Amazon Bedrock AgentCoreとAmazon Nova Sonic 2.0を使用したエージェント型AI映画アシスタントで超パーソナライズされた視聴体験を提供
AWSはAmazon Bedrock AgentCoreとNova Sonic 2.0を活用し、ユーザーの気分や視聴履歴を考慮した対話型映画アシスタントの実装例とコードサンプルを公開した。
キーポイント
従来の推薦システムの文脈欠如
協調フィルタリングやコンテンツベースの手法では「時間帯」や「気分」といった文脈を捉えきれないため、生成AIと組み合わせるハイブリッドアプローチが求められている。
アジェンティックAIによる双方向体験
ユーザーのリアルタイムなフィードバックや質問に反応し、プロットや登場人物を解説する「知識豊富なキュレーター」のような対話型インターフェースを実現する。
AWSエコシステムを活用した実装アーキテクチャ
Strands Agents SDK、Amazon Bedrock AgentCore、Model Context Protocol (MCP) を組み合わせ、音声処理とコンテキスト管理を最適化する構成を示している。
影響分析・編集コメントを表示
影響分析
本記事は、単なる推薦アルゴリズムの進化ではなく、「エージェント型AI」をメディア配信プラットフォームに組み込む実装パターンを示している。MCPや専用SDKの採用により、開発者の参入障壁が下がり、次世代のパーソナライズドストリーミングサービスが普及する土壌を作る。ただし、AWS固有のクラウドリソースに依存するため、業界全体への即座な波及効果は限定的である。
編集コメント
クラウドベンダー主導の技術ブログではあるが、MCPとエージェントSDKの組み合わせにより、複雑なAIオーケストレーションの実装パターンを可視化した点は評価できる。今後はベンダーロックインの懸念をどう解決するかが、業界標準化の鍵となるだろう。
Amazon Nova Sonic 2.0 を活用したエージェント型 AI 映画アシスタントによる、超個別化された視聴体験の提供
推薦システムは現代のメディアストリーミングサービスの基盤であり、ユーザーがコンテンツを発見する方法を形作っています。従来の機械学習(ML)システムは、協調フィルタリングまたはコンテンツベースのフィルタリングを用いてコンテンツの嗜好を予測しますが、一日の時間帯や気分、社会的状況など、文脈に依存するニーズを見逃すことがよくあります。例えば、『ショーシャンクの空に』を見た後に、システムがさらに刑務所ドラマを提案し、リラックスするために軽い作品を求めている可能性を無視してしまうようなケースです。
ハイブリッドアプローチは、従来の機械学習のパターン認識能力と生成 AI の文脈理解・対話能力を組み合わせてこのギャップを埋めます。エージェント型 AI はこれを一歩進め、動的な対話を通じてユーザーと関わり、視聴の文脈について推論を行います。これらの推薦エージェントは、プロット要約、レビュー、視聴履歴など複数のソースから情報を合成し、リアルタイムのユーザーフィードバックを取り入れます。ユーザーは特定のシーンやテーマについて質問でき、エージェントは文脈に即した説明を提供します。これにより、コンテンツと個人の嗜好の両方を理解する知識豊富なキュレーターに相談するような体験が創出されます。
本稿では、ユーザーの視聴体験を向上させる 2 つのユースケースについて解説します。まず、長い一日を終えた後に「何か楽しいものが欲しい」と AI エージェントに伝えると、過去の視聴履歴だけでなく、現在の気分にも合致する推薦が得られる状況を想像してください。次に、映画鑑賞中に一時停止して「あの俳優は誰ですか?」や「直前のシーンの要約を教えてください」と問いかけると、即座に回答が返ってくる状況を思い浮かべてください。このような対話型アシスタントを構築するには、リアルタイム音声処理、文脈管理、ツール呼び出し、そして厳選された応答の調整が必要です。これは複雑な課題ですが、Strands Agents SDK、Amazon Bedrock AgentCore、および Amazon Nova Sonic 2.0 を含むエージェント型 AI ツールとフレームワークを活用することで、効率的に解決できます。このエージェント型 AI システムは Model Context Protocol (MCP) を使用し、自然な対話を通じてユーザーの好みを理解するパーソナライズされたエンターテインメントコンシェルジュを提供します。本アプリケーションのコードサンプルは、GitHub リポジトリで公開しています。
アーキテクチャ
本ソリューションのアーキテクチャは、1/映画推薦と 2/映画シーンの分析に焦点を当てています。これらのフローについては、本稿の後続セクションでより詳細に解説します。
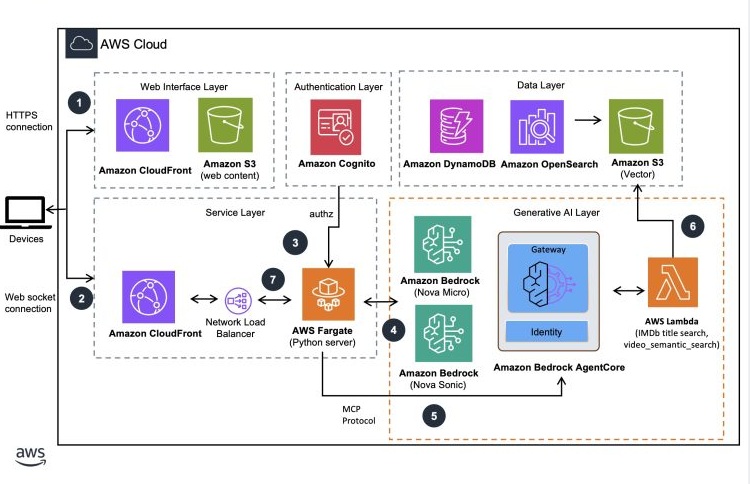
ユーザーインタラクションワークフロー
- ユーザーは、Amazon Simple Storage Service (Amazon S3) でホストされる静的ウェブサイトとして提供され、Amazon Cognito を通じて Amazon CloudFront によって配信される Web UI を介して認証を行います。
- クライアントから AWS Fargate にホストされたサーバーへ WebSocket 接続が確立されます。このサーバーは Amazon CloudFront エンドポイントを通じて公開されています。クライアントとサーバー間のセッション通信はこの接続を介して行われます。WebSocket 接続では、接続時に JWT トークンの検証が必要です。
- AWS Fargate サーバーは着信接続を検証し、Amazon Nova Sonic 2.0 をインスタンス化して、サーバーとの双方向ストリーミング通信を開始します。
- ユーザーの音声コマンドは、確立された WebSocket 接続を介して Amazon Nova Sonic モデルに送信されます。Fargate コンテナは、Nova Sonic モデルと通信するために双方向の Smithy ストリーミング RPC プロトコルを使用します。モデルからの応答はコンテナによって処理されます。
- AWS Fargate コンテナは Nova Sonic からのツールイベントを管理し、MCP サーバーを使用してユーザーリクエストを処理することで、エージェントワークフローを開始します。Amazon Bedrock AgentCore Gateway は、AWS Lambda 関数をエージェント用の MCP 互換ツールに変換する役割を果たします。
- AWS Lambda は、処理に Amazon Nova 理解モデル(micro, lite, pro)を使用し、OpenSearch と S3 ベクターを意味検索およびストレージ層として活用します。結果は Amazon Bedrock AgentCore Gateway を介してサーバーへ返されます。
- AWS Fargate は応答を Amazon Nova Sonic に送信し、最終的な音声応答の生成を行います。生成された音声応答は WebSocket 接続を介して Web UI へストリーミングされます。
自然音声ユーザーインターフェース
私たちは、低遅延で人間のような音声会話をリアルタイムに実現する最新の音声対音声モデル「Amazon Nova Sonic 2.0」を採用しています。これにより、本格的な会話のように滑らかなやり取りが可能となり、AI とのインタラクションが硬直した Q&A セッションから、動的で生産的な対話へと変革されます。タスク完了のための非同期サポート機能を活用することで、アクティブな会話中に複雑な処理をバックグラウンドで行いながら、会話を途切れさせることなく継続できます。最後に、Nova Sonic 2.0 はテキスト入力とストリーミング音声入力の両方をネイティブでサポートしており、AI アシスタントとのインタラクション方法に柔軟性をもたらします。また、会話の開始時にシステムプロンプトを提供することで、AI アシスタンの個性を定義することも可能です。アシスタントの個性を制御できる機能により、回答がブランドイメージに沿った適切な範囲内に留まり、サービスの評判を守ることに貢献します。Nova Sonic で効果的なシステムプロンプトを作成するためのベストプラクティスについては、こちらで共有しています。当ソリューションで定義された完全なシステムプロンプトは、この モジュール で確認できます。
プリプロセッシングワークフロー
以下の図は、タイトルカタログデータ、映画シーン、および映画脚本から重要なインサイトを生成するオフラインプロセスを示しています。これらのインサイトは、当ソリューションにおける映画パーソナライゼーションとシーン分析のワークフローを支援し、映画アシスタントエージェントのための基盤知識として機能します。
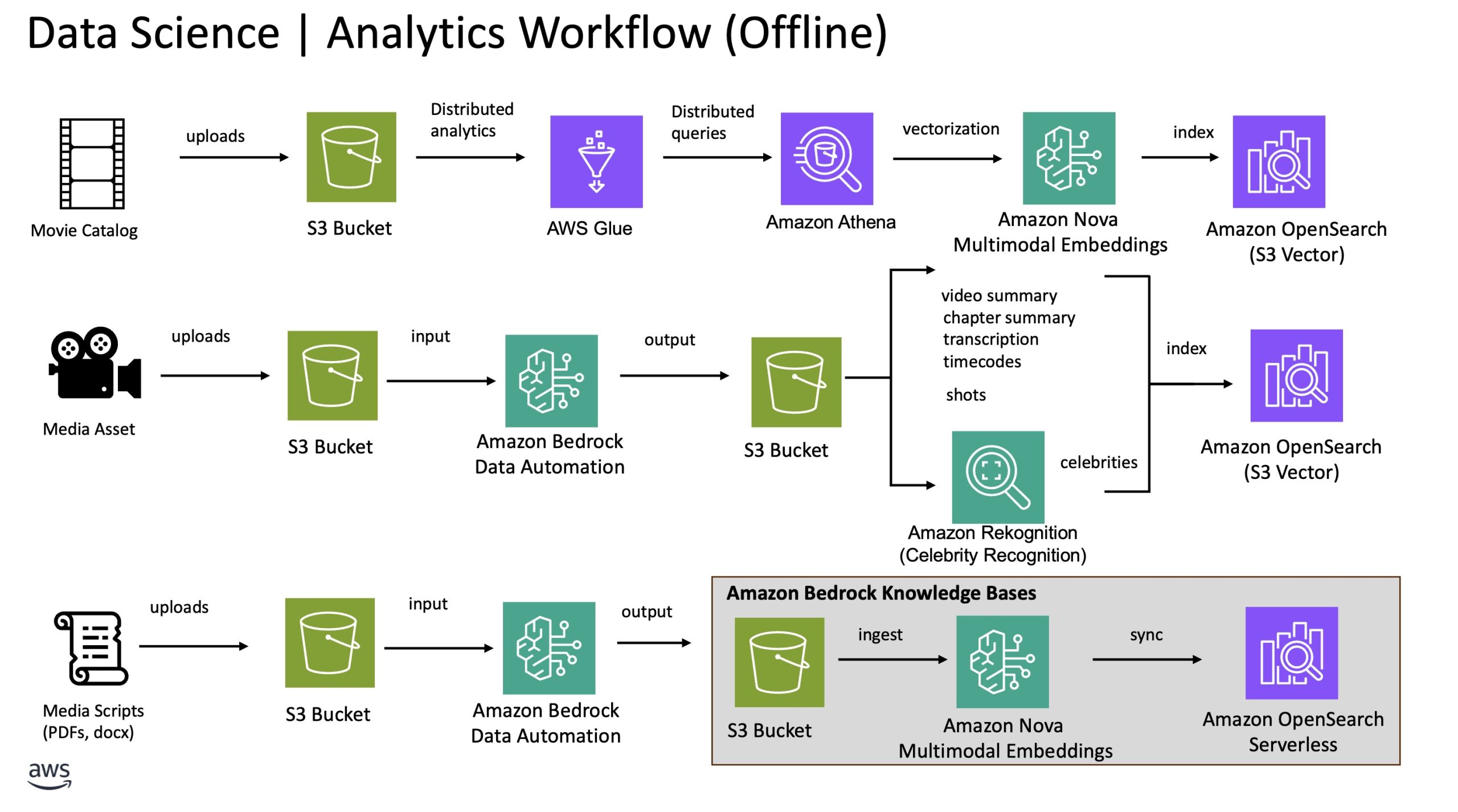
映画パーソナライゼーション機能を紹介するために、カタログを代表する 500 のサンプル映画を作成しました。タイトル、ジャンル、説明を含む映画のメタデータは、その意味を捉えた数値表現である埋め込み(embedding)に変換されます。これにより、正確なキーワードではなく意味に基づいてクエリがマッチングされるセマンティック検索が可能になります。キャストメンバーや公開日などの他のメタデータは、Amazon Simple Storage Service (Amazon S3) ベクトルをストレージ層とする Amazon OpenSearch Service クラスター内の同じインデックスに属性として保存されます。このインデックスは、前節で説明したハイブリッド検索および映画推薦ワークフローの駆動に使用されます。
高精度なシーン分析機能を有効化するために、メディアコンテンツの処理を2つのステップに分割しました。まず、Amazon Bedrock Data Automation を使用して、ビデオコンテンツから主要なインサイトを抽出します。このインサイトには、章ごとの要約と対応するタイムコード、文字起こし、音声セグメントなどが含まれます。さらに、Amazon Rekognition の有名人認識機能 を使用して、各章に登場する有名人を特定します。次に、Amazon Bedrock Data Automation を通じて抽出された映画脚本から生成された埋め込み(embeddings)を用いて、意味的類似性検索を行います。これらの埋め込みは、エージェントが与えられた映画シーン要約と一致する脚本内の最も意味的に類似した瞬間を見つけるための基盤となります。これについては後述のセクションでより詳細を説明します。
映画推薦フロー
以下のユーザーインタラクションは、コンテンツパーソナライゼーションワークフローをより詳細に示しています:

前回の図を参照すると、ユーザーが映画の推薦を求めた際、Amazon Nova Sonic はユーザーの意図を認識し、そのリクエストを処理するための適切なツールをトリガーします。AgentCore Gateway を介して Lambda 関数が起動され、リクエストが処理されます。この関数はまず DynamoDB テーブルからユーザーのアフィニティ(親和性)を取得し、ユーザーのプロファイルをより深く理解します。このテーブルは、各ユーザーの好み、嗜好、視聴パターンを表すパーソナライズされたプロファイルです。例えば、過去にハリー・ポッターシリーズを視聴したことがある場合、システムはそのユーザーに対してファンタジーやアドベンチャージャンルにより高いアフィニティを割り当てることができます。ユーザーのアフィニティとクエリを組み合わせて、一連の連鎖型大規模言語モデル(LLM)呼び出しでリクエストを処理します。まず、LLM がクエリの意図に基づいて検索タイプを分類します。この分類により、使用する適切な検索クエリを決定できます。具体的には、一般的な映画推薦、直接的な映画検索、映画のセリフ引用、あるいは映画とは全く無関係の内容などです。ここでは価格対効果に優れる Amazon Nova Micro をこのプロンプトに使用しています。意図分類やその他のメタデータを抽出するためのプロンプトは、こちらの コードサンプル で確認できます。
次に、ユーザーのクエリを別の大規模言語モデル(LLM)に送信し、映画カタログデータに対するセマンティック検索で使用できる、より豊かで関連性の高い検索クエリへと書き換えます。例えば、以下のユーザークエリ:
「面白い映画を探しています。何かおすすめはありますか?」
は以下のように書き換えられます:
「ユーモア、興奮、または楽しいストーリーテリングを提供する、面白くてエンターテインメント性の高い映画」
内部テストの結果、Amazon Nova Lite を使用することが、構造化された応答を最もコスト効率よく生成する方法であることが判明しました。完全なクエリ書き換えプロンプスのスニペットは、以下の コードサンプル で確認できます。
リライトおよび意図分類プロンプトへのクエリの出力は、Amazon OpenSearch Service の検索クエリのパラメータとして使用されます。意味検索のために、リライトされたクエリを Nova embeddings を用いて 1024 次元ベクトルに変換します。さらに、検索クエリには新規性と人気度のブーストを組み込み、ランキング上位に新しい作品や高パフォーマンスの番組を配置しています。具体的な検索クエリのスニペットは、以下の OpenSearch モジュール 内の _get_titles_from_query_v2 関数で確認できます。
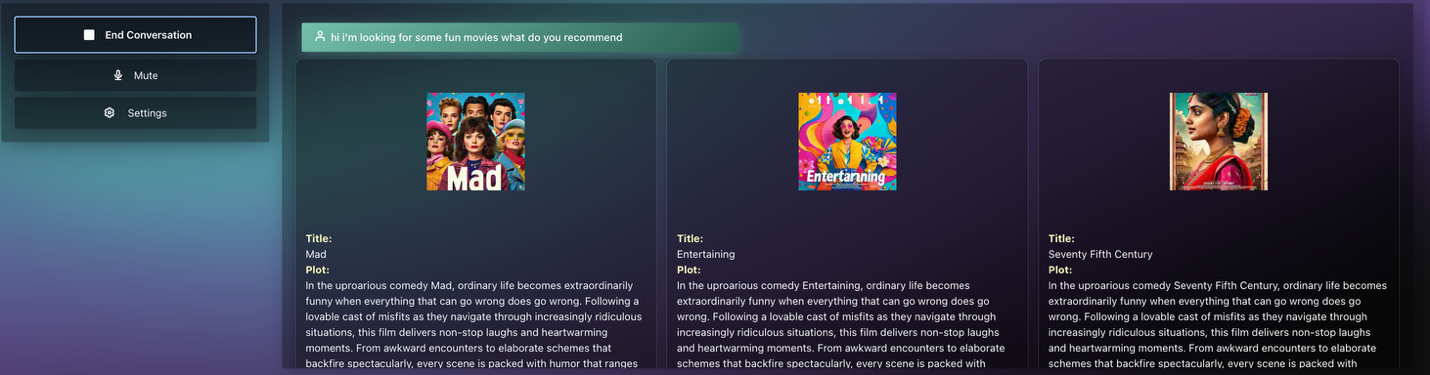
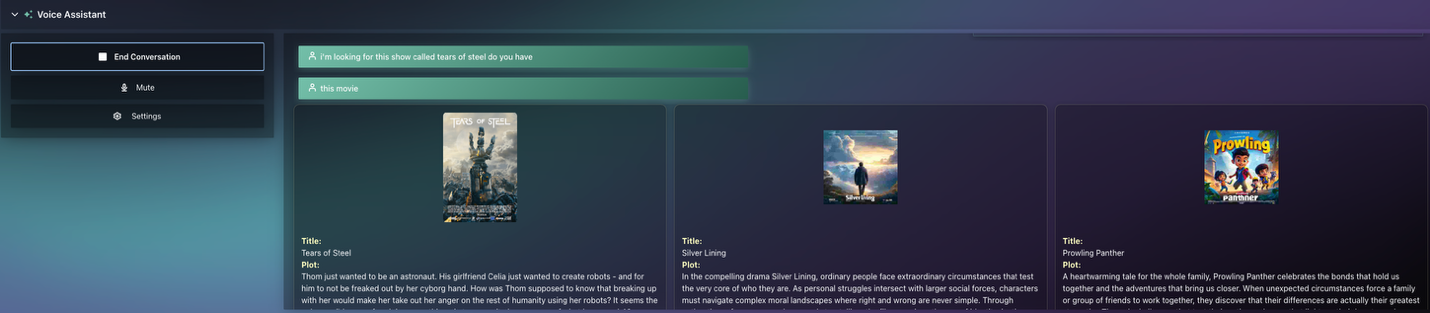
サンプル検索クエリの結果として、30 の関連する映画が返されました。最後に、Amazon Rerank モデルを使用して、検索結果とリライトされたユーザーのクエリに基づいて推薦映画の順位を再調整し、最も関連性の高い上位 3 つの映画を返します。このプロセスはユーザーセッション全体で繰り返され、会話履歴は前の LLM チェーンへの文脈の一部として組み込まれ、ユーザー体験をさらに豊かにする役割を果たします。以下に、映画推薦クエリの例を示すスクリーンショットを掲載します:
一般的な推薦リクエスト
Q: 「面白い映画を探しています。何かおすすめはありますか?」
**
Q:** 「もっと最近のものはありますか?」
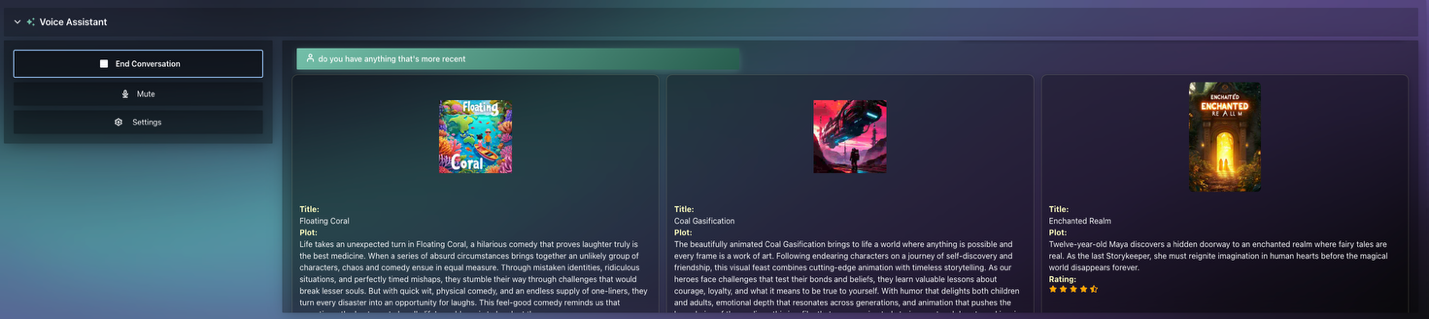
映画の直接検索
Q: 「『Tears of Steel』という映画を探しています。この映画はありますか?」
映画シーンの分析フロー
推薦のフローと同様に、ここでは同じコンポーネントを介して可能になるシーン分析のワークフローを概説します。お気に入りの番組を見ている途中で休憩が必要になり、数分見逃してしまったと想像してください。このアシスタントは、その部分の要約を提供してくれます。また、出演者やそのシーンで何が起こっているかを含む、シーンの詳細な分析も提供可能です。

ユーザーが映画を一時停止して質問をした際、アプリケーションは現在のタイムコードや映画タイトルなどの関連メタデータを取得し、後で使用するために Amazon DynamoDB テーブルに保存します。例えば、ユーザーが「このシーンで何が起こっているのか教えてくれますか?」と尋ねた場合、アプリケーションはユーザーの視聴ログを参照して、最新のステートと現在視聴中の映画を特定します。このシーンの分析は、ユーザーとの対話の文脈理解に基づいて Amazon Nova Sonic によってトリガーされるツールによって処理されます。シーン分析リクエストは、一連に連鎖された複数の LLM(大規模言語モデル)呼び出しで処理されます。まず、Amazon Nova Micro を使用し、ユーザーのクエリに基づいてシーン分析の意図を分類するプロンプトを実行します。このタスクに使用されるプロンプトは、movie scene assistant モジュール内の movieScene_classfier 関数で確認できます。
意図分類機能に基づいて、シーン詳細を処理する適切なワークフローがトリガーされます。このセクションでは、シーンレベルの詳細に焦点を当てます。取得したユーザー視聴ログを使用して、該当するタイムコードに一致する章の要約、文字起こし、および有名人情報を抽出します。映画の洞察(シーン詳細や映画脚本を含む)は、Amazon Bedrock Data Automation を用いて処理され、意味検索とフィルタリングのために Amazon OpenSearch Serverless コレクションに保存されます。ユーザー視聴ログが章の冒頭にある場合、文脈をより豊かにしてシーンの分析を支援するために、オプションで前の章の情報を含めることもあります。次に、抽出したシーン詳細を使用して、映画脚本から最も意味的に類似したセグメントを検索し、脚本の詳細情報を活用して、 enriched(拡張された)なシーン理解を提供します。このプロセスを実証するため、「Tears of Steel」の 5:15 から 5:40 の間のシーンを例として考えましょう。
Amazon Bedrock Data Automation によって生成された洞察に基づき、前のシーンの章要約は以下の通り表示されます:
歴史的なヨーロッパの都市において、大型ロボットが屋根を突き破り、破壊を引き起こしています。サイバーネット義眼を持つ男がバルコニーからロボットの動きを見守っています。彼は画面外の誰かと通信し、「彼女を中に入れろ」「残り 2 分だ」と言い、さらに「急げよ、仲間よ」と促し、時間制限のある作戦であることを示唆します。ライフルを持った別の男が現れ、ロボットへの迎撃態勢をとります。このシーンは軍事または戦術的な作戦が行われている様子で、ロボットが主要な脅威となっています。サイバーネット義眼の男はカウントダウンタイマーを監視しており、ロボットとの対峙に備えていることが示唆されます。
[spk_0]: 彼女を中に入れろ。残り 2 分だ。2 分。急げよ、仲間よ。
前記のシーン要約を用いて、Amazon Bedrock Knowledge Bases が管理する Amazon OpenSearch インデックスに対してセマンティック検索を実行します。データソースには、300 トークンのチャンクサイズと 10% のオーバーラップで前処理された映画スクリプトが含まれています。取得したドキュメントは Amazon Rerank モデルを使用して再ランク付けされ、シーンの説明の最終表現として使用されるトップセグメントが選択されます。以下は、この再ランク付けプロセスから導き出されたスクリプトセグメントの例です:
周囲を見回すと、塔の中にいるバーリーを見つけます。BARLEY:(ラジオを通じて)OK、彼らが来るぞ。残り2分!14. 内部。教会/バンカー。朝ディレクターがバーリーの声をラジオで聞いています。BARLEY:(続)(ラジオを通じて)あと2分。DIRECTOR:(ラジオから拡声器へ)スピードアップしろ、トム!ヴィヴァチッシモ!15. 外部。通り。昼トムとセリアの別れの再演が再開され、セリアは当初よりもさらに脅迫的になっています。もはや動揺しているというよりは、むしろ威圧的な態度です。CELIA: 私のロボットの手に対してビビっているだけだと認めないのか?空に新しい言葉が表示され、トムがそれを読むことになります。「セリア、私のロボットの手を愛しています」という内容ですが、トムはそれを無視することにします。6. THOM: 聞いてくれ、セリア、私は若かったんだ。でもそれが世界を破壊する理由にはならない。セリアは依然としてトムを威圧的な目でじっと見つめ続けています
原文を表示
Deliver hyperpersonalized viewer experiences with an agentic AI movie assistant using Amazon Nova Sonic 2.0Recommendation systems are the backbone of modern media streaming services, shaping how users discover content. Traditional machine learning (ML) systems use collaborative or content-based filtering to predict content preferences. However, they often miss context-dependent needs, such as time of the day, mood, or social settings. For example, after watching ‘The Shawshank Redemption,’ a system might suggest more prison dramas, ignoring that the user might want something lighter to unwind. A hybrid approach addresses this gap by combining traditional machine learning pattern-recognition capabilities with generative AI’s contextual understanding and conversational abilities. Agentic AI takes this further by engaging users through dynamic dialogue and reasoning about viewing context. These recommendation agents synthesize information from multiple sources—plot summaries, reviews, viewing history—and incorporate real-time user feedback. Users can ask about specific scenes or themes, and the agent provides contextual explanations. This creates an experience like consulting a knowledgeable curator who understands both content and individual preferences.
In this post, we walk through two use cases that help enhance the user viewing experience. First, imagine telling the AI agent that you want something fun after a long day, and getting recommendations that match how you feel and not only what you’ve watched before. Second, picture pausing midmovie to ask: “who is that actor?” or “summarize what just happened?” and getting an instant answer. Building this conversational assistant requires orchestrating real-time speech processing, context management, tool invocation, and curated responses. This is a complex challenge that we can help streamline using agentic AI tools and frameworks including Strands Agents SDK, Amazon Bedrock AgentCore, and Amazon Nova Sonic 2.0. This agentic AI system uses a Model Context Protocol (MCP) to deliver a personal entertainment concierge that understands user preferences through natural dialogue. We share the code samples for this application in the GitHub repository.
Architecture
The solution architecture focuses on 1/ movie recommendation and 2/ movie scene analysis. We elaborate on both these flows in greater detail in the subsequent sections of this post.
User interaction workflow
- User authenticates with the web UI that’s hosted as a static website on Amazon Simple Storage Service (Amazon S3) and serves through Amazon CloudFront with Amazon Cognito.
- A WebSocket connection is established from the client to the server hosted in AWS Fargate exposed using an Amazon CloudFront endpoint. The session communications between client and servers are performed through this connection. WebSocket connections require JWT token validation at connection time. The session communications between client and servers are performed through this connection.
- AWS Fargate server validates the incoming connection, instantiates a session with Amazon Nova Sonic 2.0 for bidirectional streaming communications with the server.
- User voice commands are sent to the Amazon Nova Sonic model through the established WebSocket connection. The Fargate container uses a bidirectional Smithy streaming RPC protocol to communicate with the Nova Sonic model. Responses from the model are processed by the container.
- AWS Fargate container manages the tool events from Nova Sonic and initiates an agentic workflow by using the MCP server to process user requests. Amazon Bedrock AgentCore Gateway helps transform AWS Lambda functions into MCP-compatible tools for the agent.
- AWS Lambda uses Amazon Nova understanding models (micro, lite, pro) for processing, with OpenSearch and S3 Vector serving as the semantic search and storage layers. Results are returned to the server through Amazon Bedrock AgentCore Gateway.
- AWS Fargate sends the response to Amazon Nova Sonic for the final voice response formulation. The voice response is streamed to the web UI through the WebSocket connection.
Natural speech user interface
We use Amazon Nova Sonic 2.0, our latest speech-to-speech model that delivers real-time, human-like voice conversations with low latency. This provides a user experience with fluid exchanges that feel genuinely conversational, helping transform AI interactions from rigid Q&A sessions into dynamic, productive dialogues. With asynchronous support for task completion, you can maintain fluid dialogue while processing complex tasks in the background during active conversations. Finally, Nova Sonic 2.0 natively supports both text and streaming speech inputs, giving you flexibility in how you interact with the AI assistant. You can also define the personality of the AI assistant by providing a system prompt at the beginning of the conversation. The ability to control the assistant’s personality makes sure that responses can stay on-brand and within appropriate boundaries, helping to protect your service’s reputation. We share some best practices on creating effective system prompts with Nova Sonic to help maximize the results. The complete system prompt defined in our solution can be found in this module.
Preprocessing workflow
The following diagram illustrates the offline processes that generate key insights from title catalog data, movie scenes, and movie scripts. These insights support the movie personalization and scene analysis workflows in our solution and serve as the foundational knowledge for the movie assistant agent.
To showcase the movie personalization feature, we created 500 sample movies to represent the catalog. The movie’s metadata, including title, genre, and description are converted into an embedding, a numerical representation that captures its meaning. This enables semantic search, where queries are matched based on meaning rather than exact keywords. Other metadata including cast members and released dates are stored as attributes in the same index within an Amazon OpenSearch Service cluster with Amazon Simple Storage Service (Amazon S3) Vector as the storage layer. This index is used to power the hybrid and search for movie recommendation workflow described in the previous section.
To enable the scene analysis feature with high accuracy, we split the processing of the media content into two steps. First, we use Amazon Bedrock Data Automation to extract key insights from the video content. The insights include chapter level summary and the corresponding timecodes, transcriptions, audio segments and more. Additionally, we use the celebrity recognition feature in Amazon Rekognition to identify celebrities appearing in the chapters. Second, we use the embeddings generated from the movie scripts extracted through Amazon Bedrock Data Automation for semantic similarity search. These embeddings are the foundation for which the agent uses to find the most semantically similar moments within the script that match the given movie scene summary. We provide more details on this in the later section.
Movie recommendation flow
The following user interaction demonstrates a content personalization workflow in more detail:
Referencing the previous diagram, when a user asks for a movie recommendation, Amazon Nova Sonic recognizes the user’s intent and triggers the appropriate tool to handle the movie recommendation requests. A Lambda function is triggered using AgentCore Gateway to process the request. The function first retrieves the user’s affinity from the DynamoDB table to better understand the user’s profile. This table represents a personalized profile of each user’s preferences, tastes, and viewing patterns. For instance, if the user has watched the Harry Potter series in the past, the system could assign higher affinity towards fantasy and adventure genres. Combining user affinity and the user query, we process the request in multiple large language model (LLM) calls chained in a sequence. First, an LLM classifies the type of search based on the intent of the query. The classification helps determine the appropriate search query to use. For instance, general movie recommendations, direct movie search, movie quotes, or something completely unrelated to movies. We use Amazon Nova Micro for this prompt given its price performance benefit. The prompt that extracts the intent classification, and other metadata can be found in this code sample.
Next, we send the user query to another LLM to rewrite it to provide a richer, more relevant search query that can be used for semantic search against the movie catalog data. For instance, the following user query:
I am looking for some fun movies, what do you recommend?
will be rewritten to:
Fun and entertaining movies that offer humor, excitement, or enjoyable storytelling
Through our internal testing, we found that using Amazon Nova Lite produced the structured response in the most cost optimized manner. The complete query rewrite prompt snippet is found in the following code sample.
The output from the query to rewrite and intent classification prompts are used as parameters to an Amazon OpenSearch Service search query. We convert the rewritten query into a 1024-dimension vector using Nova embeddings for semantic search. Additionally, our search query incorporates recency and popularity boosting to elevate newer, top performing shows in the recommendation rankings. An example search query snippet can found in the _get_titles_from_query_v2 function in the following OpenSearch module.
The results from the sample search query returned 30 relevant movies. Finally, we use the Amazon Rerank model to re-rank the recommended movies based on the search results and the rewritten user query to return the top three most relevant movies. This process repeats throughout the user session, with the conversation history being part of the context to the previous LLM chain to further help enrich the user experience. Here’s a screenshot of an example for a movie recommendation query:
General recommendation request
Q: “I am looking for some fun movies, what do you recommend?”
Q: “Do you have something more recent?”
Direct Movie Search
Q: “I am looking for a movie called ‘Tears of Steel’, do you have this movie?”
Movie scene analysis flow
Like the recommendation flow, here we outline a scene analysis workflow enabled through the same components. Imagine you had to take a break and missed a few minutes of your favorite show, this assistant will provide you with a summary. It can also provide you with a detailed analysis of a scene, including the actors and what’s happening in the scene.
When a user pauses the movie to ask a question, the application captures the relevant metadata such as the current timecode and movie title, then stores this information in an Amazon DynamoDB table for later use. For example, if the user asks, “Can you tell me what’s happening in this scene?”, the application references the user watch log to locate the latest state and the movie they are watching. The scene analysis is handled by a tool triggered by Amazon Nova Sonic based on the contextual understanding of the user dialog. We process the scene analysis request in multiple LLM calls chained in a sequence. First, we use Amazon Nova Micro with a prompt to classify the intent of the scene analysis based on the user query. The prompt used for this task can be found in the movieScene_classfier function in the movie scene assistant module.
Based on the intent classification functionality, we trigger the appropriate workflow to process scene details. For this section, let’s focus on the scene level detail. Using the retrieved user watch log, we extract the chapter summary, transcription, and known celebrities matching the given timecodes. The movie insights including scene detail and movie scripts, are processed using Amazon Bedrock Data Automation and stored in an Amazon OpenSearch Serverless collection for semantic search and filters. We optionally include previous chapter information when the user watch log is situated at the beginning of a chapter so that we can provide better context to help enrich the scene analysis. Next, we use the extracted scene details to find the most semantically similar segments from the movie script and use the script detail to provide the enriched scene understanding. To demonstrate this process, let’s consider a scene extracted between 5:15-5:40 from “Tears of Steel” as follows:
Based on the insights generated by Amazon Bedrock Data Automation, the chapter summary for the previous scene is shown as follows:
In a historic European city, a large robot crashes through rooftops, causing destruction. A man with a cybernetic eye watches the robot’s movements from a balcony. He communicates with someone off-screen, saying “Get her to come in” and “2 minutes left.” He then urges, “Speed it up, bud,” indicating a time-sensitive operation. Another man with a rifle appears, positioned to engage the robot. The scene shows a military or tactical operation in progress, with the robot as the primary threat. The cybernetic-eyed man monitors a countdown timer, suggesting they are preparing for a confrontation with the robot.\n[spk_0]: Get her to come in. 2 minutes left. 2 minutes. Speed it up, bud.
Using the previous scene summary, we perform a semantic search against the Amazon OpenSearch index managed by Amazon Bedrock Knowledge Bases. The data source contains the movie script preprocessed with a chunk size of 300 tokens coupled with 10% overlap. We re-rank the retrieved documents using the Amazon Rerankmodel to select the top segment to be used as the final representation of the scene description. Here’s a sample script segment derived from the reranking process:
It looks around and then spots Barley in the tower. BARLEY: (Into radio) OK, they’re coming. Two minutes left! 14. INT. CHURCH/BUNKER. MORNING The director listening to Barley over his radio. BARLEY: (CONT.) (Through radio) Two minutes. DIRECTOR: (Through radio to loudspeaker) Speed it up Thom! Vivacissimo! 15. EXT. STREET. DAY The recreation of Thom and Celia’s breakup resumes, Celia is now more threatening than she was originally, no longer upset so much as intimidating. CELIA: Why don’t you just admit that you’re freaked out by my robot hand? More words appear in the sky for Thom to read “Celia, I love your robot hand”, although he decides to ignore them. 6. THOM: Listen, Celia, I was young. But that’s no reason to destroy the world. Celia continues to stare menacingly at Th
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み