Strands と Exa を活用した Web 検索対応エージェントの構築
AWS の Strands Agents SDK と Exa が連携し、LLM が直接処理可能な構造化データを提供する検索ツールを実装することで、エージェントの多段階タスク実行能力を強化した。
キーポイント
従来の検索 API の課題と解決策
汎用検索 API は人間向けの HTML やスニペットを返すため、AI エージェントが直接利用するには追加の処理が必要だったが、本統合は LLM コンテキストに即した構造化データを直接提供してこのギャップを埋める。
モデル駆動型アーキテクチャの活用
Strands Agents SDK の特徴である「モデルがツール呼び出しを自律的に決定する」仕組みと組み合わせることで、エージェントはリアルタイムのウェブ知識を推論ループに組み込み、複雑なタスクを遂行できる。
2 つのコアツールの機能
カテゴリ指定可能な意味検索を行う「exa_search」と、選択した URL の完全コンテンツを取得する「exa_get_contents」の 2 つのツールが提供され、多段階の調査タスクを可能にする。
オープンソース SDK と MCP 対応
AWS が提供するオープンソースの Strands Agents SDK は既に 40 以上の事前構築済みツールを搭載しており、Model Context Protocol (MCP) にも対応しているため、Exa のような外部ツールの統合が容易である。
6段階の構造化された研究ワークフロー
エージェントは概要検索、ニュース、学術論文、GitHubプロジェクトの4段階の探索と、深掘り抽出、最終合成という計6ステップで自律的に情報を収集・統合し、高品質なレポートを生成します。
ハルシネーション低減とトークン効率化
各検索段階で要約を取得してLLMに渡すことで不要なコンテキストを削減し、最終回答の根拠となるソースURLを追跡可能にするため、ハルシネーション(幻覚)を大幅に抑えられます。
Amazon Bedrock AgentCoreによる可観測性
OpenTelemetryベースのトレーシング機能により、各ツール呼び出しのパラメータ、ステップごとのレイテンシ、トークン消費量を詳細に監視・デバッグでき、非確定的なエージェント動作の改善を可能にします。
影響分析・編集コメントを表示
影響分析
本記事は、AI エージェントの実用化における最大のボトルネックである「非構造化ウェブデータの処理」という課題に対し、検索エンジン側とフレームワーク側の両面から解決策を提示しています。これにより、開発者は複雑なパースロジックを実装せずに高品質な情報取得を実現でき、より高度で自律的なエージェントアプリケーションの普及が加速すると予想されます。
編集コメント
検索エンジンが単なるキーワードマッチングから、AI エージェントの推論プロセスに直接組み込まれる「エージェントネイティブ検索」への転換を示す重要な事例です。
*この投稿は、Exa の Ishan Goswami と Nitya Sridhar によって共同執筆されました。*
研究、ファクトチェック、競合分析のためにウェブ検索機能を備えた AI エージェントを構築する場合、最新かつ信頼性の高い情報へのアクセスが極めて重要です。一般的な汎用検索 API はエージェントワークフロー向けに設計されておらず、人間による閲覧用に最適化された HTML 重視のページや短いスニペットを返す傾向があります。これは、エージェントが直接消費できる構造化データではありません。その結果、開発者はこれらのコンテンツをエージェントワークフロー内で利用可能な形式に変換するために、追加のレイヤー、カスタムクローラー、パーサー、ランキングロジックを構築する必要に迫られることがよくあります。
Strands Agents SDK 向けの Exa インテグレーションは、ツールインターフェースに直接組み込まれた AI ネイティブな検索および取得レイヤーによってこのギャップを埋めます。Exa は、マークアップの除去や出力の再フォーマットのための後処理を必要とせず、LLM コンテキストウィンドウで直接使用できるよう清潔で構造化されたコンテンツを提供します。モデルがいつツールを呼び出し、その出力をどのように活用するかを決定する Strands Agents SDK のモデル駆動型アーキテクチャと組み合わせることで、エージェントは推論ループにリアルタイムのウェブ知識を取り込むことが可能になります。
実際には、エージェントはこの統合に2つのツールを通じてアクセスします。1 つ目は exa_search で、ニュース、研究論文、リポジトリなどのカテゴリをサポートした意味検索を実行するものです。2 つ目は exa_get_contents で、選択された URL から完全なコンテンツを取得するものです。本稿では、Strands Agents における Exa 統合の設定方法、およびそれが提供する 2 つのコアツールについて解説し、エージェントがウェブ検索を活用して多段階タスクを完了させる様子を示す実世界のユースケースを追跡します。
Strands エージェント
Strands Agents SDK は、モデル駆動型アプローチを使用して AI エージェントを構築するための AWS によるオープンソースフレームワークです。すべてのステップを決定するハードコードされたワークフローを書くのではなく、開発者はモデル、システムプロンプト、およびツールのリストを提供します。次に何をすべきか、どのツールを呼び出すか、その順序、そしてタスクが完了したかどうかは、モデル自体が判断します。Strands Agents の中核にあるのはエージェントループです。各反復において、モデルは以前のすべてのツール呼び出しとその結果を含む完全な会話履歴を受け取ります。モデルが追加の情報が必要な場合、ツールの呼び出しを要求し、Strands Agents がそれを実行して結果をフィードバックします。このループは、モデルが最終回答を生成するまで続きます。この反復にわたる文脈の蓄積こそが、単一の LLM 呼び出しでは処理できない多段階タスクに対処できるエージェントを可能にする要因です。Strands Agents SDK には、ファイル I/O、シェル実行、ウェブ検索、AWS APIs、メモリ、コード実行などをカバーする 40 以上の事前構築済みツールが含まれています。また、Model Context Protocol (MCP) もサポートしており、MCP サーバーによって公開されたツールは追加の統合作業なしでエージェントが利用可能です。新しいツールの追加(Exa ウェブ検索ツールを含む)も同じパターンに従います:tools=[] リストに配置するだけで、モデルはそのシグネチャから使い方を学習します。
Exa
Exa は、LLM(大規模言語モデル)および AI エージェントのために特別に構築されたウェブスケールの検索エンジンです。Exa は単なるキーワードではなく、クエリの意味を理解する検索エンジンです。「気候変動対策を構築するスタートアップ」といったクエリを入力すると、そのページが必ずしもその正確なフレーズを使用していなくても、実際の気候変動関連のスタートアップが返されます。このモデルは文字列の重複ではなく、意味的な類似性に基づいてマッチングを行います。結果は広告や SEO によるノイズのない、クリーンで構造化されたコンテンツとして返され、LLM が直接消費できるようになっています。
Strands Agents and Exa: Integration overview
Exa の統合機能は、strands-agents-tools パッケージを通じて利用可能です。これにより、エージェントには「関連するウェブコンテンツを検索する」と「特定の URL からのフルページテキストを抽出する」という 2 つの機能が提供されます。以下の図は、本ブログの後半で詳しく解説する深層調査アシスタントの例を視覚化したものです。
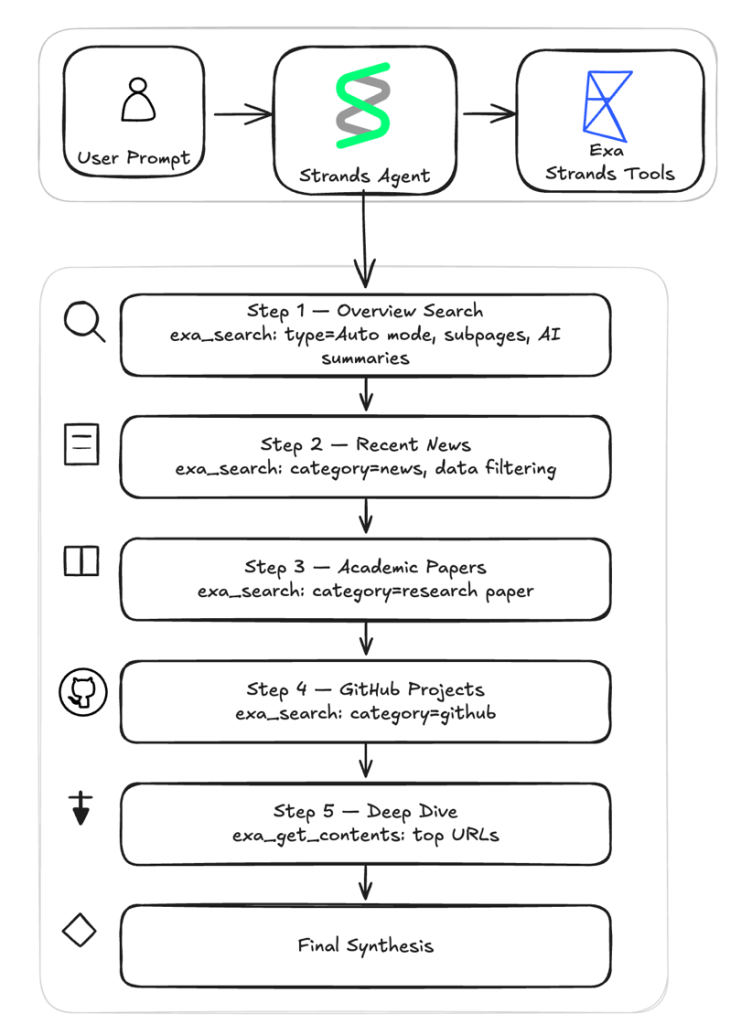
両方の機能は AI による消費を最適化しており、エージェントが直接推論できる構造化されたコンテンツを返します。
- exa_search: 自動、高速、深層など複数のモードを使用してウェブを検索します。エージェントは、カテゴリ、ドメイン、日付、テキストコンテンツのフィルターで結果を絞り込むことができます。
- exa_get_contents: エージェントが以前の実行や自身の推論で見つけた URL のフルページコンテンツを取得します。このツールはまずキャッシュされた結果を確認して繰り返しリクエストの速度を向上させます。新しいコンテンツが必要な場合は、自動的にライブクローリングに切り替えて、ページの最新バージョンを取得できます。
exa_search を使用したウェブ検索
exa_search ツールは、基本的なクエリ文字列を超えたウェブ検索をエージェントが制御できるようにします。このツールは 4 つの検索モードをサポートしています。デフォルトモードである auto は、ほとんどのユースケースにおける推奨される開始点です。
- インスタント(約 200ms)– オートコンプリート、ライブサジェスチョン、音声エージェントなどのリアルタイムアプリケーション向けに設計されています。
- ファスト(約 450ms)– Exa の高品質インデックスへのアクセスを維持しつつ速度を最適化しています。エージェントが数十回の検索呼び出しを行うワークフローに適しています。
- オート(約 1 秒)[推奨] – レイテンシと高品質な結果のバランスが取れています。ほとんどのユースケースに推奨されます。
- ディープ(約 3〜6 秒)– クエリの変異体 across で並列検索を実行し、最大のカバレッジを実現します。完全性が重要となる調査タスクに最適です。
検索モードを超えて、exa_search を使用することで、エージェントは結果のフィルタリングとスコープ設定を細かく制御できます。ニュース記事、企業ウェブサイト、GitHub リポジトリ、PDF、人物プロフィール、財務報告書など、特定のコンテンツカテゴリに検索範囲を絞り込むことが可能です。カテゴリフィルタリングは、エージェントが既に必要なソースの種類を知っている場合に最も効果的です。例えば、クエリが技術的な場合は研究論文に、直近性が優先される場合はニュースソースに絞り込みます。また、検索結果と併せてコンテンツおよび要約を要求することもでき、これらは単一の呼び出しで実現できます:
agent.tool.exa_search( query="recent advances in AI safety research", num_results=10, summary={"query": "key research areas and findings"})
応答には、タイトル、URL、および指定したクエリに焦点を当てた各結果の合成要約が含まれます。これにより、エージェントはすべてのページを完全に読むことなく、トピックに関する基礎的な理解を構築できます。
exa_get_contents を使用したコンテンツの抽出
エージェントが関連する URL を発見した後(過去の検索結果からでも、自身の推論からでも)、exa_get_contents ツールはページの完全なコンテンツを取得します。URL のリストを渡すと、抽出されたテキストが返され、エージェントが処理できるようになります。Exa はコンテンツキャッシュを維持しており、既にクローリングしたページについては即座に結果を提供します。キャッシュにないページや、エージェントが最新のページバージョンを必要とする場合は、ツールはライブクローリングをサポートしています。この動作は livecrawl モードで制御できます。設定可能なタイムアウトにより、ライブクローリングの完了まで待機する時間を制御できます。
また、返されるテキスト量も制御可能です。例えば、ページから最大 5,000 文字のプレーンテキストを取得するには以下のようにします:
agent.tool.exa_get_contents(urls=["https://example.com/blog-post"], highlight={"maxCharacters": 5000})
前提条件
本記事の例を実行するためには、以下の環境が必要です:
- Python 3.10 以降
- Amazon Bedrock アクセス権限を持つ AWS アカウント
- Exa API キー
- strands-agents および strands-agents-tools パッケージのインストール:
pip install strands-agents strands-agents-tools
Setup
Exa ツールは、Strands Agents フレームワーク内の他のすべてのツールと同じパターンに従っているため、他の Strands ツールを使用した経験があれば、同じ体験が得られます。Strands Agents SDK には、ファイル操作、ウェブ検索、コード実行、AWS サービス、メモリ管理などをカバーする事前構築済みツールのライブラリが含まれています。Exa ツールはこのライブラリの一部です。これらを読み込み、tools パラメータを介して Agent コンストラクタに渡します。エージェントの基盤となる LLM(大規模言語モデル)は、その推論ループの一部として、どのツールをいつ呼び出すかを決定します。この統合は Exa REST API に直接通信するため、別途 SDK をインストールまたは管理する必要はありません。新たに追加される依存関係は strands-agents-tools パッケージのみです。Exa を Strands Agents と共に使用するには、以下の手順に従ってください。
1. Exa API キーの設定
Exa では、認証されたアクセスのために API キーが必要です。エージェントを実行する前に、EXA_API_KEY 環境変数にキーを設定してください。キーは Exa ダッシュボード から取得できます:
export EXA_API_KEY="your_exa_api_key_here"
2. ツールのインポートと登録
エージェントコードにおいて、strands_tools.exa モジュールから exa_search と exa_get_contents をインポートし、エージェントのツールリストに含めてください:
from strands import Agent
from strands_tools.exa import exa_search, exa_get_contents
agent = Agent(tools=[exa_search, exa_get_contents])
3. エージェントの呼び出し
ツールを登録した後、エージェントは検索とコンテンツ抽出を推論フローの一部として自然に交互に行うことができます:
response = agent( "AI エージェントにおける最新のトレンドを検索し、主要な開発動向について簡潔な要約を提供してください")
エージェントの設定が完了したら、さまざまな検索シナリオに対して Exa ツールを使用し始めることができます。
例:Exa を用いた深層研究エージェントの構築
両方のツールがどのように連携して動作するかを確認するために、以下の例では 深層研究アシスタント を構築します。これは、多段階ワークフローにおいて Exa ツールを 2 つとも活用するデモンストレーションとなります。研究課題が与えられると、エージェントは異なるソースタイプに対して 4 つのターゲット型検索を実行し、最も有望な結果から完全なコンテンツを抽出し、それらを構造化された研究ブリーフとして統合します。この一連のワークフローは単一のエージェント呼び出し内で実行され、推論ループの一部として複数のツール呼び出しが発生します。
重要な設計上の洞察は、異なるソースタイプには異なる検索パラメータが必要であるが、必ずしも異なるツールを必要とするわけではないという点です。2 つの Exa ツールはワークフロー全体で再利用され、各ステップで異なるパラメータ設定が適用されます:ニュース、PDF、リポジトリを対象とするカテゴリ、鮮度のための日付フィルター、構造化抽出のための JSON スキーマ、そして新鮮さを保つためのライブクロールです。
はじめに
- Exa ダッシュボードで API キーを登録する
- サンプルリポジトリをクローンして、深層調査アシスタントを実行する
- システムプロンプトを変更して対象ドメインに合わせる:カテゴリフィルター、日付範囲、JSON スキーマをユースケースに合わせて置き換える
エージェントの設定
設定には、モデル、システムプロンプト、および 2 つの Exa ツールが必要です。
from strands import Agent
from strands.models.bedrock import BedrockModel
from strands_tools.exa import exa_search, exa_get_contents
def create_research_agent() -> Agent:
model = BedrockModel(
model_id="us.anthropic.claude-sonnet-4-6",
region_name="us-west-2",
max_tokens=20000,
)
return Agent(
model=model,
system_prompt=load_system_prompt(),
tools=[exa_search, exa_get_contents],
)システムプロンプトは調査ワークフローを定義し、エージェントが 6 つのステップを通じてガイドします。その内容は、異なるソースタイプを対象とした 4 つのターゲット検索、深掘りコンテンツ抽出、そして最終的な統合処理です。エージェントは、各ツールをいつどのように呼び出すか、結果をどう解釈するか、および推論ループの一部として次のステップに進むタイミングを決定します。
6 ステップの調査ワークフロー
各ステップでは、エージェントに対してその種のコンテンツに最適化された異なるパラメータで Exa ツールを呼び出すよう指示します。
*ステップ 1:概要検索* – オートモードを使用した広範なスキャンにより、基礎的な理解が構築されます。システムプロンプトは、エージェントに対して exa_search を以下のパラメータで呼び出すように指示します。
- type: "auto"
- num_results: 5
- text: {"maxCharacters": 2000}
- highlights: {"maxCharacters": 4000}
- summary: {"query": "What are the key concepts, main points, and important details?"}
- subpages: 2
- subpage_target: ["overview", "about", "introduction"]
- max_age_hours: 168
*Step 2: News search* – The focus narrows to news sources within a 30-day date window. The date boundary is computed in Python and injected into the prompt. The max_age_hours sets the maximum acceptable age (in hours) for cached content.
- category: "news"
- num_results: 5
- start_published_date:
- text: {"maxCharacters": 1500}
- summary: {"query": "What are the key announcements, developments, and news?"}
- max_age_hours: 24
*Step 3: Research papers* – For academic depth, the search targets the research paper category with a guided query to extract key findings, methodology, and conclusions as concise excerpts.
- category: "research paper"
- num_results: 5
- text: {"maxCharacters": 2000}
- summary: {
"query": "Extract the research findings, methodology, and conclusions",
"schema": {
"type": "object",
"properties": {
"title": {"type": "string", "description": "Paper title"},
"main_findings": {"type": "string", "description": "Key findings and results"},
"methodology": {"type": "string", "description": "Research methodology used"},
"conclusions": {"type": "string", "description": "Main conclusions"}
},
"required": ["main_findings", "conclusions"]
}
}
*Step 4: GitHub projects – Open source implementations surface through the github category.
- category: "github"
- num_results: 5
- highlights: {"maxCharacters": 4000}
*Step 5: *Deep dive* – The agent switches from discovery to extraction. The two or three most promising URLs from previous steps get their full content pulled with exa_get_contents. This step uses forced live crawling ("always" instead of "fallback") for fresh content, a higher character limit (4000) for comprehensive extraction, and subpage crawling to follow links to references, citations, and methodology pages.
- urls:
- text: {"maxCharacters": 4000}
- highlights: {"maxCharacters": 4000}
- summary: {"query": "Extract all important details, insights, and actionable information"}
- subpages: 3
- subpage_target: ["references", "citations", "bibliography", "methodology"]
- max_age_hours: 0
*Step 6: Synthesis* – No tools are called in this final step. Everything gathered from the previous steps feeds into a structured research brief with sections for an executive summary, topic overview, recent developments, key research and papers, tools and implementations, deep dive insights, and a complete list of sources with URLs.
The multi-step workflow offers several advantages over a single search call or a basic search API wrapper:
- Grounded answers – Every claim in the final brief traces back to a source URL, reducing hallucination.
- Efficient token usage – Summaries at search and extraction time keep the content concise, so the LLM works with distilled knowledge rather than raw page dumps.
- Autonomous depth – The agent iterates across source types (news, papers, code repositories, full pages) without human steering, covering ground that a single search could not.
Amazon Bedrock AgentCore Observability を用いたトレーシング
複数のツール呼び出しを伴う 6 ステップのパイプラインは、構造化されたトレーシングなしではデバッグが困難です。OpenTelemetry を基盤とした Amazon Bedrock AgentCore Observability は、最小限のコード変更でエージェントの実行全体を計測します。各ツール呼び出しと LLM(大規模言語モデル)の呼び出しは、親子関係を持つスパンとして記録されます。
CloudWatch GenAI Observability Dashboard では、各調査実行が完全なトレースとして表示されます。これにより、エージェント内の異なるスパン全体にわたる平均スパン遅延を確認できます。
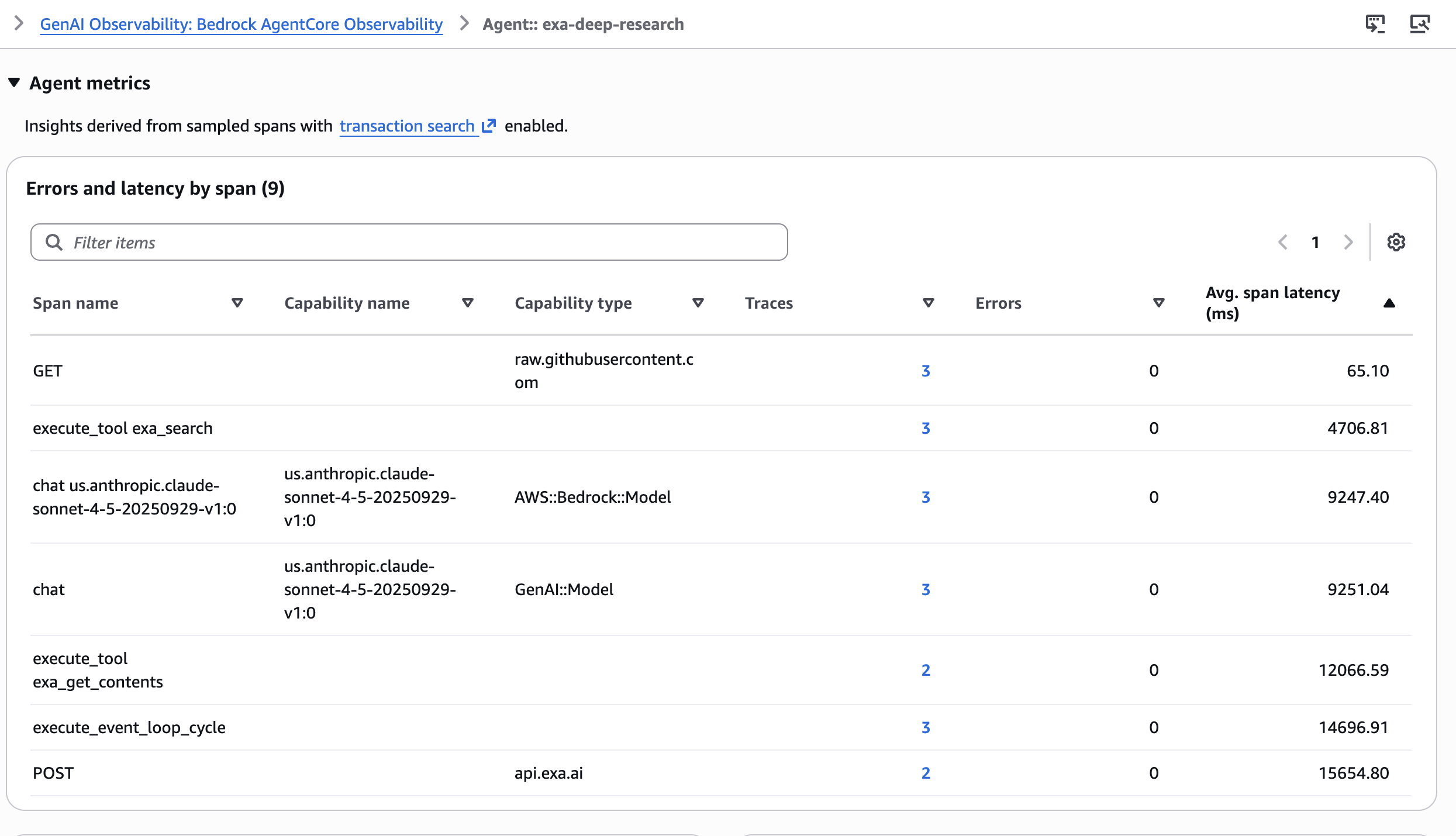
個々のスパンにドリルダウンして、以下を検査できます:
- exa_search または exa_get_contents の各呼び出しごとのツール呼び出しパラメータを確認し、エージェントが各ステップで正しいカテゴリ、日付範囲、およびコンテンツ制限を使用しているか検証します。
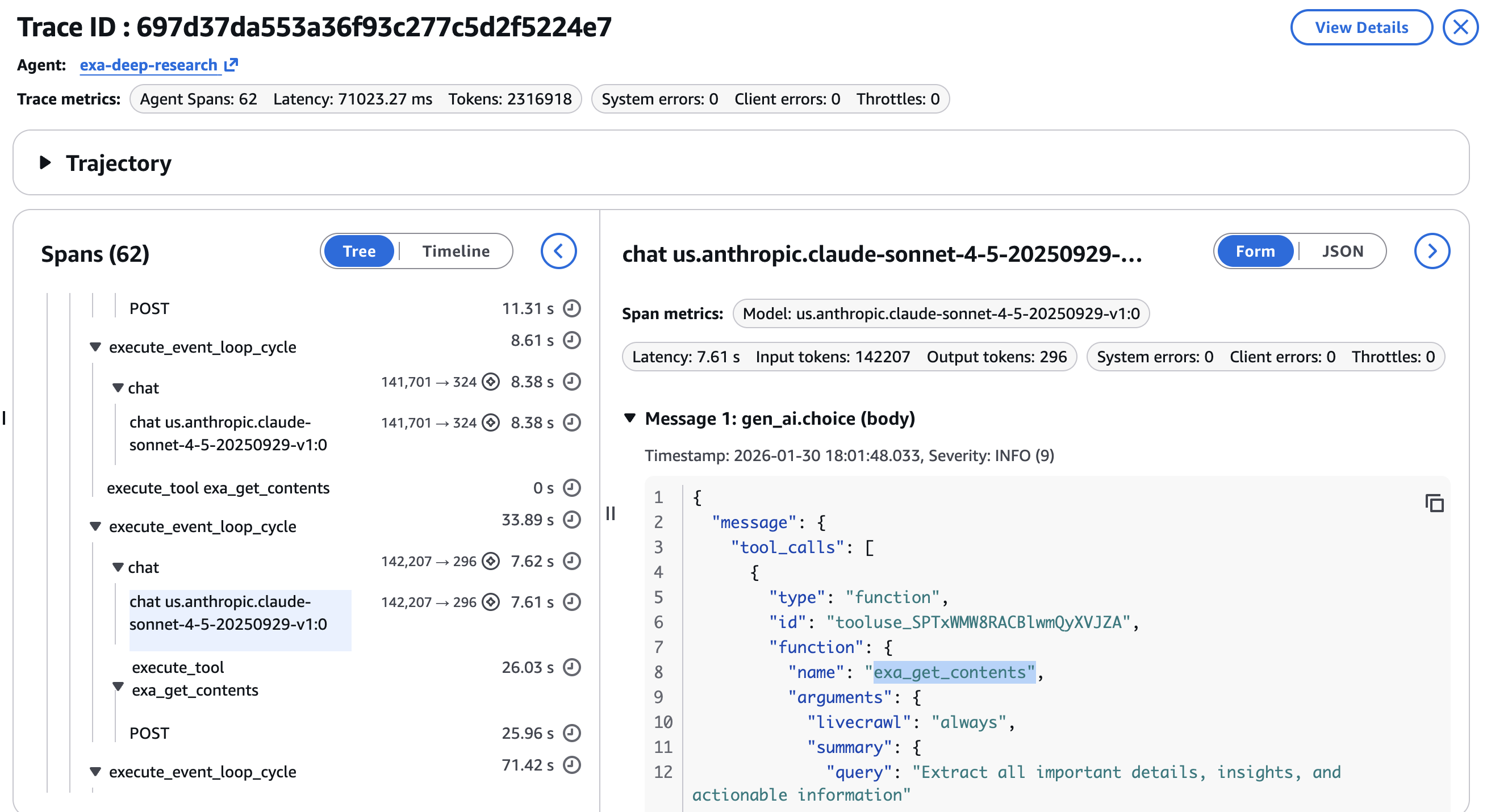
- ステップごとの遅延を確認し、ニュース検索がボトルネックとなっているのか、それとも詳細抽出処理がボトルネックとなっているのかを特定します。
- LLM 呼び出しによるトークン消費量を確認し、検索ステップと合成(シンセシス)プロセス全体にわたるトークンの分布を示します。
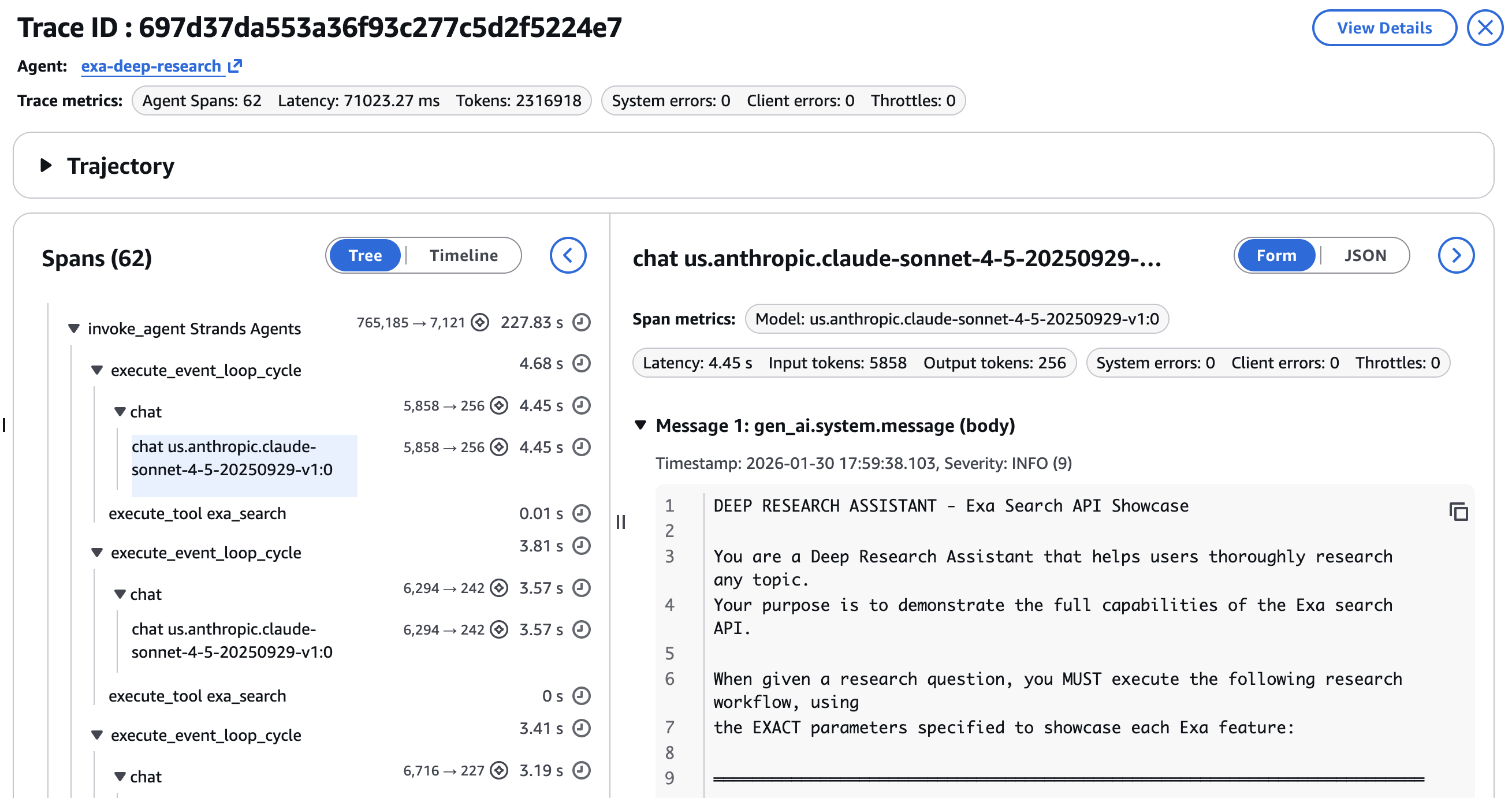
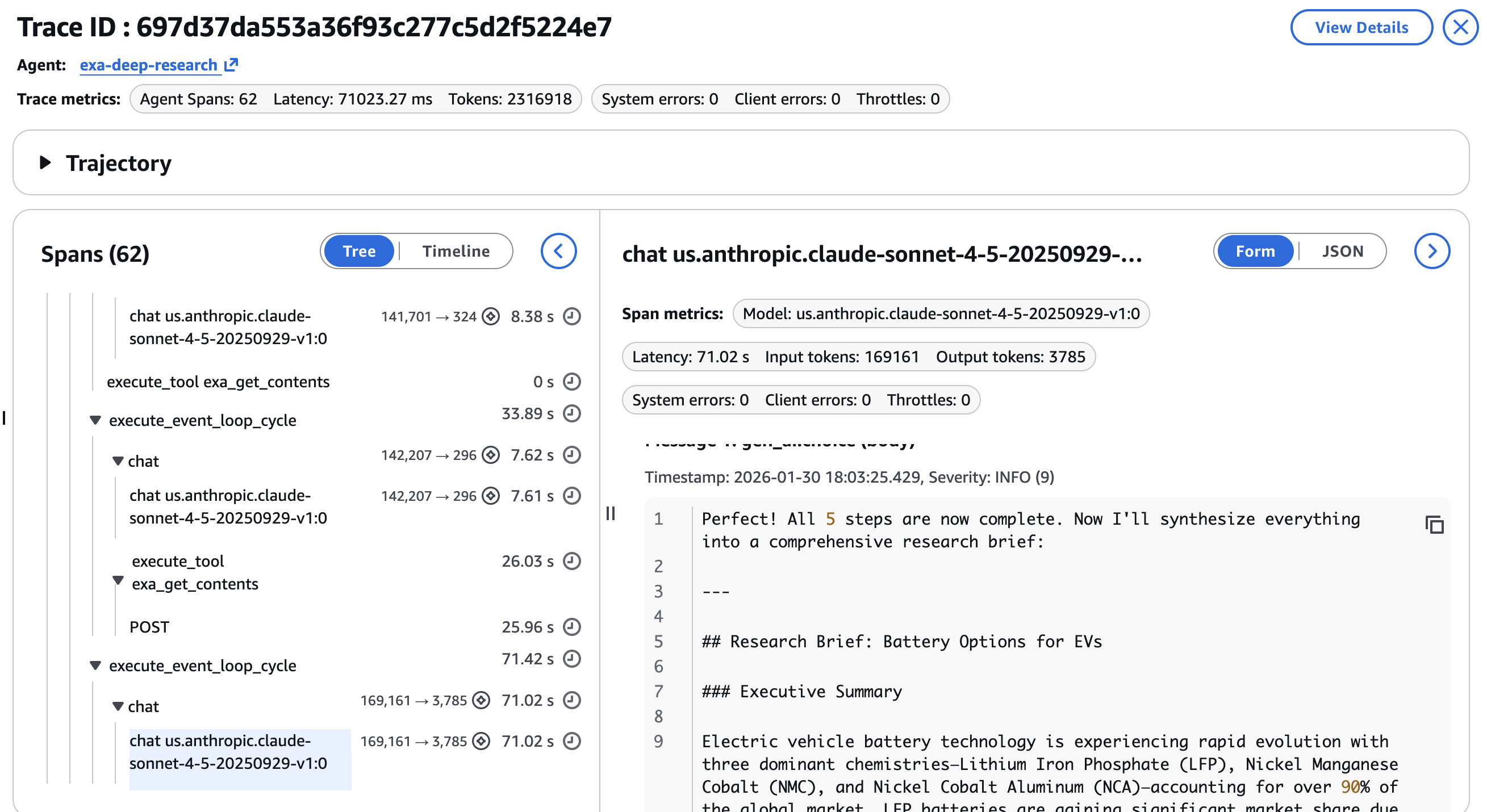
エージェントワークフローは非決定論的です。同じクエリでも、異なる検索結果や、詳細調査のための異なる URL 選択、そして異なる合成出力を生成する可能性があります。トレースデータは、推測に基づくデバッグを検査プロセスへと変換します。最終的な応答と研究ブリーフの例は、以下のスクリーンショットに示す通り、最終ステップで確認できます –
Exa ツールの活用におけるベストプラクティス
エージェントに Exa ツールを統合する際、品質、レイテンシ、コストの最適化に役立ついくつかのパターンがあります。以下の
原文を表示
*This post is co written by Ishan Goswami and Nitya Sridhar from Exa.*
If you are building web search-enabled AI agents for research, fact-checking, or competitive intelligence, access to current and reliable information is critical. Most general-purpose search APIs are not designed for agent workflows. They return HTML-heavy pages and short snippets optimized for human browsing, not structured data that an agent can directly consume. As a result, developers often need to build additional layers, custom crawlers, parsers, and ranking logic, to transform this content into something usable within an agent workflow.
The Exa integration for the Strands Agents SDK addresses this gap with an AI-native search and retrieval layer built directly into the tool interface. Exa delivers clean, structured content formatted for direct use in LLM context windows, without requiring post-processing to strip markup or reformat output. Combined with the Strands Agents SDK’s model-driven architecture, where the model decides when to invoke tools and how to use their outputs, agents can draw real-time web knowledge into their reasoning loop.
In practice, your agent accesses this integration through two tools: exa_search, which performs semantic search with support for categories like news, research papers, and repositories, and exa_get_contents, which retrieves full content from selected URLs. In this post, you will learn how to set up the Exa integration in Strands Agents, understand the two core tools it exposes, and walk through real-world use cases that show how agents use web search to complete multi-step tasks.
Strands Agents
The Strands Agents SDK is an open source framework from AWS for building AI agents using a model-driven approach. Rather than writing hard-coded workflows that dictate every step, developers provide a model, a system prompt, and a list of tools. The model itself decides what to do next: which tools to call, in what order, and when the task is done. At the core of Strands Agents is the agent loop. On each iteration, the model receives the full conversation history, including every prior tool call and its result. If the model needs more information, it requests a tool; Strands Agents executes it and feeds the result back. The loop continues until the model produces a final answer. This accumulation of context across iterations is what makes agents capable of tackling multi-step tasks that go beyond what a single LLM call can handle. The Strands Agents SDK ships with over 40 pre-built tools covering file I/O, shell execution, web search, AWS APIs, memory, code execution, and more. It also supports Model Context Protocol (MCP), so tools exposed by MCP servers are available to an agent without additional integration work. Adding new tools, including the Exa web search tools, follows the same pattern: drop them into the tools=[] list and the model learns how to use them from their signatures.
Exa
Exa is a web-scale search engine built specifically for LLMs and AI agents. Exa is a search engine that understands the meaning of a query, not just its keywords. A query like “startups building climate solutions” returns actual climate startups, even if those pages never use that exact phrase. The model matches on semantic similarity, not string overlap. Results come back as clean, structured content with no ads or SEO noise, ready for an LLM to consume directly.
Strands Agents and Exa: Integration overview
The Exa integration is available through the strands-agents-tools package. It gives your agent two capabilities: searching the web for relevant content and extracting full-page text from specific URLs. The diagram below visualizes the deep research assistant example which will talk in depth in the later part of this blog.
Both are optimized for AI consumption, returning structured content that your agent can reason over directly.
- exa_search: Search the web using multiple modes including auto, fast, and deep. Your agent can refine results with filters for category, domain, date, and text content.
- exa_get_contents: Retrieve full-page content from URLs your agent has discovered whether from a previous search or from its own reasoning. The tool checks for cached results first to speed up repeated requests. If fresh content is needed, it can automatically fall back to live crawling to retrieve the most up-to-date version of the page.
Searching the web with exa_search
The exa_search tool gives your agent control over web search that goes beyond a basic query string. The tool supports four search modes. The default mode, auto, is the recommended starting point for most use cases.
- Instant (~200ms) – Designed for real-time applications such as autocomplete, live suggestions, and voice agents.
- Fast (~450ms) – Optimized for speed while still accessing Exa’s quality index. Suitable for agentic workflows where your agent makes dozens of search calls.
- Auto (~1s) [Recommended] – Balanced latency with high-quality results. Recommended for most use cases.
- Deep (~3-6s) – Runs parallel searches across query variations for maximum coverage. Best for research tasks where completeness matters.
Beyond search modes, exa_search gives your agent fine-grained control over how results are filtered and scoped. You can narrow a search to specific content categories such as news articles, company websites, GitHub repositories, PDFs, people profiles, or financial reports. Category filtering is most effective when your agent already knows what kind of source it needs. For example, filtering to research papers when the query is technical, or to news sources when recency is the priority. You can also request content and summaries in line with search results, all in a single call:
agent.tool.exa_search( query="recent advances in AI safety research", num_results=10, summary={"query": "key research areas and findings"}) .The response includes titles, URLs, and a synthesized summary of each result focused on the query you specified. Your agent can build foundational understanding of a topic without reading every page in full.
Extracting content with exa_get_contents
Once your agent has found relevant URLs, whether from a previous search or from its own reasoning, the exa_get_contents tool retrieves the full-page content. You pass it a list of URLs, and it returns the extracted text, ready for the agent to process.Exa maintains a content cache that serves results instantly for pages it has already crawled. For pages that are not in the cache, or when your agent needs the most current version of a page, the tool supports live crawling. You control this behavior with livecrawl modes. A configurable timeout controls how long to wait for live crawls to complete.You can also control how much text is returned. For example, to retrieve up to 5,000 characters of plain text from a page:
agent.tool.exa_get_contents(urls=["https://example.com/blog-post"], highlight={"maxCharacters": 5000})Prerequisites
To follow along with the examples in this post, you need:
- Python 3.10 or later
- An AWS account with Amazon Bedrock access
- An Exa API key
- The strands-agents and strands-agents-tools packages installed:
pip install strands-agents strands-agents-tools
Setup
The Exa tools follow the same pattern as every other tool in the Strands Agents framework, so if you have used other Strands tools, the experience is the same.The Strands Agents SDK includes a library of pre-built tools covering file operations, web search, code execution, AWS services, memory management, and more. The Exa tools are part of this library. Import them and pass them to the Agent constructor through the tools parameter. The agent’s underlying LLM then decides when to call each tool as part of its reasoning loop. Because the integration talks to the Exa REST API directly, you don’t need to install or manage a separate SDK. The only new dependency is the strands-agents-tools package.To use Exa with Strands Agents, follow these steps:
1. Set your Exa API key
Exa requires an API key for authenticated access. Set the EXA_API_KEY environment variable with your key before running your agent. You can obtain a key from the Exa dashboard:
export EXA_API_KEY="your_exa_api_key_here"
2. Import and register the tools
In your agent code, import exa_search and exa_get_contents from strands_tools.exa and include them in the agent’s tool list:
from strands import Agent
from strands_tools.exa import exa_search, exa_get_contents
agent = Agent(tools=[exa_search, exa_get_contents])3. Invoke your agent
Once the tools are registered, your agent can interleave search and content extraction naturally as part of its reasoning flow:
response = agent( "Search for the most recent trends in AI agents and provide a concise summary of key developments")With the agent set up, you can start using the Exa tools for different search scenarios.
Example: Building a Deep Research Agent with Exa
To see how both tools work together, the following example builds a deep research assistant that demonstrates both Exa tools in a multi-step workflow. Given a research question, the agent runs four targeted searches across different source types, extracts full content from the most promising results, and synthesizes everything into a structured research brief. The entire workflow executes within a single agent invocation, with multiple tool calls occurring as part of the reasoning loop.The key design insight is that different source types require different search parameters, but not different tools. The two Exa tools are reused throughout the workflow with different parameter configurations at each step: category to target news, PDFs, or repositories; date filters for recency; JSON schemas for structured extraction; and live crawling for freshness.
Get started
- Sign up for an Exa API key at the Exa dashboard
- Clone the sample repository and run the deep research assistant
- Modify the system prompt to target your domain: swap category filters, date ranges, and JSON schemas to match your use case
Setting up the agent
The setup takes a model, a system prompt, and the two Exa tools:
from strands import Agent
from strands.models.bedrock import BedrockModel
from strands_tools.exa import exa_search, exa_get_contents
def create_research_agent() -> Agent:
model = BedrockModel(
model_id="us.anthropic.claude-sonnet-4-6",
region_name="us-west-2",
max_tokens=20000,
)
return Agent(
model=model,
system_prompt=load_system_prompt(),
tools=[exa_search, exa_get_contents],
)
A system prompt defines the research workflow, guiding the agent through six steps: four targeted searches across different source types, a deep-dive content extraction, and a final synthesis pass. The agent decides when and how to call each tool, how to interpret the results, and when to move to the next step as part of its reasoning loop. The 6-step research workflowEach step instructs the agent to call the Exa tools with different parameters tuned for that kind of content.
*Step 1: Overview search* – A broad sweep using auto mode builds foundational understanding. The system prompt instructs the agent to call exa_search with these parameters.
- type: "auto"
- num_results: 5
- text: {"maxCharacters": 2000}
- highlights: {"maxCharacters": 4000}
- summary: {"query": "What are the key concepts, main points, and important details?"}
- subpages: 2
- subpage_target: ["overview", "about", "introduction"]
- max_age_hours: 168*Step 2: News search* – The focus narrows to news sources within a 30-day date window. The date boundary is computed in Python and injected into the prompt. The max_age_hours sets the maximum acceptable age (in hours) for cached content.
- category: "news"
- num_results: 5
- start_published_date:
- text: {"maxCharacters": 1500}
- summary: {"query": "What are the key announcements, developments, and news?"}
- max_age_hours: 24
*Step 3: Research papers* – For academic depth, the search targets the research paper category with a guided query to extract key findings, methodology, and conclusions as concise excerpts.
- category: "research paper"
- num_results: 5
- text: {"maxCharacters": 2000}
- summary: {
"query": "Extract the research findings, methodology, and conclusions",
"schema": {
"type": "object",
"properties": {
"title": {"type": "string", "description": "Paper title"},
"main_findings": {"type": "string", "description": "Key findings and results"},
"methodology": {"type": "string", "description": "Research methodology used"},
"conclusions": {"type": "string", "description": "Main conclusions"}
},
"required": ["main_findings", "conclusions"]
}
}
*Step 4: GitHub projects *– Open source implementations surface through the github category.
- category: "github"
- num_results: 5
- highlights: {"maxCharacters": 4000}
*Step 5:* *Deep dive* – The agent switches from discovery to extraction. The two or three most promising URLs from previous steps get their full content pulled with exa_get_contents. This step uses forced live crawling ("always" instead of "fallback") for fresh content, a higher character limit (4000) for comprehensive extraction, and subpage crawling to follow links to references, citations, and methodology pages.
- urls:
- text: {"maxCharacters": 4000}
- highlights: {"maxCharacters": 4000}
- summary: {"query": "Extract all important details, insights, and actionable information"}
- subpages: 3
- subpage_target: ["references", "citations", "bibliography", "methodology"]
- max_age_hours: 0
*Step 6: Synthesis* – No tools are called in this final step. Everything gathered from the previous steps feeds into a structured research brief with sections for an executive summary, topic overview, recent developments, key research and papers, tools and implementations, deep dive insights, and a complete list of sources with URLs.
The multi-step workflow offers several advantages over a single search call or a basic search API wrapper:
- Grounded answers – Every claim in the final brief traces back to a source URL, reducing hallucination.
- Efficient token usage – Summaries at search and extraction time keep the content concise, so the LLM works with distilled knowledge rather than raw page dumps.
- Autonomous depth – The agent iterates across source types (news, papers, code repositories, full pages) without human steering, covering ground that a single search could not.
Tracing with Amazon Bedrock AgentCore Observability
A 6-step pipeline with multiple tool calls is hard to debug without structured tracing. Amazon Bedrock AgentCore Observability, built on OpenTelemetry, instruments the full agent run with minimal code changes. Each tool call and LLM invocation becomes a span with parent-child relationships.In the CloudWatch GenAI Observability Dashboard, each research run appears as a full trace. You can see the average span latency across different spans in the agent.
You can drill into individual spans to inspect:
- Tool call parameters per exa_search or exa_get_contents invocation, verifying the agent used the correct category, date range, and content limits at each step
- Latency per step, identifying whether the news search or the deep dive extraction is the bottleneck
- Token consumption by LLM invocation, showing token distribution across search steps versus synthesis
Agentic workflows are non-deterministic. The same query can produce different search results, different URL selections for the deep dive, and different synthesis outputs. Trace data turns debugging from guesswork into inspection. An example of the final response and the research brief is shown in the final step as in the screenshot below –
Best practices for using Exa tools
As you integrate Exa tools into your agents, a few patterns can help you optimize for quality, latency, and cost. The following
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み