Amazon Bedrock を活用した貨物物流向けバイリンガル NER の構築
IBS Software は Amazon Bedrock のモデル蒸留機能を活用し、英語と日本語の二言語対応貨物物流 NER システムを構築して、95% 以上の精度を維持しながら運用コストを 14 倍削減しました。
キーポイント
モデル蒸留によるコスト削減と高精度化
Amazon Nova Pro から Amazon Nova Lite へ知識を蒸留することで、F1 スコア 95.085% を維持しつつ、運用コストを 14 倍削減することに成功しました。
二言語対応の複雑なエンティティ抽出
英語と日本語の貨物物流メールから、AWB 番号、フライト詳細、重量、配送指示など 23 種類の異なるエンティティをリアルタイムで正確に抽出するシステムを実現しました。
実運用における課題解決
従来の手動介入やオープンソース実装の限界に対し、スケーラブルかつ低遅延な AWS 上の生産環境ソリューションを提供し、業務効率を劇的に改善しました。
カスタムモデルによる多様なエンティティ抽出
Amazon Bedrock のカスタムモデルを使用して、航空運送証番号や重量、荷主など物流分野に特化した14種類以上のエンティティを同時に抽出可能である。
動的なタスク定義による柔軟性
API リクエスト内で 'taskType' と 'entityTypes' を指定することで、特定の業務要件に合わせて抽出対象のエンティティタイプを柔軟に切り替えて処理できる。
コスト削減と性能維持
Amazon Bedrock の管理型知識蒸留機能により、運用コストを14倍削減しながら、教師モデルの98%のパフォーマンスを維持するバイリンガルNERシステムを構築しました。
処理速度と精度の実証
AWS Lambda と Amazon S3 を活用したパイプラインにより、メールメッセージの処理が2秒未満で完了し、F1 スコア95.085%という高い精度を実現しています。
影響分析・編集コメントを表示
影響分析
この事例は、大規模言語モデルの運用コストが高いという課題に対し、モデル蒸留技術によって「精度」と「経済性」の両立を実現する具体的な実証例を提供しています。特に二言語対応や多様なエンティティ抽出といった複雑な業務要件においても、クラウドネイティブな AI 活用が即座に生産性を向上させる可能性を示しており、物流業界における AI 導入の標準的なアプローチの一つとして定着する可能性があります。
編集コメント
モデル蒸留技術の実証事例として、コスト削減と精度維持の両立という AI 実装における最大の課題に対する解決策を明確に示しており、実務家にとって非常に参考になるケーススタディです。
IBS Software の Cargo システムは、毎日数千通の二言語対応(英語・日本語)の貨物物流関連メールを処理しています。このシステムでは、航空運送状 (AWB) 番号、フライト詳細、重量、配送指示といった重要な情報を、英語と日本語の両方から抽出します。これにより、堅牢な名前付きエンティティ認識 (Named Entity Recognition: NER) ソリューションを構築する際の複雑さが増大しました。課題としては、業務を遅らせる手動介入が必要であったこと、および精度とコストのトレードオフが挙げられます。IBS Software は、2 つの言語にわたる 23 種類の異なるエンティティタイプを正確に特定できつつ、スケールしても費用対効果の高い AI ソリューションを必要としていました。
複数のアプローチを検討した結果、IBS Software は Amazon Bedrock の管理された知識蒸留 (distillation) 機能を活用し、本番環境で即座に使用可能なソリューションを作成しました。Amazon Nova Pro から得た知識を、より効率的な Amazon Nova Lite モデルへ蒸留することで、IBS Software は運用コストを 14 倍削減しながら、F1 スコア精度で 95.085% を達成しました。本ケーススタディでは、複雑なオープンソース実装に直面していた段階から、貨物メールメッセージをリアルタイムで処理する AWS 上での成功したデプロイに至るまでの道のりを詳しく解説します。
本稿では、トークンベースの知識蒸留(knowledge distillation)を用いた技術的アプローチ、教訓、およびデプロイメントアーキテクチャについて共有します。同様の二言語 NER(Named Entity Recognition:固有表現認識)課題に直面している場合は、IBS Software の Amazon Bedrock における知識蒸留機能の活用経験から有益な知見を得られるでしょう。
ソリューションの概要
目標は、英語と日本語で書かれた貨物物流関連のメールメッセージから 23 のエンティティタイプを抽出できる二言語 NER システムを構築することでした。主要なエンティティには以下が含まれます:
- AWB(Air Waybill)番号。
- フライト番号およびルート。
- 重量(総重量、課税重量、体積換算重量)。
- 寸法および容積。
- 商品説明。
- 荷主および受取人の情報。
- 特別取扱コード。
- 配送指示。
主なリスクとしては、両言語における高精度の維持、大規模運用時の推論コスト管理、リアルタイム処理のための低レイテンシの実現が挙げられます。Amazon Bedrock のモデル蒸留機能を活用することで、より小型で高速かつ費用対効果の高いモデルを使用できます。これらのモデルは、Amazon Bedrock 内で最も先進的なモデルと同等の精度を、特定のユースケースにおいて提供します。
以下の図は、Amazon Bedrock 上のエンドツーエンドの二言語 NER ワークフローを示しています。
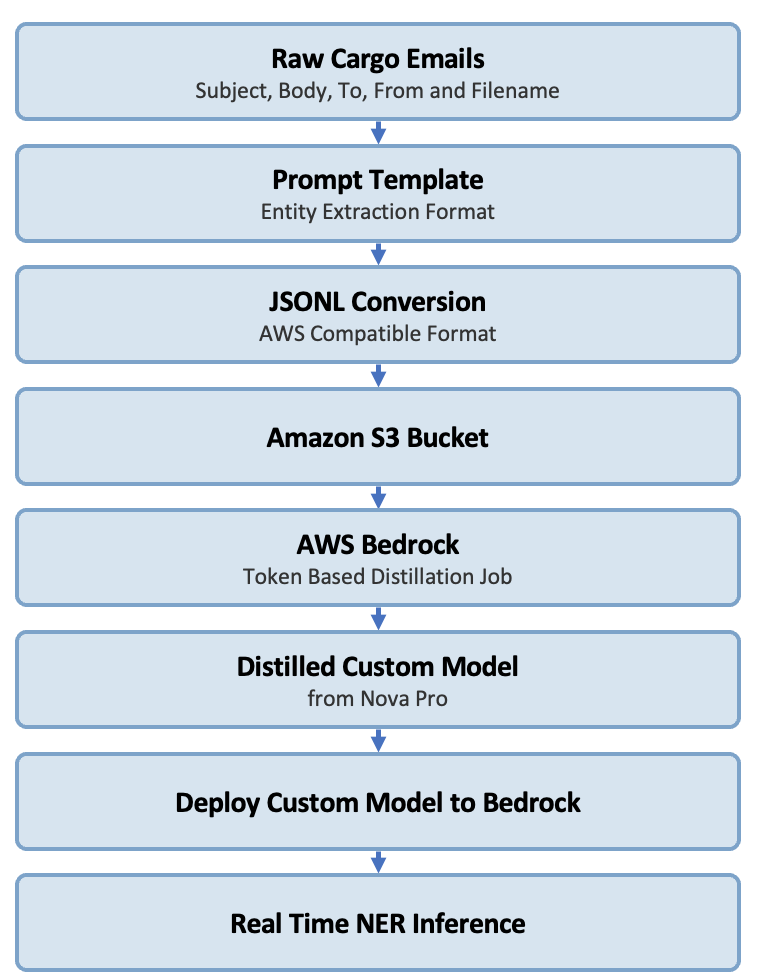
*図 1: Amazon Bedrock 上のエンドツーエンドの二言語 NER ワークフロー*
ソリューション
IBS のチームには研究者とエンジニアが9名在籍し、このソリューションの開発と導入に約4ヶ月を要しました。プロジェクトのタイムラインは以下の通りです。
- 1 ヶ月目:500 通の二言語メールのデータセット準備および注釈付け。
- 2 ヶ月目:オープンソースフレームワーク(PyTorch、TextBrewer)における課題。
- 3 ヶ月目:Amazon Bedrock を用いた成功した知識蒸留(Nova Pro → Nova Lite)。
- 4 ヶ月目:本番環境への展開と最適化。
完了した主要タスク:
- 23 のエンティティタイプを含む、500 通の貨物関連メール(英語 350 通、日本語 150 通)に注釈を付与。
- カスタムハイパーパラメータを用いた Amazon Bedrock による知識蒸留の設定。
- スチューデントモデルを 4 エポック、70 ステップでトレーニング。
- ロスを 0.05 から 0.008 に削減することに成功。
- .eml ファイル処理パイプラインを備えた推論エンドポイントの展開。
- テストセットにおいて F1 スコア 95.085 パーセントを達成。
IBS Software は、すべてのインフラストラクチャを Amazon Bedrock のマネージドサービスを使用してデプロイしました。これにより、カスタムモデルホスティングインフラの必要性が回避されました。
オープンソースアプローチにおける課題
当初、チームは PyTorch ベースの実装や TextBrewer ライブラリを含むオープンソースフレームワークを用いた知識蒸留を試みました。しかし、以下の理由によりこれらのアプローチは失敗しました。
- 二言語データに対する蒸留パイプラインの構成における複雑さ。
- 学習および展開のための管理されたインフラストラクチャの欠如。
- トークンレベルの蒸留におけるハイパーパラメータの調整の難しさ。
- 本番環境でのメール処理ワークフローとの互換性の欠如。
知識蒸留の基礎に関する詳細は、AWS Machine Learning Best Practices をご覧ください。
Amazon Bedrock の蒸留アプローチ
私たちは、教師モデルに Amazon Nova Pro を、生徒モデルに Nova Lite を用いた Amazon Bedrock Model Distillation へと方針を転換しました。主な利点は以下の通りです:
- 自動ハイパーパラメータ最適化機能を備えた管理された学習インフラストラクチャ。
- トークンレベルの蒸留に対するネイティブサポート。
- メール処理パイプラインとの統合の容易さ。
- 組み込みのモニタリングおよび評価指標。
トレーニング設定:
distillation_config = {
"teacher_model": "amazon.nova-pro-v1:0",
"student_model": "amazon.nova-lite-v1:0",
"max_sequence_length": 2048,
"epochs": 4,
"training_steps": 70,
"loss_function": "token_level_kl_divergence"
}トレーニングプロセスでは、70 ステップを経て損失が 0.05 から 0.008 に減少し、教師モデルから生徒モデルへの強力な知識転移が行われたことを示しています。
Amazon Bedrock の蒸留に関するドキュメントについては、Customize a model with distillation in Amazon Bedrock をご覧ください。
データセットの準備
当社のデータセットは、500 通の実世界の貨物物流関連メールメッセージで構成されています:
- 英語メール 350 通:航空運送状(AWB)番号、フライト詳細、重量、取扱指示を含む標準的な貨物書類。
- 日本語メール 150 通:同様の内容だが、日本固有の書式と用語を使用しているもの。
各メールメッセージは、貨物物流用語に精通したドメイン専門家によって 23 のエンティティタイプに対して手動で注釈付けされました。この注釈付けプロセスには約 3 週間を要し、両言語向けの高品質なトレーニングデータを供給しました。
モデル評価
教師モデルと学生モデルの双方を、精度(precision)と再現率(recall)の調和平均である F1 スコアを用いて評価しました:
結果:
ベースラインとなる Nova Lite モデルは全体で約 84 パーセントの F1 スコアを提供していましたが、教師モデルとカスタマイズされた Nova Lite モデルでは精度が約 10 ポイント向上しました。以下の表に F1 スコアの結果を示します。
モデル
全体 F1 スコア
英語 F1 スコア
日本語 F1 スコア
Nova Pro (教師)
97.0%
97.8%
96.2%
Nova Lite (学生)
95.085%
96.535%
93.635%
蒸留された Nova Lite モデルは、教師モデルのパフォーマンスの 98 パーセントを維持しつつ、本番環境での推論コストを 14 倍削減しました。
エラー分析と課題
学生モデルは、英語テキストと比較して日本語テキストにおいて F1 スコアが 2.565% 低いことを確認しました。この差は主に、商品説明における複雑な漢字の組み合わせ、スペースのない日本語テキストにおける曖昧なエンティティ境界、そして日本語のトレーニングデータ量の少なさ(メールメッセージ数で 150 件対 350 件)に起因しています。また、埋め込まれたエンティティを含む複数行の配送指示が、境界検出エラーを引き起こす場合もありました。
これらの課題に対処するため、合成例を用いて日本語のトレーニングデータを拡張しました。さらに、既知のエンティティパターン(AWB 形式、フライト番号の正規表現)に対する後処理ルールを適用し、信頼度の低い予測を人間によるレビュー対象としてフラグを立てるための閾値処理を実装しました。
デプロイメントワークフロー
注意: 以下のデプロイにより、課金が発生する AWS リソースが作成されます。Amazon Simple Storage Service (Amazon S3) のストレージ、AWS Lambda の呼び出し、Amazon Bedrock モデルの推論、および Amazon DynamoDB のストレージにはすべて関連コストがかかります。継続的な課金を避けるために、不要になった時点でこれらのリソースを削除してください。
本番環境でのデプロイメントでは、.eml ファイルを以下のワークフローを通じて処理します:
- メール取り込み:貨物関連のメールメッセージは、Amazon S3 に .eml ファイルとして届きます。
- 前処理:AWS Lambda がメール本文とメタデータを抽出します。
- 推論:Amazon Bedrock エンドポイントが、軽量化された Nova Lite モデルを使用してテキストを処理します。
- エンティティ抽出:モデルは 23 のエンティティタイプ(entity types)と信頼度スコアを返します。
- 後処理:検証ルールと信頼度フィルタリングが適用されます。
- 出力:抽出されたエンティティを含む構造化 JSON が Amazon DynamoDB に保存されます。
import boto3
import json
bedrock_runtime = boto3.client('bedrock-runtime')
def extract_entities(email_text):
response = bedrock_runtime.invoke_model(
modelId='',
body=json.dumps({
"inputText": email_text,
"taskType": "NER",
"entityTypes": [
"AWB_NUMBER", "FLIGHT_NUMBER", "WEIGHT_GROSS",
"WEIGHT_CHARGEABLE", "DIMENSIONS", "COMMODITY",
"SHIPPER", "CONSIGNEE", "HANDLING_CODE",
# ... 14 more entity types
]
})
)
result = json.loads(response['body'].read())
return result['entities']
Lambda の統合パターンについては、Amazon Bedrock を使用した AWS Lambda を参照してください。
このパイプライン全体は、95.085 パーセントの精度で 2 秒未満でメールメッセージを処理し、リアルタイム処理要件を満たしています。
結論
本記事では、IBS Software が Amazon Bedrock の管理された蒸留機能を活用し、貨物物流向けにコスト効率の高い二言語 NER(名前付きエンティティ認識)システムを構築した事例をご紹介しました。このシステムは F1 スコアで 95.085 パーセントを達成しながら、運用コストを 14 倍削減することに成功しています。蒸留された Nova Lite モデルは、教師モデルの性能の 98 パーセントを維持しており、高ボリュームの生産環境でのワークロードに理想的です。
私たちが得た重要な教訓は、Amazon Bedrock の管理された蒸留機能がオープンソースフレームワークが抱える複雑さを軽減してくれた点にあります。トークンレベルでの知識蒸留により、英語と日本語の両方で精度を維持することができ、2048 トークンのシーケンス長は一般的な貨物メールの長さに対応しています。AWS Lambda と Amazon S3 の統合による本番環境へのデプロイでは、最小限のカスタムインフラストラクチャで済みました。
次のステップ:
同様の二言語 NER の課題に直面している場合は、以下の点を検討してください:
- 迅速なプロトタイピングのために、Amazon Bedrock のオンデマンド基盤モデルから始める。
- 高品質な二言語トレーニングデータの注釈付けに投資する。
- トレーニングデータセットを用いたモデル蒸留を検討する。モデル蒸留の制限事項の一つとして、教師モデルと生徒モデルは同じモデルファミリー内に存在しなければならないという点があります。
本記事で議論されたトピックの詳細については、以下のリソースをご覧ください:
- Amazon Bedrock モデル蒸留のガイド
- Amazon Bedrock における Claude ツール使用によるカスタムエンティティ認識の加速
- オープンソース NER モデルと LLM を用いた AI 駆動型ドキュメント処理プラットフォームの構築(Amazon SageMaker AI)
ご自身のカスタスケースでバイリンガル NER や知識蒸留に取り組んでいる場合は、その経験をぜひお聞かせください。コメント欄でご質問やフィードバックをお寄せください。
著者について
Manu Raj L S
Manu は IBS Software のデータサイエンス部門におけるシニアコンサルタントです。
Joshwin Lal Tennyson J S
Joshwin は IBS Software のリード AI エンジニアです。
Basil K
Basil は IBS Software のリードプロダクトアーキテクトです。
Madhukiran J
Madhukiran は AWS Enterprise Support のシニアテクニカルアカウントマネージャーです。Bedrock、AgentCore、SageMaker などの AWS サービスを活用して革新的なソリューションを構築するエンタープライズ顧客をサポートしています。専門分野は機械学習、生成 AI、コンテナ(Amazon EKS、Amazon ECS)です。
原文を表示
IBS Software’s Cargo system processes thousands of bilingual cargo logistics email messages daily. The system extracts critical information such as air waybill (AWB) numbers, flight details, weights, and delivery instructions in both English and Japanese. This added to the complexity of building a robust Named Entity Recognition (NER) solution. Challenges included manual intervention that slowed operations and a trade-off between accuracy and cost. IBS Software needed an AI solution that could accurately identify 23 different entity types across two languages while remaining cost-effective at scale.
After exploring multiple approaches, IBS Software used managed distillation capabilities of Amazon Bedrock to create a production-ready solution. By distilling knowledge from Amazon Nova Pro into the more efficient Amazon Nova Lite model, IBS Software achieved 95.085 percent F1-Score accuracy while reducing operational costs by 14x. This case study details their journey from facing complex open-source implementations to a successful deployment on AWS that now processes cargo email messages in real time.
In this post, we share the technical approach using token-based distillation, lessons learned, and deployment architecture. If you face similar bilingual NER challenges, you can benefit from IBS Software’s experience with the Amazon Bedrock knowledge distillation capabilities.
Overview of solution
The goal was to build a bilingual NER system capable of extracting 23 entity types from cargo logistics email messages written in English and Japanese. The key entities include:
- AWB (Air Waybill) numbers.
- Flight numbers and routes.
- Weights (gross, chargeable, dimensional).
- Dimensions and volume.
- Commodity descriptions.
- Shipper and consignee information.
- Special handling codes.
- Delivery instructions.
The primary risks included maintaining high accuracy across both languages, managing inference costs at scale, and achieving low latency for real-time processing. With the model distillation capabilities of Amazon Bedrock, you can use smaller, faster, and more cost-effective models. These models deliver accuracy for your use case that is comparable to the most advanced models in Amazon Bedrock.
The following diagram shows the end-to-end bilingual NER workflow on Amazon Bedrock.
*Figure 1: End-to-end bilingual NER workflow on Amazon Bedrock*
Solution
IBS’s team of nine researchers and engineers spent approximately 4 months developing and deploying this solution. The project timeline included:
- Month 1: Dataset preparation and annotation of 500 bilingual email messages.
- Month 2: Challenges with open-source frameworks (PyTorch, TextBrewer).
- Month 3: Successful distillation using Amazon Bedrock (Nova Pro → Nova Lite).
- Month 4: Production deployment and optimization.
Key tasks completed:
- Annotated 500 cargo email messages (350 English, 150 Japanese) with 23 entity types.
- Configured Amazon Bedrock distillation with custom hyperparameters.
- Trained student model for 4 epochs over 70 steps.
- Achieved loss reduction from 0.05 to 0.008.
- Deployed inference endpoint with .eml file processing pipeline.
- Validated 95.085 percent F1-Score on test set.
IBS Software deployed all infrastructure using Amazon Bedrock managed services, which bypassed the need for custom model hosting infrastructure.
Challenges with open-source approaches
Initially, the team attempted knowledge distillation using open-source frameworks including PyTorch-based implementations and the TextBrewer library. These approaches failed because of:
- Complexity in configuring distillation pipelines for bilingual data.
- Lack of managed infrastructure for training and deployment.
- Difficulty tuning hyperparameters for token-level distillation.
- Incompatibility with our production email processing workflow.
For more details on knowledge distillation fundamentals, see AWS Machine Learning Best Practices.
Amazon Bedrock distillation approach
We pivoted to Amazon Bedrock Model Distillation, using Amazon Nova Pro as the teacher model and Nova Lite as the student model. The key advantages included:
- Managed training infrastructure with automatic hyperparameter optimization.
- Native support for token-level distillation.
- Ease of integration with our email processing pipeline.
- Built-in monitoring and evaluation metrics.
Training configuration:
distillation_config = {
"teacher_model": "amazon.nova-pro-v1:0",
"student_model": "amazon.nova-lite-v1:0",
"max_sequence_length": 2048,
"epochs": 4,
"training_steps": 70,
"loss_function": "token_level_kl_divergence"
}The training process reduced loss from 0.05 to 0.008 over 70 steps, indicating strong knowledge transfer from teacher to student.
For Amazon Bedrock distillation documentation, see Customize a model with distillation in Amazon Bedrock.
Dataset preparation
Our dataset consisted of 500 real-world cargo logistics email messages:
- 350 English email messages: Standard cargo documentation with AWB numbers, flight details, weights, and handling instructions.
- 150 Japanese email messages: Similar content with Japanese-specific formatting and terminology.
Each email message was manually annotated for 23 entity types by domain experts familiar with cargo logistics terminology. The annotation process took approximately 3 weeks and supplied high-quality training data for both languages.
Model evaluation
We evaluated both teacher and student models using F1-Score, the harmonic mean of precision and recall:
Results:
Although the base Nova Lite model offered approximately 84 percent overall F1-Score, the teacher model and the customized Nova Lite model achieved an approximately 10 percent uplift in accuracy. The following table shows the F1-Score results.
Model
Overall F1-Score
English F1-Score
Japanese F1-Score
Nova Pro (Teacher)
97.0%
97.8%
96.2%
Nova Lite (Student)
95.085%
96.535%
93.635%
The distilled Nova Lite model retained 98 percent of the teacher’s performance while providing 14x cost reduction in production inference.
Error analysis and challenges
We observed that the student model showed a 2.565 percent lower F1-Score on Japanese text than on English text. This gap came primarily from complex kanji character combinations in commodity descriptions, ambiguous entity boundaries in Japanese text without spaces, and the smaller volume of Japanese training data (150 compared to 350 email messages). Multi-line delivery instructions with embedded entities also occasionally caused boundary detection errors.
To overcome these challenges, we augmented Japanese training data with synthetic examples. We also applied post-processing rules for known entity patterns (AWB format, flight number regex) and implemented confidence thresholding to flag low-confidence predictions for human review.
Deployment workflow
Note: The following deployment creates AWS resources that incur charges. Amazon Simple Storage Service (Amazon S3) storage, AWS Lambda invocations, Amazon Bedrock model inference, and Amazon DynamoDB storage all have associated costs. Delete these resources when you no longer need them to avoid ongoing charges.
Our production deployment processes .eml files through the following workflow:
- Email ingestion: Cargo email messages arrive as .eml files in Amazon S3.
- Preprocessing: AWS Lambda extracts email body and metadata.
- Inference: Amazon Bedrock endpoint processes text with distilled Nova Lite model.
- Entity extraction: Model returns 23 entity types with confidence scores.
- Post-processing: Validation rules and confidence filtering applied.
- Output: Structured JSON with extracted entities stored in Amazon DynamoDB.
import boto3
import json
bedrock_runtime = boto3.client('bedrock-runtime')
def extract_entities(email_text):
response = bedrock_runtime.invoke_model(
modelId='',
body=json.dumps({
"inputText": email_text,
"taskType": "NER",
"entityTypes": [
"AWB_NUMBER", "FLIGHT_NUMBER", "WEIGHT_GROSS",
"WEIGHT_CHARGEABLE", "DIMENSIONS", "COMMODITY",
"SHIPPER", "CONSIGNEE", "HANDLING_CODE",
# ... 14 more entity types
]
})
)
result = json.loads(response['body'].read())
return result['entities']For Lambda integration patterns, see AWS Lambda with Amazon Bedrock.
The entire pipeline processes email messages in under 2 seconds with 95.085 percent accuracy, meeting our real-time processing requirements.
Conclusion
In this post, we showed how IBS Software used Amazon Bedrock managed distillation capabilities to build a cost-effective bilingual NER system for cargo logistics. The system achieves 95.085 percent F1-Score while reducing operational costs by 14x. The distilled Nova Lite model retains 98 percent of the teacher model’s performance, making it ideal for high-volume production workloads.
Our key takeaway was that Amazon Bedrock managed distillation capabilities alleviated the complexity of open-source frameworks. The token-level knowledge distillation preserved accuracy across both English and Japanese, and the 2048-token sequence length accommodated typical cargo email lengths. Production deployment with AWS Lambda and Amazon S3 integration required minimal custom infrastructure.
Next steps:
If you’re facing similar bilingual NER challenges, consider:
- Start with Amazon Bedrock on-demand foundation models for rapid prototyping.
- Invest in high-quality bilingual training data annotation.
- Explore model distillation with the training dataset. One limitation of model distillation is that the teacher model and the student model must be within the same model family.
For more information about the topics discussed in this post, see the following resources:
- A guide to Amazon Bedrock Model Distillation
- Accelerating custom entity recognition with Claude tool use in Amazon Bedrock
- Build an AI-powered document processing platform with open-source NER model and LLM on Amazon SageMaker AI
If you’re working on bilingual NER or knowledge distillation for your own use case, we’d love to hear about your experience. Share your questions or feedback in the comments.
About the authors
Manu Raj L S
Manu is a Principal Consultant, Data Science at IBS Software.
Joshwin Lal Tennyson J S
Joshwin is a Lead AI Engineer at IBS Software.
Basil K
Basil is a Lead Product Architect at IBS Software.
Madhukiran J
Madhukiran is a Sr.Technical Account Manager at AWS Enterprise Support. He supports enterprise customers leverage AWS services like Bedrock, AgentCore, and SageMaker to build innovative solutions. His expertise spans Machine learning, GenAI and Containers (Amazon EKS, Amazon ECS)
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み