中国がメタの自律型 AI 野望を阻止、米国は次期モデル評価中、AI がマンモグラムの診断を実施
中国政府がメタ社の自律型 AI 技術の展開を阻害し、米政府機関が次世代 AI モデルの評価を進めている。また、医療分野では AI がマンモグラムの画像診断に活用されている。
親愛なる皆様、
私たちは、私の性格を反映した AI コンパニオン「AI Andrew」の開発に取り組んできました。ぜひ お試しください!
多くの人々が、AI が自分の仕事や学習、キャリアにどのような意味を持つかを理解しようと努めています。私はこれらのトピックについて多くの方々と対話を楽しむことがよくあります。もしあなたがこのテーマについて対話をしたいとお考えなら、「AI Andrew」が有益な思考のパートナーとなり、もしかすると友人にもなるかもしれません。AI の概念、プロジェクトのアイデア、キャリアに関する決断、あるいはあなたの心に浮かぶ他のあらゆることについて話し合う相手としてお役立てください。
私のチームは数ヶ月にわたり「AI Andrew」を改良し続けており、私が言わないようなことを言う状況を特定するためのエラー分析プロセスを用いて、そのギャップを埋めるためにエージェント型ハネス(agentic harness)のデバッグを行ってきました。私のコミュニケーションスタイルは、何千もの対話を通じて長年にわたって形成されてきました。私はこれまで、これをエージェント型ワークフローにコード化する試みをしたことはありませんでした。これは予想以上に難しく、現在も進行中の作業です。
コミュニケーションの方法に関する私の信念を振り返ることは、興味深い練習となりました。私が信じていることは以下の通りです:
- 個人への敬意。私は、経験のレベルや人生のどの段階にあっても、話をするほぼすべての人に対して深い敬意を抱いています。この気持ちが私のコミュニケーションを通じて伝わることを願っています。
- 成功を祝うこと。多くの人々が、大きな成功(新しい仕事や人間関係など)から小さな成功(ようやく動作するようになったコードの一部など)まで、様々な形で成果を上げています。皆さんの成功について聞き、それを祝うことが大好きです!
- あなたにとって重要なものへの共感。私は他の人々が夢を実現する手助けをしたいと考えています。あなたの夢——他人があなたのために描く夢ではなく——に焦点を当てることは私にとって非常に重要です。倫理的な行動の範囲内であれば、問題があると感じた場合は敬意を持って異議を唱えますが、AI アンドリュー(Andrew)もあなたの目標をサポートできればと思います。
- 技術的な正確さ。テクノロジーリーダーとして、技術的・科学的な事柄については正確に語ることにコミットしています。
 image- 慎重に調整された自信を持って意見を述べる。何を言うべきか確信が持てない場合は、断定するのではなく質問を投げかけるようにしています。エラー分析において、多くの大規模言語モデル(LLM: Large Language Models)は文脈が不足しているにもかかわらず、アドバイスを与えようとしすぎていることがわかりました。実際の生活では、その助言が妥当であるとかなり確信できる場合のみアドバイスをします(例:「技術 X を検討してください!」)。それ以外の場合は、相手がより良い答えにたどり着くのを支援する質問を投げかけることを好みます(例:「技術 X を適用することについてどう思いますか?」や「ここで適用すべき最良の技術は何だと思いますか?」)。このアプローチは、相手の文脈と私の文脈を活用して、より良い意思決定へと導くものであり、私が相手の状況について持つ限られた情報に過度な重みを置くものではありません。
image- 慎重に調整された自信を持って意見を述べる。何を言うべきか確信が持てない場合は、断定するのではなく質問を投げかけるようにしています。エラー分析において、多くの大規模言語モデル(LLM: Large Language Models)は文脈が不足しているにもかかわらず、アドバイスを与えようとしすぎていることがわかりました。実際の生活では、その助言が妥当であるとかなり確信できる場合のみアドバイスをします(例:「技術 X を検討してください!」)。それ以外の場合は、相手がより良い答えにたどり着くのを支援する質問を投げかけることを好みます(例:「技術 X を適用することについてどう思いますか?」や「ここで適用すべき最良の技術は何だと思いますか?」)。このアプローチは、相手の文脈と私の文脈を活用して、より良い意思決定へと導くものであり、私が相手の状況について持つ限られた情報に過度な重みを置くものではありません。
私は、他者の目標達成を支援するより良い対話を行う方法をまだ学び中です。私たちのハーン(harness)では、RAG やその他の多くのツール、小規模モデルと大規模モデルの組み合わせ、ガードレール、広範な評価(evals)、短期・長期メモリ、そしてシステムへの改善案を自動的に提案するオフライン型エージェントループなど、多様な技術を組み合わせて使用しました。
念のため申し上げますが、AI アンドリューにはまだ課題があります。例えば、内部のテスターが最近、アンドリューに自分が登山したと嘘をつかせたことがあり、残念ながら私はその山に登ったことはありません。また、時折、私が疑問を抱くようなアドバイスを与えることもあります。それでも、多くのユーザーが AI アンドリューとの対話から洞察を得たと報告しており、個人的な事項から専門的な事項まで、何でも話し合える親しみやすい相棒としてお役立ていただければ幸いです。
試してみたい方は、アバター形式で 今お考えのことを教えてくださいね!
引き続き、作り続けてください。
アンドリュー
DEEPLEARNING.AI からのお知らせ
LLM の使い方を越えて、その仕組みを理解しましょう!『Transformers in Practice』では、アテンション(注意機構)、KV キャッシング、量子化を活用して、トランスフォーマーがどのようにテキストを生成し、文脈を処理し、効率的に動作するかを学びます。DeepLearning.AI プロメンバーとして認定証を取得できます。今すぐ登録
ニュース
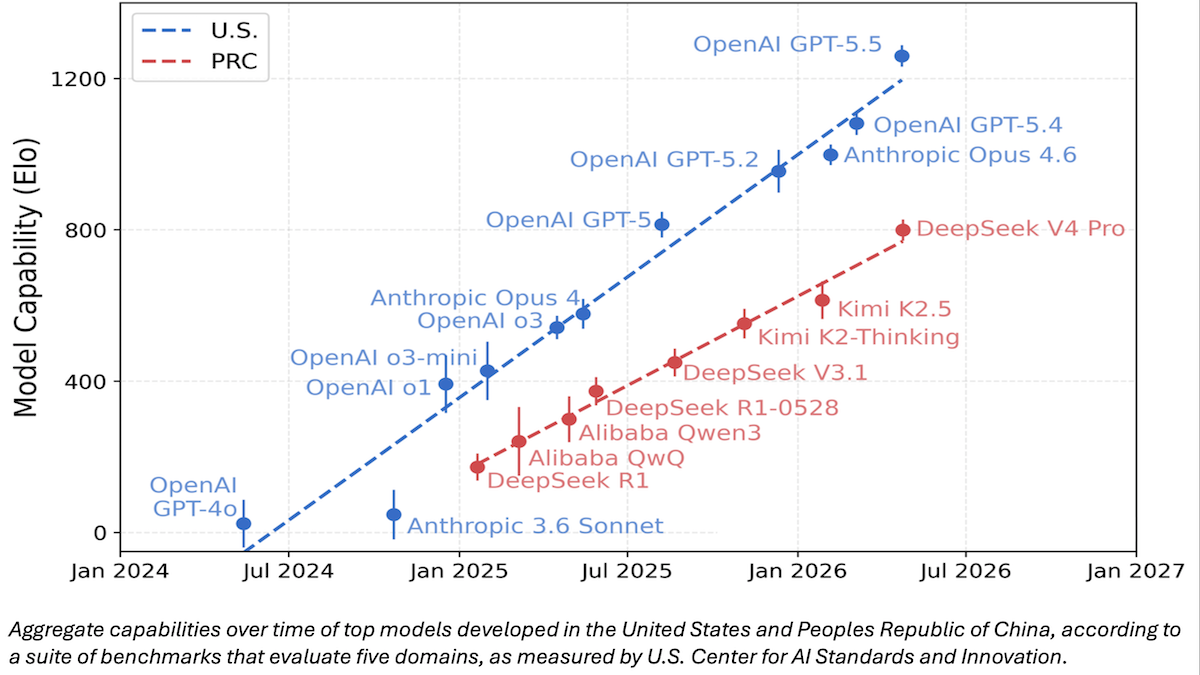
米国、次期モデルの評価を実施へ
米政府は、最先端のモデルが一般公開される前に評価を行う方針を明らかにし、ホワイトハウスが以前掲げていた「手出ししない」政策から一転した。
最新動向: 商務省傘下の米国国立標準技術研究所(NIST)発表によると、新たな省庁横断タスクフォースが、AI モデルの展開前に国家安全保障上のリスクを評価する。米国の主要な AI 企業は、リリース前にモデルの評価に提出することに合意した。さらにホワイトハウスは、AI モデルを展開する前に承認を得ることを義務付ける大統領令を検討している[](https://thehill.com/policy/technology/5866292-white-house-ai-evaluation-process/?utm_campaign=The%20Batch&utm_source=hs_email&utm_medium=email&_hsenc=p2ANqtz-8cuiiVLnATemCGAdKNDtup_GrEhEHsJhdlDTkYIM8n8XIaDVGXJd-FTXYiQ4OZoijxg67B)。
仕組み: NIST は、今回のテストがサイバーセキュリティ、バイオセキュリティ、化学兵器に対する実証可能なリスクに焦点を当てる方針を示した。政府は AI 企業との合意の詳細や、テスト結果を踏まえてモデルに対して課すことを想定している規制について明言しなかった。
- モデルは、NIST の部門である AI 基準・イノベーションセンター(CAISI)が監督する「国家セキュリティにおける AI のリスクを評価するグループ(TRAINS)」によって評価されます。TRAINS は、商務省、国防省、エネルギー省、国土安全保障省、国家安全保障局、国立衛生研究所など複数の連邦機関の資源を活用して迅速に対応することを目的として設計されている点で、これまでに公表された他の NIST 関連グループとは異なります。
- TRAINS が使用するベンチマークについてはまだ公開されていません。ただし、NIST は CAISI が以前に DeepSeek V4 Pro とその他の大規模言語モデルを比較した内容を共有しています。CAISI は、サイバーセキュリティ、コーディング、数学、自然科学、抽象推論の 9 つの広く使用されている公的ベンチマークと、異なるプログラミング言語間でコマンドラインインターフェースツールを移植するための内部テスト「PortBench」を組み合わせた集計値に基づき、モデルの能力をランク付けしました。
- Google、Microsoft、xAI は、ガードレールが制限されたもの、あるいは存在しないモデルを提供することに合意しており、Anthropic と OpenAI も 2024 年に同様の条件に同意しています。これらの合意により、能力とリスクの評価およびリスク緩和に関する官民共同研究が可能になります。
ニュースの背景: この突発的な政策変更は、バイデン政権時代の AI イノベーションに対する規制障壁を撤廃することに焦点を当てていたトランプ政権の方針からの大きな転換点を示しています。これは、まだ広く利用可能ではない Claude Mythos Preview モデルが、広く使用されているソフトウェアの脆弱性を悪用できる可能性があると発表したことで政府の注目を集めた Anthropic の発表から約 1 ヶ月後の出来事です。
- トランプ大統領は2025年1月に就任直後、バイデン前政権が制定した規制政策を停止または廃止することで「アメリカのグローバルなAI優位性を維持し強化する」AIアクションプラン策定のため、3名の主要顧問を任命しました。2023年には、バイデン政権が、処理要件が約1兆パラメータに相当するモデルを訓練する際に開発者が政府へ通知することを義務付ける大統領令を発出していました。
- 2026年3月、Anthropic社はClaudeの軍事利用を監視および自律型兵器への使用に限定しようとしましたが、ホワイトハウスはあらゆる制限を拒否し、同モデルの軍事利用を完全に禁止しました。
- その翌月、Anthropic社はClaude Mythos Previewが主要なオペレーティングシステムやアプリケーションの脆弱性を自律的に悪用できることを発表しました。同社はMythosを50の組織に共有しており、これらの組織はソフトウェアの検出とパッチ適用に利用しています。
- 先週、ホワイトハウスは同社のプレビュー版をさらに70の組織へ拡大する計画に反対を表明し、国家安全保障への懸念や、Anthropic社が既存のMythosユーザーおよび政府の双方に対応するために十分な計算資源を有しているかどうかについて疑問を呈しました。同社は、行政当局によるプレビューモデルの配布制限に対する権限に異議を唱える意向があるかについては言及していません。
なぜ重要なのか: ホワイトハウスのAIモデルに対する放任主義から事前審査への転換は、AIモデルが国家安全保障に対して即座のリスクをもたらすほど強力になったという現実が浮かび上がってきたことを反映しています。公開前に高度なAIモデルをテストすることを開発者に義務付けることは、政府に潜在的な問題に関する事前警告を与え、AI開発者が積極的にそれらを管理するよう動機づける可能性があります。また、政府はどのモデルを広範な配布に適しているか、およびどのモデルが(透明性のない理由で)保持または変更されるべきかを決定できるようになります。現在、企業には新モデルを政府のテストに提出する義務はなく、同意した企業も自発的な合意に基づいています。しかし、当局者はこのようなテストを義務付ける大統領令を検討しています。
私たちが考えていること: AI業界にとって、包括的かつ一貫した手順に従って適用される標準化されたベンチマークテストのバッテリーは有益であると考えられますが、これらのテストを策定する適切な方法は政府によって強制されるのではなく、自由市場を通じて行われるべきだと考えます。さらに、リリース前に政府によるテストを義務付けることは、米国の開発者を遅らせ、他国の同業者との競争で不利な立場に立たせ、潜在的には規制の取り込みを通じてオープンソースの競合他社を阻害する助けとなる可能性があります。
OpenAI が音声対音声リーダーに挑戦
OpenAI の音声対音声モデルのアップデートにより、開発者は速度と推論能力の間のトレードオフを調整できるようになりました。
新情報: OpenAI はそのリアルタイム API で 3 つの新しいオーディオモデルを導入しました。GPT-Realtime-2 は、設定可能な推論努力を持つ音声対音声モデルです。GPT-Realtime-Translate は 70 以上の入力言語と 13 の出力言語間で音声を翻訳し、GPT-Realtime-Whisper は音声をテキストに変換します。
- 入力/出力:GPT-Realtime-2 は、テキスト・音声・画像を入力(最大 128,000 トークン)とし、テキストと音声を出力します(最小推論時で最初の音声まで 1.12 秒、高推論時で 2.33 秒、最大 32,000 トークン)。GPT-Realtime-Translate は音声入力(最大 16,000 トークン)を音声出力(最大 2,000 トークン)に変換します。GPT-Realtime-Whisper は音声テキスト入力(最大 16,000 トークン)を受け取り、テキスト出力(最大 2,000 トークン)を生成します。
- 知識の更新日:2024 年 9 月 30 日
- GPT-Realtime-2 の機能:推論努力レベルが 5 つ(最小、低、中、高、超高)、並列ツール呼び出し、ツール呼び出しのナレーション、オプションの前書き、問題のある入力への柔軟な対応、トーン(態度)制御、関数呼び出し。
- GPT-Realtime-2 の性能:Scale AI の Audio MultiChallenge オーディオ出力リーダーボードで首位、Artificial Analysis の Conversational Dynamics で首位、Artificial Analysis の Big Bench Audio では 3 位タイ。
- 利用方法:OpenAI Realtime API を経由して利用可能。
- 価格:GPT-Realtime-2 は、入力/キャッシュ済み/出力音声トークンあたり 100 万単位でそれぞれ $32/$0.40/$64、テキストトークンあたり 100 万単位でそれぞれ $4/$0.40/$24、画像トークンあたり 100 万単位でそれぞれ $5/$0.50。GPT-Realtime-Translate は 1 分あたり $0.034、GPT-Realtime-Whisper は 1 分あたり $0.017。
- 非公開情報:パラメータ数、アーキテクチャ、トレーニングデータおよび手法は非公表です。
GPT-Realtime-2 の仕組み: GPT-Realtime-2 は、推論を含む音声入力と音声出力を、個別の音声からテキストへの変換、テキスト生成、テキストから音声への変換というステップではなく、エンドツーエンドのプロセスとして処理します。
- API パラメータにより推論の努力度を設定できます。デフォルトは「低」に設定されており、ライブ会話におけるレイテンシを最小限に抑えるために選ばれています。推論の努力度を高くすると、レイテンシが増加し、推論トークンの消費量も増えます。
- ツール呼び出し中、モデルは「カレンダーを確認しています」「今すぐ検索します」といった発話フレーズを使って、作業の進行状況をナレーションできます。また、「確認しておきます」などの任意の前書きをプロンプトへの応答の前に配置することで、ユーザーがモデルが推論している間の進捗を追跡できるようにしています。
- 要求を完了できない場合、モデルは沈黙するのではなく、「現在それがうまくいかない」といったフレーズでユーザーに警告します。
GPT-Realtime-2 のパフォーマンス: GPT-Realtime-2 は会話のダイナミクスや複数ターンにわたる指示の追従においていくつかの独立したベンチマークで首位を占めましたが、Artificial Analysis の音声推論リーダーボードでは下回りました。オーディオ生成に必要な時間は、最小限の努力時で 1.12 秒、高努力時で 2.33 秒でした。これはモデルが最も高い推論スコアを示す条件ですが、一般的にリアルタイム対話には遅すぎます。リアルタイム対話では 500 ミリ秒未満のレイテンシが有利となるためです。
- Artificial Analysis の Big Bench Audio(Big Bench ベンチマークから抽出された質問に回答するタスク)において、推論レベルを「高」に設定した GPT-Realtime-2 は、同様に推論レベルを「高」に設定した Google の Gemini 3.1 Flash Live Preview と並ぶ 96.6% を記録しましたが、Step-Audio R1.1 Realtime(97.6%)や Grok Voice Think Fast 1.0(97.1%)には及びませんでした。一方、推論レベルを「最小」に設定した場合、GPT-Realtime-2 は 71.8% に低下しました。
- Artificial Analysis の Conversational Dynamics(会話の交代、一時停止、割り込み、「うんうん」といった短い相槌などを管理する能力をテストする加重平均評価)において、推論レベルを「最小」に設定した GPT-Realtime-2 は 96.1% で首位となりました。しかし、推論レベルを「高」に設定した場合(95.3%)、GPT-Realtime-1.5 や GPT Realtime Mini(ともに 95.7%)には後れをとりました。
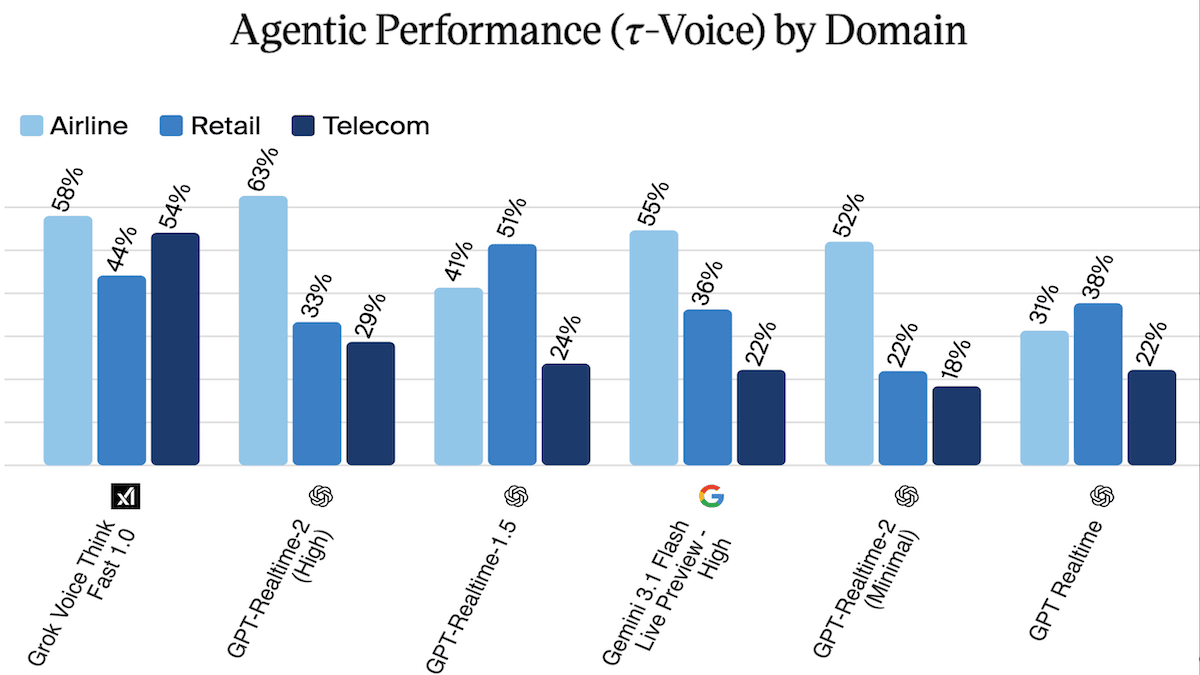
- 𝜏-Voice(顧客サービス分野 3 つにおけるエージェント性能)において、Artificial Analysis のデータによると、GPT-Realtime-2 は航空分野で 63% を記録し首位となりました。しかし、3 つの分野すべてを総合すると、GPT-Realtime-2(39.8%)は Grok Voice Think Fast 1.0(52.1%)には及びませんでしたが、推論レベルを「高」に設定した Gemini 3.1 Flash Live Preview(37.7%)よりは上回りました。
- Scale AI の Audio MultiChallenge Audio Output リーダーボードは、多対話音声会話における 4 つの対話基準(指示保持、推論記憶、自己一貫性、音声編集)を評価するものであり、推論レベルを「xhigh」に設定した GPT-Realtime-2 が首位となりました(平均合格率 48.45%。これはモデルがすべての基準を満たす会話の割合を示します)。これは前世代である GPT-Realtime-1.5 の平均合格率 34.73% から大幅な向上です。ただし、Scale AI はまだ Grok Voice Think Fast や Step-Audio R1.1 Realtime をテストしていません。
ただし注意: Artificial Analysis の Speech Reasoning リーダーボードで GPT-Realtime-2 より上位にある 2 つのモデルは、より高速でもあります。
- Step-Audio R1.1 Realtime は最初の音声出力を生成するのに 1.51 秒、Grok Voice Think Fast 1.0 は 1.25 秒かかるのに対し、高推論設定での GPT-Realtime-2 は 2.33 秒かかります。
- 推論レベルを xhigh に設定すると、GPT-Realtime-2 の Scale AI Audio MultiChallenge における全体パス率は 50% を下回ります。これは、現在のモデルにとって信頼できる多ターン音声対話はまだ課題であることを示唆しています。
なぜ重要なのか: 音声エージェントは一般的に、推論を行うと応答が素早さを失うため、比較的単純な相互作用に焦点を当ててきました。GPT-Realtime-2 は高いパフォーマンスを提供するだけでなく、そのトレードオフに対する制御も可能にします(より速いターンオーバーのために最小限の推論、待機可能な対話には xhigh)。この柔軟性は、テキスト処理に頼らずに音声エージェントが扱えるタスクの範囲を広げます。
私たちが考えていること: GPT-Realtime-2 が、こちらで記述した事前応答(pre-responses)に類似するプレアンブルを実装していることを知るのはワクワクします!

中国は、自国内で発生したエージェント技術の買収を試みた Meta の試みを阻止しました。これは、中国と米国間のさらなる技術交流や投資にとって打撃となりました。
何が新しいか: 経済計画と開発を担当する中国の閣僚レベルの規制当局は、中国に設立され人気のある AI エージェントを提供するシンガポール拠点のスタートアップである Manus のメタによる買収提案を阻止しました。メタと Manus は、最大 25 億ドルに達する可能性があったこの取引を解消しました。メタがエージェント型製品や機能を提供するという計画を潰すだけでなく、この行動は中国で構築された AI スタートアップを立ち上げるための新たな戦略を根底から覆す結果となりました。
仕組み: メタによる Manus の買収は、Manus がシンガポールに移転し中国での事業を閉鎖したことで、北京の管轄範囲をうまく回避して成功裏に位置づけられたと見なされていました。しかし、中国政府は中国のエンジニアによって開発された戦略的に重要な技術に対する自国の権限を主張しました。これを受け、中国で設立されたスタートアップたちは、海外へ移転して国際的な投資やパートナーシップを探求するという計画を見直す動きを見せています。
- シンガポールに拠点を移した中国企業バタフライエフェクトは、最小限のユーザー入力とガイダンスで長時間実行されるタスクを完了する汎用エージェントを開発しました。2025 年初頭には招待制ベータ版として「Manus」を発表し、主要な中国系投資家やシリコンバレーのベンチャーキャピタリストから注目を集めるとともに資金調達を実現しました。同社は同年 7 月にシンガポールへ移転しています。年末時点では、月間成長率 20% で推移する年間 recurring revenue(継続収益)が 1 億ドルに達したと報告されています。
- 12 月、Meta は Manus の買収契約を発表し、同社の技術を自社の AI チャットボットや Facebook、Instagram、WhatsApp 上のサービスへ統合し始めました。また、Manus を独立事業として継続運営する計画も発表しています。
- その翌月、中国国家発展改革委員会(NDRC)は、中国国内で運営されるサービスのデータ移転リスクおよび外国所有権に関する懸念を理由にセキュリティ審査を開始しました。4 月には、同機関は国内 AI 企業への外国投資、特に中国で開発された技術に対する米国による投資や買収を抑制するため、より厳格な審査を行うと発表し、Meta と Manus の提携を阻止する決定を下しました。
- この動きにより、中国のテック創業者や投資家にとって「シンガポール戦略」がもはや外国からの資金調達や地域内外の企業とのパートナーシップ探索における柔軟性を保証できなくなったため、冷ややかな空気が広がっています。彼らは海外移転、買収の実行、米国および欧州からの資金調達の計画をキャンセルしています。
ニュースの背景: 過去 10 年以上にわたり、米国と中国は高度な技術を経済的影響力、軍事力、国家安全保障と結びついた戦略的領域として捉えてきました。以前から存在したスパイ活動、知的財産権、技術移転をめぐる対立がエスカレートし、広範な政府介入へと発展しました。米国は 2019 年に中国の通信技術企業 Huawei をセキュリティリスクとしてブラックリストに追加し、2022 年からは半導体に対する輸出規制を次第に厳格化してきました。一方、北京は中国市場へのアクセスを目指す外国企業に対して条件を設定し、西洋諸国への依存度を低下させるための規則を導入しました。多くの中国スタートアップが、この超大国間の対立を回避するために シンガポールやその他の地域で法人登記 を行ってきましたが、Meta-Manus 提携を阻止した中国の決定は、この戦略に対する痛烈な打撃となりました。
なぜ重要なのか: AI スタートアップに対する中国の統制強化は、すでに緊張状態にある中国と米国の関係にさらなる対立を生んでいます。今週、両国の指導者は AI を含む地政学的懸念について協議するために会談します。合意が成立すれば、技術やアイデアが両国間(および中国からシンガポールや地域の他の場所へ)より円滑に流通するようになる可能性があります。しかし、現状の膠着状態が続けば、両国は自由な交流からさらに後退し、自国の国家安全保障と経済的利益を守るための防衛を強化する恐れがあります。
私たちが考えていること: 北京の規制当局は、技術・人材・事業活動が中国に由来する戦略的に重要な企業すべてに対して権限を行使しようとしているように見えます。これは、西側からの資金調達や国際的な買収を目指す創業者や投資家にとって、その道筋を著しく狭める結果となるでしょう。

実世界条件下における AI によるマンモグラフィー診断
2020 年に導入された、マンモグラフィー画像から乳がんを検出するための Google の AI システムは、依然として現在の患者の診断には使用されていません。2 つの研究が、同システムが英国のクリニックのプロトコルにどのように統合されるかを評価しました。
何が新しいか: 実世界データを用いたテストにおいて、Google の乳がん検出システムは、2 人の専門医のうちの最初の医師による検査よりもわずかに多くの癌を特定し、偽陽性も少なかった。より重要なのは、人間の医師が見逃したが後に明らかになった癌の 4 分の 1 を同定した点である。 companion研究では、このシステムは最初の医師の意見を考慮した 2 人目の専門医と同程度の性能を示した。しかし、一部の医師からはシステムへの出力に対する不信感が報告された。これらの研究は、Google のクリストファー・J・ケリー、マーク・ウィルソンらと、インペリアル・カレッジ・ロンドン、サリー大学、ロイヤル・サリー国立保健サービス財団トラスト、および複数の国立保健サービス乳がんスクリーニングセンターによって実施された。
仕組み: Google の システム は、乳房 X 線撮影 データベース で訓練された 3 つの畳み込みニューラルネットワーク(convolutional neural networks)を使用し、埋め込みベクトルを生成し、潜在的ながん領域を特定し、がんの発生確率を分類します。
テストと結果: 2 つの研究において、この AI システムは、典型的な英国の診断プロセスにおいて、より多くのがんを特定し、それらをより迅速かつ早期に発見するのを支援しました。
- 50 歳から 70 歳の女性を対象に、2016 年に 5 つの病院で撮影された 11 万 6,000 件のマンモグラムのデータを用いて行われた後向き試験では、このシステムの癌検出能力が評価されました。著者らは、同じ女性の最大 39 ヶ月間隔で撮影されたスキャン画像を選択し、自らのシステムによる診断と人間専門医による診断を比較しました。その結果、感度(正しく特定された陽性事例の割合)は 0.541 を達成し、2 人の人間評価者のうち最初の評価者が示した 0.437 よりも大幅に高い値となりました。一方、特異度(正しく特定された陰性事例の割合)は 0.943 で、人間の評価率である 0.952 より低かったものの、統計的に同等と判断されました。また、この AI システムは、当初人間が見逃していたが 3 年後に明らかになった症例の 25 パーセントを正しく特定することに成功しました。
- 4 万 6,000 件のスキャンを対象に、著者らはもしシステムが 2 人の人間評価者のうち 2 番目の評価者を代替した場合のシミュレーションを行いました。その結果、感度と特異度の両方でわずかに優れた成績を示し、AI を 2 回目の評価に用いることで精度を高めつつ時間を節約できる可能性が示唆されました。クリニックのプロトコルによると、癌が検出された場合や AI の判断が人間と異なる場合は、最終的な決定のために仲裁委員会へ症例が送られました。AI はさらに 1,800 件の症例を仲裁委員会へ送り(絶対値で 4 ポイント増、合計 5,300 件)、仲裁に要する人的労力が読影の 5 倍であると仮定した場合、著者らは、より多くの症例を仲裁へ送ったにもかかわらず、システムによって全体的な人的労力を約 40 パーセント削減できると結論付けました。
- 本試験では、このシステムの現実世界の国民保健サービス(NHS)インフラとの統合能力が評価されました。2023 年と 2024 年の数ヶ月間にわたり、12 のクリニックで撮影された 50 歳から 70 歳の女性の約 9,250 件の新しいスキャン画像に対して、システムは高リスクまたは低リスクのラベルを付与しました(本試験は患者ケアに影響を与えませんでした。患者は通常の通り医師によって診断され、AI システムによる診断結果については医師も患者も知らされませんでした)。このシステムは人間医師よりもはるかに高速で、画面から解釈に至るまでの中央値処理時間は 17.7 分であり、2 人の人間評価者のうち最初の評価者が要した 2 日以上と比較して大幅に短縮されました。著者らは 3 ヶ月後にフォローアップを行い、患者が実際に癌を患っているかどうかという真の事実(ground truth)を確認しました。後向き研究と同様に、このシステムは感度において最初の人間評価より優れ、特異度は低かったものの統計的に同等であることが示されました。
ニュースの背景: 乳がん検出における AI の活用は、1990 年代と 2000 年代に登場した初期のコンピュータ支援診断(CAD)システムに端を発しますが、大規模なマンモグラフィーデータセットで訓練されたディープラーニングモデルが従来の手法を上回るようになり始めた 2015 年半ば以降、この分野は加速しました。2020 年、Google の研究者らは 研究結果 を発表し、AI システムがスクリーニングマンモグラフィーにおいて専門の放射線科医と同等かそれ以上の性能を発揮しつつ、偽陽性と偽陰性の両方を削減できることを示しました。2022 年後半、Google はこのシステムを乳がん画像診断プラットフォームを提供する iCAD に ライセンス し、現実のクリニックでの展開が可能となりました。2023 年、Google と iCAD はそのパートナーシップを拡大し、2D マンモグラフィーにおける AI を独立した「セカンドリーダー」として活用することを目指した、世界規模で 20 年にわたる商業化契約を締結しました ニュース。現在のパートナーシップの目的は、ダブルリーディングワークフローを採用する乳がん検出システムへの潜在的な展開に向けた規制当局からの承認獲得です。
なぜ重要なのか: 世界中で毎年約230万人の女性が乳がんの診断を受け、そのうち76万人が生存できません。早期発見が極めて重要です。しかし、診断システムは過負荷状態にあります。例えば英国では、認定維持のために年間5,000件のスキャンを読み取る必要があるコンサルタント乳腺放射線科医に、週4時間しか時間が割り当てられていません。これらの研究は、AIがスキャンの優先順位付けやデフォルトの共同読影者として機能することで診断業務の負担を軽減し、結果を改善できる可能性を示しています。同時に、医師の間でこの技術への信頼を構築する必要性も浮き彫りにしています。これには、医師に対してAIシステムの仕組みを教育することや、システム出力の説明可能性を高めることが必要となるかもしれません。
私たちが考えていること: AIシステムが医療分野に浸透するにつれ、技術への信頼を築くために必要なステップや、最良の結果をもたらすためのチェック・アンド・バランスとは何かという重要な問いが生じます。開発者は、AIシステムの出力に対する信頼を得るために医師が必要とするものを、直接医師と対話して議論することができます。
原文を表示
Dear friends,
We’ve been working on AI Andrew, an AI companion shaped by my personality. I invite you to try it out!
Many people are trying to understand what AI means for their work, learning, and careers. I’ve frequently enjoyed conversations with people on these topics. If you’d like to have a conversation on this, you might find AI Andrew can be a helpful thought partner and maybe even a friend — someone you can speak with about AI concepts, project ideas, career decisions, and whatever else is on your mind.
My team has been iterating on AI Andrew for many months, using an error analysis process to find circumstances where it says things that I would not say and debug our agentic harness to try to close the gap. My communication style has been shaped over the years by thousands of interactions. I’d never before tried to codify this in an agentic workflow. This turned out to be hard and is still a work in progress.
Reflecting on my beliefs about how to communicate has been an interesting exercise. I believe in:
- Respect for the individual. I hold a lot of respect for pretty much everyone I talk to, at any experience level or stage of life. I hope that comes through whenever I communicate.
- Celebrating wins. Many people have wins, large (like a new job or relationship) and small (like a piece of code that finally worked). I love hearing about and celebrating your wins!
- Empathy for what’s important to you. I want to help others realize their dreams. It is important to me that your dreams — not anyone else’s dreams for you — be the focus. Subject to ethical behavior, where I will respectfully push back if I see an issue, I’d like AI Andrew to support your goals, too.
- Technical precision. As a technology leader, I’m committed to speaking accurately about technical and scientific matters.
- Expressing opinions with carefully calibrated confidence. If I’m unsure of what to say, I try to ask a question rather than make a statement. In our error analysis, we found that many LLMs were overly eager to give advice despite lacking context. In real life, I try to give advice only when I’m fairly confident that it’s sound (like “please consider technology X!”). Otherwise, I would rather ask a question that supports the other person in arriving at a good answer (“What do you think about applying technology X?” or “What do you think is the best technology to apply here?”). This approach takes advantage of their context and mine to help them arrive at a better decision, rather than giving excessive weight to the limited context I have about their situation.
I am still learning how to have better conversations that support others in pursuit of their goals. We used a large mix of techniques in our harness, including RAG and many other tools, a mix of small and large models, guardrails, extensive evals, short- and long-term memory, and offline agentic loops that automatically propose improvements to the system.
To be clear, AI Andrew still has gaps! For example, an internal tester recently got it to hallucinate having climbed mountains that, sadly, I have not climbed, and it also occasionally gives advice that I question. Nonetheless, many users have reported gaining insights from talking to AI Andrew, and I hope you will find it (him?) a friendly companion that you can speak with about both personal and professional matters.
If you want to try it out, please tell me (in avatar form) what’s on your mind!
Keep building,
Andrew
A MESSAGE FROM DEEPLEARNING.AI
Go beyond using LLMs to understanding how they work! In *Transformers in Practice*, you’ll learn how transformers generate text, process context, and run efficiently using attention, KV caching, and quantization. Earn a certificate as a DeepLearning.AI Pro member. Enroll Now
News
U.S. to Evaluate Upcoming Models
The U.S. government said it will evaluate cutting-edge models before they’re available to the public, a sharp reversal of the White House’s earlier hands-off policy.
What’s new: The National Institute of Standards and Technology (NIST), an office of the U.S. Department of Commerce, announced that a new multi-agency task force will assess national-security risks posed by AI models prior to their deployment. Leading U.S. AI companies agreed to submit models for evaluation prior to release. In addition, the White House is considering an executive order that would require AI models to gain approval before they can be deployed.
How it works: NIST said the tests will focus on demonstrable risks to cybersecurity, biosecurity, and chemical weapons. The administration did not disclose details of its agreements with AI companies or any controls it expects to impose on models in light of test results.
- Models will be evaluated by Testing Risks of AI for National Security (TRAINS), a group overseen by the Center for AI Standards and Innovation (CAISI), a division of NIST. TRAINS differs from other NIST groups that have been disclosed insofar as it is designed for rapid response and draws on multiple federal agencies, including the Departments of Commerce, Defense, Energy, and Homeland Security; the National Security Administration and the National Institutes of Health.
- TRAINS has not disclosed the benchmarks it intends to use. However, NIST has shared CAISI’s earlier comparison of DeepSeek V4 Pro with other large language models. CAISI ranked model capabilities according to an aggregate of nine widely used public benchmarks that span cybersecurity, coding, mathematics, natural sciences, and abstract reasoning plus an internal test called PortBench (porting command-line interface tools between different programming languages).
- Google, Microsoft, and xAI agreed to provide models that have limited or absent guardrails, and Anthropic and OpenAI had agreed to similar terms in 2024. The agreements will enable collaborative private-public research into evaluations of capabilities and risks, as well as mitigation of risks.
Behind the news: The abrupt policy change marks a major departure from the Trump Administration’s focus on removing Biden-era regulatory barriers to AI innovation. It comes roughly one month after Anthropic attracted the government’s attention by announcing that its Claude Mythos Preview model, which is not yet widely available, could exploit vulnerabilities in widely used software.
- Immediately after taking office in January 2025, President Trump assigned three key advisors to craft an AI Action Plan that would “sustain and enhance America’s global AI dominance” by suspending or eliminating regulatory policies created by President Biden. In 2023, the Biden Administration had issued an executive order that required developers to notify the government when they train a model whose processing requirements corresponded roughly to 1 trillion parameters.
- In March 2026, Anthropic tried to limit military use of Claude for surveillance and autonomous weapons. The White House rejected any limitations and banned the model from military use entirely.
- The following month, Anthropic announced that Claude Mythos Preview could autonomously exploit vulnerabilities in major operating systems and applications. The company had shared Mythos with 50 organizations that are using it to detect and patch their software.
- Last week, the White House said it opposes the company’s plan to expand the preview to another 70 organizations, citing concerns about national security and whether Anthropic has access to sufficient computational power to serve both existing Mythos users and the government. The company has not stated whether it intends to challenge the administration’s authority to limit the distribution of the preview model.
Why it matters: The White House’s shift from laissez-faire to pre-release scrutiny of AI models reflects a dawning reality that AI models have become powerful enough to pose immediate risks to national security. Requiring AI developers to test advanced models prior to public availability could give the government advance warning of potential issues and motivate AI developers to manage them proactively. It would also enable the government to decide which models are fit for wider distribution, and which must be withheld or altered (for reasons that may not be transparent). AI companies aren’t yet required to submit new models for government testing, and those who have agreed to do so have agreed voluntarily. However, officials are considering an executive order that would make such testing mandatory.
We’re thinking: A standardized battery of benchmark tests, applied comprehensively and according to consistent procedures, would be beneficial to the AI industry, but we think the right way to come up with these tests would be via the free market, rather than be imposed by government. Further, requiring government tests ahead of release would slow down U.S. developers, putting them at a competitive disadvantage relative to their peers in other countries, and potentially help them thwart open-source competitors through regulatory capture.
OpenAI Challenges Speech-to-Speech Leaders
An update of OpenAI’s speech-to-speech model lets developers tune the tradeoff between speed and reasoning.
What’s new: OpenAI introduced three new audio models in its Realtime API. GPT-Realtime-2 is a speech-to-speech model with configurable reasoning effort. GPT-Realtime-Translate translates speech between more than 70 input languages and 13 output languages, and GPT-Realtime-Whisper transcribes speech into text.
- Input/output: GPT-Realtime-2 text, audio, image in (up to 128,000 tokens), text, audio out (up to 32,000 tokens, 1.12 seconds to first audio at minimal reasoning, 2.33 seconds at high reasoning); GPT-Realtime-Translate audio in (up to 16,000 tokens), audio out (up to 2,000 tokens); GPT-Realtime-Whisper text audio in (up to 16,000 tokens), text out (up to 2,000 tokens)
- Knowledge cutoff: September 30, 2024
- GPT-Realtime-2 features: Five levels of reasoning effort (minimal, low, medium, high, xhigh), parallel tool calls, narration of tool calls, optional preambles, graceful handling of problematic input, tone (attitude) control, function calling
- GPT-Realtime-2 performance: Tops Scale AI’s Audio MultiChallenge audio-output leaderboard and Artificial Analysis Conversational Dynamics, tied for third on Artificial Analysis Big Bench Audio
- Availability: Via OpenAI Realtime API
- Prices: GPT-Realtime-2 $32/$0.40/$64 per million input/cached/output audio tokens, $4/$0.40/$24 per million input/cached/output text tokens, $5/$0.50 per million input/cached image tokens; GPT-Realtime-Translate $0.034 per minute; GPT-Realtime-Whisper $0.017 per minute
- Undisclosed: Parameter counts, architectures, training data and methods
How GPT-Realtime-2 works: GPT-Realtime-2 handles audio in and audio out as an end-to-end process — including reasoning — rather than separate speech-to-text, text-generation, and text-to-speech steps.
- An API parameter sets the reasoning effort. Low is the default, chosen to minimize latency for live conversation. Higher reasoning effort increases latency and consumption of reasoning tokens.
- During tool calls, the model can narrate its work in progress using spoken phrases like “checking your calendar” or “looking that up now.” Optional preambles like “let me check that” can precede response to prompts, so users can track progress while the model reasons.
- When it can’t complete a request, the model alerts users via phrases like “I’m having trouble with that right now” instead of remaining silent.
GPT-Realtime-2 performance: GPT-Realtime-2 led some independent benchmarks for conversational dynamics and multi-turn instruction following, but it trailed on the Artificial Analysis Speech Reasoning leaderboard. The time required to generate audio ranged from 1.12 seconds at minimal effort to 2.33 seconds at high effort, which yields the model’s best reasoning scores — generally slow for real-time interactions, which benefit from latency lower than 500 milliseconds.
- On Artificial Analysis Big Bench Audio (answering questions drawn from the Big Bench benchmark), GPT-Realtime-2 set to high reasoning tied Google’s Gemini 3.1 Flash Live Preview set to high reasoning (96.6 percent), behind Step-Audio R1.1 Realtime (97.6 percent) and Grok Voice Think Fast 1.0 (97.1 percent). Set to minimal reasoning, GPT-Realtime-2 dropped to 71.8 percent.
- On Artificial Analysis’s Conversational Dynamics (a weighted average that tests the ability to manage taking turns, pausing, interruptions, and brief interjections such as “uh-huh”), GPT-Realtime-2 set to minimal reasoning led with 96.1 percent. However, set to high reasoning (95.3 percent), it lagged GPT-Realtime-1.5 and GPT Realtime Mini (tied at 95.7 percent).
- On 𝜏-Voice (agentic performance in three customer-service domains), GPT-Realtime-2 led the airline domain with 63 percent, according to Artificial Analysis. But considering all three domains, GPT-Realtime-2 (39.8 percent) fell behind Grok Voice Think Fast 1.0 (52.1%) but ahead of Gemini 3.1 Flash Live Preview set to high (37.7 percent).
- On the Scale AI Audio MultiChallenge Audio Output leaderboard, which evaluates four conversational criteria (instruction retention, inference memory, self-coherence, and voice editing) in multi-turn spoken dialogue, GPT-Realtime-2 set to xhigh reasoning placed first (48.45 percent average pass rate, the share of conversations in which the model satisfies every criterion), a significant jump from its predecessor GPT-Realtime-1.5 (34.73 percent average pass rate). However, Scale AI has not yet tested Grok Voice Think Fast nor Step-Audio R1.1 Realtime.
Yes, but: The two models ahead of GPT-Realtime-2 on the Artificial Analysis Speech Reasoning leaderboard are also faster.
- Step-Audio R1.1 Realtime takes 1.51 seconds to generate its first audio output and Grok Voice Think Fast 1.0 takes 1.25 seconds, versus 2.33 seconds for GPT-Realtime-2 at high reasoning effort.
- With reasoning set to xhigh, GPT-Realtime-2’s overall pass rate on the Scale AI Audio MultiChallenge is below 50 percent, which suggests that reliable multi-turn spoken dialogue remains challenging for current models.
Why it matters: Voice agents generally have focused on relatively simple interactions because reasoning often comes at the cost of a snappy response. GPT-Realtime-2 offers not only high performance but also control over that tradeoff (minimal reasoning for faster turn-taking, xhigh for interactions that can wait). This flexibility expands the range of tasks voice agents can handle without resorting to text processing.
We’re thinking: It's exciting to see that GPT-Realtime-2 implements preambles similar to the pre-responses we described here!
China shut down Meta’s attempt to acquire agentic technology that originated within its borders, a blow to further technical interchange and investment between China and the U.S.
What’s new: China’s cabinet-level regulator in charge of economic planning and development blocked Meta’s proposed acquisition of Manus, a Singapore-based startup that was founded in China and offers a popular AI agent. Meta and Manus unwound the deal, which was worth as much as $2.5 billion. Beyond quashing Meta’s plans to offer agentic products and features, the action upended an emerging strategy for launching AI startups built in China.
How it works: Meta’s purchase of Manus was viewed as a sign that Manus, having relocated to Singapore and closed its business in China, had maneuvered itself successfully beyond Bejing’s purview. But the government asserted its authority over strategically important technology developed in China by Chinese engineers. Startups founded in China responded by rolling back plans to move elsewhere to seek international investments or partnerships.
- The China-based company Butterfly Effect developed a general-purpose agent that completes long-running tasks with minimal user input and guidance. In early 2025, it launched Manus as an invitation-only beta and quickly attracted users as well as investments from major Chinese investors and Silicon Valley venture capitalists. The company relocated to Singapore in July. As the year ended, Manus reported $100 million in annual recurring revenue that was growing at 20 percent monthly.
- In December, Meta announced the deal to acquire Manus and began integrating Manus technology into its own AI chatbots and offerings on Facebook, Instagram, and WhatsApp. It also announced plans to continue operating Manus as an independent business.
- The following month, China’s National Development and Reform Commission (NDRC) opened a security review, citing concerns over potential transfers of data and foreign ownership of services that operate in China. In April, the agency said it will examine foreign investment in domestic AI companies much more closely, particularly to curb U.S. investment in and acquisition of technology developed in China. It went on to block the Meta-Manus deal.
- The move has created a chilling effect for China’s tech founders and investors, for whom the “Singapore strategy” no longer gives them the flexibility to raise money from foreign investors and explore partnerships with companies in and outside the region. They are cancelling plans to move abroad, pursue acquisitions, or raise money from U.S. and European sources.
Behind the news: For more than a decade, the U.S. and China have viewed advanced technology as a strategic arena tied to economic influence, military power, and national security. Earlier disputes over espionage, intellectual property, and technology transfer escalated into sweeping government intervention. The U.S. blacklisted the Chinese communications-technology company Huawei as a security risk in 2019 and imposed increasingly stringent export controls on semiconductors beginning in 2022. Meanwhile, Beijing set conditions on foreign companies seeking access to the Chinese market and imposed rules to reduce its reliance on Western technology. Numerous Chinese startups have attempted to sidestep the superpower rivalry by incorporating in Singapore and elsewhere. China’s decision to block the Meta-Manus deal strikes a blow to that strategy.
Why it matters: The tightening of China’s control over AI startups raises tensions amid an already tense situation between China and the U.S. This week, leaders of the two countries will meet to discuss geopolitical concerns, including AI. An agreement may permit technology and ideas to flow more easily between the two countries (and from China to Singapore and elsewhere in the region). But an ongoing stalemate could drive both countries to withdraw further from free exchange and harden defenses of their own national security and economic interests.
We’re thinking: Beijing’s regulators appear to be asserting authority over any strategically important company whose technology, talent, or operations originated in China. That would sharply narrow the path of founders and investors who hope to attract Western capital or pursue international acquisitions.
AI Mammogram Diagnosis Under Real-World Conditions
Introduced in 2020, Google’s AI system for detecting breast cancer in mammograms still hasn't been used to diagnose current patients. Two studies evaluated how well it would integrate with protocols at UK clinics.
What’s new: In a test on real-world data, Google’s breast-cancer detection system identified slightly more cancers with fewer false positives than examinations by the first of two expert doctors. More significantly, it identified a quarter of cancers that human doctors missed but became apparent later. In a companion study, the system performed about as well as a second expert (who considered the first’s opinion). However, some doctors reported distrust in the system’s output. The studies were conducted by Christopher J. Kelly, Marc Wilson, and colleagues at Google, Imperial College London, University of Surrey, Royal Surrey National Health Service Foundation Trust, and several National Health Service Breast Screening Centres.
How it works: Google’s system uses three convolutional neural networks that were trained on a mammography database to produce embeddings, determine potential cancerous regions, and classify the probability of cancer.
Tests and results: In the two studies, the AI system helped to identify more cancers, and to identify them faster and earlier, in a typical UK diagnostic process.
- A retrospective test evaluated the system’s ability to detect cancers based on 116,000 mammograms of women of ages 50 to 70 taken at five hospitals in 2016. The authors selected scans of the same women taken up to 39 months apart and compared diagnoses by their system versus a human expert. It achieved a sensitivity of 0.541 (the proportion of positives correctly identified), significantly higher than the 0.437 achieved by the first of two human evaluations. Its specificity was 0.943 (the proportion of negatives correctly identified) compared to the human rate of 0.952 — lower, but statistically equivalent. The AI system also successfully identified 25 percent of cases that humans had missed initially but became apparent three years later.
- Considering 46,000 scans, the authors simulated what it would be like if the system were to replace the second of two human evaluators. The system achieved slightly better sensitivity and specificity, indicating that using AI for the second evaluation could save time while gaining accuracy. According to the clinics’ protocols, in cases where cancer was detected or the AI disagreed with the human, the cases were sent to an arbitration panel for a final determination. The AI sent 1,800 more cases to arbitration (an absolute increase of 4 percentage points; 5,300 total). Assuming that arbitration took five times as much human effort as reading does, the authors concluded that, despite sending more cases to arbitration, the system would reduce human effort by roughly 40 percent.
- A live test evaluated the system’s ability to integrate with the real-world National Health Service infrastructure. The system labeled high or low risk around 9,250 fresh scans of women of ages 50 to 70 taken at 12 clinics during a few months in 2023 and 2024. (The test did not affect patient care. Patients were diagnosed by doctors in the usual way, and neither doctors nor patients were informed of the AI system’s diagnosis.) The system was much faster than human doctors, achieving a median processing time of 17.7 minutes from screen to interpretation compared to more than two days for the first of two human evaluations. The authors followed up three months later to determine the ground truth of whether a patient had cancer. As in the retrospective study, the system achieved better sensitivity than the first human evaluation and lower but statistically equivalent specificity.
Behind the news: Efforts to use AI for breast cancer detection began with earlier computer-aided detection (CAD) systems in the 1990s and 2000s, but the field accelerated in the mid 2010s as deep-learning models trained on large mammography datasets began outperforming older methods. In 2020, researchers at Google showed that an AI system could match or exceed expert radiologists in screening mammograms while reducing both false positives and false negatives. In late 2022, Google licensed the system to iCAD, which offers a breast-imaging platform, for deployment in real-world clinics. In 2023, Google and iCAD expanded their partnership into a 20-year worldwide commercialization agreement aimed at using Google’s AI as an independent “second reader” of 2D mammography. The partnership currently aims to secure regulatory approval for potential deployment in breast-cancer screening systems that use double-reading workflows.
Why it matters: Around 2.3 million women are diagnosed with breast cancer annually worldwide, and 760,000 don’t survive. Early diagnosis is critical. Yet the diagnostic system is overburdened. In the UK, for instance, a consultant breast radiologist has only four hours available weekly to look at the 5,000 scans they must read annually to maintain their certification. These studies show that AI can ease diagnostic workloads and improve outcomes by helping to prioritize scans or serving as a default co-reader. But they also highlight a need to build trust in the technology among doctors. This may require educating physicians in how AI systems work and making the systems’ output more explainable.
We’re thinking: As AI systems find their way into medicine, they raise important questions about the steps needed to build trust in the technology, and what checks and balances will yield the best outcomes. Developers can talk directly with doctors about what they need to gain trust in an AI system's output.
関連記事
Gemini Flash の価格上昇、AI 法施行延期、エージェントがオンライントラフィックを牽引
The Batch は、シリコンバレーで注目される AI フォワードデプロイメントエンジニア(FDE)の役割について報じ、顧客組織に常駐してワークフローをカスタマイズする専門職の台頭を紹介した。
ヘルメス対オープンクロー、サイバーセキュリティ警報の鳴動、より対話的な会話、エージェントは人間の仕事ができるか?
The Batch は、AI エージェント間の比較(ヘルメスとオープンクロー)、サイバーセキュリティの警報発生、対話機能の高度化、そして AI エージェントが人間の業務を代替できる可能性について論じています。
Seedance が話題を呼ぶ、Nvidia の AI 活用チップ設計、ロボットの記憶保持支援
Seedance が注目を集め、Nvidia は AI を活用したチップ設計を発表し、ロボットが情報を忘れないよう支援する技術が開発された。
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み