fetch() HTTP範囲リクエストを用いた二分探索によるUnicodeエクスプローラー
Simon Willison氏は、LLMとの対話を通じて設計されたプロトタイプにより、HTTP Rangeリクエストと二分探索を組み合わせたUnicodeコードポイント検索ツール「Unicode Explorer」を開発し、大規模ファイルからの効率的なデータ取得の実証を行った。
キーポイント
LLMを活用した迅速なプロトタイピング
Simon Willison氏は、Claudeとの対話によりユースケースを特定し、Claude Codeを用いて仕様書から実装コードまで非同期で生成させることで、短時間で機能するプロトタイプを構築した。
HTTP Rangeリクエストと二分探索の応用
76.6MBのUnicodeメタデータファイルに対し、HTTP Rangeリクエストを使用してバイナリサーチを行うことで、大規模データの効率的な検索を実現した。
圧縮との互換性とCDNの挙動
RangeリクエストはHTTP圧縮と互換性がないが、CloudflareなどのCDNはContent-Rangeヘッダーが存在する場合、自動的に圧縮をスキップするため、明示的な設定省略が可能であることが確認された。
CORS対応S3バケットの利用
CloudflareでフロントエンドされたS3バケットからCORSを有効にしたデータソースへクエリを実行し、ブラウザ上で動作するデモを展開した。
影響分析・編集コメントを表示
影響分析
この事例は、LLMを単なるコーディングアシスタントとしてではなく、設計段階から実装までを含む「対話型開発パートナー」として活用する新しいワークフローを示唆しています。また、HTTP Rangeリクエストという既存の標準プロトコルを、バイナリサーチと組み合わせることで大規模データ検索に応用する技術的知見は、フロントエンド開発やデータ処理の最適化において参考になるでしょう。
編集コメント
LLMを用いたプロトタイピングの効率化と、HTTPプロトコルの深い理解を組み合わせた実践的な事例として注目です。技術者向けの実践知見が凝縮されています。
fetch()のHTTP範囲リクエストを用いた二分探索によるUnicodeエクスプローラー
これは、HTTP範囲リクエストの実験として、また、好奇心を満たすためにLLMを利用する一例として、今朝スマートフォンから作った小さなプロトタイプです。
私は以前からHTTP範囲リクエストの手法を集めていて、大きなファイルに対して二分探索を行って何か役に立つことをするツールを、自分で作ってみたら面白いだろうと考えました。
そこでClaudeとブレインストーミングを行いました。課題は、データが自然にソートされており、二分探索のメリットを活かせるユースケースを見つけることでした。
Claudeが提案した案の一つが、Unicodeコードポイントの情報を検索するというもので、これは数MBに及ぶメタデータの中を検索することを意味します。
私はClaudeに仕様書を書かせ(ここで閲覧可能)、それをClaude Codeに渡しました。その後、私のsimonw/researchリポジトリに対して、Claude Code for webを使った非同期の研究プロジェクトを開始し、その仕様を実際に動作するコードへと変換しました。
結果のレポートとコードはこちらです。この過程で学んだ興味深い点の一つは、Rangeリクエストの手法はバイトオフセットの計算を狂わせるため、HTTP圧縮と互換性がないということです。fetch()呼び出しに'Accept-Encoding': 'identity'を追加しましたが、これは実際には必要ありません。Cloudflareや他のCDNは、content-rangeヘッダーが存在する場合、自動的に圧縮を省略するからです。
私は、まずコードを調整して、Cloudflareがフロントに立つS3バケット内のCORSが有効な76.6MBファイルに対して範囲リクエストでデータを問い合わせるようにし、その後、結果を自分のtools.simonwillison.netサイトにデプロイしました。
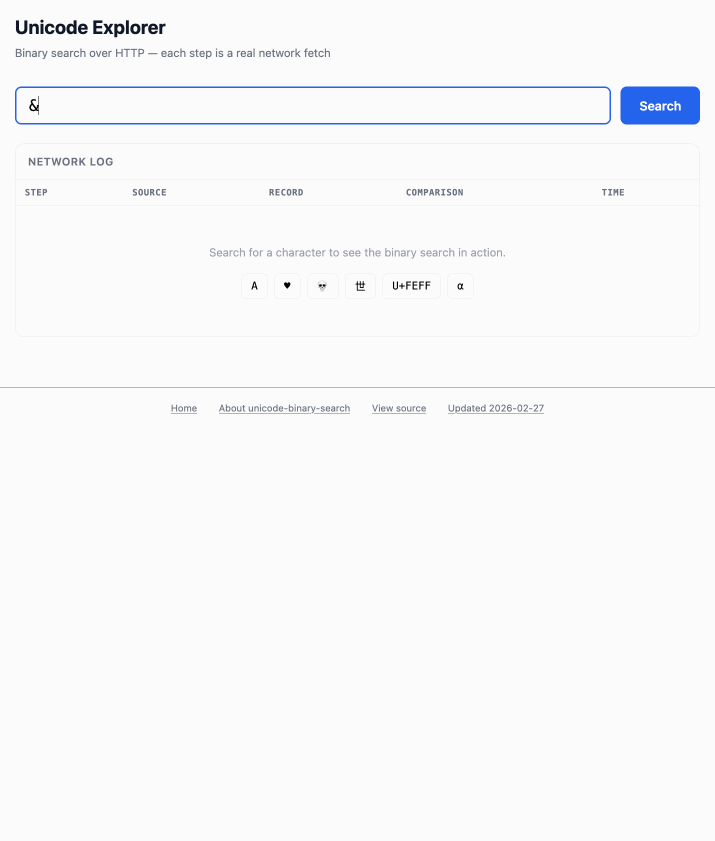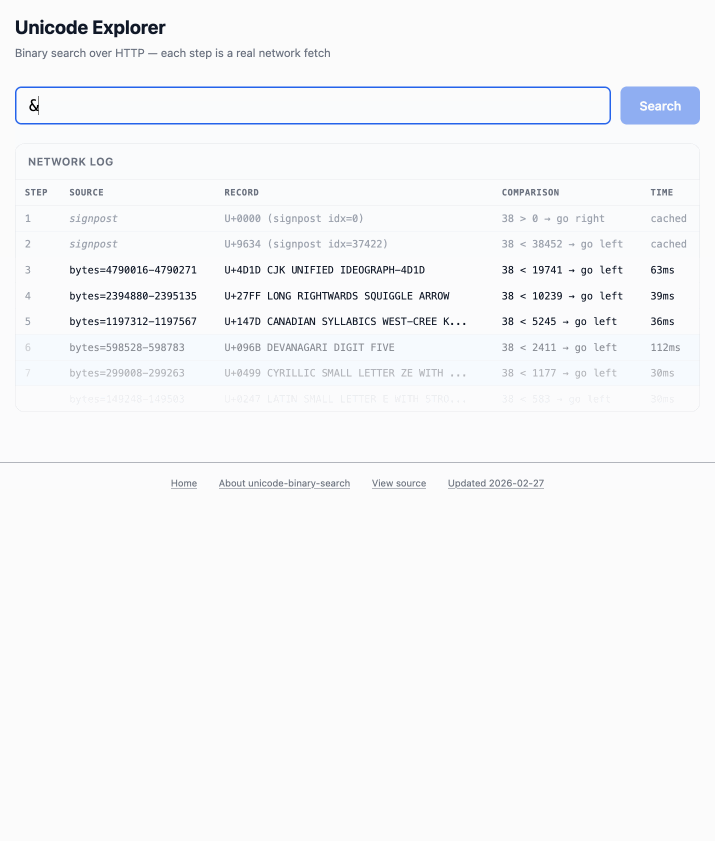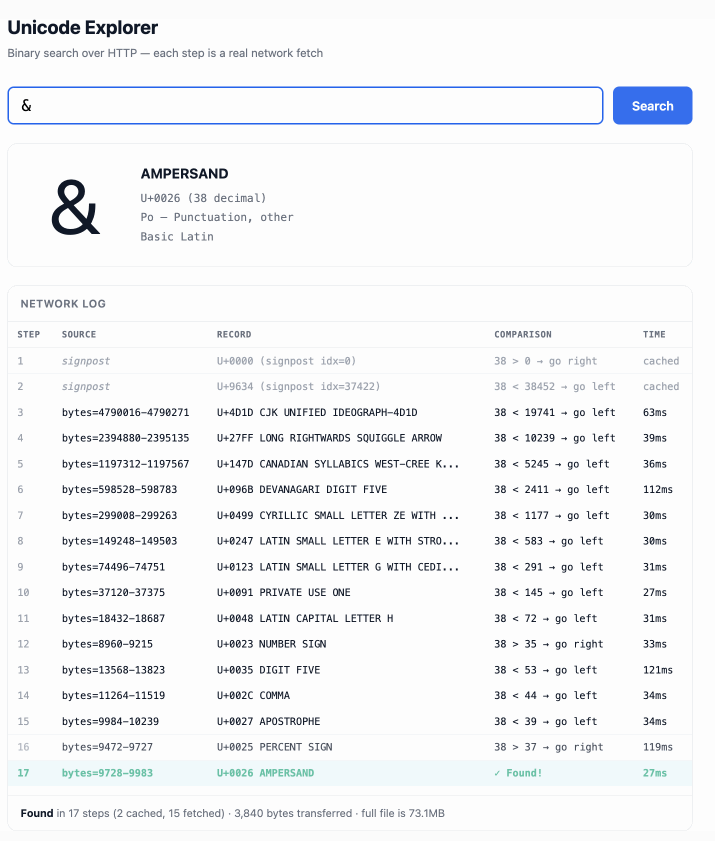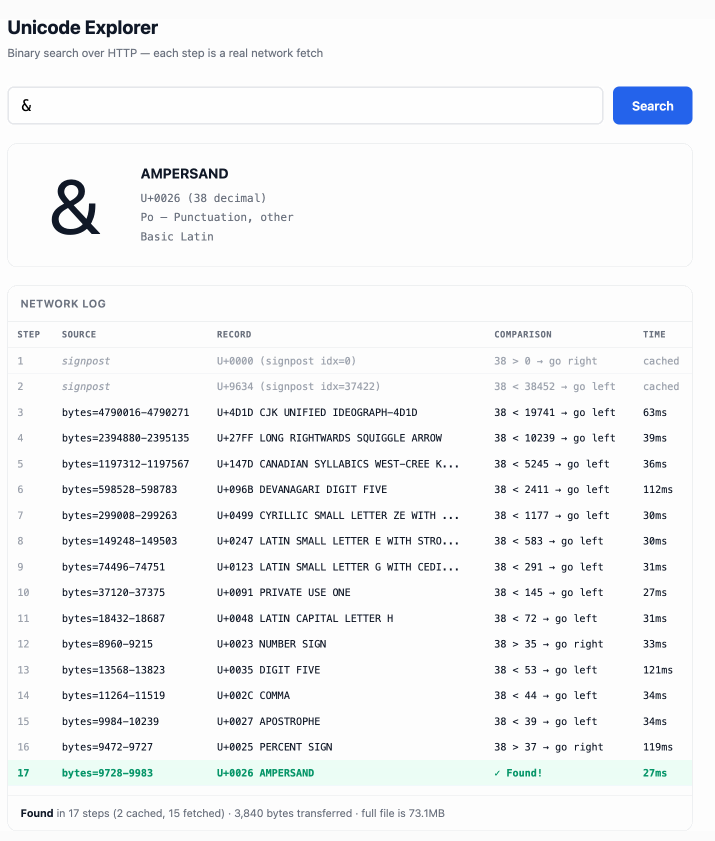
このデモは触ってみると楽しいです。øのような一文字や、1F99Cのような16進数のコードポイント指示子を入力すると、大きなファイルに対して二分探索を行い、その過程で辿ったステップを表示します:
タグ: アルゴリズム, http, 研究, ツール, unicode, ai, 生成AI, llms, AI支援プログラミング, http-range-requests
原文を表示
Unicode Explorer using binary search over fetch() HTTP range requests
Here's a little prototype I built this morning from my phone as an experiment in HTTP range requests, and a general example of using LLMs to satisfy curiosity.
I've been collecting HTTP range tricks for a while now, and I decided it would be fun to build something with them myself that used binary search against a large file to do something useful.
So I brainstormed with Claude. The challenge was coming up with a use case for binary search where the data could be naturally sorted in a way that would benefit from binary search.
One of Claude's suggestions was looking up information about unicode codepoints, which means searching through many MBs of metadata.
I had Claude write me a spec to feed to Claude Code - visible here - then kicked off an asynchronous research project with Claude Code for web against my simonw/research repo to turn that into working code.
Here's the resulting report and code. One interesting thing I learned is that Range request tricks aren't compatible with HTTP compression because they mess with the byte offset calculations. I added 'Accept-Encoding': 'identity' to the fetch() calls but this isn't actually necessary because Cloudflare and other CDNs automatically skip compression if a content-range header is present.
I deployed the result to my tools.simonwillison.net site, after first tweaking it to query the data via range requests against a CORS-enabled 76.6MB file in an S3 bucket fronted by Cloudflare.
The demo is fun to play with - type in a single character like ø or a hexadecimal codepoint indicator like 1F99C and it will binary search its way through the large file and show you the steps it takes along the way:
Tags: algorithms, http, research, tools, unicode, ai, generative-ai, llms, ai-assisted-programming, http-range-requests
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み