Amazon QuickSight に S3 Tables を導入し、データレイクを AI 対応分析へ
Amazon Quick が Apache Iceberg 形式の S3 Tables を直接データソースとしてサポートすることで、データ移動を伴わないリアルタイム分析とアーキテクチャの簡素化を実現した。
キーポイント
S3 Tables の直接接続機能の導入
Amazon Quick が Apache Iceberg テーブルを中間レイヤーなしで直接クエリ・可視化できる機能を追加し、データ移動の必要性を排除した。
アーキテクチャの簡素化とコスト削減
データウェアハウスや OLAP システムへの依存を減らし、運用複雑性とインフラオーバーヘッドを低減するストリームラインされた設計が可能になった。
ニアリアルタイムな分析の実現
パイプラインの依存関係を最小化することで、ダッシュボードや分析結果が最新のデータ状態を反映するようになり、意思決定のスピードが向上する。
影響分析・編集コメントを表示
影響分析
この発表は、データレイクと分析ツールの境界を曖昧にし、従来の複雑なデータ移動パターン(Data Lakehouse への移行など)に対する新たな選択肢を提供する。企業にとって、リアルタイム性とコスト効率を両立しつつ、ガバナンスされた単一の真実源(Single Source of Truth)を維持しながら AI/ML 分析を加速できる重要な転換点となる。
編集コメント
データ移動を伴わない分析は長年の課題であり、S3 Tables との直接連携によりその解決が現実味を帯びてきました。特に大規模なリアルタイムデータを扱う組織にとって、インフラコストと遅延の両方を削減できる画期的なアップデートです。
組織は現在、洞察と意思決定を加速させるために、分析と AI を組み合わせることをますます模索しています。Amazon Quick は、統一されたエージェント型 AI 駆動の分析および意思決定知能サービスであり、データ可視化、自然言語対話、エージェント駆動自動化を単一の統制された体験に統合します。これにより、ビジネスユーザーは専門的な機械学習 (ML) の知識を必要とせずに、データの探索、洞察の生成、アクションの実行が可能になります。
一方、現代のデータアーキテクチャは、パフォーマンス、コスト効率、ガバナンスの向上を提供する Apache Iceberg などのオープンテーブルフォーマットを基盤としたスケーラブルなデータレイクへと進化しています。しかし、大規模データの分析には、データをデータウェアハウスや OLAP システムへ移動させる必要があり、これにより遅延、追加コスト、運用上の複雑さが生じます。既存のクエリモード—例えば、データウェアハウスとの Direct Query や SPICE (*Super-fast, Parallel, In-memory Calculation Engine*) —はほとんどの分析ニーズに対応していますが、顧客は依然として、データレイクから大規模でリアルタイムのデータを直接分析するためのよりシームレスな方法を求めています。
これに対処するため、Amazon Quick は Amazon S3 Tables(Apache Iceberg テーブル)を新しいデータソースとして導入しました。この機能により、顧客は中間データレイヤーを必要とせずに、Amazon S3 テーブルバケットに格納された Apache Iceberg テーブルを直接クエリして可視化できます。このアプローチは、特にデータの移動削減、パフォーマンス向上、そして安全で統制された単一の真実源(single source of truth)の維持を要求する顧客にとって、追加的なアーキテクチャ選択肢を提供します。
本稿では、Amazon Quick と S3 Tables がどのように連携してニアリアルタイム分析を可能にし、現代的なデータアーキテクチャを合理化するかを探ります。
S3 Tables への直接接続の利点:
*S3 Tables 用の直接クエリモードと SPICE モード* は、Amazon Quick の新機能であり、中間クエリレイヤーを必要とせずに Amazon S3 テーブルバケット内の Apache Iceberg テーブルを直接消費することを可能にします。この機能は、Apache Iceberg オープンテーブルフォーマットを使用してデータレイクを「中央の真実源」として扱い、複雑なデータパイプラインや異種システム間でのデータ移動に伴うオーバーヘッドなしで高性能分析を実現する現代的なデータアーキテクチャの実装を目指す企業にとって有益です。
主な利点は以下の通りです:
- シームレス化されたアーキテクチャ データレイク内のデータを直接照会可能にすることで、別個のデータウェアハウスや OLAP レイヤーを不要とし、運用上の複雑さとインフラストラクチャのオーバーヘッドを削減します。
- ほぼリアルタイムなインサイト データ移動とパイプライン依存関係を最小限に抑え、ダッシュボードや分析が利用可能な最新データを反映することを保証します。
- スケーラブルなパフォーマンス Amazon S3 テーブルバケットに保存された大規模データセットを、データのキュレーション、レプリケーション、またはサイズ制約を必要とせずに照会できるため、シームレスなスケーラビリティを実現します。
ソリューション概要
今回の新機能により、Amazon Quick では SPICE モードまたは Direct Query モードのいずれかを使用してデータレイク内のデータを照会できるようになりました。本稿では Direct Query モードに焦点を当てますが、データセット作成時には SPICE モードを選択することも可能です。
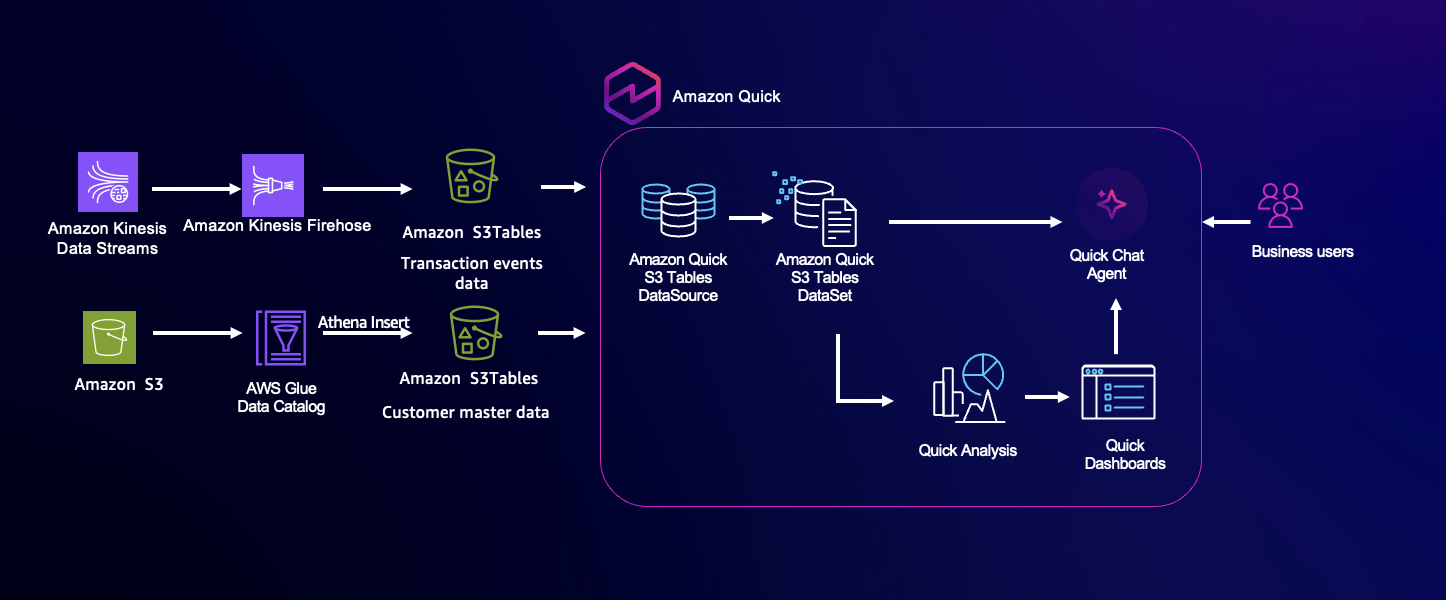
このソリューションは、複数の地域でカード取引を取り扱うグローバルな金融サービス企業である AnyCompany Corp. に対して、ほぼリアルタイムの分析と意思決定を可能にします。取引データは、POS システム、モバイルバンキングアプリ、IoT 対応決済デバイス、オンラインゲートウェイなど、多様なソースから生成されます。不正検出、承認率のモニタリング、および実行可能なインサイトへの迅速なアクセスというニーズに対応するため、ストリーミングデータ取り込み、オープンテーブルフォーマットのデータレイク、AI 駆動型分析を組み合わせたアプローチを採用しています。
トランザクションイベントは Amazon Kinesis Data Streams にストリーミングされ、Amazon Data Firehose を介して Amazon S3 テーブルバケットに配信されます。Quick のネイティブ S3 Tables コネクタを使用することで、ビジネスユーザーはデータレイクをニアリアルタイムで照会し、自然言語による対話を通じてデータを分析できるようになります。これにより、バッチ処理への依存が不要となり、地域ごとの不正取引の傾向や承認率などのインサイトを即座に発見することが可能になり、運用の可視性が向上するとともに、より迅速なデータ駆動型の意思決定を支援します。
アーキテクチャの概要
本アーキテクチャは、データ取り込み、ストレージ、クエリ、分析という 4 つのコアレイヤーで構成されています。本稿では*クエリ*および*分析*レイヤーに焦点を当てます。分散型決済システムからのトランザクションイベントは、Amazon Kinesis Data Streams を用いてリアルタイムに取り込まれ、スケーラブルかつ低遅延のストリーミング層を提供します。これらのイベントは継続的に Apache Iceberg 形式の Amazon S3 テーブルバケットへ配信され、ストリーミングと分析ワークロードの両方をサポートする高パフォーマンスなデータレイクを形成します。従来、データは Amazon Athena を通じてクエリ可能でしたが、Amazon Quick では S3 Tables の直接かつニアリアルタイムなクエリが可能となり、AI 駆動の自然言語分析も実現します。ビジネスユーザーは技術的専門知識なしに生データを探索し、可視化を生成し、直近 1 時間における不正率の高い地域を特定するといった洞察を得ることができます。本アーキテクチャにより、意思決定が最新データに基づいて行われ、迅速かつ正確なビジネスアクションが可能になります。
前提条件
本稿の内容を追うためには、以下の準備が整っていることを確認してください。
- データ取り込みおよびストレージレイヤーを含むストリーミングパイプラインが既にセットアップされており、データが Amazon S3 テーブルバケットに利用可能であること。
- Amazon Quick Enterprise のサブスクリプションを保有していること。
実装手順
ビジネスユーザーに Amazon Quick で Apache Iceberg テーブルへのアクセス権限を与えるための手順を以下に示します。これは、Amazon Quick の分析および対話型ワークロードにおいて利用可能です。
ステップ 1: Amazon Quick での S3 Tables データアクセスの有効化
まず、データソースの構築時に自動的に検出されるように、Amazon Quick を設定して S3 Tables にアクセスできるようにしましょう。
- 右上隅にあるアカウント名を選択し、「アカウントの管理」をクリックします。
- 左側のナビゲーションメニューで、「権限」セクションの下にある「AWS リソース」を選択します。
- 「これらのリソースへのアクセス許可と自動検出を有効にする」セクションで、「Amazon S3 Tables」を選択します。
- 「S3 テーブルバケットの選択」をクリックし、このブログ記事で使用されるサンプルデータを含む関連する S3 テーブルバケットを選択して「完了」をクリックします。(本稿では、s3table-datasamples バケットを使用します。)
- 「Amazon S3 バケット」オプションが選択されていることを確認し、「保存」をクリックします。
この手順により、Amazon Quick のロールに必要な権限が付与され、データソースを作成する際に Amazon Quick インスタンスが特定の S3 テーブルバケットデータを正常に検出できるようになります。
ステップ 2: S3 Tables を使用して Amazon Quick のデータソースを作成する
次に、s3table-datasamples バケットを指す Amazon Quick のデータソースを作成します。このバケットには 2 つのテーブルが含まれています。customer(顧客)ディメンションと transaction_events(取引イベント)です。customer ディメンションテーブルはファイルベースで、架空の銀行顧客情報を含んでいますが、transaction_events はこれらの顧客に関連する架空のストリーミングクレジットカード取引データを表しています。
- 左上隅の Amazon Quick を選択して、Quick ホームページに移動します。
- メニューから「データセット」を選択し、「データソース」タブに進んで「データソースの作成」を選択します。
- 次の画面で、データソースタイプとして「Amazon S3 Tables (Apache Iceberg テーブル)」を選択し、「次へ」をクリックします。
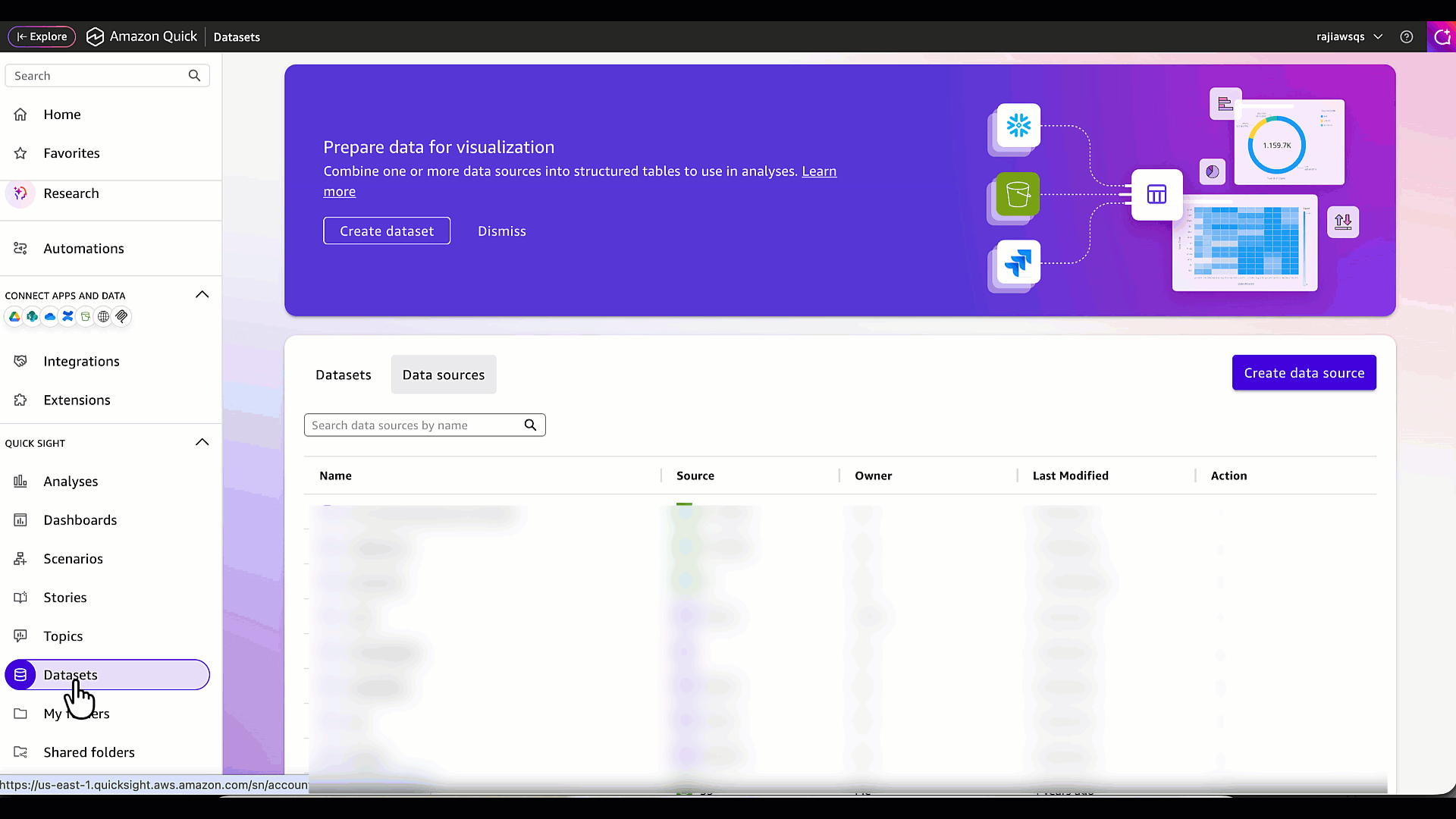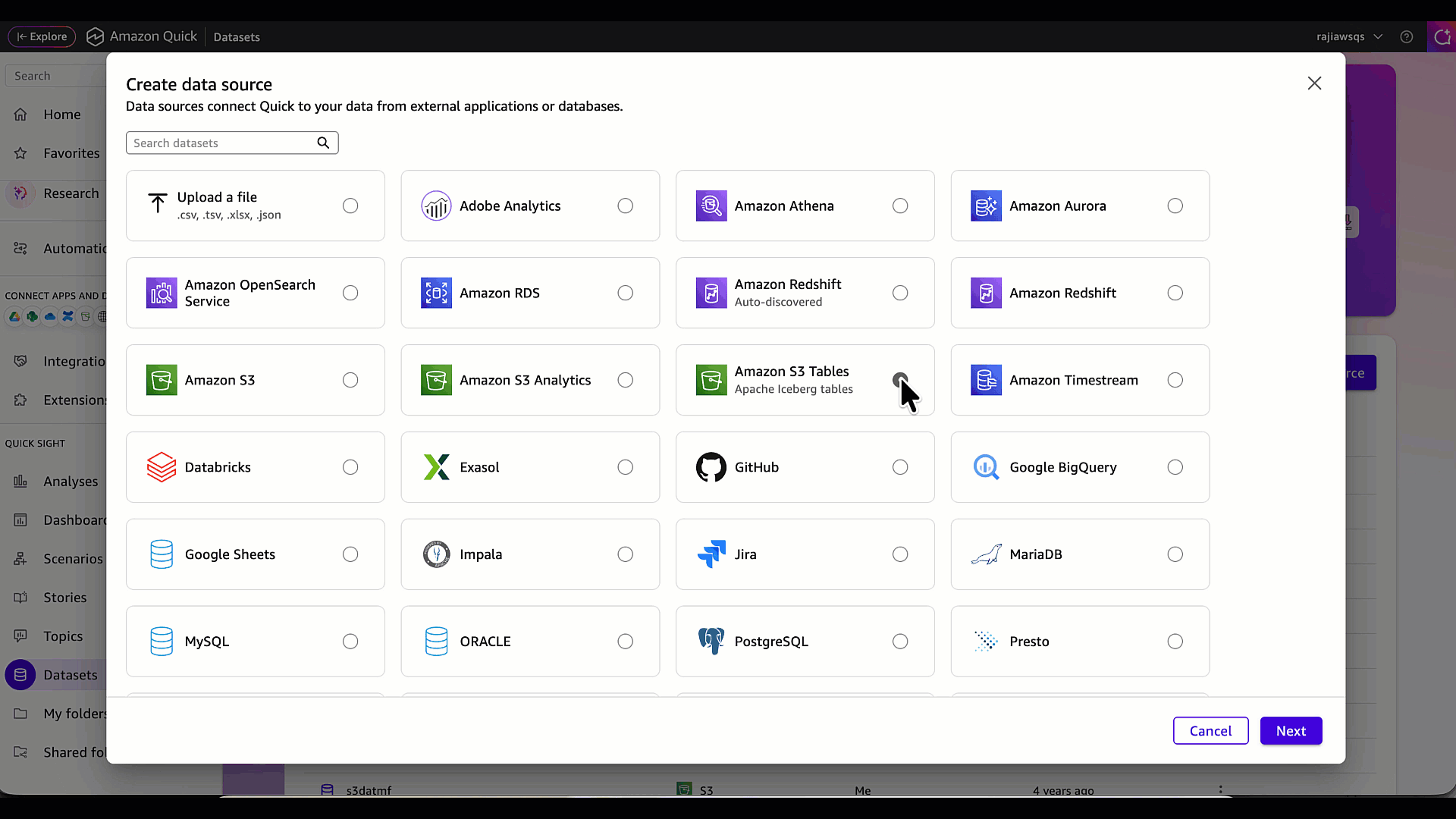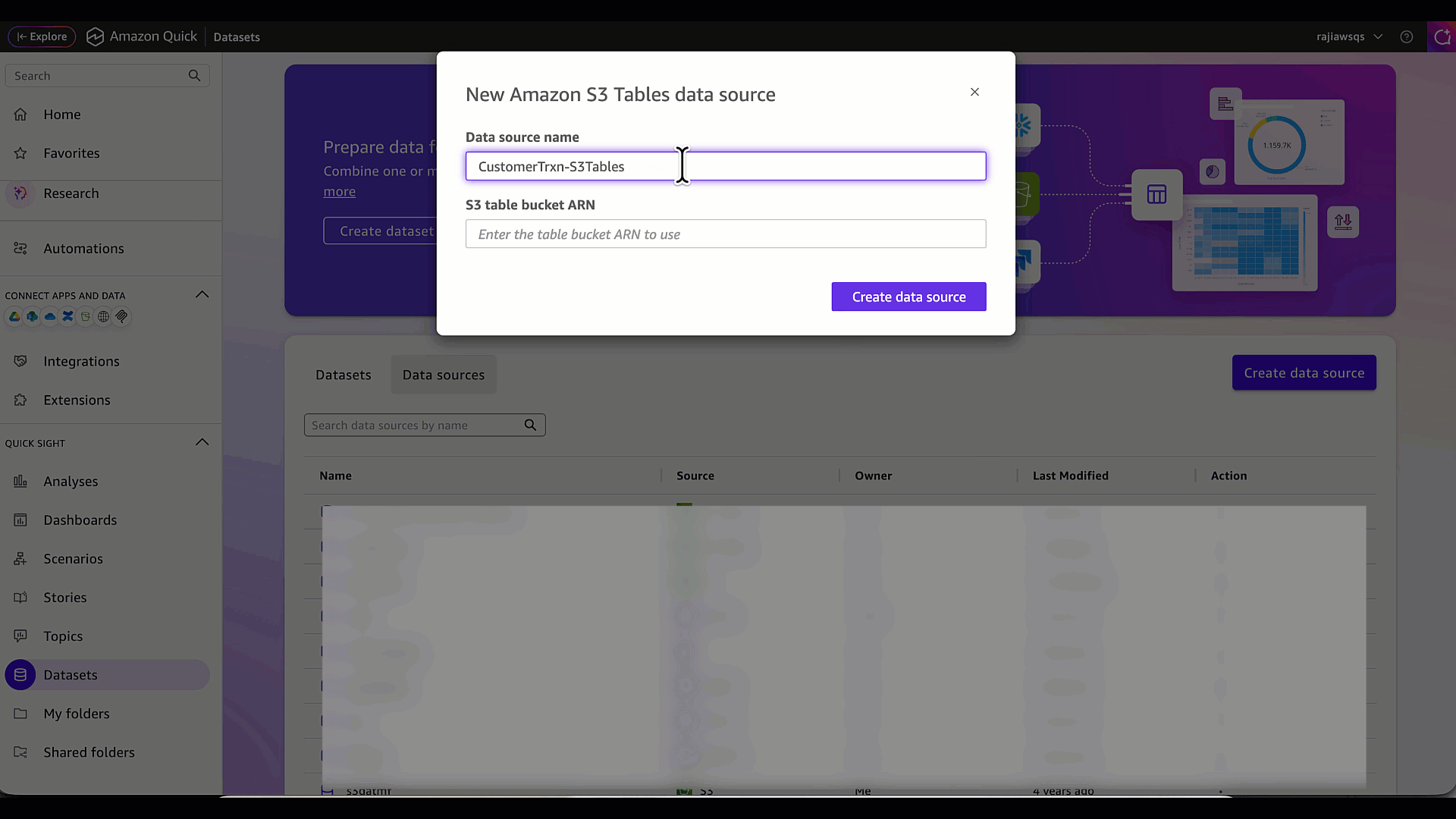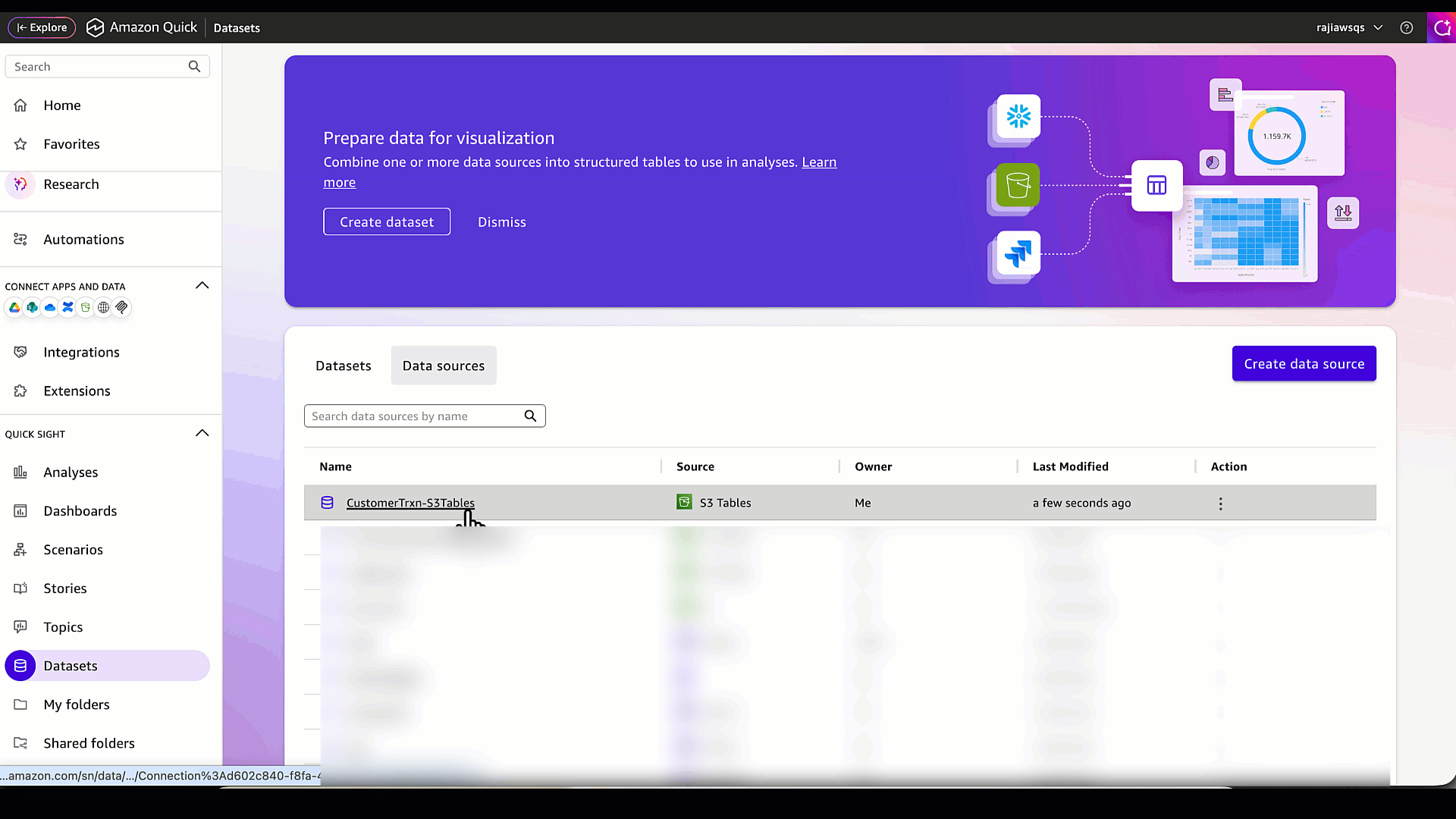
- データソース名(例:CustomerTrxn-S3Tables)を入力し、S3 テーブルバケットの ARN を提供します。この例では、s3table-datasamples バケットの ARN です。
- 「データソースの作成」を選択します。
*データソースが正常に作成されたことを確認してください。*
ステップ 3: Amazon Quick でデータセットを構築する
このステップでは、以前作成したデータソースを使用してデータセットを構築します。
- 前手順で作成したデータソース (CustomerTrxn-S3Tables) を選択し、[Create dataset](データセットの作成)を選択します。
- データソースに対して自動的に設定された名前空間を選択し、リストからテーブルを選んで [Edit/Preview data](編集/データのプレビュー)をクリックします。この例では、s3table-data 名前空間には 2 つのテーブルが含まれています。まずは顧客次元テーブルから始めます。
- プレビュータブで、S3 Tables から取得されたデータを確認します。
- 他のテーブルを追加するには、メニューから [Add data](データの追加)を選択します。この例では transaction_events テーブルを追加します。
- データ追加画面で、ドロップダウンリストから [Data source](データソース)を選択します。
- [Select a data source](データソースの選択)リストから CustomerTrxn-S3Tables を選び、[Select](選択)をクリックします。
- テーブル一覧から transaction_events を選択し、[Select](選択)をクリックします。
- customer_master テーブルの隣のプラス (+) アイコンを選択して「Join」を選ぶことで、2 つのテーブルを結合します。
- customer_id カラムを使用して結合を設定します:
「Inner Join」オプションを選択します。
- 右側のテーブルとして transaction_events を選択します。
- 左側と右側の両方のテーブルから customer_id を結合キー (join keys) として選択します。
- 複数のテーブルを扱う際に識別しやすくするために、結合に名前を付けます(例:TrxnJoin)。
- 左上隅でデータセットに名前を付けます(例:CxTrxn_S3TableData)。
- 右上隅で「Direct Query」モードが選択されていることを確認してください。これは S3 Tables (S3 テーブル) からニアリアルタイムのデータアクセスを完全に活用するために重要です。代わりに、ニアリアルタイムアクセスよりもスケジュールされたデータ更新を希望する場合は、「SPICE」モードを選択することもできます。
- 「Save & Publish」を選択します。
ステップ 4: Amazon Quick Chat を使用してデータセットと対話する
次に、このデータセットでチャットを開始し、自然言語を使用してインサイトを収集しましょう。これには、「My Assistant」というデフォルトのチャットを使用します。
- Amazon Quick のホームページで、左側のナビゲーションパネルから「Chat agents」を選択し、次に「My Assistant」を選択します。
- 「My Assistant」の隣にある「Chat」を選択します。
- 「All data and apps」から「Add」を選択して「Datasets」を選びます。その後、「CxTrxn_S3TableData」というデータセットを選択し、「Save」をクリックします。
- チャットパネルに「今月までに発生した取引の総数を表示してください」と入力して、送信ボタンを押します。
- 現在の月の取引総数を示すチャットの応答を確認します。次に、エージェントに日別内訳を求めましょう。
- チャットパネルに「 ingestion timestamp(取り込みタイムスタンプ)を使用して日別に内訳してください」と入力し、送信ボタンを押します。
- エージェントが提供する日別の内訳を確認します。今回の例では、4 月 1 日から 4 月 17 日の期間です。

ステップ 5: ストリーミングデータによるリアルタイムユーザーインタラクションの実演
次に、新しい取引データをストリーミングして、チャットのニアリアルタイム応答性をテストします。このデモでは、Kinesis Data Stream のプロデューサーとして AWS Lambda を使用し、Firehose を介して Apache Iceberg 形式の S3 Tables として S3 テーブルバケットに受信データを保存します。新しいデータがストリーミングされるにつれて、エンドユーザーが何らかの操作を行う必要なく、チャット内の取引カウントは自動的に更新されます。これは、手動介入や複雑なアーキテクチャを必要としないシームレスなニアリアルタイムデータアクセスを示しています。この Lambda 関数を数回実行して、新しいトランザクションイベントデータをストリーミングします。
このデモのために独自のストリーミングソースを作成したい場合は、詳細なガイダンスについては公式のAWS ドキュメントまたは関連する AWS のブログ投稿を参照してください。
次に、チャットエージェントで最近ストリーミングされたデータを確認してみましょう。
- 同じチャットセッションで「My Assistant」に戻り、新しいプロンプト「今月発生した取引の総数を表示してください。すべての最新のストリーミングデータを含め、取り込みタイムスタンプごとに内訳も示してください」と入力して[送信]を押します。
- My Assistant は Direct Query を介して CxTrxn_S3TableData データセットを照会し、4 月 18 日に新しく取り込まれたレコードを返します。これは、手動でのデータセット更新を必要とせずに、最近ストリーミングされたデータが利用可能であることを示しています。

クリーンアップ
このソリューションの一部としてデプロイされたリソースが不要になり、継続的なコストを避けたい場合は、Amazon Quick 関連のリソースをすべて削除し、Amazon Quick アカウントからの購読を解除することで、関連コンポーネントをクリーンアップして削除することを推奨します。
結論
本記事では、Amazon QuickSight の新しいデータソースである Amazon S3 Tables が、現代のデータアーキテクチャを簡素化しながらニアリアルタイム分析を可能にする方法について探りました。Amazon S3 内の Apache Iceberg テーブルを直接クエリすることで、中間層が不要となり、データの移動が削減され、単一の統制された真実の源が維持されます。さらに、My Assistant などの自然言語チャット体験を活用すれば、手動での更新や技術的なオーバーヘッドなしに、最新のインサイトを容易に取得できます。
その結果、データ、インサイト、アクションがニアリアルタイムでシームレスに統合された、AI を活用した分析体験が実現します。組織はより迅速に動き、より良い意思決定を行い、アーキテクチャをシンプルかつスケーラブルでコスト効率の高いまま保ちながら、データの潜在価値を最大限に引き出すことができます。もし、スケジュールされたデータ更新に基づく典型的な分析シナリオであり、ニアリアルタイムアクセスが必要ない場合は、SPICE モードが依然として適切な選択肢となります。この機能の詳細については、Amazon S3 Tables を使用したデータセットの作成をご覧ください。
追加の議論やご質問への回答を得るためには、Amazon QuickSight コミュニティをご確認ください。
著者について

Raji Sivasubramaniam は、Agentic AI に特化した AWS のシニアソリューションアーキテクトです。彼女は、Agentic AI、ビジネスインテリジェンス、データ管理、高度な分析にわたるエンドツーエンドのエンタープライズソリューションを、世界中のフォーチュン100 社および500 社の組織が実装できるよう支援することに注力しています。Raji は医療分野における深い専門知識を持ち、マネージドマーケット、医師ターゲティング、患者分析など多様なデータセットを扱う豊富な経験を通じて、高インパクトなデータ駆動型の意思決定を推進してきました。

Emily Zhu は、Amazon Quick のシニアプロダクトマネージャーであり、ガバナンスされたデータおよびエンタープライズスケールのデータアーキテクチャ、高性能な分析・対話型クエリエンジン、そして大規模なデータに真の意味を与えるセマンティック層とオントロジー層を含む、構造化データのスタック全体を担当しています。彼女は強力なデータ戦略が AI 戦略をどのように解放するかについて情熱を持っており、Quick Suite 全体の対話型および分析体験の基盤として構造化データスタックを整備することを目指して活動しています。

Priya Kakarlaは、ヘルスケア、金融、デジタルネイティブ組織など多様な業界での経験を持つモダン分析および AI ドライブ型ソリューションに特化したスペシャリスト ソリューションアーキテクトです。彼女は、スケーラブルで直感的かつエージェント駆動のアプローチを通じて、組織がデータから価値を引き出すお手伝いをすることに情熱を注いでいます。顧客第一の考え方を強く持つことで知られる Priya は、ビジネス目標に合致し、測定可能な成果をもたらすよう調整された革新的なソリューションを提供することに専念しています。仕事以外では、旅行や多様な料理を探求すること、家族や友人との時間を過ごすことを楽しんでいます。
原文を表示
Organizations today are increasingly looking to combine analytics and AI to accelerate insights and decision-making. Amazon Quick, a unified agentic AI-powered analytics and decision intelligence service, brings together data visualization, natural language interaction, and agent-driven automation in a single, governed experience. With this, business users can explore data, generate insights, and take action without requiring specialized machine learning (ML) expertise.
At the same time, modern data architectures are evolving toward scalable data lakes built on open table formats such as Apache Iceberg, which offer improved performance, cost efficiency, and governance. However, analyzing large-scale data often requires moving it into data warehouses or OLAP systems, introducing latency, added cost, and operational complexity. Although existing query modes—such as Direct Query and SPICE (*Super-fast, Parallel, In-memory Calculation Engine*) with data warehouses —address most analytics needs, customers continue to seek a more seamless way to analyze large, real-time datasets directly from their data lakes.
To address this, Amazon Quick introduces Amazon S3 Tables (Apache Iceberg tables) as a new data source. With this feature, customers can directly query and visualize Apache Iceberg tables stored in an Amazon S3 table bucket without the need for intermediate data layers. This approach provides additional architectural choice especially when customers are requiring to reduce data movement, improve performance, and maintain a secure, governed single source of truth.
In this post, we explore how Amazon Quick and S3 Tables work together to enable near real-time analytics and streamline modern data architectures.
Benefits of directly connecting with S3 Tables:
*Direct Query and SPICE modes for S3 Tables*, a new Amazon Quick feature, enables direct consumption of Apache Iceberg tables in Amazon S3 table bucket without requiring intermediate query layers. This feature is beneficial for enterprise looking to implement modern data architecture using Apache Iceberg open table format to treat their data lake as a “central source of truth,” enabling high-performance analytics without complex data pipeline and the overhead of moving data between disparate systems.
Key benefits include:
- Streamlined architecture Removes the need for separate data warehouses or OLAP layers by enabling direct querying of data in the data lake, reducing operational complexity and infrastructure overhead.
- Near real-time insights Minimizes data movement and pipeline dependencies, ensuring dashboards and analytics reflect the most current data available.
- Scalable performance Supports querying large-scale datasets stored in Amazon S3 table bucket without requiring data curation, replication, or size constraints—enabling seamless scalability.
Solution overview
With this new launch, Amazon Quick now supports querying data lakes using either SPICE or Direct Query mode. In this post, we focus on Direct Query mode, though you can choose SPICE mode when creating your dataset.
This solution enables near real-time analytics and decision-making for AnyCompany Corp., a global financial services organization handling card transactions across multiple regions. Transaction data is generated from diverse sources, including point-of-sale systems, mobile banking apps, IoT-enabled payment devices, and online gateways. To address the need for fraud detection, approval rate monitoring, and fast access to actionable insights, the solution uses a combination of streaming data ingestion, open table format data lakes, and AI-powered analytics.
Transaction events are streamed into Amazon Kinesis Data Streams and delivered using Amazon Data Firehose into an Amazon S3 table bucket. With the native S3 Tables connector of Quick, business users can query the data lake in near real-time and analyze data using natural language interactions, removing dependency on batch processing. You can use this unified approach to uncover insights such as regional fraud trends and approval rates instantly, improving operational visibility and supporting faster, data-driven decisions.
Architecture overview
The architecture is composed of four core layers: data ingestion, storage, querying, and analytics. For this post, we focus on the *query *and* analytics *layer. Transaction events from distributed payment systems are ingested in real-time using Amazon Kinesis Data Streams, providing a scalable, low-latency streaming layer. These events are continuously delivered to an Amazon S3 table bucket in Apache Iceberg format, forming a high-performance data lake that supports both streaming and analytical workloads. While data could traditionally be queried through Amazon Athena, Amazon Quick allows direct, near real-time querying of S3 Tables and enables AI-powered, natural language analysis. Business users can explore live datasets, generate visualizations, and obtain insights—such as identifying regions with high fraud rates in the last hour—without technical expertise. This architecture keeps decisions informed by the most current data, supporting rapid and accurate business actions.
Prerequisites
To follow along with this post, ensure that you have the following in place:
- Your steaming pipeline including data ingestion and storage layers are already set up and your data is available in an Amazon S3 table bucket.
- An Amazon Quick Enterprise subscription.
Implementation steps
Here are the steps to give your business users access to your Apache Iceberg tables using Amazon Quick analytical and conversational workloads:
Step 1: Enable S3 Tables data access for Amazon Quick
Let’s start by configuring Amazon Quick to access S3 Tables, so they can be automatically discovered when building the data source.
- Select your account name in the top-right corner and select Manage account.
- In the left navigation menu, under Permissions, choose AWS Resources.
- In the Allow access and auto discovery for these resources section, select Amazon S3 Tables.
- Choose Select S3 table buckets, then choose the relevant S3 table bucket containing the sample data for this blog and click Finish. (For this post, we use the s3table-datasamples bucket.)
- Ensure that the Amazon S3 bucket option is selected, then choose Save.
This step adds required permission to your Amazon Quick role and allows your Amazon Quick instances to successfully discover the specific S3 table bucket data while creating a data source.
Step 2: Create an Amazon Quick data source using S3 Tables
Now, let’s create an Amazon Quick data source pointing to the s3table-datasamples bucket. This bucket contains two tables: customer dimension and transaction_events. The customer dimension table is file-based and includes fictional bank customer information, while transaction_events represents fictional streaming credit card transaction data associated with those customers.
- Choose Amazon Quick in the top-left corner to navigate to the Quick home page.
- From the menu, select Datasets, then go to the Data sources tab and choose Create data source.
- On the next screen, select Amazon S3 Tables (Apache Iceberg tables) as the data source type, then choose Next.
- Enter a data source name (for example, CustomerTrxn-S3Tables) and provide the S3 table bucket ARN. In this example, it’s the ARN for the s3table-datasamples bucket.
- Choose Create data source.
*Verify that the data source has been created successfully.*
Step 3: Build a dataset in Amazon Quick
In this step, we use the data source created earlier to build a dataset.
- Select the data source (CustomerTrxn-S3Tables) created in the previous step and choose Create dataset.
- Choose the namespace automatically populated for your data source, then select a table from the list and click Edit/Preview data. In this example, the s3table-data namespace contains two tables. We begin with the customer dimension table.
- In the Preview tab, review the data pulled from S3 Tables.
- To add another table, select Add data from the menu. In this example, we will add the transaction_events table.
- In the Add data screen, select Data source from the dropdown list.
- Choose CustomerTrxn-S3Tables from the Select a data source list, and then choose Select.
- From the list of tables, select transaction_events and choose Select.
- Join the two tables by selecting the plus (+) icon next to the customer_master table and selecting Join.
- Configure the join using the customer_id column:
Select the Inner Join option.
- Choose transaction_events as the right table.
- Select customer_id from both the left and right tables as the join keys.
- Provide a name for the join (for example, TrxnJoin) to help identify it when working with multiple tables.
- Name the dataset in the top-left corner (for example, CxTrxn_S3TableData).
- Ensure that Direct Query mode is selected in the top-right corner. This is important to fully use near real-time data access from S3 Tables. Alternatively, you can choose SPICE mode if you prefer scheduled data refreshes rather than near real-time access.
- Choose Save & Publish.
Step 4: Interact with the dataset using Amazon Quick chat
Now let’s start chatting with this dataset to gather insights using natural language. For this, we use the default chat named, “My Assistant.”
- In the Amazon Quick home page, choose Chat agents on the left navigation panel and then My Assistant.
- Choose Chat next to the My Assistant.
- From All data and apps, choose Add and select Datasets. Then select the CxTrxn_S3TableData dataset. Choose Save.
- In the chat panel, enter “Show the total number of transactions occurred so far in this month” and press Send.
- Notice the chat response showing the total transaction count for the current month. Next, let’s ask the agent to break it down by day.
- In the chat panel, enter “break it down by day using ingestion timestamp” and press Send.
- Review the daily breakdown provided by the agent. In our example, from April 1–April 17.
Step 5: Demonstrate real-time user interaction with streaming data
Next, we test the near real-time responsiveness of the chat by streaming new transaction data. In this demo, we use AWS Lambda as a producer for a Kinesis Data Stream and then store the incoming data in an S3 table bucket as S3 Tables – in Apache Iceberg format using Firehose. As new data is streamed in, the transaction counts will automatically update within the chat without the end user needing to take any action. This demonstrates seamless near real-time data access without manual intervention or complex architecture. We run this Lambda function a few times to stream new transactional events data.
If you’re interested in creating your own streaming source for this demo, you can refer to the official AWS documentation or relevant AWS posts for detailed guidance.
Now let’s check the recently streamed data in our chat agent.
- Navigate back to My Assistant in the same chat session, enter a new prompt “Show the total number of transactions occurred so far in this month, include all recent streaming data and break it down by ingestion timestamp.” and press Send.
- My Assistant queries the CxTrxn_S3TableData dataset via Direct Query and returns the newly ingested records for April 18. This demonstrates that the recently streamed data is available without requiring a manual dataset refresh.
Cleanup
If you no longer need the resources deployed as part of this solution and want to avoid ongoing costs, we recommend that you clean up and remove the relevant components by deleting all Amazon Quick–related resources and unsubscribing from your Amazon Quick account.
Conclusion
In this post, we explored how Amazon Quick’s new Amazon S3 Tables data source enables near real-time analytics while streamlining modern data architectures. By querying Apache Iceberg tables directly in Amazon S3, it removes intermediate layers, reduces data movement, and preserves a single, governed source of truth. Additionally, you can use natural language chat experiences, like My Assistant, to access up-to-date insights effortlessly, without manual refreshes or technical overhead.
The result is a unified, AI-powered analytics experience where data, insights, and actions come together seamlessly in near real-time. Organizations can move faster, make better decisions, and unlock the full value of their data—while keeping architectures simpler, more scalable, and cost-efficient. If your use case is a typical analytical scenario sourced from scheduled data refreshes and does not require near real-time access, SPICE mode remains a suitable option. For more details on this feature, see Creating a dataset using Amazon S3 Tables.
For additional discussions and help getting answers to your questions, check out the Amazon Quick Community.
About the authors
Raji Sivasubramaniam is a Principal Solutions Architect at AWS, specializing in Agentic AI. She focuses on helping Fortune 100 and 500 organizations globally implement end-to-end enterprise solutions across Agentic AI, business intelligence, data management, and advanced analytics. Raji brings deep expertise in healthcare, with extensive experience navigating diverse datasets—including managed markets, physician targeting, and patient analytics—to drive high-impact, data-driven decision-making.
Emily Zhu is a Senior Product Manager at Amazon Quick, responsible for the full structured data stack — spanning governed and enterprise-scale data architecture, high-performance analytical and conversational query engines, and the semantic and ontology layer that gives data real meaning at scale. She’s passionate about how a strong data strategy unlocks AI strategy, and is on a mission to make the structured data stack the foundation for conversational and analytical experiences across Quick Suite.
Priya Kakarla is a Specialist Solutions Architect focused on modern analytics and AI-driven solutions, with experience across industries including healthcare, finance, and digital-native organizations. She is passionate about helping organizations unlock value from their data through scalable, intuitive, and agentic-driven approaches. Known for a strong customer-first mindset, Priya is dedicated to delivering tailored, innovative solutions that align with business goals and drive measurable outcomes. Outside of work, she enjoys traveling, exploring diverse cuisines, and spending time with family and friends.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み