Pulse AI と Amazon Bedrock を活用した金融文書処理の構築
AWS Machine Learning Blog は、Pulse AI と Amazon Bedrock を組み合わせた金融文書処理パイプラインの構築方法を提示し、従来の OCR の限界を克服する実用的なアプローチを紹介している。
キーポイント
金融文書の複雑性と従来手法の限界
財務諸表や SEC 提出書類などの複雑な構造を持つ文書において、従来の OCR は画像として処理するだけで構造的関係や文脈を見失い、エラーが連鎖する問題がある。
Pulse AI と Amazon Bedrock の統合アプローチ
ビジョン言語モデルと古典的 ML を組み合わせた Pulse AI が、Amazon Bedrock 上のカスタマイズされた LLM と連携し、構造化データ抽出とドメイン特化型学習データの生成を可能にする。
実証された処理効率の劇的向上
従来は数日を要していた約 1,000 件の複雑な金融文書の処理が、このパイプラインにより 3 時間未満で完了し、分析用として即座に利用可能な構造化出力を生成した事例がある。
影響分析・編集コメントを表示
影響分析
この記事は、単なるツール紹介ではなく、金融業界が抱える構造的・文脈的なデータ処理の課題に対して、最新のビジョン言語モデルと LLM を組み合わせた具体的な解決策を示している点で重要です。企業にとって、高コストな手動修正や分析エラーを回避し、AI による意思決定を加速させるための実装ロードマップを提供する意義があります。
編集コメント
金融分野における AI の実用化において、単なるテキスト抽出を超えた「文脈理解」の重要性を浮き彫りにする記事です。AWS と Pulse AI の連携事例は、MLops の負担を減らしつつ高精度な業務自動化を実現するための参考モデルとして価値が高いと言えます。
金融機関は毎日数千件の複雑な文書を処理しています。財務データにおける光学式文字認識(OCR)エラーは、相互接続された計算を通じて伝播し、分析の精度に影響を及ぼします。標準的な法律文書における単一の OCR エラーが迅速な手動修正で済む場合でも、財務データにおける同じミスは相互接続された計算を通じて連鎖し、分析に体系的な誤りを生じさせ、組織にとって潜在的に高コストとなる可能性があります。
金融機関が日常的に扱う複雑な財務文書——貸借対照表、損益計算書、SEC 提出書類、調査報告書、監査資料など——の処理において、従来の OCR ツールは致命的に不十分です。これらの文書には、結合セルと階層データを持つ複雑な表構造、相互参照を伴う多段レイアウト、意味的理解を必要とする文脈依存情報が特徴としてあります。従来の OCR アプローチはこれらの文書を単なる画像として扱い、財務文書に意味を与える構造的関係や文脈の微妙なニュアンスを見逃します。その結果、手動修正の連鎖、データ入力遅延、体系的な分析エラーが生じます。
本記事では、これらの重要な課題に対処するドキュメント抽出およびモデルファインチューニングパイプラインの構築方法について解説します。Pulse AI の高度なドキュメント理解機能と Amazon Bedrock の強力な AI サービスを組み合わせることで、組織はエンタープライズグレードの精度を実現し、文脈に即した財務インサイトをスケーラブルに抽出することが可能になります。Amazon Bedrock は、ゼロの機械学習 (ML) オプオーバーヘッドで完全に管理されたモデルカスタマイズを提供し、キャパシティプランニングなしでのオンデマンド展開を可能にし、Nova モデルファミリーは優れたコストパフォーマンス特性を備えているため、チームはインフラストラクチャよりもイノベーションに注力できます。
従来のモノリシック OCR パイプラインとは異なり、Pulse はドキュメント理解のために特別に設計されたビジョンランゲージモデルと古典的 ML コンポーネントを統合し、意味論的意識を持って構造化データを抽出し、財務ドメインモデル用の改善された教師ありファインチューニングデータセットを生成し、特定の財務データでトレーニングされたカスタム大規模言語モデル (LLM) の展開を可能にする知的ソリューションを実現しています。Pulse は、Samsung、Cloudera、Howard Hughes、Fortune 500 財務機関、および高ボリュームの財務・運用ドキュメントを処理する主要なプライベートエクイティファームを含むグローバル企業に展開されています。
あるデプロイメントでは、従来は数日かかっていた約 1,000 件の複雑な金融文書のバッチ処理を、3 時間未満で完了させ、下流の分析や AI アプリケーションに即座に活用可能な構造化された監査可能な出力を生成しました。
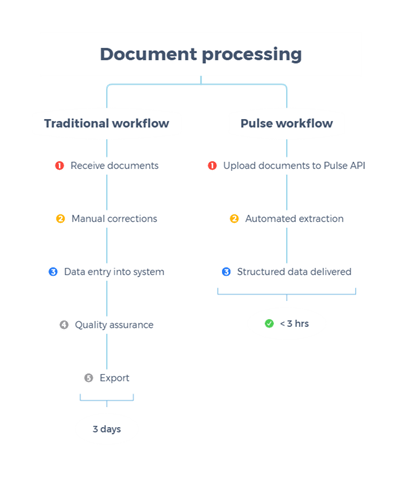
図 1: ドキュメント処理ワークフロー:従来方式 vs. Pulse
要するに、Pulse AI と Amazon Bedrock を組み合わせることで以下が可能になります:
- Pulse AI は、複雑な表、多段レイアウト、階層データを取り扱う複雑な金融文書から、構造化され意味情報を考慮したデータを抽出します。
- Amazon Bedrock は、この高品質なデータを用いて Amazon Nova モデルをファインチューニングし、組織の金融慣習に特化したドメイン固有の知能を作成します。
- カスタムモデルはその後、組織固有の理解に基づいて新しい文書を処理し、手動レビューにかかる時間を数日から数時間に短縮します。
以下のワークフローは、Pulse AI と Amazon Bedrock を活用したインテリジェントな金融アプリケーション構築のアプローチを示しています。生データである金融文書から始まり、ドキュメント処理やファインチューニング、デプロイメントに至るまで、金融データの分析と洞察に特化したカスタム AI ソリューションを創出するための複雑な一連のステップをオーケストレーションします。
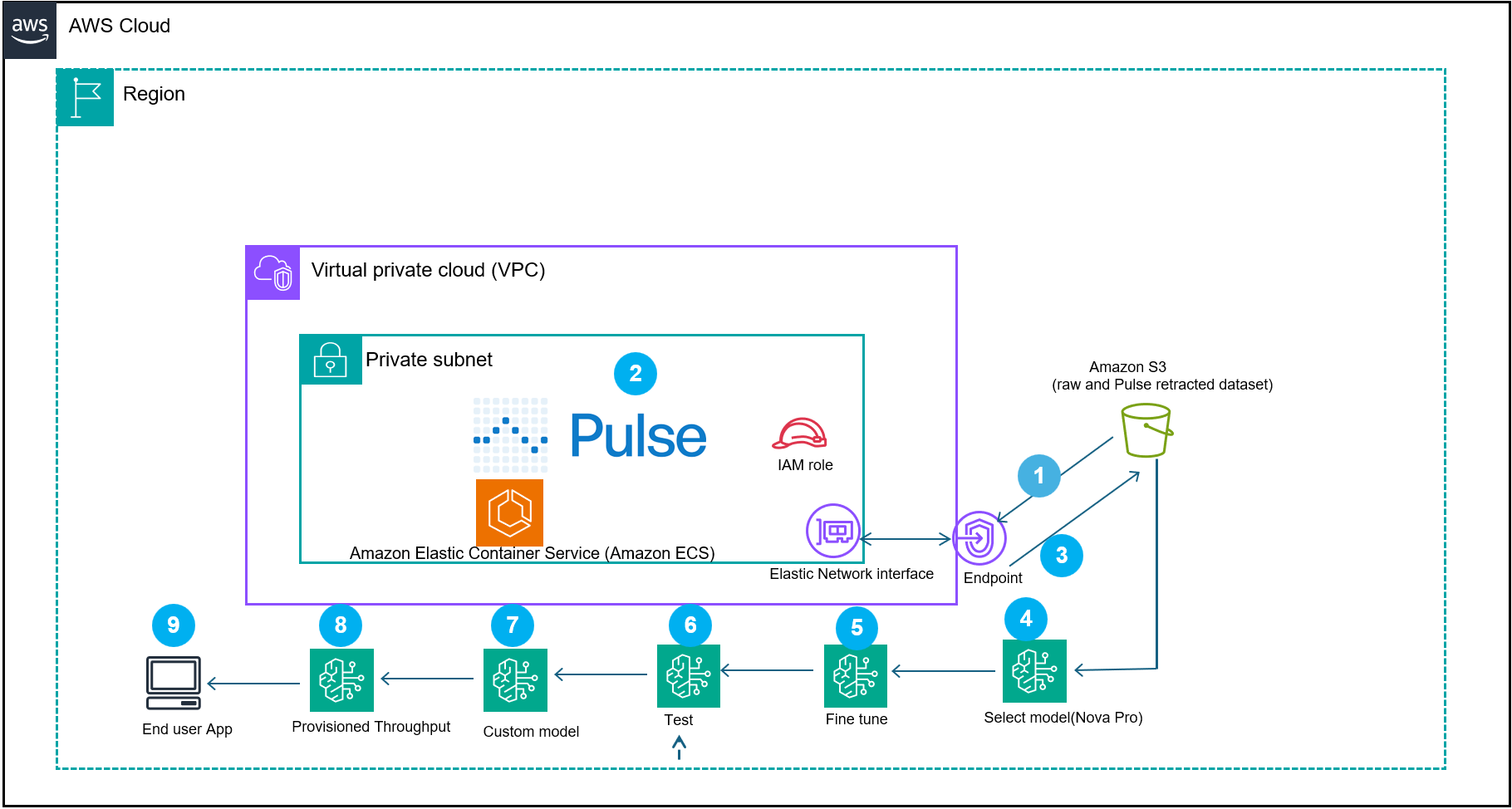
図 2: ドメイン固有モデルを構築してインテリジェントドキュメント処理(IDP)を実現する、Pulse AI と AWS サービスを統合したドキュメント処理の参照アーキテクチャワークフローを示しています。
システムはまず(ステップ 1)、VPC 内の Pulse コンテナへ、または SaaS オファリングとしての Pulse ソフトウェアへドキュメントを取り込みます。次に、Pulse モデルが財務ドキュメントを処理します(ステップ 2)。抽出されたデータの出力は、Amazon Bedrock Nova Micro の教師あり微調整形式に変換され、Amazon Simple Storage Service (Amazon S3) に保存されます(ステップ 3)。
その後、ワークフローでは Amazon Bedrock のその他の拡張機能を使用します:
教師ありファインチューニングジョブは、テキストベースの抽出タスク用に設計されたコスト効率の高いモデルである Amazon Nova Micro (amazon.nova-micro-v1:0) と、128K のコンテキストウィンドウを使用して実行されます(ステップ 5 および 6)。Nova Micro は競争力のある価格パフォーマンスを提供します。ジョブ完了後、結果として得られたモデルをオンデマンド推論用にデプロイできます。また、一貫したパフォーマンスが必要なミッションクリティカルなワークロードには、Provisioned Throughput(割り当てスループット)を使用することも可能です。*Test in Playground* を使用して応答の評価および比較を行ってください。結果として得られたカスタムモデルは Amazon Bedrock にインポートされ(ステップ 8)、スケーラブルなエンドユーザーアプリケーションを駆動するために、Provisioned Throughput でデプロイされます(ステップ 9)。このアーキテクチャは、ドメイン固有の金融データセットとカスタムの教師ありファインチューニング済みモデルを組み合わせたものであり、組織はパフォーマンスとコスト効率を維持しながら金融文脈を理解する、本番環境対応型の AI アプリケーションを構築することができます。
Prerequisites
この投稿に沿って進めるためには、以下の前提条件を満たす必要があります。
- AWS アカウント – Amazon Bedrock やデータセット用の S3 ストレージを含む AWS サービスにアクセスするために必要です。
- AWS Identity and Access Management (IAM) ポリシーで Amazon Bedrock が S3 データセットにアクセスできる権限 – Amazon Bedrock が S3 バケット内に保存されたデータを安全に読み取り、処理するための必要な権限を付与します。
- Pulse Standard アカウント(runpulse.com でサインアップ)– このワークフローで Pulse システムと統合し、その機能を利用するために必要です。
- AWS リージョン要件:us-east-1。
- Python 3.12 以降。
- インスタンスタイプ:t3.medium。
- Amazon Elastic Compute Cloud (Amazon EC2) インスタンスは時間課金されます。このチュートリアル完了後はインスタンスを停止し、継続的なコストが発生しないようにしてください。
- Amazon Linux 2023(最新バージョン)。
- 公開財務諸表:https://www.impact-bank.com/user/file/dummy_statement.pdf。
- S3 訓練データ用バケット:s3:///training-data/。
注:このチュートリアルでは、EC2 インスタンス(時間課金)、S3 ストレージ(GB-月あたり)、Amazon Bedrock のファインチューニング(トレーニング時間あたり)、プロビジョンドスループットデプロイメント(時間課金)、AWS Secrets Manager(シークレット数・月額)など、課金が発生する AWS リソースが作成されます。
ステップバイステップの実装
Pulse AI と Amazon Bedrock を使用して財務文書処理パイプラインを設定および構成するには、以下の手順に従ってください。
- Pulse コンソールにアクセスし、アカウントを作成してください。
- AWS コンソールを使用して EC2 インスタンスを起動します。
EC2 コンソールへ移動します。
- [インスタンスの起動] を選択します。
- AMI の選択画面で、Amazon Linux 2023 AMI を検索してください。
- Amazon Linux 2023 AMI を選択します。
- インスタンスタイプの画面で t3.medium を選択します。
- Linux インスタンスへの SSH アクセス用の新しいキーペアを作成します。
- セキュリティグループの設定において、ご自身の IP アドレスから SSH(ポート 22)を許可するルールを追加してください。
- [起動] を選択します。
- 成功メッセージに表示されるインスタンス ID を保存してください。
- RunPulse から API キーを作成してください。
- インスタンスのパブリック DNS を確認するには、
EC2 コンソールへ移動します。
- あなたのインスタンスを選択します。
- [詳細] タブからパブリック IPv4 DNS の値をコピーします。
- EC2 インスタンスに接続するには、以下の SSH コマンドを実行してください。YOUR_KEY_FILE.pem を実際のキーペアのファイル名に、YOUR_INSTANCE_DNS をステップ 4a で取得したパブリック IPv4 DNS の値に置き換えてください:ssh -i YOUR_KEY_FILE.pem ec2-user@YOUR_INSTANCE_DNS 例:ssh -i my-keypair.pem ec2-user@ec2-54-123-45-67.compute-1.amazonaws.com
- EC2 インスタンス上で aws configure コマンドを実行して AWS 認証情報を設定してください。プロンプトが表示されたら、Access Key ID(アクセスキー ID)、シークレットアクセスキー、リージョン(us-east-1)、出力形式(json)を入力します。
- 提供されたコマンドを使用して Pulse API キーを AWS Secrets Manager に保存してください:aws secretsmanager create-secret --name pulse-api-key --secret-string "your-api-key"
- ARN をメモしておいてください。これは権限ポリシーに必要です。
注: AWS Command Line Interface (AWS CLI) version 2 は、Amazon Linux 2023 AMI ではデフォルトで事前にインストールされています。
- EC2 インスタンスの下に runpulse SDK をインストールします。
pip のインストール:sudo yum install pip
- Pulse Python SDK のインストール:pip install pulse-python-sdk
- EC2 インスタンス上で、現在の作業ディレクトリ内に以下の構成を示す bedrock-trust-policy.json という名前のファイルを作成してください。テキストエディタの nano や vi を使用できます:nano bedrock-trust-policy.json.
bedrock-trust-policy.json の作成 {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "bedrock.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "your-aws-account-ID"
},
"ArnLike": {
"aws:SourceArn": "arn:aws:bedrock:us-east-1:your-aws-account-ID:model-customization-job/*"
}
}
}
]
}
bedrock-permissions.json の作成 {
"Version": "2012-10-17",
"Statement": [
{
"Sid": "S3AccessForFineTuning",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::your-bucket-name",
"arn:aws:s3:::your-bucket-name/*"
]
},
{
"Sid": "SecretsManagerAccess",
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue",
"secretsmanager:PutSecretValue",
"secretsmanager:CreateSecret",
"secretsmanager:UpdateSecret",
"secretsmanager:DescribeSecret"
],
"Resource": [
"arn:aws:secretsmanager:us-east-1:your-aws-account-ID:secret:your-secret-name-*"
]
}
]
}
次に、ロールを作成します:aws iam create-role --role-name AmazonBedrock-FineTuning-S3-Role --assume-role-policy-document file://bedrock-trust-policy.json --description "Role for Bedrock fine-tuning with S3 and Secrets Manager access" 期待される出力:ロール ARN、ID、および作成タイムスタンプを含む JSON。次に、
- パーミッションポリシーを作成します:
aws iam put-role-policy --role-name AmazonBedrock-FineTuning-S3-Role --policy-name Bedrock-S3-Access-Policy --policy-document file://bedrock-permissions.json
- ロールと信頼ポリシーを表示します:
aws iam get-role --role-name AmazonBedrock-FineTuning-S3-Role
- 参照となる金融文書からデータセットを抽出するには、EC2 インスタンスで以下のコマンドを実行してください
API キーを Secrets Manager から取得します。セキュリティのベストプラクティス:認証情報をハードコードしないでください。AWS Secrets Manager から取得してください。
curl -X POST https://api.runpulse.com/extract -H "x-api-key: $(aws secretsmanager get-secret-value --secret-id pulse-api-key --query SecretString --output text)" -H "Content-Type: application/json" -d '{ "file_url": "https://www.impact-bank.com/user/file/dummy_statement.pdf", "figureProcessing": {"description": true}, "extensions": {"altOutputs": {"returnHtml": true}} }' > pulse_output.json
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
Pulse AI サンプル抽出 JSON スニペット:
{"bounding_boxes":{"Header":[{"average_word_confidence":0.9940000000000001,"bounding_box":[0.7418,0.04248181818181818,0.8901529411764706,0.042281818181818184,0.8901764705882352,0.05528181818181818,0.741835294117647,0.05548181818181818],"content":"0a-Account # 12345678","id":"txt-8","original_content":"Account # 12345678","page_number":2}],"Page Number":[{"average_word_confidence":0.99425,"bounding_box":[0.8071411764705881,0.24754545454545454,0.889635294117647,0.2474909090909091,0.8896588235294117,0.2616454545454545,0.8071529411764706,0.2617],"content":"0a-Page 1 of 2","id":"txt-3","original_content":"Page 1 of 2","page_number":1},{"average_word_confidence":0.9925,"bounding_box":[0.8076235294117646,0.057600000000000005,0.8898117647058823,0.05738181818181818,0.8898705882352942,0.0704,0.8076823529411765,0.07061818181818182],"content":"0a-Page 2 of 2","id":"txt-9","original_content":"Page 2 of 2","page_number":2}],"Tables":[{"cell_data":[{"confidence":0.9772562500000003,"location":{"coordinates":[0.0906,0.44435454545454545,0.8865647058823529,0.44499090909090905,0.8865647058823529,0.4685,0.0906,0.4678636363636363],"page":1},"position":{"column":0,"row":0},"properties":{"spans_columns":4,"type":"header"},"text":"0t-"},
- 抽出が成功したことを確認するには、ファイルが存在し有効な JSON を含んでいるかを確認します。
jq empty pulse_output.json && echo "Valid JSON" || echo " Invalid JSON"
- 次に、抽出されたデータを Nova のトレーニングデータセットに変換します。
- convert_to_nova.py という名前の新しいファイルを作成し、以下のコードを貼り付けます。
import jsonINPUT_FILE = "pulse_output.json" OUTPUT_FILE = "nova_dataset.jsonl"MAX_TOKENS = 30000 # バッファは 32,768 の制限未満に設定def estimate_tokens(text): """概算トークン推定:トークンあたり約 4 文字""" return len(text) // 4def create_truncated_samples(data): """トークン制限内でより小さなトレーニングサンプルを作成します""" samples = [] # サンプル 1: ヘッダーとページ番号のみ if "bounding_boxes" in data: if "Header" in data["bounding_boxes"] and "Page Number" in data["bounding_boxes"]: header_sample = { "Header": data["bounding_boxes"]["Header"], "Page Number": data["bounding_boxes"]["Page Number"] } samples.append({ "document": header_sample, "extracted_data": header_sample }) # サンプル 2-4: 個別のテーブル(20 セルに切り詰め) if "Tables" in data["bounding_boxes"]: for i, table in enumerate(data["bounding_boxes"]["Tables"][:3]): truncated_table = { "table_info": table.get("table_info", {}), "cell_data": table.get("cell_data", [])[:20] } samples.append({ "document": {"Tables": [truncated_table]}, "extracted_data": {"Tables": [truncated_table]} }) # サンプル 5-7: テキストチャンク(各 3 項目) if "Text" in data["bounding_boxes"]: text_items = data["bounding_boxes"]["Text"] chunk_size = 3 for i in range(0, min(9, len(text_items)), chunk_size): text_chunk = {"Text": text_items[i:i+chunk_size]} samples.append({ "document": text_chunk, "extracted_data": text_chunk }) # サンプル 8: タイトルのみ if "Title" in data["bounding_boxes"]: title_sample = {"Title": data["bounding_boxes"]["Title"]} samples.append({ "document": title_sample, "extracted_data": title_sample }) return samplesdef convert_to_nova_format(sample): """ ドメイン固有の学習のための指示付きプロンプトを備えた Nova 形式に変換します。 この関数は、モデルに以下を教えるトレーニングサンプルを作成します: 1. 財務文書の構造認識(ヘッダー、テーブル、取引) 2. データ型の標準化(日付を ISO 8601 に、金額を数値に) 3. 階層関係の維持(口座 → 取引 → 詳細) 4. 順序外検出(*印付き項目) 5. 財務ドメインの慣習(小切手番号、ターミナル ID、商社データ)""" doc_str = json.dumps(sample["document"]) extract_str = json.dumps(sample["extracted_data"]) total_tokens = estimate_tokens(doc_str) + estimate_tokens(extract_str) if total_tokens > MAX_TOKENS: print(f"Warning: Sample too large ({total_tokens} tokens), skipping...") return None return { "schemaVersion": "bedrock-conversation-2024", "messages": [ { "role": "user", "content": [{"text": doc_str}] }, { "role": "assistant", "content": [{"text": extract_str}] } ] }# 入力ファイルの読み込みwith open(INPUT_FILE, "r") as f: pulse_data = json.load(f)if isinstance(pulse_data, dict): pulse_data = [pulse_data]# 切り詰められたサンプルの生成all_samples = []skipped = 0for record in pulse_data: truncated_samples = create_truncated_samples(record) for sample in truncated_samples: nova_record = convert_to_nova_format(sample) if nova_record: all_samples.append(nova_record) else: skipped += 1# JSONL 形式への書き込みwith open(OUTPUT_FILE, "w") as f: for nova_record in all_samples: f.write(json.dumps(nova_record) + "\n")print(f"✓ Created {len(all_samples)} training samples")print(f"✓ Skipped {skipped} samples that were too large")print(f"✓ Output saved to: {OUTPUT_FILE}")print(f"All samples are under {MAX_TOKENS} tokens (limit: 32,768)")print(f"Next steps:")print(f"1. Verify: wc -l {OUTPUT_FILE}")print(f"2. Upload: aws s3 cp {OUTPUT_FILE} s3://anypulse/training-data/nova_dataset.jsonl")print(f"3. Create new fine-tuning job")"""TRAINING FORMAT EXPLANATION:What this fine-tuning teaches Nova Micro:This conversion script creates training samples in a format that teaches Nova Micro domain-specific financial document understanding through pattern learning. Wh
原文を表示
Financial institutions process thousands of complex documents daily. Optical Character Recognition (OCR) errors in financial data can propagate through interconnected calculations, affecting analytical accuracy. While a single OCR error in a standard legal document might require only a quick manual correction, the same mistake in financial data can cascade through interconnected calculations, leading to systematic errors in analysis and potentially costly to organizations.
Traditional OCR tools fall critically short when processing the complex financial documents that institutions handle daily—balance sheets, income statements, SEC filings, research reports, and audit materials. These documents feature intricate table structures with merged cells and hierarchical data, multi-column layouts with interconnected references, and context-dependent information requiring semantic understanding. Traditional OCR approaches treat these documents as images, missing the structural relationships and contextual nuances that make financial documents meaningful. The result is a cascade of manual corrections, data entry delays, and systematic analytical errors.
This post demonstrates how to build a documentation extraction and model fine-tuning pipeline that addresses these critical challenges. By combining Pulse AI’s advanced document understanding capabilities with the powerful AI services of Amazon Bedrock, organizations can achieve enterprise-grade accuracy and extract contextually relevant financial insights at scale. Amazon Bedrock delivers fully managed model customization with zero machine learning (ML) ops overhead, on-demand deployment without capacity planning, and the Nova model family offers strong cost-to-performance characteristics, so teams can focus on innovation rather than infrastructure.
Unlike traditional monolithic OCR pipelines,Pulse integrates vision language models with classical ML components specifically engineered for document understanding, creating an intelligent solution that extracts structured data with semantic awareness, generates improved supervised fine-tuning datasets for financial domain models, and enables deployment of custom large language models (LLMs) trained on your specific financial data. Pulse is deployed across global enterprises including Samsung, Cloudera, Howard Hughes, and Fortune 500 financial institutions and leading private equity firms processing high volumes of financial and operational documents.
In one deployment, a batch of about 1,000 complex financial documents that previously required multi day turnaround was processed in under three hours, producing structured, auditable outputs ready for downstream analytics and AI applications.
Fig 1 : Document processing workflows: Traditional vs. Pulse
In summary, Pulse AI and Amazon Bedrock together provides:
- Pulse AI extracts structured, semantically-aware data from complex financial documents handling intricate tables, multi-column layouts, and hierarchical data.
- Amazon Bedrock fine-tunes Amazon Nova models on that high-quality data to create domain-specific intelligence for your organization’s financial conventions.
- Custom models then process new documents with organization-specific understanding, reducing manual review from days to hours.
The following workflow demonstrates an approach to building intelligent financial applications powered. Starting with raw financial documents, the pipeline orchestrates a sophisticated series of steps—from document processing and fine-tuning, and deployment—to create a custom AI solution tailored to financial data analysis and insights.
Fig 2: represents a document processing reference architecture workflow that demonstrates how Pulse AI, integrated with AWS services, creates domain-specific models for intelligent document processing (IDP)
The system begins by (step 1) ingesting the documents into the Pulse container in your VPC or Pulse software as a service (SAAS) offering. The Pulse model processes the financial documents (step 2). The output of the extracted data gets converted to Amazon Bedrock Nova Micro supervised fine-tuning format and then gets stored in an Amazon Simple Storage Service (Amazon S3) (step 3).
The workflow then uses other extended features of Amazon Bedrock:
A supervised fine-tuning job runs using Amazon Nova Micro (amazon.nova-micro-v1:0) and a cost-efficient model designed for text-based extraction tasks with a 128K context window (Step 5 and 6). Nova Micro offers competitive price performance. After job completion, deploy the resulting model for on-demand inference. You can also use Provisioned Throughput for mission-critical workloads that require consistent performance. Use *Test in Playground* to evaluate and compare responses. The resulting custom model is imported into Amazon Bedrock (step 8) and deployed with provisioned throughput (step 9) to power a scalable end-user application (step 10). This architecture combines the domain specific financial dataset with the custom supervised fine-tuned model, so organizations can build production-ready AI applications that understand financial context while maintaining performance and cost efficiency.
Prerequisites
You must have the following prerequisites to follow along with this post.
- AWS Account – Required to access AWS services, including Amazon Bedrock and S3 storage for your datasets.
- AWS Identity and Access Management (IAM) Policies allowing Amazon Bedrock access to S3 datasets – Grants the necessary permissions for Amazon Bedrock to read and process your data stored in S3 buckets securely.
- Pulse Standard Account (sign up at runpulse.com) – Required to integrate with the Pulse system and access its features for this workflow.
- AWS Region requirement: us-east-1.
- Python 3.12 or later.
- Instance type: t3.medium.
- Amazon Elastic Compute Cloud (Amazon EC2) instances incur hourly charges. Remember to terminate the instance after completing this tutorial to avoid ongoing costs.
- Amazon Linux 2023 (latest).
- Public financial statement: https://www.impact-bank.com/user/file/dummy_statement.pdf.
- S3 training data bucket: s3:///training-data/.
Note: This tutorial creates AWS resources that incur charges, including: EC2 instance (hourly), S3 storage (per GB-month), Amazon Bedrock fine-tuning (per training hour), provisioned throughput deployment (hourly), and AWS Secrets Manager (per secret per month).
Step-by-step implementation
Follow these steps to set up and configure your financial document processing pipeline using Pulse AI and Amazon Bedrock.
- Navigate to the Pulse console and create an account.
- Launch an EC2 instance using the AWS Console.
Navigate to the EC2 console.
- Choose Launch Instance.
- In the AMI selection screen, search for Amazon Linux 2023 AMI.
- Select Amazon Linux 2023 AMI.
- In the instance type screen, select t3.medium.
- Create new key pair for SSH access to the Linux instance.
- In the security group configuration, add a rule to allow SSH (port 22) from your IP address.
- Choose Launch.
- Save the instance ID that appears in the success message.
- Create your API key from the RunPulse.
- To find your instance’s public DNS,
Navigate to the EC2 console.
- Select your instance.
- Copy the Public IPv4 DNS value from the Details tab.
- To connect to your EC2 instance, run the following SSH command. Replace YOUR_KEY_FILE.pem with your actual key pair filename and YOUR_INSTANCE_DNS with the Public IPv4 DNS value from step 4a:
ssh -i YOUR_KEY_FILE.pem ec2-user@YOUR_INSTANCE_DNS Example: ssh -i my-keypair.pem ec2-user@ec2-54-123-45-67.compute-1.amazonaws.com- On your EC2 instance configure your AWS credentials by running aws configure. When prompted, enter your Access Key ID, secret access key, Region (us-east-1), and output format (json).
- Store your Pulse API key in AWS Secrets Manager using the command provided:
aws secretsmanager create-secret --name pulse-api-key --secret-string "your-api-key"- Note down the ARN, as it required for the permissions policy
Note: AWS Command Line Interface (AWS CLI) version 2 comes pre-installed on Amazon Linux 2023 AMIs by default.
- Under your EC2 instance, install the runpulse SDK.
Install pip:
sudo yum install pip- Install the Pulse Python SDK:
pip install pulse-python-sdk- On your EC2 instance, create a file named bedrock-trust-policy.json in your current working directory with the configuration shown in the following section. You can use a text editor like nano or vi: nano bedrock-trust-policy.json.
Create bedrock-trust-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "bedrock.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "your-aws-account-ID"
},
"ArnLike": {
"aws:SourceArn": "arn:aws:bedrock:us-east-1:your-aws-account-ID:model-customization-job/*"
}
}
}
]
}- Create bedrock-permissions.json
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "S3AccessForFineTuning",
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::your-bucket-name",
"arn:aws:s3:::your-bucket-name/*"
]
},
{
"Sid": "SecretsManagerAccess",
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue",
"secretsmanager:PutSecretValue",
"secretsmanager:CreateSecret",
"secretsmanager:UpdateSecret",
"secretsmanager:DescribeSecret"
],
"Resource": [
"arn:aws:secretsmanager:us-east-1:your-aws-account-ID:secret:your-secret-name-*"
]
}
]
}- Then create the role:
aws iam create-role --role-name AmazonBedrock-FineTuning-S3-Role --assume-role-policy-document file://bedrock-trust-policy.json --description "Role for Bedrock fine-tuning with S3 and Secrets Manager access"Expected output: JSON with role ARN, ID, and creation timestamp. Next,
- Create the permissions policy:
aws iam put-role-policy --role-name AmazonBedrock-FineTuning-S3-Role --policy-name Bedrock-S3-Access-Policy --policy-document file://bedrock-permissions.json
- View the role and trust policy:
aws iam get-role --role-name AmazonBedrock-FineTuning-S3-Role- To extract the dataset from the reference financial document, run the following command on the EC2 instance
Retrieve API key from Secrets Manager. Security best practice: Don’t hardcode credentials. Retrieve from AWS Secrets Manager.
curl -X POST https://api.runpulse.com/extract -H "x-api-key: $(aws secretsmanager get-secret-value --secret-id pulse-api-key --query SecretString --output text)" -H "Content-Type: application/json" -d '{ "file_url": "https://www.impact-bank.com/user/file/dummy_statement.pdf", "figureProcessing": {"description": true}, "extensions": {"altOutputs": {"returnHtml": true}} }'> pulse_output.jsonPulse AI sample extracted json snippet:
{"bounding_boxes":{"Header":[{"average_word_confidence":0.9940000000000001,"bounding_box":[0.7418,0.04248181818181818,0.8901529411764706,0.042281818181818184,0.8901764705882352,0.05528181818181818,0.741835294117647,0.05548181818181818],"content":"0a-Account # 12345678","id":"txt-8","original_content":"Account # 12345678","page_number":2}],"Page Number":[{"average_word_confidence":0.99425,"bounding_box":[0.8071411764705881,0.24754545454545454,0.889635294117647,0.2474909090909091,0.8896588235294117,0.2616454545454545,0.8071529411764706,0.2617],"content":"0a-Page 1 of 2","id":"txt-3","original_content":"Page 1 of 2","page_number":1},{"average_word_confidence":0.9925,"bounding_box":[0.8076235294117646,0.057600000000000005,0.8898117647058823,0.05738181818181818,0.8898705882352942,0.0704,0.8076823529411765,0.07061818181818182],"content":"0a-Page 2 of 2","id":"txt-9","original_content":"Page 2 of 2","page_number":2}],"Tables":[{"cell_data":[{"confidence":0.9772562500000003,"location":{"coordinates":[0.0906,0.44435454545454545,0.8865647058823529,0.44499090909090905,0.8865647058823529,0.4685,0.0906,0.4678636363636363],"page":1},"position":{"column":0,"row":0},"properties":{"spans_columns":4,"type":"header"},"text":"0t-"},- Verify the extraction succeeded by checking the file exists and contains valid JSON
jq empty pulse_output.json && echo "Valid JSON" || echo " Invalid JSON"- Next, convert the extracted data to a Nova training dataset.
- Create a new file named convert_to_nova.py and paste the following code.
import jsonINPUT_FILE = "pulse_output.json" OUTPUT_FILE = "nova_dataset.jsonl"MAX_TOKENS = 30000 # Buffer below 32,768 limitdef estimate_tokens(text): """Rough token estimation: ~4 characters per token""" return len(text) // 4def create_truncated_samples(data): """Creates smaller training samples within token limits""" samples = [] # Sample 1: Header and Page Number only if "bounding_boxes" in data: if "Header" in data["bounding_boxes"] and "Page Number" in data["bounding_boxes"]: header_sample = { "Header": data["bounding_boxes"]["Header"], "Page Number": data["bounding_boxes"]["Page Number"] } samples.append({ "document": header_sample, "extracted_data": header_sample }) # Samples 2-4: Individual tables (truncated to 20 cells) if "Tables" in data["bounding_boxes"]: for i, table in enumerate(data["bounding_boxes"]["Tables"][:3]): truncated_table = { "table_info": table.get("table_info", {}), "cell_data": table.get("cell_data", [])[:20] } samples.append({ "document": {"Tables": [truncated_table]}, "extracted_data": {"Tables": [truncated_table]} }) # Samples 5-7: Text chunks (3 items each) if "Text" in data["bounding_boxes"]: text_items = data["bounding_boxes"]["Text"] chunk_size = 3 for i in range(0, min(9, len(text_items)), chunk_size): text_chunk = {"Text": text_items[i:i+chunk_size]} samples.append({ "document": text_chunk, "extracted_data": text_chunk }) # Sample 8: Title only if "Title" in data["bounding_boxes"]: title_sample = {"Title": data["bounding_boxes"]["Title"]} samples.append({ "document": title_sample, "extracted_data": title_sample }) return samplesdef convert_to_nova_format(sample): """ Converts to Nova format with instructional prompts for domain-specific learning This function creates training samples that teach the model: 1. Financial document structure recognition (headers, tables, transactions) 2. Data type standardization (dates to ISO 8601, amounts to numbers) 3. Hierarchical relationship preservation (accounts → transactions → details) 4. Out-of-sequence detection (items marked with *) 5. Financial domain conventions (check numbers, terminal IDs, merchant data)""" doc_str = json.dumps(sample["document"]) extract_str = json.dumps(sample["extracted_data"]) total_tokens = estimate_tokens(doc_str) + estimate_tokens(extract_str) if total_tokens > MAX_TOKENS: print(f"Warning: Sample too large ({total_tokens} tokens), skipping...") return None return { "schemaVersion": "bedrock-conversation-2024", "messages": [ { "role": "user", "content": [{"text": doc_str}] }, { "role": "assistant", "content": [{"text": extract_str}] } ] }# Read inputwith open(INPUT_FILE, "r") as f: pulse_data = json.load(f)if isinstance(pulse_data, dict): pulse_data = [pulse_data]# Generate truncated samplesall_samples = []skipped = 0for record in pulse_data: truncated_samples = create_truncated_samples(record) for sample in truncated_samples: nova_record = convert_to_nova_format(sample) if nova_record: all_samples.append(nova_record) else: skipped += 1# Write to JSONLwith open(OUTPUT_FILE, "w") as f: for nova_record in all_samples: f.write(json.dumps(nova_record) + "\n")print(f"✓ Created {len(all_samples)} training samples")print(f"✓ Skipped {skipped} samples that were too large")print(f"✓ Output saved to: {OUTPUT_FILE}")print(f"All samples are under {MAX_TOKENS} tokens (limit: 32,768)")print(f"Next steps:")print(f"1. Verify: wc -l {OUTPUT_FILE}")print(f"2. Upload: aws s3 cp {OUTPUT_FILE} s3://anypulse/training-data/nova_dataset.jsonl")print(f"3. Create new fine-tuning job")"""TRAINING FORMAT EXPLANATION:What this fine-tuning teaches Nova Micro:This conversion script creates training samples in a format that teaches Nova Micro domain-specific financial document understanding through pattern learning. Wh
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み