Stripe の金融コンプライアンス向け本番級 AI エージェント:AWS ベッドロックでの構築教訓
Stripe は AWS Bedrock を活用した生産レベルの AI エージェントシステムを構築し、金融コンプライアンス業務の処理時間を 26% 短縮しつつ、人間の監督下で 96% 以上の有用性を達成する実証例を示した。
キーポイント
大規模データにおけるコンプライアンス課題と解決策
年間 1.4 兆ドルの取引を扱う Stripe は、手作業によるレビューのボトルネックに対し、AI エージェントと自動オーケストレーションを組み合わせたシステムを導入した。
ReAct フレームワークと AWS Bedrock の活用
Stripe は独自の ReAct エージェントフレームワークを AWS Bedrock 上で構築し、タスクの分解やオーケストレーションパターンを通じて複雑な金融リスク評価を自動化した。
人間の監督と説明可能性の維持
最終決定権は常に人間が保持する設計とし、監査可能性と責任所在を明確に保ちながら、AI が下準備や分析を支援するハイブリッドモデルを実現した。
コスト最適化とプロンプトキャッシング
大規模運用におけるコスト管理のため、プロンプトキャッシングなどの技術的工夫を採用し、96% 以上の有用性 rating を維持しながら効率を最大化した。
影響分析・編集コメントを表示
影響分析
この記事は、生成 AI が単なる実験段階から、金融規制という厳格な要件を持つ実業務で信頼性の高い「生産レベル」のシステムとして機能し得ることを示す決定的な証拠です。特に、AI の判断を完全に委ねるのではなく、人間の専門知識と組み合わせたハイブリッドモデルが、スケーラビリティとコンプライアンス品質の両立において有効であることを実証しており、他業界への展開にも大きな示唆を与えます。
編集コメント
金融規制という極めて厳しい制約下で AI エージェントを実用化した Stripe の事例は、業界全体における「信頼性の高い AI 実装」の基準を示す重要なケーススタディです。特に人間の監督を維持しつつ効率化を図るアプローチは、他業種での AI 導入検討において非常に参考になるでしょう。
*この投稿は、Stripe の Christopher Phillippi と Chrissie Cui が共同執筆したものです。*
Stripe は 50 カ国にまたがる年間 1.4 兆ドルの決済取引高を処理しており、コンプライアンスチームが毎日数千件の取引レビューを行う必要があります。本稿では、Stripe が Amazon Bedrock を活用して AWS 上で生産環境向けの AI エージェントシステムを構築し、人間の監督体制を維持しながらレビュー対応時間を 26% 削減した事例について探ります。また、最終決定権は人間が確実に握りつつも、96% 以上の有用性評価を獲得したアジェンティック AI の導入から得られた技術アーキテクチャ、インフラ設計の判断、そして教訓についても解説します。
本稿では、Stripe が金融コンプライアンスのために生産環境向けの AI エージェントシステムをどのように構築したかについて学びます。Stripe の ReAct エージェントフレームワークの技術アーキテクチャと、専用エージェントサービスを支えるインフラ設計の背景について取り上げます。さらに、説明責任を維持するための人間の監督の役割や、タスク分解、オーケストレーションパターン、プロンプトキャッシングを通じたコスト最適化に関する重要な教訓についても議論します。これらを通じて、品質や監査可能性を損なうことなくコンプライアンス運用をスケーラブルに設計するアジェンティックシステムの構築方法について理解を深めていただけます。
Stripe のスケールとコンプライアンスの課題
Stripe の基盤となるミッションは、インターネットの国内総生産(GDP)を成長させることです。この追求には、あらゆる規模の企業にとって円滑な取引と運用管理を支えるために設計されたプログラム可能な金融インフラが必要です。2026 年初頭時点で、Stripe は開発者中心の決済 API としての起源を超え、世界経済のシステム的な柱へと成長しました。同社は 50 カ国にわたる数百万社をサポートしており、初期段階のスタートアップからフォーチュン 500 社の 62% に至るまでをカバーし、年間約 1.4 兆ドルの決済取引量を処理しています。このスケールは世界の総 GDP の約 1.3% に相当し、Stripe を技術革新と強力な規制枠組みの重要な接点に位置づけています。
コンプライアンスのスケーリング問題
Stripe のグローバル展開が 50 カ国に及ぶにつれ、組織は重要な課題に直面しました。すなわち、人的リソースを比例して増やすことなくコンプライアンス業務を拡張しつつ、規制の品質基準を維持する方法です。毎日、コンプライアンスチームは金融犯罪リスクを特定し軽減するために詳細なレビューを実施しています。しかし、熟練したアナリストたちは、高価値のリスク評価を行うのではなく、断片化されたシステムを移動してドキュメントを集めることに時間を最大 80% も費やしていました。Stripe の解決策は、AI エージェントと自動化されたオーケストレーションを統合し、コンプライアンスをリソース集約型のプロセスからスケーラブルなエンジンへと変革しました。このアプローチは、リアルタイムでカードテスト攻撃の 95% を特定し、不要な顧客摩擦を 20% 削減することで、世界全体の 2,060 億ドルに及ぶコンプライアンス負担に対処します。また、規制当局が要求する監査可能性と精度も維持されます。
なぜコンプライアンスにエージェント型 AI を用いるのか?
複雑で判断を要するコンプライアンス業務における従来の自動化の限界は、AI エージェントが必要であることを意味します。これにより、規模に応じた支援調査、一貫した品質、完全な監査可能性を実現しつつ、人間が制御権を保持することが可能になります。
3 つの柱
- 監督と説明責任 – 設定可能な承認ワークフローと多層化された意思決定チェックポイントによる、人間中心の検証。人間が運転席に座り続け、エージェントによってサポートされます。
- 透明性 – すべての行動、意思決定、およびその根拠の不変的なドキュメントを含む完全な監査証跡。
- 効率性 – 事前調査と動的分析により、より深いレビューを高速で実施可能になります。
技術アーキテクチャ
Stripe のエージェント型コンプライアンスシステムの技術的実装は、3 つの主要なコンポーネントから構成されています。すなわち、タスク分解とオーケストレーション、ReAct エージェントフレームワーク、およびそれを支えるインフラストラクチャサービスです。各コンポーネントは、スケーラブルで監査可能なコンプライアンス自動化を実現する上で決定的な役割を果たします。
タスク分解とレビューのオーケストレーション
この長く複雑なレビューを単一のエージェントに任せて一度に行うアプローチは機能しなかったでしょう。制約のない単一のエージェントは、不要な点に過度に集中し、実際に必要なことに十分な注目を払わなかっただろう。そこで Stripe は、複雑なレビューを組み合わせ可能な小分けのサブタスクに分解することで、解決策を実行可能なものにした。各サブタスクは、有向非巡回グラフ(DAG)として他のサブタスクの結果に依存する可能性がある。これらの「レール」により、品質テストを通じて測定された検証済みの質問に対してのみ、各エージェントプロセスが実行されることを確認できる。また、調査が必要な項目をすべて網羅しているかを確認し、エージェントに十分な文脈と焦点を提供して高品質な結果を導き出すのを支援する。
各サブタスクにおけるエージェント応答の厳格な品質テストにもかかわらず、Stripe の実装は単一のエージェントの応答に完全に依存しているわけではない。代わりに、これらの応答は人間によるレビューアーへの補足情報として提供され、最終的に各サブタスクに対する回答を行うのは人間である。これにより、監督と説明責任を確保しつつ、効率性のメリットも同時に捉えることができる。高レベルのレビューフローは以下の図に示されている。
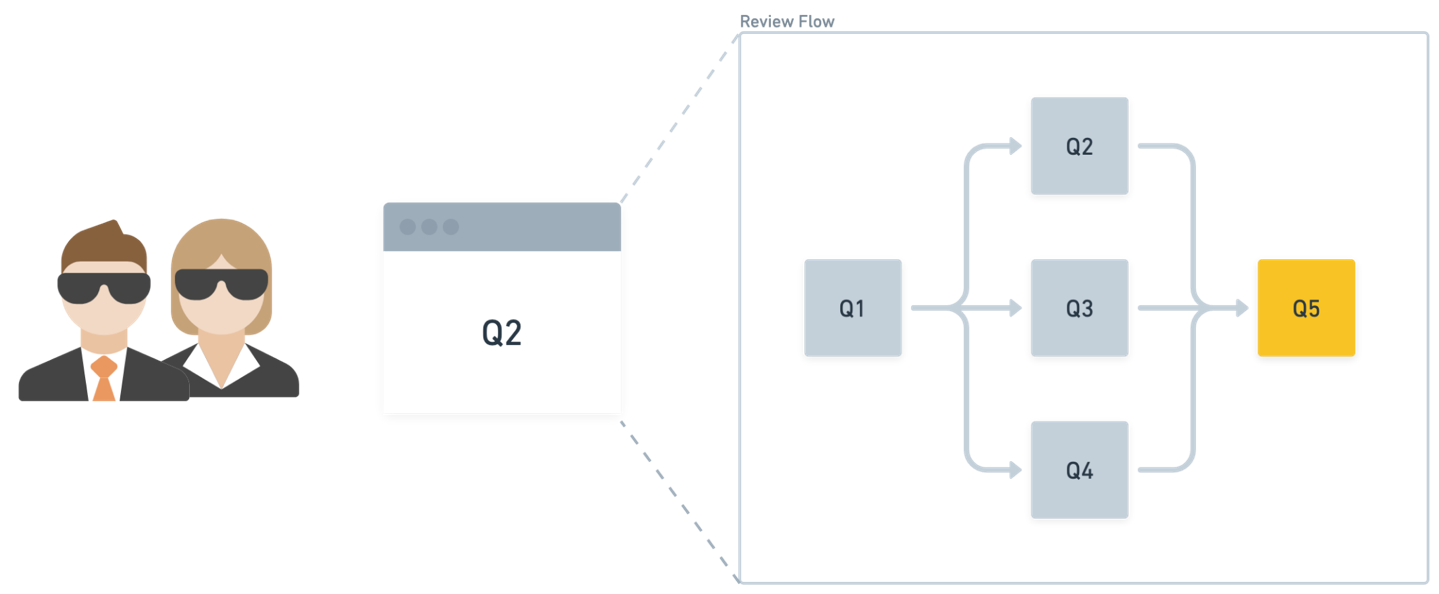
レビュー担当者は、現在の質問を認識し、その回答を文脈として必要とする後続の質問があることを理解するレビューツールと対話します。このツールはオーケストレーターとして機能し、人間がレビューした回答を次の質問への文脈としてパイプラインで流します。
ReAct エージェントフレームワークの実装
各サブクエリに対する調査情報を取得するために、Stripe は ReAct(推論と行動)エージェントフレームワークの一種を用いたコンプライアンスエージェントを構築しました。大規模言語モデル(LLM)を使用するだけでなく、Amazon Bedrock 上の基盤モデル(FM)の一種である推論用モデルを活用し、エージェント機能はツール呼び出しを通じて関連するシグナルを動的に収集します。Stripe はこのエージェントフレームワークを選択したことで、特定の主題に対して関連性があるかどうか不明な極めて多数のシグナルという課題に対処しました。エージェントはどのシグナルが関連するかを判断し、最終回答を提供するのに十分な自信を持つまでフォローアップを提案します。高レベルのエージェントロジックは以下の図に示されています。
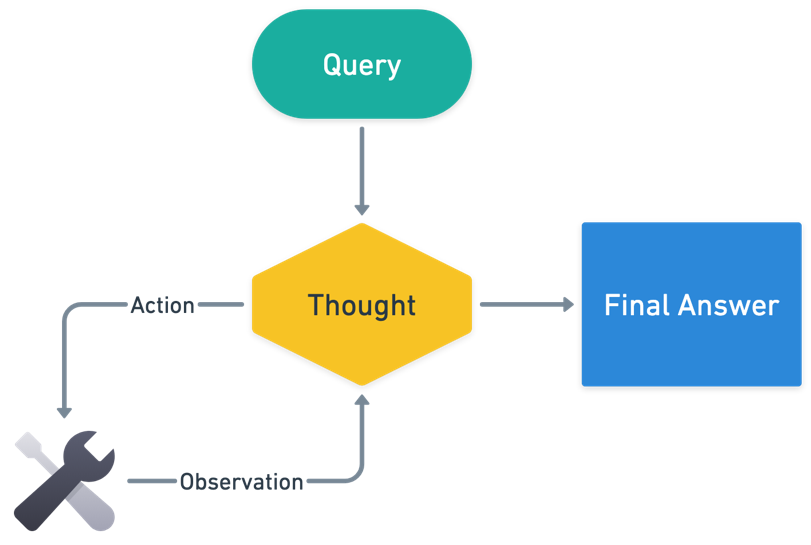
このフローを追うために、次のクエリを問われたと想像してください:「πで割った 10 の答えは何ですか?」
もしあなたが ReAct エージェントだったなら、最初の思考はすでに答えを持っているかどうかを検討することになるでしょう。答えがない場合、電卓を取り出して 10/π を入力するという行動を提案します。すると電卓が観測結果を返します。次の思考では、答えがあるかどうかを判断し、その計算結果を最終回答として提示します。
より困難な例としては、「来年の企業収益を予測する分析を作成する」といったタスクがあり、これはデータベース照会(ツール)と解釈(思考)の反復サイクルを多数必要とするものです。
ReAct サイクルにおいて、思考ブロックでツールの使用が要求されると、エージェントフレームワークは LLM の実行を一時停止し、代わりにそのツールをプログラム的に実行します。その後、その出力を観測結果としてエージェントに強制的に戻し、継続を許可します。この注入パターンは、以下の機能を持つ*閉ループ制御機構*を実装しています:
- Grounds agent reasoning in actual data – By mandating that every tool output must be processed as an observation, this prevents the agent from hallucinating or fabricating tool results.
- Maintains context coherence – Forces the agent to explicitly acknowledge and reason about each piece of retrieved information before proceeding.
- Prevents reasoning drift – The observation step acts as a checkpoint, helping verify the agent's thought process remains anchored to factual tool outputs rather than speculative reasoning.
- Supports auditability – Creates an explicit trace of tool invocation → observation → reasoning that can be logged for compliance review.
This is analogous to a *feedback control system* (フィードバック制御システム) in engineering. The agent can't proceed to the next action without first processing the feedback (observation) from its previous action, preventing open-loop behavior that could lead to hallucinations or off-track reasoning.
このアプローチにおける課題は、タスクが非常に複雑で多くのターンと観測を必要とする場合、特に冗長な観測がある場合、後続のターンではプロンプトが非常に長くなってしまうことです。サブタスクへの分解により、各質問のスコープを制限してターンの数を抑えています。また、プロンプトキャッシングは入力トークンのコスト削減にも寄与します。ここではこれが主要なコストドライバーとなっています。プロンプトキャッシングを利用すれば、各ターンで前のメッセージに追加される新しい観測と思考に対してのみ課金されます。Amazon Bedrock はこの機能を提供しています。
完全なエージェント型レビューアーキテクチャおよびインフラストラクチャ
Stripe は実際のエージェント実行をサポートするために大量のインフラストラクチャを利用しました。以下の図は完全なアーキテクチャを示しています。
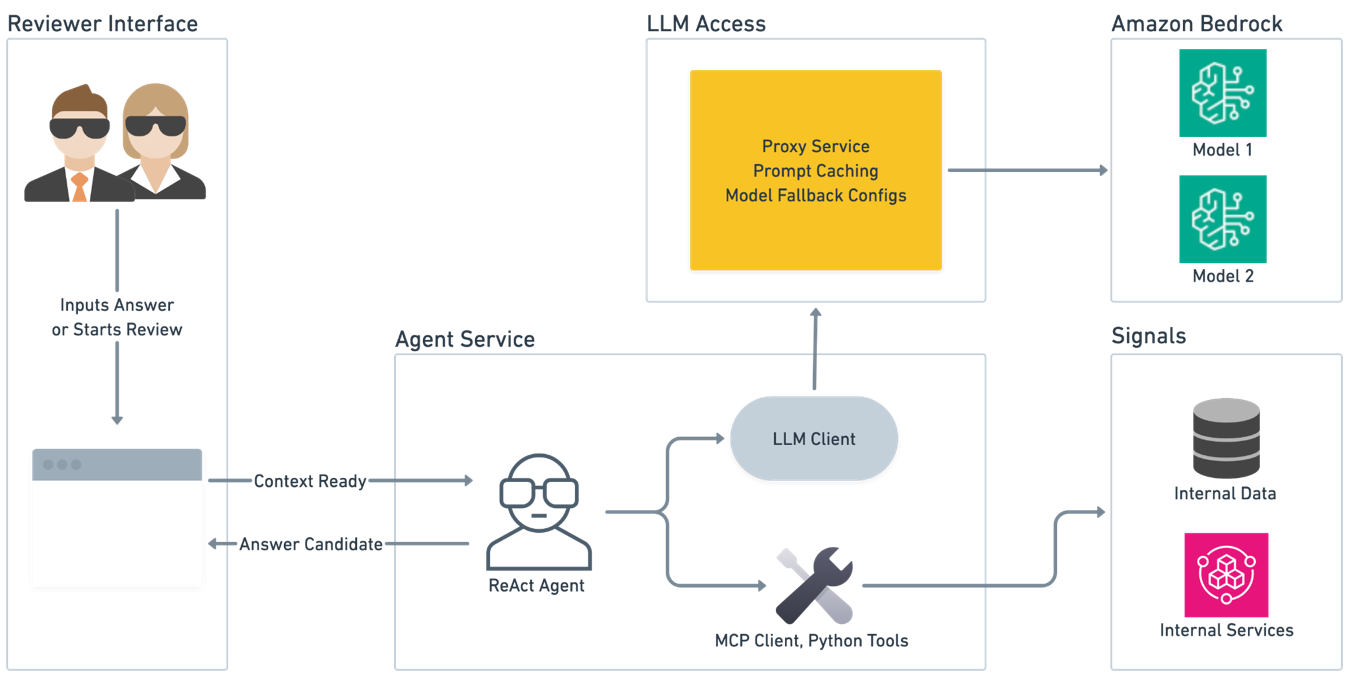
完全なアーキテクチャは、前述のレビューインターフェースとオーケストレーターに加え、エージェントロジックをホストして実行を支援する「エージェントサービス (agent service)」で構成されています。このエージェントサービスは、Stripe の「LLM プロキシ (LLM Proxy) サービス」によってサポートされ、利用可能なエージェントツールを通じて内部シグナルに接続されています。
専用エージェントサービスの構築
本プロジェクト以前には Stripe にエージェントサービスは存在せず、本プロジェクトを契機として Stripe がその要求を行いました。当初、Stripe は従来の機械学習推論エンジン (ML inference engine) にエージェントを組み込もうと試みました。しかし、以下の理由によりこのアプローチはすぐに却下されました:
- Compute profiles – Traditional ML is compute bound, requiring expensive hardware such as GPUs, fast multi-threaded CPUs, or large memory allocations. In contrast, agentic applications are mostly network bound, waiting on foundation models to finish or tool calls to run.
- Latency – Referencing the ReAct flow described previously, an agent can take an indeterminate amount of time to finish, depending on how many rounds of tool calls it needs. A long agent query or a database tool call could cause a thread to sit idle for minutes, compared to an XGBoost model that would finish in milliseconds.
- Different API – In contrast to traditional ML that tends to output basic types (floats, Booleans, and others), agents need more flexibility in their schema to annotate their results. Some agents need to maintain stateful conversation states.
As a result, Stripe stood up its own agent service, initially resembling a stateless, synchronous inference endpoint. Today it also handles stateful, multi-turn conversational agents. It has grown from a few agents at launch to well over 100 agents in less than a year.
LLM proxy architecture
Stripe's ReAct agent doesn't call Amazon Bedrock directly. Instead, Stripe uses an LLM Proxy microservice as its standard method for LLM access. The following diagram shows the LLM Proxy architecture.
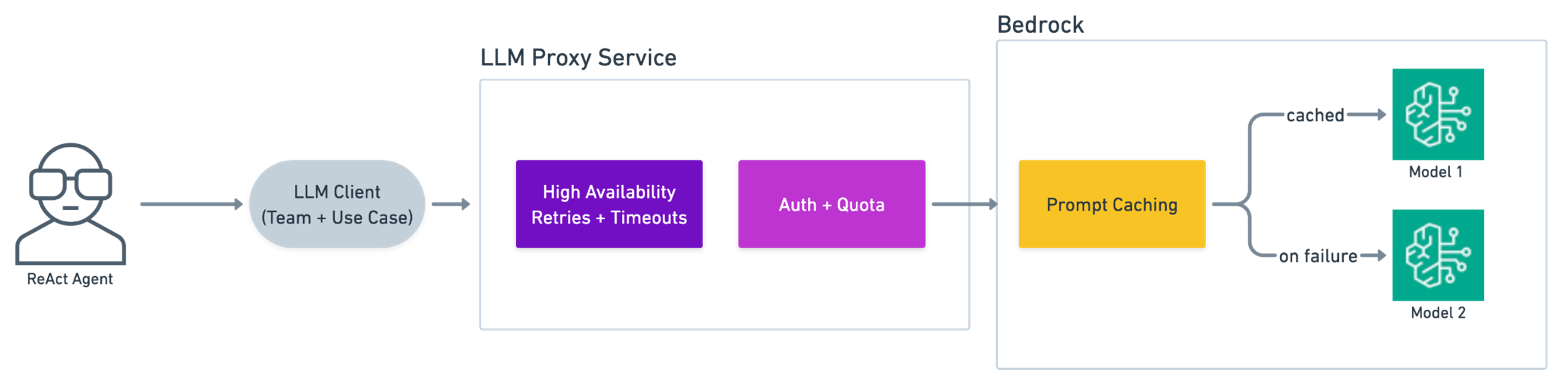
Stripe は、以下の理由から LLM プロキシサービスを利用しています。
- ノイジーな隣人 – Stripe には、さまざまなアプリケーションに LLM を使用する多くのチームがあります。LLM プロキシは、特定のモデルに対して他のチームが帯域幅を独占することを防ぎ、リソース競合を防ぐためのセーフガードを提供します。
- 1 つの API、多数のモデル – 単一のエンドポイントにより、Amazon や主要な AI 企業からのファウンデーションモデル全体に、プロンプトキャッシュやツール呼び出しなどの機能を指定する作業が簡素化されます。モデルを変更する際も、各ユースケースで多数の異なるクライアントを管理する必要はなく、引数としてモデルタイプを変更するだけで済みます。
- モデルのフォールバック – これにより、リソース制約が発生した場合や完全な失敗が生じた場合に、デフォルトのモデルを自動的に指定する機能が提供されます。
- モニタリング – 認証を必須とすることで、このサービスはモデルの使用状況を追跡し、将来のリソース需要を見積もるのを助け、アプリケーションのプライバシーレベルに応じて適切なモデルが使用されていることを確認できます。
アーキテクチャコンポーネントの連携
人間によるレビュー担当者が主導し、エージェントレスポンスを事前取得した調査資料として活用します。回答を進める中で、これらのレスポンスは、同じレビュー内でより深い質問を行うためのプロンプトに利用され、レビューの問いかけが有向非巡回グラフ(DAG: Directed Acyclic Graph)としてオーケストレーションされます。
特定の質問に対して、エージェントは必要な場合にツールを呼び出して内部データやサービスに動的にアクセスできます。このアプローチが取られるのは、検討対象となる潜在的な関連信号が、プロンプトに含まれる量よりも通常はるかに大きいためです。エージェントのツール呼び出し機能により、思考ログには現在の質問に答えるために必要なデータのみが含まれ、不要な情報が追加されないため、焦点が絞られます。
エージェント自体は、Amazon や主要な AI 企業から提供される基盤モデルによって駆動されており、思考プロセスや必要なツールの呼び出しを決定する役割を担っています。エージェントアプリケーションは LLM クライアントを通じて大規模言語モデル(LLM)にアクセスし、プロンプトのキャッシュ機能やモデルのフォールバックなどの機能を抽象化しています。
Amazon Bedrock 統合によるメリット
Stripe はその LLM プロキシ内で Amazon Bedrock を活用しています。Amazon Bedrock は以下のさらなる利点を提供します:
- 標準化されたプライバシーとセキュリティ – 決済処理業者である Stripe は、プライバシーとセキュリティに関して特に注意を払う必要があります。Amazon Bedrock を利用することで、Amazon および主要な AI 企業からのファウンデーションモデルが、既存のセキュリティおよびプライバシーの制約内に収まっていることを検証でき、各モデルごとに追加のレビューオーバーヘッドが発生しません。
- 豊富な機能 – 前述した通り、Amazon Bedrock は対応するモデルにおいてプロンプトキャッシング(prompt caching)を可能にします。さらに、Amazon Bedrock ではファインチューニングやカスタムモデルの提供もサポートしており、Stripe は今後 1 年間でこれらに注力する見込みです。
- 1 つの API で多数のモデル – モデルが同じ API の範囲内にあるため、統合は非常に簡単です。モデルを変更する場合は、異なるモデル名を使用するだけで済みます。Amazon Bedrock はまた、Amazon および主要な AI 企業からの多種多様なファウンデーションモデルをサポートしており、Stripe に対して業界標準の性能を提供します。
規制遵守のための監査証跡の実装
最終的に Stripe では人間によるレビュー官が判断と決定を下しますが、システムは依然として規制当局の審査に耐えうるものであることを検証する必要があります。その結果、Stripe はログ機能を導入し、各実行履歴においてエージェントのログ全体を後から検索可能にしました。すべてのエージェントのアクション、意思決定、およびその根拠が文書化されています。
結果と影響:レビュー処理時間が 26% 短縮され、有用性評価は 96% を超える
Stripe は、エージェント型自動化を通じて、中央値のレビュー処理時間を 26% 削減することに成功しました。同時に、レビュー担当者からの有用性評価は 96% を維持し、最終的な意思決定は人間が管理する体制を構築しています。これらは、監査基準に適合した完全な監査証跡を提供しながら達成された成果です。
Stripe の成長が続く中で、組織はリスク管理に対する需要の増加にも比例して対応できるようになります。人間のレビュー担当者は、より困難な問題や新たな調査機会に時間を集中させることが可能となり、コンプライアンスプログラムの改善につながります。
本番環境での展開から得た教訓
この本番用エージェント型 AI システムの構築と展開のプロセスを通じて、Stripe はプロジェクトの成功を形作り、同様の導入事例にも示唆を与えるいくつかの洞察を導き出しました。
小さなタスクへの分割 – エージェントのタスクは作業記憶(working memory)で扱える範囲に小さく保つこと。いきなり完全自動化を目指すのではなく、品質を段階的にテストしていくことが重要です。
オーケストレーション – 複雑なエージェント間の相互作用を管理しつつ、大規模化しても監査可能性と人間の監督体制を維持するためには、DAG(有向非巡回グラフ)サポートを備えた非同期ワークフローアーキテクチャが不可欠です。
インフラストラクチャー – 専用マイクロサービスアーキテクチャが重要なのは、エージェントが従来の機械学習モデルとは根本的に異なるリソースプロファイルを持つからです。従来の推論システムは計算リソースに制約され、高価な GPU ハードウェア上でミリ秒単位の応答を最適化しています。一方、エージェントはネットワークリソースに制約され、LLM 呼び出しやツール実行の待ち時間に数分を費やし、予測不能なレイテンシパターンを示します。専用エージェントサービスは、非同期実行パターンを通じてこれらの長時間実行かつ状態を保持するインタラクションを処理します。これにより、スレッドは外部呼び出しにブロックされることなく、複数の並行するエージェントセッションを効率的に管理できます。トークンキャッシングは、各ステップで会話履歴全体を再処理するのではなく、共通のプロンプトプレフィックスをエージェントのターン間で再利用することでコストを 60% 削減します。コスト計測機能は、各エージェント呼び出しごとのトークン使用量を追跡し、ワークロードがスケールする際に支出を見積もるのを支援するとともに、予算に影響を与える前に最適化の機会を特定することを可能にします。このインフラファーストのアプローチにより、エージェントは実験的なプロトタイプから、Stripe 全体で 100 以上のエージェントをサポートする本番サービスへと変貌しました。
人間による制御を維持 – エージェントは支援しますが、最終的な意思決定権限は専門家のレビューアーが保持します。コンテキストの範囲を制限するために、エージェントにレール(制約)を設けてください。
今後の展望
当初、Stripe はレビュー開始前に回答可能な質問に焦点を当てていました。残りの質問には、レビュー中に既知で検証された上流の文脈が必要となる可能性が高く、これによりより複雑なマルチステップの処理へと発展していくことになります。
原文を表示
*This post is co-written by Christopher Phillippi and Chrissie Cui from Stripe.*
Stripe processes $1.4 trillion in annual payment volume across 50 countries, requiring compliance teams to review thousands of transactions daily. This post explores how Stripe built a production-grade AI agent system on AWS using Amazon Bedrock that reduced review handling time by 26 percent while maintaining human oversight. The post covers the technical architecture, infrastructure decisions, and lessons learned from deploying agentic AI that achieved over 96 percent helpfulness ratings, with human experts firmly in control of final decisions.
In this post, you learn how Stripe built a production-grade AI agent system for financial compliance. We cover the technical architecture of Stripe’s ReAct agent framework and the infrastructure decisions behind a dedicated agent service. We also discuss the role of human oversight in maintaining accountability, and key lessons about task decomposition, orchestration patterns, and cost optimization through prompt caching. By the end, you will understand how to design agentic systems that scale compliance operations without compromising quality or auditability.
Stripe’s scale and compliance challenge
The foundational mission of Stripe is to grow the gross domestic product (GDP) of the internet. That pursuit requires programmable financial infrastructure designed to support smooth transactions and operational management for businesses of all scales. As of early 2026, Stripe has grown beyond its origins as a developer-centric payment API to become a systemic pillar of the global economy. The company supports millions of companies across 50 countries, from early-stage startups to 62 percent of the Fortune 500, and processes approximately $1.4 trillion in annual payment volume. This scale represents approximately 1.3 percent of the total global GDP, positioning Stripe at the critical nexus of technological innovation and strong regulatory frameworks.
The compliance scaling problem
As Stripe’s global footprint expanded across 50 countries, the organization faced a critical challenge: how to scale compliance operations without proportional headcount increases while maintaining regulatory quality standards. Every day, compliance teams conduct detailed reviews to identify and mitigate financial crime risks. However, skilled analysts were spending up to 80% of their time navigating fragmented systems to gather documentation rather than performing high-value risk assessments. Stripe’s solution integrates AI agents with automated orchestration, transforming compliance from a resource-intensive process into a scalable engine. This approach addresses the $206 billion global compliance burden by helping organizations identify 95% of card-testing attacks in real time and reduce unnecessary customer friction by 20%. The approach also maintains the auditability and precision required by regulators.
Why agentic AI for compliance?
The limitations of traditional automation for complex, judgment-based compliance work mean AI agents are needed to handle assisted investigations with scale, consistent quality, and full auditability while keeping humans in control.
Three pillars
- Oversight and accountability – Human-centered validation with configurable approval workflows and multi-layered decision checkpoints. Humans stay in the driver’s seat, supported by agents.
- Transparency – Full audit trail with immutable documentation of every action, decision, and rationale.
- Efficiency – Pre-investigation and dynamic analysis allow deeper reviews at faster pace.
Technical architecture
The technical implementation of Stripe’s agentic compliance system consists of three key components: task decomposition and orchestration, the ReAct agent framework, and supporting infrastructure services. Each component plays a critical role in achieving scalable, auditable compliance automation.
Task decomposition and review orchestration
Assigning a single agent to handle this long, complicated review in one go wouldn’t have worked. A single, unconstrained agent would have focused too much on the wrong things and not enough on what was actually needed. Instead, Stripe made the solution tractable by breaking the complicated review into composable, bite-sized sub-tasks. Each sub-task could potentially depend on the results of other sub-tasks as a directed acyclic graph (DAG). These *rails* help verify each agentic process is only run on vetted questions where quality has been measured through quality testing. They also help confirm the investigation covers the required bases, and provide the agent sufficient context and focus to deliver quality results.
Despite rigorous quality testing of the agent responses in each sub-task, Stripe’s implementation does not rely outright on the response of an agent. Instead, the responses are provided as supplementary information to the human reviewer, who must ultimately answer each sub-task of the review. This solves for oversight and accountability while still capturing the efficiency benefits. The high-level review flow is shown in the following diagram.
Reviewers interact with the review tooling, which is aware of the current question and which subsequent questions require that answer as context. The tooling functions as the orchestrator, piping human-reviewed answers as context for further questions.
ReAct agent framework implementation
To fetch research for each sub-question, Stripe built a compliance agent using a form of the ReAct (reasoning and acting) agent framework. Beyond using a large language model (LLM), a type of foundation model (FM) on Amazon Bedrock for reasoning, the agentic aspect dynamically gathers relevant signals through tool calls. Stripe chose this agent framework to solve the problem of a near-infinite number of signals that may or may not be relevant for a given subject. Agents determine which signals are relevant and propose follow-ups until they are sufficiently confident to provide a final answer. The high-level agent logic is shown in the following diagram.
To walk through this flow, imagine being asked the query: “what is the answer to 10 divided by the number π?”
If you were a ReAct agent, your first thought would be to consider whether you already have the answer. You don’t, so you would propose an action of taking out a calculator and inputting 10/π. The calculator would then return an observation. Your next thought would be to determine whether you have an answer, and you would provide that calculation as your final answer. You can imagine something harder, such as “produce an analysis forecasting next year’s company revenue”, taking many cycles of database querying (Tool) and interpretation (Thought) iterations.
In the ReAct cycle, whenever a tool is requested in the Thought block, the agent framework stops the LLM execution and instead programmatically runs that tool. It then forces that output as an observation back to the agent before allowing it to continue. This injection pattern implements a *closed-loop control mechanism* that:
- Grounds agent reasoning in actual data – By mandating that every tool output must be processed as an observation, this prevents the agent from hallucinating or fabricating tool results.
- Maintains context coherence – Forces the agent to explicitly acknowledge and reason about each piece of retrieved information before proceeding.
- Prevents reasoning drift – The observation step acts as a checkpoint, helping verify the agent’s thought process remains anchored to factual tool outputs rather than speculative reasoning.
- Supports auditability – Creates an explicit trace of tool invocation → observation → reasoning that can be logged for compliance review.
This is analogous to a *feedback control system* in engineering. The agent can’t proceed to the next action without first processing the feedback (observation) from its previous action, preventing open-loop behavior that could lead to hallucinations or off-track reasoning.
A challenge with this approach is that when a task is so complicated that it needs many turns and observations, the prompt can get very long in the later turns, particularly with verbose observations. The sub-task decomposition limits the scope of each question to keep the number of turns smaller. Prompt caching also helps with the cost of input tokens, which is the primary cost driver here. With prompt caching, you only pay for the new observations and thoughts that are appended to the previous messages at each turn. Amazon Bedrock provides this capability.
Full agentic review architecture and infrastructure
Stripe relied on a significant amount of infrastructure to support the actual agentic execution. The following diagram shows the full architecture.
The full architecture consists of the review interface and orchestrator covered earlier and an *agent service* that hosts the agent logic and facilitates execution. The agent service is supported by Stripe’s *LLM Proxy* service and connected to internal signals through available agent tools.
Building a dedicated agent service
Before this project, Stripe’s agent service didn’t exist, and this project resulted in Stripe requesting it. Initially, Stripe attempted to fit an agent into a traditional ML inference engine. This approach was rejected quickly for the following reasons:
- Compute profiles – Traditional ML is compute bound, requiring expensive hardware such as GPUs, fast multi-threaded CPUs, or large memory allocations. In contrast, agentic applications are mostly network bound, waiting on foundation models to finish or tool calls to run.
- Latency – Referencing the ReAct flow described previously, an agent can take an indeterminate amount of time to finish, depending on how many rounds of tool calls it needs. A long agent query or a database tool call could cause a thread to sit idle for minutes, compared to an XGBoost model that would finish in milliseconds.
- Different API – In contrast to traditional ML that tends to output basic types (floats, Booleans, and others), agents need more flexibility in their schema to annotate their results. Some agents need to maintain stateful conversation states.
As a result, Stripe stood up its own agent service, initially resembling a stateless, synchronous inference endpoint. Today it also handles stateful, multi-turn conversational agents. It has grown from a few agents at launch to well over 100 agents in less than a year.
LLM proxy architecture
Stripe’s ReAct agent doesn’t call Amazon Bedrock directly. Instead, Stripe uses an LLM Proxy microservice as its standard method for LLM access. The following diagram shows the LLM Proxy architecture.
Stripe uses an LLM Proxy service for the following reasons:
- Noisy neighbors – Stripe has many teams using LLMs for various applications. The LLM Proxy provides safeguards from other teams hogging the LLM bandwidth for a particular model, preventing resource contention.
- One API, many models – The single endpoint simplifies specifying capabilities such as prompt caching or tool calling across foundation models from Amazon and leading AI companies. Changing models requires only changing the model type as an argument, instead of each use case managing many different clients.
- Model fallbacks – This provides the ability to automatically specify default models in the case of resource constraints or outright failure.
- Monitoring – By requiring authentication, the service can track model usage to help forecast future resource demand and confirm the appropriate models are being used depending on the privacy of the application.
How architectural components work together
Human reviewers drive the review, using agentic responses as pre-fetched research. As they answer, those responses can be used in the prompts for deeper questions during the same review, orchestrating review questions as a directed acyclic graph (DAG).
For a given question, the agent can call tools to dynamically access internal data or services as needed. This approach is used because the potential relevant signals that could be examined are typically much larger than what can be included in a prompt. The tool-calling aspect of the agent means the thought log includes only the relevant data to answer the current question, without additional irrelevant information, inducing focus.
The agent itself is driven by foundation models from Amazon and leading AI companies, which are responsible for thinking and determining which tool calls are needed. The agent application accesses the LLM through the LLM Client, which abstracts away features such as prompt caching and model fallbacks.
Amazon Bedrock integration benefits
Stripe uses Amazon Bedrock within its LLM Proxy. Amazon Bedrock provides the following further benefits:
- Standardized privacy and security – As a payment processor, Stripe must be extra careful around privacy and security. Amazon Bedrock helps verify that foundation models from Amazon and leading AI companies fit within existing security and privacy constraints, without additional review overhead for each model.
- Feature rich – As described earlier, Amazon Bedrock allows for prompt caching on supported models. Additionally, Amazon Bedrock allows for fine-tuning and serving custom models, which Stripe expects to focus on in the coming year.
- One API, many models – Integration is straightforward because models fall within the same API. Changing models requires using a different model name. Amazon Bedrock also supports many different foundation models from Amazon and leading AI companies, providing industry-standard performance for Stripe.
Audit trail implementation for regulatory compliance
Even though Stripe ultimately uses human reviewers to make judgments and decisions, the system still must verify it stands up to regulatory scrutiny. As a result, Stripe implemented logging so the entire agent log is retrievable for each run historically. Every agent action, decision, and rationale is documented.
Results and impact: 26 percent faster reviews with over 96 percent helpfulness
Stripe achieved a 26 percent reduction in median review handling time through agentic automation, with over 96 percent helpfulness ratings maintained from reviewers, and human reviewers in control of decisions. This was accomplished while providing full audit trails meeting examination standards.
As Stripe continues to grow, the organization will be able to keep up with proportional demand for risk management. Human reviewers can focus their time on tougher problems or new investigation opportunities, leading to an improved compliance program.
Key lessons learned from production deployment
Through the process of building and deploying this production agentic AI system, Stripe distilled several insights that shaped the project’s success and can inform similar implementations.
Bite-sized tasks – Keep agent tasks small enough for working memory. Test quality incrementally rather than diving straight into full automation.
Orchestration – Async workflow architecture with DAG support is essential for complex agent interactions while maintaining auditability and human oversight at scale.
Infrastructure – Dedicated microservice architecture matters because agents have fundamentally different resource profiles than traditional ML models. Traditional inference systems are compute-bound and optimized for millisecond responses on expensive GPU hardware. Agents are network-bound, spending minutes waiting on LLM calls and tool executions with unpredictable latency patterns. A dedicated agent service handles these long-running, stateful interactions through async execution patterns. This allows threads to efficiently manage multiple concurrent agent sessions without blocking on external calls. Token caching reduces costs by 60% by reusing common prompt prefixes across agent turns rather than reprocessing the entire conversation history on each step. Cost instrumentation tracks token usage per agent invocation, helping teams forecast spend as workloads scale and identify optimization opportunities before they impact budgets. This infrastructure-first approach transformed agents from an experimental prototype into a production service supporting more than 100 agents across Stripe.
Keep humans in control – Agents assist, but expert reviewers maintain final decision authority. Constrain agents with rails to bound context.
What’s next
Initially, Stripe focused on questions that can be answered before the review even starts. Remaining questions likely require upstream context known and validated during the review. This will lead to more complex, multi
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み