BI を超える:Amazon QuickSight のデータセット Q&A 機能が次世代の意思決定を推進する仕組み
Amazon QuickSight の新機能「Dataset Q&A」は、自然言語による即座のデータ分析を可能にし、BI チームへの依存や手作業によるデータ取得のボトルネックを解消することで、意思決定プロセスを革新する。
キーポイント
従来の BI ダッシュボードの限界突破
既存のダッシュボードは既知の質問には優れているが、予期せぬ多角的な問いには対応できず、BI チームへの依存や待機時間が発生する課題を解消する。
自然言語による即時分析の実現
ユーザーは専門知識なしで自然言語で質問し、数秒以内に正確な回答を得られるため、データ探索のスピードが劇的に向上する。
PII 保護とコンテキストの活用
個人情報(PII)を安全に扱いつつ、定性データを分析に組み込むことで、データの背後にある「なぜ」を解明し、実用的な洞察を得られる。
ワークフローの非破壊的統合
既存のダッシュボードや運用プロセスを中断・変更することなく、対話型コンバージョンとして機能するため、現場への導入障壁が低い。
影響分析・編集コメントを表示
影響分析
この機能は、データドリブンな意思決定における「BI チームのボトルネック」という普遍的な課題を解決する重要な転換点です。従来の静的レポートから動的な対話型分析への移行を加速させ、組織全体のデータリテラシーと意思決定速度を底上げする可能性があります。特に大規模組織において、複雑な問いに対する迅速な回答が必要となる場面で大きなインパクトを発揮すると予測されます。
編集コメント
BI チームの負荷軽減と意思決定のスピードアップを両立させる、実用的な AI 活用事例です。特に「既存資産を壊さずに導入できる」という点は、大企業における採用の鍵となるでしょう。
業界を問わずビジネスリーダーは、チームが日常業務で実行する際の共通の真実源として運用ダッシュボードに依存しています。しかし、ダッシュボードは既知の質問に答えるために構築されたものです。チームがさらに探索したり、アドホックな、多次元の、あるいは予期せぬ質問をしたりする場合、ボトルネックに直面します。BI チームに新しいビューを構築したりレポートを更新したりしてもらうために数時間から数日待たされるのです。Dataset Q&A 機能はこのギャップを埋めます。自然言語で質問し、秒単位で正確な回答を得ることができます。新しいダッシュボードの構築も、待ち行列への並ぶ必要もありません。既存のデータセットとの対話型会話を行うだけであり、チームがすでに依存しているダッシュボードを妨げることはありません。
課題
AWS の顧客は、新技術の評価や生産環境の問題トラブルシューティング、クラウド変革の計画において、迅速で根拠のあるサポートを期待しています。この体験をスケールして提供するために、AWS の技術フィールドチームは複雑な運用上の質問に対する即座の回答が必要です。顧客需要はどこで増加しているのか?適切な専門知識を持つチームはどれか?顧客とのエンゲージメントは十分に速く解決されているか?そして、顧客成果に影響を与える可能性のある新たなギャップはどこにあるのか?
AWS の技術分野コミュニティ(TFC)プログラムは、年間を通じて数十の専門技術ドメインにわたって、数十万件もの顧客エンゲージメントを支援しています。プログラムのリーダーや現場チームにとって、これらのエンゲージメントの動向を理解することは、単に指標を追跡するだけでなく、適切なスキルを適切な場所に、必要なタイミングで配置して顧客の成功を支えることを確実にすることです。しかし、こうしたエンゲージメントの規模が大きくなるにつれ、リーダーが答えなければならない質問の複雑さも増大しました。従来の静的なダッシュボードは、洗練された多次元の問いかけに耐えられなくなってきました。ステークホルダーたちは、顧客をよりよく支援する方法を明確に把握するために、異なるシステムの間を行き来し、手動でデータセットを相互参照するという迷宮のような状況に直面していました。データの背後にある「なぜ」を理解することは、必ずしも難しい技術的な問題ではなく、ワークフロー上の課題です。リーダーの質問は BI エンジニアにとって中断となり、エンジニアは計画された作業を一時停止して集計を実行し、回答を返しますが、その回答が必然的に次の質問を生み出すことになります。実際に失われる時間は、クエリ自体にあるのではなく、質問を持つ人と、それを答えるためのツールを持つ人との間の引き渡しプロセスにあります。リーダーたちは、組織的・技術的な境界を越えた複雑でリアルタイムな質問を投げかけていました。
データは存在していましたが、プログラムリーダーのニーズのあらゆるニュアンスを予測できない硬直した可視化の背後に「閉じ込められて」いることが多くありました。さらに、個人識別情報(PII)が存在するため、データを行動可能にする文脈そのものである特定の質的詳細が、安全に表面化させるのが制限され困難なままでした。
対話型分析の未来:TARA の紹介
このギャップを埋めるため、AWS は TARA(Technical Analysis Research Agent)を開発しました。TARA は AWS の内部分析ニーズのために構築されていますが、私たちが使用したデータセット Q&A の機能は、同様の課題に直面している Quick の顧客にも利用可能です。Specialist Data Lens (SDL) チームによって開発された TARA は、Quick の カスタムチャットエージェント 機能を活用した AI パワー型の分析アシスタントです。TARA は、自然言語を通じて複数の統合データセット、ライブシステム API、および専門的な研究エージェントを探索するために使用できる統一された対話型インターフェースとして機能します。MCP を使用して構造化データセットと外部システム、ドメイン固有の研究エージェントを安全に接続することで、TARA は定量的指標と質的文脈の間のギャップを埋めます。これにより、リーダーは現場で起きていることの真実に定量的指標を結びつけることができ、リアルタイムの運用コンテキストによって分析インサイトを豊かにしつつ、機密性の高い PII が保護されることを確保できます。
TARA の対話型分析機能を進化させるために、セマンティッククエリ生成とインサイト提供の基盤として Dataset Q&A 機能を採用しました。本稿ではその道のりと、ビジネスユーザーがデータとより自然な形で対話することによる影響について探ります。セマンティック定義をデータセットに直接埋め込み、SQL 生成をデータのビジネス意味に基づかせることで、Dataset Q&A はインサイトの品質と信頼性を大幅に向上させました。この強化により、回答精度は 48% 以上改善し、クエリの失敗はほぼゼロまで減少、分析にかかる時間は数時間から数分に短縮されました。
Dataset Q&A の紹介
2026 年第 1 四半期、SDL チームは Dataset Q&A(データセット対話)機能の早期採用者となりました。これにより、トピックやダッシュボードを構築する必要なく、自然言語で質問し、データから直接回答を受け取る能力が解放されました。その核心は、クエリ実行時に自然言語を SQL に変換する点にあり、これは別個に管理されるトピックではなく、データセット自体に存在する意味定義に基づいています。つまり、フィールドの説明、類義語、データセットの指示など、データのビジネス上の意味は一度定義されれば、あらゆる場所で再利用されます。
SDL チームにとって、これは画期的な突破でした。プログラムのリーダーたちはついに、BI チームがビジネス用語の定義を更新したり新しいフィールドマッピングを設定したりするのを待たずに、実際に重要な質問を投げかけることができるようになりました。つまり、深い運用上の質問、高度なトレンド分析、そして自由な探索もすべて、正確かつオンデマンドで回答できるようになったのです。
この実現を可能にしたのはアーキテクチャの違いです。クエリが事前に設定されたフィールド定義やビジネスルールを経由してルーティングされるのではなく、Dataset Q&A はユーザーの意図を動的に解釈し、関連するデータセットを特定し、クエリ実行時に改善された SQL を生成します。これにより、システムには、以前のトピックベースモデルでは処理できなかった複雑で多次元の分析に対応する柔軟性が与えられました。
SDL チームは早期テストに参加し、その結果は即座に現れました。クエリの精度を測定するために、代表的な実世界シナリオのセット全体において、TARA が生成した回答を手動検証された SQL クエリおよびアナリストがレビューした期待される出力と比較する構造化されたグランドトゥルーステストを実施しました。3 つの改善点が際立っていました:
- 精度:グランドトゥルースベンチマークにおけるクエリの精度は約 48% 向上しました。
- 信頼性:以前は失敗していた複雑な分析質問が実行可能となり、クエリ障害はほぼゼロまで減少しました。
- 速度:応答時間が数分(約 2〜3 分)から数秒(約 10 秒)に短縮され、90% 以上の削減を実現し、ニアリアルタイムのデータ探索を可能にしました。
これらの成果により、TARA は単なる便利なレポート作成アシスタントから、AWS プログラムリーダーのための信頼性の高い意思決定支援ツールへと変貌しました。
始め方
環境で直接データセット Q&A を実装する前に、以下の準備を完了してください:
- AWS アカウント。設定手順については、「AWS の開始」をご覧ください。
- アカウント内で Amazon Quick Enterprise Edition が有効化されており、少なくとも 1 つのエンタープライズユーザーとプロフェッショナルユーザーが登録されていること。詳細は「Amazon Quick Sight エディションおよび価格」をご覧ください。
- データセットやチャットインターフェースなどの Amazon Quick Sight の概念に精通していること。始めるには Amazon Quick Sight ドキュメントを参照してください。
技術的深掘り:TARA アーキテクチャ
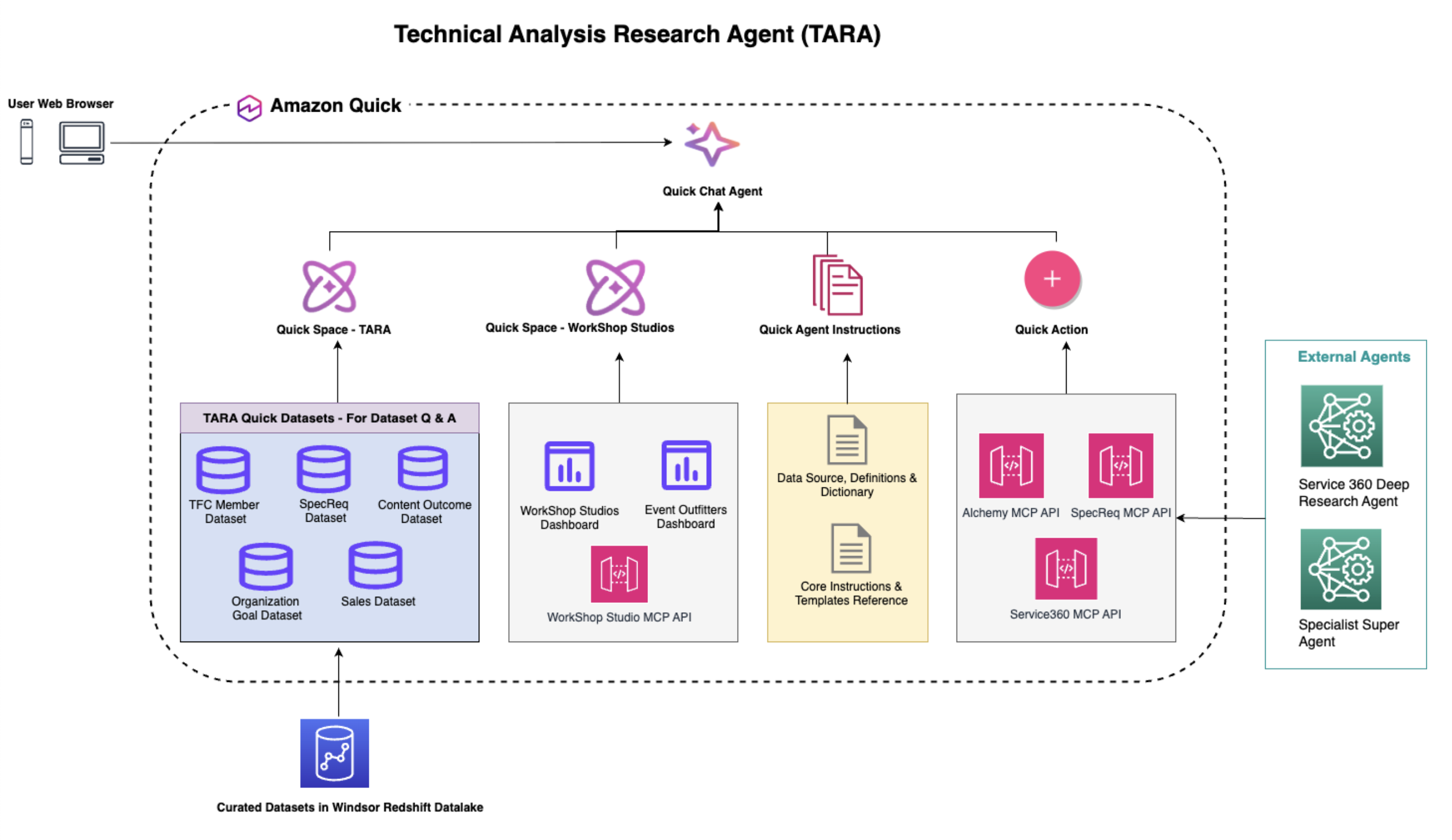
システムアーキテクチャとコネクテッド・インテリジェンス
TARA のアーキテクチャは Amazon Quick に構築されており、構造化された分析、運用システム、組織のナレッジを単一の会話型インターフェースに統合することを目的としています。この体験の中心には、ユーザーのエントリーポイントでありながら、リクエストのオーケストレーションハブとしても機能する「Amazon Quick Chat Agent」があります。直感的な自然言語インターフェースを通じて、AWS のリーダーたちはツールを切り替えることなく、キュレーションされたビジネスデータセット、ライブシステム API、および専門的な研究エージェントにアクセスできます。
このアーキテクチャは、4 つの密接に統合されたレイヤーに従って構成されています:
1. ユーザーアクセスとオーケストレーション層
ユーザーは Web ブラウザを使用して「Amazon Quick Chat Agent」を通じて TARA と対話します。このチャットインターフェースは、会話型分析の主要なクライアントとして機能し、AWS アカウントを通じた厳格な認証を行い、リクエストをより広範な TARA 環境へルーティングします。これは、クエリが構造化されたダッシュボード、ガバナンスされたデータセット、運用 API、または外部エージェントのいずれを使用して回答されるべきかを判断するインテリジェントなオーケストレーション層として機能します。
- データセット Q&A とワークスペース統合レイヤー
TARA の中核となる分析基盤は、Windsor Amazon Redshift データレイクにホストされ、Amazon Quick Spaces を通じて提供されるキュレーション済みデータセットによって支えられています。Quick Spaces は、チーム間での発見と再利用のためにデータを安全な論理ドメインに整理します。TARA の重要な機能の一つは、Amazon Quick の「データセット Q&A」機能を活用している点です。これにより、ユーザーは自然言語を用いて運用指標、メンバーのパフォーマンス、専門家のリクエスト、コンテンツの結果、組織目標、および販売インサイトなどを照会できます。データセットを TARA に紐付けられた Quick Spaces に直接接続することで、システムはスキーマやダッシュボード、クエロロジックを理解する必要なく、信頼できるインサイトを即座に利用可能にします。
主要な TARA Space には、運用およびパフォーマンス分析のための基盤となるビジネスデータセットがホストされており、別の Workshop Studio Space では、ダッシュボードと MCP(Model Context Protocol)の統合を通じてワークショップやイベントの実施データをアクセスできます。このクロススペース設計は、Amazon Quick が所有権とガバナンスを維持しつつ、組織境界を超えてデータ資産を安全に連合させる方法をどのように実現しているかを示しています。
- カスタムエージェント指示によるセマンティックインテリジェンス**** TARA のアーキテクチャにおける重要な差別化要因は、慎重に設計されたカスタムエージェント指示によって駆動されるセマンティックインテリジェンス層です。この層はビジネスロジック、ドメイン用語、指標解釈ルール、およびビジネスセマンティクスを定義し、回答が文脈的に正確で一貫性のあるものとなるようにします。単に生きたスキーマやテーブル名に依存するのではなく、TARA は指示駆動型の推論を用いて、ユーザーの意図をビジネス用語として解釈します。具体的には以下のようになります。
- 「アクティブメンバー」は、メンバーシップティアではなくステータスフラグに基づいて解釈される
- スペシャリストのリクエスト解決率は、キャンセルされたリクエストを除く完了したエンゲージメントのみを使用して計算される
- 「今月」とは、現在の暦上のものであるのではなく、完全なデータが存在する直近の月をデフォルトとする
これらの指示セットは、ビジネス言語と基盤となるデータ構造の間のセマンティック翻訳層として機能します。これは、経営陣向けのインサイトに対する信頼を構築し、ユーザー間での一貫性があり信頼性の高い回答を促進するために不可欠です。
- 連携システムおよびアクションレイヤー****構造化された分析を超えて、TARA は Amazon Quick Actions および MCP (Model Context Protocol) インテグレーションを通じて、運用ワークフローや深層調査へと拡張します。このアクションレイヤーにより、TARA は AWS チームがすでに使用しているシステムに直接接続することが可能となり、単なるレポート作成アシスタント以上の役割を果たすようになります。
現在のインテグレーションには以下のものが含まれます:
- Alchemy:優先度の高い顧客ユースケースの発見を支援し、AWS およびパートナーによるソリューション資産、技術検証リソース、販売プレイブックをキュレーションします。
- SpecReq:専門家のリクエスト受付、ルーティング、追跡、および技術サポートエンゲージメントにおける履行を支援します。
- Service 360 Deep Research Agent(深層調査エージェント):製品機能要望、専門家リクエストの傾向、顧客の課題点を深層分析し、標準的なダッシュボードを超えた洞察を発見します。
TARA は将来の拡張性も考慮して設計されており、計画中の統合には以下が含まれます:
- Specialist Super Agent(専門スーパーエージェント):30 以上の技術ドメインにわたってオンデマンドで技術専門知識を提供する AI エージェント群のフレームワーク。
- InstructAI:収益、パイプライン、パフォーマンスに関する洞察のためのワークフロー自動化およびビジネスインテリジェンスサービス。
この階層型アーキテクチャにより、TARA は従来の分析アシスタントを超えた存在となります。これは、管理されたデータ、ネイティブの対話型分析、意味推論、ライブな運用コンテキスト、そして専門的な AI 機能を統合した接続されたインテリジェンスシステムであり、AWS のリーダーがより迅速かつ根拠のある意思決定を行えるよう支援します。
ソリューション概要
TARA は、直接のデータセット Q&A(クエリーアンドアンスワー)機能を通じて、複数の構造化データを統一された対話型分析体験に統合します。実装は以下の 4 つの段階から構成されます:
ステージ 1:カスタムチャットエージェントの設定
TARA は、ビジネスセマンティクス、ドメイン専門知識、および応答動作を定義する独自の手順で構成されたカスタム Amazon Quick チャットエージェントです。前述のアーキテクチャセクションで説明した通り、これらの手順により、ユーザーからの質問が SDL のビジネスロジコンテキストで一貫して解釈されるようになります。後述のステージで設定される「スペース(Spaces)」と「アクション(Actions)」は、このエージェントにリンクされます。
ステージ 2:データセットの準備と統合
中核となる分析用データセットは、Amazon Quick Space に直接接続されています。これを設定するには、Amazon Quick のサイドパネルにある「スペース」セクションへ移動し、新しいスペースを作成します。スペースの名前を付け、その目的を定義した後、利用可能なデータ資産から関連する Amazon Quick Sight データセットを追加します。TARA の場合、これはメンバーシップ、能力追跡、専門家のリクエスト解決およびパフォーマンス指標、ドメインレベルのレポート、個人貢献の詳細にわたる 7 つのデータセットを含みます。これらのデータセットは、独自のスキーマ、列定義、およびデータ型を維持しており、別途セマンティックモデリングを行う必要はありません。データセットは既存のスケジュールで更新されるため、TARA は常に最新データをクエリします。
ステージ 3:MCP を用いたアクション統合
構造化データセットを超えて TARA の機能を拡張するため、外部システムは Amazon Quick Actions を通じて接続されます。これらのアクションは異なるシステムの MCP サーバーと連携し、クエリ実行時に生きた運用データや文脈情報を取得できるようにします。これを実現するには、Amazon Quick の「Integrations」セクションで新しい Action を作成し、対象の MCP サーバーに接続した上で、その Action を TARA チャットエージェントにリンクさせる必要があります。
ステージ 4:自然言語クエリ処理
ユーザーが質問を入力すると、Dataset Q&A エンジンは自然言語による意図を解釈し、接続されたデータセットに対して直接最適化された SQL クエリを生成します。このエンジンは、実行時に動的に関連するデータセットを特定し、結合条件やフィルタリング条件を決定し、集計処理を適用してクエリを構築します。運用システムからのデータが必要な文脈的な質問については、TARA が自動的に適切な MCP Action へリクエストをルーティングします。例えば、専門家のリクエスト解決率に関する質問は構造化データセットに対して SQL を生成しますが、最近の顧客インタラクションの詳細を求めるリクエストは、生きた文脈情報を取得するために関連する MCP インテグレーションにルーティングされます。
TARA の実働例:**
技術ドメインのパフォーマンスを評価する必要があるドメインリーダーを想定してください。従来、これは複数のダッシュボードタブを移動し、フィルターを適用し、データを手作業でつなぎ合わせることを意味しており、時間のかかるプロセスでした。TARA を使用すれば、この一連のワークフローが単一の会話で完結します。
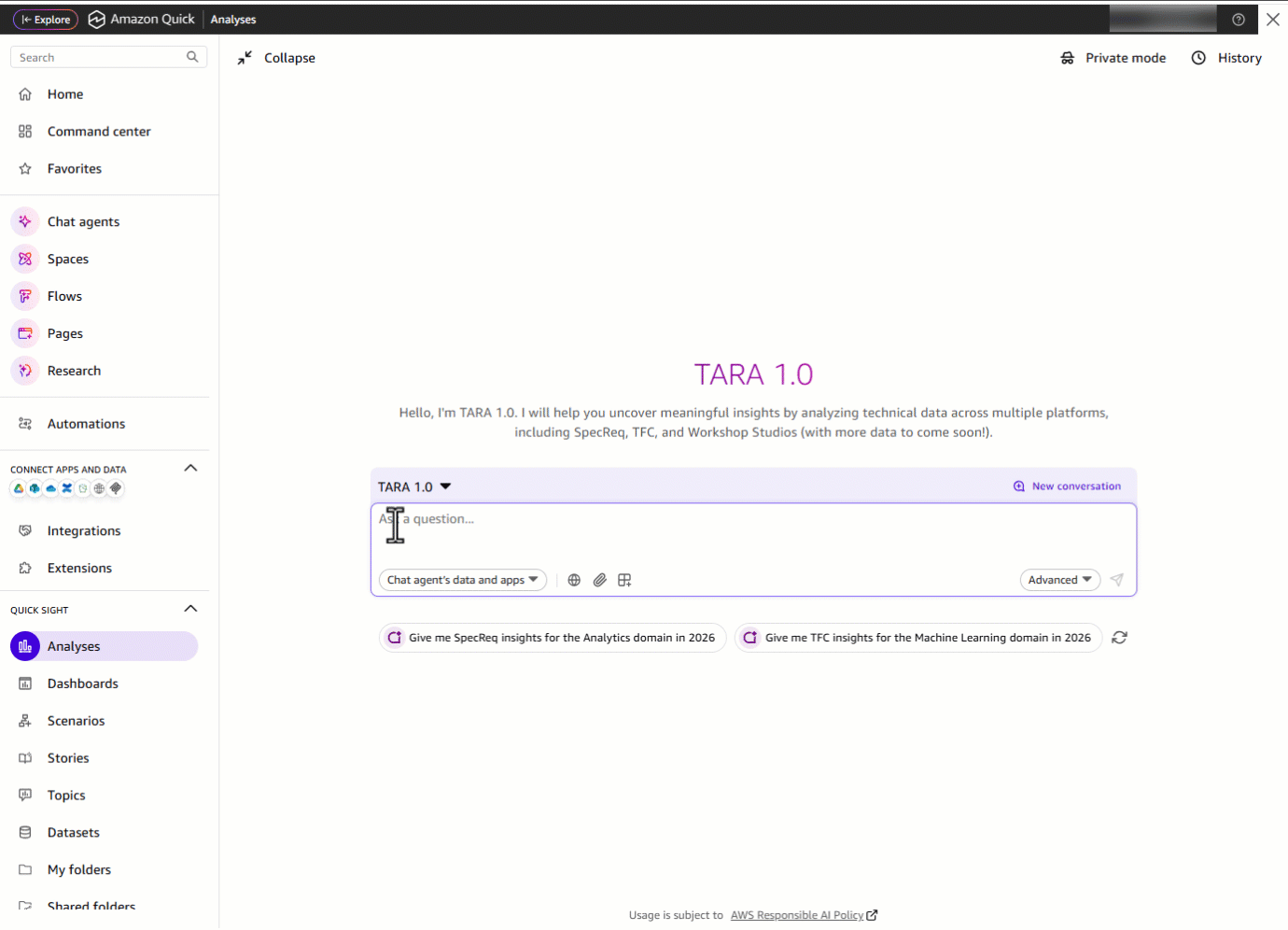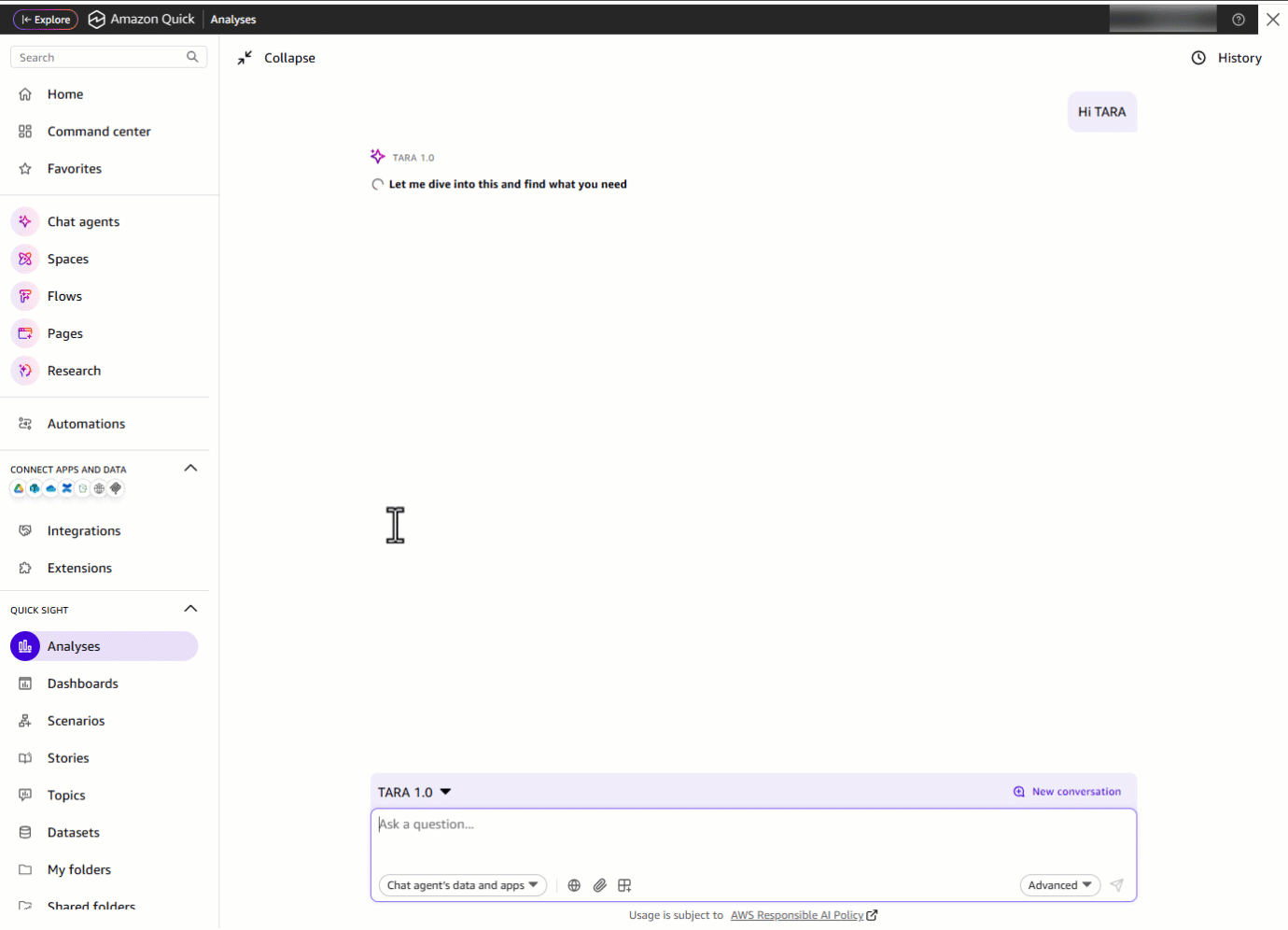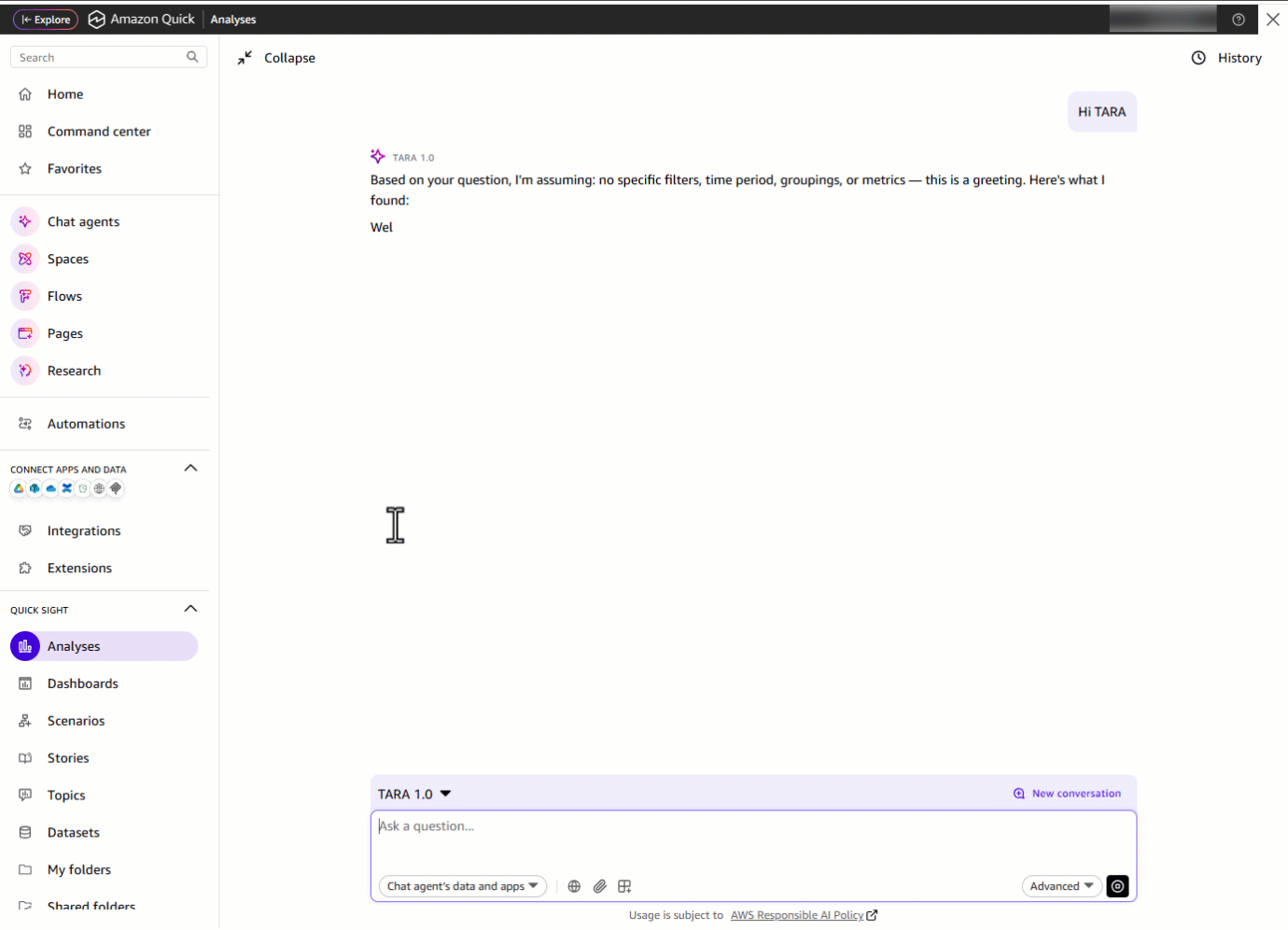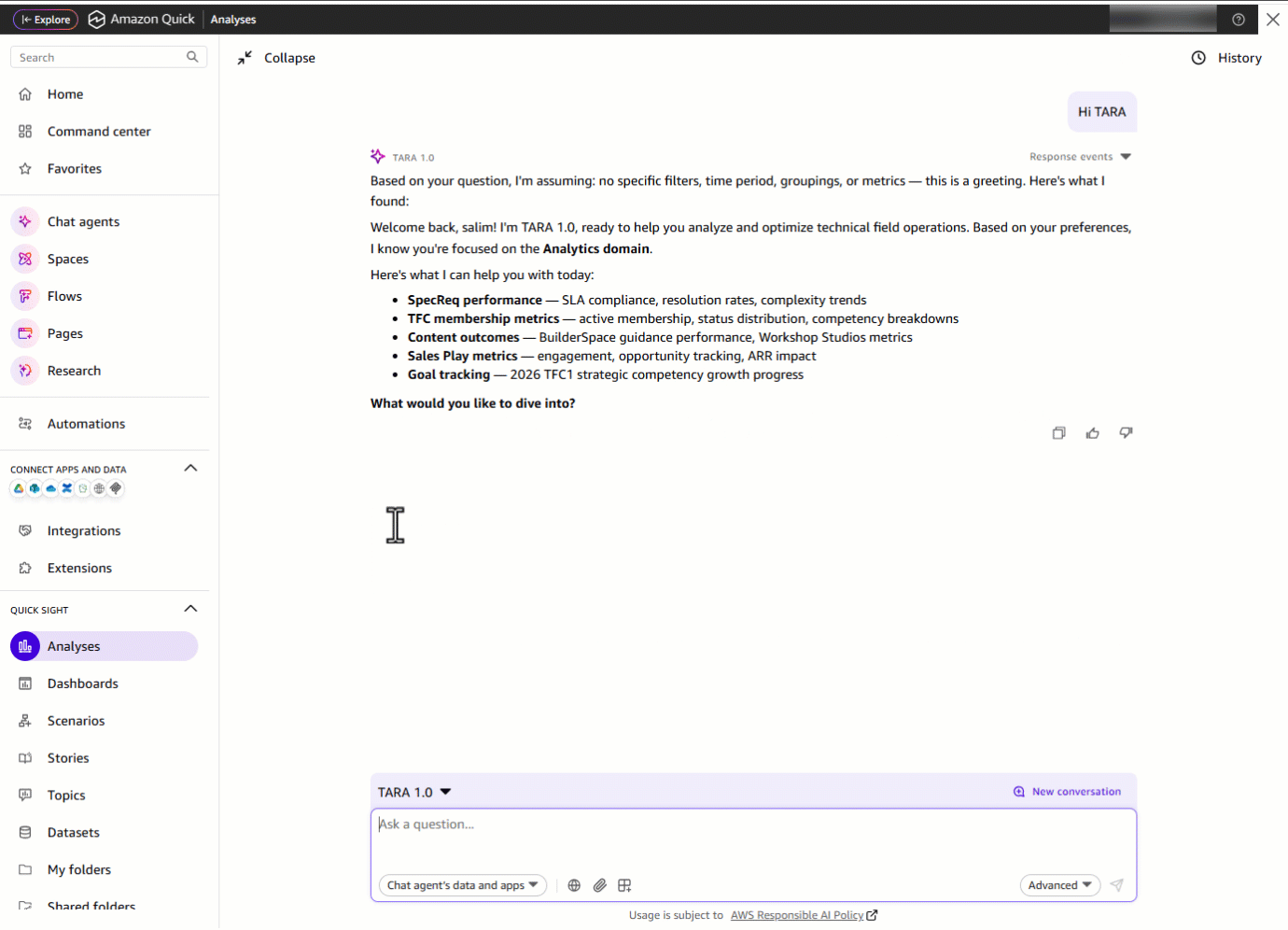
ドメインリーダーは TARA を開き、「Hi TARA!」と入力します。TARA は挨拶をすると同時に、利用可能な主要なデータ領域を即座に提示し、さらにそれらすべてを一つの場所からアクセス可能にします。
「Hi TARA!」と入力する
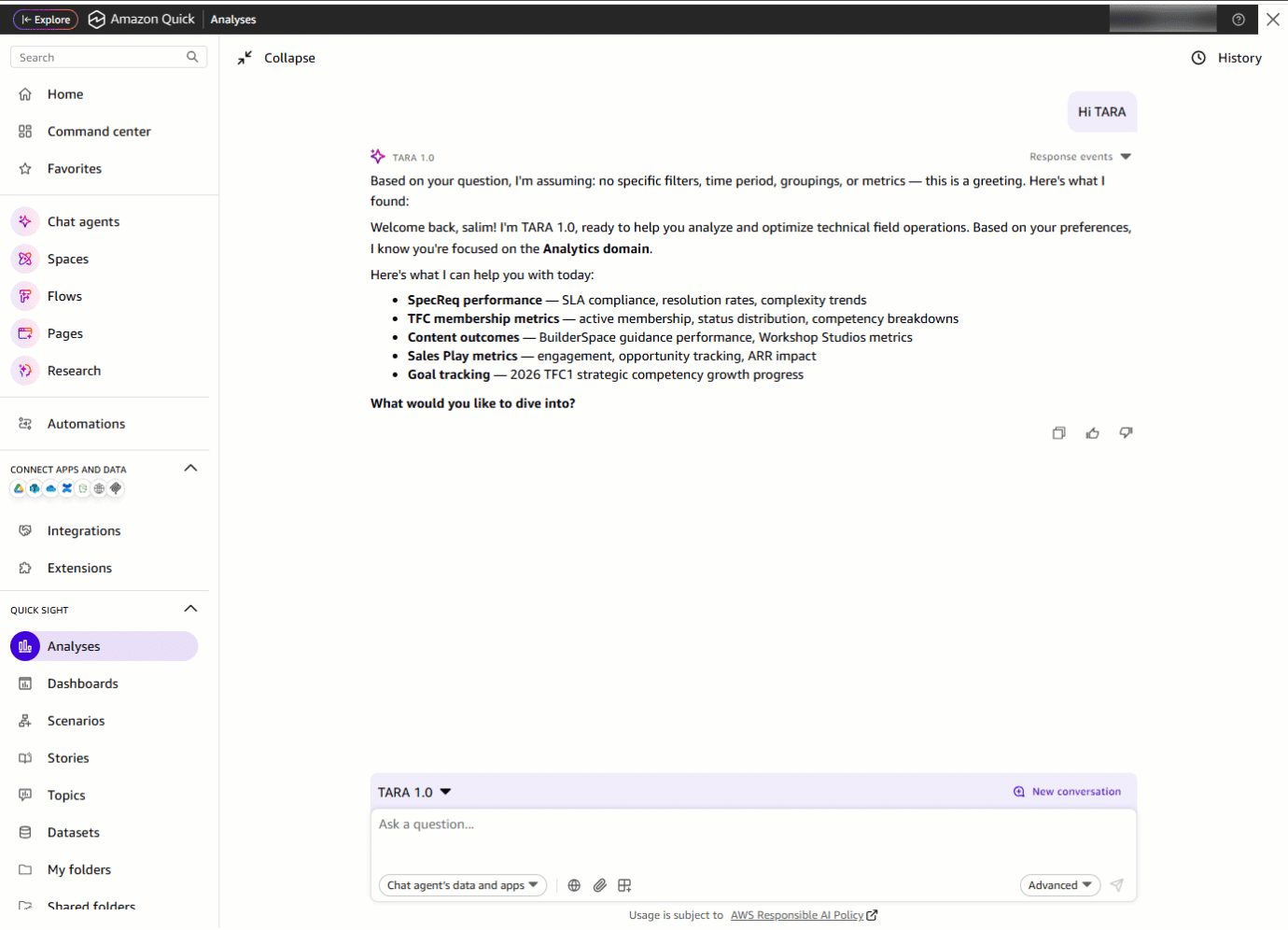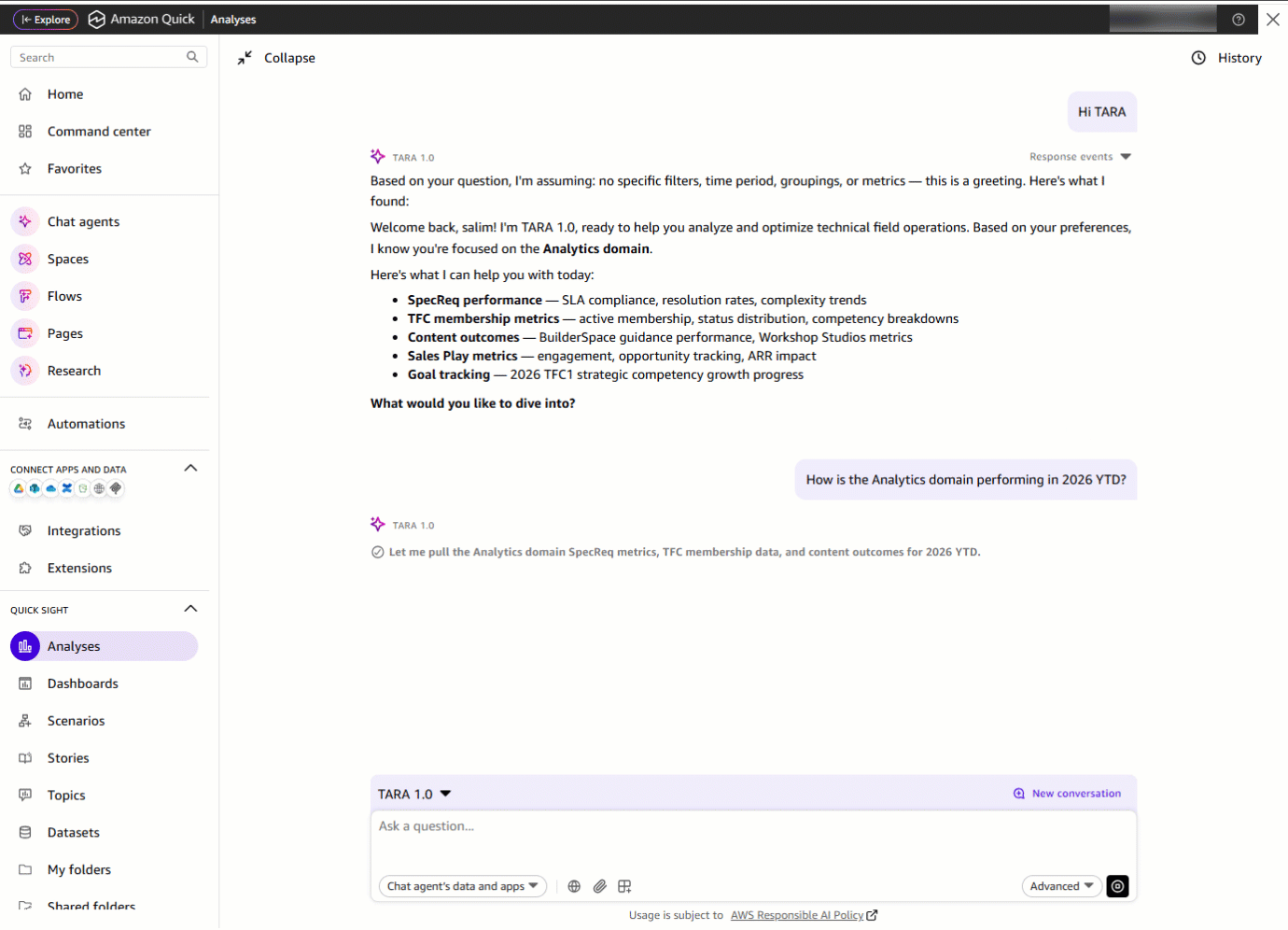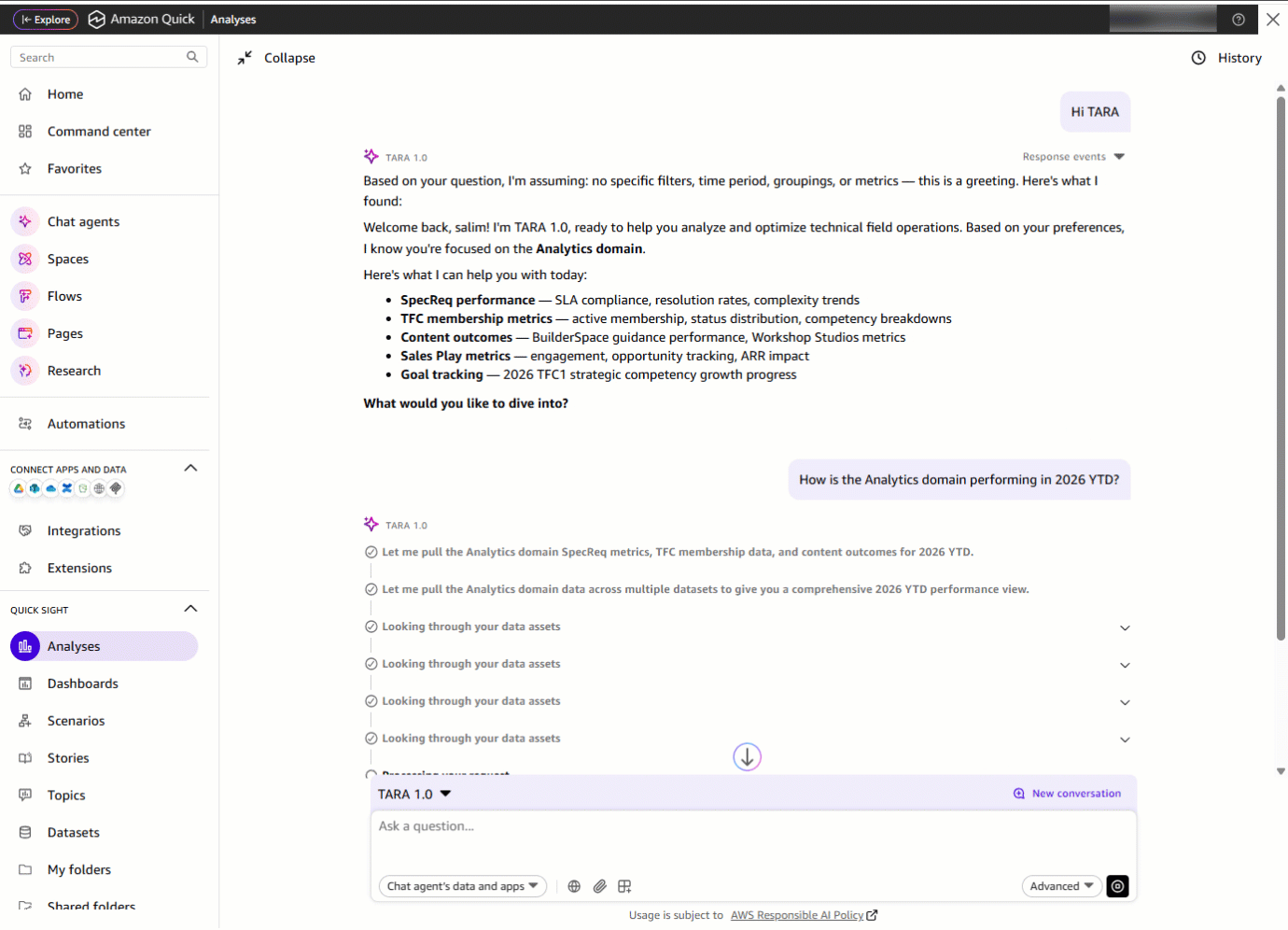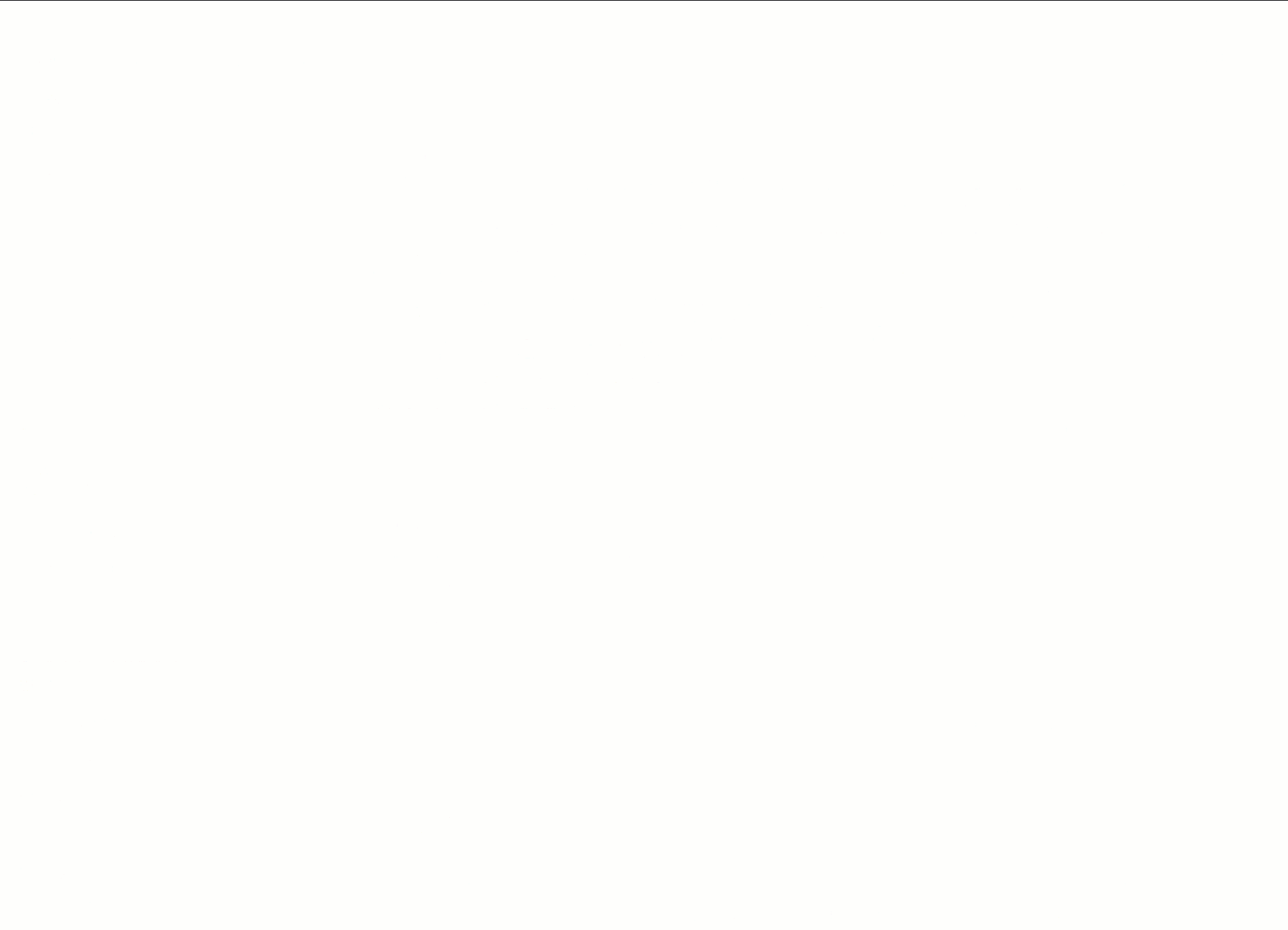
次に、彼らは「2026 年の YTD(年初来)におけるアナリティクスドメインのパフォーマンスはどうですか?」と質問します。TARA は単一のプロンプトで複数のデータセットにわたるメトリクスを抽出します。以前は別々のダッシュボードを開く必要があったものが、今では数秒で届く単一の統合されたレスポンスとなりました。
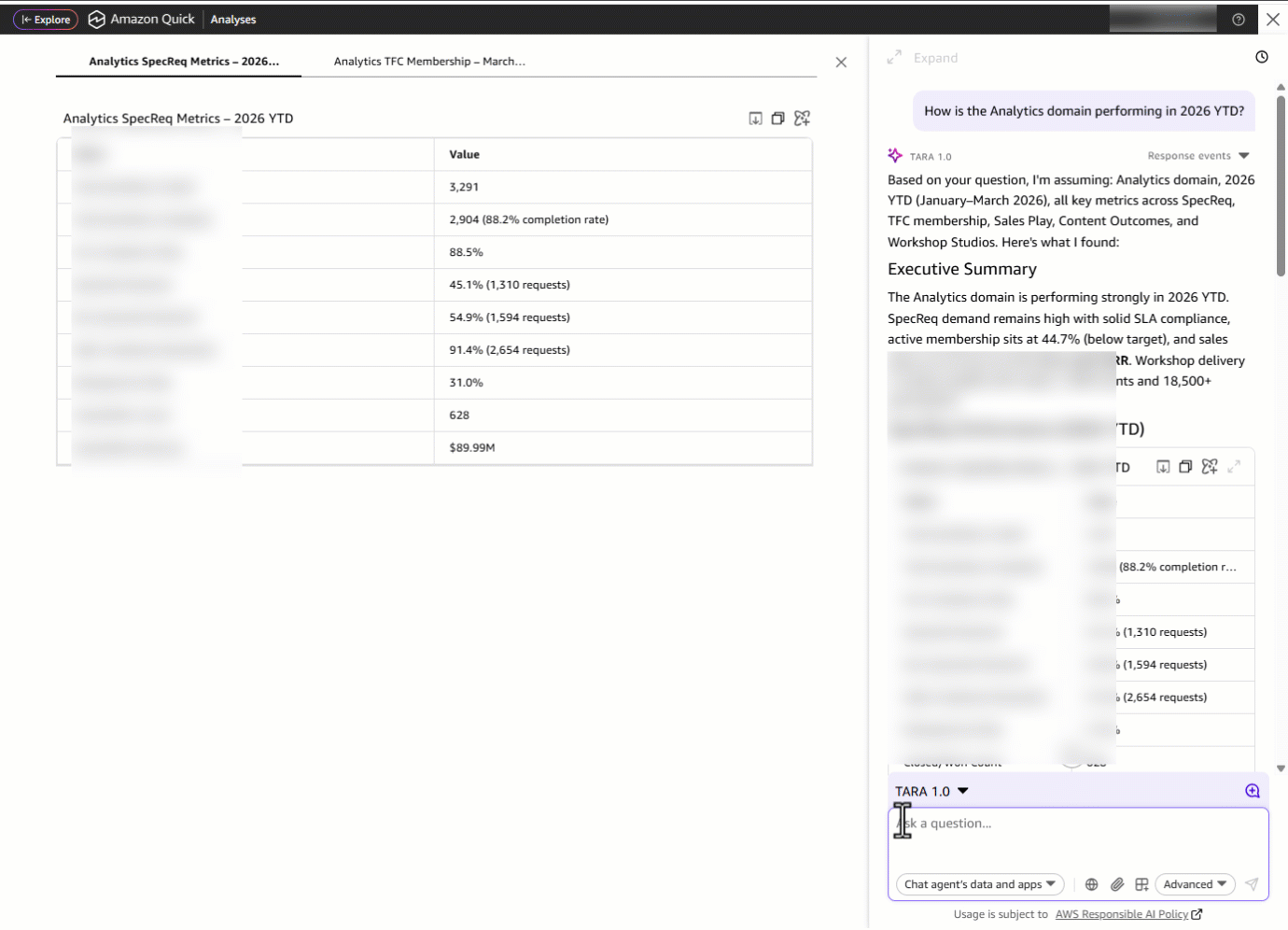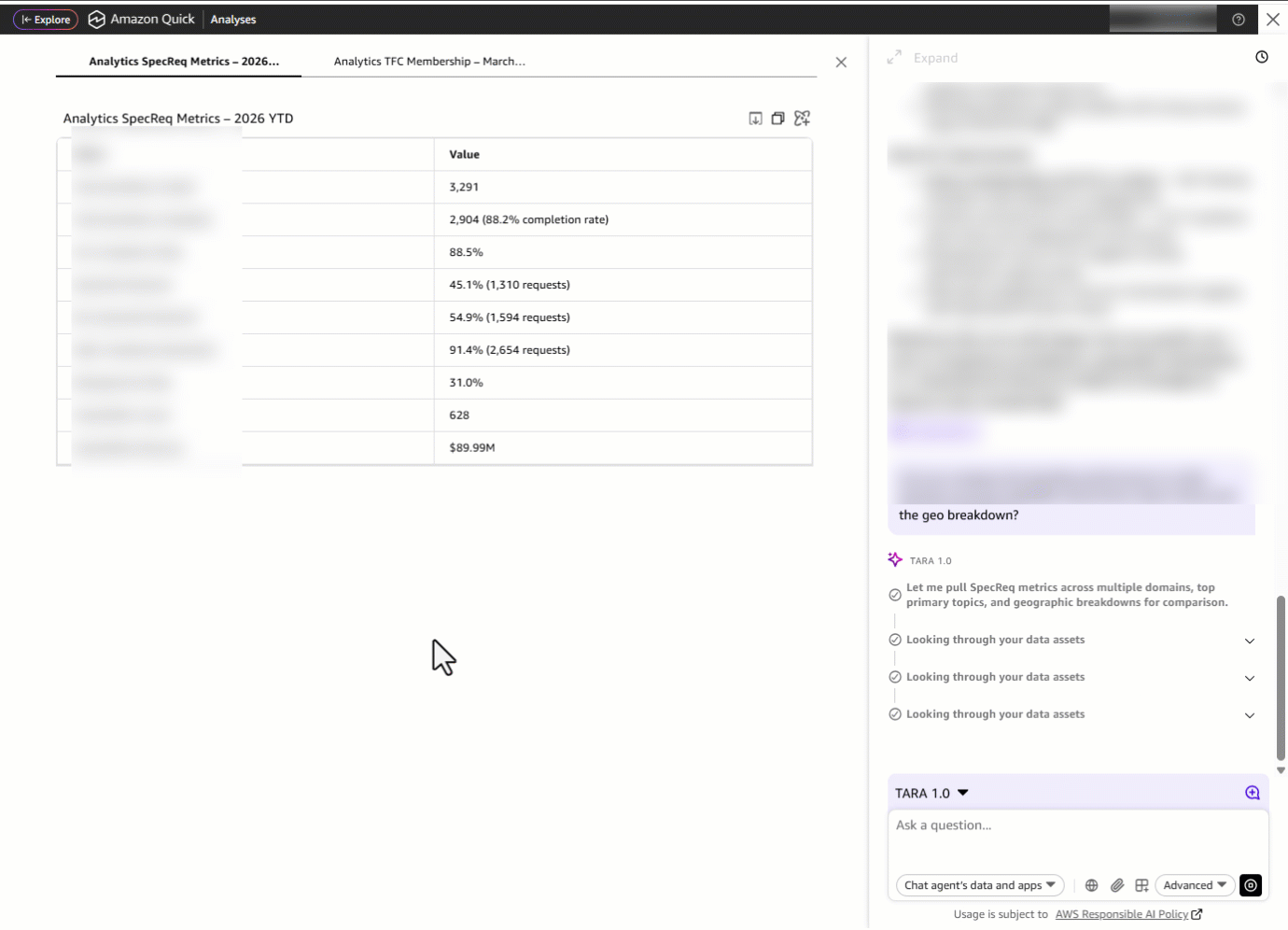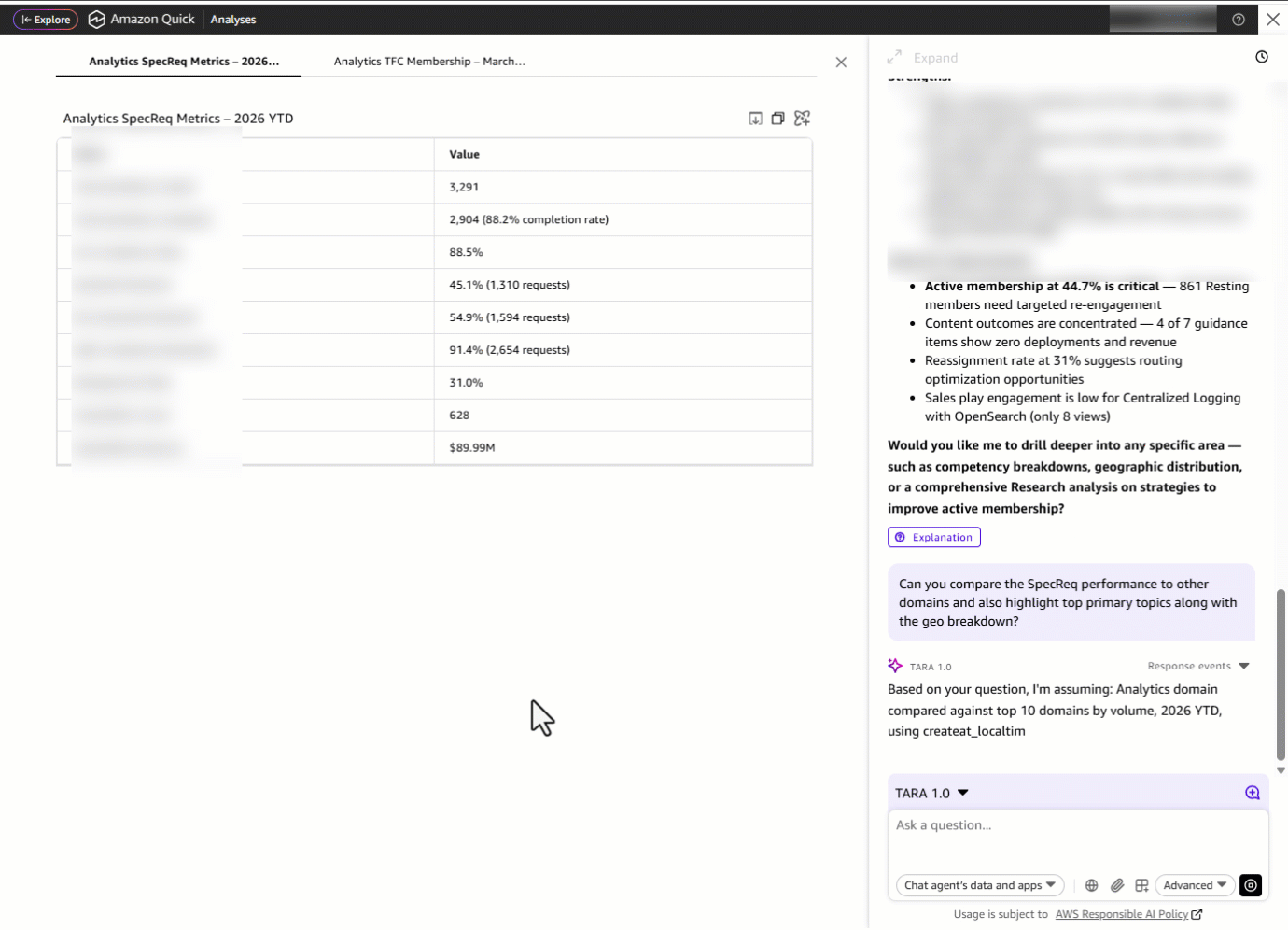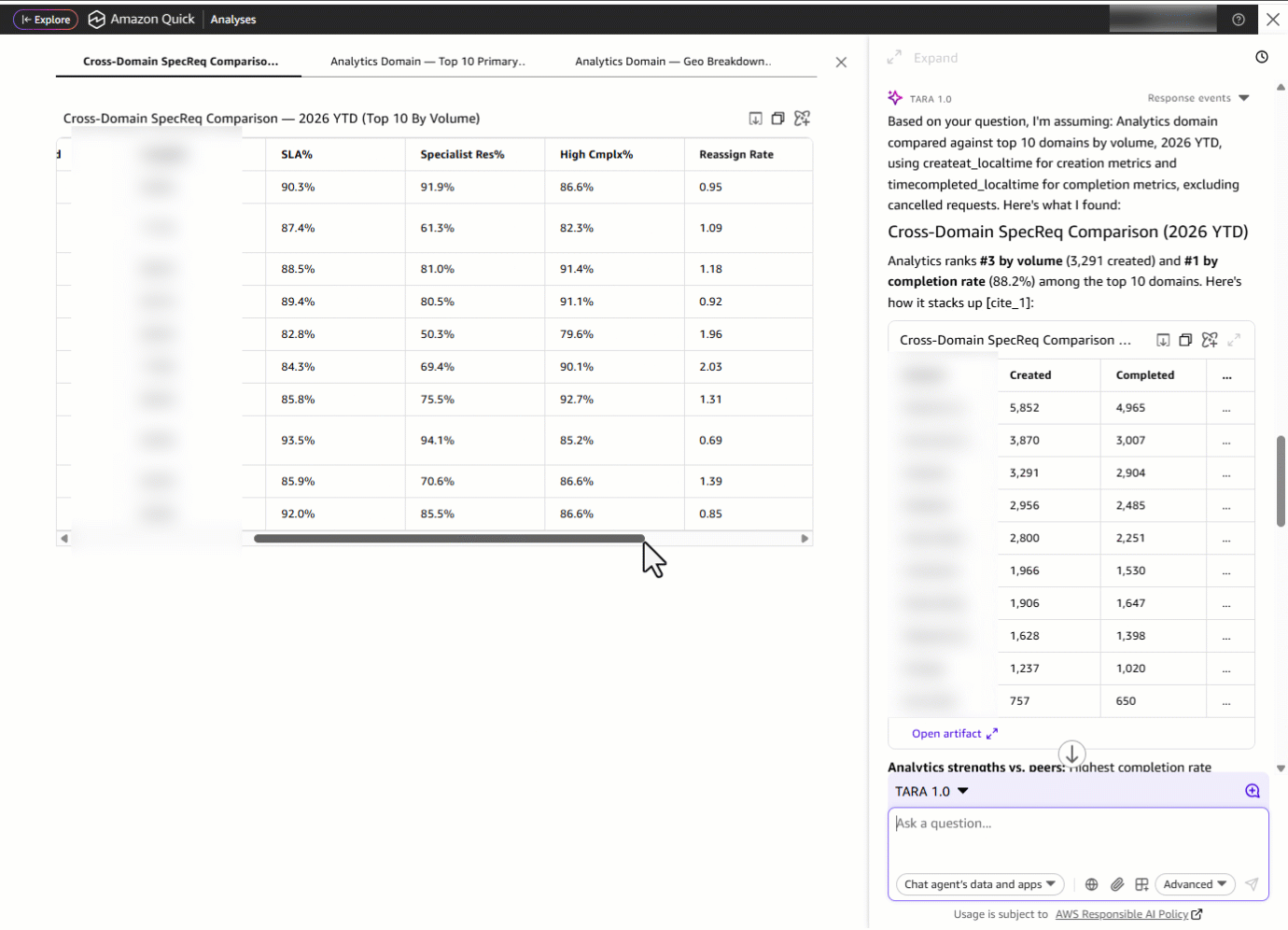
しかし、ドメインリーダーは孤立して活動するわけではありません。文脈が必要です。彼らは「SpecReq のパフォーマンスを他のドメインと比較し、主要なトピックの上位と地理的な内訳も強調してほしい」と尋ねます。ダッシュボードのタブ間を行き来したり、各ドメインごとにフィルターを再適用したり、手動で比較スプレッドシートを作成したりする代わりに、TARA はクロスドメイン比較テーブルを提供します。これにより、Analytics が指標においてどのように位置しているか、最もリクエストの多い主要トピック(ドメイン内のサブドメイン)、地理的分布、およびドメイン自体を同時に確認できます。
何かが彼らの目を引きます。SLA(サービスレベルアグリーメント)指標が 92.7 パーセントという高いパフォーマンスを示しています。これは最近の改善なのか、それとも一貫した結果なのでしょうか。彼らは「過去 15 か月の SLA トレンドを深掘りしてほしい」と尋ねます。TARA は 2025 年 1 月から 2026 年 3 月までの月別 SLA 傾向ラインを表示し、現在のパフォーマンスが持続的な軌道なのか、それとも最近の急上昇なのかを明らかにします。これにより、ドメインリーダーは進捗について自信を持って報告したり、浮上するリスクを指摘したりできます。
しかし TARA は単にトレンドを提示するだけでなく、その根拠も示します。可視化と並んで展開可能な説明パネルが、各データポイントの計算方法を詳細に分解して示します:基盤となる数式(*SLA Met ÷ Total SpecReqs*)、適用された特定のフィルター、ボリュームの文脈、そして前年比比較です。この組み込まれた説明可能性により、ドメインリーダーは 3.0 ポイントの改善を生データまで遡って追跡し、仮定を検証でき、メトリクスの背後にあるストーリーに完全な自信を持って経営陣へのレビューに臨むことができます。

各レスポンスは、Amazon Quick の直接データセット Q&A によって駆動されており、自然言語を基盤となるデータに対するリアルタイム SQL クエリに変換し、数秒で書式設定された分析結果と可視化を提供します。
主要なアーキテクチャ上の差別化要因:
トピックベースの Q&A から直接データセット Q&A への重要な転換は、t の除去にあります
原文を表示
Business leaders across industries rely on operational dashboards as the shared source of truth that their teams execute against daily. But dashboards are built to answer known questions. When teams need to explore further, ad-hoc, multi-dimensional, or unforeseen questions, they hit a bottleneck. They wait hours or days for BI teams to build new views or update reports. The Dataset Q&A feature bridges that gap. You can ask questions in natural language, get accurate answers in seconds, with no new dashboards to build, and no queue to wait in. Just an interactive conversation with your existing datasets, without disrupting the dashboards your teams already depend on.
The challenge
AWS customers expect fast, informed support when they’re evaluating new technologies, troubleshooting production issues, or planning cloud transformations. To deliver that experience at scale, AWS technical field teams need immediate answers to complex operational questions: Where is customer demand increasing? Which teams have the right expertise to respond? Are customer engagements being resolved quickly enough? And where are emerging gaps that could impact customer outcomes?
The AWS Technical Field Communities (TFC) program supports hundreds of thousands of these customer engagements annually across dozens of specialized technology domains. For program leaders and field teams, understanding the pulse of these engagements isn’t just about tracking metrics; it’s about making sure that we have the right skills in the right places at the right time to help our customers succeed. Yet, as the scale of these engagements grew, so did the complexity of the questions our leaders needed to answer. Traditional, static dashboards began to struggle under the weight of sophisticated, multi-dimensional inquiries. Stakeholders found themselves navigating a maze of different systems, manually cross-referencing datasets just to get a clear picture of how to better serve the customer. Getting to the “why” behind the data isn’t always a hard technical problem, it’s a workflow problem. A leader’s question becomes an interruption for a BI engineer, who pauses planned work, runs the aggregation, and returns an answer that inevitably spawns the next question. The real time lost isn’t in the query. It’s in the handoff between the person with the question and the person with the tools to answer it. Leaders were asking complex, real-time questions that crossed organizational and technical boundaries.
While the data existed, it was often “trapped” behind rigid visualizations that couldn’t anticipate every nuance of a program leader’s needs. Furthermore, the presence of personally identifiable information (PII) meant that certain qualitative details, the very context that makes data actionable, remained restricted and difficult to surface safely.
Introducing TARA: The future of conversational analytics
To bridge this gap, AWS developed TARA (Technical Analysis Research Agent). While TARA has been built for the internal analytics needs of AWS, the Dataset Q&A capabilities that we used are available to Quick customers facing similar challenges. Built by the Specialist Data Lens (SDL) team, TARA is an AI-powered analytics assistant that uses the custom chat agent capabilities of Quick. TARA serves as a unified conversational interface that you can use to explore multiple integrated datasets, live system APIs, and specialized research agents through natural language. By using MCP to securely connect structured datasets with external systems and domain-specific research agents, TARA bridges the gap between quantitative metrics and qualitative context. This allows leaders to tie quantitative metrics to the ground truth of what’s happening in the field, enriching analytical insights with real-time operational context while making sure sensitive PII remains protected.
We evolved TARA’s conversational analytics capabilities by adopting the Dataset Q&A feature as the foundation for semantic query generation and insight delivery. This post explores that journey and the impact of business users interacting with data more naturally. By embedding semantic definitions directly into the dataset and grounding SQL generation in the business meaning of the data, Dataset Q&A significantly improved the quality and reliability of insights. This enhancement delivered more than a 48 % improvement in response accuracy, reduced query failures to near zero, and shortened analysis time from hours to minutes.
Introducing Dataset Q&A
In Q1 2026, the SDL team became early adopters of the Dataset Q&A feature, unlocking the ability to ask natural language questions and receive answers directly from data, without needing to build topics or dashboards. At its core, Dataset Q&A translates natural language into SQL at query time, grounded in semantic definitions that live on the dataset itself rather than in a separately maintained Topic. This means the business meaning of your data, including field descriptions, synonyms, and dataset instructions, is defined once and reused everywhere.For the SDL team, this was a significant breakthrough. Program leaders could finally ask the questions that actually mattered, without waiting for BI teams to update business term definitions or configure new field mappings. That meant deep operational questions, advanced trend analysis, and open-ended exploration , all answered accurately and on demand.
The architectural difference made this possible. Instead of routing queries through preconfigured field definitions and business rules, Dataset Q&A dynamically interprets user intent, identifies the relevant datasets, and generates improved SQL at query time, giving the system the flexibility to handle complex, multidimensional analysis that the previous Topic based model couldn’t.
The SDL team participated in early testing, and the results were immediate. To measure query accuracy, we conducted structured ground truth testing by comparing TARA’s generated answers against manually validated SQL queries and analyst reviewed expected outputs across a representative set of real-world scenarios. Three improvements stood out:
- Accuracy: Query accuracy improved by about 48% on ground truth benchmarks.
- Reliability: Complex analytical questions that previously failed began executing successfully, reducing query failures to near zero.
- Speed: Response times improved from minutes (about 2–3 min) to seconds (about 10 sec), an over 90% reduction, enabling near-instant data exploration.
Together, these gains transformed TARA from a helpful reporting assistant into a reliable decision support tool for AWS program leaders.
Getting started
Before implementing direct dataset Q&A in your environment, make sure that you have:
- An AWS account. For setup instructions, see Getting Started with AWS.
- Amazon Quick Enterprise Edition enabled in your account with at least one Enterprise user and Professional user. For details, see Amazon Quick Sight editions and pricing.
- Familiarity with Amazon Quick Sight concepts such as datasets and the chat interface. See the Amazon Quick Sight documentation to get started.
Technical deep dive: The TARA architecture
System architecture and connected intelligence
TARA’s architecture is built on top of Amazon Quick and is designed to unify structured analytics, operational systems, and institutional knowledge into a single conversational interface. At the center of the experience is the Amazon Quick Chat Agent, which serves as both the user entry point and the orchestration hub for requests. Through a straightforward natural language interface, AWS leaders can access curated business datasets, live system APIs, and specialized research agents without switching tools.
The architecture follows four tightly integrated layers:
1. User Access and Orchestration Layer** Users interact with TARA through a web browser using the Amazon Quick Chat Agent. This chat interface acts as the primary client for conversational analytics, securely authenticating users through their AWS accounts and routing requests across the broader TARA environment. It acts as an intelligent orchestration layer that determines whether a query should be answered using structured dashboards, governed datasets, operational APIs, or external agents.
- Dataset Q&A and Workspace Integration Layer**** TARA’s core analytics foundation is powered by curated datasets hosted in the Windsor Amazon Redshift data lake and surfaced through Amazon Quick Spaces, which organize data into secure logical domains for discovery and reuse across teams. A key capability of TARA is its use of Amazon Quick’s Dataset Q&A feature, which allows users to query operational metrics, member performance, specialist requests, content outcomes, organizational goals, and sales insights using natural language. By connecting datasets directly to Quick Spaces attached to TARA, the system makes trusted insights instantly accessible without requiring users to understand schemas, dashboards, or query logic. The primary TARA Space hosts foundational business datasets for operational and performance analysis, while a separate Workshop Studio Space provides access to workshop and event delivery data through dashboard and MCP integration. This cross-space design demonstrates how Amazon Quick enables secure federation of data assets across organizational boundaries while preserving ownership and governance.
- Semantic Intelligence Through Custom Agent Instructions**** A key differentiator in TARA’s architecture is its semantic intelligence layer, powered by carefully designed custom agent instructions. This layer defines business logic, domain terminology, metric interpretation rules, and business semantics so that responses are contextually accurate and consistent. Rather than relying only on raw schema or table names, TARA uses instruction-driven reasoning to interpret user intent in business terms. For example:
- “Active members” are interpreted based on status flags rather than membership tier
- Specialist request resolution rates are calculated using only completed engagements, excluding cancelled requests
- “Current month” defaults to the most recent month with complete data, not the current calendar month
These instruction sets function as a semantic translation layer between business language and underlying data structures. This is critical for building trust in executive-facing insights and facilitating consistent, reliable answers across users.
- Connected Systems and Action Layer**** Beyond structured analytics, TARA extends into operational workflows and deep research through Amazon Quick Actions and MCP integrations. This action layer allows TARA to connect directly to systems AWS teams already use, making it more than a reporting assistant.
Current integrations include:
- Alchemy: supports priority customer use case discovery and curates AWS and partner solution assets, technical validation resources, and sales plays.
- SpecReq: supports specialist request intake, routing, tracking, and fulfillment across technical support engagements.
- Service 360 Deep Research Agent: performs deep analysis of product feature requests, specialist request trends, and customer pain points to uncover insights beyond standard dashboards.
TARA is also designed for future extensibility, with planned integrations including:
- Specialist Super Agent: a framework of AI agents delivering on-demand technical expertise across more than 30 technology domains.
- InstructAI: a workflow automation and business intelligence service for revenue, pipeline, and performance insights.
This layered architecture makes TARA more than a traditional analytics assistant. It’s a connected intelligence system that combines governed data, native conversational analytics, semantic reasoning, live operational context, and specialized AI capabilities to help AWS leaders make faster, better-informed decisions.
Solution overview
TARA integrates multiple structured datasets into a unified conversational analytics experience through the direct Dataset Q&A capability. The implementation consists of four stages:
Stage 1: Custom chat agent configuration
TARA is configured as a custom Amazon Quick chat agent with tailored instructions that define business semantics, domain expertise, and response behavior. As described in the previous architecture section, these instructions make sure that user questions are interpreted consistently in the context of SDL business logic. The Spaces and Actions configured in the following stages are then linked to this agent.
Stage 2: Dataset Preparation and Integration
The core analytics datasets are connected directly to an Amazon Quick Space. To set this up, navigate to the Spaces section in the Amazon Quick side panel and create a new Space. After naming the Space and defining its purpose, add the relevant Quick Sight datasets from the available data assets. In TARA’s case, this includes seven datasets spanning membership, competency tracking, specialist request resolution and performance metrics, domain level reporting, and individual contribution details. These datasets retain their native schema, column definitions, and data types, with no separate semantic modeling required. Because datasets are refreshed on their existing schedules, TARA consistently queries current data.
Stage 3: Action integration using MCP
To extend TARA beyond structured datasets, external systems are connected through Amazon Quick Actions. These Actions integrate with MCP servers from different systems, allowing TARA to retrieve live operational data and contextual information at query time. To configure this, create a new Action in the Integrations section of Amazon Quick, connect it to the target MCP server, and link the Action to the TARA chat agent.
Stage 4: Natural Language Query Processing
When a user submits a question, the Dataset Q&A engine interprets the natural language intent and generates optimized SQL queries directly against the connected datasets. The engine dynamically identifies relevant datasets, determines joins and filter conditions, applies aggregations, and constructs the query at runtime. For contextual questions that require operational system data, TARA automatically routes requests to the appropriate MCP Action. For example, a question about specialist request resolution rates generates SQL against structured datasets, while a request for recent customer interaction details is routed to the relevant MCP integration for live context retrieval.
TARA in action:**
Consider a domain leader who needs to assess their technology domain’s performance. Previously, this meant navigating multiple dashboard tabs, applying filters, and manually piecing together data, a time-consuming process. With TARA, that entire workflow becomes a single conversation.The domain leader opens TARA and starts with a “Hi TARA!”. TARA greets them and immediately surfaces the key data areas available, and more, all accessible from one place.
Enter* “Hi TARA!”*
Next, they ask: “How is the Analytics domain performing in 2026 YTD?” With one prompt, TARA pulls metrics across multiple datasets. What previously required opening separate dashboards is now a single, consolidated response delivered in seconds.
But a domain leader doesn’t operate in isolation, they need context. They ask: “Can you compare the SpecReq performance to other domains and also highlight top primary topics along with the geo breakdown?” Instead of switching between dashboard tabs, re-applying filters for each domain, and manually building a comparison spreadsheet, TARA delivers a cross-domain comparison table showing how Analytics stacks up on metrics, alongside the most requested primary topics *(sub-domain within a domain)*, geographic distribution and domains.
Something catches their eye: the SLA metric is showing strong performance at 92.7 percent. Is this a recent improvement, or has it been consistent? They ask: “Deep dive into the SLA trends for the last 15 months.” TARA surfaces a month-by-month SLA trend line from January 2025—March 2026, revealing whether the current performance is a sustained trajectory or a recent spike, so the domain leader can confidently report on progress or flag emerging risks.
But TARA doesn’t just surface the trend, it shows its work. Alongside the visualization, an expandable explanation panel breaks down exactly how each data point was calculated: the underlying formula (*SLA Met ÷ Total SpecReqs*), the specific filters applied, volume context, and year-over-year comparisons. This built-in explainability means the domain leader can trace the 3.0 percentage-point improvement back to the raw data, verify assumptions, and walk into their leadership review with full confidence in the story behind the metric.
Each response is powered by Amazon Quick’s direct dataset Q&A, which translates natural language into real-time SQL queries against the underlying data, delivering formatted analytics and visualizations in seconds.
Key Architectural Differentiator:
The critical shift from Topics-based Q&A to direct dataset Q&A is the removal of t
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み