WINTICKET Webリージョン障害対策――Weighted Backend ServiceとサーバーレスNEGの外れ値検出
株式会社WinTicketのWebチームは、Google CloudのCloud Runをマルチリージョン運用する中で発生したリージョン障害に対し、Weighted Backend Serviceによる手動ルーティング制御とサーバーレスNEGの外れ値検出による自動切り離しという二段階の対策を導入した事例を紹介している。
キーポイント
課題:リージョン障害時のトラフィック継続問題
従来のCloud Load Balancing構成では、特定リージョン(例:大阪)のCloud Runが障害でインスタンス数0になっても、そのリージョンを指すNEGにリクエストが送られ続け、ユーザーにエラーが返される問題が発生した。
対策1:Weighted Backend Serviceによる手動切り離し
リージョン別にBackend Serviceを用意し、重み付けでルーティングを制御。障害時は異常リージョンの重みを0に、正常リージョンの重みを100%に設定変更することで、トラフィックを即時に切り離せるようにした。
対策2:サーバーレスNEGの外れ値検出による自動切り離し
HTTPレスポンスのパターン(連続する5xxエラーやGatewayエラー)から異常なNEGを自動検知し、一時的にトラフィックから切り離す機能を導入。設定パラメータを調整して運用に最適化した。
構成と適用対象
アーキテクチャはCloud Load Balancing → Backend Service → Serverless NEG → Cloud Run。この対策は、Google CloudのCloud Runを運用する開発者や、マルチリージョン構成の可用性・障害対策を検討する開発者に参考となる。
影響分析・編集コメントを表示
影響分析
この記事は、特定企業の事例紹介という形式ではあるが、クラウドネイティブなマルチリージョンアーキテクチャにおける一般的な可用性課題と、Google Cloudプラットフォームが提供する具体的な解決策(Weighted Backend ServiceとサーバーレスNEG外れ値検出)の組み合わせ方を示しており、実務者にとっての実用性が高い。業界全体を変えるような技術的革新ではないが、クラウド運用のベストプラクティスとしての普及・啓発に寄与する内容である。
編集コメント
企業ブログの事例紹介だが、技術的詳細や設定パラメータに踏み込んでおり、クラウドエンジニア向けの実用的なトラブルシューティング・設計ノウハウとして価値が高い。
Weighted Backend Service によるルーティング制御
サーバーレス NEG の外れ値検出
Cloud Load Balancing におけるリージョン障害時のリクエストルーティングの課題
リージョン別 Backend Service と重み付けによるルーティング制御(Weighted Backend Service)
サーバーレス NEG の外れ値検出機能による異常 NEG の自動切り離し
Google Cloud の Cloud Run を運用している開発者
マルチリージョン構成における可用性・障害対策を検討している開発者
株式会社 WinTicket の Web チームでエンジニアをしている安井(@ytaisei_)です。
WINTICKET Web では東京と大阪のリージョンに Cloud Run を配置しています。以前、大阪側の Cloud Run が一時的にダウンしたことにより、同リージョンにルーティングされたユーザーがサービスにアクセスできない状況が発生しました。この事態を踏まえ、Weighted Backend Service によるルーティング制御とサーバーレス NEG の外れ値検出を導入しました。
本記事では、その背景となる課題と、両対策の内容について紹介します。
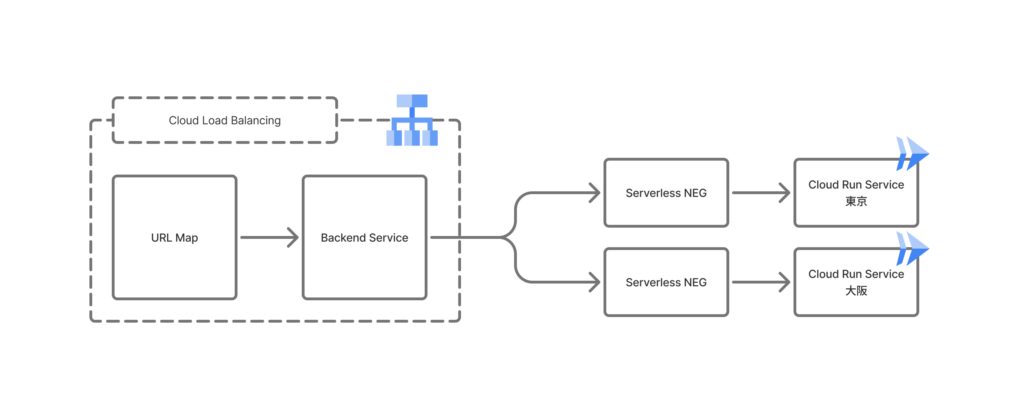
WINTICKET Web のリクエストは、Google Cloud の Cloud Load Balancing(URL Map → Backend Service)→ Serverless Network Endpoint Group(NEG)→ Cloud Run Service の流れで処理されます。
発生した事象は以下のとおりです。
- 約 30 分間にわたり、エラーレートが高まっていた
- 大阪側で一部のリクエストが約 100 件/h ほどエラーになっていた
- 大阪側の Cloud Run インスタンス数が 0 になっていた
- 直前までの CPU・メモリ使用率および 5xx エラーレートは正常だった
当時の構成では、特定のリージョンに障害が発生した場合でも、Cloud Load Balancing は該当の NEG にリクエストを送り続けてしまいます。その結果、異常な NEG へトラフィックが流れ、ユーザーにエラーが返される事態となり得ました。
Weighted Backend Service によるルーティング制御
そこで、リージョンごとに専用の Backend Service を用意し、Backend Service 間で重み付け設定を可能にしました。これにより、障害時に異常な NEG へリクエストが流れ続ける事態を防ぎます。
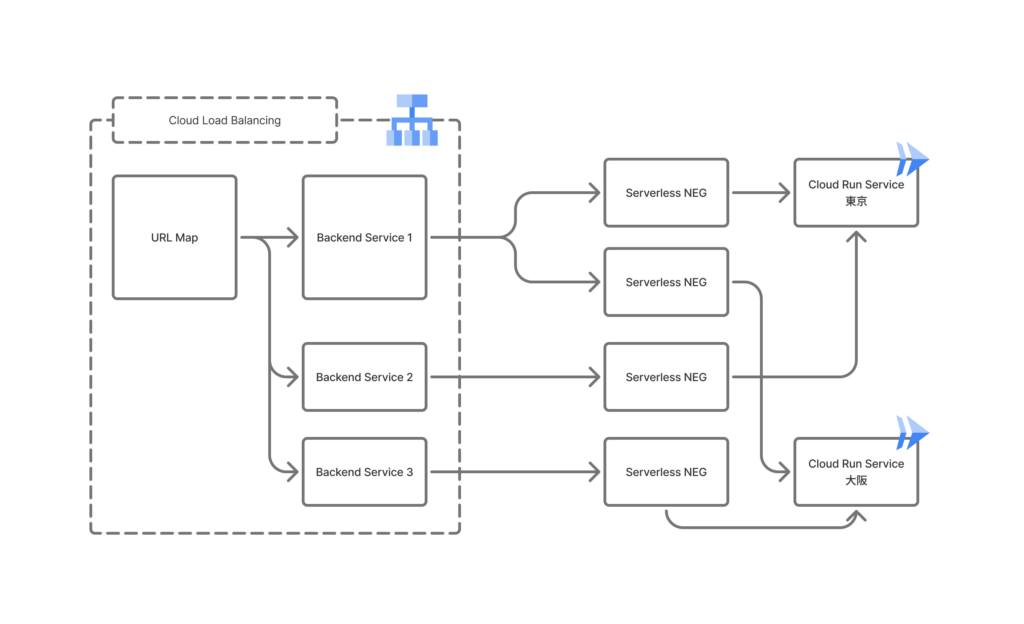
通常時は、図内の Backend Service 1 に 100% の重みを設定します。複数 NEG を持つ Backend Service は、Google Cloud 内部の最適化に基づいてルーティングされるため、従来どおりの挙動となります。
リージョン障害時は、図内の Backend Service 2 または 3 の重みを操作します。例えば、大阪リージョンで障害が発生した場合は、東京を指す Backend Service 2 に対して 100% ルーティングするように設定変更することで、異常なリージョンへのトラフィックを即時に遮断できます。
#### Terraform での設定例
google_compute_url_map リソースの default_route_action ブロック内で weighted_backend_services を設定します。
resource "google_compute_url_map" "default" {
default_route_action {
weighted_backend_services {
backend_service = google_compute_backend_service.default.self_link
weight = 100
}
weighted_backend_services {
backend_service = google_compute_backend_service.tokyo.self_link
weight = 0
}
weighted_backend_services {
backend_service = google_compute_backend_service.osaka.self_link
weight = 0
}
}
}この対応により、リージョン障害発生時でも異常リージョンへのトラフィックを即時に切り離し、正常なリージョンへルーティングできるようになりました。
サーバーレス NEG の外れ値検出
Weighted Backend Service の導入により障害時に正常なリージョンへルーティングすることは可能ですが、Backend Service の設定を手動で更新する作業が必要です。しかし本来はリージョン側の異常を自動で検知し、リクエストを最適に振り分けたいところです。そこで、サーバーレス NEG の外れ値検出を導入しました。
サーバーレス NEG の外れ値検出は、HTTP レスポンスのパターンから異常なサーバーレス NEG を検知し、その NEG を一時的に切り離す機能です。異常と判断された NEG にはトラフィックを送らず、正常な NEG へリクエストを振り分けることで、エラー率の低減を図ります。
外れ値検出を有効化する際、以下のパラメータを設定しました。
- base_ejection_time: 切り離し後トラフィックを送らない時間。約 3 分間。短すぎると異常状態での復帰が多くなり、長すぎると正常復帰後の待ち時間が長くなる。
- max_ejection_percent: 最大で切り離せる NEG の割合。東京・大阪の 2 リージョン運用のため、片方異常時は全てのトラフィックを正常側へルーティングできるよう 50% に設定。
- consecutive_errors: 切り離しを開始するまでの連続 5xx エラー回数。
- consecutive_gateway_failure: 切り離しを開始するまでの連続 Gateway エラー回数(502、503、504 のみ)。
- enforcing_consecutive_gateway_failure: 連続 Gateway エラー検知時に実際に切り離しを実行する確率。
上記の設定により、10 秒ごとに各 NEG のレスポンスを分析し、5 回連続で 5xx エラーまたは Gateway エラー(502、503、504)が発生した NEG を切り離します。切り離された NEG は最大 3 分間トラフィックを受けなくなります。
#### Terraform での設定例
Terraform では google_compute_backend_service リソースの outlier_detection ブロックで設定します。
resource "google_compute_backend_service" "default" {
outlier_detection {
base_ejection_time {
seconds = 180
}
interval {
seconds = 10
}
max_ejection_percent = 50
consecutive_errors = 5
consecutive_gateway_failure = 5
enforcing_consecutive_gateway_failure = 100
}
}両対策を導入した結果
両対策を導入した結果、以下のような構成となりました。
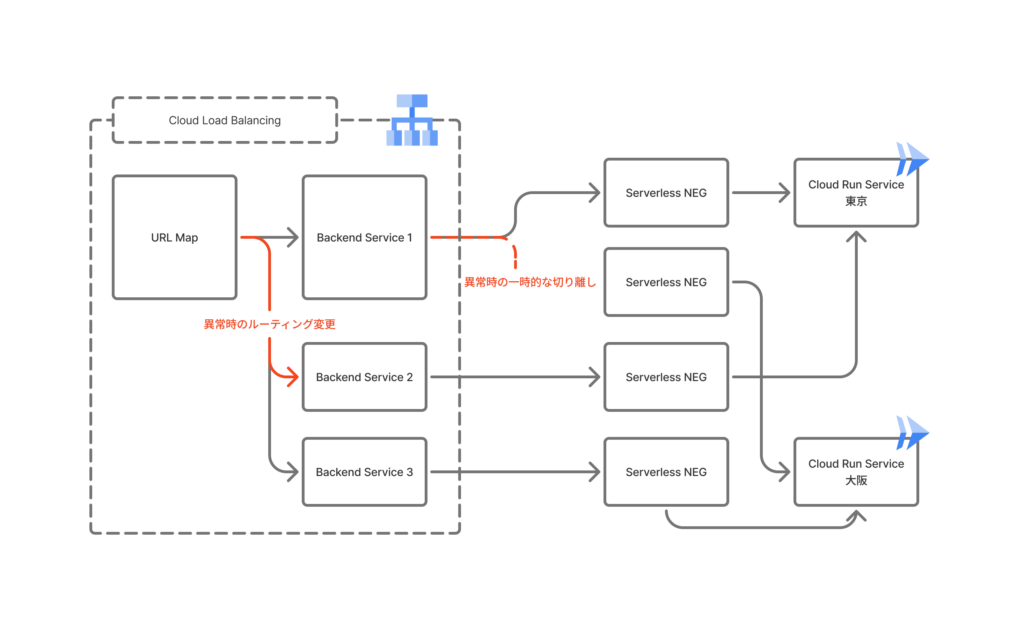
Cloud Load Balancing の URL Map で Backend Service 1〜3 にトラフィックを振り分け、各 Backend Service は Serverless NEG を経由して東京・大阪の Cloud Run Service に接続します。
- Weighted Backend Service により、URL Map で Backend Service 間の重みを設定し、障害時に手動で重みを変更することで異常リージョンへのトラフィックを完全に遮断し、正常なリージョンへルーティング可能になりました。
- サーバーレス NEG の外れ値検出 により、HTTP レスポンスパターンに基づき異常な Serverless NEG を自動検知し、その NEG を一時的(最大 3 分間)に切り離してエラー率を軽減します。
一方で、Weighted Backend Service とサーバーレス NEG の外れ値検出にはそれぞれ制約があります。
#### Weighted Backend Service によるルーティング制御の制約
Weighted Backend Service は、異常なリージョンへのトラフィックを完全に遮断することが可能です。しかし、重みの変更は手動での設定更新が必要であり、切り離し実行までにオペレーションの時間がかかります。
#### サーバーレス NEG の外れ値検出の制約
外れ値検出だけでは、完全な遮断はできません。今回の設定値では、切り離しは最大 3 分間有効であり、3 分経過後には切り離されていた NEG へ再度リクエストが送信されます。ただし、再度外れ値が検出された場合は、その NEG が再び切り離されます。
まとめ
両技術の役割を整理すると以下のようになります。
- Weighted Backend Service:リージョン全体がダウンしている場合に、手動でルーティング割合を変更して完全に遮断する。
- サーバーレス NEG の外れ値検出:自動で異常を検知・切り離ししてエラー率を軽減し、いち早く対応する。
本記事では、WINTICKET Web のリージョン障害対策として実施した以下 2 つの対策を紹介しました。
- Weighted Backend Service:障害時に手動でルーティング重みを変更し、異常リージョンへのトラフィックを即時に遮断できる。
- サーバーレス NEG の外れ値検出:HTTP レスポンスパターンに基づき異常 NEG を自動検知し、一部のトラフィックを正常側へ転送してエラー率を軽減する。
双方を組み合わせることで、リージョン障害時の影響を抑えられる体制を整えました。
参考リンク
原文を表示
Weighted Backend Service によるルーティング制御
サーバーレス NEG の外れ値検出
Cloud Load Balancing におけるリージョン障害時のリクエストルーティングの課題
リージョン別 Backend Service と重み付けによるルーティング制御(Weighted Backend Service)
サーバーレス NEG の外れ値検出機能による異常 NEG の自動切り離し
Google Cloud の Cloud Run を運用している開発者
マルチリージョン構成における可用性・障害対策を検討している開発者
株式会社 WinTicket の Web チームでエンジニアをしている安井(@ytaisei_)です。
WINTICKET Web では東京と大阪のリージョンに Cloud Run を配置しています。以前、大阪側の Cloud Run が一時的に落ちたことにより、同リージョンにルーティングされたユーザーがサービスにアクセスできない状況が生じました。この事態を踏まえ、Weighted Backend Service によるルーティング制御とサーバーレス NEG の外れ値検出を導入しました。
本記事では、その背景となる課題と、両対策の内容について紹介します。
WINTICKET Web のリクエストは、Google Cloud の Cloud Load Balancing(URL Map → Backend Service)→ Serverless NetworkEndpointGroup(NEG)→ Cloud Run Service の流れで処理されます。
発生した事象は以下のとおりです。
約 30 分間にわたり、エラーレートが高まっていた
大阪側で一部のリクエストが約 100 件/h ほどエラーになっていた
大阪側の Cloud Run インスタンス数が 0 になっていた
直前までの CPU・メモリ使用率および 5xx エラーレートは正常だった
当時の構成では、特定のリージョンに障害が発生した場合でも、Cloud Load Balancing は該当の NEG にリクエストを送り続けてしまいます。その結果、異常な NEG へトラフィックが流れ、ユーザーにエラーが返される事態となり得ました。
Weighted Backend Service によるルーティング制御
そこで、リージョンを指定した Backend Service を用意し、Backend Service 間の重み付け設定を可能にしました。これにより、障害時に異常な NEG へリクエストが流れ続ける事態を防ぎます。
通常時は、図内の Backend Service 1 に 100% の重みを設定します。複数 NEG を持つ Backend Service は、Google Cloud 内で内部最適化に基づいてルーティングされるため、従来どおりの挙動となります。
リージョン障害時は、図内の Backend Service 2 か 3 に重みを操作します。例えば、大阪リージョンで障害が発生した場合は、東京を指す Backend Service 2 に対して 100% ルーティングするように設定変更することで、異常なリージョンへのトラフィックを即時に切り離しできます。
Terraform での設定例
google_compute_url_map
default_route_action
weighted_backend_services
resource "google_compute_url_map" "default" { default_route_action { weighted_backend_services { backend_service = google_compute_backend_service.default.self_link weight = 100 } weighted_backend_services { backend_service = google_compute_backend_service.tokyo.self_link weight = 0 } weighted_backend_services { backend_service = google_compute_backend_service.osaka.self_link weight = 0 } } }
この対応により、リージョン障害発生時でも異常リージョンへのトラフィックを即時に切り離し、正常なリージョンへルーティングできるようになりました。
サーバーレス NEG の外れ値検出
Weighted Backend Service の導入により障害時に正常なリージョンへルーティングすることは可能ですが、Backend Service の設定を更新するオペレーションが必要です。しかし本来はリージョン側の異常を自動で検知し、リクエストを最適に振り分けたいところです。そこで、サーバーレス NEG の外れ値検出を導入しました。
サーバーレス NEG の外れ値検出は、HTTP レスポンスのパターンから異常なサーバーレス NEG を検知し、その NEG を一時的に切り離す機能です。異常と判断された NEG にはトラフィックを送らず、正常な NEG へリクエストを振り分けることで、エラー率の低減を図ります。
連続する Gateway エラー(502、503、504 の HTTP ステータスコードのみ)
外れ値検出を有効化する際、以下のパラメータを設定しました。
base_ejection_time
切り離し後トラフィックを送らない時間。約 3 分間。短すぎると異常状態での復帰が多い。長いと正常復帰後の待ち時間が長くなる
max_ejection_percent
最大で切り離せる NEG の割合。東京・大阪の 2 リージョン運用のため、片方異常時は全てを正常側へルーティングする
consecutive_errors
切り離しまでの連続 5xx エラー回数
consecutive_gateway_failure
切り離しまでの連続 Gateway エラー回数(502、503、504 のみ)
enforcing_consecutive_gateway_failure
連続 Gateway エラー検知時に実際に切り離す確率。
上記の設定により、10 秒ごとに各 NEG のレスポンスを分析し、5 回連続で 5xx または Gateway エラー(502、503、504)が発生した NEG を切り離します。切り離された NEG は最大 3 分間トラフィックを受けなくなります。
Terraform での設定例
Terraform では google_compute_backend_service
outlier_detection
resource "google_compute_backend_service" "default" { outlier_detection { base_ejection_time { seconds = 180 } interval { seconds = 10 } max_ejection_percent = 50 consecutive_errors = 5 consecutive_gateway_failure = 5 enforcing_consecutive_gateway_failure = 100 } }
両対策を導入した結果、以下のような構成となりました。
Cloud Load Balancing の URL Map で Backend Service 1〜3 にトラフィックを振り分け、各 Backend Service は Serverless NEG を経由して東京・大阪の Cloud Run Service に接続します。
Weighted Backend Service により、URL Map で Backend Service 間の重みを設定し、障害時に手動で重みを変更することで異常リージョンへのトラフィックを完全に切り離し、正常なリージョンへルーティング可能になりました。
そして、サーバーレス NEG の外れ値検出により、HTTP レスポンスパターンに基づき異常な Serverless NEG を自動検知し、その NEG を一時的(最大 3 分間)に切り離してエラー率を軽減します。
一方で、Weighted Backend Service とサーバーレス NEG の外れ値検出のそれぞれに制約があります。
Weighted Backend Service によるルーティング制御の制約
Weighted Backend Service は、異常なリージョンへのトラフィックを完全に切り離すことが可能です。しかし、重みの変更は手動での設定更新が必要であり、切り離し実行までにオペレーションの時間が必要になります。
サーバーレス NEG の外れ値検出の制約
外れ値検出だけでは、完全な切り離しはできません。今回の設定値では、切り離しは最大 3 分間有効であり、3 分経過後には切り離されていた NEG へ再度リクエストが送信されます。ただし、再度外れ値が検出された場合は、その NEG が再び切り離されます。
Weighted Backend Service:リージョン全体が落ちている場合に、手動でルーティング割合を変更して完全に切り離す
サーバーレス NEG の外れ値検出:自動で検知・切り離ししてエラー率を軽減し、いち早く異常に対応できる
本記事では、WINTICKET Web のリージョン障害対策として実施した以下 2 つの対策を紹介しました。
Weighted Backend Service:障害時に手動でルーティング重みを変更し、異常リージョンへのトラフィックを即時に切り離しできる
サーバーレス NEG の外れ値検出:HTTP レスポンスパターンに基づき異常 NEG を自動検知し、一部のトラフィックを正常側へ転送してエラー率を軽減する
双方を組み合わせることで、リージョン障害時の影響を抑えられる体制を整えました。
重み付きロード バランシングを構成する
Terraform weighted_backend_services
サーバーレス NEG の外れ値検出
Terraform outlier_detection
関連記事
【Next Tokyo セッション公開】スクウェア・エニックスとリクルートが「Gemini 本番実装」のアーキテクチャを公開
スクウェア・エニックスとリクルートは、Google Developers JP が開催した Next Tokyo セッションで、大規模言語モデル Gemini を本番環境に導入する際の具体的なアーキテクチャ設計について発表した。
Google、信頼性の高い分散型エージェント実行環境「Agent Executor」を発表
Google は、長期にわたるエージェントワークフローの信頼性と効率を高めるためのオープンソースランタイム標準「Agent Executor」を発表した。同製品は、永続的な実行や安全な隔離機能を提供し、Kubernetes Engine と連携して大規模展開時の計算リソース効率を最適化する。
Google I/O、Gemini Spark、アンチグラビティ
Simon Willison は、試せない発表や「近日公開」の情報は書かない方針のため、今年度の Google I/O で実際に体験可能な Gemini 3.5 Flash などの利用可能になった技術について言及している。