Claude Codeのトークン節約ガイド:100万コンテキストの使用に注意、新セッションの開始方法を適切に選択
Claude Codeのトークン消費を最適化するためには、キャッシュメカニズムを理解し、タスクが変わらない限り同一セッションを継続し、1Mコンテキストのデフォルト使用を避けることが重要である。
キーポイント
キャッシュメカニズムの理解がコスト削減の鍵
Claude Codeは入力の同一プレフィックスに対して中間計算結果(キャッシュ)を保持し、次回の計算コストを約1/10に削減するため、頻繁なセッション再開は逆に高コストとなる。
セッション継続 vs 新規開始の判断基準
タスクが同一でキャッシュが有効(1時間以内)な場合はセッションを継続し、タスク変更・キャッシュ失効(1時間以上経過)・コンテキストがノイズで埋まった場合は新規セッションを開始することが最適である。
1Mコンテキストの落とし穴
2026年3月からデフォルトとなる1Mコンテキストウィンドウは、キャッシュ失効時の再計算コストが膨大となり、実際の日常利用では80-120Kで圧縮が発生するため、過剰な使用は避けるべきである。
入力品質の制御が出力長制御より効果的
大量のログなどを直接貼り付けるのではなく、ファイルパスを渡してClaude Codeに必要な情報のみを取得させるなど、コンテキストに入るトークン数を根本から減らすことが最も効果的である。
六つのルール
Claude Codeでトークンを節約するための具体的な実践ルールが提示されている。
フレームワーク委譲
効率的なコード生成のために適切なフレームワーク選択と委譲の重要性が説明されている。
比較と神話の打破
一般的な誤解を解き、効果的なコンテキスト使用方法について比較分析が行われている。
影響分析・編集コメントを表示
影響分析
この記事は、高額化するLLM利用コストの中で、特に開発者向けツールであるClaude Codeの実用的なコスト最適化手法を詳細に解説しており、ユーザーの運用習慣を変える可能性がある。また、提供元であるAnthropicのビジネスモデル(サブスクリプションの採算性)や今後の製品設計(デフォルトコンテキスト長の見直し)にも影響を与える実践的な洞察を提供している。
編集コメント
技術的なキャッシュ機構をユーザー行動の具体的なDO/DON'Tに落とし込んだ実践ガイドであり、サブスクリプション価格と実際のAPIコストの乖離というビジネス視点も含んだ、質の高い分析記事である。
最近コミュニティでは不満の声が上がっています:クォータがすぐに使い切れてしまいます。Max ユーザーの週間の利用枠を、ある人はわずか 2 日で使い果たしてしまいました。AWS Bedrock で計算したところ、1 つのセッションにおける実際のコストは 134 ドルを超えましたが、Pro Max の 5 倍サブスクリプションでは月額 100 ドルです。Anthropic のサブスクリプション自体が赤字で販売されています。
多くの人の第一反応は、頻繁に「/clear」コマンドを実行するか、ステップごとに新しいセッションを開始することです。「軽装して進むことでコストを節約できる」と考えているのです。しかし、Claude Code 背後のキャッシュ(注:計算結果の保存機能)メカニズムを理解すれば、この操作がしばしば逆効果になることがわかります。あなたはまさに全額支払いでのコンテキスト再構築をトリガーし、継続して会話をするよりも多くのお金を費やしていることになります。
なぜクォータがこれほど速く消費されるのか理解するには、まず大規模言語モデル(LLM)が入力を処理する仕組みを知る必要があります。それは人間の「続きから読む」という行為とは全く異なります。
気候変動に関する論文を書いていると想像してください。図書館に行くたびに同じことをしなければなりません:500 ページの『世界気候報告書』を見つけ、必要な章に飛び込み、重要なデータを写し取ることです。初めては 40 分かかりました。2 回目は異なる質問をしましたが、同じ本なのでまた 40 分かかりました。3 回目、4 回目も、同じく 40 分かかります。
大規模言語モデルが行っているのはまさにこれです。「記憶」を持っていません。直前に読んだからといってスキップすることはありません。あなたのメッセージを受け取るたびに、完全な入力内容を最初から「読み直す」必要があります。読む時間は入力内容の長さに比例します。
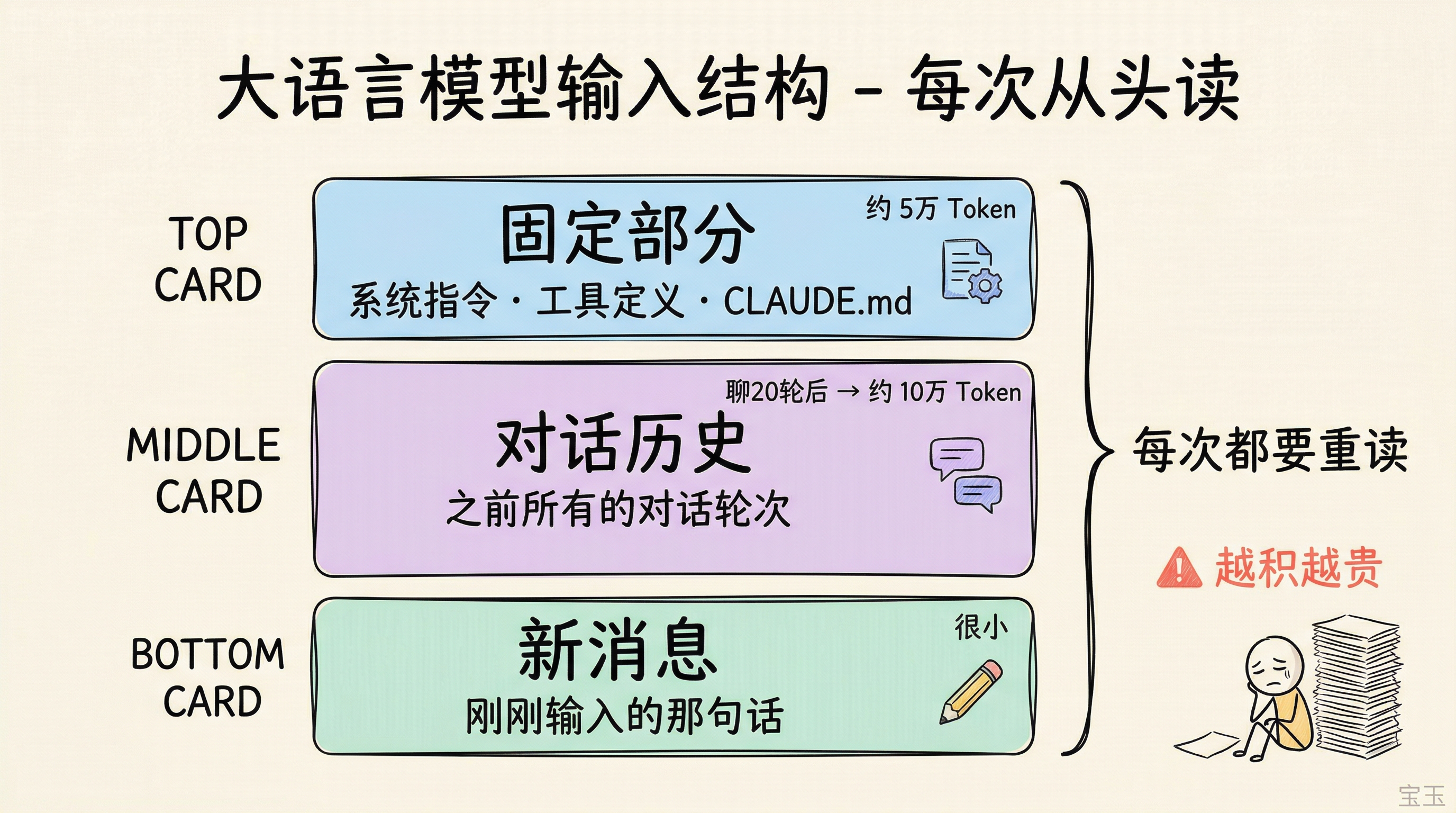
Claude Code における入力内容は通常、以下の 3 つの部分で構成されます:
固定部分:システム指示、ツール定義、CLAUDE.md に記載されたプロジェクトルール
前 2 つの部分は同じセッション内ではほとんど変化しませんが、モデルは毎回それらを再「読み」直す必要があります。20 ラウンド会話した後、新しいメッセージ 1 つあたりには 10 万トークンの「古い荷物」が付属することになり、処理が遅く、かつ高価になります。
500 ページの書を毎回最初からめくるのは、誰にとっても耐えられません。解決策は非常に直接的です:事前にノートを作成しておき、次回からはそのノートを参照するだけです。
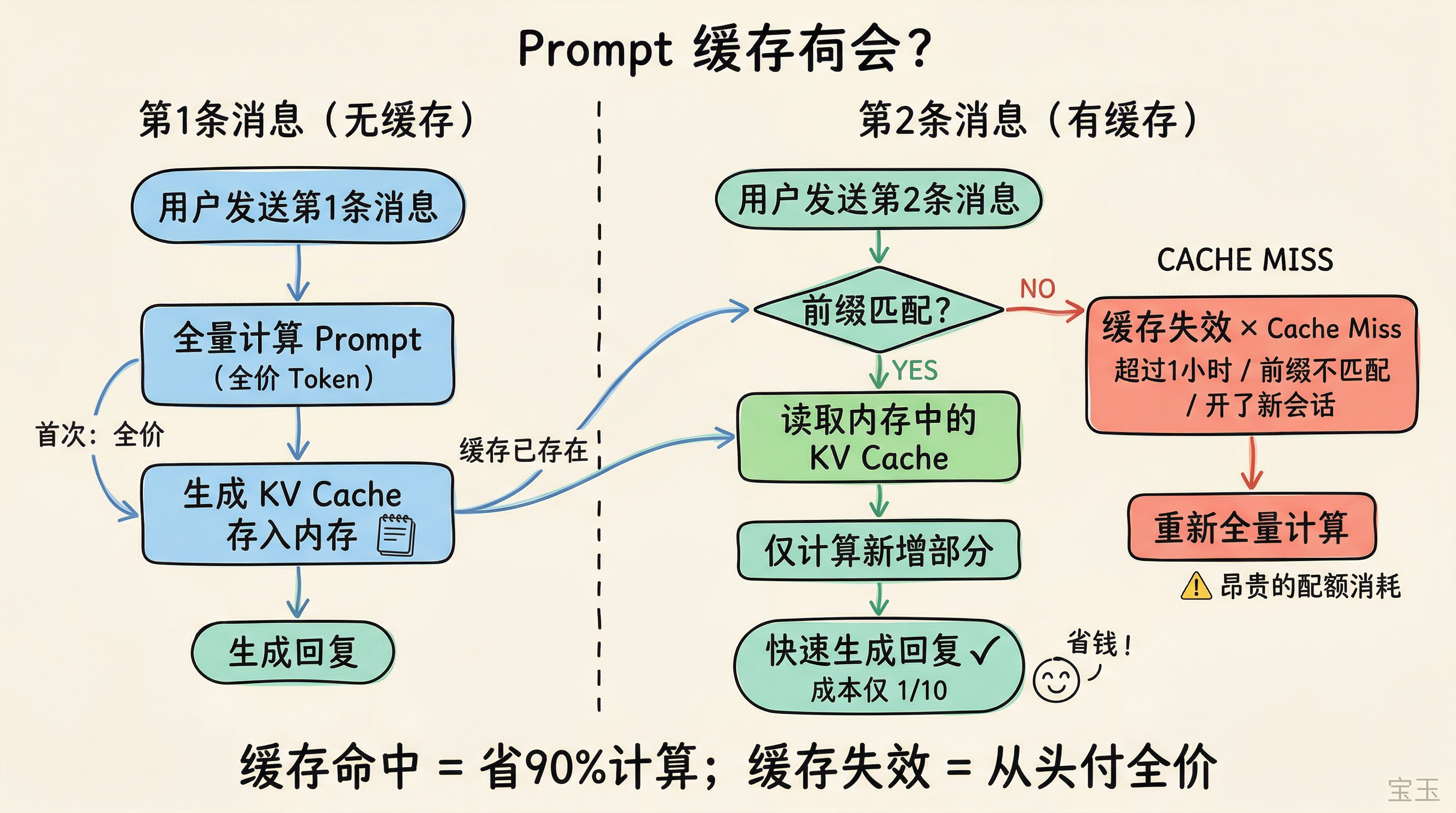
モデルが入力を読み終えると、一連の中間計算結果を生成します。これは「読書ノート」に相当します。その後回答を生成する際、モデルはこのノートに基づいて動作し、原文に戻って確認することはありません。プロンプトキャッシュ(注:入力の一部が重複した場合に計算結果を再利用する機能)の仕組みは以下の通りです:最初にノートを計算して保存しておき、次回同じ入力プレフィックス(注:入力の先頭部分)に出会った場合、保存されたノートを使用して重複計算をスキップします。
キャッシュからの読み取りコストは、再計算のコストの約 10 分の 1 です。
大まかに計算すると:20 ラウンドのセッションで 10 万トークンのコンテキストがあり、キャッシュが常にヒット(注:保存されたデータが見つかること)する場合、入力コストは毎回全額処理するよりも 6 倍以上安くなります。
第一に、キャッシュは「プレフィックス」に対してのみ有効です。最初から始まり、文字通り一字一句正確に一致している必要があります。
例え話しましょう:作文用紙に文章を書いたとします。最初の 3 ページが一字も違わず同じで、4 枚目のページで 1 字だけ変更した場合。使えるのは最初の 3 ページのみで、4 枚目からは再計算が必要になります。もし 1 枚目で 1 字変更したら?キャッシュはすべて無効化され、最初から計算し直さなければなりません。
したがって、Claude Code の入力構造が非常に重要です:システム指示やツール定義など変化しない内容は最前面に配置し、会話履歴を中間に、新しいメッセージを最後に配置します。これにより、毎回末尾の一小部分のみが再計算され、前方の大部分はキャッシュヒットします。
同じアクティブなセッション内では、プレフィックスが本質的に一致しているため、各ラウンドは尾部に新コンテンツを追加するだけであり、キャッシュヒット率は非常に高くなります。しかし、新しいセッションを開始すると、プレフィックスはゼロから始まり、以前蓄積されたキャッシュは一切利用できません。
第二に、キャッシュには有効期限があります。Claude Code チームの説明によると、メインエージェントのキャッシュウィンドウ(注:キャッシュが保持される時間)は 1 時間、サブエージェントは 5 分です。API ユーザーの場合、デフォルトは 5 分ですが(有料で 1 時間に延長可能ですが、より高額になります)。キャッシュヒットするたびにタイマーがリセットされ、インタラクションの頻度を保っていれば、キャッシュは常に有効な状態を維持できます。
Claude Code チームの原文:
「Claude Code はキャッシュ利用率が最も高いフレームワークです。」
しかし、キャッシュミス(注:保存されたデータが見つからないこと)のコストは、コンテキスト長が増大するにつれて急激に増加します。200K のキャッシュミスと 1M のキャッシュミスでは、コストの規模が全く異なります。
このキャッシュの仕組みを理解した上で、いくつかの「常識」を覆す必要があります。
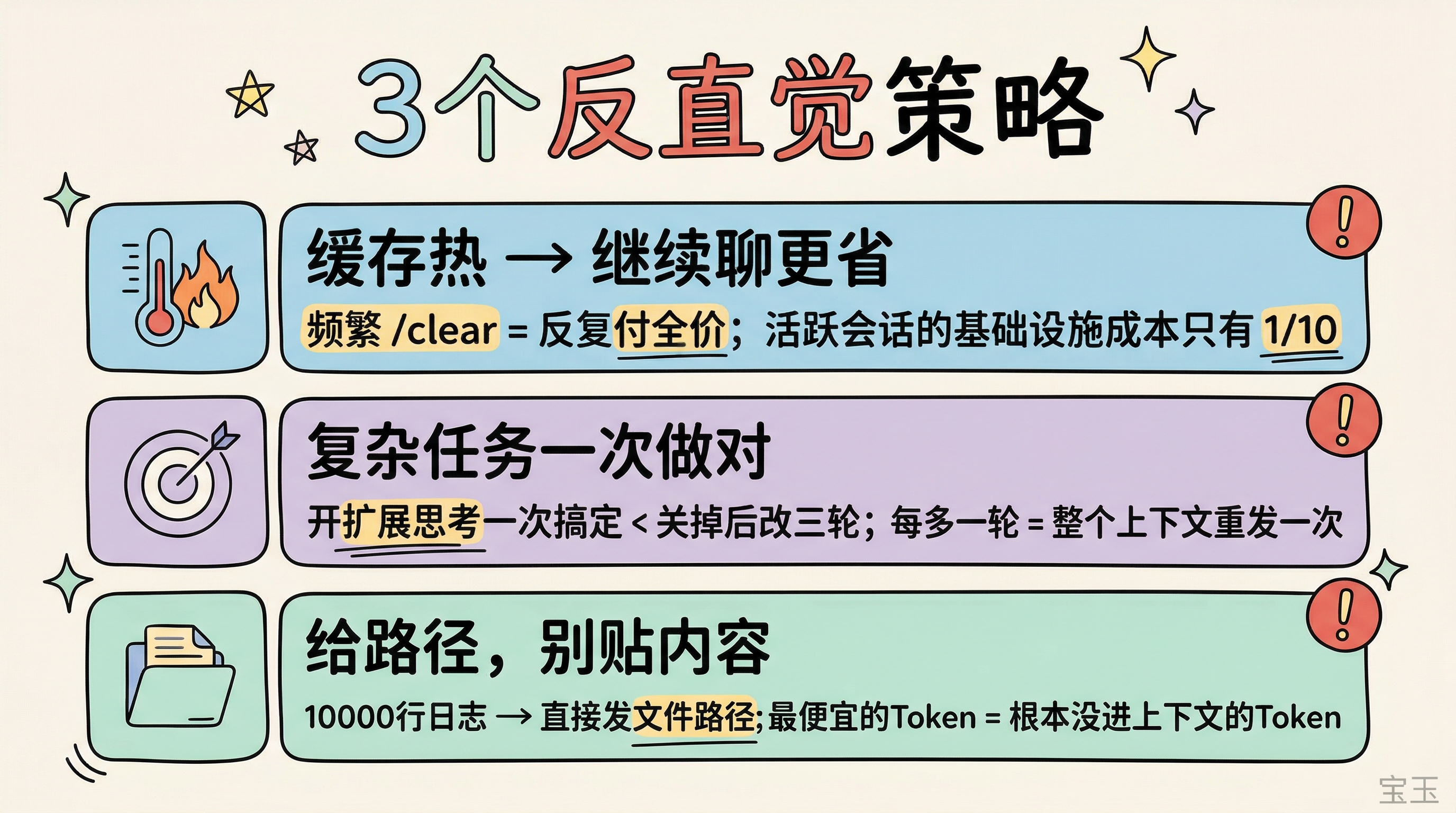
キャッシュがまだ有効な状態(ホット)であれば、新しいセッションを開くよりも継続して会話をする方が安価です。
Claude Code は毎回新しいセッションを開始するたびに、システムプロンプト、ツール定義、CLAUDE.md、プロジェクト設定といった「インフラストラクチャ」を再読み込みする必要があります。これらのおよそ 5 万トークンは、頻繁に /clear コマンドを実行すると、不変な内容に対して毎回全額分の書き込みコストを支払うことと同じです。
一方、アクティブなセッション内ではこれらの内容は常にキャッシュされており、そのたびにコストは約十分の一で済みます。
Anthropic の社員である Lydia Hallie 氏が「1 時間ほどアイドル状態になった大型のセッションは、再開を推奨する」と述べた際のキーワードは「アイドル状態」です。作業中のアクティブなセッションではキャッシュが常にホット(有効)な状態を保っており、継続して対話を行うのが最もコストを抑える方法です。
複雑なタスクを一度で正しく完了させる方が、何度も修正を繰り返すよりもトークン消費が少ない
拡張思考機能をオフにすると、単一のリクエスト内でのトークン節約にはなります。しかし、複雑なリファクタリングタスクにおいて、拡張思考をオンにして一度で完了させるのと、オフにした後に 3 回やり直すのでは、後者の方がコストが高くなる可能性が非常に高いです。なぜなら、対話のラウンドが増えるたびにコンテキスト全体が再送信される必要があり、3 ラウンドにわたる累積トークン数は、1 回の深い思考にかかる追加コストを遥かに上回るからです。
単純なタスクの場合は逆です。/effort コマンドで設定を下げるか、/config で思考モードをオフにすると、効果は即座に現れます。思考用のトークンは出力価格で課金されるため、デフォルトの予算設定では単純なタスクに対して明らかに無駄が生じます。
出力長を制御するよりも重要なのは、入力品質を制御することです。10,000 行のログをコピー&ペーストして Claude に自分でエラーを探させるのではなく、ログファイルのパスを直接渡してください。Claude Code は grep などのツールを使って必要な情報を検索し、関連する内容のみをコンテキストに読み込みます。最も安価なトークンとは、そもそもコンテキストに含まれていないトークンのことです。
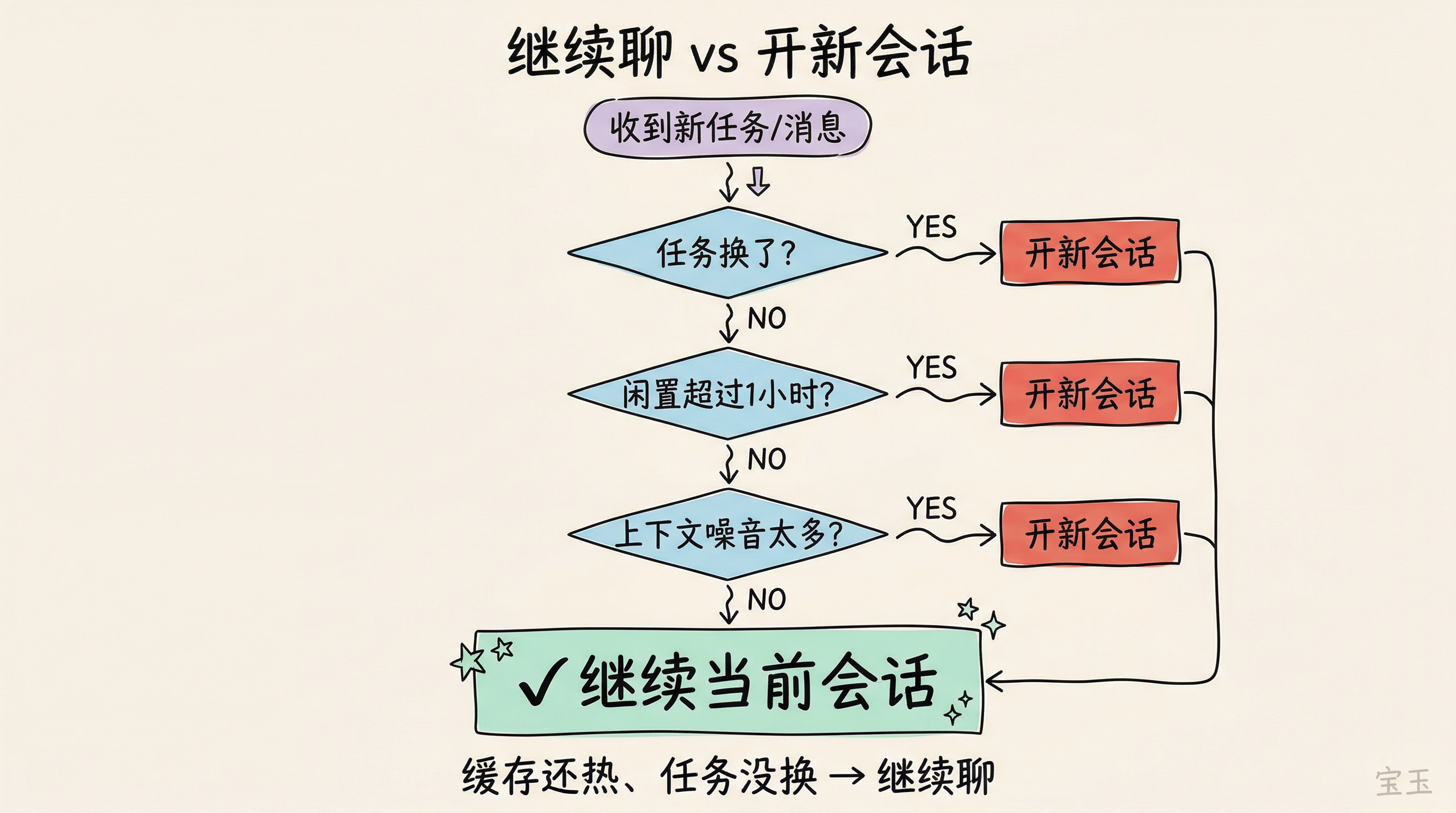
継続対話か新セッションかの判断:意思決定表
これは Claude Code でトークンを節約するための最も重要な判断基準となるかもしれません。多くの人のデフォルトの習慣は「完了したらクリアする」ですが、実際には最もコストを抑えるためのデフォルト習慣はその逆、「続けられるなら続けること」、そして新セッションは条件付きでトリガーされる操作であるべきです。
以下のいずれかの条件に当てはまる場合は、現在のセッションを継続してください:
- タスクが変更されていない。同じバグの修正中、同じモジュールの作成中、あるいは同一グループのファイルに関する作業中であること。
- 最後のメッセージから 1 時間以内であること。キャッシュはまだ有効であり、これまでに蓄積されたコンテキストはほぼ無料です。
- コンテキスト内の内容が現在の作業に依然として有用であること。以前読み込んだファイルや議論された解決策など、モデルがまだ活用している情報がある場合です。
もし思考中で一時的に入力がない場合は、短いメッセージを送ってキャッシュを活性状態に保ちましょう。あるユーザーは、キャッシュの自動維持のために「ハートビート拡張機能」まで作成しており、キャッシュを更新するコストは、キャッシュミス(未ヒット)時の全量再構築コストの約十分の一です。
タスクが変更された場合。認証モジュールの作成が終わった直後に支払い機能の実装に移るなど、2 つのタスクではコンテキストが全く異なります。古いセッションに蓄積されたコードファイルやデバッグ記録は新任務には無用であり、各リクエストでこれらの無関係な内容に対して課金されています。
アイドル状態が 1 時間を超えた場合。キャッシュはおそらく期限切れとなっており、継続対話を行うことは全量再構築をトリガーするのと同じです。むしろクリーンな状態から始める方がマシです。
コンテキストが無関係なコンテンツで埋め尽くされている場合。十数種類の試行や大量の無関係なファイルの読み込みが行われ、それらがまだスペースを占有しています。キャッシュがヒットしていても、モデルはノイズの中から信号を検出する必要があり、出力品質が低下します。また、圧縮後に重要な情報が失われる可能性もあります。
一言でまとめると:キャッシュがホットでタスクが変わっていないなら継続対話。キャッシュが期限切れ、タスクが切り替わった、あるいはコンテキスト内のノイズが多すぎる場合は、迷わず新セッションを開始してください。
コミュニティからは、「1 つのセッションで 1 つのことだけを行う」という働き方では、ほぼクォータ(利用枠)の問題に直面しないという報告もあります。
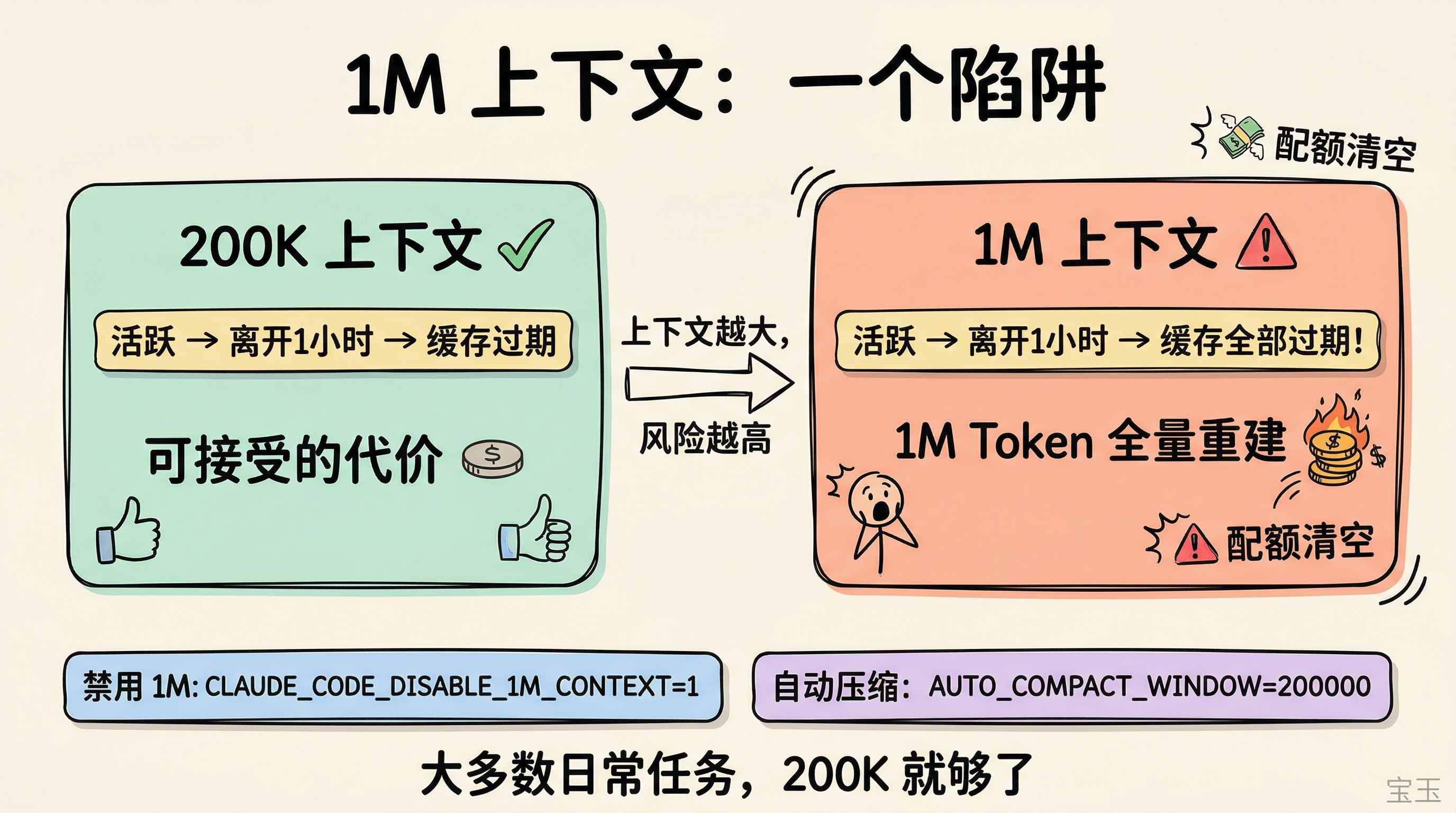
2026 年 3 月より、Max、Team、Enterprise プランではデフォルトで Opus 4.6 の 1M トークンコンテキストウィンドウが使用されます。Anthropic は長文コンテキストに対する 2 倍の価格プレミアムを撤廃し、1M ウィンドウと 200K ウィンドウは同額となりました。
しかし、1M コンテキストは多くのユーザーにおいてクォータ不足の主要な原因となっています。
問題はキャッシュが失効した際の代償にあります。1M トークンコンテキストを使って長いセッションを積み重ねた後、1 時間以上離席して戻り、継続対話を行うと、1M トークンのキャッシュはすべて期限切れとなり、1 メッセージ送るだけで全量再構築がトリガーされます。チームはこの問題を確認しており、デフォルトのコンテキストサイズを 1M から 400K に引き下げることを検討しています。
また、多くの日常会話では 80-120K のコンテキスト(文脈)の時点で圧縮がトリガーされ、200K も使えず、ましてや 1M を使う必要もありません。コミュニティで得られた経験則データも同じ結論を指し示しています:コンテキストが 200K を超えるとモデルのパフォーマンスは顕著に低下し、350K を超えればほぼ運頼みです。
1M のコンテキストが適しているシナリオは確かに存在します:大規模なコードベースを一度に読み込んでグローバルリファクタリングを行う場合や、長時間の多輪対話で圧縮によって中断されたくない場合などです。しかし、日常のコーディングやバグ修正には使いません。
私の提案:1M のウィンドウは維持しつつ、保守的な自動圧縮閾値を設定し、柔軟性と効率性の両方を兼顾することです。
もし 1M コンテキストを無効化したい場合は、~/.claude/settings.json に以下を追加してください。
{
"env": {
"CLAUDE_CODE_DISABLE_1M_CONTEXT": "1"
}
}
自動圧縮の閾値を設定したい場合は:
{
"env": {
"CLAUDE_CODE_AUTO_COMPACT_WINDOW": "200000"
}
}
コンテキストが約 20 万トークンに近づくと自動的に要約・圧縮され、文脈の連続性を保ちつつコストの暴走を防ぎます。
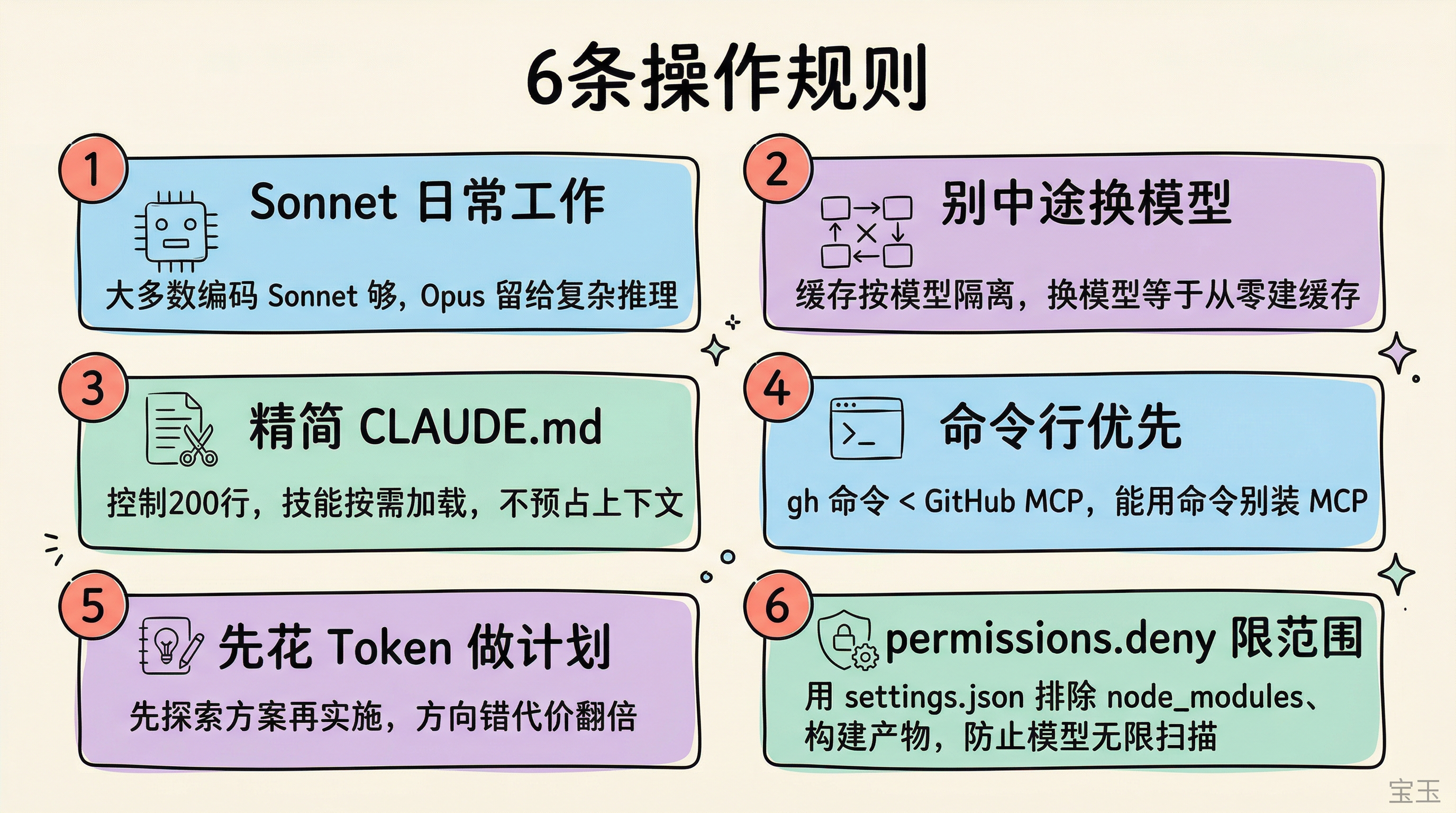
一、日常業務には Sonnet を使う
Opus の入力コストは Sonnet の約 1.7 倍ですが、より重要なのは Opus がトークンを消費する速度が Sonnet の約 2 倍である点です。多くのチームが Opus のトークン使用量を減らす方法に時間を費やしていますが、まずは「このタスクに本当に Opus が必要か?」と自問すべきです。ほとんどのコーディングタスクには Sonnet で十分であり、Opus は複雑なアーキテクチャの意思決定や多段階推論のために取っておくべきです。
Claude Code では /model コマンドを入力すると、モデルを切り替えることができますが、プロンプトキャッシュはモデルごとに隔離されています。Opus で 10 万トークンのキャッシュを蓄積した後、Sonnet に簡単な質問をすると、Sonnet はゼロから独自のキャッシュを構築する必要があります。この場合、より「安価」な Sonnet に切り替えるよりも、Opus が直接回答する方がコストは少なくなります。軽量モデルが必要なシナリオでは、主モデルを切り替えるのではなくサブエージェントを使用してください。
三、CLAUDE.md を簡素化し、スキルの数を制御する
CLAUDE.md の内容はすべてのリクエストに注入されます。公式の推奨事項として 200 行以内に抑え、本当に長期的に有効なルールのみを残すべきです。コードレビューのプロセスやデータベースマイグレーションの手順など、特定のタイミングでのみ必要な長い説明は「スキル」に移管してください。スキルはデフォルトで呼び出し時にのみロードされ、事前にコンテキストを占有しません。
ただし、スキルも多ければ多いほど良いわけではありません。読み込みすぎたスキルとエージェントは、クォータ消費の隠れた要因となります。チームはこの消費量をより可視化できるようインターフェースの改善を進めています。スキルはプロジェクトディレクトリ(.claude/skills/)に配置します。
ちょっとしたコツ:CLAUDE.md 内で HTML コメントを使ってメンテナ向けの注釈を書くと、Claude がコンテキストを注入する前にコメントが削除されるため、トークンを消費しません。
五、まず少しのトークンを使って計画を立てる
複雑なタスクでは、まず計画モードに入り、Claude にコードの探索と方案の提案を行ってもらってから実施フェーズに入ることで、総コストは往々にして低くなります。本当に高価なのは、方向を誤った後にコードを再スキャンし、実装を書き直し、テストを再実行することです。
質問も同様です。「このコードベースを最適化してほしい」といった曖昧なプロンプトは広範なスキャンを引き起こしますが、「auth.ts に対して認証ロジックの改善案を提示して」のように具体的な指示を出すことで、無駄な処理を防げます。
六、permissions.deny を使ってモデルの読み取り範囲を制限する
インデックス化されていないコードベースでは、モデルが文脈を見つけるためにファイル検索に頼らざるを得ず、効率が極めて低くなります。.claude/settings.json に以下のように設定してください。
{
"permissions": {
"deny": [
"Read(./.env)",
"Read(./.env.*)",
"Read(./secrets/**)",
"Read(./node_modules/**)",
"Read(./build)"
]
}
}
これにより、機密情報や不要なファイルへのアクセスを明示的に拒否し、トークン使用量とコストを抑制できます。
これらのパターンに一致するファイルは、ファイル発見および検索結果から除外され、読み取り操作も直接拒否されます。モデルは場合によっては 5 分以上にわたってコードベースの検索ループに陥ることがあり、ファイルパスを指定したとしても、背景で関連しないファイルを繰り返し読み続けることがあります。
permissions.deny
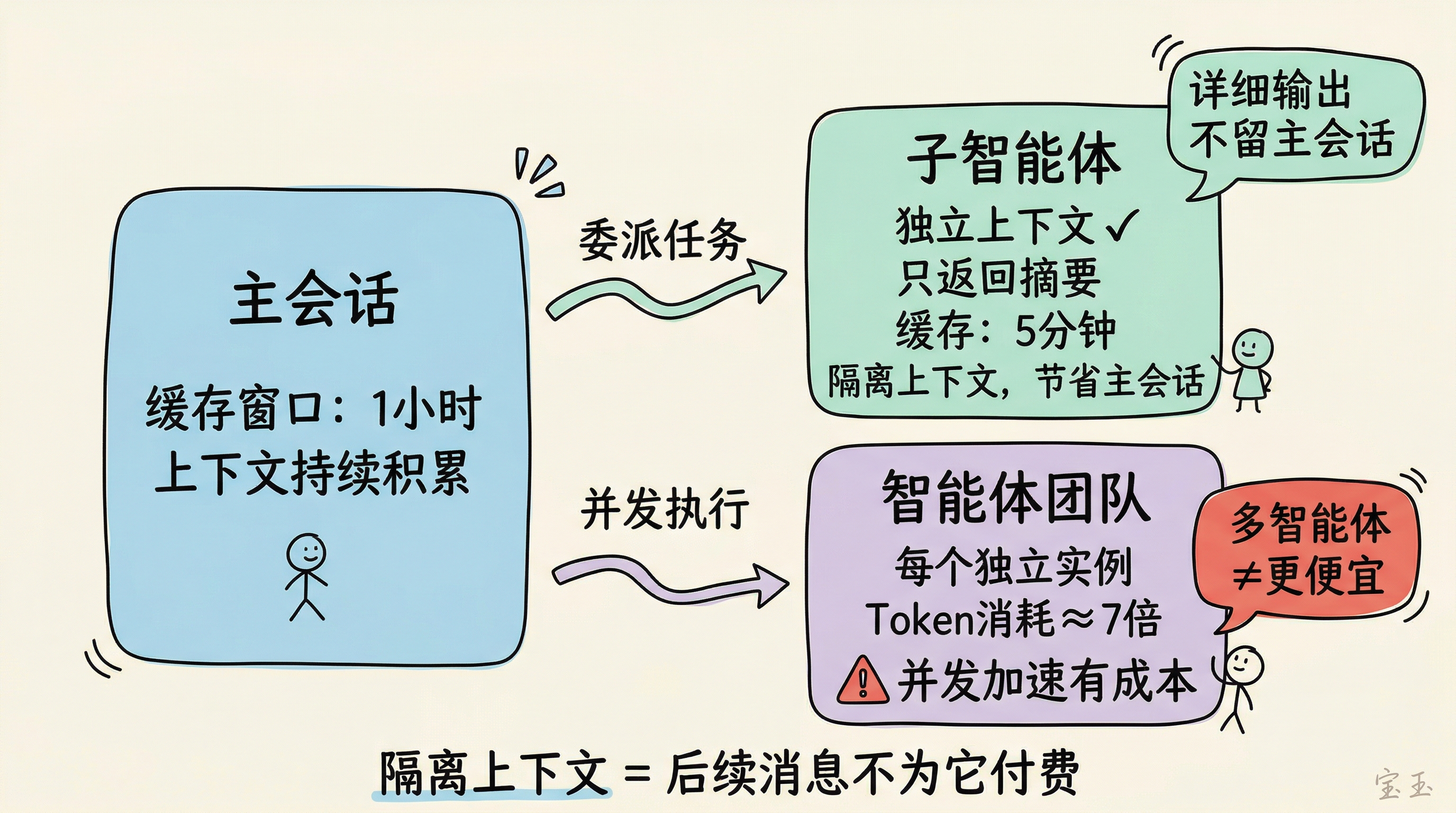
2 つの委譲アプローチにより、メインセッションのトークン消費を削減できます。
サブエージェント:Claude Code のサブエージェントは独立したコンテキストを持ち、完了後に短いサマリーのみをメインセッションに返します。サブエージェントのキャッシュウィンドウは 5 分(メインエージェントは 1 時間)と短く、各呼び出しにおけるキャッシュ利用率も低くなります。しかしその価値はコンテキストの隔離にあります:コードレビュー、テスト実行、ドキュメント検索といった作業の詳細な出力がメインセッションに残らないため、以降のメッセージでこれらの内容に対して課金される必要がありません。
エージェントチームはサブエージェントとは異なります。エージェントチーム内の各メンバーは独立した Claude インスタンスであり、それぞれが独自のコンテキストウィンドウを維持します。プランニングモードにおけるエージェントチームのトークン消費量は標準セッションの数倍(コミュニティでの推計では約 7 倍)に達し、アイドル状態のメンバーも継続してリソースを消費します。並列処理による加速にはコストがかかり、「マルチエージェント=より安価」とは限りません。
Codex プラグイン:OpenAI のサブスクリプションをお持ちの場合は、コミュニティ内で openai/codex-plugin-cc が利用されています。
claude mcp add codex -- npx -y @openai/codex-plugin-cc
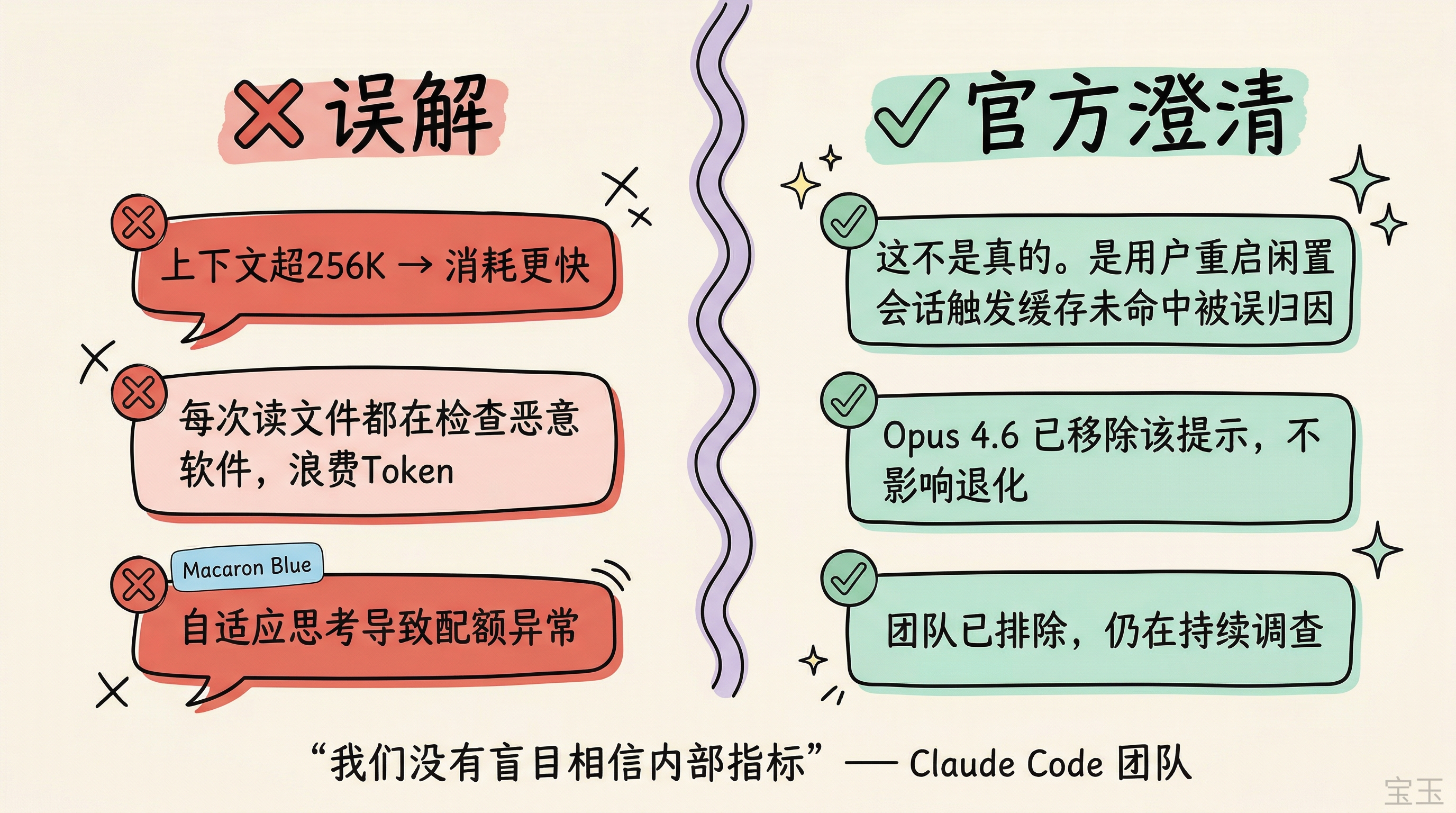
コミュニティではトークン消費に関する様々な噂が流れていますが、Claude Code チームは議論の中で公式に澄清を行いました。
最も広まっているのは「コンテキストが 256K を超えると消費速度が加速する」という説です。これに対する公式の回答は非常に明確です:これは事実ではありません。実際の原因として考えられるのは、長期間アイドル状態だったセッションをユーザーが再起動し、大規模なキャッシュミスが発生したことが、コンテキスト長のせいだと誤って帰属されたケースです。
また、「モデルがファイルを読み込むたびにマルウェアチェックを行っており、トークンを浪費している」という不満もあります。このセキュリティ検知の通知は Sonnet 3.7 から導入されており、各新モデルで評価が行われましたが、性能低下を引き起こすことはありませんでした。Opus 4.6 ではすでにこの通知が削除されています。「適応的思考による配额消費の異常」についてもチームは否定しています。チームは内部指標を盲目的に信じておらず、引き続き調査を進めています:
「私たちはこの件を真摯に受け止め、継続して調査を行っています。内部指標を盲目的に信頼しているわけではありません。」
トークンを節約する核心的な考え方は一言で表せます:キャッシュのヒット率を可能な限り高め、コンテキストには無関係な内容を極力含めないようにすることです。
新しいセッションを開くことは手段の一つですが、プロンプトキャッシュの仕組みを理解すれば、「アクティブなセッション内で作業を継続する」ことがデフォルト戦略であり、「新しいセッションを開く」のは特定の条件下での最適化操作であることがわかります。
コミュニティでは多くの人が Claude Code、Codex、Cursor のいずれがより寛容なクォータを提供しているかを比較しています。しかし、クォータの引き締めは業界全体の傾向かもしれません。「補助金付き計算資源時代の終焉」に直面していると語る人もおり、かつて Uber が 3 ドルで配車サービスを提供していた時期のような状況です。どの企業がより長く補助金を続けるか賭けるよりも、コスト構造を明確にし、予算を最も効果的な場所に投じるべきでしょう。
皆さんは普段、1 つのセッションがどれくらいの長さになることが多いですか?また、会話が続くのを恐れて頻繁に /clear コマンドを実行する習慣はありませんか?

Claude Code のトークン節約ガイド:1M コンテキストを不用意に使用せず、新しいセッションを開き続けるのも、常に同じセッションを使い続けるのも正解ではありません(続き 5/5)
原文を表示
最近社区里怨声载道:配额烧得太快了。Max 用户一周的额度,有人两天就用完。有人在 AWS Bedrock 上算了一笔账,一个会话的真实成本超过 134 美元,而 Pro Max 5x 订阅一个月才 100 美元。Anthropic 的订阅本身就是亏本在卖。
很多人的第一反应是频繁 /clear,或者每做完一步就开新会话。觉得这样"轻装上阵"能省钱。但如果你理解了 Claude Code 背后的缓存机制,会发现这个操作经常适得其反:你刚刚触发了一次全价上下文重建,花的钱比继续聊下去还多。
要理解配额为什么烧得快,得先搞清楚大语言模型处理输入的方式——它跟人类的“接着读”完全不同。
想象你在写一篇关于气候变化的论文,每次去图书馆都要做同一件事:找到那本 500 页的《全球气候报告》,翻到需要的章节,把关键数据抄下来。第一次花 40 分钟,第二次问了个不同的问题,还是同一本书,又花 40 分钟。第三次、第四次,同样的 40 分钟。
大语言模型干的就是这件事。它没有“记忆”,不会因为刚读过就跳过。每次收到你的消息,它都要从头“读”一遍完整的输入内容,读的时间和内容长度成正比。
在 Claude Code 里,输入内容通常包括三部分:
固定部分:系统指令、工具定义、CLAUDE.md 里的项目规则
前两部分在同一个会话里几乎不变,但模型每次都要重新"读"一遍。聊了 20 轮之后,每条新消息可能要带上 10 万个 Token 的"旧行李",既慢又贵。
每次都从头翻那本 500 页的书,任谁都受不了。解决办法很直接:把笔记提前做好,下次只翻笔记本。
模型读完一段输入后,会生成一组中间计算结果,相当于"阅读笔记"。后续生成回答时,模型靠的就是这组笔记,不会再回去看原文。提示缓存的机制是:第一次算完笔记后存下来,下次再遇到相同的输入前缀,直接用存好的笔记,跳过重复计算。
读取缓存的成本只有重新计算的十分之一。
粗略算一下:一个 20 轮的会话,10 万 Token 的上下文,缓存一直命中的话,输入成本比每次都全价处理低 6 倍以上。
第一,缓存只对"前缀"有效。 必须从头开始、一字不差地匹配。
打个比方:你在作文纸上写了一篇文章,前 3 页一字不差,第 4 页改了一个字。只有前 3 页能用缓存,第 4 页开始就得重新计算。如果你在第 1 页就改了一个字?整个缓存全部失效,从头算。
所以 Claude Code 的输入结构很重要:系统指令、工具定义这些不变的内容放在最前面,对话历史在中间,新消息放在最后。每次只有末尾那一小段需要重新计算,前面一大段都能命中缓存。
在同一个活跃会话里,前缀天然一致,每一轮只是在尾部追加新内容,缓存命中率很高。但如果你开了一个新会话,前缀从零开始,之前积累的缓存全部用不上。
第二,缓存有存活时间。 根据 Claude Code 团队的说明,主智能体的缓存窗口是 1 小时,子智能体是 5 分钟。API 用户默认只有 5 分钟(可以付费开启 1 小时,但更贵)。每次缓存命中都会刷新计时器,只要你保持交互频率,缓存可以一直活着。
Claude Code 团队的原话:
"Claude Code 是缓存利用率最高的框架。"
但缓存未命中的代价,随上下文长度增大而急剧增加。一个 200K 的缓存未命中和一个 1M 的缓存未命中,完全是两个量级的开销。
理解了缓存之后,有些"常识"要翻过来。
缓存还热的时候,继续聊比开新会话便宜
Claude Code 每次新会话启动,都要重新加载系统提示、工具定义、CLAUDE.md、项目配置。这些"基础设施"大约 5 万 Token。频繁 /clear 等于反复为这些不变的内容付全价写入费。
而在活跃会话里,这些内容一直在缓存中,每次只付十分之一的价格。
Anthropic 员工 Lydia Hallie 说的"闲置约一小时的大型会话,建议重新开始",关键词是"闲置"。活跃工作中的会话,缓存一直是热的,继续聊才最省。
复杂任务一次做对,比来回改三轮更省
关掉扩展思考确实能在单次请求里省 Token。但一个复杂的重构任务,开着扩展思考一次搞定,和关掉之后来回改三轮,后者更贵的概率很大。因为每多一轮对话,整个上下文都要重新发送一次,三轮累积的 Token 远超一次深度思考的额外开销。
简单任务反过来。把 /effort 调低或者在 /config 里关掉思考模式,效果立竿见影。思考 Token 按输出价计费,默认预算对简单任务来说浪费明显。
比起控制输出长度,更有效的是控制输入质量。不要把 10000 行日志复制粘贴到对话里让 Claude 自己找错误,直接把日志文件路径发给它。Claude Code 会自己用 grep 之类的工具去检索需要的信息,只把相关内容拉进上下文。最便宜的 Token,永远是根本没进上下文的 Token。
继续聊还是开新会话:一张决策表
这可能是 Claude Code 省 Token 最关键的一个判断。很多人的默认习惯是"做完就清",实际上最省的默认习惯应该反过来:能继续就继续,开新会话是有条件触发的操作。
满足以下任一条件,继续当前会话:
任务没变。还在调同一个 bug、写同一个模块、围绕同一组文件工作。
距离上一条消息不超过 1 小时。缓存还活着,前面积累的上下文几乎不花钱。
上下文里的内容对当前工作仍然有用。之前读过的文件、讨论过的方案,模型还在用。
如果在思考问题暂时没有输入,可以发一条简短消息保持缓存活跃。有用户甚至写了心跳扩展来自动保活缓存,刷新一次缓存的成本只有完整缓存未命中的十分之一。
任务换了。刚写完认证模块要做支付功能,两件事的上下文完全不同。老会话里堆的代码文件、调试记录对新任务毫无用处,每条请求都在为这些无关内容付费。
闲置超过 1 小时。缓存大概率已经过期,继续聊等于触发全量重建,还不如从干净状态开始。
上下文被不相关内容塞满。试了十几种方案、读了大量无关文件,这些内容还在占位。即使缓存命中,模型也要在噪音里找信号,输出质量下降,而且压缩后可能丢掉关键信息。
一句话总结:缓存还热、任务没换,继续聊。缓存过期、任务切换、上下文里噪音太多,果断重开。
社区里有人反馈,一个会话只做一件事的工作方式,几乎不会触发配额问题。
从 2026 年 3 月起,Max、Team、Enterprise 计划默认使用 Opus 4.6 的 1M 上下文窗口。Anthropic 取消了长上下文的 2 倍价格溢价,1M 窗口和 200K 同价。
但 1M 上下文正在成为很多人配额见底的头号原因。
问题出在缓存失效的代价上。你用 1M 上下文积累了一个很长的会话,中间离开电脑超过 1 小时,回来继续聊,这时候 1M Token 的缓存全部过期,一条消息就要触发全量重建。团队确认了这个问题,正在考虑将默认上下文从 1M 降到 400K。
而且大多数日常会话在 80-120K 上下文时就会触发压缩,根本用不到 200K,更别说 1M。社区里的经验数据也指向同一个结论:上下文超过 200K 后模型表现明显下降,350K 以上基本靠运气。
适合 1M 的场景确实存在:一次性加载大型代码库做全局重构、长时间多轮对话不想被压缩打断。但日常写代码改 bug 用不上。
我的建议:保留 1M 窗口但设一个保守的自动压缩阈值,兼顾灵活性和效率。
如果你想禁用 1M 上下文,在 ~/.claude/settings.json
{ "env": { "CLAUDE_CODE_DISABLE_1M_CONTEXT": "1" } }
如果你想设置自动压缩上下文的阈值:
{ "env": { "CLAUDE_CODE_AUTO_COMPACT_WINDOW": "200000" } }
上下文接近 20 万 Token 时自动压缩摘要化,既保留上下文连续性,又防止成本失控。
一、用 Sonnet 做日常工作
Opus 的输入成本大约是 Sonnet 的 1.7 倍,但更关键的是 Opus 消耗 Token 的速度大约是 Sonnet 的两倍。很多团队花大量时间研究怎么让 Opus 少说点,不如先问一句:这件事真的需要 Opus 吗?大多数编码任务 Sonnet 就够了,Opus 留给复杂架构决策和多步推理。在 Claude Code 里输入 /model
提示缓存按模型隔离。你在 Opus 上积累了 10 万 Token 的缓存,切到 Sonnet 问个简单问题,Sonnet 要从零建立自己的缓存。这时候让 Opus 直接回答,反而比切到"更便宜"的 Sonnet 花得少。需要用轻量模型的场景,用子智能体而非切换主模型。
三、精简 CLAUDE.md,控制技能数量
CLAUDE.md 的内容会注入到每一次请求里。官方建议控制在 200 行以内,只保留真正长期有效的规则。代码审查流程、数据库迁移步骤这类只在特定时刻需要的长说明,挪到技能里去;技能默认只在调用时加载,不会提前占上下文。
但技能也不是越多越好。加载太多技能和智能体是配额消耗的一个隐形杀手,团队正在改进界面让这些消耗更可见。技能放在项目目录(.claude/skills/
一个小技巧:在 CLAUDE.md 里用 HTML 注释写维护者备注,Claude 注入上下文前会把注释剥掉,不花 Token。
五、先花一点 Token 做计划
复杂任务先进入计划模式,让 Claude 先探索代码、提出方案,再进入实施,总成本往往更低。真正昂贵的是方向错了以后重扫代码、重写实现、重跑测试。
提问也是一样:「帮我优化这个代码库」这种模糊提示会触发广泛扫描;「给 auth.ts
六、用 permissions.deny 限制模型的阅读范围
没有索引的代码库会迫使模型通过文件搜索来寻找上下文,效率极低。在 .claude/settings.json
permissions.deny
{ "permissions": { "deny": [ "Read(./.env)", "Read(./.env.*)", "Read(./secrets/)", "Read(./node_modules/)", "Read(./build)" ] } }
匹配这些模式的文件会被排除在文件发现和搜索结果之外,读取操作也会被直接拒绝。模型有时候会陷入长达 5 分钟以上的代码库搜索循环,即便你指明了文件路径,它仍可能在背景中反复读取不相关文件。permissions.deny
两个委派思路可以减少主会话的 Token 消耗。
子智能体:Claude Code 的子智能体有独立上下文,完成后只返回简短摘要给主会话。子智能体的缓存窗口只有 5 分钟(主智能体是 1 小时),每次调用的缓存利用率更低。但它的价值在于隔离上下文:代码审查、跑测试、查文档这些工作的详细输出不会留在主会话里,后续每条消息都不用为这些内容付费。
智能体团队和子智能体不同。智能体团队里每个成员都是独立 Claude 实例,各自维护自己的上下文窗口。计划模式下智能体团队的 Token 消耗是标准会话的数倍(社区估算约 7 倍),闲置的成员也在继续消耗。并发加速有成本,多智能体不等于更便宜。
Codex 插件:如果你同时有 OpenAI 订阅,社区里有人用 openai/codex-plugin-cc
claude mcp add codex -- npx -y @openai/codex-plugin-cc
社区里流传不少关于配额消耗的说法,Claude Code 团队在讨论中做了官方澄清。
流传最广的一条是"上下文超过 256K 之后消耗会更快"。官方回应很直接:这不是真的。 实际原因很可能是用户重启了闲置已久的会话,触发了大规模缓存未命中,被误归因于上下文长度。
还有人抱怨模型每次读文件都在检查是否为恶意软件,浪费 Token。这个安全检测提示从 Sonnet 3.7 就有了,每次新模型都做过评估,没有引发退化。Opus 4.6 已经移除了这个提示。至于"自适应思考导致配额消耗异常",团队也已排除。团队表示没有盲目相信内部指标,仍在持续调查:
"我们在认真对待这件事,仍在持续调查。我们没有盲目相信内部指标。"
省 Token 的核心思路就一句话:让缓存尽可能多地被命中,让上下文尽可能少地装无关内容。
开新会话是手段,理解了提示缓存之后你会发现,"在活跃会话里继续工作"才是默认策略,"开新会话"是特定条件触发的优化操作。
社区里很多人在比较 Claude Code、Codex、Cursor 的配额谁更慷慨。但配额收紧可能是个行业趋势,有人说我们正处在"补贴算力时代的末期",类似当年 Uber 3 美元打车的阶段。与其赌哪家补贴更久,不如搞清楚成本结构,把钱花在刀刃上。
你们平时一个会话大概多长?有没有因为不敢继续聊而频繁 /clear 的习惯?
関連記事
1 ドルあたりの知能(2 分読了)
マイクロソフトはモデルリリースカードに「平均トークン使用量」を導入し、知能の効率性を重視する指標を設けた。これにより各社はパフォーマンスとコストの両面で競争を迫られ、価格設定が完了したサポートケースなどの具体的な成果と連動することになる。
IPO 計画を背景にアントロピックが企業パートナープログラムを強化
アントロピックは、自社 AI 製品「Claude」の第三者販売業者向けパートナープログラムを強化した。同社は IPO 申請を控え、市場に対して事業規模拡大への意欲を示す狙いがある。
Uber、コスト管理のためClaude CodeなどのAIツールの利用を制限
Uberは2026年のAI予算を4ヶ月で使い果たしたため、Claude CodeなどのAIツールの利用に上限を設けてコスト削減を図っている。