サーモン・イン・ザ・ループ
環境科学分野における水車ダム通過魚類の計数プロジェクトを通じて、人間をループに組み込んだデータセット制作の複雑さとステークホルダーとの協働プロセスが分析されている。
キーポイント
FERC 規制と環境影響評価の背景
米国連邦エネルギー規制委員会(FERC)の許可取得には、水力発電施設が魚類に与える悪影響を検証する詳細な計画提出が義務付けられており、違反時は制裁や運転停止のリスクがある。
人間をループにしたデータ制作の実践
AI 技術だけでなく、専門家の判断を介在させる「ヒューマン・イン・ザ・ループ」方式が魚類計数において不可欠であり、その調整と管理には多大な労力と複雑さが伴う。
ステークホルダーとの進捗共有の難しさ
技術的な成果を、規制当局や地域住民など多様なステークホルダーにどのように理解させ、合意形成を図るかという社会的・技術的課題が浮き彫りになっている。
水力発電ダムによる生態系への影響
ダムの建設は水路を分断し、魚の移動や産卵行動に深刻な悪影響を与える可能性があり、特に太平洋岸北西部では絶滅危惧種のサケ類が脅かされています。
規制遵守とデータ提出の義務
連邦エネルギー規制委員会(FERC)の規制により、水力発電ダムは操業が絶滅危惧種に悪影響を与えていないことを証明するデータを定期的に生成し、報告する義務を負っています。
魚道調査とカウントデータの重要性
規制遵守を証明するために行われる魚道調査は、ダム通過時の魚の数を計測するという主要なデータセットに依存しており、これがすべての評価の基礎となっています。
視覚的魚類カウントの専門性と限界
魚種や傷、孵化場由来などの微妙な特徴を識別するには高度な専門知識が必要であり、悪天候や過酷な環境下での作業は正確性を損なうリスクがある。
影響分析・編集コメントを表示
影響分析
この記事は、AI が社会実装される際に直面する「非技術的」な障壁、特に規制対応や人間との協働の難しさを浮き彫りにしており、技術者にとって重要な教訓となる。特に環境分野のような厳格な規制下での AI 導入事例として、単なるアルゴリズムの精度だけでなく、プロセス管理とステークホルダーエンゲージメントの重要性を再認識させる内容である。
編集コメント
技術的なアルゴリズムの革新性よりも、AI プロジェクトが現実社会で機能するために不可欠な「人間との協働」や「規制対応」という文脈を強調した貴重な事例記事です。
最後に、この問題領域の一部として、強い組織的圧力から生じる根本的な労働問題に対処する必要があります。魚の計数は、水力発電ダムの運営者が可能な限り排除または削減したいコストセンターです。したがって、魚を正確に数える技術的解決策は非常に魅力的です。しかし、これはゴーストワークに関する懸念を引き起こします。ゴーストワークとは、モデルの訓練と検証に人間の労働力が使用されるにもかかわらず、その貢献が認知されず、適切な報酬も支払われない状況を指します。人間の労働者をコンピュータビジョン・ソリューションに置き換えることは、解雇された労働者に経済的困難をもたらし、彼らの職務スキルと専門知識を陳腐化させることで、重大な影響を与える可能性があります。魚の識別に関する人間の専門知識が失われれば、種の保全において最適とは言えない決定が下され、最終的にはシステム全体の有効性を損なう恐れがあります。この技術が単なるコスト削減策として実施される場合、保全の目的にとってはさらに危険です。モデルがドリフトしたとき、もはや
原文を表示
 imageOne of the most fascinating problems that a computer scientist may be lucky enough to encounter is a complex sociotechnical problem in a field going through the process of digital transformation. For me, that was fish counting. Recently, I worked as a consultant in a subdomain of environmental science focused on counting fish that pass through large hydroelectric dams. Through this overarching project, I learned about ways to coordinate and manage human-in-the-loop dataset production, as well as the complexities and vagaries of how to think about and share progress with stakeholders.
imageOne of the most fascinating problems that a computer scientist may be lucky enough to encounter is a complex sociotechnical problem in a field going through the process of digital transformation. For me, that was fish counting. Recently, I worked as a consultant in a subdomain of environmental science focused on counting fish that pass through large hydroelectric dams. Through this overarching project, I learned about ways to coordinate and manage human-in-the-loop dataset production, as well as the complexities and vagaries of how to think about and share progress with stakeholders.
Background
Let’s set the stage. Large hydroelectric dams are subject to Environmental Protection Act regulations through the Federal Energy Regulatory Commission (FERC). FERC is an independent agency of the United States government that regulates the transmission and wholesale sale of electricity across the United States. The commission has jurisdiction over a wide range of electric power activities and is responsible for issuing licenses and permits for the construction and operation of hydroelectric facilities, including dams. These licenses and permits ensure that hydroelectric facilities are safe and reliable, and that they do not have a negative impact on the environment or other stakeholders. In order to obtain a license or permit from FERC, hydroelectric dam operators must submit detailed plans and studies demonstrating that their facility meets regulations. This process typically involves extensive review and consultation with other agencies and stakeholders. If a hydroelectric facility is found to be in violation of any set standards, FERC is responsible for enforcing compliance with all applicable regulations via sanctions, fines, or lease termination--resulting in a loss of the right to generate power.
Hydroelectric dams are essentially giant batteries. They generate power by building up a large reservoir of water on one side and directing that water through turbines in the body of the dam. Typically, a hydroelectric dam requires lots of space to store water on one side of it, which means they tend to be located away from population centers. The conversion process from potential to kinetic energy generates large amounts of electricity, and the amount of pressure and force generated is disruptive to anything that lives in or moves through the waterways—especially fish.

To demonstrate compliance with FERC regulations, large hydroelectric dams are required to routinely produce data which shows that their operational activities do not interfere with endangered fish populations in aggregate. Typically, this is done by performing fish passage studies. A fish passage study can be conducted many different ways, but boils down to one primary dataset upon which everything is based: a fish count. Fish are counted as they pass through the hydroelectric dam, using structures like fish ladders to make their way from the reservoir side to the stream side.

These modes of data collection are great, but there are varying degrees of error that could be imparted through their recording. For example, some visual fish counts are documented with pen and paper, leading to incorrect counts through transcription error; or there can be disputes about the classification of a particular species. Different dam operators collect fish counts with varying degrees of granularity (some collect hourly, some daily, some monthly) and seasonality (some collect only during certain migration patterns called “runs”). After collection and validation, organizations correlate this data with operational information produced by the dam in an attempt to see if any activities of the dam have an adverse or beneficial effect on fish populations. Capturing these data piecemeal with different governing standards and levels of detail causes organizations to look for new efficiencies enabled by technology.
Enter Computer Vision
Some organizations are exploring the use of computer vision and machine learning to significantly automate fish counting. Since dam operators subject to FERC are required to collect fish passage data anyway, and the data were previously produced or encoded in ways that were challenging to work with, an interesting “human-in-the-loop” machine learning system arises. A human-in-the-loop system combines the judgment and expertise of subject-matter expert humans (fish biologists) with the consistency and reliability of machine learning algorithms, which can help to reduce sources of error and bias in the output dataset used in the machine learning system. For the specific problem of fish counting, this could help to ensure that the system's decisions are informed by the latest scientific understanding of fish taxonomy and conservation goals, and could provide a more balanced and comprehensive approach to species or morphological classification. An algorithmic system could reduce the need for manual data collection and analysis by automating the process of identifying and classifying species, and could provide more timely and accurate information about species' health.
Building a computer vision system for a highly-regulated industry, such as hydropower utilities, can be a challenging task due to the need for high accuracy and strict compliance with regulatory standards. The process of building such a system would typically involve several steps:
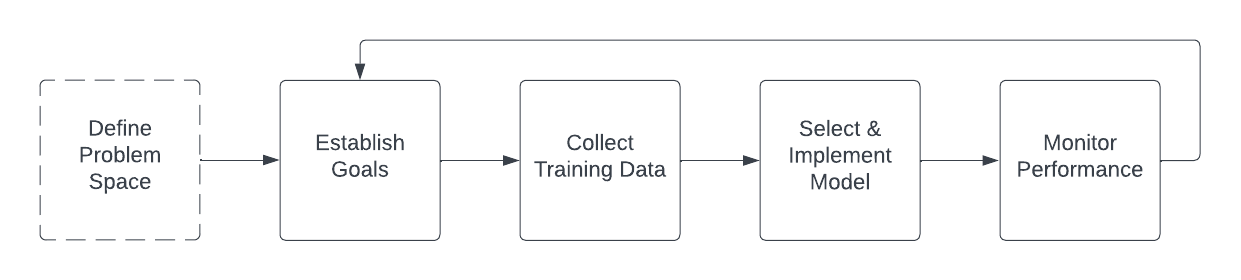
Once the problem space is defined, more technical decisions can be made about how to implement the solution. For example, if the goal is to estimate population density during high fish passage using behavioral patterns such as schooling, it may make sense to capture and tag live video, to see the ways in which fish move in real time. Alternatively, if the goal is to identify illness or injury in a situation where there are few fish passing, it may make sense to capture still images and tag subsections of them to train a classifier. In a more developed hypothetical example, perhaps dam operators know that the fish ladder only allows fish to pass through it, all other species or natural debris are filtered out, and they want a “best guess” about rare species of fish that pass upstream. It may be sufficient in this case to implement generic video-based object detection to identify that a fish is moving through a scene, take a picture of it at a certain point, and provide that picture to a human to tag with the species. Once tagged, these data can be used to train a classifier which categorizes fish as being the rare species or not.
- Establish performance goals: The definition of the problem space and the initial suggested process flow should be shared with all stakeholders as an input to the performance goals. This helps ensure all interested parties understand the problem at a high level, and what is possible for a given implementation. Practically, most hydropower utilities are interested in automated fish count solutions that meet an accuracy threshold of 95% as compared to a regular human visual count, but expectations around whether these metrics are achievable and at what part of the production cycle will be a highly negotiated series of points. Establishing these goals is a true sociotechnical problem, as it cannot be done without taking into account both the real-world constraints that limit the data and the system. These constraining factors will be discussed later in the Obstacles section of the paper.
- Collect and label training data: In order to train a machine learning model to perform the tasks required by the system, it is first necessary to produce a training dataset. Practically, this involves collecting a large number of fish images. The images are annotated with the appropriate species classification labels by a person with expertise in fish classification. The annotated images are then used to train a machine learning model. Through training, the algorithm learns the features characteristic of each subclass of fish and identifies those features to classify fish in new, unseen images. Because the end goal of this system is to minimize the counts that humans have to do, images with a low “confidence score” (a metric commonly produced by object-detection models) may be flagged for identification and tagging by human reviewers. The more seamless an integration with a production fish counting operation, the better.
- Select a model: Once the training data has been collected, the next step is to select a suitable machine learning model and train it on the data. This could involve using a supervised learning approach, where the model is trained to recognize the different categories of fish after being shown examples of labeled data. At the time of this writing, deep learning systems based on pretrained models like ImageNet are popular choices. Once trained, the model should be validated against tagged data that it has not seen before and fine-tuned by adjusting the model parameters or refining the training dataset and retraining.
- Monitor system performance: Once the model has been trained and refined, it can be implemented as part of a computer vision system for regular use. The system's performance should be monitored regularly to ensure that it is meeting the required accuracy targets and to ensure that model drift does not occur, perhaps from changes in environmental conditions, such as water clarity; or morphological changes alluded to in a later section
It is at this point that the loop of tasks begins anew; to eke out more performance from the system, it is likely that more refined and nuanced negotiation about what to expect from the system is necessary, followed by additional training data, model selection, and parameter tuning/monitoring. The common assumption is that an automated or semiautomatic system like this is “set it and forget it” but the process of curating and collating datasets or tuning hyper parameters is quite engaged and intentional.
Obstacles
In order for the computer vision algorithm to accurately detect and count fish in images or video frames, it must be trained on a large and diverse dataset that includes examples of different fish species and morphologies. However, this approach is not without challenges, as specified in the diagram below and with bolded phrases in subsequent paragraphs:
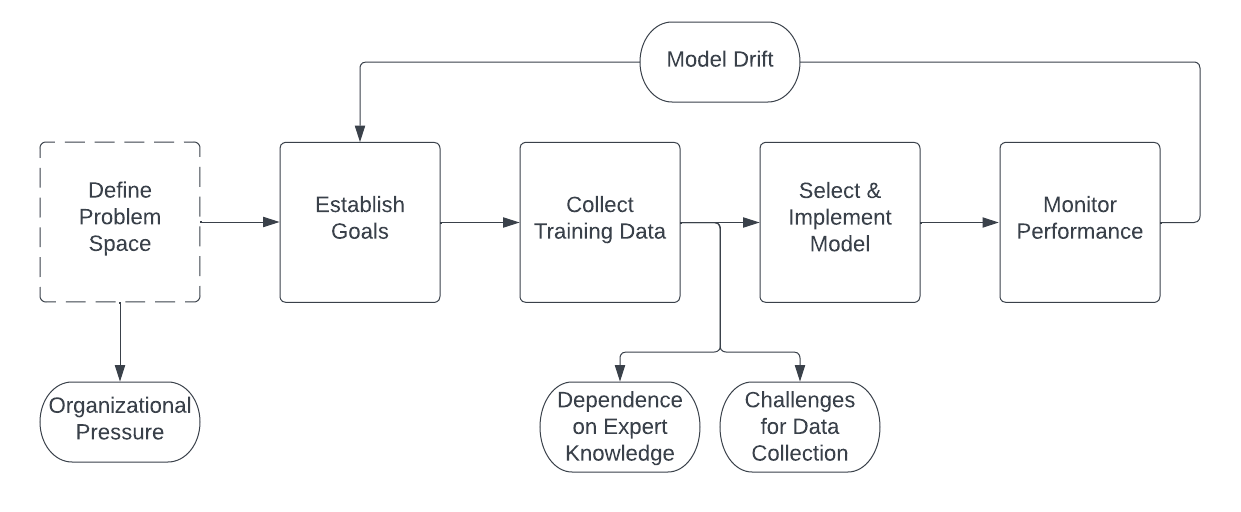
Environmental conditions at hydroelectric dams present challenges for data collection as well. Inadequate illumination and poor image quality can make it difficult for both humans and machine learning algorithms to accurately classify fish. Similarly, changing conditions, like a reduction in water clarity following a seasonal snowmelt can obscure fish in imagery. Migratory fish can be difficult to identify and classify on their own terms, due to the wide range of species and subspecies that exist, and the way their bodies change as they age. These fish are often difficult to study and monitor due to their migratory habits and the challenging environments in which they live. Further, there are often inconsistent data taxonomies produced across organizations, leading to different classifications depending on the parent organization undertaking the data tagging process. If humans cannot create accurate classifications to populate the initial dataset, the machine learning system will not be able to accurately produce predictions when used in production.

Finally, there are background labor issues to be dealt with as part of this problem space coming from intense organizational pressure. Fish counting is a cost center that hydroelectric dam operators would like to eliminate or reduce as much as possible. A technical solution that can accurately count fish is therefore very appealing. However, this raises concerns about ghost work, where human labor is used to train and validate the model, but is not acknowledged or compensated. Replacing human workers with a computer vision solution may significantly impact the displaced workers through financial hardship or the obsoletion of their job skills and expertise. If human expertise in the identification of fish is lost, this could lead to suboptimal decisions about species conservation, and could ultimately undermine the effectiveness of the system. This becomes more dangerous for conservation purposes if the technology is implemented as a cost-reduction measure: it could be the case that—when the model drifts—there are no ta
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み