Qwen3.6-35B-A3BがClaude Opus 4.7より優れたペリカン画像を生成
Simon Willison氏がローカル環境で動作するQwen3.6-35B-A3BとAnthropicのClaude Opus 4.7を比較し、ローカルモデルの方が空間認識と指示遵守において優れていることを実証した。
キーポイント
ローカル推論環境の実用性向上
MacBook Pro M5上で20.9GBの量子化モデルをLM Studio経由で実行し、API依存なしで高品質な画像生成を実現した。
クラウド大規模モデルの空間認識課題
Claude Opus 4.7は自転車のフレーム形状を誤るなど物理構造の生成に苦戦し、思考レベルを最大にしても改善不明显だった。
コミュニティベンチマークの検証力
作者は過剰学習疑惑を検証するためバックアップテストを実施し、Qwenの汎化能力とベンチマークの実効性を裏付けた。
影響分析・編集コメントを表示
影響分析
本記事は、クラウド大規模言語モデルの優位性が相対的に低下しつつある現状を浮き彫りにし、ローカル推論環境の急速な成熟を示している。開発者やエンドユーザーにとって、APIコストやプライバシーを気にせず高性能なマルチモーダルモデルをローカルで運用できる道が開けたことを意味する。また、コミュニティベンチマークが公式評価指標に匹敵する実証力を得つつある点も、AI評価文化の多様化を示唆している。
編集コメント
ローカル推論環境の成熟により、クラウドAPIに依存しない高品質な画像生成が可能になりつつある。開発者は用途に応じてローカルモデルとクラウドAPIの使い分けを戦略的に検討すべきだ。
もし私のpelican riding a bicycle benchmarkを、モデルをテストする堅牢な手法として真剣に受け止めてくださっている方がいれば、今朝の2つの大規模モデルリリースからのペリカン画像をお届けします。Alibaba製のQwen3.6-35B-A3Bと、Anthropic製のClaude Opus 4.7です。
こちらはQwen 3.6のペリカンです。Unslothによるthis 20.9GB Qwen3.6-35B-A3B-UD-Q4_K_S.gguf量子化モデル (quantized model) を使用し、MacBook Pro M5上でLM Studio(およびllm-lmstudioプラグイン)経由で実行して生成しました。-transcript here:

そしてこちらはAnthropicのbrand new Claude Opus 4.7から得たものです。(transcript):

こちらはQwen 3.6に軍配を上げます。Opusは自転車フレームの描写を台無しにしてしまいました!
thinking_level: max (thinking_level) を渡してOpusを2回目のテストで試しましたが、あまり改善しませんでした(transcript):

Qwenが不正をしているとは思えない
多くの人が、ラボが私のくだらないベンチマークのために学習していると確信しています。私はそうは思いませんが、正直この結果は少し疑念を抱かせるものでした。そこで秘密のバックアップテストの一つを投入します - 「Generate an SVG of a flamingo riding a unicycle」というプロンプトで、Qwen3.6-35B-A3BとOpus 4.7から得た結果がこちらです:
Qwen3.6-35B-A3B
 image
image
Opus 4.7
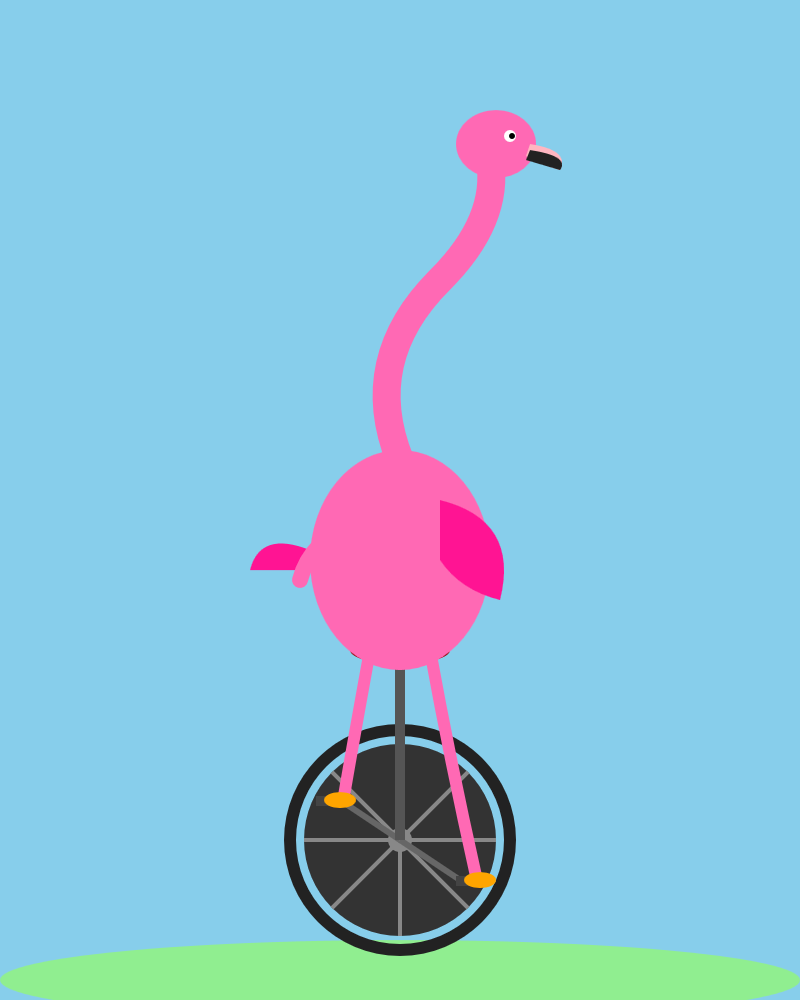 image
image
私はこの結果もQwenに軍配を上げます。優れたSVGコメント (SVG comment) のおかげもあってのことです。
ここから何が学べるのか
このpelican benchmarkは常にジョークとして意図されたものであり、主にこれらのモデルを比較するという作業がいかに難解で不合理であるかを示す声明です。
そのジョークの奇妙な点は、大部分において、生成されたペリカンの品質とモデル (models) の全体的な有用性の間に直接的な相関関係があったことです。それらの2024年10月最初のペリカンはゴミ同然でした。より最近の投稿は全体的にずっとずっと良く、ペリカンが自転車に乗っているイラストを急務で必要とするような場合であれば、Gemini 3.1 Proは実際にどこかで使えるイラストを生み出すに至っています。
今日の時点で、その有用性への緩やかな結びつきでさえ断ち切られています。Qwenに対しては多大な敬意を抱いていますが、彼らの最新モデルの21GB量子化版 (quantized version) がAnthropicの最新の独自リリース (proprietary release) よりも強力であるか、あるいは有用であると確信できるわけではありません。
ただし、あなたが求めているのがペリカンが自転車に乗っているSVGイラスト (SVG illustration) であるならば、現時点ではラップトップ上で動作するQwen3.6-35B-A3Bの方が、Opus 4.7よりも確実な選択肢と言えます!
タグ: ai, generative-ai, local-llms, llms, anthropic, claude, qwen, pelican-riding-a-bicycle, llm-release, lm-studio
原文を表示
For anyone who has been taking my pelican riding a bicycle benchmark seriously as a robust way to test models, here are pelicans from this morning's two big model releases - Qwen3.6-35B-A3B from Alibaba and Claude Opus 4.7 from Anthropic.
Here's the Qwen 3.6 pelican, generated using this 20.9GB Qwen3.6-35B-A3B-UD-Q4_K_S.gguf quantized model by Unsloth, running on my MacBook Pro M5 via LM Studio (and the llm-lmstudio plugin) - transcript here:
And here's one I got from Anthropic's brand new Claude Opus 4.7 (transcript):
I'm giving this one to Qwen 3.6. Opus managed to mess up the bicycle frame!
I tried Opus a second time passing thinking_level: max. It didn't do much better (transcript):
I don't think Qwen are cheating
A lot of people are convinced that the labs train for my stupid benchmark. I don't think they do, but honestly this result did give me a little glint of suspicion. So I'm burning one of my secret backup tests - here's what I got from Qwen3.6-35B-A3B and Opus 4.7 for "Generate an SVG of a flamingo riding a unicycle":
Qwen3.6-35B-A3B([transcript)](https://static.simonwillison.net/static/2026/qwen-flamingo.png)
Opus 4.7([transcript)](https://static.simonwillison.net/static/2026/opus-flamingo.png)
I'm giving this one to Qwen too, partly for the excellent `` SVG comment.
What can we learn from this?
The pelican benchmark has always been meant as a joke - it's mainly a statement on how obtuse and absurd the task of comparing these models is.
The weird thing about that joke is that, for the most part, there has been a direct correlation between the quality of the pelicans produced and the general usefulness of the models. Those first pelicans from October 2024 were junk. The more recent entries have generally been much, much better - to the point that Gemini 3.1 Pro produces illustrations you could actually use somewhere, provided you had a pressing need to illustrate a pelican riding a bicycle.
Today, even that loose connection to utility has been broken. I have enormous respect for Qwen, but I very much doubt that a 21GB quantized version of their latest model is more powerful or useful than Anthropic's latest proprietary release.
If the thing you need is an SVG illustration of a pelican riding a bicycle though, right now Qwen3.6-35B-A3B running on a laptop is a better bet than Opus 4.7!
Tags: ai, generative-ai, local-llms, llms, anthropic, claude, qwen, pelican-riding-a-bicycle, llm-release, lm-studio
関連記事
2026年3月6日 Frontier Red TeamによるClaudeのCVE-2026-2796エクスプロイトのリバースエンジニアリング
Frontier Red Teamが、Claudeの脆弱性CVE-2026-2796を悪用するエクスプロイトをリバースエンジニアリングした。
フロンティア・レッドチーム、Firefoxのセキュリティ向上のためにMozillaと提携
フロンティア・レッドチームは、Firefoxのセキュリティを向上させるため、Mozillaと提携した。
59%のユーザーがより安価なモデルを選択:Sonnet 4.6の詳細解説
Anthropic社がClaude Sonnet 4.6をリリースし、Claude Codeテストで70%のユーザーが前世代モデルより好み、59%がフラッグシップモデルOpus 4.5よりも選択した。コーディング、コンピュータ利用、100万トークンコンテキストなど6次元で全面アップグレードされ、価格は据え置き。