Amazon Nova Sonic と WebRTC を用いたリアルタイム音声ストリーミングアプリケーションの構築
AWS は、ネットワーク制約や言語の壁を克服するリアルタイム音声ストリーミングアプリケーション向けに、Amazon Nova Sonic と WebRTC を統合した新ソリューションを発表し、低遅延かつ多言語対応可能な自然な対話型 AI エージェントの実装を可能にした。
キーポイント
統合アーキテクチャによる低遅延実現
従来の別個のモジュール(音声認識、処理、合成)ではなく、Nova Sonic が音声から直接音声への統一型アーキテクチャを採用し、リアルタイムな対話と自然な人間のような会話を可能にしている。
不安定なネットワーク環境での品質維持
Amazon Kinesis Video Streams WebRTC がビットレートを動的に調整することで、帯域幅の制約下でも音声品質を維持し、接続断を防ぐ仕組みを提供する。
フルマネージド型スケーラビリティ
両サービスとも AWS によって完全にマネージされており、インフラコストとパフォーマンスのバランスを保ちながら、自動的にスケールして高い耐障害性を確保する。
影響分析・編集コメントを表示
影響分析
この発表は、リアルタイム音声 AI アプリケーション開発における最大の障壁であった「遅延」と「ネットワーク不安定性」を同時に解決する画期的なアプローチを示しています。特にスタートアップや大規模システムにおいて、複雑なインフラ構築コストを抑えつつ、高品質で多言語対応の対話型インターフェースを迅速に実装できるため、業界全体の音声 AI 応用の普及スピードを加速させる可能性があります。
編集コメント
音声 AI の実用化において長年の課題であった「遅延」と「ネットワーク耐性」を、単一のマネージドサービスで解決した点は非常に注目すべき進展です。開発負荷の軽減とパフォーマンス向上の両立により、より多くの企業が高度な音声対話型アプリケーションへの参入を容易にします。
リアルタイム音声対話機能を備えたエンドツーエンドのライブストリーミングアプリケーションを構築するには、いくつかの課題があります。ネットワーク帯域幅の制約により、時間的制約のあるアプリケーションで遅延や品質劣化が発生する可能性があります。言語の壁は、多言語音声通信における効果的な人間と機械との対話を制限します。スケーラビリティと耐障害性は、パフォーマンスとインフラコストの間で難しいバランスを取ることを要求します。また、クロスブラウザおよびモバイル環境での互換性を確保するには、特にスタートアップ企業にとって多大な開発努力が必要です。
本稿では、これらの課題に対処する Amazon Nova 2 Sonic(Nova Sonic)および Amazon Kinesis Video Streams WebRTC(WebRTC)に基づくソリューションを紹介します。WebRTC は、不安定なネットワーク環境においてビットレートを動的に調整する役割を担い、接続の切断を減らしながら音声品質を維持するのに役立ちます。Nova Sonic は効果的な人間同士の対話を実現するため、ユーザーは選択した言語でより自然に対話を行うことができます。両サービスとも AWS によって完全にマネージドされており、高い耐障害性を備えて自動的にスケールします。また、AWS ではオープンソースのサンプルも提供しており、これを自社のアプリケーション開発の出発点として利用できます。
本稿では、ソリューションアーキテクチャ、実装パターン、および 2 つの実世界におけるシナリオ例について順を追って解説します。
Nova Sonic と WebRTC
従来の音声エージェントパイプラインでは、通常、音声認識、言語処理、音声合成のために別々のモジュールが用いられていました。Nova Sonic は、低遅延でユーザーと AI エージェント間のリアルタイムな音声会話を可能にする、統合された音声対音声アーキテクチャを提供します。

統合された音声理解と生成により、Nova Sonic は自然で人間のような対話型 AI を実現します。Nova Sonic モデルは、外部エージェント向けの異なる話し方やツールインターフェースを提供しています。これを用いることで、文脈認識能力が高く、より反応が良く直感的な音声インターフェースを構築できます。
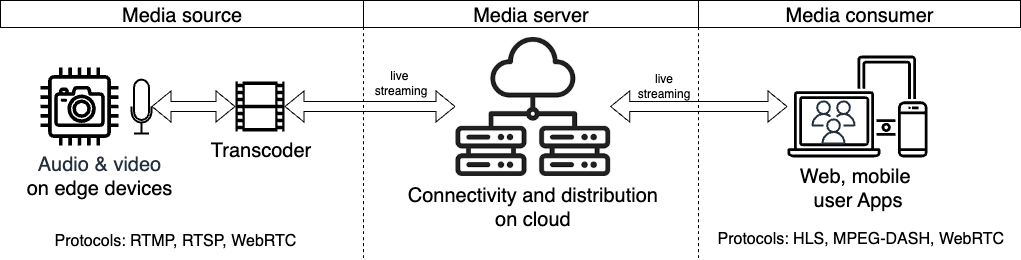
典型的なストリーミングパイプラインは、メディアソース、メディアサーバー、メディアコンシューマーの 3 つの主要コンポーネントで構成されます。前述の図では、これらのコンポーネントと、それぞれに対応する RTMP、RTSP、HLS、MPEG-DASH、WebRTC などのプロトコルが示されています。
Web Real-Time Communication (WebRTC) は、追加のプラグインやソフトウェアのインストールを必要とせず、リアルタイムのピアツーピア直接接続を提供することでライブストリーミングを近代化する公開プロトコルです。このアプローチは中間サーバーの必要性を排除し、レイテンシを大幅に削減します。すべてのメディアストリーミングプロトコルの中で、WebRTC は以下の画像に示されるように、最も低いレイテンシを実現します。

WebRTC には、適応型ビットレート (ABR) ストリーミング、フォワードエラー訂正 (FEC)、およびjitter buffer 管理といった組み込み機能も含まれています。これらの機能により、帯域幅の使用量を自動的に調整し、接続が不安定な環境におけるパケットロスやジッターの問題を解決できます。ネットワーク状態が悪い場合でも、滑らかな会話の維持が可能です。
WebRTC のオープンソースであることと、Chrome、Firefox、Safari、Edge、Android、iOS などの幅広いブラウザとの互換性は、ソリューションの採用を加速し、継続的な改善を促します。また、AI 機能を持つメディアストリームのリアルタイム処理にも非常に適しています。
ソリューションアーキテクチャ
以下のシナリオにおいて、多言語音声対話機能を備えたライブストリーミングソリューションの導入を検討する場合があります:コネクテッドビークルでは、リアルタイム翻訳機能でドライバーを支援します。スマートファクトリーでは、音声起動型品質管理システムを通じて異文化間のオペレーター間コミュニケーションをサポートします。ロボティクスアプリケーションでは、多言語でのカスタマーサービス対話を提供します。スマートホームデバイスでは、異なる言語での即時音声制御を実現し、リアルタイムのオーディオ翻訳と視覚的ガイダンスを通じてグローバルな技術サポートを取得できるようにします。
以下の図は、Nova Sonic ソリューションを管理された WebRTC サービスとして Kinesis Video Streams と共にデプロイする方法を示しています。また、検索拡張生成 (RAG)、モデルコンテキストプロトコル (MCP)、Strands エージェントなどの一般的なソースとのツール統合も示されています。
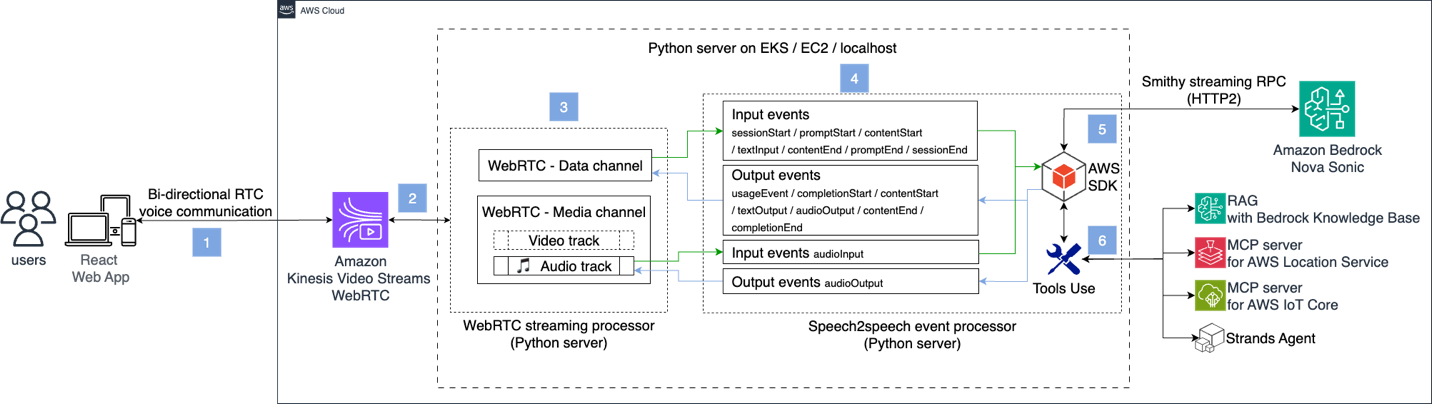
[1] クライアントアプリ上では、ユーザーが Kinesis Video Streams の WebRTC シグナリングチャネルに接続することで WebRTC 交渉プロセス を確立します。音声およびビデオデータは、双方向の WebRTC 接続を介して送信されます。
[2] セッション記述プロトコル (SDP) のオファー/アンスワー およびインタラクティブ接続確立 (ICE) キャンディデート の交換のためのシグナリングメッセージの後、クライアントとサーバーは双方向のピア接続試行を開始します。その後、成功した RTC 接続を通じて、低遅延でビデオおよびオーディオデータを転送することができます。
[3] メディアチャネルは、適応型ビットレート制御とコーデックネゴシエーションを備えたリアルタイムオーディオおよびビデオストリーミングを処理します。データチャネルは、テキスト、ファイル、制御メッセージなどの任意のアプリケーションデータの信頼性が高く順序通りの転送を提供します。両方とも Datagram 輸送層セキュリティ (DTLS) の暗号化と、ネットワークアドレス変換 (NAT) 透過のための Session Traversal Utilities for NAT (STUN)/Traversal Using Relays around NAT (TURN) プロトコルを使用しています。
[4] 音声対音声イベントプロセッサは、Nova Sonic との 入力イベント および 出力イベント の相互作用を調整します。当社のソリューションでは、これらは WebRTC メディアチャネル経由で転送されるメディアイベントと、WebRTC データチャネル経由のテキストデータに分類されます。
[5] Python SDK を使用して、Nova Sonic と双方向ストリーミングを行うための HTTP/2 接続を確立します。この接続はリアルタイムのメディアデータ通信をサポートし、ユーザーにとっての遅延を最小限に抑えます。
[6] また、事前学習済み知識による音声対話に加え、Nova Sonic は MCP サーバーや Strands エージェント、RAG(Retrieval-Augmented Generation)へのアクセスを可能にする非同期ツール呼び出し asynchronous tool calling もサポートしています。本記事では、これらのツールの使用例を通じてその機能を紹介いたします。
すでに Nova Sonic をご使用中の方には、このアーキテクチャが WebSocket 解決策と類似していることに気づかれるでしょう。ここでは主要な違いについて解説します。
ソリューション比較
WebSocket デプロイ オプションと比較して、この WebRTC ベースの音声対話ソリューション は、モバイル機器や IoT デバイスに適した異なるネットワーク層を提供します。これらのデバイスは、高いネットワーク帯域幅を必要とせずとも低遅延接続を要することが多くあります。また、本ソリューションにはユーザーエクスペリエンスを向上させるためにカスタマイズされた音声活動検出(VAD: Voice Activity Detection)レイヤーも組み込まれています。
WebSocket から WebRTC への変更されたオーディオストリーミングプロトコル
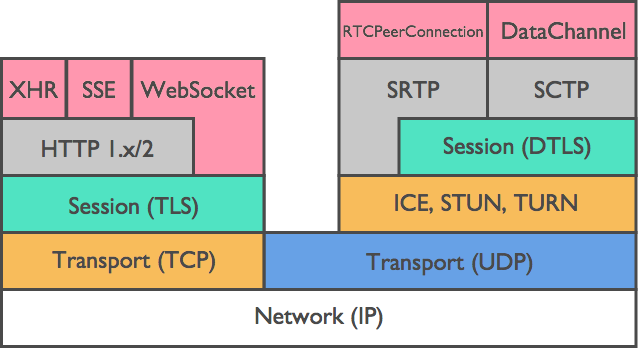
音声データは、WebSocket メッセージではなく、Secure Real-time Transport Protocol (SRTP) フォーマットによるピア接続のオーディオトラックを介したストリーミング方式で WebRTC メディアチャネルを通じて送信されます。WebRTC の機能(SDP offer/answer、DTLS、Stream Control Transmission Protocol (SCTP)、SRTP、およびピア接続など)は、aiortc Python ライブラリを使用して実装しました。
人間の声検出メカニズム
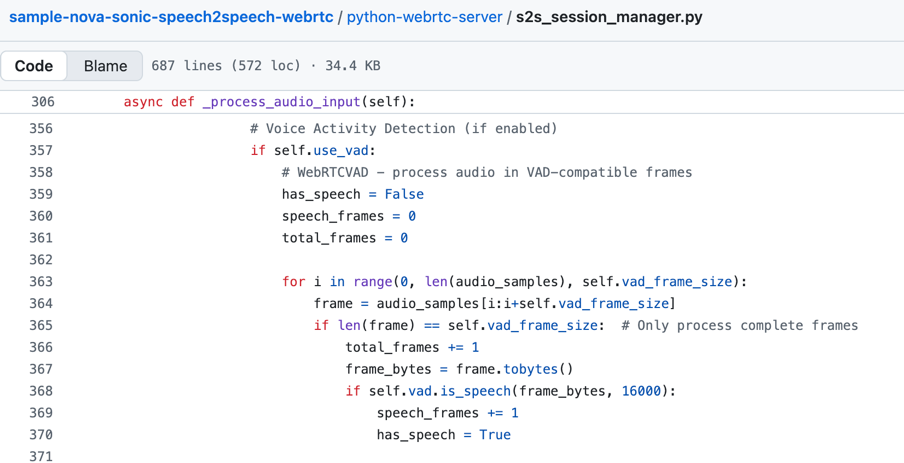
React WebRTC クライアントはオーディオを継続的にキャプチャし、Python WebRTC サーバーへ送信します。ノイズの抑制、発話精度の向上、および Nova Sonic に対するオーディオトークンの削減を実現するため、本ソリューションではサーバー側のパイプラインに Voice Activity Detection (VAD) を適用しています。Python WebRTCVAD library に基づくコードの実装は以下の画像に示されています。Gaussian Mixture Model (GMM) を基盤とするこのライブラリは軽量で安定しており、WebRTC フレームレベルのオーディオ処理において高速です。また、Silero VAD や Pyannote VAD などの他のライブラリも利用可能です。
オーディオデータ形式の適応
WebRTC は特定のオーディオおよびビデオフォーマット標準を定義しています。WebRTC 接続を通じてオーディオデータを送受信する際には、何らかの形式変換(Audio Data Adaptation)を行う必要があります:[[1]](https://github.com/aws-samples/sample-nova-sonic-speech2speech-webrtc/blob/main/docs/AudioDataAdaption.md#interleaved-layout-unpacking) インターリーブされたステレオフレームでは、左または右のオーディオチャンネルを抽出する必要があります。[[2]](https://github.com/aws-samples/sample-nova-sonic-speech2speech-webrtc/blob/main/docs/AudioDataAdaption.md#sampling-rate-48khz-to-16khz) 48kHz またはその他のサンプリングレートは、Nova Sonic API の要件に従って 16kHz にリサンプリングされます。[[3]](https://github.com/aws-samples/sample-nova-sonic-speech2speech-webrtc/blob/main/docs/AudioDataAdaption.md#type-conversion-from-int16-to-float32) Int16 データ値は、計算精度を向上させるために Float32 に変換されます。詳細については、GitHub ドキュメント を参照してください。
ソリューションのウォークスルー
この GitHub リポジトリ のソリューションでは、汎用的なサンプルと 2 つの具体的なシナリオ例(スマートホーム例およびコネクテッドビークル例)が提供されています。これらのパターンは、ご自身のアプリケーションに適応させることができます。
スマートホームの例
スマートホームのシナリオでは、Nova Sonic と対話して IoT デバイスを制御します。完全なコマンドパイプラインを示すために、本ソリューションは Amazon Bedrock の Knowledge Base を使用して MQTT トピックを取得し、AI 応答を生成します。その後、MCP server for AWS IoT Core に接続してコマンドメッセージを送信します。完全なアーキテクチャは以下の画像に示されています。
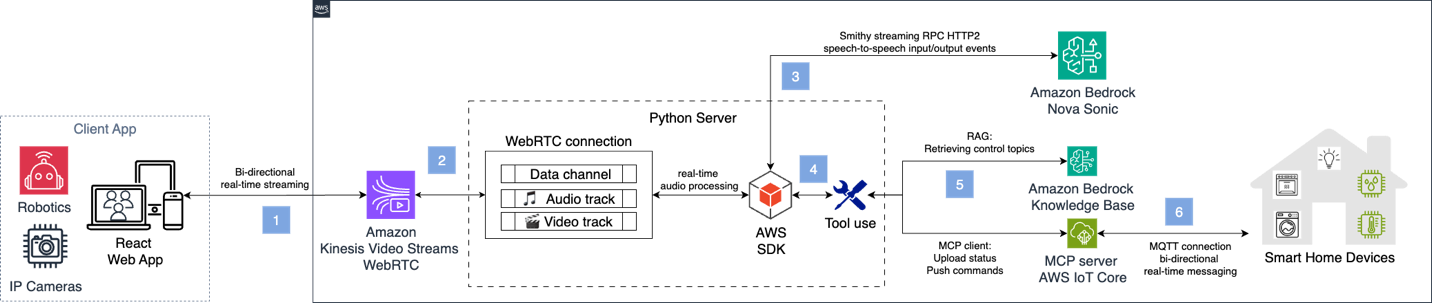
セットアップ手順については、GitHub の smart-home readme を参照してください。
接続車両の例
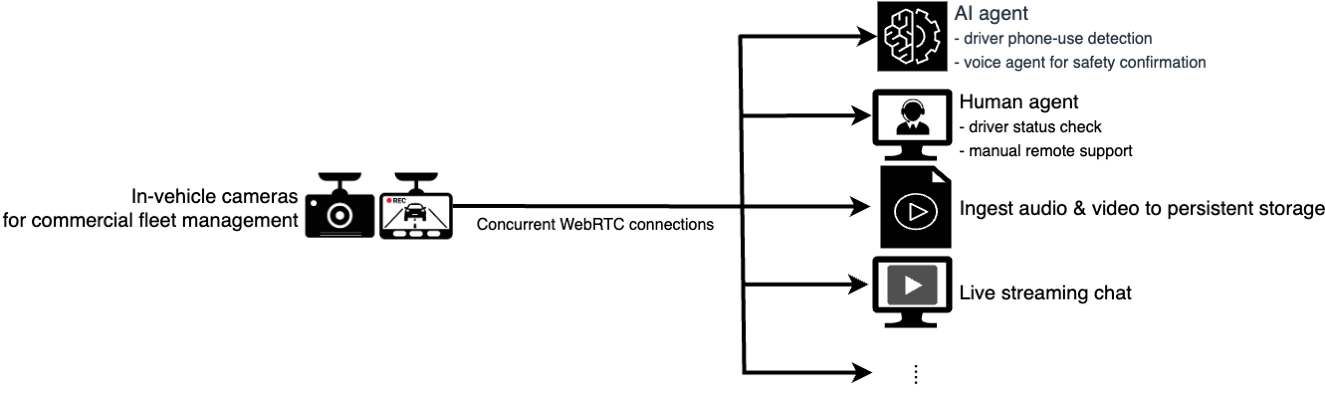
接続車両のシナリオでは、システムがリアルタイム監視を確立して、運転者の危険な携帯電話使用行動を検出します。システムは音声アシスタントを使用して、支援が必要かどうかを問い合わせ、運転者の注意力を確認します。監督担当者は、独立したビデオチャネルでリアルタイム監視フィードにアクセスし、車両と運転者の安全状態を確認できます。以下のアーキテクチャがこのシナリオに対応しています。
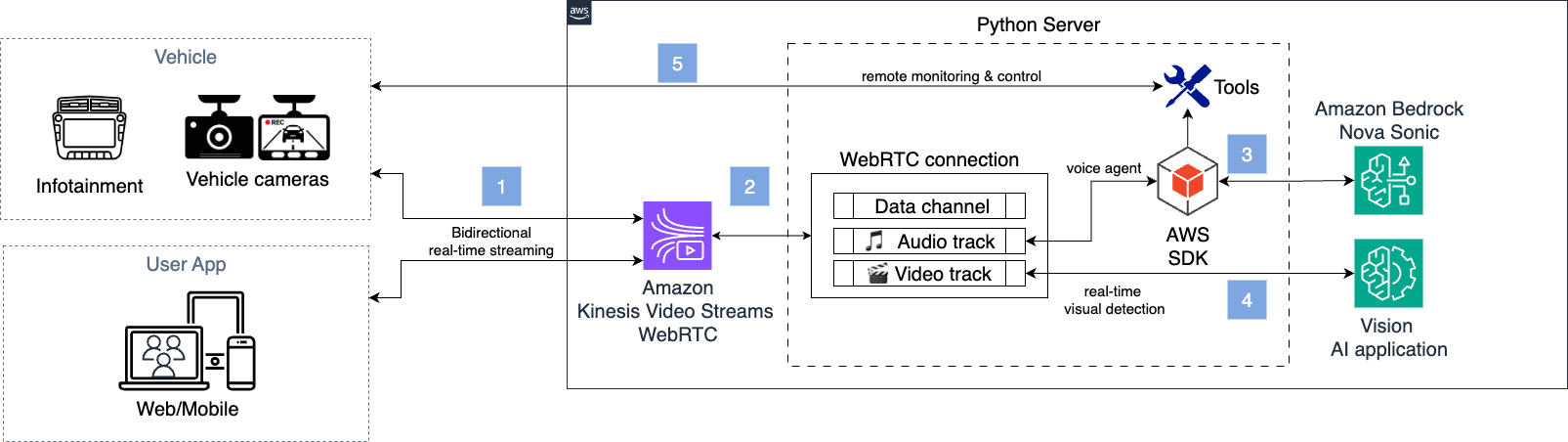
接続車両シナリオにおける完全なメディアパイプラインは、以下の図に示されています。並行して確立される WebRTC 接続はそれぞれ独立しており、専用の TLS 暗号化が適用されます。
セットアップ手順については、GitHub 上の connected-vehicle readme をご覧ください。
結論
本記事では、Amazon Nova 2 Sonic と Amazon Kinesis Video Streams WebRTC を組み合わせた、WebRTC ベースのソリューション構築方法をご紹介しました。このソリューションは、不安定なネットワーク環境におけるパフォーマンス低下や、会話型インテリジェンスの欠如といった、ライブストリーミングにおける一般的な課題を解決するものです。本ソリューションは、スマートデバイスや接続車両の利用者向けに、低遅延で知的かつ堅牢性が高く柔軟な音声アシスタントアプリケーションを構築するための基盤として活用できます。
始め方と詳細については以下をご覧ください:
- 最新の Amazon Nova 2 Sonic の機能については、Speech-to-Speech ブログ記事をお読みください。
- より多くのシナリオについては、GitHub 上の Speech-to-Speech リポジトリをご探索ください。
- その他のライブストリーミングユースケースについては、Amazon Kinesis Video Streams 開発者ガイドをご覧ください。
執筆者について
 image
image
Zihang Huang
Zihang Huang は、AWS のアジェンティック AI 専門ソリューションアーキテクトです。彼はコネクテッドカー、スマートホーム、再生可能エネルギー、産業用 IoT におけるアジェンティック AI の専門家として活動しています。現在、AgentCore、物理的 AI(Physical AI)、IoT、エッジコンピューティング、ビッグデータを活用した AI ソリューションに注力しています。

Lana Zhang
Lana Zhang は、AWS のワールドワイド・スペシャリスト組織に所属するジェネレーティブ AI 専門のシニアソリューションアーキテクトです。AI/ML を専門とし、特に AI ボイスアシスタントやマルチモーダル理解(Multimodal Understanding)などのユースケースに焦点を当てています。メディア・エンターテインメント、ゲーム、スポーツ、広告、金融サービス、ヘルスケアなど多様な業界の顧客と緊密に連携し、AI を活用したビジネスソリューションの変革を支援しています。

Bin Chen
Bin Chen は、2019 年に AWS に加入したジェネレーティブ AI 専門ソリューションアーキテクトです。Amazon Bedrock や Amazon SageMaker などのサービスを活用し、顧客が生成 AI の最前線を探求し、概念実証(Proof of Concept)から本番環境へのプロジェクト移行を支援することに尽力しています。現在特に注力しているのは、アジェンティック AI とエンドツーエンドの音声モデルです。

Siva Somasundaram
Siva Somasundaram 氏は AWS のシニアエンジニアであり、Kinesis Video Streams(動画ストリーミングサービス)の組み込み SDK およびサーバーサイドコンポーネントの開発を担当しています。15 年以上にわたる動画ストリーミングサービスの経験を持ち、大規模な動画取り込みのためのメディア処理パイプライン、トランスコーディング機能、セキュリティ機能を開発してきました。彼の専門知識は、動画圧縮、WebRTC(リアルタイム通信プロトコル)、RTSP(リアルタイムストリーミングプロトコル)、および動画 AI に及びます。彼は意味検索や RAG(Retrieval-Augmented Generation: 検索拡張生成)を駆動するメタデータハブの構築に情熱を注いでいます。
原文を表示
Building end-to-end live streaming applications with real-time voice interaction presents several challenges: network bandwidth constraints can cause high latency and quality degradation in time-critical applications. Language barriers limit effective human-machine interaction in multilingual voice communication. Scalability and resilience require a difficult balance between performance and infrastructure costs. Cross-browser and mobile compatibility demands significant development effort, especially for startups.
This post introduces a solution based on Amazon Nova 2 Sonic (Nova Sonic) and Amazon Kinesis Video Streams WebRTC (WebRTC) that addresses these challenges. WebRTC is responsible for dynamically adjusting the bitrate in unstable networks, which helps to maintain audio quality while reducing dropped connections. Nova Sonic provides effective human language dialogues, so users can interact more naturally in their chosen language. Both services are fully managed by AWS, so they scale automatically with high resilience. AWS also provides open-source samples that you can use as a starting point for your own application.
In this post, we’ll walk through the solution architecture, implementation patterns, and two real-world scenario examples.
Nova Sonic and WebRTC
Traditional voice agent pipelines typically involve separate modules for speech recognition, language processing, and speech synthesis. Nova Sonic offers a unified speech-to-speech architecture that enables real-time voice conversations between users and AI agents with low latency.
With unified speech understanding and generation, Nova Sonic delivers natural, human-like conversational AI. The Nova Sonic model provides different speaking styles and tool interfaces for external agents. You can use it to build a more responsive and intuitive voice interface with higher contextual awareness.
A typical streaming pipeline comprises three main components: media source, media server, and media consumer. The previous diagram shows these components and their respective protocols, such as RTMP, RTSP, HLS, MPEG-DASH, and WebRTC.
Web Real-Time Communication (WebRTC) is a public protocol that modernizes live streaming by providing real-time peer-to-peer direct connections without additional plugins or software installations. This approach eliminates the need for intermediate servers and significantly reduces latency. Among all media streaming protocols, WebRTC delivers the lowest latency, as shown in the following image.
WebRTC also includes built-in features like adaptive bitrate (ABR) streaming, forward error correction (FEC), and jitter buffer management. These features can automatically adjust the bandwidth consumption, and resolve packet loss or jitter issues in weak connectivity. You can maintain fluent conversations even in poor network conditions.
WebRTC’s open-source nature and broad browser compatibility (Chrome, Firefox, Safari, Edge, Android, iOS, etc.) will accelerate solution adoption and encourage continuous improvement. It is also well suited for real-time processing of media streams with AI functions.
Solution architecture
You might want to deploy live streaming solutions with multilingual voice interaction for the following scenarios: Connected vehicles that assist drivers with real-time translation capabilities. Smart factories that support cross-cultural operator communication through voice-activated quality control systems. Robotics applications that provide multilingual customer service interactions. Smart home devices that offer instant voice control in different languages, so that you can obtain global technical support through real-time audio translation and visual guidance.
The following diagram illustrates how to deploy Nova Sonic solution together with Kinesis Video Streams as a managed WebRTC service. It shows tool integration with popular sources such as Retrieval Augmented Generation (RAG), Model Context Protocol (MCP), and Strands Agents.
[1] On the client App, users establish the WebRTC negotiation process by connecting to the Kinesis Video Streams WebRTC signaling channel. Audio and video data are transmitted through the bidirectional WebRTC connection.
[2] After signaling messages for Session Description Protocol (SDP) offer/answer and Interactive Connectivity Establishment (ICE) candidates exchange, the client and server initiate the bi-directional peer connection attempts. Then video and audio data can be transmitted with low latency through the successful RTC connection.
[3] The media channel handles real-time audio and video streaming with adaptive bitrate control and codec negotiation. The data channel provides reliable and ordered transmission of arbitrary application data, e.g. text, files, and control messages. Both use Datagram Transport Layer Security (DTLS) encryption and Session Traversal Utilities for NAT (STUN)/Traversal Using Relays around NAT (TURN) protocols for Network Address Translation (NAT) traversal.
[4] Speech-to-speech event processor orchestrates the input events and output events interaction with Nova Sonic. In our solution, they are categorized into media events which are transmitted via WebRTC media channel, and text data via WebRTC data channel.
[5] You use the Python SDK to establish an HTTP/2 connection for bidirectional streaming with Nova Sonic. This connection supports real-time media data communication and minimizes latency for users.
[6] In addition to speech-to-speech audio conversation with pre-trained knowledge, Nova Sonic supports asynchronous tool calling to access MCP servers, Strands agents, or RAG. This post demonstrates the tool use feature with examples.
If you’re already using Nova Sonic, you will notice this architecture is similar to the WebSocket solution. I’ll show you the key differences.
Solution comparison
Compared to the WebSocket deployment option, this WebRTC-based speech-to-speech solution provides a different network layer suited for mobile and IoT devices. These devices often require low-latency connections without high network bandwidth. The solution also incorporates a customized Voice Activity Detection (VAD) layer for an enhanced user experience.
Audio streaming protocol changed from WebSocket to WebRTC
The voice data are transmitted through WebRTC media channel in a streaming way, namely through the audio track of the peer connection in Secure Real-time Transport Protocol (SRTP) format, instead of WebSocket messages. We implemented WebRTC features (such as SDP offer/answer, DTLS, Stream Control Transmission Protocol (SCTP), SRTP, and peer connection) using the aiortc Python library.
Human voice detection mechanism
The React WebRTC client continuously captures audio and sends it to the Python WebRTC server. To suppress noise, increase speech accuracy, and reduce audio tokens for Nova Sonic, the solution appliesVoice Activity Detection (VAD) to the pipeline on server side. The code implementation based on the Python WebRTCVAD library is shown in the following image. Built on a Gaussian Mixture Model (GMM), this library is lightweight, stable, and fast for WebRTC frame-level audio processing. You can also use other libraries such as Silero VAD, Pyannote VAD.
Audio data format adaptation
WebRTC defines specific audio and video format standards. When sending and receiving audio data through a WebRTC connection, you must perform some format adaptation: [[1]](https://github.com/aws-samples/sample-nova-sonic-speech2speech-webrtc/blob/main/docs/AudioDataAdaption.md#interleaved-layout-unpacking) Interleaved stereo frames require extracting the left or right audio channel; [[2]](https://github.com/aws-samples/sample-nova-sonic-speech2speech-webrtc/blob/main/docs/AudioDataAdaption.md#sampling-rate-48khz-to-16khz) 48kHz or other sampling rates will be resampled to 16kHz, as required by Nova Sonic API; [[3]](https://github.com/aws-samples/sample-nova-sonic-speech2speech-webrtc/blob/main/docs/AudioDataAdaption.md#type-conversion-from-int16-to-float32) Int16 data values will be converted to Float32 for enhanced calculation precision. For more information, see the GitHub documentation.
Solution walkthrough
The solution in this GitHub repository provides a generic sample and two specific scenario examples: a smart home example and a connected vehicle example. You can adapt these patterns for your own applications.
Smart home example
In the smart home scenario, you open a dialog with Nova Sonic to control IoT devices. To illustrate a full command pipeline, the solution uses an Amazon Bedrock Knowledge Base to retrieve MQTT topics and generate AI responses. It then connects to the MCP server for AWS IoT Core to deliver command messages. The full architecture is shown in the following image.
For setup steps, see the smart-home readme on GitHub.
Connected vehicle example
In the connected vehicle scenario, the system establishes real-time monitoring to detect dangerous phone-use behaviors of drivers. The system uses voice assistants to ask if assistance is needed and verify driver attentiveness. Supervisory personnel can access real-time monitoring feeds in an independent video channel to confirm the safety status of both vehicles and drivers. The following architecture addresses this scenario:
The full media pipeline in the connected vehicle scenario is shown in the following diagram. The concurrent WebRTC connections are independent from each other with dedicated TLS encryption.
For setup steps, see the connected-vehicle readme on GitHub.
Conclusion
In this post, we showed you how to build a WebRTC-based solution that combines Amazon Nova 2 Sonic and Amazon Kinesis Video Streams WebRTC. This solution addresses common barriers in live streaming, such as degraded performance in unstable networks and the lack of conversational intelligence. You can use this solution as the basis for building your own low-latency, smart, robust, flexible voice assistant applications for users of smart devices and connected vehicles.
To get started and learn more:
- Read the speech-to-speech blog to learn about the latest Amazon Nova 2 Sonic features.
- Explore the speech-to-speech repository on GitHub for more scenarios.
- See the Amazon Kinesis Video Streams Developer Guide for more live streaming use cases.
About the authors
Zihang Huang
Zihang Huang is a specialist solution architect for Agentic AI at AWS. He is an agentic AI expert for connected vehicles, smart home, renewable energy, and industrial IoT. Currently, he focuses on AI solutions with AgentCore, physical AI, IoT, edge computing, and big data.
Lana Zhang
Lana Zhang is a Senior Specialist Solutions Architect for Generative AI at AWS within the Worldwide Specialist Organization. She specializes in AI/ML, with a focus on use cases such as AI voice assistants and multimodal understanding. She works closely with customers across diverse industries, including media and entertainment, gaming, sports, advertising, financial services, and healthcare, to help them transform their business solutions through AI.
Bin Chen
Bin Chen is a Generative AI Specialist Solutions Architect at AWS, which he joined in 2019. He is dedicated to helping customers explore the frontiers of generative AI and bring projects from proof of concept to production using services such as Amazon Bedrock and Amazon SageMaker. He is currently especially focused on Agentic AI and end-to-end speech models.
Siva Somasundaram
Siva Somasundaram is a senior engineer at AWS and builds embedded SDK and server-side components for Kinesis Video Streams. With over 15 years of experience in video streaming services, he has developed media processing pipelines, transcoding and security features for large-scale video ingestion. His expertise spans across video compression, WebRTC, RTSP, and video AI. He is passionate about creating metadata hubs that power semantic search, RAG expe
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み