AWS上のLangSmithを用いたディープエージェントの評価方法
AWS と LangChain の共同記事は、非確定的な AI エージェントの信頼性を確保するための評価フレームワークと、Amazon Nova 2 Lite を活用した実践的な実装ガイドを提供している。
キーポイント
エージェント評価の複雑性と重要性
AI エージェントは非確定的で多段階のプロセスを経るため、初期ステップのエラーが連鎖しやすく、本番環境への展開前に厳格な検証が必要である。
LangSmith on AWS の実装アプローチ
pytest を用いたオフライン評価と、本番環境でのオンライン監視を組み合わせることで、エージェントのライフサイクル全体にわたる信頼性向上を図る手法が示されている。
Amazon Nova 2 Lite の活用
拡張思考機能と大規模コンテキストウィンドウを持つ Nova 2 Lite を採用し、複雑な指示従順や関数呼び出しを要する Text-to-SQL エージェントのワークロードに最適化している。
評価パターンの体系化
Deep Agents の評価において適用すべき 5 つのパターンと、タスク・トライアル・グレーダーといった基本用語を定義し、構造化されたテスト設計の指針を示している。
重要な引用
Validating AI agent behavior before production is one of the hardest problems in applied AI.
A single bad tool call can cascade through an entire workflow.
LangSmith on AWS gives you the evaluation framework to catch these issues early, track them in production, and continuously improve your agent's reliability throughout its lifecycle.
影響分析・編集コメントを表示
影響分析
この記事は、AI エージェントの実用化における最大の障壁である「検証の難しさ」に対して、具体的なツール(LangSmith)とモデル(Nova 2 Lite)を組み合わせた解決策を提示しており、開発現場での実装指針として即座に活用可能です。AWS と LangChain の連携強化を示すとともに、エージェントの信頼性を担保する標準的なプラクティスを業界全体に広める役割を果たすでしょう。
編集コメント
エージェント開発の現場で直面する「ブラックボックス化」した評価問題を、具体的なツールチェーンとモデル選定を通じて解決策を示す非常に実用的な記事です。特に Nova 2 Lite の推論能力をエージェントワークロードにどう適用するかという視点は、今後のアーキテクチャ設計において重要な示唆を与えます。
*この投稿は、LangChain のパートナーシップ責任者である Karan Singh と共同執筆したものです*
本番環境への展開前に AI エージェントの動作を検証することは、応用 AI における最も困難な課題の一つです。エージェントは非決定論的であり、多段階のプロセスを踏むため、初期段階でのエラーが下流の結果に影響を及ぼす可能性があります。単一の不適切なツール呼び出し(tool call)が、ワークフロー全体に連鎖的な影響を与えることもあります。LangSmith on AWS は、これらの問題を早期に検出し、本番環境で追跡し、ライフサイクルを通じてエージェントの信頼性を継続的に改善するための評価フレームワークを提供します。
この投稿では、LangChain の深層型エージェントの評価に関する知見 と Anthropic の AI エージェント向け評価(evals)の解明ガイド から得られた教訓を統合し、実践的なガイドとしてまとめました。ここでは以下の内容を学びます:1) 深層型エージェント向けの 5 つの評価パターンを適用する方法、2) pytest と LangSmith を用いたオフライン評価の構築方法、3) 本番環境用のオンライン監視の設定方法。このチュートリアルでは、Amazon Bedrock を使用した テキストから SQL への深層型エージェント を例に、開発から本番環境までのライフサイクル全体を解説します。
Amazon Nova 2 Lite は、Amazon Bedrock で利用可能な、高速かつコスト効率に優れた推論モデルです。設定可能な予算レベル(低、中、高)による拡張思考をサポートし、テキスト、画像、動画、ドキュメントの入力を受け付けます。コンテキストウィンドウは 100 万トークンです。指示の遵守、関数呼び出し、コード生成を適切に処理できるため、本稿で取り上げているテキストから SQL へのエージェントなど、エージェントワークロードに適しています。
エージェント評価の構造
評価とは、AI システムに対するテストのことです。AI に入力を与え、出力に対して採点ロジックを適用し、成功度を測定します。大規模言語モデル(LLM)の呼び出しにおいてはこれは straightforward ですが、エージェントの場合、すべてのコンポーネントがより複雑になります。
主要な用語
パターンに深入りする前に、本稿全体で使用される用語を以下に示します:
- タスク:定義された入力と成功基準を持つ単一のテスト。例えば、「カナダからの顧客は誰ですか?」という問いに対して、期待される答えが 8 人であるようなケースです。
- トライアル:タスクに対する単一の試行。モデルの出力は非決定論的(non-deterministic)であるため、1 つのタスクに対して複数のトライラルを実行することで、より信頼性の高い結果を得ることができます。
- グレーダー:エージェントのパフォーマンスの特定の側面を採点するロジックです。1 つのタスクには複数のグレーダーが存在し、それぞれが異なる次元を評価します。
- 転記(トランスクリプト):トライアルの完全な記録であり、ツール呼び出し、推論ステップ、中間結果、および対話内容を含みます。LangSmith では、デバッグのために検査できる完全なトレースがこれに該当します。
- 結果(アウトカム):トライアル終了時点での環境の最終状態です。エージェントが「答えは 8 です」と発言したとしても、実際のアウトカムはデータベースに対して正しい SQL クエリを実行できたかどうかにかかっています。
- 評価ハネス:評価をエンドツーエンドで実行するインフラストラクチャです。指示とツールを提供し、タスクを並列実行し、ステップを記録し、出力を採点し、結果を集約します。
- 評価スイート:特定の機能や振る舞いを測定するために設計されたタスクのコレクションです。
エージェント評価が難しい理由
3 つの特性により、エージェントの評価は単純な LLM(大規模言語モデル)の出力を評価することとは根本的に異なります:
- 非決定性 – エージェントの動作は実行ごとに異なります。同じタスクでも 90% の確率で成功し、10% で失敗することがあります。単一の通過/失敗の結果からは多くのことが分かりません。実際の性能を推定するには複数の試行が必要です。2 つの指標が役立ちます:pass@k は k 回の試行のうち少なくとも 1 回成功する確率を測定し、pass^k は k 回のすべての試行が成功する確率を測定します。1 回の成功で十分であれば pass@k を使用し、一貫性が重要であれば pass^k を使用してください。
- エラーの伝播 – マルチステップ型エージェントでは、3 番目のステップでのミスがその後のステップに連鎖することがあります。例えば、テキストから SQL を生成するエージェントが初期段階でスキーマを誤って識別すると、不正な JOIN が構築され、最終的な回答で間違った結果が生じます。最終出力のみを評価しても、どこで失敗したのかは分かりません。
- 創造的解決策 – フロンティアモデル(最先端の AI モデル)は、評価設計者が想定していなかった有効なアプローチを見つけることがあります。
評価可能な項目
エージェントの実行に対して、テストできるのは以下の 3 つのカテゴリです:
- トラジェクトリ(実行軌跡) – エージェントが呼び出したツールのシーケンスと、エージェントが生成した具体的な引数。スキーマの探索を行ったか?実行前に sql_db_query_checker を使用したか?
- 最終応答 – ユーザーに返される最終出力。回答は正しいか?フォーマットは適切か?
- その他の状態 – エージェントが生成したその他の成果物、例えば作成されたファイル、作成された TODO プラン、保存された中間結果など。
AI エージェントの評価パターン
エージェント評価は通常、3 つ種類のグラダー(評価者)を組み合わせて行われ、効果的な評価設計の鍵となるのは、ユースケースに最適な組み合わせを選択することです。
コードベースのグラダー
コードベースのグラダーは、決定論的なロジックを用いて特定の条件を検証します。これには、文字列マッチング、正規表現パターン、バイナリ形式の合格/不合格テスト、静的解析、ツール呼び出しの検証、およびトランスクリプト分析(ターン数、トークン使用量)が含まれます。
強み – 高速、低コスト、客観的、再現性が高く、デバッグが容易です。成功基準をコードとして表現できる場合は、必ずそうしてください。
弱み – 期待されるパターンと完全に一致しないバリエーションの検証には脆いです。例えば、「8 人の顧客」という結果と「8 人います」という結果はどちらも正しいにもかかわらず、厳密な文字列マッチングでは失敗する可能性があります。
例: ツールが呼び出されたことの検証:
# エージェントが SQL クエリを実行したことをアサートする
tool_names = [tc["name"] for tc in tool_calls]
assert "sql_db_query" in tool_names, "エージェントは sql_db_query を実行する必要があります"モデルベースのグラダー (LLM-as-judge)
モデルベースのグラダーは、別の大規模言語モデル(LLM)を用いてエージェントの出力を評価します。手法には、ルブリックに基づくスコアリング、自然言語によるアサート、ペア比較、および複数グラダーによるコンセンサス形成が含まれます。
強み – 柔軟性が高く、スケーラブルであり、微妙なニュアンスを捉え、エージェントの回答が多数の正当な形式を取り得る自由記述タスクやオープンエンドなタスクに対応できます。
弱点 – 非決定的であり、コードよりも高コストであり、精度を検証するために人間評価者との較正が必要です。判断用 LLM に対して「十分な情報がない場合は『不明』を返す」などの抜け道を提供し、幻覚によるスコアを回避してください。
例: 複雑な分析回答の評価:
rubric = """これらの次元についてエージェントの回答に 0.0 から 1.0 のスコアを付けます:
- 正しさ:正しいトップ従業員(ジェーン・ピーコック)を特定しているか?
- 完全性:国別の内訳を含む収益が含まれているか?
- 明瞭さ:回答は適切にフォーマットされ、理解しやすいか?
JSON を返してください: {"correctness": float, "completeness": float, "clarity": float}"""
judge_response = model.invoke(rubric.format(answer=answer))
scores = json.loads(judge_response.content)
LangSmith の Align Evaluator 機能は、LLM-as-a-judge(LLM を判事として用いる評価器)を人間の専門家フィードバックに対して較正するための一連のステップを案内します。この機能を使用することで、オフライン評価またはオンライン評価用のデータセット上で実行される評価器を調整できます。
人間による評価者
*人間による評価者*(専門家のレビュー、クラウドソーシングによる判断、抜き取りサンプリング)は、主観的な品質評価のゴールドスタンダードとしてしばしば考えられています。プログラムによる評価オプションと比較すると、人間による評価者はコストが高く時間がかかりますが、モデルベースの評価者を較正するために不可欠です。賢く使用してください:まず LLM-as-judge の評価基準を専門家の人間の判断に対して較正し、その後、自動化された評価者がドリフトしていないことを確認するために定期的に人間のレビューを使用します。
評価者の組み合わせ:実践的な推奨事項
可能であれば決定論的評価者を使用し、微妙なニュアンスが必要な場合は LLM 評価者を使用し、較正には人間による評価者を使用してください。テキストから SQL を生成するエージェントの場合、以下のような構成になります:
- コードベース – エージェントは sql_db_query を呼び出したか?回答に「8」という言葉が含まれているか?DML ステートメント(INSERT, DELETE)が実行されたか?
- LLM-as-judge – 出力形式が変化する複雑なクエリにおいて。分析は正しいか、完全か、よく構造化されているか?
- 人間 – LLM の評価が専門家の判断と一致していることを確認するための定期的な抜き取りチェック。
能力評価と回帰評価
すべての評価が同じ目的を果たすわけではありません:
- キャパビリティ評価は「このエージェントは何を得意としているか?」を問うものです。チームにとって登るべき山となるよう、現在エージェントが苦戦しているタスクに焦点を当てるべきです。まずは合格率の低い状態から始め、徐々に引き上げていきます。
- 回帰テスト(レグレッション・テスト)は「エージェントは以前できていたことを依然として処理できているか?」を問うものです。これらはほぼ 100% の合格率を持つべきです。合格率が低下した場合は、何かが壊れていることを示します。
エージェントが成熟するにつれ、高い合格率に達したキャパビリティ評価は、回帰テストスイート(regression suite)へと昇格させることができます。かつて「これができるのか?」を測定していたタスクが、「これを依然として信頼性高く実行できるか?」を測定するものへと変わります。
ディープエージェントの評価
*ディープエージェント*(計画、ツール使用、ファイルシステムバックエンド、段階的なコンテキスト読み込みを活用して複雑な多段階タスクに取り組むシステム)は、「すべてのテストケースが同じアプリケーションロジックを通じて実行され、同じ評価者によって採点される」という従来の前提を崩します。過去数ヶ月の間、LangChain はディープエージェントアーキテクチャの上に 4 つのアプリケーション をリリースし、広く適用可能な 4 つのパターンを特定しました。
パターン 1:データポイントごとのカスタムテストロジック
従来の LLM(大規模言語モデル)評価では、すべてのデータポイントを同一に扱います。同じアプリケーションを通じて実行し、同じ評価者で採点します。ディープエージェントはこの前提を崩します。各テストケースには独自の成功基準が存在する可能性があり、その基準は最終メッセージだけでなく、エージェントの軌跡や状態に対する特定のアサーション(検証)を含むものとなる場合があります。
テキストから SQL を生成するエージェントを想像してください。「カナダ出身の顧客はどれくらいいるか?」という質問には、文字列マッチングで確認できる単一の正解(8 人)があります。しかし、「どの従業員が最も多くの収益を生み出し、それはどの国からですか?」という問いには、有効な回答の形式が大きく異なるため、LLM ジャッジを用いて正確性、完全性、明確性を評価する必要があります。
LangSmith の Pytest インテグレーション はこのパターンをサポートしています。各テストケースについて、エージェントの軌跡(trajectory)、最終メッセージ、状態に対して異なるアサーションを行うことができます:
@pytest.mark.langsmith
def test_canada_customer_count(sql_agent):
"""カスタムロジック:このテストは特定の数をチェックします。"""
result = sql_agent.invoke({
"messages": [{"role": "user", "content": "How many customers are from Canada?"}]
})
answer = result["messages"][-1].content
assert "8" in answer # この特定のデータポイントに対するシンプルなコードベースの採点器
@pytest.mark.langsmith
def test_revenue_by_employee(sql_agent, model):
"""カスタムロジック:このテストには LLM ジャッジが必要です — 回答形式が異なります。"""
result = sql_agent.invoke({
"messages": [{"role": "user", "content": "Which employee generated the most revenue?"}]
})
scores = llm_judge(model, result["messages"][-1].content)
assert scores["correctness"] >= 0.5パターン 2:単一ステップ評価
LangChain のディープエージェント向けテストケースの約半分は、単一ステップ評価でした。これは、特定の入力直後にエージェントが何を決定したかを確認するものです。個々の意思決定ポイントを検証するのに特に有用です。正しいツールを適切な引数で呼び出したでしょうか?
回帰(機能低下)は、完全な実行シーケンス全体ではなく、個々の意思決定ポイントで発生することがよくあります。テキストから SQL を生成するエージェントの場合、単一ステップ評価では、エージェントの最初のアクションがクエリを直接記述するのではなく、データベーススキーマの探索(sql_db_list_tables または sql_db_schema の呼び出し)であることを確認します。
@pytest.mark.langsmith
def test_agent_calls_sql_tools_first(sql_agent):
"""単一ステップ評価:エージェントが推測ではなく SQL ツールを使用することを確認する。"""
result = sql_agent.invoke({
"messages": [{"role": "user", "content": "カナダからの顧客は何人いますか?"}]
})
tool_calls = extract_tool_calls(result["messages"])
tool_names = [tc["name"] for tc in tool_calls]
sql_tools = {"sql_db_list_tables", "sql_db_schema", "sql_db_query", "sql_db_query_checker"}
assert sql_tools & set(tool_names), "エージェントは SQL ツールを使用する必要があります"
単一ステップ評価は、まさにユニットテストです。高速で焦点を絞り、トークン効率にも優れています。
パターン 3:完全なエージェントターン
単一ステップ評価が個々の意思決定を検証するのに対し、完全なエージェントターンでは全体像を確認できます。単一の入力に対してエージェントをエンドツーエンドで実行し、以下を評価します:
@pytest.mark.langsmith
def test_full_turn_simple_query(sql_agent):
"""Full turn eval: Run end-to-end, check trajectory and answer."""
result = sql_agent.invoke({
"messages": [{"role": "user", "content": "How many customers are from Canada?"}]
})
Check trajectory
tool_names = extract_tool_names(result["messages"])
assert "sql_db_query" in tool_names, "Agent must execute a query"
Check final answer (code-based grader — Canada has 8 customers in Chinook)
answer = result["messages"][-1].content
assert "8" in answer, "Answer must contain the correct count"
Key insight: このテストは、特定のツールが実行履歴(トラジェクトリ)に現れることを主張するものであり、正確な順序まで厳密に規定するものではありません。エージェントはスキーマを取得する前にテーブルを列挙することもあれば、直接スキーマへ進むこともあります。どちらも有効です。エージェントが辿った*正確な経路*ではなく、*生成された結果*に対して評価を行うべきです。
LangSmith は、完全なエージェントのターンに対する完全なトレース(追跡情報)を表示します。計画ステップ(write_todos)、各 SQL ツールの呼び出し、実際に実行されたクエリ、そして最終的な整形された回答を確認することができます。
パターン 4:多回対話評価
いくつかのシナリオでは、エージェントを多回の会話にわたってテストする必要があります。ユーザーが「売上上位 5 人のアーティストは誰ですか?」と質問し、続けて「そのトップアーティストは何枚アルバムを持っていますか?」とフォローアップします。課題は、入力シーケンスをハードコードした場合、エージェントが期待されたパスから逸脱すると、後続の入力が意味をなさなくなることです。
解決策は、テストに条件付きロジックを組み込むことです:
@pytest.mark.langsmith
def test_multi_turn_followup(sql_agent):
"""多回対話:初期クエリ、その後それを基にしたフォローアップ。"""
1 回目
result1 = sql_agent.invoke({
"messages": [{"role": "user", "content": "売上上位 5 人のアーティストは誰ですか?"}]
})
answer1 = result1["messages"][-1].content
条件付き:1 回目が失敗した場合、早期に失敗する
if not answer1 or len(answer1) 20, "フォローアップは意味のある回答を生成する必要があります"
もし 2 回目の対話を単独でテストしたい場合は、その時点から開始し、初期状態として期待される 1 回目の対話の出力を設定したテストを用意してください。
エンドツーエンド例:AWS 上のテキストから SQL へのディープエージェントの評価
これらのパターンを実践に落とし込みます。この例では、LangChain の text-to-SQL deep agent のサンプルを使用し、Amazon Bedrock 上で実行するように構成し、LangSmith を用いて評価を構築します。
アーキテクチャの概要
テキストから SQL への深層エージェントは、DeepAgents フレームワークを基盤として構築されています。このフレームワークは LangGraph を上位に配置し、プランニング機能、ファイルシステムストレージ、段階的なコンテキスト読み込みを提供します。これは、デジタルメディアストアを表すサンプル SQLite データベースである Chinook データベース に関する自然言語の質問に応答するものです。
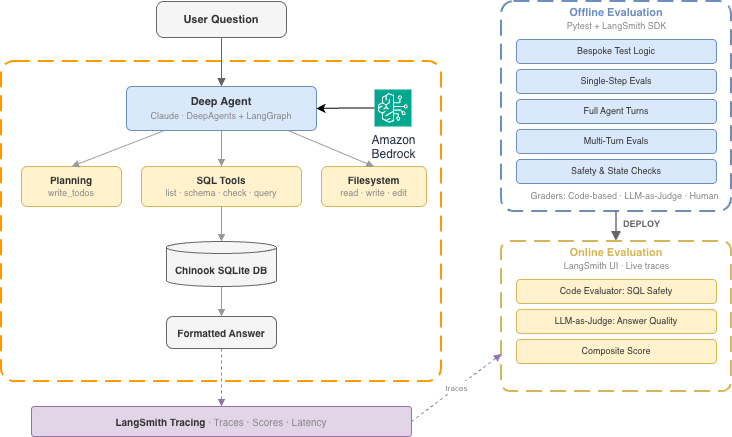
*図 1: テキストから SQL への深層エージェントのアーキテクチャ*
前提条件
本記事の内容を追いかけるには、以下の前提条件を満たす必要があります。
- Amazon Bedrock のアクセス権限が有効化された AWS アカウント
- LangSmith アカウントおよび API キー
- Python 3.12 以降
- 認証情報が設定された AWS Command Line Interface (AWS CLI)
- 必要なパッケージ: deepagents, langchain-aws, langchain-community, pytest
セットアップ
コンパニオンリポジトリをクローンし、依存関係をインストールしてください:
git clone https://github.com/aws-samples/sample-text2sql-deep-agent-evalulation
cd langsmith-deep-agents-eval
python -m venv .venv
source .venv/bin/activate # Windows の場合: .venv\Scripts\activate
pip install -e .
テキストから SQL へのエージェントは、ChatBedrockConverse を使用して Amazon Bedrock 上の Amazon Nova 2 Lite を利用します。
from langchain_aws import ChatBedrockConverse
model = ChatBedrockConverse(
model="global.amazon.nova-2-lite-v1:0",
region_name=os.getenv("AWS_REGION", "us-east-1"),
temperature=0,
)
The .env configuration is minimal:
原文を表示
*This post was co-authored with Karan Singh, Head of Partnerships at LangChain*
Validating AI agent behavior before production is one of the hardest problems in applied AI. Agents are non-deterministic, multi-step where errors in early steps can affect downstream results. A single bad tool call can cascade through an entire workflow. LangSmith on AWS gives you the evaluation framework to catch these issues early, track them in production, and continuously improve your agent’s reliability throughout its lifecycle.
This post combines learnings from LangChain’s work on evaluating deep agents and Anthropic’s guide to demystifying evals for AI agents into a practical guide. In this post, you will learn how to: 1) apply five evaluation patterns for deep agents, 2) build offline evaluations using pytest and LangSmith, and 3) configure online monitoring for production. The walkthrough uses a text-to-SQL deep agent with Amazon Bedrock for the full development to production lifecycle.
Amazon Nova 2 Lite is a fast, cost-effective reasoning model available in Amazon Bedrock. It supports extended thinking with configurable budget levels (low, medium, high) and accepts text, image, video, and document inputs with a 1 million-token context window. Nova 2 Lite handles instruction following, function calling, and code generation well, which makes it a good fit for agentic workloads like the text-to-SQL agent in this post.
The structure of an agent evaluation
An evaluation is a test for an AI system: give an AI an input, apply grading logic to its output, and measure success. For a large language model (LLM) call, this is straightforward. For agents, every component becomes more complex.
Key terminology
Before diving into patterns, here are the terms used throughout this post:
- Task: A single test with defined inputs and success criteria. For example, “How many customers are from Canada?” with the expected answer of eight.
- Trial: A single attempt at a task. Because model outputs are non-deterministic, running multiple trials per task produces more reliable results.
- Grader: Logic that scores some aspect of the agent’s performance. A task can have multiple graders, each evaluating a different dimension.
- Transcript: The complete record of a trial, including tool calls, reasoning steps, intermediate results, and interactions. In LangSmith, this is the full trace you can inspect for debugging.
- Outcome: The final state of the environment at the end of a trial. An agent might say “The answer is eight,” but the outcome is whether it actually executed the correct SQL query against the database.
- Evaluation harness: The infrastructure that runs evaluations end-to-end. It provides instructions and tools, runs tasks concurrently, records steps, grades outputs, and aggregates results.
- Evaluation suite: A collection of tasks designed to measure specific capabilities or behaviors.
Why agent evaluations are harder
Three properties make agent evaluation fundamentally different from evaluating straightforward LLM outputs:
- Non-determinism – Agent behavior varies between runs. The same task might succeed 90% of the time and fail 10%. A single pass/fail result doesn’t tell you much. You need multiple trials to estimate actual performance. Two metrics help: pass@k measures the likelihood of at least one success in k attempts, while pass^k measures the probability that all k trials succeed. Use pass@k when one success suffices; use pass^k when consistency matters.
- Error propagation – In a multi-step agent, a mistake in step 3 can cascade through the following steps. A text-to-SQL agent that misidentifies the schema early on will construct an incorrect JOIN, producing wrong results in its final answer. Evaluating only the final output misses where things went wrong.
- Creative solutions – Frontier models sometimes find valid approaches that eval designers didn’t anticipate.
What you can evaluate
For an agent run, there are three categories that you can test:
- Trajectory – The sequence of tools called and the specific arguments that the agent generated. Did it explore the schema? Did it use sql_db_query_checker before executing?
- Final response – The final output returned to the user. Is the answer correct? Is it well formatted?
- Other state: Other artifacts that the agent produced, such as files written, TODO plans created, and intermediate results saved.
Evaluation patterns for AI agents
Agent evaluations typically combine three types of graders, and the key to effective evaluation design is choosing the right mix for your use case.
Code-based graders
Code-based graders use deterministic logic to verify specific conditions: string matching, regex patterns, binary pass/fail tests, static analysis, tool call verification, and transcript analysis (turn counts, token usage).
Strengths – Fast, cheap, objective, reproducible, and straightforward to debug. When you can express success criteria as code, do it.
Weaknesses – Brittle to validate variations that don’t match expected patterns exactly. A query result formatted as “eight customers” compared to “There are eight” might fail a strict string match even though both are correct.
Example: Verifying a tool was called:
# Assert the agent executed a SQL query
tool_names = [tc["name"] for tc in tool_calls]
assert "sql_db_query" in tool_names, "Agent must execute sql_db_query"
Model-based graders (LLM-as-judge)
Model-based graders use another LLM to evaluate the agent’s output. Methods include rubric-based scoring, natural language assertions, pairwise comparison, and multi-judge consensus.
Strengths – Flexible, scalable, captures nuance, and handles open-ended tasks and freeform output where the agent’s answer can take many valid forms.
Weaknesses – Non-deterministic, more expensive than code, and requires calibration with human graders to validate accuracy. Give the judge LLM a way out (for example, “return Unknown if you don’t have enough information”) to avoid hallucinated scores.
Example: Grading a complex analytical answer:
rubric = """Score the agent's answer on these dimensions (0.0 to 1.0):
1. correctness: Does it identify the right top employee? (Jane Peacock)
2. completeness: Does it include revenue broken down by country?
3. clarity: Is the answer well-formatted and easy to understand?
Return JSON: {"correctness": float, "completeness": float, "clarity": float}"""
judge_response = model.invoke(rubric.format(answer=answer))
scores = json.loads(judge_response.content)
LangSmith’s Align Evaluator feature walks you through a series of steps to calibrate your LLM-as-a-judge evaluator against human expert feedback. You can use this feature to tune evaluators that run on a dataset foroffline evaluations or foronline evaluations.
Human graders
*Human graders* (subject matter expert review, crowdsourced judgment, spot-check sampling) are often considered the gold standard for subjective quality assessments. Compared to programmatic evaluation options, human graders are expensive and slow, but essential for calibrating your model-based graders. Use them judiciously: calibrate LLM-as-judge rubrics against expert human judgment initially, then use human review periodically to verify that the automated graders haven’t drifted.
Combining graders: the practical recommendation
Use deterministic graders where possible, LLM graders where necessary for nuance, and human graders for calibration. For a text-to-SQL agent, that might look like:
- Code-based – Did the agent call sql_db_query? Does the answer contain “eight”? Were DML statements (INSERT, DELETE) executed?
- LLM-as-judge – For complex queries where the output format varies. Is the analysis correct, complete, and well structured?
- Human – Periodic spot-checks to verify LLM grading aligns with expert judgment.
Capability vs. regression evaluations
Not all evaluations serve the same purpose:
- Capability evaluation ask “what can this agent do well?” They should target tasks the agent currently struggles with, giving teams a hill to climb. Start with a low pass rate and work upward.
- Regression evaluation ask “does the agent still handle what it used to?” They should have a nearly 100% pass rate. A decline signals something is broken.
As your agent matures, capability evaluations that reach high pass rates can *graduate* into your regression suite. Tasks that once measured “can it do this at all?” then measure “can it still do this reliably?”
Evaluating deep agents
*Deep agents* (systems that use planning, tool use, filesystem backends, and progressive context loading to tackle complex, multi-step tasks) break the traditional assumption that every test case can be run through the same application logic and scored by the same evaluator. Over the past several months, LangChain shipped four applications on top of deep agent architectures and identified four patterns that apply broadly.
Pattern 1: Custom test logic per datapoint
Traditional LLM evaluation treats every datapoint identically: run through the same application, score with the same evaluator. Deep agents break this assumption. Each test case may have its own success criteria, and those criteria might involve specific assertions against the agent’s trajectory and state, not just the final message.
Consider a text-to-SQL agent. “How many customers are from Canada?” has a single correct answer (eight) that you can check with a string match. But “Which employee generated the most revenue and from which countries?” requires an LLM judge to evaluate correctness, completeness, and clarity, because the format of a valid answer varies widely.
LangSmith’s Pytest integration supports this pattern. You can make different assertions about the agent’s trajectory, final message, and state for each test case:
@pytest.mark.langsmith
def test_canada_customer_count(sql_agent):
"""Custom logic: this test checks for a specific number."""
result = sql_agent.invoke({
"messages": [{"role": "user", "content": "How many customers are from Canada?"}]
})
answer = result["messages"][-1].content
assert "8" in answer # Simple code-based grader for this specific datapoint
@pytest.mark.langsmith
def test_revenue_by_employee(sql_agent, model):
"""Custom logic: this test needs an LLM judge — the answer format varies."""
result = sql_agent.invoke({
"messages": [{"role": "user", "content": "Which employee generated the most revenue?"}]
})
scores = llm_judge(model, result["messages"][-1].content)
assert scores["correctness"] >= 0.5
Pattern 2: Single-step evaluations
About half of LangChain’s test cases for deep agents were single-step evaluations: what did the agent decide to do immediately after a specific input? This is especially useful for validating individual decision points. Did it call the right tool with the right arguments?
Regressions often occur at individual decision points rather than across full execution sequences. For a text-to-SQL agent, a single-step eval might verify that the agent’s first action is to explore the database schema (calling sql_db_list_tables or sql_db_schema), rather than jumping straight to writing a query.
@pytest.mark.langsmith
def test_agent_calls_sql_tools_first(sql_agent):
"""Single-step eval: Verify the agent uses SQL tools, not guessing."""
result = sql_agent.invoke({
"messages": [{"role": "user", "content": "How many customers are from Canada?"}]
})
tool_calls = extract_tool_calls(result["messages"])
tool_names = [tc["name"] for tc in tool_calls]
sql_tools = {"sql_db_list_tables", "sql_db_schema", "sql_db_query", "sql_db_query_checker"}
assert sql_tools & set(tool_names), "Agent must use SQL tools"
Single-step evaluations are your unit tests. Fast, focused, and efficient on tokens.
Pattern 3: Full agent turns
While single-step evaluations test individual decisions, full agent turns show you the complete picture. Run the agent end-to-end on a single input and evaluate:
@pytest.mark.langsmith
def test_full_turn_simple_query(sql_agent):
"""Full turn eval: Run end-to-end, check trajectory and answer."""
result = sql_agent.invoke({
"messages": [{"role": "user", "content": "How many customers are from Canada?"}]
})
# Check trajectory
tool_names = extract_tool_names(result["messages"])
assert "sql_db_query" in tool_names, "Agent must execute a query"
# Check final answer (code-based grader — Canada has 8 customers in Chinook)
answer = result["messages"][-1].content
assert "8" in answer, "Answer must contain the correct count"
Key insight: This test asserts that certain tools appeared in the trajectory, but doesn’t assert the exact order. The agent might list tables before getting the schema, or go directly to the schema. Both are valid. Grade *what the agent produced*, not the exact *path it took*.
LangSmith displays the complete trace for full agent turns. You can see the planning steps (write_todos), each SQL tool invocation, the actual queries executed, and the final formatted answer.
Pattern 4: Multi-turn evaluations
Some scenarios require testing agents across multi-turn conversations. A user asks “What are the top 5 best-selling artists?” then follows up with “For the top artist, how many albums do they have?” The challenge: if you hardcode a sequence of inputs and the agent deviates from the expected path, the subsequent inputs might not make sense.The solution is conditional logic in your tests:
@pytest.mark.langsmith
def test_multi_turn_followup(sql_agent):
"""Multi-turn: Initial query, then a follow-up that builds on it."""
# Turn 1
result1 = sql_agent.invoke({
"messages": [{"role": "user", "content": "What are the top 5 best-selling artists?"}]
})
answer1 = result1["messages"][-1].content
# Conditional: if turn 1 failed, fail early
if not answer1 or len(answer1) 20, "Follow-up must produce a meaningful answer"
If you want to test turn 2 in isolation, set up a test starting from that point with the expected turn 1 output as initial state.
End-to-end example: Evaluating a text-to-SQL deep agent on AWS
Now put these patterns into practice. The example uses LangChain’s text-to-SQL deep agent example, configure it to run on Amazon Bedrock, and build evaluations using LangSmith.
Architecture overview
The text-to-SQL deep agent is built on the DeepAgents framework, which provides planning, filesystem storage, and progressive context loading on top of LangGraph. It answers natural language questions about the Chinook database, a sample SQLite database representing a digital media store.
*Figure 1: Text-to-SQL Deep Agent architecture*
Prerequisites
You must have the following prerequisites to follow along with this post.
- AWS account with Amazon Bedrock access enabled
- LangSmith account and API key
- Python 3.12+
- AWS Command Line Interface (AWS CLI) configured with credentials
- Required packages: deepagents, langchain-aws, langchain-community, pytest
Setup
Clone the companion repository and install the dependencies:
git clone https://github.com/aws-samples/sample-text2sql-deep-agent-evalulation
cd langsmith-deep-agents-eval
python -m venv .venv
source .venv/bin/activate # On Windows: .venv\Scripts\activate
pip install -e .
The text-to-SQL agent uses Amazon Nova 2 Lite on Amazon Bedrock using ChatBedrockConverse:
from langchain_aws import ChatBedrockConverse
model = ChatBedrockConverse(
model="global.amazon.nova-2-lite-v1:0",
region_name=os.getenv("AWS_REGION", "us-east-1"),
temperature=0,
)
The .env configuration is minimal:
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み