ポプサがアマゾン・ノバを活用し、パーソナライズされたタイトル提案で顧客にインスピレーションを与えた方法
PopsaはAmazon BedrockとNovaモデルを活用し、メタデータやコンピュータビジョンを統合したRAGアーキテクチャで12言語に対応するパーソナライズされたタイトル生成を実現し、顧客満足度と購入率を向上させた。
キーポイント
Amazon BedrockとNovaモデルの活用
AnthropicのClaude 3 Haiku、Amazon Nova LiteおよびProを組み合わせた統一APIを用い、品質向上、コスト削減、応答時間短縮を実現した。
RAGアーキテクチャによる高度な生成
メタデータ(タイムスタンプ、地理座標)とオンデバイスCNNによる画像特徴抽出を組み合わせ、Retrieval-Augmented Generative AI(RAG)でクリエイティブなタイトルを自動生成している。
ビジネスインパクトの顕著な向上
2025年に550万以上のパーソナライズドタイトルを生成し、顧客満足度、エンゲージメント、購入率の測定可能な向上をもたらした。
影響分析・編集コメントを表示
影響分析
この事例は、大規模言語モデル(LLM)やマルチモーダルAIを単なるチャットボットやコンテンツ生成だけでなく、既存の製品機能(Photo Bookのタイトル)の高度化にどう統合するかという実装パターンを示している。特に、コストと速度を犠牲にせず品質を向上させるために、複数のモデルを用途に応じて使い分けるアーキテクチャ設計は、他のSaaS企業にとって参考になる実用的な知見である。
編集コメント
AWS公式ブログであるためPR色は否めないが、複数のAIモデルをAPI経由で組み合わせてコストと品質のバランスを取る具体的なアーキテクチャ事例として、実務者の参考価値は高い。
この投稿は、PopsaのBradley GranthamとHugo Dugdaleとの共著です。
Popsaは、ユーザーが写真ライブラリに隠された意味のある思い出を再発見し、再び楽しむのを支援するテクノロジー企業です。50以上の国と12の言語で提供されており、デザイン自動化とAIを活用して、美しく印刷されたPhoto Booksなど、日常的な写真をパーソナライズされ、共有可能な体験に変換しています。
2016年、私たちは*PrintAI*をリリースしました。これは、ユーザーの写真から多様で興味深いデザインを完全に制御して作成するための先駆的なアルゴリズムです。顧客はこのアルゴリズムを使用して、5分以内にプロフェッショナルなデザインに見えるPhoto Booksを作成できました。
私たちのビジネスの中核となる哲学は、「テクノロジーがユーザーのために重い作業を行うべきである」というものであり、自動化は常に私たちの製品の不可欠な一部でした。現在の*Generative AI(生成AI)*の時代において、ソフトウェアの使用をより複雑にすることなく、顧客の体験をさらに向上させる方法をさらに開発することができます。
この投稿では、Amazon Bedrock と Amazon Nova モデルファミリーを活用して、タイトル提案機能をどのように再構築したかをご紹介します。メタデータ、コンピュータビジョン、および検索拡張生成 AI(Retrieval-Augmented Generative AI)を組み合わせることで、12 言語にわたってブランドのトーンに合ったクリエイティブなタイトルとサブタイトルを自動的に生成しています。Amazon Bedrock の統一 API、Anthropic の Claude 3 Haiku、そして Amazon Nova Lite および Pro を使用することで、品質の向上、コスト削減、応答時間の短縮を実現しました。その結果、顧客満足度の向上、エンゲージメントおよび購入率の測定可能な増加、そして 2025 年に 550 万件以上のパーソナライズされたタイトルが生成されるという成果を上げました。
Amazon Bedrock を用いたタイトル提案の生成
顧客がフォトブックを受け取った際、最初に目にするのは前面カバーであり、そこには大きなタイトルとサブタイトルが表示されます。高品質なタイトルとサブタイトルはフォトブックのデザインを格上げしますが、ほとんどの顧客はプロのコピーライターではなく、「2024 年のフランス」「スペインからの写真」、さらには単に「写真」といったシンプルなタイトルで満足することが多いです。
ユーザーの写真をより魅力的にするため、私たちは「タイトル提案」と呼ばれる機能を開発し、2021 年からユーザーに提供しています。
ユーザーがフォトブックのデザイン用写真を選択すると、モバイルアプリは画像からタイムスタンプや地理座標などのメタデータを読み取り、オンデバイスでの畳み込みニューラルネットワーク(Convolutional Neural Networks)を実行して関連する特徴を抽出します。例えば、画像にビーチやバーベキュー、ペットが含まれているかどうかを判別します。
このデータを活用するため、「Title Suggestion Graph(タイトル提案グラフ)」というアルゴリズムを作成しました。このアルゴリズムは、選択された写真のメタデータとデータを用い、一連のルールやテンプレートに従って可能なタイトルのリストを構築し、適切な提案のセットに到達します。例えば:
もしデザイン内のすべての写真が同じ日に撮影された場合
then「On this Day(この日)」をタイトルとして、特定の日期をサブタイトルとする提案を行います。
2024年6月、生成型AI(Generative AI)を適用してタイトル提案を改善する機会を見出し、ユーザーにより創造的なタイトルでインスピレーションを与えることを目的としました。まず、問題を明確に定義し、評価指標を確立することから始めました。私たちのソリューションは厳格な要件を満たす必要がありました:
- 文字数制限
レイアウトの制約により表紙に表示されるテキストの表示方法に影響するため、タイトルとサブタイトルの両方が36文字を超えてはいけません。
- タイトルのカテゴリ
各タイトル・サブタイトルのペアには、ユーザーに表示されるアイコンを決定する関連するカテゴリが存在する必要があります。想像上の間違ったカテゴリでは、アイコンがレンダリングされません。
- JSON形式
最後に、すべての出力は title、subtitle、category というキーを持つ有効なJSONである必要があります。これにより、アプリ内での一貫したパース(解析)、検証、レンダリングが可能になりました。
これらのルールはコードで定義可能だったため評価に役立ちました。そのため、100冊以上の例となるフォトブックのデータセットを構築し、評価パイプライン内で指標を定義しました。
- 文字数制限内でのタイトル/サブタイトルの提案率
- 有効なタイトルカテゴリの割合
- 正しいJSON形式での回答率
これらの厳格なルールの他にも、ソリューションは以下のより広範なガイドラインを満たす必要がありました:
- テーマの一貫性
カテゴリはコンテンツと一致している必要があります(例えば、デザインの対象がビーチの休暇である場合、スキーのアイコンは適切ではありません)
- ブランドスタイル
提案はPopsaのトーンとブランドアイデンティティを反映している必要があります
- タイトルとサブタイトルの調和
ペアはお互いを補完するものでありなければならず、反復的であったり不整合であってはなりません。
- 多言語の品質
提案は、私たちがサポートする12すべての言語で高品質である必要がありました。
私たちは、これらのガイドラインに対するパフォーマンスを評価するために「LLM-as-a-judge(LLMを審査員として用いる手法)」を使用することにしました。これにより、異なるモデル、プロンプト、方法を迅速にテストし、最も信頼性の高いアプローチを特定することができました。2つまたは3つのオプションに絞り込んだ後、私たちは広範な社内テストを実施しました。
私たちの最上位の結果は、「検索ベースのフューショットプロンプティング」から得られました。私たちは、例となるフォトブックと許容されるタイトル提案のデータベースを作成しました。新しいフォトブックに対して、類似した数件のフォトブックデザインと、それらの提案されたタイトルからランダムに選択されたものを取得しました。
Amazon BedrockとAnthropicのClaude 3 Haikuを活用し、ユーザーの新しいデザイン文書を最後のメッセージとして追加する前に、これらの例を*システム*メッセージとして会話にシードしました。これにより、大規模言語モデル(LLM: Large Language Model)が過去の応答を模倣しつつ、私たちが定義したルールを自然に遵守することが可能になりました。
このソリューションの全体アーキテクチャは、以下の図で確認できます:
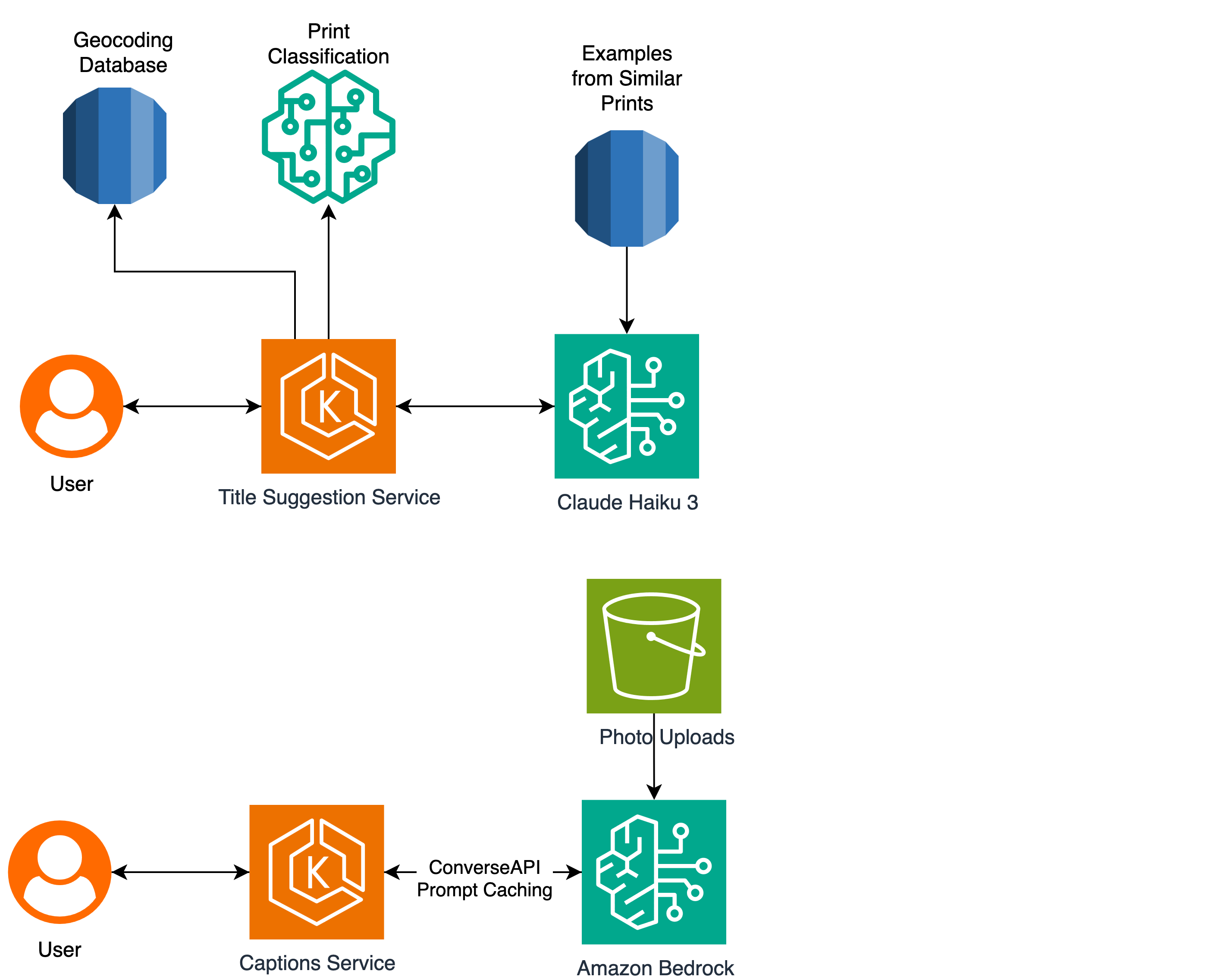
Title Suggestion Service(タイトル提案サービス)がリクエストを受信すると、まずユーザーのデザインを復号・処理してタイムスタンプを抽出します。次に、デザインに含まれる緯度と経度に対して逆ジオコーディング処理を実行し、物体のランドマークに基づいてデザインの主題を分類します。
これにより、「*2025年1月21日から2025年1月23日の間にアルプスで撮影された21枚の写真によるスキーフォトブック*」といった説明が生成されます。その後、この説明を*検索ベースのフューショットプロンプティング(retrieval-based few-shot prompting)*コンポーネントに渡して、最終的なユーザー向け提案を生成します。
以前のグラフベースの手法との比較では、より良い結果が得られています:
改善効果を定量化するために、私たちはフィードバックループを活用しました。これは、ユーザーが提案されたタイトルを「肯定的」「中立」「否定的」のいずれかで評価する仕組みです。また、数十万人規模のユーザーを対象に多変量テストも実施しました。その結果、生成AIによるタイトル提案が強く支持され、「デザイン作成数」や「購入数」といった主要指標も向上しました。数ヶ月のテストを経て、この機能は全ユーザーに展開されました。
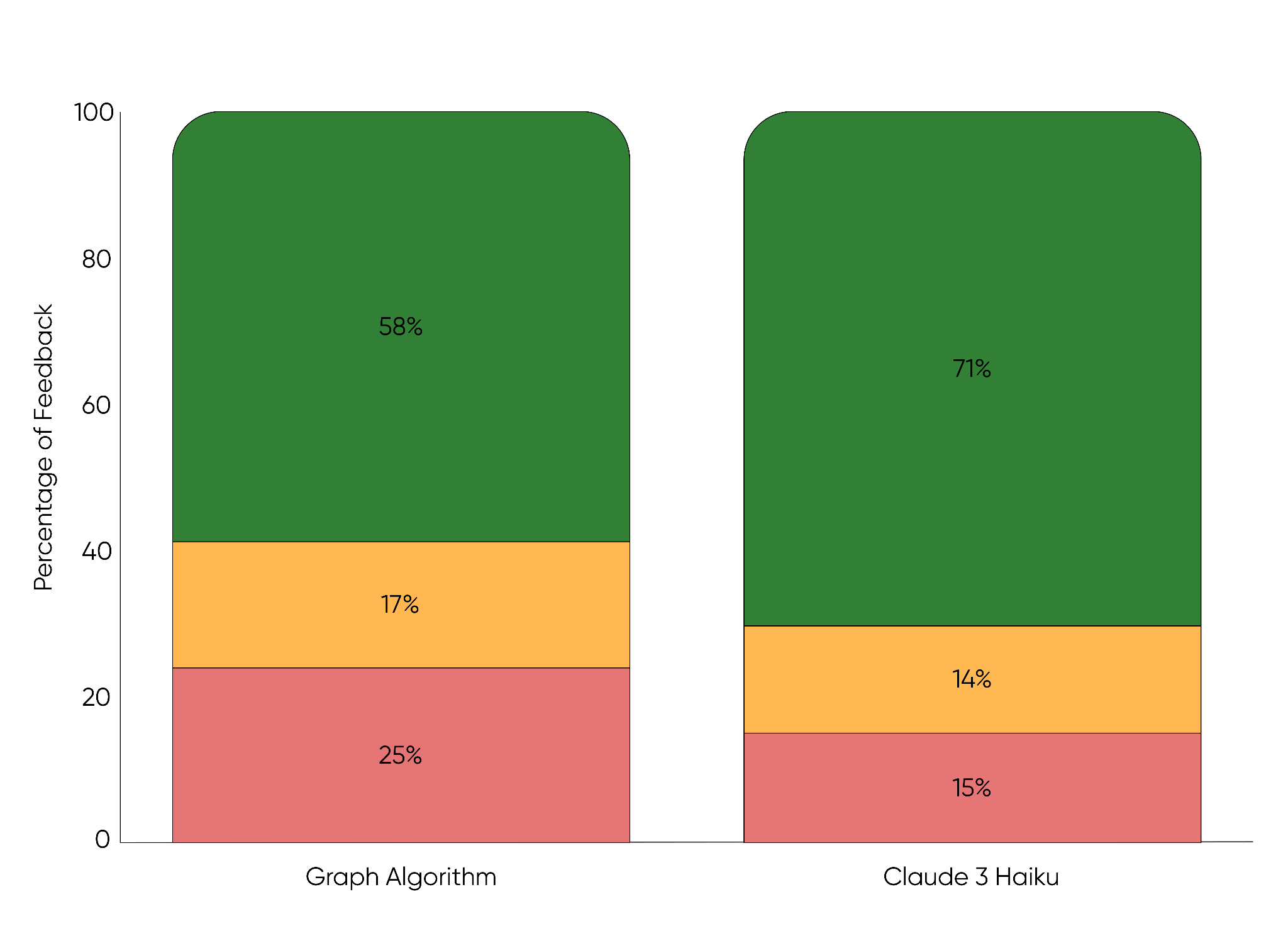
グラフアルゴリズムからタイトル生成にClaude 3 Haikuを使用するよう移行したことで、肯定的なユーザーフィードバックは13ポイント増加しました(58%から71%へ)。
Amazon Novaによる顧客満足度の向上とコスト削減
2024年に生成AIを活用した「タイトル提案」機能が再リリースされて以来、大規模言語モデル(LLM: Large Language Model)の技術はパフォーマンス、コスト、速度の面で大幅に改善しました。Amazon Bedrockの統一APIにより、モデルIDを切り替えるだけで新モデルの比較やテストが可能となり、実験結果の反映が数週間ではなく数時間で完了するようになりました。私たちは最近、低レイテンシで200以上の言語をサポートする「Amazon Nova」ファミリー(Micro、Lite、Pro)をテストしました。
2025年初頭、私たちはClaude 3 HaikuとNovaモデルを比較する多変量A/Bテストを実施し、ガードレール指標を追跡するとともに、アプリ内フィードバック機能を通じてユーザーの直接的な嗜好データを収集しました。
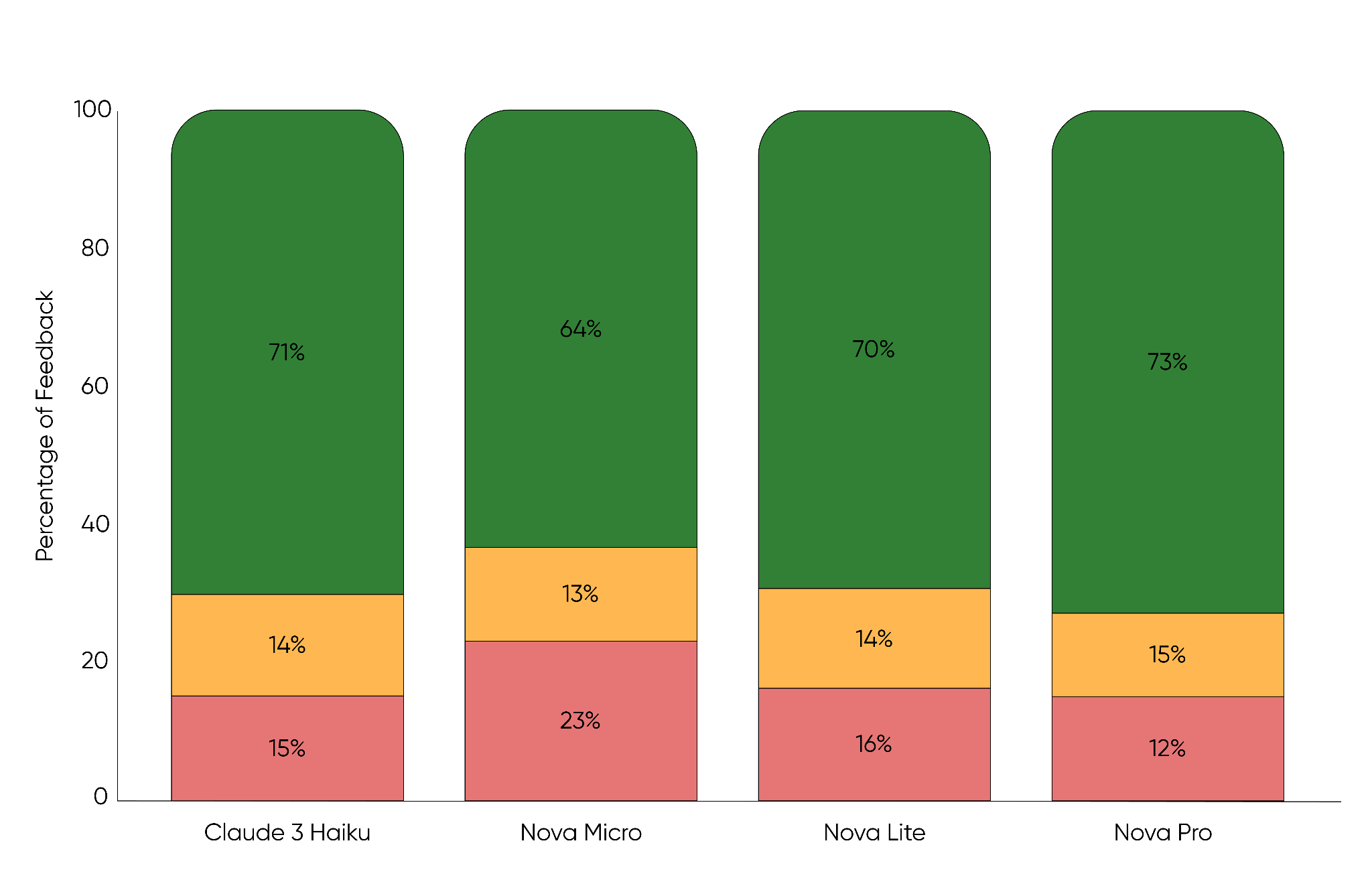
タイトル生成のための各種モデルのテストでは、Claude 3 Haiku(肯定的な評価71%)が良好なパフォーマンスを示したものの、Nova Proは最も低い否定的な評価(12%)で73%の肯定的なユーザー満足度を達成し、最高でした。
Nova Microは従来の*Graph*メソッドを上回りましたが、他の大規模言語モデル(LLM)と比較するとユーザー満足度が劣り、見送られました。残ったモデルのうち、私たちは品質だけでなく、コスト、レイテンシ、スループットにも焦点を当てました。以下の表に示す比較結果から、Nova LiteはClaude Haikuとほぼ同等の品質を、より低コストかつ高速な応答時間で提供していることが明確になりました。
モデル
1,000入力トークンあたりの価格
1,000出力トークンあたりの価格
応答時間(500トークンの出力にかかった秒数)
Claude 3 Haiku
$0.00025
$0.00125
6.8
Amazon Nova Lite
$0.000069
$0.000276
2.4
Amazon Nova Pro
$0.00092
$0.00368
3.4
*価格はAmazon Bedrockの料金ページから取得
*パフォーマンス指標はArtificial Analysisから取得
ConverseStream APIによる最初の提案までの時間短縮
私たちが追跡する重要なレイテンシ指標の一つに、*最初の提案までの時間*(TTFS: Time to First Suggestion)があります。これは、ユーザーのリクエスト後、最初の有効な提案が表示されるまでの速度を測定するものです。バックグラウンドでより多くのオプションが生成されている場合でも、TTFSを短縮することで機能のレスポンス性が向上し、ユーザーが次の操作に移る前に提案が表示されるようになります。
TTFSを改善するため、私たちはAmazon BedrockのInvokeModel APIからConverseStream APIへ移行し、トークンが生成されるたびにストリーミング配信するようにしました。当社のサービスでは有効な「タイトル・サブタイトル・カテゴリ」のトリプレットが必要となるため、FastAPIを拡張してストリームをリアルタイムで解析し、検証が完了次第すぐに最初の提案を返すようにしました。追加の提案はバックグラウンドでストリーミング配信され続けますが、クライアント側ではすでに表示可能な内容が準備されています。
この変更により、最初の洗練された提案までのTTFSは、一連の提案がすべて完了するのを待つ必要がなく、1秒未満に劇的に短縮されました。
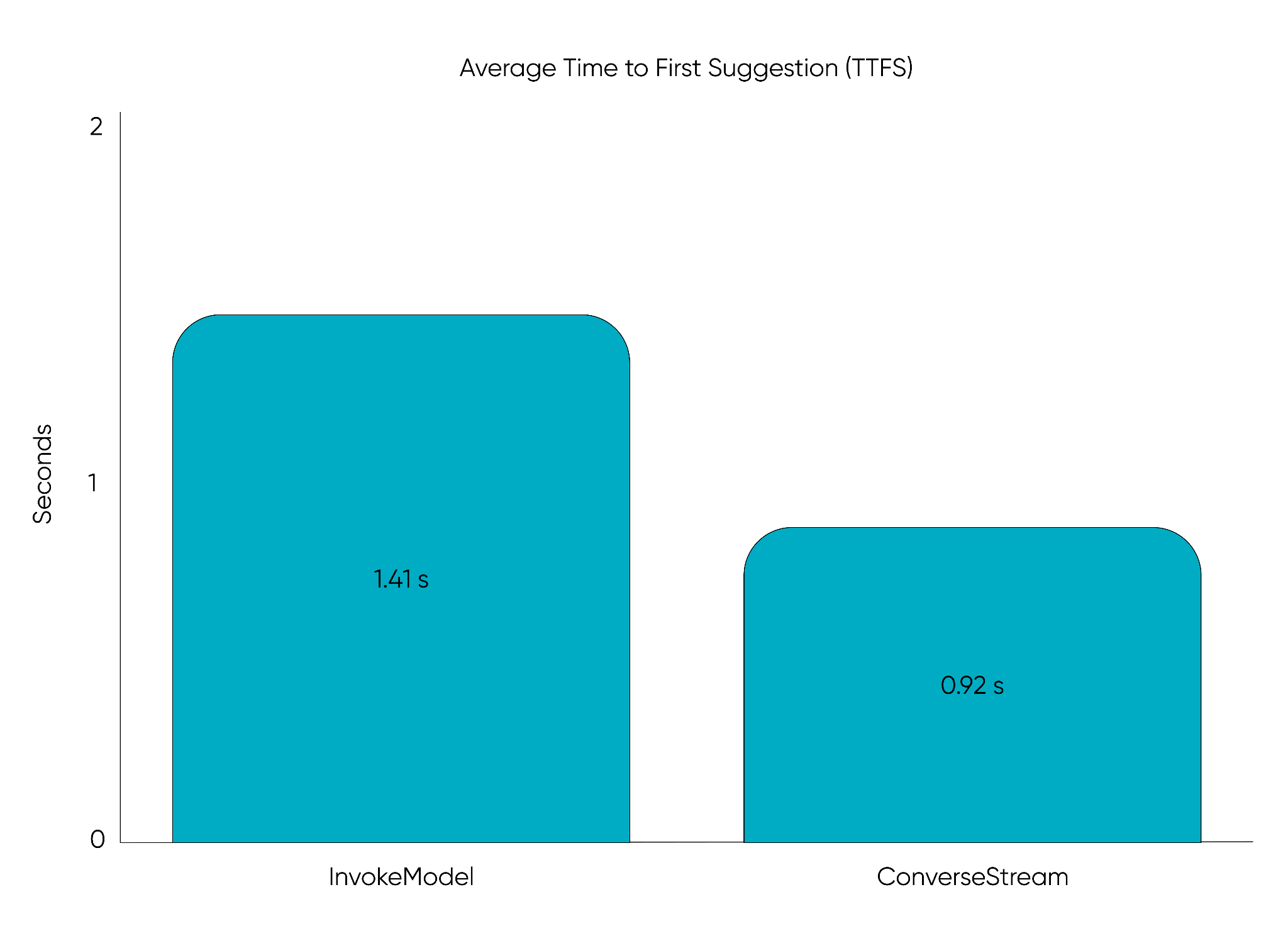
ConverseStream APIへの移行により、最初の提案までの平均時間は1.41秒から0.92秒に短縮され、ユーザーへのタイトル提案の提供速度が35%向上しました。
次のステップ
2025年、当社のタイトル提案機能は550万本以上のタイトルを生成し、どの要素が響き、どの要素が響かないか、そして人々が当社の提案とどのように相互作用しているかについての洞察を提供しました。このフィードバックループは、機能の進化を引き続き推進していきます。
今後、私たちはNova Proのような大規模モデルをユーザーベースの一部に使用することを計画しており、スケーラビリティを保ちながらコスト効率を維持しつつ、創造性とニュアンスを引き出します。これらの実験から収集したデータは、小規模モデルのファインチューニングに役立ち、レイテンシや費用対効果を損なうことなく、大規模モデルの強みを継承することを可能にします。
今後の取り組みには、イベントの詳細から季節のヒントまで、各フォトブックに関するLLM(大規模言語モデル)のコンテキストをより豊かにするツール統合が含まれており、よりパーソナライズされ、テーマ性があり、ブランドに準拠したタイトルを生成することを目指しています。
これらの開発は、当社のミッションを引き続き推進するものです:スキルレベルに関係なく、誰もが自分の写真をすばやく意味深く、創造的で、大切にされる思い出の品に変えられるようにすること。
著者について
 image
image
ブラッドリー・グランサム
ブラッドリーはPopsaのシニアデータサイエンティストであり、そのチームは数百万人の人々が個人のフォトライブラリを振り返り、整理するのを支援するAIシステムを開発しています。彼の業務範囲は、オンデバイスコンピュータビジョン、Amazon Bedrockを活用した生成AI、そして研究からデプロイメントに至るまで生産環境向けのMLシステム構築に及びます。

ヒュー・ダグデール
ヒューは、デジタルメモリを物理的なフォト製品に変えることを支援するテクノロジー企業Popsaのデータサイエンティストです。彼はコンピュータビジョン、地理空間データ、生成AIの分野で活動し、大規模な個人のフォトライブラリをPopsaがどのように理解し整理するかを支えるシステムの構築とデプロイメントを行っています。

アイマン・エルサayed
アイマンはAWSのスタートアップソリューションアーキテクトかつ生成AIスペシャリストであり、英国およびアイルランドのスタートアップ企業と連携し、そのAIによる拡大の野心を支え、ビジネス目標の達成を支援しています。以前はMatchGroupに買収されたHawayaのCTO/プロダクト責任者、そしてEdTech AIスタートアップMavericksの共同創業者兼CTOを務め、英国のスタートアップエコシステム内でグローバルにAI製品のガイダンス、構築、スケーリングを指導する実践的な経験を持っています。

エレン・フランクリン
エレンは、AWSのシニアアカウントマネージャーで、B2C(Business-to-Consumer)、FSI(Financial Services Industry:金融サービス業界)、ISV(Independent Software Vendor:独立系ソフトウェアベンダー)の各セクターにおける英国・アイルランド(UKI)地域の急成長スタートアップ企業に対して7年間のコンサルティング経験を持っています。AWSソリューションアーキテクトアソシエイトおよびAIプラクティショナーの認定資格を保有し、商業戦略と技術革新の接点に位置しています。創業者やリーダーシップチームと連携し、スケールアップの障壁を排除し、エンタープライズ市場への参入(go-to-market)を円滑化し、成長を引き出し、AWSパートナーシップの価値を最大化することに取り組んでいます。
原文を表示
*This post was co-written with Bradley Grantham and Hugo Dugdale from Popsa.*
Popsa is a technology company that helps users rediscover and relive the meaningful memories hidden in their photo libraries. Available across more than 50 countries and 12 languages, we use design automation and AI to transform everyday photos into personal, shareable experiences, including beautifully printed Photo Books.
In 2016, we released *PrintAI*, a pioneering algorithm to take complete control of creating a varied and interesting design from a user’s photos. Our customers could use the algorithm to create Photo Books that appeared professionally designed, in less than 5 minutes.
A core philosophy of our business is that *technology should do the heavy lifting for our users*, so automation has always been an intrinsic part of our product. In the current *Generative AI* age, we can develop even more ways to elevate our customers’ experience, without making our software more complicated to use.
In this post, we share how we applied Amazon Bedrock and the Amazon Nova family of models to reimagine our Title Suggestion feature. By combining metadata, computer vision, and retrieval-augmented generative AI, we now automatically generate creative, brand-aligned titles and subtitles across 12 languages. Using the unified API of Amazon Bedrock, Anthropic’s Claude 3 Haiku, and Amazon Nova Lite and Pro, we improved quality, reduced cost, and cut response times. This resulted in higher customer satisfaction, measurable uplifts in engagement and purchase rates, and over 5.5 million personalised titles generated in 2025.
Generating title suggestions with Amazon Bedrock
When a customer receives their Photo Book, the first thing they see is the front cover, with a prominent title and subtitle. A high-quality title and subtitle elevate a Photo Book’s design, however most customers aren’t professional copywriters and many of them settle for simple titles like “France 2024”, “Photos from Spain” or even, “Photos”.
To help users elevate their photos, we developed and launched a feature called Title Suggestion, which has been available to our users since 2021.
When users select photos for a Photo Book design, our mobile app reads metadata—such as timestamps and geocoordinates—from the images and runs on-device convolutional neural networks to extract relevant features. For example, whether the image contains a beach, a barbecue, or a pet.
To use this data, we created an algorithm called *Title Suggestion Graph*. This algorithm used the metadata and data of the selected photos to build a list of possible titles, following a set of rules and templates to arrive at a set of suitable suggestions. For example:
If all photos in the design were taken on the same day
then suggest “On this Day” as a title with a subtitle of the specific date
In June 2024, we identified an opportunity to improve Title Suggestion by applying generative AI, with the aim of inspiring our users with more creative titles. We began by clearly defining the problem and establishing evaluation metrics.Our solution had to meet strict requirements:
- Character limit
Both the title and subtitle must not exceed 36 characters due to layout restrictions affecting how the text would be displayed on a front cover.
- Title category
Each title–subtitle pair must also have an associated category that determines the icon displayed alongside the pair to users. Imagined or incorrect categories would prevent an icon from being rendered.
- JSON format
Finally, all outputs must be valid JSON with keys title, subtitle and category. This helped with consistent parsing, validation, and rendering in the app.
These rules helped with evaluation because they could be defined in code, so we built a dataset of over 100 example Photo Books and defined our metrics in an evaluation pipeline:
- % of title/subtitle suggestions within the character limit
- % of valid title categories
- % of responses in the correct JSON format
In addition to these strict rules, we needed our solution to satisfy some broader guidelines:
- Theme consistency
Categories should match the content (for example, skiing icons wouldn’t be appropriate if the design subject was a beach holiday)
- Brand style
Suggestions should reflect Popsa’s tone and brand identity
- Title-subtitle cohesion
Pairs should complement each other; they shouldn’t be repetitive or disjointed.
- Multilingual quality
Suggestions needed to be high quality in all 12 languages we support.
We decided to use an *LLM-as-a-judge* to evaluate performance against these guidelines. This helped us to rapidly test different models, prompts, and methods to identify the most reliable approach. After narrowing to two or three options, we conducted extensive internal testing.
Our top results came from *Retrieval-based few-shot prompting*. We created a database of example Photo Books and acceptable title suggestions. For a new Photo Book, we retrieved a few similar Photo Book designs and a random selection of their suggested titles.
Using Amazon Bedrock and Anthropic’s Claude 3 Haiku, we seeded the conversation with these examples as * – * messages before appending the user’s new design document as the final ** message. This allowed the large language model (LLM) to emulate prior responses while naturally following the rules that we defined.
Our full architecture for this solution can be seen in the following diagram:
When our Title Suggestion Service receives a request, it first decrypts and processes the user’s design to extract the timestamps. Then, it performs a reverse geocoding operation on any latitudes and longitudes included in the design, and then classifies the subject of the design based on object landmarks.
This generates a description like “*A skiing photobook with 21 photos taken in the Alps between 21st January 2025 and 23rd January 2025”*. We then pass this description to our *retrieval-based few-shot prompting *component to produce a final set of user-facing suggestions.
Comparisons to our previous graph-based method show better results:
To quantify improvements, we relied on a feedback loop, where customers rated suggestions as positive, neutral, or negative. We also conducted multivariate testing with hundreds of thousands of users. Feedback strongly favored generative AI titles, and key metrics like Design Created and Purchase also improved. After several months, we rolled the feature out to 100% of our users.
By moving from the Graph Algorithm to Claude 3 Haiku for generating title suggestions, we increased positive user feedback by 13% (from 58% to 71%).
Improving customer satisfaction and reducing cost with Amazon Nova
Since the generative AI based re-launch of Title Suggestions in 2024, LLM technology has improved significantly in performance, cost, and speed. The unified API of Amazon Bedrock has helped us to compare and test new models by flipping model IDs and shipping experiments in hours instead of weeks. We recently tested the Amazon Nova family (Micro, Lite, and Pro) which support more than 200 languages at low latency.
In early 2025, we ran a multivariate A/B test comparing Claude 3 Haiku and Nova models, tracking guardrail metrics and gathering direct user preferences through our in-app feedback feature.
Testing various models for title generation showed that while Claude 3 Haiku (71% positive) performed well, Nova Pro achieved the highest user satisfaction at 73% positive feedback with the lowest negative feedback at 12%.
While Nova Micro-outperformed our legacy *Graph* method, it lagged in user satisfaction compared to the other LLMs and were set aside. Among the remaining models, we focused not only on quality, but also on cost, latency and throughput, as shown in the following table. These comparisons made it clear that Nova Lite offered near-identical quality to Claude Haiku at lower cost and faster response times.
Model
Price per 1,000 input tokens
Price per 1,000 output tokens
Response Time (Seconds To Output 500 Tokens)
Claude 3 Haiku
$0.00025
$0.00125
6.8
Amazon Nova Lite
$0.000069
$0.000276
2.4
Amazon Nova Pro
$0.00092
$0.00368
3.4
*pricing taken from the Amazon Bedrock pricing page
*performance metrics taken from Artificial Analysis
Reducing Time to First Suggestion with the ConverseStream API
One of the key latency metrics that we track is *Time to First Suggestion* (TTFS), which measures how quickly the first valid suggestion appears after a user request. Even if more options are being generated in the background, lowering TTFS makes the feature feel more responsive, so suggestions are visible before the user moves on.
To improve our TTFS, we migrated from the InvokeModel API of Amazon Bedrock to the ConverseStream API, to stream tokens as they are generated.Because our services require valid title-subtitle-category triplets, we extended the FastAPI to parse streams in real time, returning the first suggestion immediately upon validation. Additional suggestions continue streaming in the background, but the client already has something ready to display.
This shift dramatically reduced TTFS to under one second for the first polished suggestion, instead of waiting for an entire batch of suggestions to complete.
By migrating to the ConverseStream API, we reduced the average time to first suggestion from 1.41 seconds to 0.92 seconds, delivering title suggestions 35% faster to users.
What’s next
In 2025, our Title Suggestion feature has generated over 5.5 million titles, providing insights into what resonates, what doesn’t, and how people interact with our suggestions. That feedback loop will continue to drive evolution of the feature.
Looking ahead, we plan to use larger models like Nova Pro for a portion of our user base, to capture creativity and nuance while still operating cost-effectively at scale. The data that we gather from these experiments will help us to fine-tune smaller models, helping them inherit the strengths of their larger counterparts without compromising latency or affordability.
Future work includes tool integrations that give the LLM richer context about each Photo Book, from event details to seasonal cues, with the aim of generating more personalised, thematic, and brand-aligned titles.
These developments continue our mission: enabling anyone, no matter their skill level, to quickly turn their photos into meaningful, creative, and treasured keepsakes.
About the authors
Bradley Grantham
Bradley is the Lead Data Scientist at Popsa, where his team builds the AI systems that help millions of people revisit and organise their personal photo libraries. His work spans on-device computer vision, generative AI powered by Amazon Bedrock, and production ML systems built from research through deployment.
Hugo Dugdale
Hugo is a Data Scientist at Popsa, the technology company helping millions of people turn their digital memories into physical photo products. He works across computer vision, geospatial data, and generative AI – building and deploying the systems that power how Popsa understands and organises personal photo libraries at scale.
Ayman ElSayed
Ayman is a Startup Solutions Architect and Gen AI specialist at AWS, partnering with UK & Ireland startups to scale their AI ambitions and achieve their business objectives. Previously CTO/Product at Hawaya (acquired by MatchGroup) and co-founder/ CTO at EdTech AI startup Mavericks, he brings hands-on experience guiding, building and scaling AI products globally within the UK startup ecosystem.
Ellen Franklin
Ellen is a Senior Account Manager at AWS with 7 years’ experience advising high-growth UKI startups across B2C, FSI, and ISV sectors. A certified AWS Solutions Architect Associate and AI Practitioner, she sits at the intersection of commercial strategy and technical innovation, partnering with founders and leadership teams to remove barriers to scale, navigate enterprise go-to-market, unlock growth, and maximise the value of their AWS partnership.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み