Amazon NeptuneとMem0を活用したAmazon Bedrockの企業別メモリ機能
TrendMicroはAmazon Bedrock、Neptune、Mem0を組み合わせ、企業固有の長期記憶と会話型短期記憶を統合するハイブリッドアーキテクチャを実現し、エンタープライズ向けAIチャットボットの文脈認識能力と精度を大幅に向上させた。
キーポイント
ハイブリッドメモリアーキテクチャの実装
Amazon Neptuneで構造化ナレッジグラフを管理し、Mem0で会話履歴と長期記憶を分離・統合する設計により、組織固有のコンテキストを正確に保持する。
Bedrockによるワークフローオーケストレーション
Claudeモデルでエンティティ抽出と埋め込みを行い、Amazon Bedrockが両メモリ連携を制御することで、推論時に文脈に即した応答を生成する。
エンタープライズ実証ケースの提供
TrendMicroの「Trend's Companion」チャットボートで、セキュリティ、正確性、スケーラビリティを両立する実運用例を示し、開発者の設計参考としている。
長短期記憶の統合課題への解決策
組織知識の長期保持と対話履歴の短期管理をシームレスに連携させることで、ハルシネーションの低減と一貫性のあるユーザー体験の実現を目指す。
影響分析・編集コメントを表示
影響分析
本記事は、エンタープライズAI実装における「メモリ管理」のベストプラクティスを明確に示している。知識グラフと会話型メモリを組み合わせるハイブリッドアプローチは、ハルシネーションの抑制と文脈の一貫性確保に直結するため、今後の企業向けAIエージェント開発の標準アーキテクチャとなる可能性が高い。AWSとオープンソースツールの連携事例は、開発者にとって即座に適用可能な設計図を提供する。
編集コメント
エンタープライズAIの実用化において「いかに記憶を設計するか」が競争力の分かれ目となる。本記事のハイブリッドメモリパターンは、ハルシネーション対策とコンテキスト保持を両立する実務的な基準となりそうだ。
*本記事はTrendMicroのShawn Tsaiとの共著です。*
関連性の高く、文脈を考慮した(context-aware)回答を提供することは、顧客満足度の向上に重要です。エンタープライズグレードの(enterprise-grade)AIチャットボットにとって重要なのは、現在のクエリだけでなく、それに関連する組織的な文脈を理解することです。Amazon NeptuneとMem0によって駆動されるAmazon Bedrockの企業別メモリ(Company-wise memory)は、AIエージェントに永続的な(persistent)、企業固有のコンテキストを提供し、複数のやり取りを通じて学習し、適応し、インテリジェントに回答することを可能にします。世界最大のアンチウイルスソフトウェア企業の1つであるTrendMicroは、Trend’s Companionチャットボットを開発しました。これにより、顧客は自然な会話型のやり取りを通じて情報を探索できます(詳細はこちら)。
TrendMicroは、エンタープライズ顧客に対してパーソナライズされたコンテキスト対応のサポートを提供するため、AIチャットボットサービスの強化を目指しました。このチャットボットは、一貫性を保つために会話履歴を保持し、大規模な企業固有の知識を参照でき、メモリが正確で安全かつ最新の状態であることを確保する必要がありました。課題は、組織的な知識のための長期メモリ(long-term memory)と継続的な会話のための短期メモリ(short-term memory)を統合し、同時に企業全体の知識共有をサポートすることにあります。AWSのGenerative AI Innovation Centerを含むAWSチームとの協力により、TrendMicroはAmazon Neptune、Amazon OpenSearch、およびAmazon Bedrockを使用してこの課題に取り組みました。これについては本ブログで詳しく解説します。
解決策の概要
TrendMicroは複数のAWSサービスを組み合わせることで、Amazon Bedrockに企業別メモリを実装しました。Amazon Neptuneは組織内の関係、プロセス、データを表す企業固有のナレッジグラフ(knowledge graph)を保存し、正確かつ構造化された情報取得を可能にします。Mem0は即時のコンテキスト用の短期会話メモリ(short-term conversational memory)と、セッションを跨ぐ永続的な知識用の長期メモリを管理します。Amazon BedrockはAIエージェントのワークフローをオーケストレーションし、NeptuneおよびMem0と連携して推論(inference)処理中にコンテキスト知識を検索・適用します。このアーキテクチャにより、チャットボットは関連する履歴を想起し、構造化された企業知識を検索して、文脈に合わせた詳細な回答を提供できます。これによりユーザーエクスペリエンスの大幅な向上を実現します。
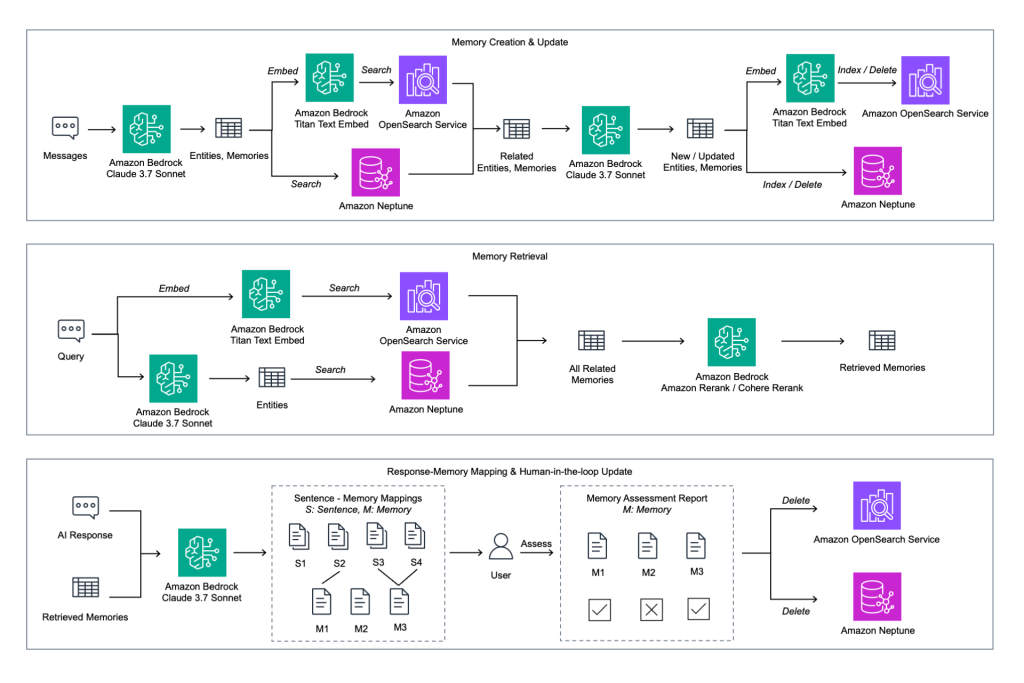
メモリの作成と更新
本アーキテクチャは、Amazon Bedrock上のClaudeモデルを用いてユーザーメッセージを取得し、エンティティ、関係性、潜在的なメモリを抽出することから始まります。その後、Amazon BedrockのTitan Text Embedを用いて埋め込みベクトルを生成し、Amazon OpenSearch ServiceおよびAmazon Neptuneの両方に対して検索を実行します。関連するエンティティとメモリが取得され、モデルを通じて更新された後、再度埋め込み処理が行われ、OpenSearchとNeptuneへインデックスとして戻されます。このクローズドループプロセスにより、エンティティ関連のメモリを継続的に更新でき、Neptune内のナレッジグラフが会話からの洞察と常に整合性を持つことが保証されます。
メモリの取得
ユーザーのクエリを処理する際、システムはBedrock Titanを用いた同様の埋め込みパイプライン(Embedding Pipeline)を適用し、OpenSearch Service内のベクトル埋め込みとNeptune内のエンティティトリプル(Entity Triple)の両方に対して検索を行います。その後、Amazon Bedrock RerankまたはCohere Rerankモデルを用いて関連メモリを再ランク付け(Reranking)し、文脈的に最も正確な情報が提供されるようにします。このデュアル取得戦略は、OpenSearchからの意味的な柔軟性とNeptuneからの構造化された精度の両方を提供し、チャットボットが高度に関連性があり文脈を把握した回答を提供することを可能にします。
回答とメモリのマッピング、およびヒューマンインザループフィードバック
各AIの回答に対して、システムは参照された特定のメモリに文脈をマッピングし、メモリ評価レポートを生成します。その後、ユーザーはこれらのマッピングの承認または却下の機会を与えられます。承認されたメモリはナレッジベースの一部として残りますが、却下されたものはOpenSearch ServiceおよびNeptuneの両方から削除されます。これにより、検証され信頼された知識のみが保持されることが保証されます。このヒューマンインザループ(Human-in-the-Loop)メカニズムは信頼性を高め、メモリの精度を継続的に改善するのに役立ち、エンタープライズ顧客が自身のAIの知識の洗練に直接影響を与えることを可能にします。
Amazon Neptuneの実践例
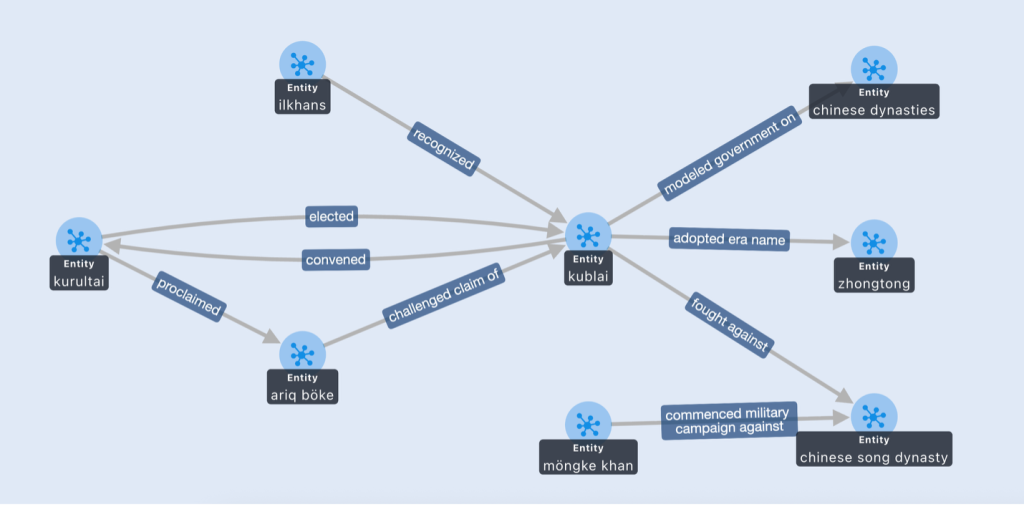
Amazon Neptuneがチャットボットのメモリをどのように強化するかを示すため、顧客が「誰がクビライを支配者として認めたか?」と質問するケースを考えてみましょう。ナレッジグラフがない場合、AIは「クビライは複数のグループから承認を得たモンゴルの支配者でした」といった曖昧な回答を返す可能性があります。この種の回答は一般的であり、精度に欠けます。
同じ質問がなされた場合でも、Neptuneのエンティティグラフをクエリして大規模言語モデル(Large Language Model, LLM)のコンテキストウィンドウ(Context Window)に配置すると、モデルは(Ilkhans, recognized, Kublai)のような構造化されたトリプルに基づいて推論の基盤とすることができます。その後、チャットボットはより正確に「組織のナレッジベースによると、クビライはイルハン朝によって支配者として認められました」と回答できます。この前後の例は、Neptune内の構造化されたエンティティ関係が、モデルが文脈的に適切かつ検証可能な回答を生成することを可能にする方法を証明しています。
結論と次のステップ
AWS Trend Micro事例研究で説明されている通り、Trend MicroはAWSを活用して、より安全でスケーラブルかつインテリジェントな顧客体験の提供を支援しています。この基盤の上に、Trend MicroはAmazon Bedrock、Amazon Neptune、Amazon OpenSearch Service、Mem0を組み合わせ、組織固有の永続メモリを備えたAIチャットボットを作成し、大規模なインテリジェントで文脈を考慮した対話を実現しています。グラフベースのナレッジ(graph-based knowledge)とジェネレーティブAI(generative AI)を統合することで、Trend Microは回答品質の向上が期待されており、より明確で正確な応答を提供するとともに、組織知識の変化に継続的に適応するAIシステムの基盤を構築しています。この取り組みは現在も評価とチューニングが行われており、エンドユーザー体験のさらなる向上を目指しています。
今後の展望として、TrendMicroはより広範なグラフカバレッジ(graph coverage)、追加のアップデートパイプライン(update pipelines)、多言語サポートなどの機能強化を検討しています。さらに深く掘り下げたい読者の皆様には、実装したソースコードを含むGitHubサンプル実装と、技術的な詳細やインスピレーションを得るためのAmazon Neptuneドキュメントの探索を推奨します。
著者について

Shawn Tsai
Shawn TsaiはTrend Microのシニアアーキテクトであり、大規模言語モデル(Large Language Model)アプリケーション開発およびセキュリティプラクティス(security practices)、クラウドアーキテクチャ設計(cloud architecture design)、大規模ソフトウェアアーキテクチャ設計、DevOpsプラクティス(DevOps practices)に専門知識を有しています。現在、主にTrend Microの大規模言語モデルアプリケーション開発およびセキュリティフレームワークを担当しています。

Ray Wang
Ray WangはAWSのシニアソリューションズアーキテクトです。バックエンドおよびコンサルティング分野で12年以上の経験を持つRayは、クラウドにおけるモダンなソリューション構築に専念しており、特にNoSQL、ビッグデータ(big data)、機械学習(machine learning)、ジェネレーティブAI(Generative AI)の分野を得意としています。技術知識の幅と深さを高めるため、12種類のAWS認定資格すべてを取得した情熱的なプロフェッショナルです。趣味は読書とSF映画鑑賞です。

Zhihao Lin
Zhihao Linは、AWS Generative AI Innovation CenterのApplied Scientist(応用科学者)です。北京大学で修士号を取得し、CVPRやIJCAIといった主要カンファレンスに論文を発表しており、その豊富なAI/ML(人工知能/機械学習)研究の経験を活かして職務に携わっています。AWSでは、最先端技術を活用した革新的なアプリケーションに向けて生成AI(Generative AI)ソリューションの開発に注力しています。複雑なコンピュータビジョン(Computer Vision)や自然言語処理(Natural Language Processing)の課題解決を専門とし、ビジネスにおける生成AIの実践的な活用推進にも取り組んでいます。
原文を表示
*This post is cowritten by Shawn Tsai from TrendMicro.*
Delivering relevant, context-aware responses is important for customer satisfaction. For enterprise-grade AI chatbots, understanding not only the current query but also the organizational context behind it is key. Company-wise memory in Amazon Bedrock, powered by Amazon Neptune and Mem0, provides AI agents with persistent, company-specific context—enabling them to learn, adapt, and respond intelligently across multiple interactions. TrendMicro, one of the largest antivirus software companies in the world, developed the Trend’s Companion chatbot, so their customers can explore information through natural, conversational interactions (learn more).
TrendMicro aimed to enhance its AI chatbot service to deliver personalized, context-aware support for enterprise customers. The chatbot needed to retain conversation history for continuity, reference company-specific knowledge at scale, and ensure that memory remained accurate, secure, and up to date. The challenge is in integrating long-term memory for organizational knowledge with short-term memory for ongoing conversations, while supporting company-wide knowledge sharing. In collaboration with the AWS team, including AWS’s Generative AI Innovation Center, TrendMicro addressed this challenge using Amazon Neptune, Amazon OpenSearch, and Amazon Bedrock, as we elaborate in this blog.
Solution overview
TrendMicro implemented company-wise memory in Amazon Bedrock by combining multiple AWS services. Amazon Neptune stores a company-specific knowledge graph, representing organizational relationships, processes, and data to enable precise and structured retrieval. Mem0 manages short-term conversational memory for immediate context and long-term memory for persistent knowledge across sessions. Amazon Bedrock orchestrates the AI agent workflows, integrating with both Neptune and Mem0 to retrieve and apply contextual knowledge during inference. This architecture allows the chatbot to recall relevant history, retrieve structured company knowledge, and respond with tailored, context-rich answers—helping significantly improve user experience.
Memory creation and update
The architecture begins with capturing user messages and extracting entities, relationships, and potential memories through the Claude model on Amazon Bedrock. These are then embedded with Amazon Bedrock Titan Text Embed and searched against both Amazon OpenSearch Service and Amazon Neptune. Relevant entities and memories are retrieved, and updated through the model before being re-embedded and indexed back into OpenSearch and Neptune. This closed-loop process makes sure that entity-related memories can be continuously refreshed and the knowledge graph in Neptune remains consistent with conversational insights.
Memory retrieval
When handling user queries, the system applies a similar embedding pipeline with Bedrock Titan to search across both vector embeddings in OpenSearch Service and entity triples in Neptune. The relevant memories are then reranked using Amazon Bedrock Rerank or Cohere Rerank models to make sure that the most contextually accurate information is delivered. This dual retrieval strategy provides both semantic flexibility from OpenSearch and structured precision from Neptune, enabling the chatbot to deliver highly relevant, context-aware answers.
Response-memory mapping and human-in-the-loop feedback
For each AI response, the system maps sentences to the specific memories referenced, generating a memory assessment report. Users are then presented with the opportunity to approve or reject these mappings. Approved memories remain part of the knowledge base, while rejected ones are removed from both OpenSearch Service and Neptune. This makes sure that only validated and trusted knowledge persists. This human-in-the-loop mechanism strengthens trust and helps continuously improve memory accuracy and gives enterprise customers direct influence over the refinement of their AI’s knowledge.
Amazon Neptune in action
To illustrate how Amazon Neptune enriches chatbot memory, consider a customer asking, “Who recognized Kublai as ruler?” Without the knowledge graph, the AI might return a vague response such as: “Kublai was a Mongol ruler who gained recognition from different groups.” This kind of answer is generic and lacks precision.
When the same question is asked but the Neptune entity graph is queried and placed into the large language model’s (LLM) context window, the model can ground its reasoning in structured triples like (Ilkhans, recognized, Kublai). The chatbot can then reply more accurately: “According to the organizational knowledge base, Kublai was recognized by the Ilkhans as ruler.” This before-and-after example demonstrates how structured entity relationships in Neptune allow the model to produce answers that are both contextually relevant and verifiable.
Conclusion and next step
As described in the AWS Trend Micro case study, Trend Micro uses AWS to help deliver more secure, scalable, and intelligent customer experiences. Building on this foundation, Trend Micro combines Amazon Bedrock, Amazon Neptune, Amazon OpenSearch Service, and Mem0 to create an AI chatbot with persistent, organization-specific memory that delivers intelligent, context-aware conversations at scale. By integrating graph-based knowledge with generative AI, Trend Micro is expected to improve answer quality, delivering clearer and more accurate responses while establishing a foundation for AI systems that continuously adapt to evolving organizational knowledge; This work remains under evaluation and tuning to further enhance the end-user experience.
Looking ahead, TrendMicro is exploring future enhancements such as broader graph coverage, additional update pipelines, and multilingual support. For readers who want to dive deeper, we recommend exploring the GitHub sample implementation, which includes the source code we implemented, and the Amazon Neptune Documentation for further technical details and inspiration.
About the authors
Shawn Tsai
Shawn Tsai is a senior architect at Trend Micro, specializing in large language model application development and security practices, cloud architecture design, large-scale software architecture design, and DevOps practices. He is currently primarily responsible for Trend Micro’s large language model application development and security framework.
Ray Wang
Ray Wang is a Senior Solutions Architect at AWS. With 12+ years of experience in the backend and consultant, Ray is dedicated to building modern solutions in the cloud, especially in especially in NoSQL, big data, machine learning, and Generative AI. As a hungry go-getter, he passed all 12 AWS certificates to increase the breadth and depth of his technical knowledge. He loves to read and watch sci-fi movies in his spare time.
Zhihao Lin
Zhihao Lin is an Applied Scientist at the AWS Generative AI Innovation Center. With a Master’s degree from Peking University and publications in top conferences such as CVPR and IJCAI, he brings extensive AI/ML research experience to his role. At AWS, he focuses on developing generative AI solutions, leveraging cutting-edge technology for innovative applications. He specializes in solving complex computer vision and natural language processing challenges and advancing the practical use of generative AI in business.
関連記事
AIコーディング企業Cognition、250億ドルの評価額で資金調達交渉中
AIコーディング企業Cognitionは、評価額を250億ドルに倍増させる資金調達を巡り早期の交渉を行っている。同社はDevinという主力製品を通じて、AndurilやMicrosoftなどの企業向けにコード作成とデバッグの効率化を提供している。
Claudeマネージドエージェントの標準内蔵メモリ機能
アントロピックは、Claudeマネージドエージェントに標準内蔵メモリ機能を搭載したと発表した。これにより、エージェントは過去のコンテキストを自動保持し、ユーザーの継続的な利用環境を提供する。
Grok Voice Think Fast 1.0 の発表
xAI は音声エージェント機能の大幅な向上として、新フラッグシップ音声モデル「grok-voice-think-fast-1.0」を発表した。このモデルは、カスタマーサポートや営業などにおける複雑で曖昧なマルチステップ作業に優れ、高精度なデータ入力と大量のツール呼び出しを必要とする重要なシナリオに適している。