Claudeの知能を活用する
AnthropicのClaudeブログは、Claudeの進化する知能に対応しながら遅延とコストをバランスさせるための3つのアプリケーション構築パターン(既知のツール活用、不要な処理の見直し、エージェントハーネスの境界設定)を紹介している。
キーポイント
Claudeの既知ツールを活用する
Claudeがよく理解するツール(bashやテキストエディタなど)を使用してアプリケーションを構築し、これらの汎用ツールを組み合わせて様々な問題を解決するパターンを形成する。
不要な処理を見直す
Claudeが自律的に実行できるようになったことで、エージェントハーネスが前提としていた制約を定期的にテストし、不要なコンテキスト処理を削減して遅延とコストを最適化する。
エージェントハーネスの境界を慎重に設定
Claudeの能力向上に伴い、エージェントハーネスが行うオーケストレーション判断をClaude自身に委ねることで、より効率的な処理が可能になる。
Claudeの進化的特性
生成AIシステムは構築されるよりも「育てられる」ものであり、研究者が成長条件を設定しても、出現する構造や能力は必ずしも予測可能ではない。
コード実行ツールによる自律的なツール連携
Claudeにコード実行ツールを与えることで、ツール呼び出しとその間のロジックをコードで表現し、コンテキストウィンドウに触れることなく結果をフィルタリング・パイプできるようになる。
スキルによる段階的なコンテキスト開示
YAMLフロントマターで概要を提供し、必要に応じてファイル読み取りツールで詳細を段階的に開示することで、Claudeがタスクに応じて自身のコンテキストを構築できる。
コンパクションによる長期的なコンテキスト管理
Claudeが過去のコンテキストを要約して長期間のタスクの連続性を維持し、Opus 4.6ではBrowseCompで84%の精度を達成した。
影響分析・編集コメントを表示
影響分析
この記事は、大規模言語モデルの実用応用における重要な課題(能力進化への対応、コスト最適化、効率的なツール設計)に焦点を当てており、AIエージェント開発の実践的な指針を提供している。特に、モデル能力の向上に伴うシステム設計の見直し必要性を強調することで、持続可能なAIアプリケーション開発の方向性を示している。
編集コメント
Claude開発元による実践的な技術記事で、AIエージェント開発の現場で直面する具体的な課題(コスト、遅延、能力進化への対応)に焦点を当てた貴重な内容。ただし、自社製品の宣伝色が若干見られる点に注意が必要。
アクションを専用ツールに昇格させる決定は、継続的に再評価されるべきです。例えば、Claude Codeの自動モード(公開時点では研究モード)は、bashツールの周囲にセキュリティ境界を提供します。具体的には、2つ目のClaudeインスタンスにコマンド文字列を読ませ、その安全性を判断させます。このパターンは専用ツールの必要性を抑えることができ、ユーザーが大まかな方向性を信頼できるタスクにのみ使用されるべきです。特定の高リスクアクションについては、専用ツールが依然として価値を発揮します。
今後の展望
Claudeの知能の最先端は常に変化しています。Claudeができないことについての前提は、その能力が向上するたびに再検証する必要があります。
私たちはこのパターンを繰り返し目にしています。長期的なタスクのために構築したエージェントでは、Sonnet 4.5はコンテキスト制限に近づいていると感知すると、早々に作業を終了してしまいました。この「コンテキスト不安」に対処するために、コンテキストウィンドウをクリアするリセット機能を追加しました。Opus 4.5では、この動作は見られなくなりました。私たちが補償のために構築したコンテキストリセットは、エージェントハーネスの中で不要なものとなってしまったのです。
このような不要な要素を取り除くことは重要です。なぜなら、それはClaudeのパフォーマンスのボトルネックになる可能性があるからです。時間の経過とともに、私たちのアプリケーションにおける構造や境界は、「何をやめられるか?」という問いに基づいて見直されるべきです。
ここで議論したすべてのツールとパターンを使用するには、私たちのclaude-apiスキルを確認してください。
謝辞
Claudeプラットフォームチームの技術スタッフメンバー、ランス・マーティンが執筆しました。取り上げたトピックについて有益な議論をしてくださったタリク・シーパー、バリー・チャン、マイク・ランバート、デビッド・ハーシー、およびダリアン・リーに特に感謝します。編集レビューとフィードバックを提供してくださったリディア・ハリー、レキシ・ロス、ケイトリン・レッセ、アンディ・シュマイスター、レベッカ・ヒスコット、ジェイク・イートン、ペドラム・ナビッド、およびモリー・ボーワックに感謝します。
PrevPrev0/5NextNexteBook
Claudeで構築するチームのための、より多くの製品ニュースとベストプラクティスを探求する。
AIエージェントの一般的なワークフローパターン――そしてそれらを使用するタイミング
エージェントAIエージェントの一般的なワークフローパターン――そしてそれらを使用するタイミングAIエージェントの一般的なワークフローパターン――そしてそれらを使用するタイミングAIエージェントの一般的なワークフローパターン――そしてそれらを使用するタイミングAIエージェントの一般的なワークフローパターン――そしてそれらを使用するタイミング  2026年2月24日金融向けのコワークとプラグイン
2026年2月24日金融向けのコワークとプラグイン
エンタープライズAI金融向けのコワークとプラグイン 金融向けのコワークとプラグイン 金融向けのコワークとプラグイン 金融向けのコワークとプラグイン  2026年2月24日エンタープライズ全体のチーム向けのコワークとプラグイン
2026年2月24日エンタープライズ全体のチーム向けのコワークとプラグイン
エージェントエンタープライズ全体のチーム向けのコワークとプラグインエンタープライズ全体のチーム向けのコワークとプラグインエンタープライズ全体のチーム向けのコワークとプラグインエンタープライズ全体のチーム向けのコワークとプラグイン  2026年1月23日マルチエージェントシステムの構築:それらを使用するタイミングと方法
2026年1月23日マルチエージェントシステムの構築:それらを使用するタイミングと方法
エージェントマルチエージェントシステムの構築:それらを使用するタイミングと方法マルチエージェントシステムの構築:それらを使用するタイミングと方法マルチエージェントシステムの構築:それらを使用するタイミングと方法マルチエージェントシステムの構築:それらを使用するタイミングと方法Claudeであなたの組織の運営方法を変革する
開発者向けニュースレターを入手する
製品アップデート、ハウツー、コミュニティスポットライトなど。毎月あなたの受信箱にお届けします。
購読する購読する月次の開発者向けニュースレターの配信をご希望の場合は、メールアドレスを入力してください。いつでも購読を解除できます。



原文を表示
Harnessing Claude’s intelligence
Building applications that balance intelligence, latency, and cost.
ProductClaude Platform
DateApril 2, 2026
Reading time5min
ShareCopy linkhttps://claude.com/blog/harnessing-claudes-intelligence
One of Anthropic’s co-founders, Chris Olah, says that generative AI systems like Claude are grown more than they are built. Researchers set the conditions to direct growth, but the exact structure or capabilities that emerge aren’t always predictable.
This creates a challenge for building with Claude: agent harnesses encode assumptions about what Claude can’t do on its own, but those assumptions grow stale as Claude gets more capable. Even lessons shared in articles like this deserve frequent revisiting.
In this article, we share three patterns that teams should use when building applications that keep pace with Claude’s evolving intelligence while balancing latency and cost: use what it already knows, ask what you can stop doing, and carefully set boundaries with the agent harness.
- Use what Claude knows
We suggest building applications using tools that Claude understands well.
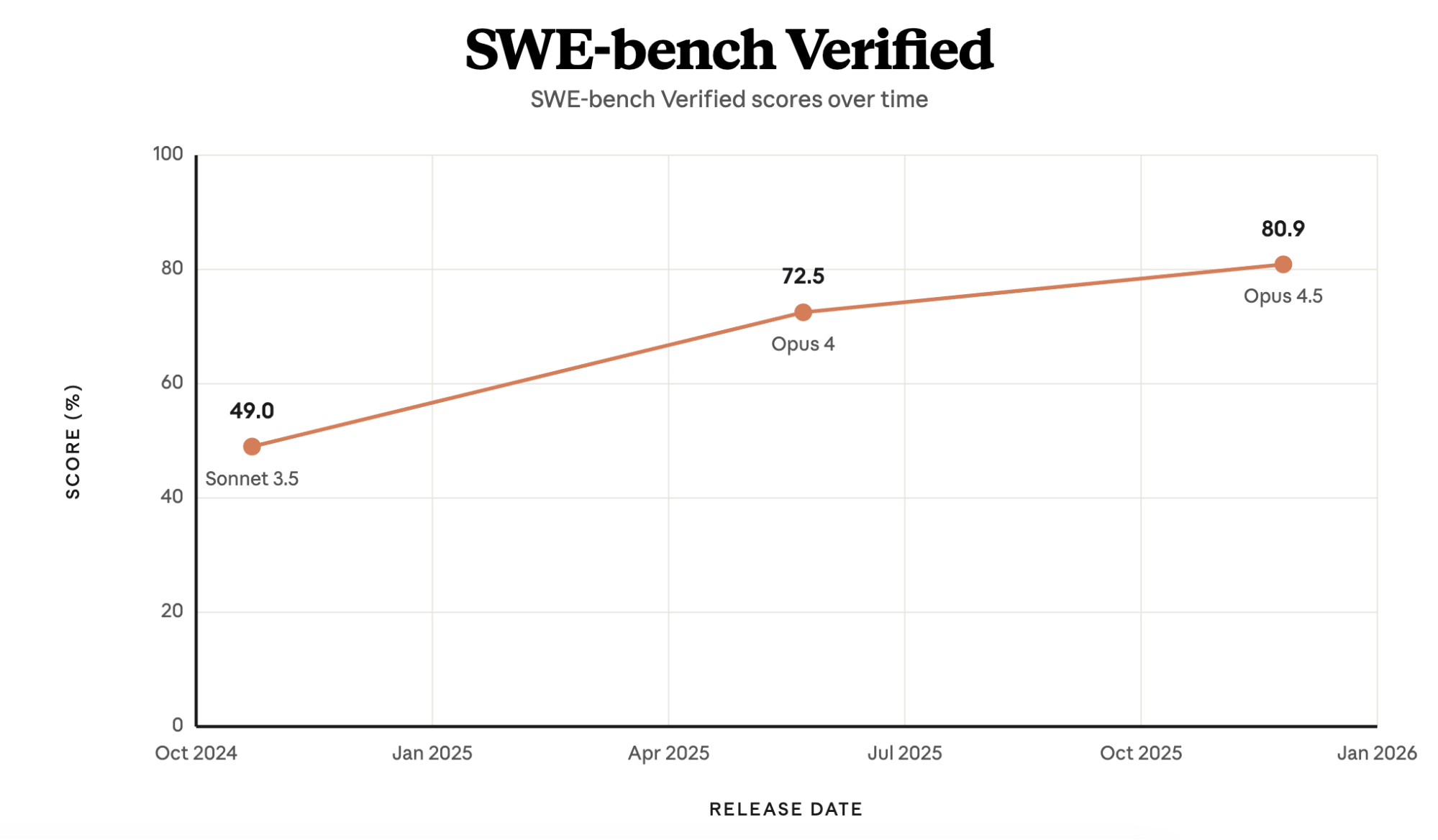
In late 2024, Claude 3.5 Sonnet reached 49% on SWE-bench Verified—then state of the art—with only a bash tool and a text editor tool for viewing, creating, and editing files. Claude Code is grounded in these same tools. Bash wasn’t designed for building agents, but it's a tool that Claude knows how to use and gets better at using over time.
Scores on the SWE-bench Verified benchmark across Claude model versions highlight its evolution.
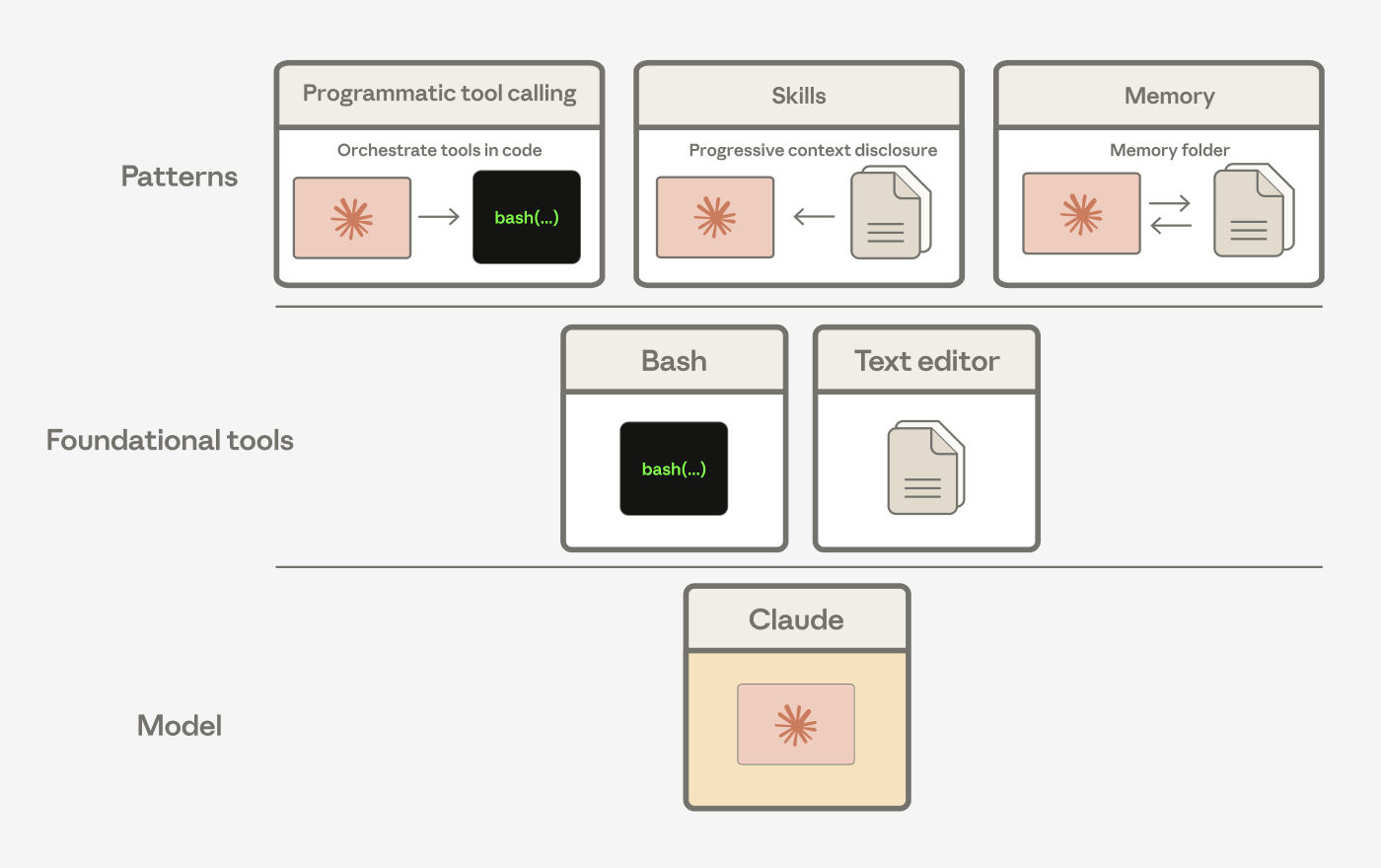
We've seen Claude compose these general tools into patterns that solve different problems. For instance, Agent Skills, programmatic tool calling, and the memory tool are all built from the bash and text editor tools.
Programmatic tool calling, skills, and memory are compositions of our bash and text editor tools.
- Ask ‘what can I stop doing?’
Agent harnesses encode assumptions about what Claude can’t do on its own. As Claude gets more capable, those assumptions should be tested.
Let Claude orchestrate its own actions
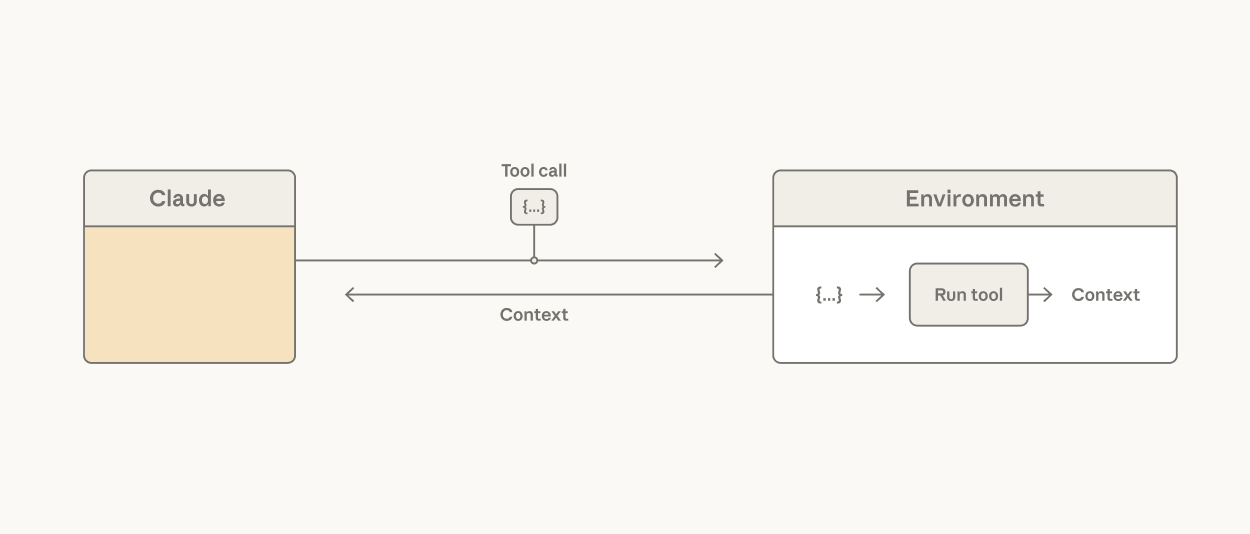
A common assumption is that every tool result should flow back through Claude’s context window to inform the next action. Processing tool results in tokens can be slow, costly, and unnecessary if it only needs to be passed to the next tool or if Claude only cares about a small slice of the output.
Claude calls tools, which are executed in an environment.
Consider reading a large table to reason about a single column: the whole table lands in context and Claude pays the token cost for every row it doesn't need. It’s possible to tackle this in tool design, using hard-coded filters. But this does not address the fact that the agent harness is making an orchestration decision that Claude is better positioned to make.
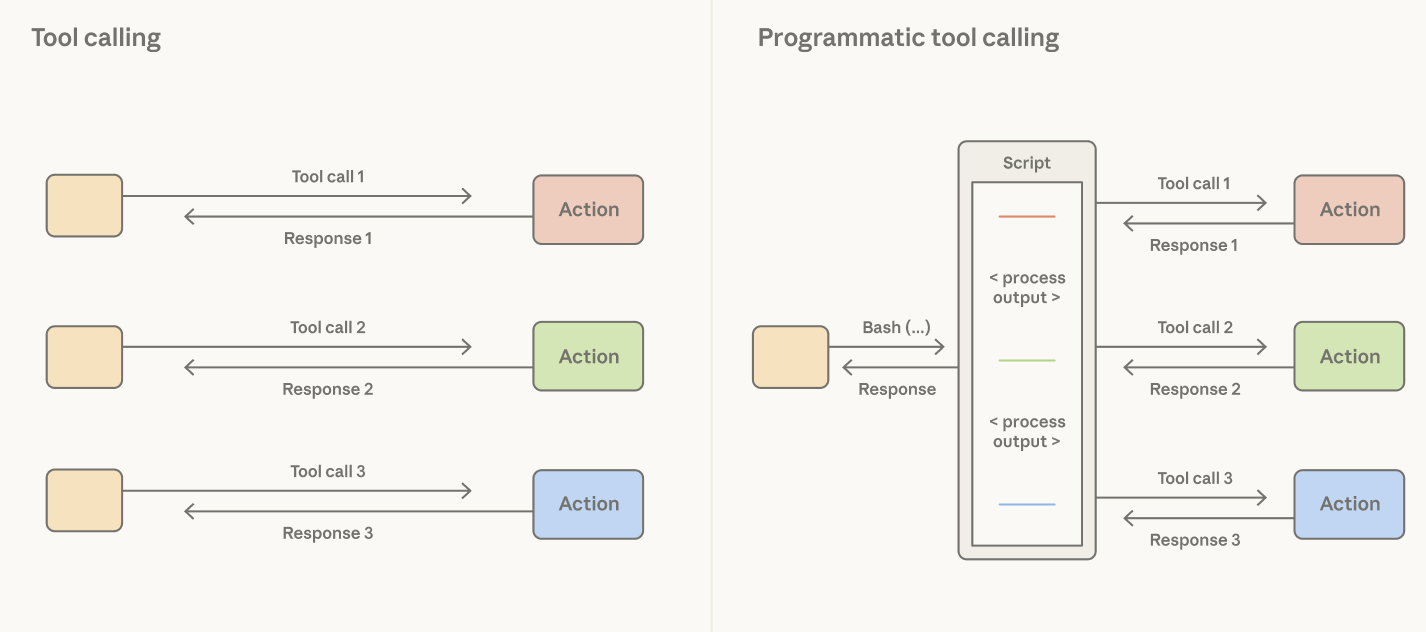
Giving Claude a code execution tool (e.g., bash tool or language-specific REPL) addresses this: it allows Claude to write code to express tool calls and the logic between them. Rather than the harness deciding that every tool call result is processed as tokens, Claude decides what results to pass through, filter, or pipe into the next call without touching the context window. Only the output of code execution reaches Claude’s context window.
Claude can write code that expresses tool calls and the logic between them.
The orchestration decision moves from the harness to the model. Since code is a general way for Claude to orchestrate actions, a strong coding model is also a strong general agent. Claude shows strong performance on non-coding evals using this pattern: on BrowseComp, a benchmark that tests the ability of agents to browse the web, giving Opus 4.6 the ability to filter its own tool outputs brought accuracy from 45.3% to 61.6%.
Let Claude manage its own context
Task-specific context steers Claude’s use of general tools like bash and the text editor tool. A common assumption is that system prompts should be hand-crafted with task-specific instructions. The problem is that pre-loading prompts with instructions does not scale across many tasks: every token added depletes Claude’s attention budget and it is wasteful to pre-load context with rarely used instructions.
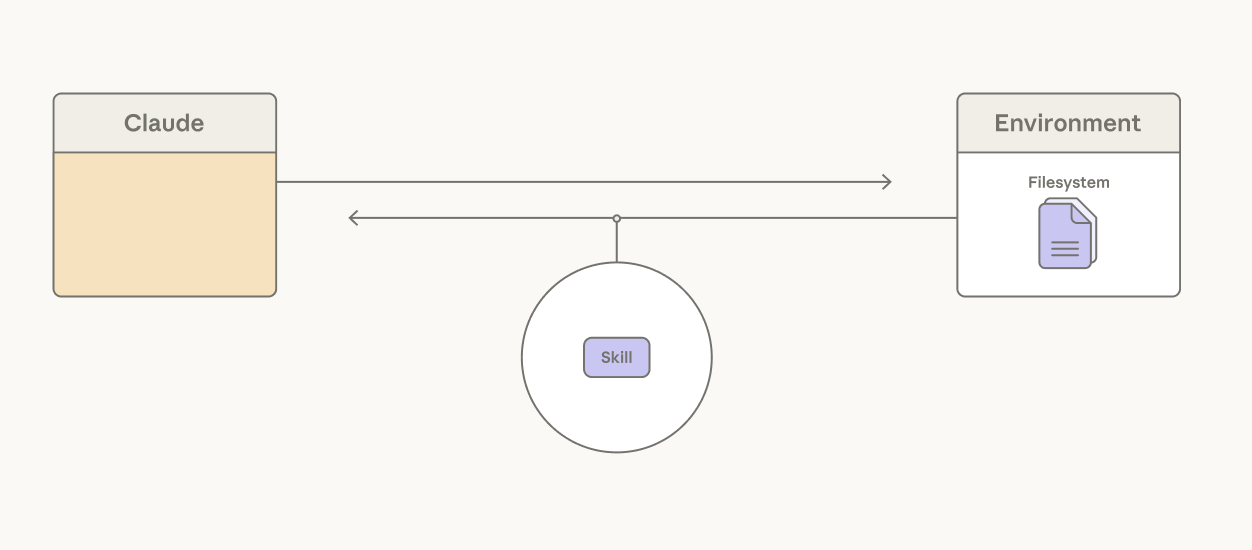
Giving Claude the ability to access skills addresses this: the YAML frontmatter of each skill is a short description pre-loaded into the context window, providing an overview of the skill contents. The full skill can be progressively disclosed by Claude calling a read file tool if a task calls for it.
Claude can use skills to progressively disclose task-relevant context.
While skills give Claude the freedom to assemble its own context window, context editing is the inverse, providing a way to selectively remove context that’s become stale or irrelevant, such as old tool results or thinking blocks.
With subagents, Claude is getting better at knowing when to fork into a fresh context window to isolate work on a specific task. With Opus 4.6, the ability to spawn subagents improved results on BrowseComp by 2.8% over the best single-agent runs.
Let Claude persist its own context
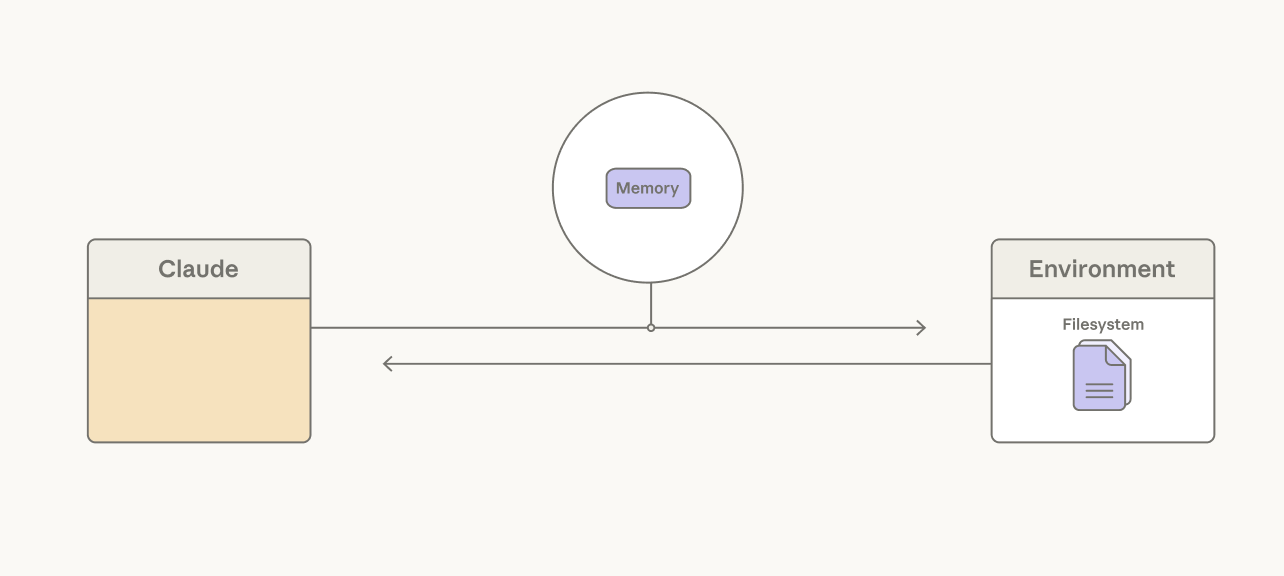
Long-running agents can exceed the limit of a single context window. A common assumption is that memory systems should rely on retrieval infrastructure around the model. Much of our work has focused on giving Claude simple ways to choose for itself what content to persist.
For example, compaction lets Claude summarize its past context in order to maintain continuity on long-horizon tasks. Over several releases, Claude has gotten better at choosing what to remember. On BrowseComp, for example, an agentic search task, Sonnet 4.5 stayed flat at 43% regardless of the compaction budget we gave it. Yet Opus 4.5 scaled to 68% and Opus 4.6 reached 84% with the same setup.
A memory folder is another approach, allowing Claude to write context to files and later read them as needed. We’ve seen Claude use this for agentic search. On BrowseComp-Plus, giving Sonnet 4.5 a memory folder lifted accuracy from 60.4% to 67.2%.
Claude can persist context to a memory folder.
Long-horizon games, such as Pokémon, are an example of Claude’s improved ability to use a memory folder. Sonnet 3.5 treated memory as a transcript, writing down what non-player characters (NPCs) said rather than what mattered. After 14,000 steps it had 31 files—including two near-duplicates about caterpillar Pokémon—and was still in the second town:
caterpie_weedle_info: - Caterpie and Weedle are both caterpillar Pokémon. - Caterpie is a caterpillar Pokémon that does not have poison. - Weedle is a caterpillar Pokémon that does have poison. - This information is crucial for future encounters and battles. - If our Pokémon get poisoned, we should seek healing at a Pokémon Center as soon as possible.
Later models wrote tactical notes. Opus 4.6, at the same step count, had 10 files organized into directories, three gym badges, and a learnings file distilled from its own failures:
/gameplay/learnings.md: - Bellsprout Sleep+Wrap combo: KO FAST with BITE before Sleep Powder lands. Don't let it set up! - Gen 1 Bag Limit: 20 items max. Toss unneeded TMs before dungeons. - Spin tile mazes: Different entry y-positions lead to DIFFERENT destinations. Try ALL entries and chain through multiple pockets. - B1F y=16 wall CONFIRMED SOLID at ALL x=9-28 (step 14557)
- Set boundaries carefully
Agent harnesses provide structure around Claude to enforce UX, cost, or security.
Design context to maximize cache hits
The Messages API is stateless. Claude cannot see the conversation history of prior turns. This means that the agent harness needs to package new context alongside all past actions, tool descriptions, and instructions for Claude at each turn.
Prompts can be cached based on set breakpoints. In other words, the Claude API writes context up until a breakpoint to the cache and checks whether the context matches any prior cache entries.
Since cached tokens are 10% the cost of base input tokens, here are a few principles in the agent harness help maximize cache hits:
Static first, dynamic last
Order requests so that stable content (system prompt, tools) come first.
Messages for updates
Append a <system-reminder>
Don't change models
Avoid switching models during a session. Caches are model-specific; switching breaks them. If you need a cheaper model, use a subagent.
Carefully manage tools
Tools sit in the cached prefix. Adding or removing one invalidates it. For dynamic discovery, use tool search, which appends without breaking cache.
Update breakpoints
For multi-turn applications (e.g., agents), move the breakpoint to the latest message in order to keep the cache up-to-date. Use auto-caching for this.
Use declarative tools for UX, observability, or security boundaries
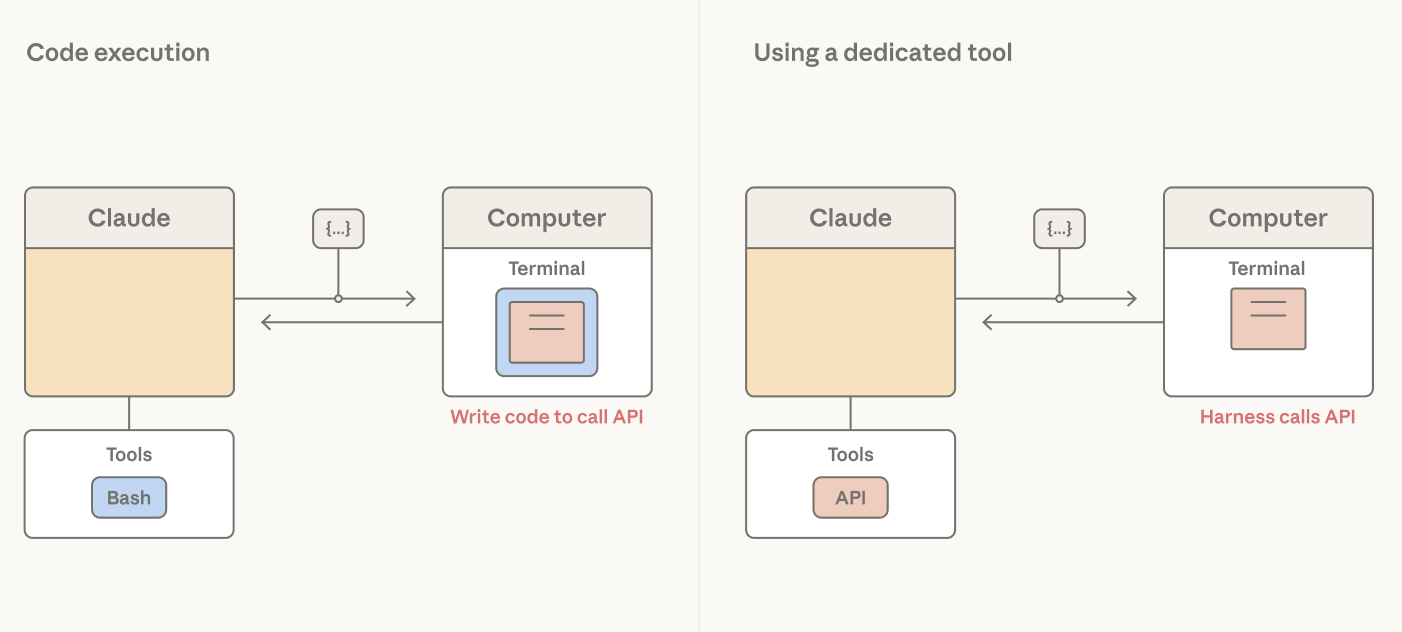
Claude doesn't necessarily know an application's security boundary or UX surface. Claude emits tool calls, which are handled by the harness. A bash tool gives Claude broad programmatic leverage to perform actions, but it gives the harness only a command string—the same shape for every action. Promoting actions to dedicated tools gives the harness an action-specific hook with typed arguments it can intercept, gate, render, or audit.
Actions that require a security boundary are natural candidates for dedicated tools. Reversibility is often a good criterion, and hard-to-reverse actions such as external API calls can be gated by user confirmation. Write tools like edit
Dedicated tools can be used for actions based upon security, UX, or observability considerations.
Tools are also useful when an action needs to be presented to a user. For example, they can be rendered as a modal to display a question clearly to the user, give the user multiple options, or block the agent loop until a user provides feedback.
Finally, tools are useful for observability. When the action is a typed tool, the harness gets structured arguments it can log, trace, and replay.
The decision to promote actions to tools should be continually re-evaluated. For example, Claude Code's auto-mode (in research mode at the time of publication) provides a security boundary around the bash tool: it has a second Claude read the command string and judge whether it's safe. This pattern can limit the need for dedicated tools, and should only be used for tasks where users trust the general direction. Dedicated tools can still earn their place for certain high-stakes actions.
Looking forward
The frontier of Claude’s intelligence is always changing. Assumptions about what Claude can’t do need to be re-tested with each step change in its capability.
We see this pattern repeat itself. In an agent we built for long-horizon tasks, Sonnet 4.5 would wrap up prematurely as it sensed the context limit approaching. We added resets to clear the context window in order to address this "context anxiety." With Opus 4.5, the behavior was gone. The context resets we built to compensate had become dead weight in the agent harness.
Removing this dead weight is important because it can bottleneck Claude’s performance. Over time, the structure or boundaries in our applications should be pruned based the question: what can I stop doing?
To use all tools and patterns discussed here, check out our claude-api skill.
Acknowledgements
Written by Lance Martin, member of technical staff on the Claude Platform team. Special thanks to Thariq Shihipar, Barry Zhang, Mike Lambert, David Hershey, and Daliang Li for helpful discussion on the topics covered. Thanks to Lydia Hallie, Lexi Ross, Katelyn Lesse, Andy Schumeister, Rebecca Hiscott, Jake Eaton, Pedram Navid, and Molly Vorwerck for their editorial review and feedback.
PrevPrev0/5NextNexteBook
Explore more product news and best practices for teams building with Claude.
Common workflow patterns for AI agents—and when to use them
AgentsCommon workflow patterns for AI agents—and when to use themCommon workflow patterns for AI agents—and when to use themCommon workflow patterns for AI agents—and when to use themCommon workflow patterns for AI agents—and when to use them Feb 24, 2026Cowork and plugins for finance
Enterprise AICowork and plugins for finance Cowork and plugins for finance Cowork and plugins for finance Cowork and plugins for finance Feb 24, 2026Cowork and plugins for teams across the enterprise
AgentsCowork and plugins for teams across the enterpriseCowork and plugins for teams across the enterpriseCowork and plugins for teams across the enterpriseCowork and plugins for teams across the enterprise Jan 23, 2026Building multi-agent systems: When and how to use them
AgentsBuilding multi-agent systems: When and how to use themBuilding multi-agent systems: When and how to use themBuilding multi-agent systems: When and how to use themBuilding multi-agent systems: When and how to use themTransform how your organization operates with Claude
Get the developer newsletter
Product updates, how-tos, community spotlights, and more. Delivered monthly to your inbox.
SubscribeSubscribePlease provide your email address if you'd like to receive our monthly developer newsletter. You can unsubscribe at any time.
関連記事
2026年3月6日 Frontier Red TeamによるClaudeのCVE-2026-2796エクスプロイトのリバースエンジニアリング
Frontier Red Teamが、Claudeの脆弱性CVE-2026-2796を悪用するエクスプロイトをリバースエンジニアリングした。
フロンティア・レッドチーム、Firefoxのセキュリティ向上のためにMozillaと提携
フロンティア・レッドチームは、Firefoxのセキュリティを向上させるため、Mozillaと提携した。
59%のユーザーがより安価なモデルを選択:Sonnet 4.6の詳細解説
Anthropic社がClaude Sonnet 4.6をリリースし、Claude Codeテストで70%のユーザーが前世代モデルより好み、59%がフラッグシップモデルOpus 4.5よりも選択した。コーディング、コンピュータ利用、100万トークンコンテキストなど6次元で全面アップグレードされ、価格は据え置き。