私が構築してきたもの:ATOMレポート、ポストトレーニング講座、書籍の完成、そして継続的な研究
ATOMプロジェクトの「ATOM Report」公開、RLHFに関する書籍の出版準備完了、およびポストトレーニングコースの開発という、オープンモデル生態系と教育リソースに関する複数のプロジェクトの進捗報告。
キーポイント
ATOM Reportの公開とRAM指標
オープン言語モデル生態系への投資を主張する「The ATOM Project」の技術報告書を更新し、Relative Adoption Metric (RAM) を用いて中国勢やGemma 4などの早期採用状況を定量的に分析した。
RLHF書籍の出版準備完了
ポストトレーニング領域の入門者向けに執筆した書籍「RLHF Book」が編集作業を終え、印刷へ向けてManning出版社と連携中であり、プレオーダーが可能になっている。
付随する教育リソースの開発
書籍と連動して、ポストトレーニングに関するコースやコード開発を進めており、技術的な理解を深めるための実践的な教材を提供する予定である。
Post-training学習コースの構築
書籍を単なるリソースから包括的な学習体験へと拡張し、YouTubeで無料公開される講義シリーズとコミュニティQ&Aを作成中。
マルチターン対話とエージェント研究へのシフト
TurnWine論文を通じてマルチターン対話の特性を調査し、エージェント分野において効率的なタスク解決のためのユーザーインターフェース問題に注力している。
自己反映を用いたメタ強化学習研究
Xiaoらによる論文で、エージェント検索における自己反映(self-reflection)を活用したメタ強化学習手法に関する研究に携わっている。
RLVRをメタ学習問題として定式化
過去の試行からのコンテキストを活用して将来のロールアウトを改善するメタ学習問題として、困難な問題解決を強化学習による検証(RLVR)で扱う。
重要な引用
The ATOM Report is dense with the methods Florian and I use to keep track of the open ecosystem.
The goal of this book was to write the book I wished I had when I was getting started in post-training language models.
The RAM score is designed so that a score >1 indicates a model is, at that point in time, on track to be a top 10 most downloaded model of its size category, ever.
"The goal of my book is for it to be the central resource for people looking to transition from beginner to expert in post-training."
"My interests here have fully shifted to agents, where I see multi-turn interactions as a very important user interface problem"
This paper frames solving hard problems with RLVR as a meta-learning problem, where context from previous attempts should be used to inform future rollouts.
影響分析・編集コメントを表示
影響分析
この記事は、特定の技術革新そのものよりも、オープンソースLLMエコシステムの可視化と教育インフラの整備という「生態系構築」の側面に重点を置いています。RAM指標のような定量的評価手法の公開は、投資家や開発者がオープンモデルの選別を行う際の基準として活用される可能性があります。また、RLHF書籍の出版は、専門知識の民主化を促進し、業界全体のスキル向上に寄与する中長期的な影響を持ちます。
編集コメント
個別のモデルベンダーへの言及は限定的ですが、RAM指標のような定量的評価フレームワークの公開は、オープンモデル市場の透明性向上に寄与する重要な動きです。教育リソースの充実も合わせて注目すべきトピックです。
この投稿は、個別の「Interconnects」記事にするほどではないが、私が最近取り組んでいること、それらに時間を割く理由、そしてその成果をまとめたものです。
ATOMレポート:オープン言語モデルエコシステムの測定
RLHF本の完成と予約注文開始!
作成中のポストトレーニング講座
最近の技術的研究
共有
- ATOMレポート:オープン言語モデルエコシステムの測定
https://arxiv.org/abs/2604.07190
2025年8月に当初ローンチされた、米国におけるオープンモデルへの投資を主張するマニフェストとも言うべき「The ATOM Project」メモに付随するものとして、最新のデータ、分析、そしてオープン言語モデルエコシステム内のストーリーテリングを含む更新版技術レポートを公開しました。ATOMレポートには、Florianと私がオープンエコシステムを追跡するために使用する手法が凝縮されており、GPT-OSSの台頭、推論(inference)市場シェア、Moonshot、Z.ai、MiniMaxなどの中国の中堅プレイヤーの影響、米国におけるオープンモデルの進捗の兆しなどが網羅されています。
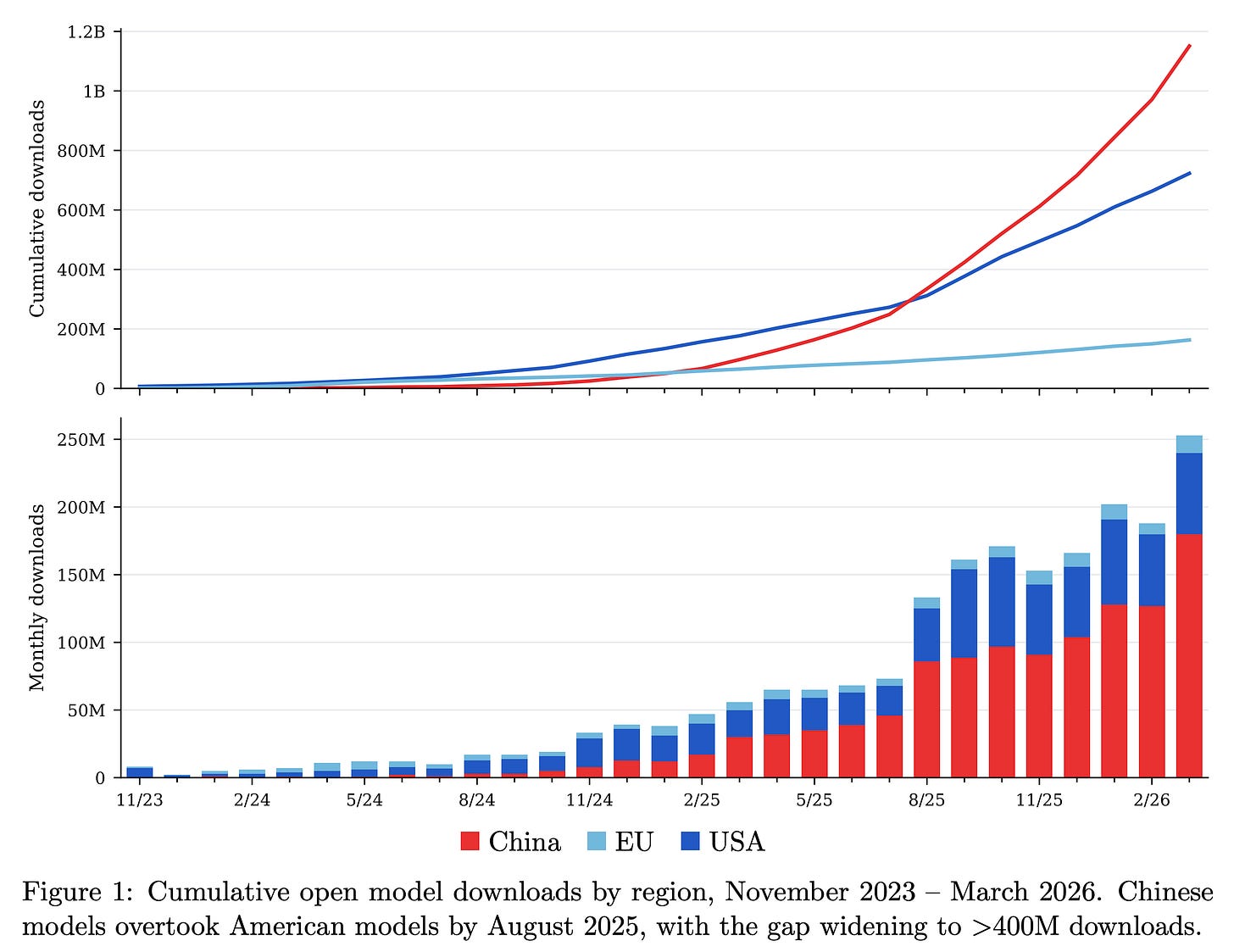
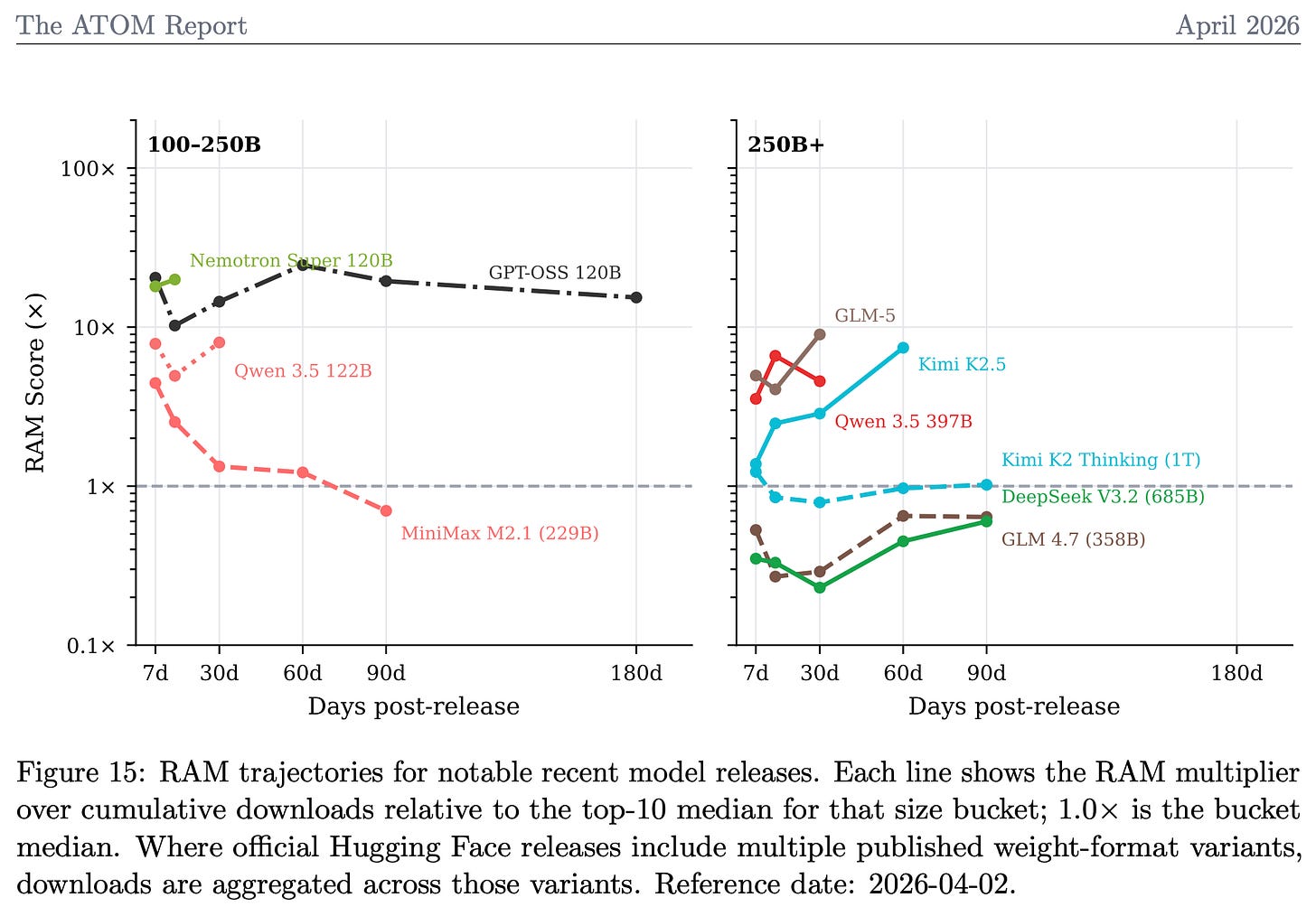
特に、本論文ではRelative Adoption Metric(RAM)の更新内容を詳述しています。この指標は、時系列かつサイズ正規化された方法で、最近のモデルの普及度を評価するために使用しています。以下は、RAMスコアにおける主な中国製モデルのサンプルです。RAMスコアの設計上、1より大きい値は、その時点においてそのサイズのカテゴリで過去最高のダウンロード数トップ10に入る見込みがあることを示します。複雑な状況を、解釈しやすい単一の数値に簡素化したのです!
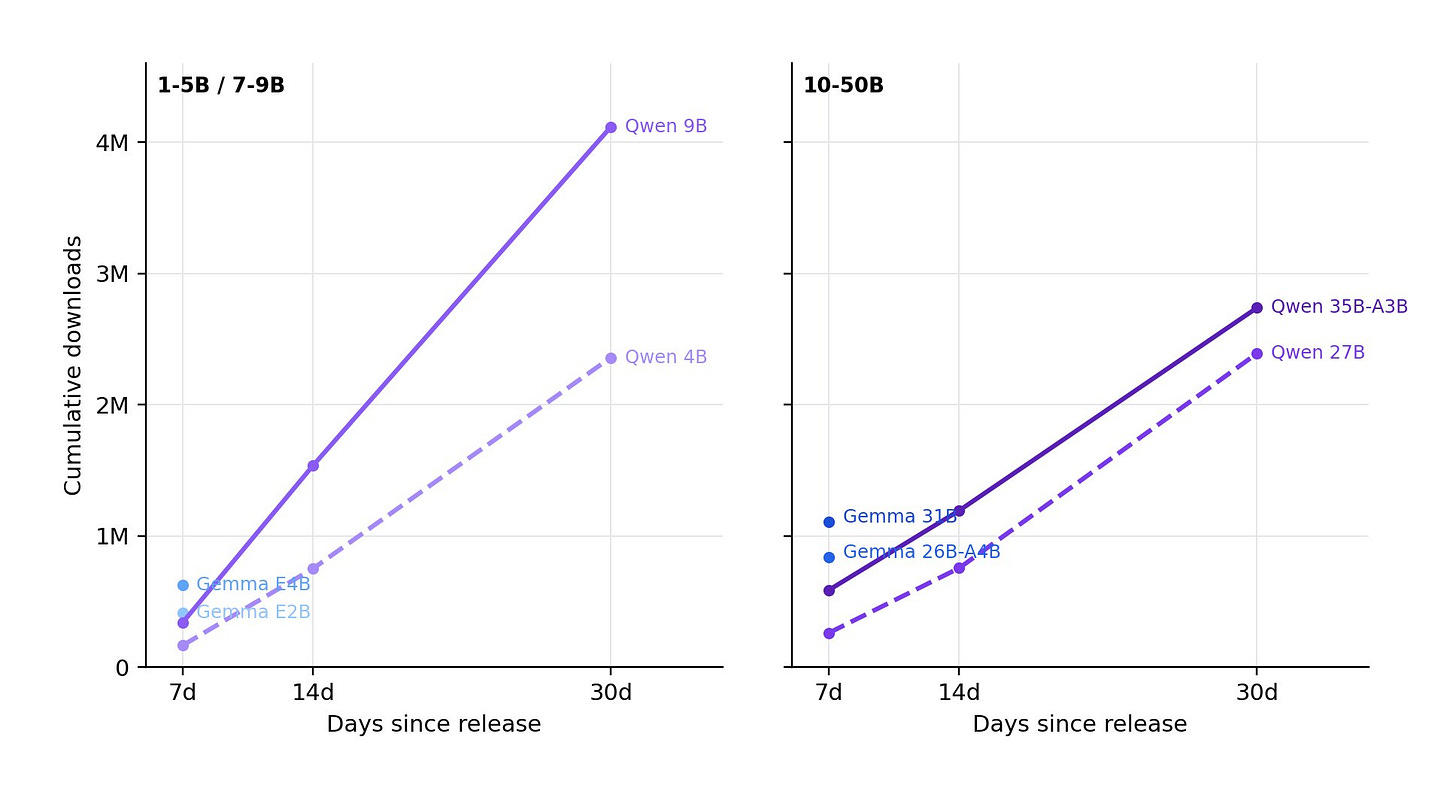
また、このデータを用いて、初期の普及数が非常に高いGemma 4のリリースについても分析を行いました。今後の動向にも注目していきます!
この種のアップデートを受け取るには、(不定期に更新される)ATOM ProjectのSubstackに登録してください!
- RLHFに関する書籍が完成し、予約注文が可能になりました!
http://rlhfbook.com/
この本の目標は、ポストトレーニング言語モデルの分野でキャリアを始めた際に、自分自身があればよかったと思うような本を書くことでした。このプロジェクトは長年にわたり私の頭の中にあり、2024年5月20日にドメイン rlhfbook.com を購入し、より本格的に取り組み始めました。そして今、ここにいます!
先週、Manning チームへ納品されました。これはコンテンツの編集が完了し、約2ヶ月後に印刷版が発行されることを意味します。その間、私は関連するコードとコースの開発に時間を費やしています(詳細は後述)。
Amazon または Manning で予約購入できます(現在、Manning の方が安価です)。

- 作成中のポストトレーニング講座
https://rlhfbook.com/course
私の本の目標は、ポストトレーニングにおいて初心者から上級者への移行を目指す人々にとっての中核的なリソースとなることです。必ずしも入門書というわけではありませんが、AI モデルが強化するにつれて、これはコミュニティ形成の取り組みでもあります。単なる本から完全な学習体験へと範囲を広げるために私が取った最初のステップは、講義シリーズの構築です。この講義は YouTube で無料で公開され、コミュニティからの質問と回答(講義間のスタンドアロン動画として)を組み込みます。
以下の最初のバッチの動画をご覧いただき、YouTube でチャンネル登録して今後の動画もご覧ください。今夏は、書籍のコードベースを開発し、対面イベントを開催しながら、書籍プラットフォームをさらに強化していく予定です。
ウェルカム動画と YouTube プレイリスト
RLHF とポストトレーニングの概要 | RLHF 書籍講座、講義 1
RLHF の基礎、IFT(Instruction Fine-Tuning)、報酬モデル、拒否サンプリング | RLHF 講座 講義 2
LLM における強化学習のためのポリシー勾配アルゴリズムの理解 | RLHF 講座 講義 3
LLM 向けの強化学習アルゴリズムの実装 | RLHF 講座 講義 4

- 最近の技術的研究
Interconnects の長年の読者ならご存知のとおり、このブログは分野における基礎研究の解説にルーツを持っています。これには二つの側面で極めて大きな価値があります。第一に、AI が驚くべき速さで進化している現在、より多くの人々が研究を解析して技術に対する正しい判断を下せるようになる必要があります。研究は、大きな変化が訪れることへの唯一の早期警報です。第二に、それは私の協力者たち、つまり私が生涯を共にする人々のキャリア向上に寄与します。その点で、以下の特権的な機会をいただいた二つの論文をご一読ください。
https://arxiv.org/abs/2603.16759 - TurnWise: The Gap between Single- and Multi-turn Language Model Capabilities, Graf et al. 2026
この研究では、マルチターン対話環境における各種モデルの強み、それを改善するためのトレーニングデータ作成方法、およびポストトレーニングにおけるその他の特性について探求しています。ここで私の関心は完全にエージェントへとシフトしており、マルチターン対話を非常に重要なユーザーインターフェース問題として捉えています。具体的には、手抜きをせず、いかに早くタスクを解決するためにユーザーにどのような情報を提示すべきかという問いです。
https://arxiv.org/abs/2603.11327 - Meta-Reinforcement Learning with Self-Reflection for Agentic Search, Xiao et al. 2026
この論文は、RLVR(Reinforcement Learning with Verifiable Rewards:検証可能な報酬を用いた強化学習)を用いて難問を解決することをメタラーニング問題として位置づけています。過去の試行からのコンテキスト(文脈)を活用して、将来のロールアウト(実行計画)にフィードバックを与えるというアプローチです。これはある意味で非常に自明なアイデアであり、LLM(Large Language Model:大規模言語モデル)の強化学習の大部分がまだオンポリシー(on-policy)でありながら幼稚な状態にあることに起因しています。モデルはパラメータ内での最近の試行から学習しますが、コンテキスト内からは学習しません。この研究は、強化学習を異なる形態の継続的学習(continual learning)を解決するために定式化する方法に関する、他の多くの最近の研究に繋がっています。また、関連する素晴らしい論文として「Learning to Discover at Test Time」があります。
コメントを残す
私は今後数ヶ月以内に中国(そして hopefully ワシントンD.C.)へ向かい、世界がAIの進歩をどのように見ているのかについてさらに学びたいと考えています。私のFocused technical job(集中した技術職)では通常接する範囲よりも、より多様な人々と話すことを楽しみにしています。いつも通り読んでいただき、ありがとうございます!
原文を表示
This post is a roundup of my recent efforts that did not warrant a standalone Interconnects post, why I’m spending time on them, and what they accomplished.
The ATOM Report: Measuring the Open Language Model Ecosystem
RLHF Book is done & ready for pre-order!
A post-training course I’m making
Recent technical research
Share
- The ATOM Report: Measuring the Open Language Model Ecosystem
https://arxiv.org/abs/2604.07190
To accompany The ATOM Project memo, arguably a manifesto, making the case for investment in open models in the U.S. – originally launched in August 2025 – we’ve released an updated technical report with our latest data, analysis, and storytelling within the open language model ecosystem. The ATOM Report is dense with the methods Florian and I use to keep track of the open ecosystem. It covers GPT-OSS’s rise, inference market share, the influence of China’s mid-tier players like Moonshot, Z.ai, & MiniMax, signs of the U.S.’s progress on open models, and much more.
In particular, the paper details our updates to the Relative Adoption Metric (RAM), which we use to evaluate the adoption of recent models in a time-varying and size-normalized manner. Here’s a sampling of recent, primarily Chinese, models on the RAM score. The RAM score is designed so that a score >1 indicates a model is, at that point in time, on track to be a top 10 most downloaded model of its size category, ever. It reduces a messy landscape to one, easily interpretable number!
We used the data to also analyze the recent Gemma 4 release, which is showing incredible early adoption numbers. We’ll stay tuned on it!
Subscribe to the (infrequent) ATOM Project Substack for more updates like this!
- RLHF Book is done & ready for pre-order!
http://rlhfbook.com/
The goal of this book was to write the book I wished I had when I was getting started in post-training language models. This project has been on my mind for a long time. I bought the domain rlhfbook.com and started to take it more seriously on May 20th, 2024. Here we are!
Last week, it was sent to production with the Manning team. This means content edits are done, and it’ll be sent to print in ~2 months. In the meantime, I’m spending my time developing the accompanying code and course (more on that below).
You can preorder on Amazon or Manning (currently cheaper).
- A post-training course I’m making
https://rlhfbook.com/course
The goal of my book is for it to be the central resource for people looking to transition from beginner to expert in post-training. It’s not necessarily an entry-level book, but as AI models become stronger, it needs to be a community-building effort as well. The first step I’ve made to expand the scope from just a book to a complete learning experience is building a lecture series. The lectures will be freely available on YouTube and incorporate community questions & answers (as standalone videos in between lectures).
You can watch the first batch of videos below, and subscribe on YouTube for future ones. I’m going to build on the book platform more this summer, as I develop the book codebases and host in-person events.
Welcome video & YouTube playlist
RLHF and Post-training Overview | RLHF Book Course, Lecture 1
RLHF Foundations, IFT, Reward Modeling, Rejection Sampling | RLHF Course Lecture 2
Understanding Policy Gradient Algorithms for RL on LLMs | RLHF Course Lecture 3
Implementing RL Algorithms for LLMs | RLHF Course Lecture 4
- Recent technical research
Long-time followers of Interconnects know that this blog has its roots in explaining fundamental research in the field. This has immense value in two ways. First, as AI moves incredibly fast, far more people need to be able to parse research to make the right bets on the technology. Research is the only early warning of some big changes coming. Second, it helps uplift the careers of my collaborators – the people I spend my life with! On that note, check out two papers I had the privilege of being part of below.
https://arxiv.org/abs/2603.16759 - TurnWise: The Gap between Single- and Multi-turn Language Model Capabilities, Graf et al. 2026
This work explores the strengths of various models in multi-turn dialogue settings, how to create training data to improve it, and other quirks in post-training. My interests here have fully shifted to agents, where I see multi-turn interactions as a very important user interface problem — what information do I show to the user to solve the task as soon as possible without cutting corners?
https://arxiv.org/abs/2603.11327 - Meta-Reinforcement Learning with Self-Reflection for Agentic Search, Xiao et al. 2026
This paper frames solving hard problems with RLVR as a meta-learning problem, where context from previous attempts should be used to inform future rollouts. It’s a very obvious idea in some ways, where most of RL for LLMs is still very on-policy, but naive. The models learn from recent trials in parameters, but not in context. This research feeds into a ton of other recent work on ways that RL can be formulated to solve different forms of continual learning. Another great related paper is Learning to Discover at Test Time.
Leave a comment
I’m off to China (and then hopefully DC) in the next couple of months to learn even more about how the world sees progress in AI. I’m excited to talk to a broader range of people than I tend to in my focused technical job. Thanks for reading, as always!
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み