Anthropic と米国政府の対立、Nano Banana のリニューアル、フロンティアエージェント管理、Google の数学的解決策
Andrew Ng は、AI コーディングエージェントが最新 API を認識できないという課題に対し、開発者による手動ドキュメント作成を自動化するオープンソースツール「Context Hub」を発表した。
キーポイント
コーディングエージェントの知識陳腐化問題
AI モデルは学習データの切り捨て日(カットオフ)により、最新の API やツール(例:OpenAI の新しいレスポンス API や Nano Banana)を認識できず、誤ったコードを生成する傾向がある。
Context Hub の概要と目的
開発者がエージェントに直接利用させるためのオープンソース・コンテキスト管理システムで、最新の API ドキュメントを提供し、自動フィードバックを通じてエージェントの性能を継続的に向上させる。
実装方法と使用例
npm を介してインストール可能で、「chub search」や「chub get」などのコマンドにより、特定のサービス(OpenAI など)の最新ドキュメントをエージェントに取得させることができる。
Context Hub の公開
コーディングエージェントが最新かつ正確な API ドキュメントを取得し、コードを正しく記述できるよう支援するオープンソースツール「Context Hub」が公開されました。
Nano Banana 2 の登場
Google は前作より約半額の価格で、4 倍の速度と高い精度を実現した画像生成モデル「Nano Banana 2」を発表し、市場競争を激化させました。
米軍と Anthropic の対立
米国国防総省が Anthropic の技術使用制限に反発し、同社を「サプライチェーンリスク」と指定して排除した結果、OpenAI と契約を結ぶ事態となりました。
影響分析・編集コメントを表示
影響分析
本記事は、生成 AI の実用化における最大のボトルネックの一つである「最新情報の欠如」に対する具体的な解決策を示しており、AI エージェントの信頼性を高める上で重要な一歩となる。特に、開発者が個別にドキュメントを管理する負担を軽減し、エージェントが常に最新の技術仕様に基づいて動作できる環境を整えることで、産業レベルでの AI 実装の質向上に寄与する。
編集コメント
AI エージェントが「過去」の知識に縛られて最新技術に対応できないという深刻な課題に対し、実用的なオープンソースツールで対抗する姿勢は評価できます。ただし、これは特定のツールの紹介であり、業界全体の標準化に向けた動きとしてはまだ初期段階と言えます。
親愛なる皆様、
コーディングエージェントに正確なコードを記述するために必要な API ドキュメンテーションを提供する新ツール「Context Hub」Context Hub を発表できることを大変嬉しく思います。モダンな技術を用いて AI システムを構築されている場合、コーディングエージェントは頻繁に古くなった API を使用したり、パラメータをでっち上げたり、あるいは使用するべきツール自体を認識していなかったりします。これは AI ツールが急速に進化している一方で、コーディングエージェントが最新のツールを反映していない古いデータに基づいて訓練されているためです。「Context Hub」はあなたではなく、あなたのコーディングエージェントが利用するために設計されており、必要なコンテキスト(文脈)を提供します。また、自動的なエージェントフィードバックを受け付けることで、時間とともにコーディングエージェントの改善を支援します。
例えば、現在おそらく最良のコーディングモデルである Claude Opus 4.6 は、知識のカットオフ日が 2025 年 5 月となっています。OpenAI の GPT-5.2 を呼び出すコードを書くよう依頼すると、OpenAI が推奨する新しい Responses API (client.responses.create) ではなく、古い OpenAI チャット完了 API (client.chat.completions.create) を使用します。新しい API はすでに 1 年前に登場していますが、Opus が学習したデータには、この古いインターフェースを使用するものが圧倒的に多く含まれています。また、2025 年 8 月にリリースされた Nano Banana の存在についても全く知りません。より一般的には、コーディングモデルが Gemini や多くのデータベースサービスに対して正しい API 呼び出しを行えない事例や、私があまり使わないパラメータを選択した場合など、人気のあるサービスであっても失敗したり、特定のツールが存在すること自体を知らないケースを目にしています。
そのため、私はしばしば、コーディングエージェントに対して異なるサービスの使用方法に関する情報を提供するために、Markdown でドキュメントを作成するようになりました(AI とウェブ検索の助けを借りて)。各開発者が利用したいすべてのサービスについて手動でこれを行う代わりに、週末を利用して Rohit Prsad と私は、コーディングエージェントに必要なコンテキストを提供するためのオープンなコンテキスト管理システムを開発しました。このプロジェクトの支援に尽力してくれた Xin Ye 氏と Neil Thomas 氏にも感謝しています。
Context Hub(略称:chub)を npm を通じてインストールし、その出力を確認するようお勧めします:
npm install -g @aisuite/chub
chub search openai # 利用可能なものを検索
chub get openai/chat --lang py # 現在のドキュメントを取得
コーディングエージェントに chub を使用させるには、プロンプトで指示を出す(例:「OpenAI への呼び出しに関する最新 API ドキュメントを取得するために CLI コマンド chub を使用してください。'chub help'を実行して動作方法を確認してください」)か、SKILL.md を使用してエージェントスキルを付与し、chub を自動的に使用できるようにするか、できればエージェントに対して chub の使用を忘れないようプロンプトで指示してください。(Claude Code を使用している場合は、ディレクトリ ~/.claude/skills/get-api-docs を作成し、このファイルをそこに配置します)。
Chub は、エージェントが時間とともに改善できるよう設計されています。例えば、あるツールに関するドキュメントが不十分であることに気づきつつも回避策を発見したエージェントは、メモを残すことで次回からゼロから再発見する必要をなくすことができます。
OpenClaw の爆発的な成長に伴い、エージェント同士が情報を共有し議論を行うためのソーシャルネットワーク Moltbook が目覚ましく台頭してきました。これに触発され、私たちは chub を進化させ、異なるエージェントがそれぞれのツールに関する発見や、ドキュメントにバグが含まれている可能性のある箇所について情報を共有できるようにする計画です。これはまだ実装されていませんが、コーディングエージェントのコミュニティがお互いを助け合う姿を見るのは非常に楽しみです。
chub には、主要な LLM プロバイダー、データベース、決済プロセッサ、ID 管理ソリューション、メッセージングプラットフォームなど、最も人気のあるツールのいくつかに関する初期ドキュメントセットを充实しました。現在のリストは こちら で確認できます。人気のあるエージェントツールのプロバイダーである方は、ドキュメントの提供をご検討ください。コミュニティ全体で Context Hub を改善し、皆のために役立つものにしていきたいと考えています。
作り続けよう!
Andrew
A MESSAGE FROM DEEPLEARNING.AI
現在利用可能:Google とのコラボレーションにより制作された「JAX を用いた大規模言語モデルの構築とトレーニング」。JAX を使用して、2000 万パラメータの MiniGPT スタイルの言語モデルをトレーニングします。アーキテクチャの実装から、トレーニングデータの事前処理、チェックポイントの管理、そしてチャットインターフェースを通じた推論実行まで、大規模言語モデルのトレーニングワークフロー全体に取り組みます。今すぐ登録
News

Nano Banana 2 がパフォーマンスと価格比を向上
Google は、主力画像生成モデルの後継として、より安価で高速な製品を発表し、約半分の価格でより高いインタラクティブ性を実現しました。
新機能: Google は Nano Banana 2(正式名称:Gemini 3.1 Flash Image)をリリースしました。これは、Gemini 3 Flash の高速性と、言語・推論における強みを活用した画像生成システムです。その速度は前世代の Nano Banana Pro と比べて約 4 倍速く、画像あたりのコストも約半分に抑えられています。
- 入力/出力:テキストと画像(最大 100 万トークン)を入力し、画像を出力(最大 4,000 トークン;解像度は 512x512、1024x1024、2048x2048、または 4096x4096 ピクセルのいずれか;アスペクト比は 14 種類;画像生成に要する時間は 1 枚あたり 4〜6 秒)
- アーキテクチャ:Gemini 3 Flash(ジェミニ 3 フラッシュ)を基盤とした Mixture-of-experts(専門家混合型)トランスフォーマー、および非公開のレンダリングモデル
- 機能:検索(テキストおよび画像)、2 レベルの推論(最小限または高レベル)、多言語テキスト描画、複数生成画像にわたる最大 5 人のキャラクターと 14 のオブジェクトの一貫性維持、出力には合成された SynthID(シンシッド)透かしと C2PA コンテンツ認証情報(画像がいつ・どのように生成されたかを記録)が付与される
- パフォーマンス:Arena.ai テキストから画像へのリーダーボードで人間の選好において首位。GPT Image 1.5 および Nano Banana Pro に次いで、Artificial Analysis のテキストから画像へおよび画像編集のアリーナ型リーダーボードでそれぞれ 2 位と 3 位
- 利用可能:Gemini アプリ、Google Ads(グーグル広告)、Google Antigravity(アンチグラビティ)、Flow を通じて無料(制限あり)。API 入力は 100 万トークンあたり 0.50 ドル。出力は画像 1 枚あたり、解像度 512x512 ピクセルで 0.045 ドル、1024x1024 ピクセルで 0.067 ドル、2048x2048 ピクセルで 0.101 ドル、4096x4096 ピクセルで 0.151 ドル。画像検索は月間 5,000 クエリまで無料、追加の 1,000 クエリあたり 14 ドル
- 非公開:アーキテクチャの詳細、パラメータ数、トレーニングデータおよび手法、レンダリングモデル
仕組み: Google は Nano Banana 2(ナノバナナ 2)が「Gemini 3 Flash に基づいている」と述べる以外に、その構築方法についてほとんど詳細を明らかにしていない。ウェブ検索に基づくグラウンディング、推論能力、高解像度出力といった機能は、前バージョンの Nano Banana Pro とほぼ同等である。ただし、新システムはより高速であり、これにより出力を反復的かつ逐次的に改良しやすくなっている。一部のユーザーは、テキストの描画精度が向上したと報告している。
パフォーマンス: Nano Banana 2 は、独立したリーダーボードにおいて画像生成モデルの上位 3 位以内に入る性能を誇ります。
- Arena.ai のテキストから画像へのリーダーボード(システムを人間の好意度で順位付けする直接対決形式の比較)では、Nano Banana 2 が首位(Elo 1,280)に立ち、GPT Image 1.5(1,248)や Nano Banana Pro(1,238)を上回っています。Arena.ai の画像編集リーダーボードでは、ウェブ検索機能を有効にした Nano Banana 2 が第 2 位(Elo 1,401、暫定結果)となり、OpenAI の GPT Image(Elo 1,407)に次ぎ、Nano Banana Pro(Elo 1,398)を上回っています。ただし、Nano Banana 2 のスコアは暫定値(約 3,000 票)であるのに対し、GPT Image 1.5 のスコアは確立されたもの(約 50,000 票)です。
- Artificial Analysis のテキストから画像へのリーダーボード(これも人間の好意度でシステムを順位付けする直接対決形式の比較)では、Nano Banana 2(Elo 1,264)は高推論モードに設定された OpenAI の GPT Image 1.5(Elo 1,268)に次ぎ、Nano Banana Pro(Elo 1,220)を上回っています。Artificial Analysis の画像編集リーダーボードでは、Nano Banana 2(Elo 1,233)は高推論モードに設定された GPT Image 1.5(Elo 1,268)および Nano Banana Pro(Elo 1,250)に次いでいます。
ニュースの背景: 画像生成における競争は非常に激しく、急速に進んでいます。2025 年 8 月末にリリースされた最初のバージョンの Nano Banana(正式名称は Gemini 2.5 Flash Image)は 数週間で Gemini アプリに 1,000 万人以上の新規ユーザーをもたらしました。11 月には、Google の Gemini 3 Pro ビジョン言語モデルを基盤とする Nano Banana Pro が画像生成リーダーボードで首位に立ちました。OpenAI はこれに対し、CEO サム・アルトマンが Google に追いつくための「コードレッド」指令を出したことに反応し、リリースを加速させた GPT Image 1.5 を 12 月に発表 しました。これは *TechCrunch* の報道 によると、同社が Google に追いつくための「コードレッド」作戦を継続していることを示しています。Nano Banana 2 は、高品質モードに設定された GPT Image 1.5 の価格の約 60% 低い価格で、テキストから画像へのトップポジションに近づいています。
なぜ重要なのか: マーケティング資料の作成、製品の可視化、ストーリーボード制作などのクリエイティブなアプリケーションでは、所望の構成、照明、スタイルに到達するために多くの反復が必要になることがよくあります。そのため、画像あたりのコストと速度が重要な要素となります。ウェブ検索に基づく機能は、出力を正しく得るために必要な試行回数を減らすことができ、画像あたりのコストを半分にすることで、残りの予算を倍増させることができます。
私たちが考えていること: Nano Banana はさらに熟成しています!

米国防総省が Anthropic を解雇し、OpenAI を採用
OpenAI は、機密情報を安全に処理する AI システムを提供するため、米国軍と契約を結び、Anthropic の Claude に取って代わりました。OpenAI は自社の技術の使用制限について交渉しましたが、解釈の余地を残しています。
何が起きたか: OpenAI と米国戦争省(Department of War)との間の合意は、ホワイトハウスと Anthropic の間で 1 週間にわたる対立があった直後の数時間後に成立した。Anthropic は、監視や自律型兵器への自社の技術の利用を制限しようとしていた。この対立は、Anthropic との取引を行うことをホワイトハウスが禁止したことで終結した。OpenAI の CEO サム・アルトマンは後に、自分が交渉した急遽の契約は誤りだったと発言し、監視や自律型兵器に関する制限の一部を再交渉したと述べた。その結果、同社は「機会主義的でずさんな」企業として映ってしまった。Anthropic は、適切な理由や権限なく自社の事業を制限した政府に対して訴訟を起こすと誓約した。
権力闘争: 米国軍は、少なくとも 2025 年初頭にトランプ大統領が AI 開発への障壁を排除するよう連邦機関に指示を出して以来、Anthropic、OpenAI、Google、xAI の大規模言語モデルの利用を拡大してきました。
- 1月3日、米軍はベネズエラに対して作戦を開始し、軍事・法執行機関向けにデータ分析を行う Palantir が提供するクラウドプラットフォームを介して Anthropic の技術を運用した。Anthropic の経営陣はこの利用について Palantir に懸念を表明したが、Palantir はその会話を政府へ伝えた。その後、Anthropic はベネズエラ作戦に反対したことはないと否定した。
- 翌週、戦争省(Department of War)は、戦闘・情報収集・組織管理において主要な AI モデルを実験するプログラムを開始した。このプログラムでは、AI 企業に対し既存契約の再交渉を求めた。
- その後の交渉で、Anthropic は Claude を米国人の監視や完全自律型兵器の運用に使用しないことを条件とした。戦争省は外部からの制限を容認しないと表明した。同省は Claude を監視や自律型兵器に使用する意図はないとしているが、受け入れることができる制限は米国法によって要求されるもののみであると述べた。
- 2月23日、xAI と戦争省は、軍が Grok を機密システムで「すべての合法的な用途」で使用することを認める合意に至った。
- その翌日、国防長官のピーター・ヘグセス(Pete Hegseth)は Anthropic の CEO ダリオ・アモダイ(Dario Amodei)と会談し、同社が金曜日の午後5時01分までに制限を緩和することに合意しない場合、「国家安全保障に対するサプライチェーンリスク」として指定すると誓約した。米軍に供給する請負業者は、サプライチェーンリスクと見なされた企業との取引を禁止されている。この指定はこれまで国家安全保障への脅威となる非米国企業に対してのみ適用されていた。
- 数時間後、OpenAI も同様に契約に署名し、独自の安全ガードレール(安全装置)を維持しつつ、戦争省がその技術を「すべての合法的な目的」で使用することを認めた。
- Anthropic は交渉を続けたが、「合法的な用途」という表現には抵抗を示した。なぜなら、過去にも法律は政府による米国人のスパイ活動を阻止しなかったからである。戦争省は、位置情報やウェブデータを含む、米国人に関する非機密・商用の大量データを分析したいと考えていると述べた。米軍が米国人に対する監視を行うことは禁止されているが、商用データの集約と分析は許可されている。
- 2月27日午後1時直前(期限の4時間前)、トランプ大統領は自身が所有するソーシャルネットワーク「Truth Social」に投稿し、すべての連邦機関に対し6ヶ月以内に Anthropic の技術の使用を停止するよう指示した。この投稿では、Anthropic が協力しない場合、「重大な民事・刑事上の結果」が科されると脅し、同社を「制御不能で、現実の世界について何も知らない人々が運営する過激な左派の AI 企業」と呼んだ。
- その日午後5時14分、ヘグセスはソーシャルネットワーク「X」上で、Anthropic を国家安全保障に対するサプライチェーンリスクとして指定し、米軍と取引を行う請負業者・供給業者・パートナーがその技術を使用することを禁止すると発表した。
- その後、一部の非軍事系の米国機関も Anthropic の製品の使用を停止した。
- 3月2日、OpenAI のアルトマン(Altman)は、同社の合意が急遽行われたと発表し、修正された。これは表面上、監視や自律型兵器への使用に対する制限を組み込むためであったが、依然として大きな曖昧さが残されている。改訂された契約では、「商業的に取得した個人情報または識別可能な情報」の分析を含む米国人の国内監視に OpenAI の技術を使用することを禁止しているが、これはおそらく他の種類の情報の利用を許容するものである。また、「法律・規制・省の方針により人間の制御が必要となるあらゆる場合において、自律型兵器を独立して指揮すること」の使用も禁止されているが、これは明らかに他の方法で自律型兵器を運用するための余地を残している。
ニュースの背景: 米国の多くの法律は、戦争省に国家安全保障に対するサプライチェーンリスクを指定する権限を与えている。この指定により、政府は当該企業を防衛契約またはすべての連邦契約から排除し、他の請負業者との取引も禁止できる。この権力の行使が公記録に残った唯一の事例は昨年であり、ロシアとのつながりを報告しているスイスのサイバーセキュリティ企業 Acronis に対して戦争省が発令した命令である(*Lawfare* 報道)。他の法律は、他の連邦省庁にもサプライチェーンリスクを指定する権限を与えている。例えば、2024 年に商務省はロシアのサイバーセキュリティ企業 Kaspersky を連邦情報システムに対するサプライチェーンリスクとして指定し、2020 年には連邦通信委員会(FCC)が中国の電子機器メーカー Huawei と ZTE を通信サプライチェーンへのリスクと認定した。
なぜ重要なのか: AI は急速に国家安全保障と国民のアイデンティティの問題に絡み合いつつあります。Anthropic、ホワイトハウス、そして戦争省(Department of War)間の争いと、それが OpenAI、xAI、Google に与える影響は、政府が戦争を管理する権限の限界や、AI 企業が自社のモデルの利用条件を設定する権限について、難しい問いを投げかけています。AI を自由に利用したいと考える戦争省は、前代未聞の罰則を科しました。これは多くの観察者にとって、Anthropic の毅然とした姿勢に対する厳しい報復に見えました。一方、Anthropic は裁判所が この処罰を無効とする判決 を下すだろうと信じています。
私たちが考えていること: アメリカ合衆国議会は、アメリカ国民を大規模監視や自律型兵器から守るための規則を作る責任を負っています。この責任を果たすことは、政府と AI 開発者の間の対立を防ぐことに繋がります。AI アプリケーションに適切な制限を設ける法律は、軍事部門とテクノロジー企業との間の権力闘争を解決するための明確な指針を提供するでしょう。
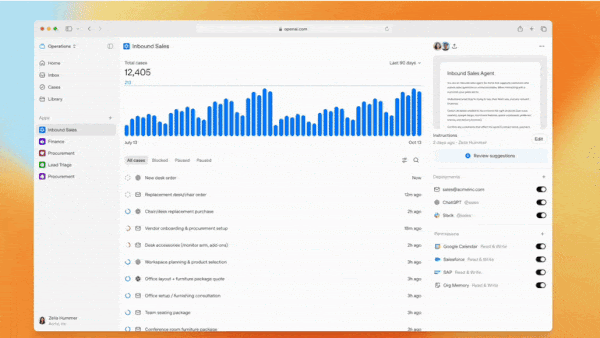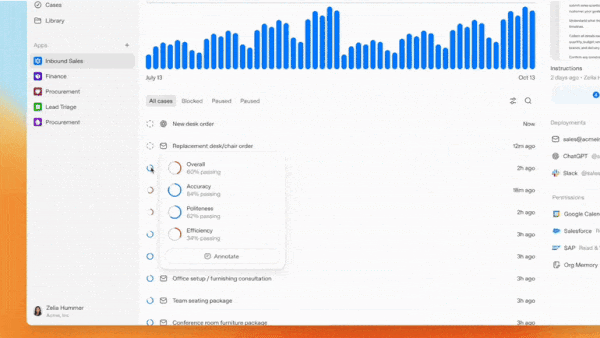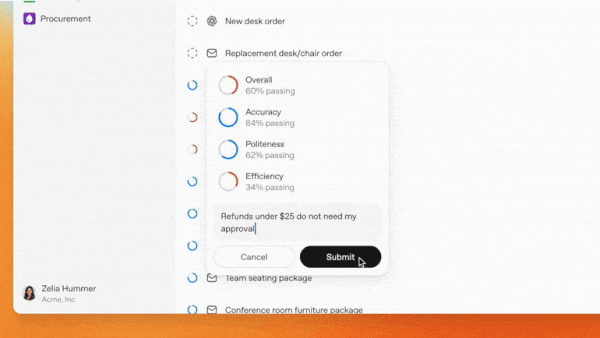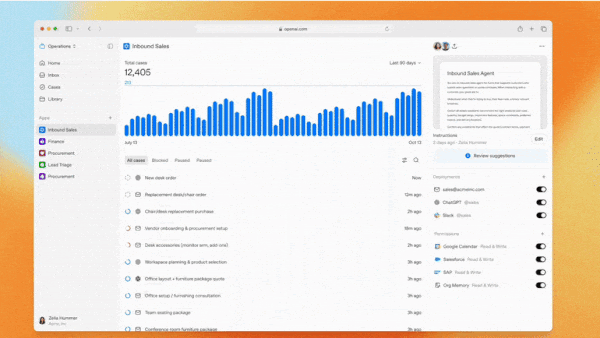
Management for Agents
管理者は、部下がどのように仕事を行い、どのようなリソースを必要とし、何を達成するかを理解する必要があります。OpenAI の最新製品は、チームメイトが AI エージェントである場合にこのニーズに応えることを目指しています。
What's new: OpenAI は Frontier を発表しました。これは、エージェントの企業組織を調整するためのプラットフォームであり、その構築や、情報・ビジネスコンテキストの共有、パフォーマンスの評価、従業員および相互間のインタラクション管理などを支援するものです。Cisco と T-Mobile はパイロットプロジェクトでこのシステムを使用しており、OpenAI は HP、Intuit、Uber などの選定クライアントに対して、専用エンジニアリングサポートとともに Frontier を提供しています。今後は未公開の条件の下、今後数ヶ月以内に Frontier の利用範囲をより広く拡大する計画です。
How it works: Frontier は、関連するフレームワークやモデルに関わらず、エージェントを管理するための統一されたユーザーインターフェースを提供します。管理者はエージェントの構築またはインポート、アクセス権の付与、データソースおよびアプリケーションとの統合、請求管理など、さまざまな機能を担うことができます。OpenAI はシステムに関する詳細情報をほとんど公開していませんが、いくつかの重要なポイントを共有しました。
- 各エージェントは独自のアイデンティティ、権限、ガードレールを持ち、企業はどの従業員やグループがそれを使用できるかを制御できます。
- エージェントはデータへのアクセス、ツール、アプリケーション、関連するシステムおよびワークフローに関する情報など、コンテキストを共有できます。
- Frontier はエージェントの出力を評価し、パフォーマンス向上のためのフィードバックを提供します。プロモーション用のイラストによると、ユーザーは正確性などのグランドトゥルースデータや、大規模言語モデルを使用して礼儀正しさを測定するなど、モデルの出力に基づいて評価指標を設定できるようです。
- エージェントは「記憶を構築し、過去の対話を有用なコンテキストに変換する」ことができ、これはエージェントが以前のプロンプトに対する成功した回答を思い出すことで、時間とともに自動的にパフォーマンスを向上させることができることを示唆しています。
ニュースの背景: Frontier は、Word や Excel などの Microsoft アプリケーションと統合された同様のプラットフォームである Microsoft が数ヶ月前にリリースした Agent 365 に続いて登場しました。Agent 365 はセキュリティとガバナンスにより焦点を当てていますが、Frontier はエージェントの構築、評価、改善のためのより多くの機能を提供します。
なぜ重要なのか: 企業がより多くのエージェントを稼働させるにつれ、それらを大量に管理する能力はますます価値を持つようになります。例えば、ある企業内の一つのグループによって展開されたエージェントがより広い有用性を持つ場合や、異なるグループによって展開されたエージェントが機能を重複させたり、互いに矛盾した目的で作業したりする可能性があります。統一された制御インターフェースにより、こうした機会と課題がより明確になるでしょう。OpenAI と Microsoft のエージェント管理システムは、チームが高レベルからこれらの活動を管理できるようにすることを目的としています。
私たちが考えていること: 概念的には、エージェント向けの「人事」システムは理にかなっています。このようなシステムはまだ初期段階にあります——OpenAI の限定的な展開とエンジニアリング支援の提供が示唆しているように—しかし、企業がより多くのエージェントを自らのために稼働させるにつれて、その明確な有用性は成長していく可能性が高いです。
エージェントが頑固な数学問題を解決
LLM は数学コンテストで金メダル級の性能を達成しました。エージェントシステムは数学研究においても強みを示しています。
何の新情報: トニー・フォン、クオック・V・リー、タン・ルオン、および Google の同僚たちは Aletheia を発表しました。これは、これまで解かれていなかった数学問題に対する解決策を生成し、検証し、修正するエージェントです。Aletheia は、同社の最上位 AI サービスのサブスクリプションユーザー向けに特別化された推論モードである Gemini 3 Deep Think(最新アップデート版)を活用した、数学研究のためのエージェントワークフローです。同時に Google は、Gemini 3 Deep Think を API を通じてより広く利用可能にしました。
Gemini 3 Deep Think: Google は Deep Think を、最も高度な推論モードとして位置づけており、数学・科学・工学における多段階タスク向けに設計されています。これは複数の推論チェーンを並列に生成し、それらを考慮した上で、最終的な出力を得るために修正または組み合わせを行います。
- 入力/出力:テキスト、画像、動画、音声、PDF(最大 100 万トークン)の受け取りと、テキスト出力(最大 65,000 トークン)
- パフォーマンス:HLE で 48.4%(ツールなし)、ARC-AGI-2 で 84.6%、Codeforces で 3455 Elo、GPQA Diamond で 93.8% を達成し、いずれも最先端の記録を樹立
- 利用方法:Google AI Ultra サブスクリプション(月額 250 ドル)付きの Gemini アプリ経由、または早期アクセスによる API 経由で利用可能
- 機能:ウェブ検索、コード実行
- 非公開情報:Gemini 3 Pro と Deep Think 能力の開発手法については、Google はほとんど情報を開示していない
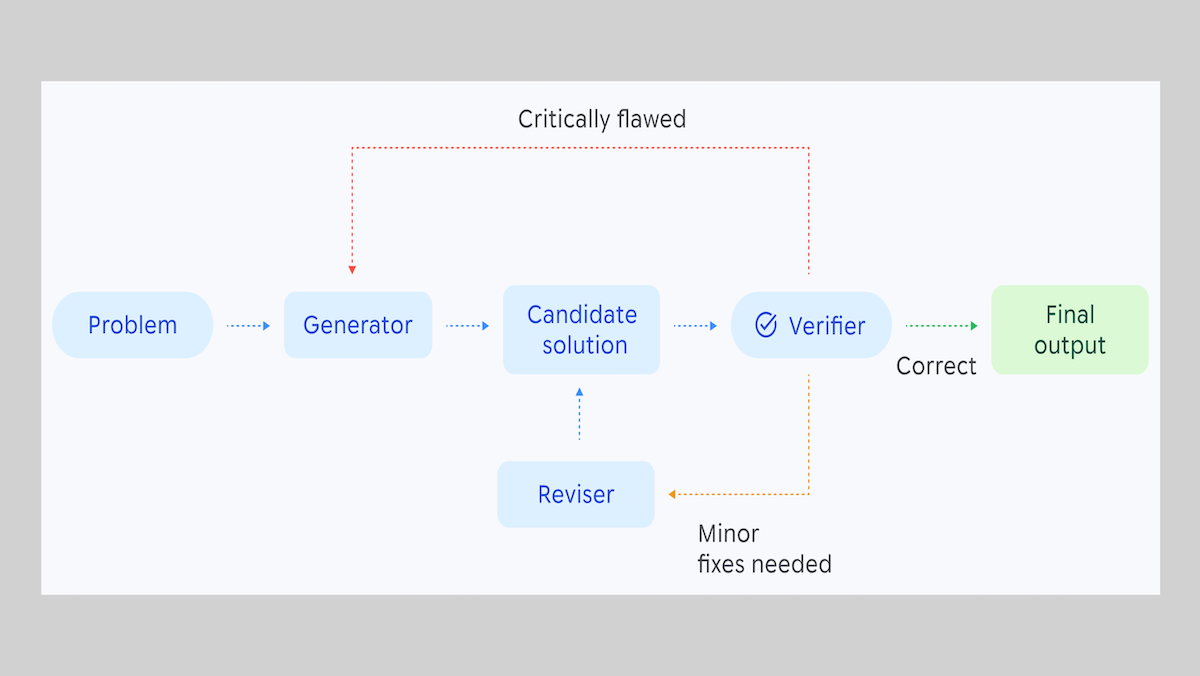
仕組み: Aletheia は、ジェネレーター(生成器)、バーフィア(検証者)、リバイザー(修正者)の 3 つの部分からなるエージェントワークフローであり、すべて Gemini 3 Deep Think によって駆動されています。
- 問題を与えると、生成器は初期の解決策を生成します。
- 検証者はその解決策を確認し、それが「完了」「修正が必要」「致命的に欠陥あり」のいずれかに分類してマークします。
- 解決策に修正が必要な場合、修正担当者が問題と解決策を受け取り、修正されたバージョンを生成して検証者にフィードバックします。
- 解決策が致命的に欠陥がある場合、生成器は問題を再度受け取り、新しい解決策を生成します。
- このプロセスは、検証者が問題を「解決済み」とマークするか、または著者によって設定されたモデル呼び出し回数に達するまで繰り返されます。
結果: 研究者たちはこれまでに Aletheia を6編の論文で使用しています。そのうち2編では Aletheia がほぼすべての作業を担い、2編では人間と Aletheia の双方が重要な貢献をし、残りの2編では人間の側が主要な作業を行い、Aletheia は補助的な役割を果たしました。著者らは、Aletheia は数学の各分野にわたる広範な知識が役立つ状況でよく機能するが、特定の分野における深さについては人間専門家に劣ると指摘しています。
- ある論文は、数学者ポール・エルデシュが提案した解きにくい数学的予想の集合である未解決のエルデシュ問題に対して、4 つの新たな解決策を提供しています。残りの 700 の未解決のエルデシュ問題のうち、Aletheia はそのうち 212 件の解決策を見つけたと述べています。
- 数学者たちはこの 212 の解決策を検討し、200 のケースにおいてそれらが正しいか誤りかを判定しました(残りの 12 件については、問題または解決策が曖昧でした)。200 のうち、137 件(68.5%)は誤りであり、63 件(31.5%)は問題の解釈によっては技術的に正しく、13 件(6.5%)は意図された解釈において正しいものでした。
- 著者たちはこの 13 の正解を評価し、その新規性を検証しました。そのうち 9 件の問題はすでに解決済みであり、Aletheia は既存の研究から解決策を特定するか、既存の研究に解決策が存在する問題を解いたかのいずれかでした。
- 残りの 4 つの解決策は新規性がありました。
ニュースの背景: AI を活用した証明には限定的ながら実効的な成功例があります。これまでの多くの 研究 成果 では、研究者が与えられた定理を証明するのを支援するために大規模言語モデル(LLM)を使用しており、Aletheia のような汎用システムを構築するものではありません。最も類似するのは Google の AlphaEvolve で、これはデータセンターでの計算リソースのスケジューリングや行列乗算のアルゴリズムを改善するエージェント型システムです。
なぜ重要なのか: エージェント型システムは、数学者と協力して新しい手法やロードマップなどを生成できる有用な数学的ツールへと進化しています。アレイシアのようにエージェントの強みが広範な知識にある場合、多くの分野にまたがる問題に関する研究を加速させる一方で、人間の専門家は引き続き自分の得意分野に没頭し続けることができるでしょう。
私たちが考えていること: エルドースは 1930 年代初めから 1996 年の死去までにかけて、ほぼ 1,200 の問題を提案しました。そのうち 500 未満しか解決されていませんが、AI モデルは過去 6 ヶ月だけで約 100 の問題を解決する手助けをしました!
原文を表示
Dear friends,
I’m thrilled to announce Context Hub, a new tool to give to your coding agents the API documentation they need to write correct code. If you’re building AI systems using modern technologies, your coding agent will often use outdated APIs, hallucinate parameters, or not even know about the tool it should be using. This happens because AI tools are rapidly evolving, and coding agents were trained on old data that does not reflect the latest tools. Context Hub, which is designed for your coding agent to use (not for you to use!) provides the context it needs. It also accepts automatic agentic feedback to help your coding agents improve over time.
For example, Claude Opus 4.6, possibly the best coding model currently, has a knowledge cutoff date of May 2025. When I ask it to write code to call OpenAI's GPT-5.2, it uses the older OpenAI chat completions API (client.chat.completions.create) rather than the newer responses API (client.responses.create) that OpenAI recommends. Even though the newer API is a year old, there's a lot more data that Opus was trained on that uses the older interface. It also has no idea about the existence of Nano Banana, which was released in August 2025. More generally, I’ve seen coding models fail to make correct API calls to Gemini and many database services (even popular ones, when I use less common parameter choices), or just not know about a particular tool I want.
Consequently, I’ve found myself often writing documentation in Markdown (with help from AI and web search) to give to my coding agent information on how to use different services. In lieu of every developer doing this manually for every service they want to use, over a weekend, Rohit Prsad and I got together to develop an open context management system for giving coding agents the context they need. I’m also grateful to Xin Ye and Neil Thomas for helping with this project.
I encourage you to install Context Hub (chub for short) using npm, and run it to get a sense of its output:
npm install -g @aisuite/chub
chub search openai # find what's available
chub get openai/chat --lang py # fetch current docs

To get your coding agent to use chub, either prompt it (e.g., "Use the CLI command chub to get the latest API documentation for calling OpenAI. Run 'chub help' to understand how it works."), or give it an agent skill to use chub automatically, by using SKILL.md, and ideally prompt your agent to remember to use it. (If you are using Claude Code, create the directory ~/.claude/skills/get-api-docs and put this file there).
Chub is built to enable agents to improve over time. For example, if an agent finds that the documentation for a tool is incomplete but discovers a workaround, it can save a note so as not to have to rediscover it from scratch next time.
Alongside the explosive growth of OpenClaw, we’ve seen the remarkable rise of the social network Moltbook for agents, where agents share information and debate with each other. Motivated by this, we plan to evolve chub toward letting different agents share information about what they discover about different tools and where documentation might contain bugs. This is not yet implemented, but it will be exciting to see a community of coding agents help each other!
We’ve populated chub with an initial set of documentation for some of the most popular tools, like common LLM providers, databases, payment processors, identity management solutions, messaging platforms, and so on. You can see the current list here. If you’re a provider of a popular agent tool, please consider contributing documentation. I hope our community can collectively improve Context Hub for everyone.
Keep building!
Andrew
A MESSAGE FROM DEEPLEARNING.AI
Now available: “Build and Train an LLM with JAX,” made in collaboration with Google. Train a 20 million-parameter, MiniGPT-style language model using JAX. You’ll work through the full LLM training workflow: implementing the architecture, preprocessing training data, managing checkpoints, and running inference through a chat interface. Enroll now
News
Nano Banana 2 Ups Performance/Price
Google launched a cheaper, faster successor to its flagship image generator, delivering greater interactivity at roughly half the price.
What’s new: Google launched Nano Banana 2 (formally designated Gemini 3.1 Flash Image), an image-generation system that takes advantage of Gemini 3 Flash’s speed and strengths in language and reasoning. It’s around four times faster and costs roughly half as much per image as its predecessor Nano Banana Pro.
- Input/output: Text and images in (up to 1 million tokens), images out (up to 4,000 tokens; 512x512, 1024x1024, 2048x2048, or 4096x4096 pixel resolutions; 14 aspect ratios; 4 seconds to 6 seconds per image)
- Architecture: Mixture-of-experts transformer based on Gemini 3 Flash, undisclosed rendering model
- Features: Search (text and image), two levels of reasoning (minimal or high), multilingual text rendering, character and object consistency for up to five characters and 14 objects across multiple generated images, output marked with invisible SynthID watermark and C2PA Content Credentials that record how and when images were generated
- Performance: Leads Arena.ai text-to-image leaderboard of human preference, ranks second and third on Artificial Analysis Text to Image and Image Editing arena-style leaderboards after GPT Image 1.5 and Nano Banana Pro
- Availability: Free (with limits) via Gemini app, Google Ads, Google Antigravity, and Flow; API input $0.50 per 1 million tokens, output $0.045 (512x512 pixel resolution), $0.067 (1024x1024 pixel resolution), $0.101 (2048x2048 pixel resolution), and $0.151 (4096x4096 pixel resolution) per image; image search free for the first 5,000 queries per month, $14 per 1,000 additional queries
- Undisclosed: Architecture details, parameter count, training data and methods, rendering model
How it works: Google disclosed few details about how it built Nano Banana 2 beyond stating that it is “based on” Gemini 3 Flash. Capabilities such as grounding in web search, reasoning, and high-resolution output essentially match those of the previous version Nano Banana Pro. However, the new system is faster, which makes it easier to refine the output iteratively and sequentially. Some users reported that it renders text more accurately.
Performance: Nano Banana 2 ranks among the top three image generators on independent leaderboards.
- On Arena.ai’s text-to-image leaderboard (a head-to-head comparison that ranks systems by human preference), Nano Banana 2 leads (1,280 Elo), ahead of GPT Image 1.5 (1,248) and Nano Banana Pro (1,238). On Arena.ai’s image edit leaderboard, Nano Banana 2 (with web search enabled) places second (1,401 Elo, preliminary results) behind OpenAI’s GPT Image (1,407 Elo) and ahead of Nano Banana Pro (1,398 Elo). However, Nano Banana 2’s score is preliminary (around 3,000 votes), while GPT Image 1.5’s score is well established (around 50,000 votes).
- On the Artificial Analysis text-to-image leaderboard (also a head-to-head comparison that ranks systems by human preference), Nano Banana 2 (1,264 Elo) fell behind OpenAI’s GPT Image 1.5 set to high reasoning (1,268 Elo) and ahead of Nano Banana Pro (Elo 1,220). On the Artificial Analysis image editing leaderboard, Nano Banana 2 (1,233 Elo) trailed GPT Image 1.5 set to high reasoning (1,268 Elo) and Nano Banana Pro (1,250 Elo).
Behind the news: Competition in image generation has been fast and furious. Launched in late August 2025, the first version of Nano Banana (officially called Gemini 2.5 Flash Image) attracted over 10 million new users to the Gemini app within weeks. In November, Nano Banana Pro, based on Google’s Gemini 3 Pro vision-language model, topped image-generation leaderboards. OpenAI responded in December with GPT Image 1.5 — a launch that OpenAI accelerated in response to CEO Sam Altman’s “code red” instructions to catch up to Google, according to *TechCrunch*. Nano Banana 2 nears the top text-to-image position at a price roughly 60 percent lower than that of GPT Image 1.5 set to high quality.
Why it matters: Creative applications like producing marketing materials, product visualization, or storyboards often require many iterations to arrive at a desired composition, lighting, and style. That makes per-image cost and speed important factors. Grounding in web search can reduce the number of attempts needed to get the output right, and halving the cost per image doubles the budget for those that remain.
We’re thinking: Nano Banana keeps ripening!
U.S. Dept. of War Dismisses Anthropic, Embraces OpenAI
OpenAI signed a contract with the U.S. military to provide AI systems that securely process classified information, displacing Anthropic’s Claude. OpenAI negotiated limits on how its technology can be used, but they leave room for interpretation.
What happened: The agreement between OpenAI and the U.S. Department of War came only hours after a week-long standoff between the White House and Anthropic, which wanted to limit military use of its technology for surveillance and autonomous weapons. The standoff ended with a White House ban on doing business with Anthropic. OpenAI CEO Sam Altman later said the hasty contract he had negotiated was a mistake — the parties renegotiated some restrictions around surveillance and autonomous weapons — and made his company look “opportunistic and sloppy.” Anthropic vowed to sue the government for limiting its business without proper reason or authority.
Power struggle: The U.S. military has been expanding its use of large language models from Anthropic, OpenAI, Google, and xAI at least since early 2025, when President Trump directed federal agencies to eliminate obstacles to AI development.
- On January 3, the U.S. military launched an operation against Venezuela in which it used Anthropic’s technology via a cloud platform provided by Palantir, which performs data analytics for military and law-enforcement agencies. Anthropic executives reportedly expressed concern about that use to Palantir, which relayed the conversation to the government. Anthropic later denied it had objected to the Venezuela operation.
- The following week, the Department of War launched a program to experiment with leading AI models in combat, intelligence, and organizational management. The program required AI companies to renegotiate existing contracts.
- In subsequent negotiations, Anthropic stipulated that Claude could not be used in surveillance of U.S. citizens or to operate fully autonomous weapons. The Department of War said it would not tolerate external limitations. Although the department said it did not intend to use Claude for surveillance or autonomous weapons, the only limits it would accept were those required by U.S. law.
- On February 23, xAI and the Department of War reached an agreement to allow the military to use Grok in classified systems for “all lawful uses.”
- The next day, Secretary of Defense Pete Hegseth met with Anthropic CEO Dario Amodei and vowed to designate Anthropic a “supply chain risk to national security” if the company did not agree to relax its restrictions by 5:01 p.m. on Friday. Contractors that supply the U.S. military are barred from doing business with companies that are deemed supply-chain risks. This designation previously had been applied only to non-U.S. companies that posed a risk to national security.
- Within hours, OpenAI, too, signed a contract that allows the Department of War to use its technology “for all lawful purposes” while retaining its own safety guardrails.
- Anthropic continued to negotiate but balked at the language about lawful purposes, since the law has not stopped the government from spying on U.S. citizens in the past. The Department of War said it wanted to analyze unclassified, commercial bulk data on U.S. citizens, including locations and web data. While the U.S. military is prohibited from conducting surveillance on U.S. citizens, it is allowed to aggregate and analyze commercial data.
- On February 27 just before 1:00 p.m. — four hours before the deadline — President Trump posted on Truth Social, a social network owned by the President, directing all federal agencies to stop using Anthropic’s technology within six months. The post threatened “major civil and criminal consequences” if Anthropic did not cooperate, calling Anthropic an “out-of-control, Radical Left AI company run by people who have no idea what the real World is all about.”
- At 5:14 p.m. that day, Hegseth announced on the X social network that he had designated Anthropic a supply-chain risk to national security, forbidding contractors, suppliers, and partners that do business with the United States military from using its technology.
- Subsequently, some non-military U.S. agencies terminated their use of Anthropic products.
- On March 2, OpenAI’s Altman announced that his company’s agreement had been rushed. It was amended, ostensibly to build in limits on uses for surveillance and autonomous weapons, but also leaving substantial ambiguity. The revised contract prohibits uses of OpenAI technology for domestic surveillance of U.S. citizens including via analysis of “commercially acquired personal or identifiable information,” which presumably allows uses of other types of information. It also bars uses to “independently direct autonomous weapons in any case where law, regulation, or Department policy requires human control,” apparently leaving room to use the technology to operate autonomous weapons in other ways.
Behind the news: A number of U.S. laws empower the Department of War to name supply-chain risks to national security. This designation allows the government to exclude such risky companies from either defense contracts or all federal contracts and to disallow other contractors from working with them. The only use of this power in the public record occurred last year, when the Department of War issued an order against Acronis, a Swiss cybersecurity firm that has reported ties to Russia, *Lawfare* reported. Other laws empower other federal departments to name supply-chain risks. For instance, in 2024 the Department of Commerce designated Kaspersky, a Russian cybersecurity company, a supply-chain risk to federal information systems, in 2020 the Federal Communications Commission labeled the Chinese electronics manufacturers Huawei and ZTE risks to communications supply chains.
Why it matters: AI is rapidly becoming entangled in issues of national security and national identity. The disputes between Anthropic, the White House, and the Department of War, and their implications for OpenAI, xAI, and Google, raise difficult questions about limits on the power of governments to manage warfare and the power of AI companies to set the terms of their models’ use. The Department of War, which would like a free hand to use AI as it sees fit, imposed an unprecedented penalty — which struck many observers as a harsh retaliation against Anthropic’s firm stand — and Anthropic showed faith that courts will rule the punishment invalid.
We’re thinking: The U.S. Congress is responsible for making rules that protect the Americans from mass surveillance and autonomous weapons. Exercising that responsibility could head off conflicts between the government and AI developers. Laws that placed appropriate limits on AI applications would provide clear guidelines to help resolve such power struggles between the military and technology companies.
Management for Agents
Managers need to understand how their subordinates get work done, what resources they require, and what they accomplish. OpenAI’s latest product aims to fulfill this need when the teammates are AI agents.
What’s new: OpenAI announced Frontier, a platform designed to help orchestrate corporate cadres of agents, including building them, sharing information and business context among them, evaluating their performance, and managing their interactions with employees and each other. Cisco and T-Mobile have used the system in pilot projects, and OpenAI is offering it, along with dedicated engineering help, to selected clients including HP, Intuit, and Uber. It plans to make Frontier more widely available in coming months under terms that are not yet disclosed.
How it works: Frontier provides a unified user interface for managing agents regardless of the frameworks and models involved. Administrators can build or import agents, provide access to them, integrate data sources and applications, and manage billing, among other functions. OpenAI revealed little information about the system but shared some key points:
- Each agent has its own identity, permissions, and guardrails, and companies can control which employees or groups can use it.
- Agents can share context including access to data, tools, applications, and information about relevant systems and workflows.
- Frontier evaluates agents’ outputs and provides feedback to improve their performance. Based on promotional illustrations, it appears that users can set evaluation metrics based on ground-truth data, such as accuracy, or model output, for example, using a large language model to measure politeness.
- Agents can “build memories, turning past interactions into useful context,” which implies that agents can improve their performance automatically over time by recalling successful responses to earlier prompts.
Behind the news: Frontier arrives a few months after Microsoft released Agent 365, a similar platform that integrates with Microsoft applications like Word and Excel. Agent 365 focuses more tightly on security and governance, while Frontier offers more features for building, evaluating, and improving agents.
Why it matters: As a company puts more agents to work, the ability to manage them en masse becomes more valuable. For instance, an agent deployed by one group within a company may have broader utility, or agents deployed by disparate groups may duplicate functions or work at cross purposes. A unified control interface may make such opportunities and issues more apparent. The agent-management systems from OpenAI and Microsoft aim to enable teams to manage these activities from a higher level.
We’re thinking: Conceptually, a “human resources” system for agents makes sense. Such systems are in their infancy — as suggested by OpenAI’s limited rollout and provision of engineering help — but they have clear utility that’s likely to grow as companies put more agents to work on their behalf.
Agent Solves Stubborn Math Problems
LLMs have achieved gold-medal performance in math competitions. An agentic system showed strength in mathematical research as well.
What’s new: Tony Feng, Quoc V. Le, Thang Luong, and colleagues at Google introduced Aletheia, an agent that generated, verified, and revised solutions to previously unsolved math problems. Aletheia is an agentic workflow for math research that uses the latest update of Gemini 3 Deep Think, a specialized reasoning mode of the Gemini 3 Pro model for subscribers to the company’s top-tier AI service. Concurrently, Google made Gemini 3 Deep Think more widely available via API.
Gemini 3 Deep Think: Google bills Deep Think as its most advanced reasoning mode, geared toward multi-step tasks in math, science, and engineering. It generates multiple chains of reasoning in parallel, considers them, and revises or combines them to produce final output.
- Input/output: Text, image, video, audio, pdf in (up to 1 million tokens); text out (up to 65,000 tokens)
- Performance: Achieved state of the art on HLE (48.4 percent without tools), ARC-AGI-2 (84.6 percent), Codeforces (3455 Elo), GPQA Diamond (93.8 percent)
- Availability: Via Gemini app with Google AI Ultra subscription ($250/month), via API with early access
- Features: web search, code execution
- Undisclosed: Google has disclosed little information about how it built Gemini 3 Pro and the Deep Think capability
How it works: Aletheia is an agentic workflow with three parts — generator, verifier, and reviser — all powered by Gemini 3 Deep Think.
- Given a problem, the generator produces an initial solution.
- The verifier checks that solution and marks it either as complete, in need of fixes, or critically flawed.
- If the solution needs fixes, the reviser takes the problem and solution, and generates a modified version of the solution, which it feeds back to the verifier.
- If the solution is critically flawed, the generator takes the problem again and generates a new solution.
- The process repeats until the verifier marks a problem as solved or an author-set number of model calls occurs.
Results: Researchers have used Aletheia in six published papers to date: two in which Aletheia did essentially all the work, two in which both humans and Aletheia contributed significantly, and two in which humans did most of the work and Aletheia helped a little. The authors note that Aletheia works well in situations where broad knowledge across subfields of math is helpful, but it doesn’t have as much depth within subfields as a human specialist.
- One of the papers offers four novel solutions to unsolved Erdős problems, a set of difficult-to-solve mathematical conjectures proposed by the mathematician Paul Erdős. Of the remaining 700 unsolved Erdős problems, Aletheia said it found solutions to 212 of them.
- Mathematicians examined the 212 solutions and found them correct or incorrect in 200 cases. (For the other 12, the problem or solution was ambiguous.) Of the 200, 137 (68.5%) were incorrect, 63 (31.5%) were technically correct under some interpretation of the problem, and 13 (6.5%) were correct under the intended interpretation.
- The authors examined the 13 correct answers to evaluate their novelty. The problem had already been solved in 9 of them: Aletheia either identified the solution from existing research or solved a problem that had a solution in existing research.
- The remaining four solutions were novel.
Behind the news: AI-assisted proofs have had limited but real success. In most previous work, researchers used an LLM to help them prove a given theorem, as opposed to building a generalist system like Aletheia. Most similar would be Google’s AlphaEvolve, an agentic system that improved algorithms for scheduling compute usage in a data center and multiplying matrices.
Why it matters: Agentic systems are becoming useful mathematical tools that can work with mathematicians to help generate new methods, roadmaps, and the like. If, like Aletheia, an agent’s strength is its breadth of knowledge, it may accelerate research into problems that touch on knowledge from many subfields, while human specialists continue to dive into their favorite fields.
We’re thinking: Erdős proposed nearly 1,200 problems between the early 1930s and his death in 1996. Fewer than 500 have been solved, but AI models have helped to solve around 100 of them in the past six months alone!
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み