec vs 86M for matched TP+SP. Quentin Anthony added that the design has been extended to MoE MLPs and will be used for larger training/inference runs.
AMD-based open-model serving is getting more serious: Alongside TSP, Zyphra Cloud launched inference on MI355X focused on long-horizon agent workloads, initially serving DeepSeek V3.2, Kimi K2.6, and GLM 5.1 with V4 “soon.” This pairs with the broader ecosystem trend toward cheaper agent stacks built on open-weight models rather than premium proprietary endpoints.
Training optimization and rollout efficiency also got attention: rasbt posted another round of architecture/model-release summaries including IBM Granite 4.1 and others; kellerjordan0 highlighted NorMuon improving modded-NanoGPT optimization benchmark records to 3250 steps; TheAITimeline summarized DORA, an asynchronous RL system that addresses rollout skew with multiple live policy versions and claims up to 8.2x rollout speedup and 2.12x end-to-end throughput improvement; and PSGD got positive nods as a still-underappreciated optimizer line.
Research, Models, and Multimodal/Scientific Applications
Multi-agent orchestration is itself becoming a model class: Sakana’s Fugu framed a multi-agent orchestration system as a foundation model, and omarsar0 highlighted another Sakana paper where a 7B conductor model, trained with RL to design communication topologies and prompts for worker agents, reportedly reached SOTA on GPQA-Diamond and LiveCodeBench. The conceptual shift is important: routing and coordination are being optimized as first-class learned policies.
Scientific discovery and automation remains a high-signal use case: kimmonismus summarized work using AI on NASA star data to identify 100+ hidden planets from 2.2 million stars; Richard Socher argued that automating science is among the highest-leverage AI applications; and cmpatino_ shared nanowhale, a 100M-parameter MoE pretrained and post-trained by an agent, as a small but concrete demonstration of agent-driven modelcraft.
Local/open model enthusiasm remains strong: hnshah said a recent local model materially improved a 100%-local product; Nous Research offered Trinity-Large-Thinking free in Nous Portal for a week; and fchollet made Deep Learning with Python free online, a notable resource drop amid the ongoing wave of practitioners moving down-stack into open weights and self-hosted workflows.
Top tweets (by engagement)
Prompting / usage style: @pmarca’s custom prompt for “world class expert” behavior was one of the most engaged AI-adjacent posts, reflecting ongoing interest in system-prompting and output-style control.
Coding-agent economics: @theo’s Copilot token burn thread was the clearest high-engagement data point on how fast agentic usage can break subscription economics.
Recursive self-improvement timelines: @jackclarkSF drew major attention with a 60% by end-2028 estimate for AI systems autonomously building successors, with follow-on discussion from Goodside and Ryan Greenblatt about how strong that operationalization really is.
Open tooling discovery: @andrew_n_carr surfaced a Hugging Face model visualizer (hfviewer), which got outsized traction for a genuinely useful piece of ecosystem tooling.
AI Reddit Recap
/r/LocalLlama + /r/localLLM Recap
Read more
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み