Amazon Novaの強化学習ファインチューニング:フィードバックを通じてAIを教育
AWSはAmazon Novaモデル向けに、正解例の模倣ではなく評価によるフィードバックで最適化する「強化学習ファインチューニング(RFT)」を提供し、ドメイン固有の専門知識や複雑な推論タスクへのカスタマイズを効率化する。
キーポイント
RFTの基本概念とSFTとの違い
従来の教師ありファインチューニング(SFT)が数千件の正確なラベル付き例と推論プロセスを必要とするのに対し、RFTはプロンプトと正解基準(テストケースや検証可能な結果)のみを提供し、モデルがフィードバックを通じて独自の解決策を最適化する学習パラダイム。
適用分野と利点
コード生成や数学的推論など、複数の正解パスが存在し詳細なステップバイステップの例作成が困難または高コストなタスクにおいて、出力を自動検証することでデータ準備のコストと時間を削減できる。
実装オプション
完全マネージド型のAmazon Bedrockから、マルチターンエージェントワークフローに対応するNova Forgeまで、ユーザーのAI成熟度に応じて柔軟な実装方法を選択可能。
影響分析・編集コメントを表示
影響分析
この発表は、LLMのファインチューニングにおいてデータ準備のコストと品質がボトルネックとなる課題に対し、強化学習の概念を適用した実用的な解決策を示す。特に、正解例だけでなく「なぜそれが正解か」を定義する評価基準の設計が鍵となるため、企業は単なるデータ収集から「評価指標の定義」へリソースをシフトする必要が生じる。これは、より高度で信頼性の高いドメイン特化型AIアプリケーションの開発を促進し、業界全体のファインチューニング標準に影響を与える可能性がある。
編集コメント
SFTに依存していた従来のカスタマイズ手法の限界を打破するRFTの実装は、特に複雑な推論が必要な業務システムにおいてデータ準備のコストを劇的に削減する可能性がある。ただし、効果的なRFTには適切な「報酬関数」や「検証基準」の設計が不可欠であり、その品質が最終的なモデル性能を左右する。
ファウンデーションモデルは、一般的なタスクにおいて優れた初期性能を発揮しますが、多くの組織では自社の業務知識をモデルが理解・活用できることが必要となります。ドメイン固有の専門知識や特定のコミュニケーションスタイルの適用、コード生成や財務推論といった特殊なタスクへの最適化、業界規制への準拠確保など、アプリケーション構築においては汎用 AI と自社の具体的なニーズとのギャップを埋めるためにモデルのカスタマイズが不可欠です。課題は、いかに効果的にカスタマイズするかという点にあります。従来の教師ありファインチューニングは結果をもたらしますが、それは正しい最終回答だけでなく、そこに至るまでの完全な推論経路を示す数千件の慎重にラベル付けされた例が存在する場合に限られます。多くの実世界アプリケーション、特に複数の有効な解決策の道筋が存在するタスクにおいては、こうした詳細なステップバイステップの実演を作成することは、しばしば高コストで時間がかかるものとなります。
本稿では、評価を通じて学習する而非模倣による強力なカスタマイズ手法である Amazon Nova モデル向けの強化学習微調整(RFT)について探ります。RFT の仕組み、教師あり微調整との使い分けのタイミング、コード生成からカスタマーサービスに至るまでの実世界での応用例、そして完全に管理された Amazon Bedrock から Nova Forge を用いた複数回対話型エージェントワークフローに至るまでの実装オプションについて解説します。また、最適な結果を達成するためのデータ準備、報酬関数の設計、およびベストプラクティスに関する実践的なガイダンスも紹介します。
新たなパラダイム:模倣ではなく評価による学習
もし、車が地図上のすべての経路を学ぶだけでなく、間違った方向に進んだ場合のナビゲーション方法も学べるようになったらどうでしょうか?これが、私たちが Amazon Nova モデルに導入することを楽しみにしている強化学習微調整(RFT)の核心となるアイデアです。RFT は、模倣による学習から評価による学習へとパラダイムをシフトさせます。数千ものラベル付き例を提供するのではなく、プロンプトを提供し、最終的な答えが正しいとみなされる基準をテストケース、検証可能な結果、または品質基準を通じて定義します。その後、モデルは反復的なフィードバックを通じてこれらの基準を最適化することを学び、正解への独自の経路を発見していきます。
RFT は、コード生成や数学的推論におけるモデルのカスタマイズをサポートし、出力を自動的に検証することで、詳細な段階的な推論を提供する必要を排除します。私たちは、AI 活用におけるあらゆる段階のお客様のニーズに応えるため、RFT を当社の AI サービス全体で利用可能にしました:Amazon Bedrock で提供される完全管理型エクスペリエンスからシンプルに始め、SageMaker Training Jobs でより多くの制御を獲得し、SageMaker HyperPod で高度なインフラへスケールするか、または多ターン会話やカスタム強化学習環境のために Nova Forge を活用して最先端の機能を解放します。
2025 年 12 月、Amazon は Nova 2 ファミリーをリリースしました。これは、推論機能を内蔵した Amazon 初のモデルです。従来のように直接回答を生成するのではなく、Nova 2 Lite などの推論モデルは、段階的な問題分解を行い、最終的な答えを出す前に中間の思考ステップを実行します。この拡張された思考プロセスは、人間が複雑な分析タスクに取り組む方法に似ています。RFT(Reinforcement Fine-Tuning:強化学習による微調整)と組み合わせることで、この推論能力は特に強力なものとなります。RFT はモデルが生成する答えだけでなく、問題へのアプローチ方法そのものを最適化し、より効率的な推論経路を発見させる一方で、トークン使用量を削減することを可能にします。現時点では、RFT はテキストのみのユースケースでサポートされています。
実世界のユースケース
RFT は、正しい結果を定義・検証できるシナリオにおいて特に優れています。ただし、大規模な詳細な段階別解決策デモンストレーションを作成することは現実的ではありません。以下に、RFT が有効な選択肢となり得るいくつかのユースケースを示します:
- コード生成:単に正解であるだけでなく、効率的で可読性が高く、エッジケースを適切に処理するコードが必要です。これらはテスト実行やパフォーマンス指標を通じてプログラム的に検証可能な品質です。
- カスタマーサービス:返信が役立っているか、ブランドの声を維持しているか、各状況に適したトーンになっているかを評価する必要があります。これらは単純なルールに還元できない判断事項ですが、コミュニケーション基準に基づいて訓練された AI 判定者によって評価可能です。
- その他のアプリケーション:文脈やニュアンスが重要となるコンテンツモデレーション、財務分析や法文書レビューのような多段階推論タスク、そして API を呼び出すタイミングや方法、データベースを照会する方法をモデルに教える必要があるツール使用などがあります。どのケースでも、大規模な段階ごとの推論プロセスを容易に示すことができない場合であっても、正しい結果をプログラム的に定義して検証することが可能です。
- 探索が重要な問題:ゲームプレイや戦略、リソース割り当て、スケジューリングなどのユースケースでは、モデルが異なるアプローチを用いてフィードバックから学習する事例が有効です。
- ラベル付きデータが限られたシナリオ:ドメイン固有のアプリケーションで専門家が注釈をつけた例が少ない場合、確立された解決パターンがない新しい問題領域、ラベル付けコストの高いタスク(医療診断、法務分析)など、限られたラベル付きデータセットしか利用できないユースケースがあります。これらのケースでは、RFT(Reinforcement Fine-Tuning:強化学習微調整)は報酬関数から計算された報酬を最適化するために役立ちます。
RFT の仕組み
RFT は、図 1 に示される 3 つの段階からなる自動化プロセスを通じて機能します:
第 1 段階:応答生成 – アクターモデル(カスタマイズ対象となるモデル)は、トレーニングデータセットからのプロンプトを受け取り、各プロンプトに対して複数の応答を生成します。通常、4 から 8 バリエーションが作成されます。この多様性により、システムは評価・学習の対象となる広範な応答の範囲を得ることができます。
第 2 段階:報酬計算 – システムは、ラベル付き例との比較ではなく、報酬関数を用いて品質を評価します。ここでは 2 つの選択肢があります:
- 検証可能な報酬による強化学習 (RLVR): AWS Lambda 関数として実装されたルールベースの評価者で、コードの実行や数学的問題の検証など、プログラムによって正誤を判定できる客観的なタスクに最適です。
- AI フィードバックからの強化学習 (RLAIF): 設定した基準に基づいて応答を評価する AI ベースの審査員で、有用性、創造性、ブランドボイスへの準拠などを評価するような主観的なタスクに理想的です。
第 3 段階:アクターモデルのトレーニング – システムは、スコア付けされたプロンプトと応答のペアを用いて、言語モデル向けに最適化された強化学習アルゴリズム(例:Group Relative Policy Optimization (GRPO))を通じてモデルをトレーニングします。このプロセスでは、高報酬の応答を生成する確率を最大化し、低報酬の応答を最小化するように学習が進みます。この反復的なプロセスは、モデルが目標とするパフォーマンスに達するまで継続されます。
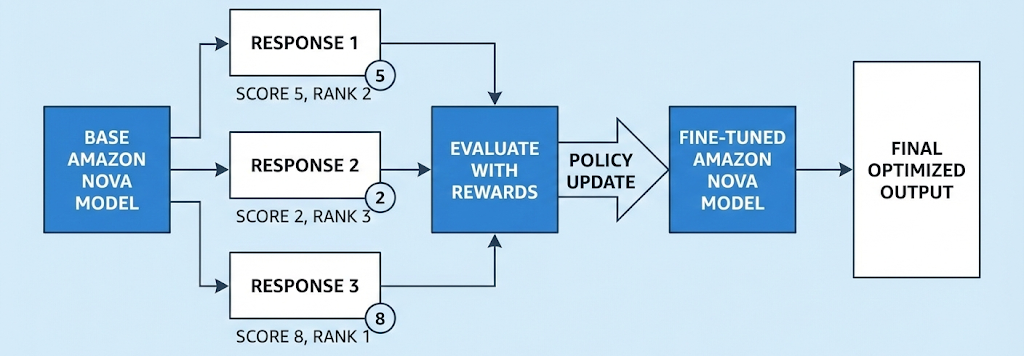
図 1: RFT のシングルパス動作の概要
RFT の主な利点
RFT の主な利点は以下の通りです:
- 大規模なラベル付きデータセットは不要 – RFT ではプロンプトと品質評価手段があれば十分です。Bedrock RFT を利用する場合は、既存の Bedrock API 呼び出しログをそのまま RFT データとして活用できるため、特別に作成したデータセットを用意する必要もありません。
- 検証可能な成果物に最適化 – 正解に至るための明示的なデモンストレーションを必要とする教師ありファインチューニングとは異なり、RFT は「正しい結果を定義・検証可能であるが、複数の有効な推論経路が存在し得る」タスクに対して最適化されています。
- トークン使用量の削減 – モデルの推論プロセスを最適化することで、タスク完了に必要なトークン数を減らし、本番環境におけるコストとレイテンシを低下させます。
- セキュアかつ監視可能 – カスタマイズ処理中も独自データは AWS の安全な環境から一切外部に流出せず、トレーニングメトリクスをリアルタイムで監視できるため、進捗状況の追跡と品質保証が可能です。
実装ティア:シンプルから複雑へ
Amazon は、Nova モデルにおけるリインフォースメント微調整(Reinforcement Fine-Tuning)に対して、完全管理型エクスペリエンスからカスタマイズ可能なインフラまで、複数の実装パスを提供しています。この階層化されたアプローチに従うことで、RFT 実装を特定のニーズ、技術的専門知識、および望む制御レベルに合わせて最適化できます。
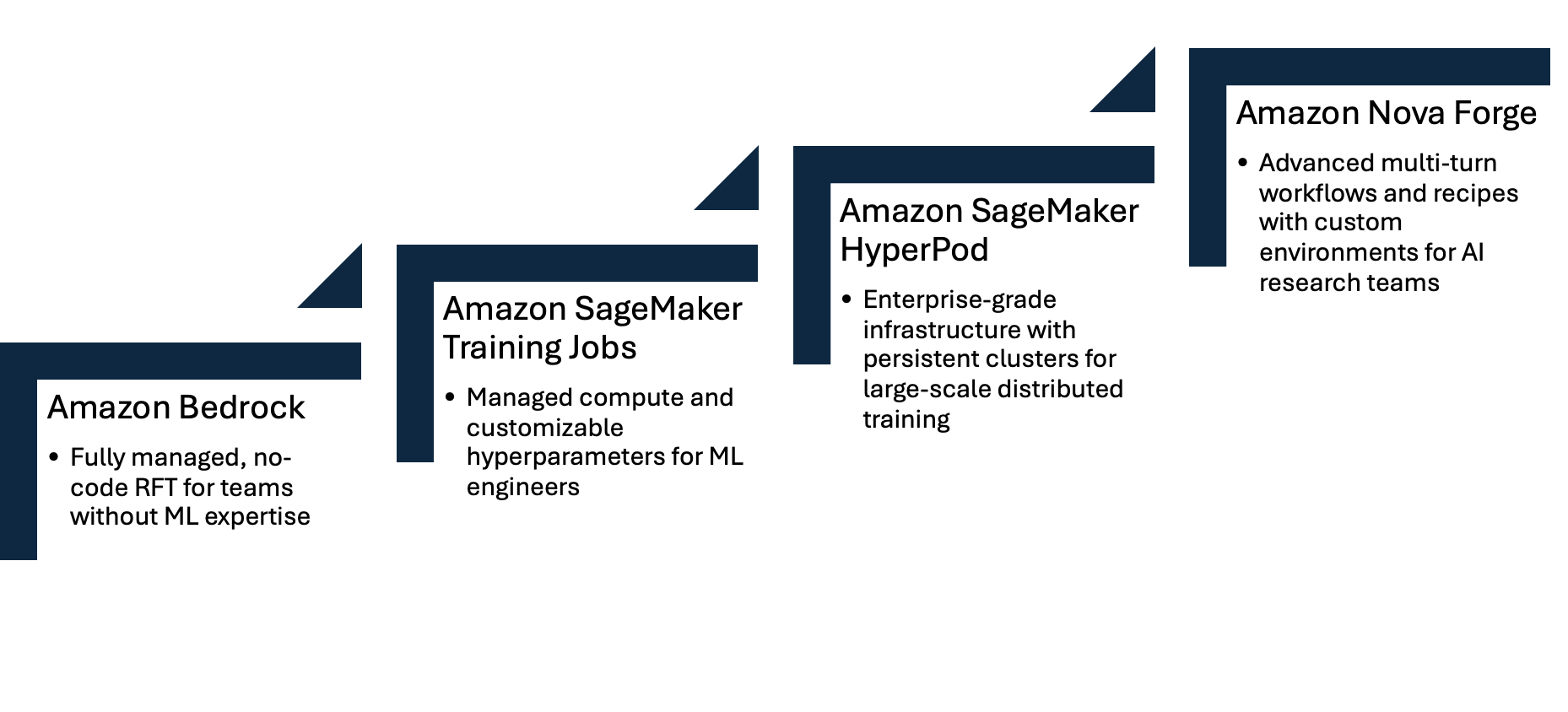
Amazon Bedrock
Amazon Bedrock は、最小限の機械学習(ML)専門知識で済む完全マネージド型体験を通じて、RFT(強化学習微調整)への入り口を提供します。Amazon Bedrock コンソールまたは API を介して、トレーニング用プロンプトをアップロードし、報酬関数を AWS Lambda として設定するだけで、数回のクリックで強化学習微調整ジョブを開始できます。Bedrock は、インフラストラクチャのプロビジョニング、トレーニングのオーケストレーション、モデルのデプロイメントをすべて自動的に処理します。このアプローチは、インフラストラクチャの管理を行わずに特定の基準を最適化する必要がある単純なユースケースで特に効果的です。この簡素化されたワークフローにより、専任の ML エンジニアを持たないチームでも RFT を利用可能になりながら、強力なカスタマイズ機能を維持できます。Bedrock の RFT は、ルールベース報酬(RLVR)と AI ベースフィードバック(RLAIF)の両方のアプローチをサポートしており、モデルの改善を追跡するための組み込みモニタリングおよび評価ツールも備えています。始め方については、Amazon Nova RFT の GitHub リポジトリをご覧ください。
SageMaker Training Jobs
トレーニングプロセスに対してより多くの制御を必要とするチーム向けに、Amazon SageMaker Training Jobs は、管理されたコンピューティングリソースと複数のハイパーパラメータの調整機能を備えた柔軟な中間的な選択肢を提供します。また、中間チェックポイントを保存して使用することで、教師あり微調整(SFT)とフィードバック強化学習(RFT)ジョブを連鎖させるなど、モデルを段階的に洗練させる反復的なトレーニングワークフローを作成することも可能です。LoRA とフルランクのトレーニングアプローチの間で選択する柔軟性があり、ハイパーパラメータに対して完全な制御権限を持ちます。デプロイメントにおいては、完全に管理された推論には Amazon Bedrock を、インスタンスタイプ、バッチ処理、パフォーマンスチューニングを自分で制御したい場合は Amazon SageMaker エンドポイントを選択できます。このティアは、Amazon Bedrock 以上のカスタマイズが必要だが、専用インフラストラクチャを必要としない機械学習エンジニアやデータサイエンティストに最適です。SageMaker Training Jobs は、実験の追跡、モデルレジストリ、デプロイメントパイプラインのために、より広範な Amazon SageMaker AI エコシステムともシームレスに統合されます。Amazon Nova の RFT を SageMaker Training Job で実行する際には、YAML レシピファイルを使用してトレーニングジョブを構成します。ベースとなるレシピは、SageMaker HyperPod recipes リポジトリ から入手できます。
ベストプラクティス:
- データ形式:1 行に 1 つの JSON オブジェクトを含む JSONL 形式を使用してください。
- 参照回答:報酬関数がモデルの予測と比較する基準となる正解値を含めてください。
- 小さく始める:スケーリングする前に、まず 100 例から始めてアプローチを検証してください。
- カスタムフィールド:評価に報酬関数が必要とする任意のメタデータを追加してください。
- 報酬関数(Reward Function):AWS Lambda を用いて、速度と拡張性を考慮して設計してください。
- Amazon SageMaker Training Jobs で Amazon Nova の RFT ジョブを開始するには、SFT および RFT ノートブックを参照してください。
SageMaker HyperPod
SageMaker HyperPod は、分散トレーニングに最適化された永続的な Kubernetes ベースのクラスターを提供し、大規模な RFT(強化学習微調整)ワークロード向けにエンタープライズグレードのインフラストラクチャを実現します。このティアは、チェックポイント管理、反復型トレーニングワークフロー、LoRA およびフルランクトレーニングオプション、柔軟なデプロイメントなど、SageMaker Training Jobs で利用可能なすべての機能を基盤としつつ、専用コンピューティングリソースと専門的なネットワーク構成を備えてより大規模に拡張されます。HyperPod における RFT 実装は、最先端の非同期強化学習アルゴリズムを通じてスループットの向上と収束速度の高速化を実現しており、推論サーバーとトレーニングサーバーが独立して最大速度で動作します。これらのアルゴリズムはこの非同期性を考慮し、ファウンデーションモデルのトレーニングに用いられる最先端の技術を組み込んでいます。また、HyperPod は高度なデータフィルタを提供し、トレーニングプロセスに対する細粒度の制御を可能にしてクラッシュの可能性を低減します。スループットとパフォーマンスを最大化するために、ハイパーパラメータに対する細粒度の制御も可能です。HyperPod は、大規模な RFT の限界に挑戦する必要がある ML プラットフォームチームや研究機関向けに設計されています。Amazon Nova RFT では、YAML レシピファイルを使用してトレーニングジョブを設定します。基本となるレシピは、SageMaker HyperPod レポジトリから取得できます。
- 詳細については、「Amazon SageMaker HyperPod 上で Amazon Nova RFT ジョブを開始するための RFT ベースの評価」をご覧ください。
Nova Forge
Nova Forge は、高度な強化学習フィードバックトレーニング機能を提供し、洗練されたエージェント型アプリケーションを構築する AI 研究チームや実践者を対象に設計されています。単一ターン対話や Lambda のタイムアウト制約から解放されることで、Nova Forge は、ご自身の VPC で実行されるカスタムスケール環境における複雑なマルチターンワークフローを可能にします。このアーキテクチャにより、標準的な RFT(強化学習フィードバック)ティアではサポートできない最先端 AI アプリケーションにとって不可欠な、軌道生成、報酬関数、およびトレーニング・推論サーバー機能との直接操作に対する完全な制御権が得られます。Nova Forge はトレーニングプラットフォームとして Amazon SageMaker HyperPod を採用し、Amazon Nova が厳選したデータセットとのデータミックスや中間チェックポイントの提供といった他の機能も備えています。
主な機能:
- マルチターン会話サポート
- 実行時間が 15 分を超える報酬関数
- 追加のアルゴリズムと調整オプション
- カスタムトレーニングレシピの変更
- 最先端の AI 技術
この段階ごとの進出は、それぞれの前段階を基盤として構築されており、RFT(強化学習微調整)の要件が変化するにつれて自然な成長パスを提供します。初期実験には Amazon Bedrock から始め、アプローチを洗練させる際には SageMaker Training Jobs へ移行し、特殊なユースケースには HyperPod または Nova Forge を HyperPod で活用して卒業してください。この柔軟なアーキテクチャにより、現在の要件に合わせた複雑さのレベルで RFT を実装でき、要件が成長するにつれて明確な次のステップを提供します。
強化学習微調整(RFT)への体系的アプローチ
強化学習微調整(RFT: Reinforcement Fine-Tuning)は、構造化された報酬ベースの学習反復を通じて、事前学習済みモデルを段階的に改善します。以下に RFT を実装するための体系的なアプローチを示します。
##
ステップ 0:ベースライン性能の評価
RFT を開始する前に、モデルが最低限許容できるレベルで動作しているか評価してください。RFT では、トレーニング中に複数の試行のうち少なくとも一つの正しい解をモデルが生み出すことが必要です。
重要な要件: グループ相対ポリシーは、効果的に学習するために複数のロールアウト(通常、プロンプトあたり 4〜8 回の生成)全体で結果の多様性を必要とします。モデルは、少なくとも 1 つの成功または 1 つの失敗が試行の中に含まれている必要があります。これにより、強化学習のために正例と負例を区別できるようになります。すべてのロールアウトが一貫して失敗する場合、モデルには学習するための正のシグナルが存在せず、RFT(Reinforcement Fine-Tuning:強化学習微調整)は効果的ではなくなります。そのような場合は、まず SFT(Supervised Fine-Tuning:教師あり微調整)を使用して基本的なタスク能力を確立してから、RFT に取り組むべきです。失敗モードが主に知識不足に起因する場合は、その場合も SFT がより効果的な出発点となり得ます。一方、失敗モードが推論の質の低さに起因する場合は、推論品質の最適化には RFT の方が適切な選択肢となります。
ステップ 1: 適切なデータセットと報酬関数の特定
モデルが生産環境で遭遇するシナリオを代表するプロンプトのデータセットを選択または作成してください。さらに重要なのは、以下の要件を満たす報酬関数を設計することです:
- 評価指標が追跡する内容を明確に反映していること:報酬関数は、生産環境で重視する品質を直接測定すべきです。
- モデルから必要なものを捉えていること:それが正しさ、効率性、スタイルの遵守、あるいはこれらの目的の組み合わせであっても構いません。
ステップ 2: デバッグと反復
トレーニングプロセス全体を通じて、トレーニング指標とモデルのロールアウトを監視する
注視すべきトレーニング指標:
- 報酬
原文を表示
Foundation models deliver impressive out-of-the-box performance for general tasks, but many organizations need models to consume their business knowledge. Model customization helps you bridge the gap between general-purpose AI and your specific business needs when building applications that require domain-specific expertise, enforcing communication styles, optimizing for specialized tasks like code generation, financial reasoning, or ensuring compliance with industry regulations. The challenge lies in how to customize effectively. Traditional supervised fine-tuning delivers results, but only if you have thousands of carefully labeled examples showing not just the correct final answer, but also the complete reasoning path to reach it. For many real-world applications, especially those tasks where multiple valid solution paths exist, creating these detailed step-by-step demonstrations can sometimes be expensive, time-consuming.
In this post, we explore reinforcement fine-tuning (RFT) for Amazon Nova models, which can be a powerful customization technique that learns through evaluation rather than imitation. We’ll cover how RFT works, when to use it versus supervised fine-tuning, real-world applications from code generation to customer service, and implementation options ranging from fully managed Amazon Bedrock to multi-turn agentic workflows with Nova Forge. You’ll also learn practical guidance on data preparation, reward function design, and best practices for achieving optimal results.
A new paradigm: Learning by evaluation rather than imitation
What if you could teach a car to not only learn all the paths on a map, but to also learn how to navigate if a wrong turn is taken? That’s the core idea behind reinforcement fine-tuning (RFT), a model customization technique we’re excited to bring to Amazon Nova models. RFT shifts the paradigm from learning by imitation to learning by evaluation. Instead of providing thousands of labeled examples, you provide prompts and define what makes a final answer correct through test cases, verifiable outcomes, or quality criteria. The model then learns to optimize those criteria through iterative feedback, discovering its own path to correct solutions.
RFT supports model customization for code generation and math reasoning by verifying outputs automatically, eliminating the need for providing detailed step by step reasoning. We made RFT available across our AI services to meet you wherever you are in your AI journey: start simple with the fully-managed experience available in Amazon Bedrock, gain more control with SageMaker Training Jobs, scale to advanced infrastructure with SageMaker HyperPod, or unlock frontier capabilities with Nova Forge for multi-turn conversations and custom reinforcement learning environments.
In December 2025, Amazon launched the Nova 2 family—Amazon’s first models with built-in reasoning capabilities. Unlike traditional models that generate responses directly, reasoning models like Nova 2 Lite engage in step-by-step problem decomposition, performing intermediate thinking steps before producing final answers. This extended thinking process mirrors how humans approach complex analytical tasks. When combined with RFT, this reasoning capability becomes particularly powerful, RFT can optimize not just what answer the model produces, but how it reasons through problems, teaching it to discover more efficient reasoning paths while reducing token usage. As of today, RFT is only supported with text-only use cases.
Real-World Use Cases
RFT excels in scenarios where you can define and verify correct outcomes, but creating detailed step-by-step solution demonstrations at scale is impractical. Below are some of the use cases, where RFT can be a good option:
- Code generation: You want code that’s not just correct, but also efficient, readable, and handles edge cases gracefully, such as qualities you can verify programmatically through test execution and performance metrics.
- Customer service: You need to evaluate whether replies are helpful, maintain your brand’s voice, and strike the right tone for each situation. These are judgment calls that can’t be reduced to simple rules but can be assessed by an AI judge trained on your communication standards.
- Other applications: Content moderation, where context and nuance matter; multi-step reasoning tasks like financial analysis or legal document review; and tool usage, where you need to teach models when and how to call APIs or query databases. In each case, you can define and verify correct outcomes programmatically, even when you can’t easily demonstrate the step-by-step reasoning process at scale.
- Exploration-heavy problems: Use cases like game playing and strategy, resource allocation, and scheduling benefit from cases where the model uses different approaches and learns from feedback.
- Limited labeled data scenarios: Use cases where limited labeled datasets are available like domain-specific applications with few expert-annotated examples, new problem domains without established solution patterns, expensive-to-label tasks (medical diagnosis, legal analysis). In these use cases, RFT helps to optimize the rewards computed from the reward functions.
How RFT Works
RFT operates through a three-stage automated process (shown in Figure 1):
Stage 1: Response generation – The actor model (the model you’re customizing) receives prompts from your training dataset and generates multiple responses per prompt—typically 4 to 8 variations. This diversity gives the system a range of responses to evaluate and learn from.
Stage 2: Reward computation – Instead of comparing responses to labeled examples, the system evaluates quality using reward functions. You have two options:
- Reinforcement learning via verifiable rewards (RLVR): Rule-based graders implemented as AWS Lambda functions, perfect for objective tasks like code execution or math problem verification where you can programmatically check correctness.
- Reinforcement learning from AI feedback (RLAIF): AI-based judges that evaluate responses based on criteria you configure, ideal for subjective tasks like assessing helpfulness, creativity, or adherence to brand voice.
Stage 3: Actor model training – The system uses the scored prompt-response pairs to train your model through a reinforcement learning algorithm, like Group Relative Policy Optimization (GRPO), optimized for language models. The model learns to maximize the probability of generating high-reward responses while minimizing low-reward responses. This iterative process continues until the model achieves your desired performance.
Figure 1: Illustration of how single pass of RFT works
Key Benefits of RFT
The following are the key benefits of RFT:
- No massive, labeled datasets required – RFT only needs prompts and a way to evaluate quality. If using Bedrock RFT, you can even leverage existing Bedrock API invocation logs as RFT data, eliminating the need for specially created datasets.
- Optimized for verifiable outcomes – Unlike supervised fine-tuning that requires explicit demonstrations of how to reach correct answers, RFT is optimized for tasks where you can define and verify correct outcomes, but multiple valid reasoning paths may exist.
- Reduced token usage – By optimizing the model’s reasoning process, RFT can reduce the number of tokens required to accomplish a task, lowering both cost and latency in production.
- Secure and monitored – Your proprietary data never leaves AWS’s secure environment during the customization process, and you get real-time monitoring of training metrics to track progress and ensure quality.
Implementation tiers: From simple to complex
Amazon offers multiple implementation paths for reinforcement fine-tuning with Nova models, ranging from fully managed experiences to customizable infrastructure. By following this tiered approach you can match your RFT implementation to your specific needs, technical expertise, and desired level of control.
Amazon Bedrock
Amazon Bedrock provides an entry point to RFT with a fully managed experience that requires minimal ML expertise. Through the Amazon Bedrock console or API, you can upload your training prompts, configure your reward function as an AWS Lambda, and launch your reinforcement fine-tuning job with just a few clicks. Bedrock handles all infrastructure provisioning, training orchestration, and model deployment automatically. This approach works well for straightforward use cases where you need to optimize specific criteria without managing infrastructure. The simplified workflow makes RFT accessible to teams without dedicated ML engineers while still delivering powerful customization capabilities. Bedrock RFT supports both RLVR (rule-based rewards) and RLAIF (AI-based feedback) approaches, with built-in monitoring and evaluation tools to track your model’s improvement. To get started, see the Amazon Nova RFT GitHub repository.
SageMaker Training Jobs
For teams that need more control over the training process, Amazon SageMaker Training Jobs offer a flexible middle ground with managed compute and ability to tweak multiple hyperparameters. You can also save intermediate checkpoints and use them to create iterative training workflows like chaining supervised fine-tuning (SFT) and RFT jobs to progressively refine your model. You have the flexibility to choose between LoRA and full-rank training approaches, with full control over hyperparameters. For deployment, you can choose between Amazon Bedrock for fully managed inference or Amazon SageMaker endpoints where you control instance types, batching, and performance tuning. This tier is ideal for ML engineers and data scientists who need customization beyond Amazon Bedrock but don’t require dedicated infrastructure. SageMaker Training Jobs also integrate seamlessly with the broader Amazon SageMaker AI ecosystem for experiment tracking, model registry, and deployment pipelines. Amazon Nova RFT on SageMaker Training Job uses YAML recipe files to configure training jobs. You can obtain base recipes from the SageMaker HyperPod recipes repository.
Best practices:
- Data format: Use JSONL format with one JSON object per line.
- Reference answers: Include ground truth values that your reward function will compare against model predictions.
- Start small: Begin with 100 examples to validate your approach before scaling.
- Custom fields: Add any metadata your reward function needs for evaluation.
- Reward Function: Design for speed and scalability using AWS Lambda.
- To get started with Amazon Nova RFT job on Amazon SageMaker Training Jobs, see the SFT and RFT notebooks.
SageMaker HyperPod
SageMaker HyperPod delivers enterprise-grade infrastructure for large-scale RFT workloads with persistent Kubernetes-based clusters optimized for distributed training. This tier builds on all the features available in SageMaker Training Jobs—including checkpoint management, iterative training workflows, LoRA and full-rank training options, and flexible deployment— on a much larger scale with dedicated compute resources and specialized networking configurations. The RFT implementation in HyperPod is optimized for higher throughput and faster convergence through state-of-the-art asynchronous reinforcement learning algorithms, where inference servers and training servers work independently at full speed. These algorithms account for this asynchrony and implement cutting-edge techniques used to train foundation models. HyperPod also provides advanced data filters that give you granular control over the training process and reduce the chances of crashes. You gain granular control over hyperparameters to maximize throughput and performance. HyperPod is designed for ML platform teams and research organizations that need to push the boundaries of RFT at scale. Amazon Nova RFT uses YAML recipe files to configure training jobs. You can obtain base recipes from the SageMaker HyperPod recipes repository.
- For more information, see the RFT based evaluation to get started with Amazon Nova RFT job on Amazon SageMaker HyperPod.
Nova Forge
Nova Forge provides advanced reinforcement feedback training capabilities designed for AI research teams and practitioners in building sophisticated agentic applications. By breaking free from single-turn interaction and Lambda timeout constraints, Nova Forge enables complex, multi-turn workflows with custom-scaled environments running in your own VPC. This architecture gives you complete control over trajectory generation, reward functions, and direct interaction with training and inference servers capabilities essential for frontier AI applications that standard RFT tiers cannot support. Nova Forge uses Amazon SageMaker HyperPod as the training platform along with providing other features such as data mixing with the Amazon Nova curated datasets along with intermediate checkpoints.
Key Features:
- Multi-turn conversation support
- Reward functions with >15-minute execution time
- Additional algorithms and tuning options
- Custom training recipe modifications
- State-of-the-art AI techniques
Each tier in this progression builds on the previous one, offering a natural growth path as your RFT needs to evolve. Start with Amazon Bedrock for initial experiments, move to SageMaker Training Jobs as you refine your approach, and graduate to HyperPod or Nova Forge using HyperPod for specialized use cases. This flexible architecture ensures you can implement RFT at the level of complexity that matches your current needs while providing a clear path forward as those needs grow.
Systematic approach to reinforcement fine-tuning (RFT)
Reinforcement fine-tuning (RFT) progressively improves pre-trained models through structured, reward-based learning iterations. The following is a systematic approach to implementing RFT.
###
Step 0: Evaluate baseline performance
Before starting RFT, evaluate whether your model performs at a minimally acceptable level. RFT requires that the model can produce at least one correct solution among several attempts during training.
Key requirement: Group relative policies require outcome diversity across multiple rollouts (typically 4-8 generations per prompt) to learn effectively. The model needs at least one success or at least one failure among the attempts so it can distinguish between positive and negative examples for reinforcement. If all rollouts consistently fail, the model has no positive signal to learn from, making RFT ineffective. In such cases, you should first use supervised fine-tuning (SFT) to establish basic task capabilities before attempting RFT. In cases where the failure modes are primarily due to lack of knowledge, in those cases as well SFT might be more effective starting point, whereas if the failure modes are due to poor reasoning, then RFT might be a better option to optimize on reasoning quality.
Step 1: Identify the right dataset and reward function
Select or create a dataset of prompts that represent the scenarios your model will encounter in production. More importantly, design a reward function that:
- Crisply follows what your evaluation metrics track: Your reward function should directly measure the same qualities you care about in production.
- Captures what you need from the model: Whether that’s correctness, efficiency, style adherence, or a combination of objectives.
Step 2: Debug and iterate
Monitor training metrics and model rollouts throughout the training process
Training metrics to watch:
Reward
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み