mimalloc:現代向けの高パフォーマンス・スケーラブルなメモリアロケータ
Microsoft Research が開発した高性能メモリアロケーター「mimalloc」が、大規模 LLM や並行処理サービスにおいて既存の malloc を凌駕する性能を発揮し、広く採用されている。
キーポイント
現代の要件に最適化された設計
数百スレッドと数百ギガバイト規模のメモリを扱う大規模サービスや LLM に特化し、最悪ケースでの割り当て時間保証と低競合を実現している。
Microsoft 社内での実証済み実績
Bing などの主要サービスのレスポンス時間を大幅に改善し、現在 Microsoft 内外の広範な大規模サービスで採用されている。
多様なエコシステムへの統合
NoGIL CPython 3.13+ のデフォルトアロケーターや Unreal Engine、ゲーム『Death Stranding』など、多言語・多プラットフォームで利用されている。
研究由来の透明性と保守性
約 12K ラインというコンパクトなコードベースでありながら、明確な内部データ構造と不変条件を重視し、理解しやすい設計となっている。
スレッドローカルヒープによる非同期化
各スレッドが独自の「theap」を保持し、通常は同期処理やアトミック操作を必要とせずにメモリ割り当て・解放が可能になります。
小さな割り当て向けの高速パス最適化
1 KiB 未満の一般的な小規模割り当てに対して、分岐を最小限にし、フリーリストからのポップ操作のみで動作する極めて効率的なコードパスを実装しています。
特殊な初期化による分岐排除
theap やページポインタが NULL になるケースを事前に防ぐため、空の theap や空のページを初期状態で用意し、NULL チェック用の分岐を不要にしています。
影響分析・編集コメントを表示
影響分析
この技術は、大規模言語モデル(LLM)や超並列処理が主流となる現代のシステムにおいて、メモリ管理のボトルネックを解消する重要な役割を果たします。特に Python やゲームエンジンなど主要な開発プラットフォームでの採用拡大は、ソフトウェアのパフォーマンス標準そのものを引き上げる可能性があり、インフラ層における実質的なデファクトスタンダード化が進んでいます。
編集コメント
メモリアロケーターという地味なインフラ層の革新が、LLM や大規模サービスの性能向上に直結する好例です。開発者が意識しなくても恩恵を受けられる「ドロップイン」型の改善は、システム全体の信頼性を底上げします。

一言で言うと
今日の重要なサービスやアプリケーションは、しばしば高度に並列化されており、数百のスレッドを使用しています。また、特に大規模言語モデル(LLM)を利用する際には、数百ギガバイトという巨大なメモリスケールで動作することも珍しくありません。
mimalloc は、malloc および free のドロップイン代替となる、オープンソースで現代的かつスケーラブルなメモリアロケータです。比較的コンパクト(約 12K ライン)であり、内部データ構造が明確で、他のプロジェクトへのビルドや統合も容易です。ほぼ排他的にアトミック操作(atomic operations)に依存することで、最悪ケースにおける割り当て時間の上限保証(OS プリミティブまで)、空間オーバーヘッドの制限、低い内部フラグメンテーション、そして最小限の競合を実現しています。
mimalloc は GitHub で利用可能で(新しいタブで開く)、スター数は 12K を超えています。
mimalloc
マイクロソフト研究所(MSR)のリサーチグループ「RiSE」では、形式手法、プログラミング言語、ソフトウェアエンジニアリング(新興のエージェントシステムを含む)に関する基礎研究を行っており、特に証明可能な正しさ、セキュリティ、およびパフォーマンスを備えたシステムに焦点を当てています。メモリアロケータの mimalloc は 2020 年に、RiSE で開発された最先端のプログラミング言語である Lean(新しいタブで開く)と Koka(新しいタブで開く)のための高速アロケータとして最初に設計されました。これら両方の言語は、Perceus を参照するとおり、独自のコンパイラ支援型参照カウント(compiler-guided reference counting)を採用しています。
mimalloc のスケーラブルな設計は、Microsoft 内の大規模サービスにおいても極めて効果的であることが証明されています。製品チームとの緊密な協力により、Bing などのサービスにおける応答時間が大幅に改善されました。現在、mimalloc は Microsoft 内外の大規模サービスやアプリケーションで広く利用されており、NoGIL CPython 3.13+ のアロケータとして機能し、Unreal Engine に統合され、『Death Stranding』のようなゲームでも採用されています。
このプロジェクトは GitHub でオープンソース化されており、スター数は 12K を超えています。その Rust ラッパー単体でも、1 日あたり 100K 回以上のダウンロード数を記録しています。
mimalloc は、Koka や Lean のような小規模アプリケーションから、メモリ使用量が 500 GiB を超え、数百のスレッドを扱う大規模サービスに至るまで、幅広いシナリオで効果を発揮します。
この多様な対応範囲にもかかわらず、コードベースは依然としてコンパクトであり、C で約 12K 行です。その研究由来を反映し、mimalloc は明確な内部データ構造と強力な不変条件(invariants)を重視しており、多くの産業用アロケータと比較して理解や推論が容易になっています。フレッド・ブルックスは名著『The Mythical Man-Month』で既にこう述べています。「フローチャートを見せられ、表を隠されれば、私は依然として困惑するだろう。しかし、表を見せられれば、フローチャートは不要だ;それは明白だからである。」
その結果、mimalloc は Windows、macOS、Linux、FreeBSD、NetBSD、DragonFly、および各種コンソールなど、多くのプラットフォームに移植され、他のプロジェクトへのビルドと統合が容易になりました。例えば、明確なデータ構造により、Sam Gross 氏らによって mimalloc が NoGIL CPython の並列アロケータとして採用されました。この設計は、その上に循環型ガベージコレクションを実装することも比較的 straightforward にします。
高速パス
tcmalloc や jemalloc などの他のスケーラブルなアロケータと同様に、mimalloc の核心的な設計原則の一つは、各スレッドが独自の thread-local heap(スレッドローカルヒープ)を維持することであり、これを「theap」と呼びます。各 theap は一連の mimalloc ページを所有しており、通常これらは 64 KiB です。各 mimalloc ページには固定サイズのブロックが含まれており、内部断片化を削減するためにサイズクラスに整理されています。各スレッドが独自の theap と mimalloc ページのセットを持つことで、メモリ割り当てと解放は通常、同期処理なしで進行します。原子演算が必要となるのは、あるスレッドが別のスレッドによって割り当てられたブロックを解放する場合のみです。
さらに、実際にはほとんどの割り当ては非常に小さく、しばしば 1 KiB 未満です。このような小規模な割り当てに対して、mimalloc は高速パスを提供しており、主要な割り当て関数は以下のような形になります:
void* mi_malloc( size_t size )
{
mi_theap_t* const theap = mi_get_thread_local_theap();
if (size > MI_MAX_SMALL_SIZE) return mi_malloc_generic(theap,size); // slow generic path
const size_t index = (size + sizeof(void*))/sizeof(void*); // round size
mi_page_t* const page = theap->small_pages[index];
mi_block_t* const block = page->free; // head of free list
if (block == NULL) return mi_malloc_generic(theap,size); // slow generic path
page->free = block->next; // pop free list
page->used++;
return block;
}
スレッドローカルな theap を使用することで、アトミック操作やスレッド同期は不要となります。また、分岐の数を最小化することにも努めています。具体的には、スレッドローカルな theap が決して NULL になることはなく、すべてのページが空である特別な空の theap で初期化されています。これにより、theap が NULL かどうかを別途チェックする必要がありません。同様に、small_pages アレイ内のポインタも決して NULL にならず、page->free==NULL となる特別な空のページを使用することで、別のチェックを回避しています。最後に、ページは別々の bump ポインタではなく、フリーリストで初期化されています。これにより特殊なケースを避け、フリーリストからブロックをポップするだけで割り当てが可能になります。x64 環境では、このコードは現在、2 つの珍しい分岐のみを持つ少数の命令に翻訳されます。
mi_malloc:
movq %rdi, %rsi ; rsi = size
movq _mi_theap_default@GOTTPOFF(%rip), %rax
movq %fs:(%rax), %rdi ; rdi = thread local theap
cmpq $1024, %rsi ; size > MI_MAX_SMALL_SIZE?
ja .LBB0_generic
leaq 7(%rsi), %rax ; round to sizeof(void*)
andq $-8, %rax
movq 232(%rdi,%rax), %rcx ; rcx = heap->small_pages[index]
movq 8(%rcx), %rax ; block = rax = page->free
testq %rax, %rax ; block == NULL?
je .LBB0_generic
movq (%rax), %rdx ; page->free = block->next
movq %rdx, 8(%rcx)
incw 16(%rcx) ; page->used++
retq
.LBB0_generic:
jmp _mi_malloc_generic@PLT ; tailcall
同様に、mimalloc はブロックを解放する際にも高速パスを提供しています。実際には、ほとんどのブロックは、そのブロックを割り当てたのと同じスレッドによって解放されます。このケースを最適化するために、現在のスレッド ID が対応する mimalloc ページに格納されているスレッド ID と一致するかを確認できます。もし一致すれば、アトミック操作やロックを必要とせずに、単にそのブロックをページのフリーリストにプッシュするだけで済みます:
void mi_free(void* p)
{
mi_page_t* const page = mi_ptr_page(p); // get the page meta-data that contains p
if (page==NULL) return;
if (mi_thread_id() == page->thread_id) { // do we own this page?
mi_block_t* const block = (mi_block_t*)p;
block->next = page->local_free; // push on the local_free list
page->local_free = block;
if (--page->used == 0) mi_page_free(page); // is the entire page free?
}
else {
mi_free_cross_thread(page, p); // free in a page owned by another thread
}
}
最新の mimalloc v3 における mi_ptr_page 関数は、メモリ全体に対するオンデマンド割り当てマップを使用してページメタデータを取得します。以前のバージョンではアライメントのトリックを用いる方が高速でしたが、実際にはグローバルに free をオーバーライドする際に無効なポインタが mi_free に渡されることがよくあります。
別のマップを使用することで、このようなケースを効率的に検出し、ポインタが無効な場合に NULL を返すことが可能になります。具体的には、mi_ptr_page(NULL) == NULL となり、ページが NULL かどうかのみを検証するだけで余分な分岐を回避できます。また、used カウントは、ページ内のすべてのブロックが解放されたタイミングを効率的に検出するために使用されます。
ブロックをスレッド間で解放する場合、mi_free_cross_thread 関数に入り、これがアトミック操作を必要とする最初のパスとなります:
void mi_free_cross_thread(mi_page_t* page, mi_block_t* block)
{
mi_block_t* tfree = mi_atomic_load(&page->thread_free); // head of the thread free list
do {
block->next = tfree; // push our block in front
} while (!mi_atomic_compare_and_swap(&page->thread_free, &tfree /*expect*/, block /*new*/))
}
ブロックは、ページのスレッドフリーリストにプッシュすることで解放できます。これはマルチスレッド環境であるため、ブロックを原子的にプッシュするには原子比較交換(atomic compare-and-swap)操作が必要です。ただし、競合がない場合、現代のハードウェアではこれらの操作は効率的です。その理由は、キャッシュ整合性プロトコル(MOESI)に統合されているためです。
PODCAST SERIES

医療における AI 革命の再考
Microsoft のピーター・リー(Peter Lee)と共に、AI がヘルスケアにどのような影響を与え、医学の未来にとって何を意味するのかを探る旅に出ましょう。
今すぐ聴く
新しいタブで開きます
フリーリストの混乱
ページごとに 3 つのフリーリストが存在します。1 つは割り当て用、もう 1 つは解放されたブロック用の local_free リスト、そしてスレッド間で解放されたブロック用の thread_free (アトミック) リストです。これにより、固定数の割り当てが行われるとフリーリストが枯渇し、結果として稀に slower generic allocation path(より遅い汎用割り当てパス)を利用することになります。また、この仕組みは、thread-local および local のフリーリストをメインのフリーリストに戻すことで、フリーリストのクリーンアップにも利用されます。(注:実際の実装では、所有スレッドが二度と割り当てを行わない場合や長時間ブロックされる場合などのケースを適切に処理するために、より慎重な配慮が必要です。)
したがって、mimalloc では (64 KiB) の mimalloc ページごとに 3 つのフリーリストを持ち、実質的にプログラムは数千ものフリーリストを持つことになります。これは、mimalloc のスケーラビリティとキャッシュ局所性にとって不可欠な要素です。
 image高さ平衡木
image高さ平衡木
 imageランダム化された木
imageランダム化された木
この設計では、ランダム化アルゴリズムからインスピレーションを得ました。例えば、二分木のバランスを保つには、重みや深さに基づいた賢明な戦略を用いて特定の回転操作を行い平衡を維持する方法がありますが、そのようなアルゴリズムは通常非常に複雑になります。しかし、プロセスを単純化し、挿入時に分割をランダムに決定することで、偶然にも十分にバランスの取れた木が得られることもあります。
同様に、多くのマルチスレッドアロケータは、共有フリーリストへのアクセスを同期させるために洗練された並行データ構造に依存しています。一方、mimalloc はページごとのスレッド非同期フリーリストを使用しており、どのスレッドも単純な原子比較交換(atomic compare-and-swap)を使用してブロックをプッシュできます。
このようなリストが数千存在するため、複数のスレッドが同時に同じページに対してブロックを解放する確率は低くなります。その結果、ほとんどのプッシュ操作は競合のない原子更新となります。
これらのリストを 64 KiB の mimalloc ページ単位で整理することで、キャッシュの局所性が向上します。これは、他のページの解放済みオブジェクトに関わらず、アロケーションがページがいっぱいになるまで同じページ内で完結する傾向があるためです。
一方、スレッドまたはプロセスごとに単一のフリーリストを持つ設計を考えると、サイズが同じオブジェクトを解放しながら新しい構造体をアロケートする場合(ツリー変換などのワークロードで一般的なパターン)には、メモリ全体に散在する直前に解放されたブロックが再利用され、局所性が低下する可能性があります。
スレッド間の共有
スケーラビリティとスレッド間での効率的なメモリ共有の間には、根本的な緊張関係が存在します。最適にスケールさせるためには、各スレッドが独自のページを排他的に所有し、スレッド同期を最小限に抑える必要があります。一方、これによりメモリが浪費される可能性があります:あるスレッドに大量の空きブロックがあり、別のスレッドがそのサイズのブロックを割り当てたい場合、これらのページを共有または奪取できないと、代わりに新しいメモリを割り当てる必要が生じます。極端なケースとして、すべてのページを単一のロックで全スレッド間で共有することも可能です:この場合、メモリ使用量は最適化されますが、スケール性は失われます。以下のベンチマーク結果はこの緊張関係を明確に示しています:
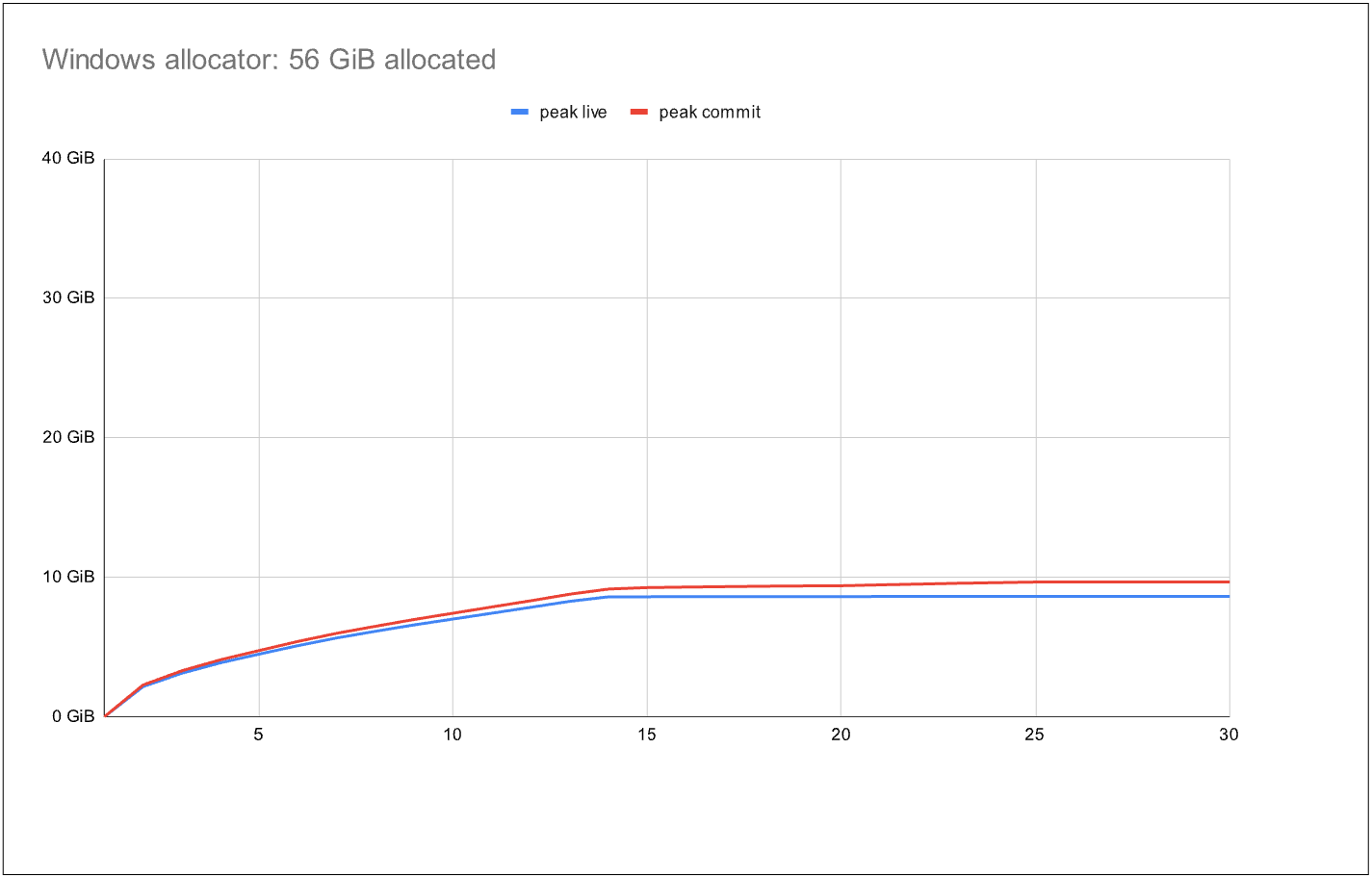 imageコミット 1.1 倍、合計 56 GiB
imageコミット 1.1 倍、合計 56 GiB
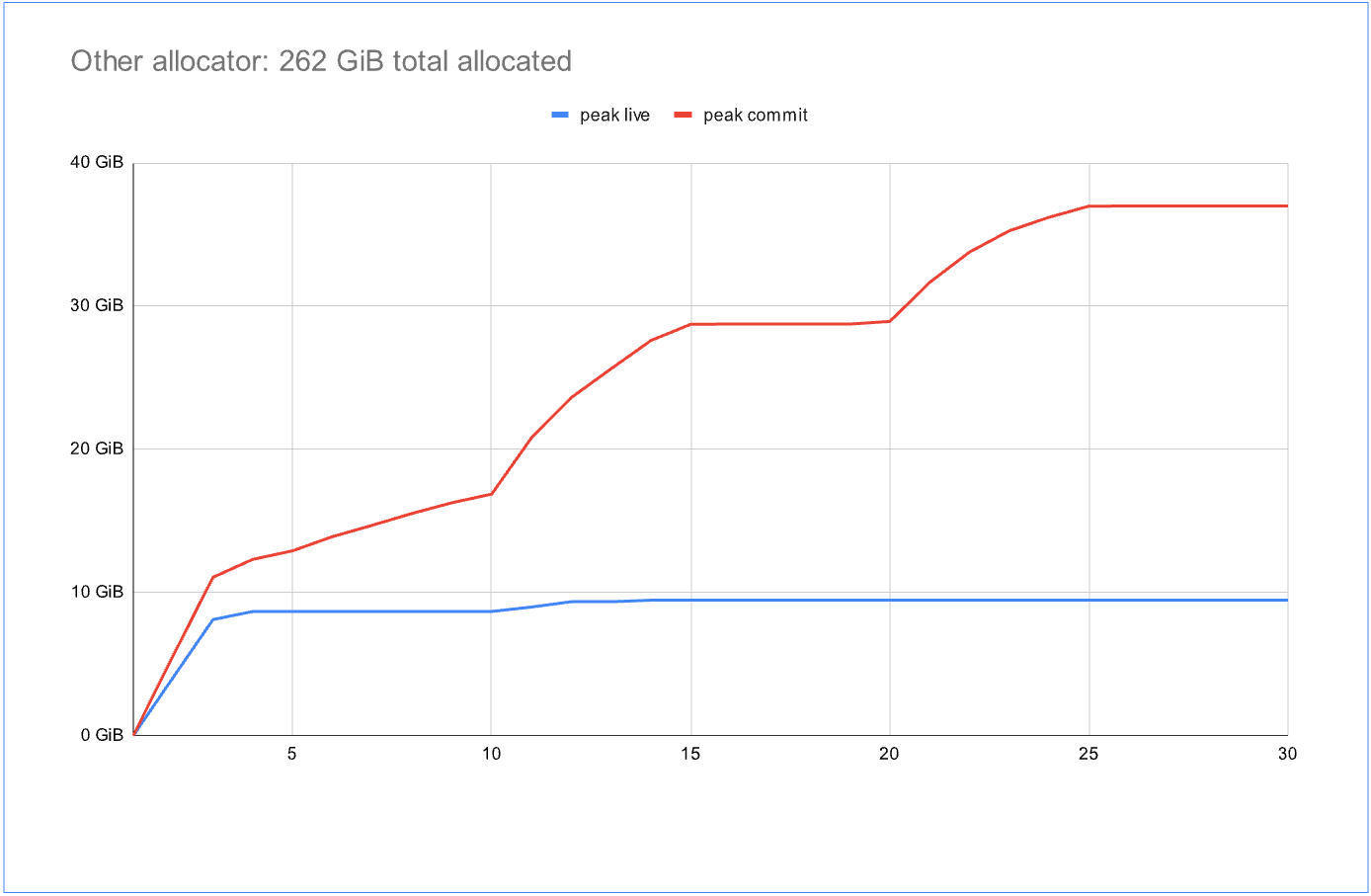 imageコミット 4 倍、合計 262 GiB
imageコミット 4 倍、合計 262 GiB
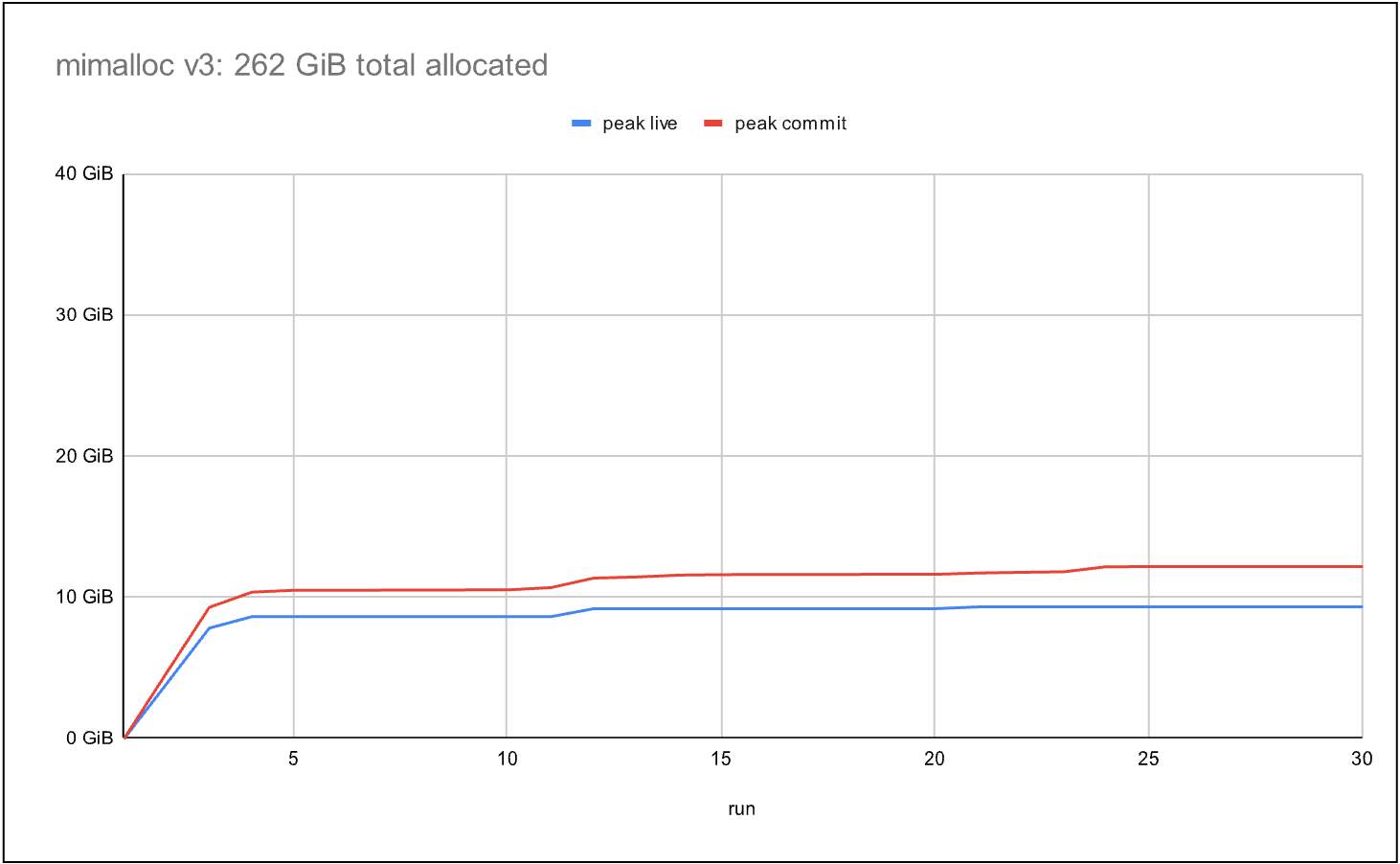 imageコミット 1.3 倍、合計 262 GiB
imageコミット 1.3 倍、合計 262 GiB
ベンチマークでは、Windows スレッドプール(約 800 のアクティブスレッド)を使用して固定時間の間に多数のタスクを実行します。これらのタスクは、割り当て、解放、および短いブロッキング期間を交互に繰り返すことで、典型的なサービスワークロードをシミュレートしています。
グラフにおいて、青い線は総ライブデータを表し、赤い線はアロケータによってコミットされた総メモリを表します。理想的な状況とは、赤い線が青い線にできるだけ近い状態です。これは標準のシステムアロケータを使用する最初のグラフでほぼ実現されています:終了時にはライブデータに対してコミット量が 1.1 倍のみであり、これは優れた結果です!しかし、ベンチマーク期間全体を通じて割り当てられたデータの総量はわずか 56 GiB でした。
これと対照的に、2 つ目のグラフにあるもう一つの高度に並列なアロケータは、ベンチマーク期間中に 262 GiB を割り当てることに成功しました。これは約 4 倍の量です。しかし、このアロケータもライブデータに対して 4 倍のメモリをコミットしてしまいました。より大きなメモリフットプリントを持つ実際のワークロードでは、このような比率はすぐに許容できなくなる可能性があります。ここで確認できるのは、標準アロケータはスケーラビリティにおいてあまり良く振る舞いませんでしたが、スレッド間でのメモリ共有においては優れた結果を示したということです。
最終的なグラフは、最新の mimalloc アロケータを示しています。2 つ目のアロケータと同様に、ベンチマーク期間中に 262 GiB を割り当てつつ、コミット済みメモリを生データ量の 1.3 倍に抑えることで、スケーラビリティとスレッド間の効率的なメモリの共有を実現しています。現代のスレッドプール実装におけるワーク・スティーリング(work-stealing)と同様に、mimalloc は「ページ・スティーリング」技術を採用しており、高価なクロススレッド同期を必要とせずに、スレッドがページの所有権を取得できるようにしています。
これらの改善点は、Microsoft の Azure Cosmos DB チームとの緊密な協力のもとで実現されました。詳細な記述はこのブログの範囲を超えますが、技術報告書をまもなく公開する予定ですので、ご注目ください。
新しいタブで開きますこの投稿「mimalloc: A new, high-performance, scalable memory allocator for the modern era」は、Microsoft Research で最初に発表されました。
原文を表示
At a glance
Today’s critical services and applications are often highly concurrent, using hundreds of threads. They also operate at large memory scales, frequently hundreds of gigabytes, especially when using large language models.
mimalloc is an open-source, modern, scalable memory allocator that is a drop-in replacement for malloc and free. It is relatively small (~12K lines), with clear internal data structures, and is easy to build and integrate into other projects. It provides bounded worst-case allocation times (up to OS primitives), bounded space overhead, low internal fragmentation, and minimal contention by relying almost exclusively on atomic operations.
mimalloc is available on GitHub (opens in new tab) and has over 12K stars.
mimalloc
At the RiSE group at Microsoft Research (MSR), we conduct fundamental research into formal methods, programming languages, and software engineering (including emerging agentic systems), with a particular focus on systems that can be provably correct, secure, and performant. The mimalloc memory allocator was initially designed in 2020 as a fast allocator for the state-of-the-art Lean (opens in new tab) and Koka (opens in new tab) programming languages developed at RiSE, both of which use novel compiler-guided reference counting (see Perceus).
The scalable design of mimalloc has also proved to work exceedingly well for large services at Microsoft. Through close cooperation with product teams, mimalloc has significantly improved the response times in services such as Bing.. Today, mimalloc is widely used in large services and applications, both within and outside Microsoft. It serves as the allocator for NoGIL CPython 3.13+, is integrated into Unreal Engine, and is used in games such as Death Stranding.
The project is open source on GitHub, with over 12K stars. Its Rust wrapper alone sees over 100K downloads per day.
mimalloc is effective across a wide range of scenarios; from small-scale applications like Koka or Lean, to large services with memory footprints exceeding 500 GiB and hundreds of threads.
Despite this range, the codebase is still compact, at around 12K lines of C. Reflecting its research origins, mimalloc emphasizes clear internal data structures with strong invariants, making it easier to understand and reason about than many industry allocators. As Fred Brooks already remarked in his famous book The Mythical Man-Month: “Show me your flowchart and conceal your tables, and I shall continue to be mystified. Show me your tables, and I won’t need your flowchart; it’ll be obvious.”
As a result, mimalloc has been ported to many platforms—Windows, macOS, Linux, FreeBSD, NetBSD, DragonFly, and various consoles—, and is easy to build and integrate into other projects. For example, the clear data structures enabled Sam Gross and others to adopt mimalloc as the concurrent allocator for NoGIL CPython. The design also makes itrelatively straightforward to implement cyclic garbage collection on top of this.
The Fast Path
As with other scalable allocators (such as tcmalloc and jemalloc), a core design principle of mimalloc is that each thread maintains its own thread-local heap, which we call a “theap”. Each theap owns a set of mimalloc “pages,” which are usually 64 KiB. Each mimalloc page contains blocks of a fixed size, organized into size classes to reduce internal fragmentation. By giving each thread its own theap and set of mimalloc pages, memory allocation and deallocation typically proceed without synchronization. Atomic operations are only required when a thread frees a block allocated by another thread.
Moreover, in practice, most allocations are quite small, often less than 1 KiB. For such small allocations, mimalloc provides a fast path where the main allocation function looks like:
void* mi_malloc( size_t size )
{
mi_theap_t* const theap = mi_get_thread_local_theap();
if (size > MI_MAX_SMALL_SIZE) return mi_malloc_generic(theap,size); // slow generic path
const size_t index = (size + sizeof(void*))/sizeof(void*); // round size
mi_page_t* const page = theap->small_pages[index];
mi_block_t* const block = page->free; // head of free list
if (block == NULL) return mi_malloc_generic(theap,size); // slow generic path
page->free = block->next; // pop free list
page->used++;
return block;
}
By using thread-local theaps, we need no atomic operations or thread synchronization. We also try to minimize the number of branches. In particular, the thread-local theap is never NULL, and we initialize it with a special empty theap with all empty pages. This way, we do not need a separate check if the theap is NULL. Similarly, the pointers in the small_pages array are never NULL, and we use again special empty pages (with page->free==NULL) to avoid a separate check. Finally, pages are initialized with a free listrather than a separate bump pointer, avoiding special cases and enabling allocation by simply popping blocks from the free list. On x64, this code now translates into few instructions with just two uncommon branches:
mi_malloc:
movq %rdi, %rsi ; rsi = size
movq _mi_theap_default@GOTTPOFF(%rip), %rax
movq %fs:(%rax), %rdi ; rdi = thread local theap
cmpq $1024, %rsi ; size > MI_MAX_SMALL_SIZE?
ja .LBB0_generic
leaq 7(%rsi), %rax ; round to sizeof(void*)
andq $-8, %rax
movq 232(%rdi,%rax), %rcx ; rcx = heap->small_pages[index]
movq 8(%rcx), %rax ; block = rax = page->free
testq %rax, %rax ; block == NULL?
je .LBB0_generic
movq (%rax), %rdx ; page->free = block->next
movq %rdx, 8(%rcx)
incw 16(%rcx) ; page->used++
retq
.LBB0_generic:
jmp _mi_malloc_generic@PLT ; tailcall
Similarly, mimalloc provides a fast path for freeing blocks. In practice, most blocks are freed by the same thread that allocated the block. We can optimize that case by checking whether the current thread ID matches the thread ID stored in the corresponding mimalloc page. If so, we can just push our block on the page’s free list without requiring atomic operations or locks:
void mi_free(void* p)
{
mi_page_t* const page = mi_ptr_page(p); // get the page meta-data that contains p
if (page==NULL) return;
if (mi_thread_id() == page->thread_id) { // do we own this page?
mi_block_t* const block = (mi_block_t*)p;
block->next = page->local_free; // push on the local_free list
page->local_free = block;
if (--page->used == 0) mi_page_free(page); // is the entire page free?
}
else {
mi_free_cross_thread(page, p); // free in a page owned by another thread
}
}
The mi_ptr_page function in the latest mimalloc v3 retrieves page metadata using an on-demand allocated map of the entire memory. In earlier versions this was faster using alignment tricks. However, in practice, invalid pointers are often passed to mi_free when overriding free globally.
Using a separate map enables such cases to be detected efficiently and return NULL when the pointer is invalid. In particular, mi_ptr_page(NULL) == NULL, which avoids an extra branch by testing only if the page is NULL. Additionally, used count is used to efficiently detect when all blocks in a page have been freed.
When a block is freed across threads, we enter the mi_free_cross_thread function—the first path that requires atomic operations:
void mi_free_cross_thread(mi_page_t* page, mi_block_t* block)
{
mi_block_t* tfree = mi_atomic_load(&page->thread_free); // head of the thread free list
do {
block->next = tfree; // push our block in front
} while (!mi_atomic_compare_and_swap(&page->thread_free, &tfree /*expect*/, block /*new*/))
}
The block can be freed by pushing it onto the thread-free list of the page. Since this is multi-threaded, it requiresan atomic compare-and-swap operation to push the block atomically. Still, on modern hardware such operations are efficient when uncontended, as their operation is integrated with the cache coherence protocol (MOESI).
PODCAST SERIES
image
The AI Revolution in Medicine, Revisited
Join Microsoft’s Peter Lee on a journey to discover how AI is impacting healthcare and what it means for the future of medicine.
Listen now
Opens in a new tab
Free list mayhem
There are three free lists per page: the free list for allocations, the local_free list for freed blocks, and the thread_free (atomic) list for blocks that were freed across threads. This guarantees that after a fixed number of allocations, the free list is exhausted, ensuring we occasionally take the slower generic allocation path. This is also used to clean up the free lists by moving thread-local and local free lists back to the main free list. (Note: Actual implementation requires more care to handle cases where the owning thread never allocates again or is blocked for a long time).
Thus, mimalloc has three free lists per (64 KiB) mimalloc page, and effectively that means that a program can easily have thousands of free lists. This is essential to the scalability and cache locality of mimalloc.
imageA height-balanced tree
imageA randomized tree
For this design, we took inspiration from randomized algorithms. For example, to balance a binary tree we can use smart strategies based on weight or depth, and perform specific rotations to keep it balanced. Such algorithms are usually quite complicated. However, we can also simplify the process and randomly decide on splits during insertion, and by sheer chance, we also end up with trees that are balanced enough.
Similarly, many multi-threaded allocators rely on sophisticated concurrent data structures to synchronize access to shared free lists. In contrast, mimalloc uses a per-page thread-free list, where any thread can push a block using a simple atomic compare-and-swap.
Because there are thousands of such lists, the probability that multiple threads concurrently free blocks to the same page is low. As a result, most push operations are uncontended atomic updates.
By organizing these lists per 64 KiB mimalloc page, cache locality is improved, as allocation tends to stay within the same page until it is full, regardless of freed objects in other pages.
In contrast, consider a design with a single free list per thread or process. When allocating a new structure while freeing objects of the same size—a common pattern in workloads such as tree transformations—allocation may reuse recently freed blocks scattered throughout memory, leading to reduced locality.
Sharing between threads
There is a fundamental tension between scalability and efficient memory sharing between threads. To scale optimally, we would give each thread exclusive ownership to its own pages to minimize any thread synchronization. On the other hand, that may lead to wasted memory: suppose a thread has large quantities of free blocks and another thread needs to allocate blocks of that size –without being able to share or steal those pages, we need to allocate fresh memory instead. In the other extreme, we could share all pages between all threads with a single lock: now memory use is optimal, but we no longer scale. The following benchmark results illustrate this tension:
image1.1x commit, 56 Gib total
image4x commit, 262 GiB total
image1.3x commit, 262 GiB Total
The benchmark runs many tasks for a fixed amount of time using the Windows thread pool with about 800 active threads. The tasks alternate between allocation, deallocation, and brief blocking periods, simulating typical service workloads. In the graphs, the blue line represents the total live data, while the red line represents total committed memory by the allocator. The ideal situation is to have the red line as close as possible to the blue line. This is almost the case for the first graph, which uses the standard system allocator: at the end there is just 1.1x more committed than live data – an excellent result! However, over the benchmark duration, it allocated a total of only 56 GiB data.
Contrast that with another highly concurrent allocator in the second graph, which was able to allocate 262 GiB over the benchmark duration—almost 4x as much. However, it also committed 4x more memory than the live data. In real workloads with larger memory footprints, such a ratio can quickly become unacceptable. Here we see that the standard allocator didn’t scale as well, but showed better cross-thread memory sharing.
The final graph shows the most recent mimalloc allocator. Like the second allocator, it allocates 262 GiB over the benchmark duration, while reducing committed memory to 1.3xthe live data, which achieves scalability and efficient memory sharing between threads. Similar to work-stealing in modern thread pool implementations, mimalloc uses a “page stealing” technique, allowing threads to take ownership of pages without expensive cross-thread synchronization.
These improvements were made in close collaboration with the Azure Cosmos DB team at Microsoft. A precise description is beyond the scope of this blog, but we will publish a technical report soon—stay tuned.
Opens in a new tabThe post mimalloc: A new, high-performance, scalable memory allocator for the modern era appeared first on Microsoft Research.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み