2024年の注目すべきAI研究論文(パート2)
AI研究者のSebastian Raschkaは、2024年下半期の注目すべきAI研究論文として、特にMeta AIのLlama 3モデルファミリーの進化とその詳細なアーキテクチャ比較を紹介している。
キーポイント
Llama 3モデルファミリーの体系的な紹介
記事は2024年7月から12月までの研究を対象とし、特にMeta AIのLlama 3、3.1、3.2、3.3モデルのパラメータサイズとリリース時期を体系的にまとめている。
Llama 2とのアーキテクチャ比較
Llama 3のアーキテクチャはLlama 2に類似しているが、語彙サイズの拡大と小規模モデル向けのグループ化クエリアテンションの導入が主な違いとして指摘されている。
学習パイプラインの進化
Llama 3モデルファミリーは、前身のLlama 2と比較して、事前学習と事後学習のパイプラインがより洗練されていると評価されている。
著者による実践的な学習リソースの提供
著者は、GPT-2からLlama 2、Llama 3、Llama 3.1、Llama 3.2への変換を実装したGitHubリポジトリを紹介し、読者がアーキテクチャを深く理解するための実践的な方法を提案している。
Llama 3のトレーニングデータ拡大
Llama 3は15兆トークンでトレーニングされており、Llama 2から大幅にデータ量が増加している。
トレーニング手法の進化
事前学習はマルチステージ化され、事後学習ではRLHF-PPOからDPOに切り替えられている。
Llama 3の影響と使用状況
リリースから半年以上経過しても、Llamaモデルは最も広く認識され使用されているオープンウェイトLLMの一つであり、ブランド認知度と汎用タスクでの堅実な性能が人気の理由と考えられる。
影響分析・編集コメントを表示
影響分析
この記事は、特定の研究者の主観的な選択に基づくレビューであり、業界全体を変革するような新規性は限定的である。しかし、主要なオープンソースLLMであるLlama 3ファミリーの体系的なまとめと比較分析は、実務者や研究者にとって有用な参考情報を提供している。
編集コメント
著者個人の選定に基づくレビュー記事であり、網羅性よりも深掘りと実践的な洞察に重点が置かれている。Llama 3の詳細なバージョン比較は参考になるが、業界全体の動向を把握するには他の情報源との併用が望ましい。
2025 年が素晴らしいスタートを切っていることを願っています!今年を締めくくるために、ついにこの「2024 年 AI リサーチハイライト」記事のドラフトと第 2 部を完成させることができました。ここでは、エキスパート混合モデルから精度のための新しい大規模言語モデル(LLM)のスケーリング法則に至るまで、多岐にわたる関連トピックを取り上げています。
なお、本記事はシリーズの第 2 部であり、2024 年後半の 7 月から 12 月までの期間に焦点を当てています。1 月から 6 月までをカバーする第 1 部はこちらで見つけることができます。
選定基準は主観的なものですが、今年私が特に印象に残ったものに基づいています。また、LLM モデルのリリースに関する内容だけでなく、多様なトピックを取り上げるよう努めました。
2025 年が素晴らしい一年になりますように、そして楽しい読書をお楽しみください!
- 7 月:Llama 3 のモデル群
読者の方々はすでに Meta AI の Llama 3 モデルおよび論文に精通されていることと思いますが、これらが非常に重要で広く使用されているモデルであるため、7 月のセクションでは Grattafiori 氏らによる「The Llama 3 Herd of Models(2024 年 7 月)」という論文を特集します。
Llama 3 モデルファミリーの注目すべき点は、その前身である Llama 2 に比べて、事前トレーニングおよび事後トレーニングのパイプラインがより洗練されていることです。これは Llama 3 のみに限らず、数ヶ月前に私の「新しい LLM 事前トレーニングと事後トレーニングのパラダイム」記事で述べたように、Gemma 2、Qwen 2、Apple のファウンデーションモデルなど他の LLM にも当てはまります。
7.1 Llama 3 アーキテクチャの概要
Llama 3 は当初、80億パラメータと700億パラメータのサイズでリリースされましたが、チームはモデルの継続的な改良を続け、Llama の 3.1、3.2、3.3 バージョンを順次公開しています。各サイズの概要は以下の通りです。
Llama 3(2024 年 4 月)
8B パラメータ
70B パラメータ
Llama 3.1(2024 年 7 月、論文で議論済み)
8B パラメータ
70B パラメータ
405B パラメータ
Llama 3.2(2024 年 9 月)
1B パラメータ
3B パラメータ
11B パラメータ(ビジョン機能搭載)
90B パラメータ(ビジョン機能搭載)
Llama 3.3(2024 年 12 月)
70B パラメータ
全体として、Llama 3 のアーキテクチャは Llama 2 と非常に類似しています。主な違いは、より大規模な語彙と、小規模モデル向けに導入されたグループ化クエリアテンション(grouped-query attention)にあります。これらの差異の要約を以下の図に示します。

私の『ゼロから大規模言語モデルを構築する』書籍の補足資料における Llama 2 と 3 の比較
アーキテクチャの詳細について興味を持たれた場合は、モデルをゼロから実装し、事前学習済み重みを読み込んで検証(sanity check)を行うことが、学ぶための優れた方法です。私は GitHub リポジトリで、GPT-2 から Llama 2、Llama 3、Llama 3.1、そして Llama 3.2 へ変換するゼロから実装されたコードを公開しています。

GPT-2 から Llama 2、Llama 3、Llama 3.1、そして Llama 3.2 への移行は、私の『ゼロから大規模言語モデルを構築する』書籍の付録資料からのものです。
7.3 Llama 3 のトレーニング
Llama 2 に対するもう一つの注目すべき更新点は、Llama 3 が現在 15 トリリオンのトークンでトレーニングされていることです。
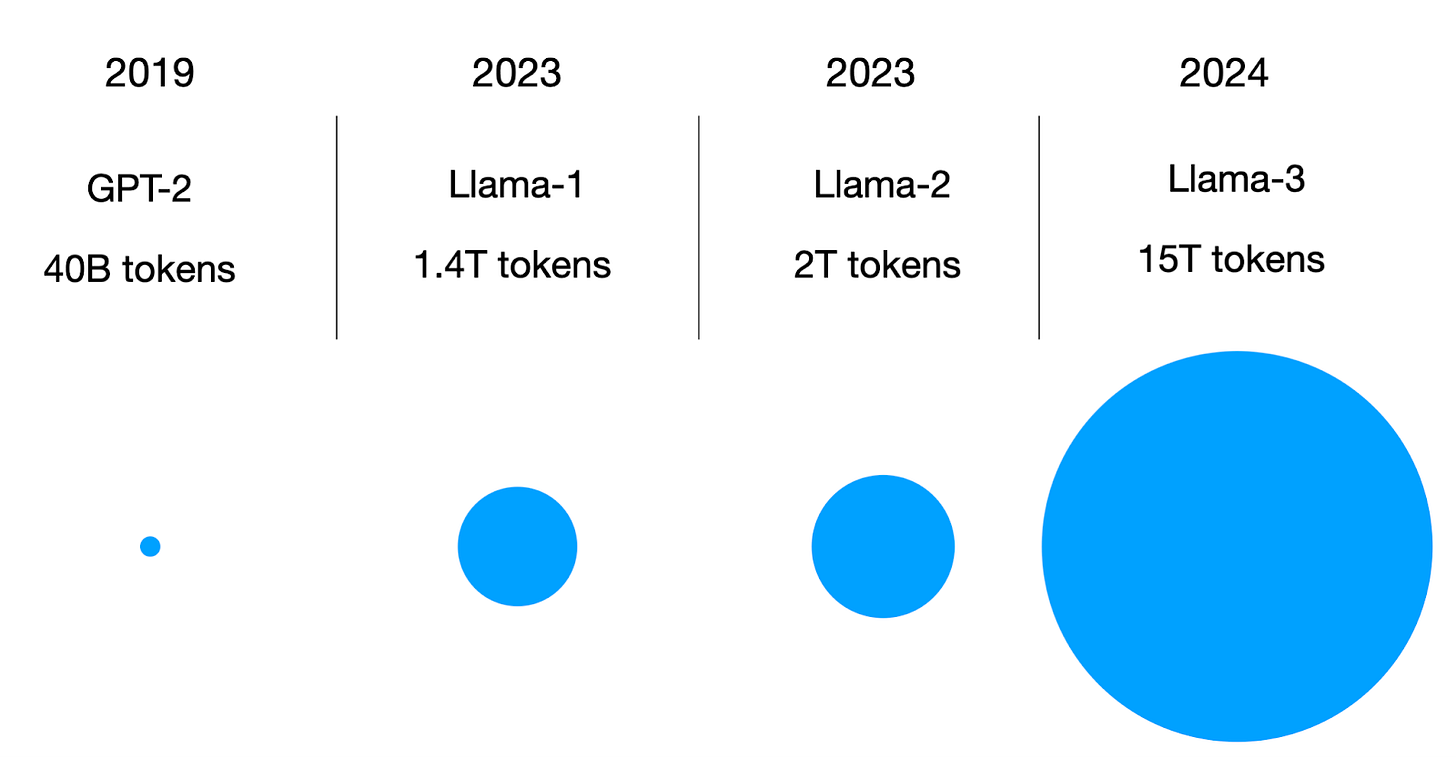
各種モデルのトレーニングセットサイズの比較。
事前トレーニングプロセスは現在、多段階で行われています。論文は主に Llama 3.1 に焦点を当てていますが、簡潔さのため、その事前トレーニング技術を図に要約しました。

Llama 3.1 の事前トレーニングで使用された技術の要約。
ポストトレーニングにおいて、Llama 2 から顕著な変化は、RLHF-PPO(強化学習による人間フィードバック最適化)から DPO(直接選好最適化)への切り替えです。これらの手法も以下の図に要約されています。

Llama 3.1 の事前学習(pre-training)で用いられた技術の概要。
簡潔さを優先するため、本記事で取り上げる論文があと 5 本あるため、他のモデルとの追加の詳細や比較については、私の過去の別の記事に譲ります。新しい大規模言語モデル(LLM: Large Language Model)の事前学習と事後学習のパラダイム。
Ahead of AI は読者支援型の出版物です。新しい投稿を受け取り、私の活動をサポートするには、無料または有料の購読者になることを検討してください。
7.4 多モーダル Llamas
Llama 3.2 モデルも同様に多モーダル(multimodal)対応でリリースされました。しかし、私はこれらのモデルが実務において広く使われているのを観察しておらず、また広く議論されているとも感じていません。本記事の 9 月のセクションで改めて多モーダル技術について取り上げます。
7.5 Llama 3 の影響と利用状況
Llama 3 がリリースされてから半年以上が経過しましたが、Llama モデルは依然として最も認知度が高く、広く使用されているオープンウェイト(open-weight)の LLM の一つです(これは私の個人的な認識に基づくものであり、具体的な出典を示すことはできません)。これらのモデルは理解しやすく、使いやすいためです。その人気には、Llama というブランドの認知度に加え、さまざまな一般タスクにおいて堅牢なパフォーマンスを発揮すること、そして微調整(finetuning)が容易であることが理由として挙げられます。
Meta AI は、Llama 3 モデルの継続的な改良により勢いを維持しており、バージョン 3.1、3.2、そして現在の 3.3 をリリースしています。これらは多様なサイズを備え、オンデバイス環境(1B)から高性能アプリケーション(400B)に至るまで、さまざまなユースケースに対応しています。
現在、Olmo 2、Qwen 2.5、Gemma 2、Phi-4 など、多くの競合するオープンソースおよびオープンウェイトの LLM(大規模言語モデル:Large Language Model)が存在しますが、私は Llama が、Anthropic の Claude、Google の Gemini、DeepSeek などの選択肢からの競争にもかかわらず ChatGPT が人気を維持し続けているように、ほとんどのユーザーにとってデファクトスタンダードであり続けるだろうと考えています。
個人的には、2025 年のどこかでリリースされることを願っている Llama 4 にワクワクしています。
- 8 月:推論時の計算リソースの拡張による LLM の改善
今月の私の選定は、「Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters(2024 年 8 月)」です。これは非常に良く書かれており詳細な論文であり、推論時(つまり、デプロイ時)における LLM の応答を改善するための興味深い洞察を提供しています。
8.1 より多くのテスト時の計算リソースの使用による出力の向上
本論文の主要な前提は、テスト時の計算リソースを増やすことでLLM(大規模言語モデル)の出力を改善できるかどうか、またその方法を探ることです。大まかな例えとして、人間が難しい課題に取り組む際、考える時間をより多く与えられるとより良い回答を生み出せる可能性があります。同様に、LLMも応答生成に要する時間やリソースを増やすことで、より優れた出力を生成できるかもしれません。より技術的な用語で言えば、研究者たちは推論時に追加の計算リソースを使用した場合、モデルが訓練された性能よりもどれだけ向上し得るかを明らかにしようとしています。
さらに、研究者たちは、固定された計算予算の下で、その計算リソースをモデルのさらなる事前学習に費やすのではなく、テスト時の計算に割くことで結果を改善できるかどうかも調査しました。これについては後ほど詳しく述べます。
8.2 テスト時計算技術の最適化
本論文では、テスト時計算を増やし改善するための技術を非常に詳細に説明しています。もし実務でLLM(前述のLlamaモデルなど)を導入するつもりがあるなら、この論文を完全に読むことを強くお勧めします。
要約すると、テスト時計算をスケーリングするための主な2つの方法は以下の通りです。
- 複数の解決策を生成し、プロセスベースの検証器報酬モデル(別途訓練が必要)を使用して最良の応答を選択する手法
- モデルの応答分布を適応的に更新する手法。これは本質的に推論生成中に応答を修正することを意味します(これも別のモデルが必要です)。
カテゴリ 1 の簡単な例を挙げると、テスト時の計算リソースを改善する素朴な方法の一つに、Best-of-N サンプリングを使用することがあります。これは、LLM に複数の回答を並列で生成させ、検証器報酬モデルに基づいて最良のものを選択するという手法です。Best of N もまた一例に過ぎず、ビームサーチ、先読みサーチ、Best-of-N など、複数の探索アルゴリズムがこのカテゴリに分類されます(以下の図参照)。

異なる探索ベースの手法は、プロセス報酬に基づくモデル(process-reward-based model)を用いて最良の回答を選択します。LLM Test-Time Compute 論文からの注釈付き図、https://arxiv.org/abs/2408.03314
カテゴリ 2 に分類される別のアプローチとして、モデルの応答を逐次的に修正する方法があります(以下の図参照)。

逐次修正アプローチ。LLM Test-Time Compute 論文からの注釈付き図、https://arxiv.org/abs/2408.03314
どちらのアプローチがより効果的でしょうか?残念ながら、万能な答えはありません。これは基盤となる大規模言語モデル(LLM)と、具体的な問題やクエリの内容に依存します。例えば、修正ベースのアプローチは難しい質問に対してはより良い結果を示しますが、簡単な質問においてはかえってパフォーマンスを低下させる可能性があります。
論文では、クエリの難易度を評価し、それに応じて適切な戦略を選択するモデルに基づいた「最適な」戦略が開発されました。
8.3 テスト時の計算リソース versus 大規模モデルの事前学習
答えたい興味深い質問は、固定された計算予算(compute budget)の下で、より大きな効果を得られるのは、より大規模なモデルを使用することか、それとも推論時の計算リソースを増やすことかという点です。
ここでは、クエリあたりのコストが同じであると仮定します。なぜなら、推論時に大規模モデルを実行する方が、小規模モデルよりもコストがかかるからです。
彼らの研究によると、難しい質問においては、より大規模なモデルの方が、前述の推論スケーリング戦略を通じて追加の推論計算リソースを得た小規模モデルよりも優れたパフォーマンスを発揮します。
しかし、簡単および中程度の難易度の質問においては、推論時の計算リソースを活用することで、同じ計算予算で 14 倍サイズのモデルと同等のパフォーマンスを達成できることが示されました!
8.4 テスト時計算リソースのスケーリングの将来性
Llama 3 などオープンウェイトモデルを使用する際、私たちは通常、生成された回答をそのまま採用します。しかし、この論文が指摘するように、推論時の計算リソースを割当てることで、回答の品質は大幅に向上させることができます。(もしモデルをデプロイされる場合は、これは必ず読むべき論文です。)
もちろん、大規模で高コストなモデルに対して推論計算予算を増やすと、運用コストはさらに高くなります。しかし、クエリの難易度に基づいて選択的に適用すれば、特定の回答において品質と精度に貴重な向上をもたらすことができ、これはほとんどのユーザーが間違いなく歓迎する点です。(OpenAI、Anthropic、Google はすでに裏側でこのような技術を活用していると仮定しても安全でしょう。)
もう一つの魅力的なユースケースは、小規模なオンデバイス大規模言語モデル(LLM: Large Language Model)のパフォーマンスを向上させることです。Apple Intelligence や Microsoft の Copilot PC における大きな発表と投資が示す通り、今後数ヶ月から数年にわたり、このテーマは引き続きホットトピックであり続けるでしょう。
- 9 月:マルチモーダル LLM パラダイムの比較
2024 年に大きな飛躍を遂げるだろうと考えていた主要な要素の一つが、マルチモーダル LLM です。そしてはい、今年もいくつかのオープンウェイト LLM が登場しました!

異なる入力モダリティ(音声、テキスト、画像、動画)を受け取り、出力モダリティとしてテキストを返すマルチモーダル LLM のイラスト。
特に私にとって印象深かった論文の一つは、Dai 氏らによる「NVIDIA's NVLM: Open Frontier-Class Multimodal LLMs」(2024 年 9 月)です。これは、2 つの主要なマルチモーダルパラダイムをうまく比較しているからです。
9.1 多モーダル大規模言語モデルのパラダイム
多モーダル LLM を構築する主なアプローチは 2 つあります:
方法 A: ユニファイド埋め込みデコーダーアーキテクチャのアプローチ;
方法 B: クロスモダリティアテンションアーキテクチャのアプローチ。

多モーダル LLM アーキテクチャを開発するための 2 つの主なアプローチ。
上記の図に示されているように、ユニファイド埋め込みデコーダーアーキテクチャ(方法 A)は、GPT-2 や Llama 3.2 のような修正を加えていない LLM アーキテクチャを模した単一のデコーダーモデルに依存しています。この方法は、画像をテキストトークンと同じ埋め込みサイズを持つトークンに変換し、LLM が連結されたテキストと画像の入力トークンを処理できるようにします。
一方、クロスモダリティアテンションアーキテクチャ(方法 B)は、アテンション層内で直接画像とテキストの埋め込みを統合するために、クロスアテンション機構を組み込んでいます。
さらに詳細に興味がある場合は、今年初めに多モーダル LLM についての記事を執筆しました。ここではこれらの 2 つの方法をステップバイステップで解説しています:「多モーダル LLM の理解 -- 主要な技術と最新モデルへの入門」。
9.2 Nvidia のハイブリッドアプローチ
今年 multimodal(多モーダル)の進展を踏まえると、NVIDIA の論文「NVLM: Open Frontier-Class Multimodal LLMs」は、これらの多モーダルアプローチを包括的な apples-to-apples(同等条件での)比較を行った点で際立っています。単一の方法に焦点を当てるのではなく、直接以下を比較しました:
Method A: 統合埋め込みデコーダアーキテクチャ("decoder-only architecture"、NVLM-D)、
Method B: クロスモーダルアテンションアーキテクチャ("cross-attention-based architecture"、NVLM-X)、
ハイブリッドアプローチ(NVLM-H)。

3 つの多モーダルアプローチの概要。(NVLM: Open Frontier-Class Multimodal LLMs 論文からの注釈付き図:https://arxiv.org/abs/2409.11402)
上記の図に要約されている通り、NVLM-D は Method A に、NVLM-X は前述の通り Method B に対応します。ハイブリッドモデル(NVLM-H)は両アプローチの強みを組み合わせています:まず画像サムネイルを入力として受け取り、その後、クロスアテンションを通じて処理される動的な数のパッチにより、より細かな高解像度の詳細を捉えます。
要約すると、主な知見は以下の通りです:
NVLM-X: 高解像度画像に対して優れた計算効率を提供します。
NVLM-D: OCR(光学文字認識)関連タスクにおいて高い精度を発揮します。
NVLM-H: 両アプローチの強みを組み合わせ、最適なパフォーマンスを実現します。
9.3 2025 年のマルチモーダル LLM
マルチモーダル LLM は非常に興味深い分野です。私は、これらが従来のテキストベースの LLM から見た次の論理的な発展段階だと考えています。OpenAI、Google、Anthropic といった主要な LLM サービスプロバイダの多くは、画像のようなマルチモーダル入力をサポートしています。個人的には、私がマルチモーダル機能を必要とするのはおそらく全体の 1% の場合だけです(通常は「表をマークダウン形式で抽出して」といったようなケースです)。私は、オープンウェイト LLM のデフォルト設定が複雑さを減らすために純粋にテキストベースであるべきだと考えています。同時に、ツールや API が進化していくにつれて、オープンウェイト LLM の選択肢が増え、より広く利用されるようになるだろうとも予想しています。
- 10 月:OpenAI o1 の推論能力の再現
私が 10 月に選んだのは、Quin とその共著者による「O1 Replication Journey: A Strategic Progress Report -- Part 1 (2024 年 10 月)」です。
OpenAI の ChatGPT o1(および現在の o3)は、推論タスクにおける LLM の性能向上においてパラダイムシフトを象徴しているかのように見られるため、大きな人気を集めています。
OpenAI の o1 の詳細な内容は未だ非公表であり、いくつかの論文がその記述や再現を試みています。では、なぜ私はこれを選んだのでしょうか?その特異な構造と学術研究の現状に関するより広範な哲学的議論が私に強く響いたからです。言い換えれば、他のものとは一線を画す特徴的な何かがあり、それが魅力的な選択となったのです。
10.1 ショートカット学習 vs 旅路学習
この論文の重要なポイントの一つは、図に示されているように、研究者たちが O1 がショートカット学習ではなく、ジャーニー・ラーニングと呼ばれるプロセスを採用しているという仮説を立てていることです。

従来、大規模言語モデル(LLM)は正解への経路(ショートカット学習)に基づいて訓練されてきましたが、ジャーニー・ラーニングでは、教師あり微調整が試行錯誤の修正プロセス全体を包含します。O1 レプリケーションレポートからの注釈付き図、https://arxiv.org/abs/2410.18982
このジャーニー・ラーニングのアプローチは、本記事の「8 月:推論時の計算リソースのスケーリングによる LLM の改善」セクションで前述したように、改訂を伴う木ベースまたはビームサーチ手法とある程度類似している点に留意する価値があります。
しかし、微妙な違いは、研究者たちがこの技術を推論時に単に適用するのではなく、モデルの微調整用のジャーニー・ラーニング訓練例を作成している点です。(なお、推論プロセスを拡張するために彼らが使用した技術に関する情報は見つけられませんでした。)
10.2 長い思考の構築
研究者らは、試行錯誤を強調しながら拡張された思考プロセスを導き出すために推論木を構築しました。このアプローチは、有効な中間ステップを通じて正解への直接的な経路を見つけることを優先する従来の手法とは異なります。彼らのフレームワークでは、推論木の各ノードには報酬モデルによって提供された評価が注釈付けされており、そのステップが正しいか間違っているかを示すとともに、その評価を正当化する理由も含まれています。
次に、深層学習モデル deepseek-math-7b-base を教師あり微調整(supervised finetuning)と直接好意最適化(DPO: Direct Preference Optimization)を通じて訓練しました。ここでは 2 つのモデルを訓練しています。
- まず、従来のショートカット学習パラダイムを使用し、正しい中間ステップのみを提供しました。
- 次に、提案されたジャーニー学習アプローチを用いてモデルを訓練しました。このアプローチには、正解と不正解を含む思考プロセス 3、バックトラックなどが含まれています。
(補足:各ケースで使用した例はわずか 327 件です!)
以下の図に示すように、ジャーニー学習プロセスは MATH500 ベンチマークデータセットにおいてショートカット学習を大幅に上回りました。

ショートカット学習とジャーニー学習で訓練された大規模言語モデル(LLMs: Large Language Models)。O1 レプリケーションレポートからの注釈付き図、https://arxiv.org/abs/2410.18982
10.3 蒸留 -- 迅速な解決策か?
1 ヶ月後、チームはもう一つのレポートを公開しました。黄氏らによる「O1 Replication Journey -- Part 2: Surpassing O1-preview through Simple Distillation, Big Progress or Bitter Lesson?」(2024 年 11 月)です。
ここでは、彼らは蒸留(distillation)アプローチを用いました。これは、o1 から思考プロセスを抽出するために注意深いプロンプトを使用し、同じ性能を達成するモデルを訓練するという手法です。この論文は長文のため詳細には立ち入りませんが、長い思考データ収集のコストのトレードオフを要約した興味深い図を紹介したいと考えています。
 paper by Grattafiori and colleagues.
What's notable about the Llama 3 model family is the increased sophistication of the pre-training and post-training pipelines compared to its Llama 2 predecessor. Note that this is not only true for Llama 3 but other LLMs like Gemma 2, Qwen 2, Apple's Foundation Models, and others, as I described a few months ago in my New LLM Pre-training and Post-training Paradigms article.
7.1 Llama 3 architecture summary
Llama 3 was first released in 8 billion and 70 billion parameter sizes, but the team kept iterating on the model, releasing 3.1, 3.2, and 3.3 versions of Llama. The sizes are summarized below:
Llama 3 (April 2024)
8B parameters
70B parameters
Llama 3.1 (July 2024, discussed in the paper)
8B parameters
70B parameters
405B parameters
Llama 3.2 (September 2024)
1B parameters
3B parameters
11B parameters (vision-enabled)
90B parameters (vision-enabled)
Llama 3.3 (December 2024)
70B parameters
Overall, the Llama 3 architecture closely resembles that of Llama 2. The key differences lie in its larger vocabulary and the introduction of grouped-query attention for the smaller model variant. A summary of the differences is shown in the figure below.
Llama 2 vs 3 comparison from the bonus material of my Build a Large Language from Scratch book
If you're curious about architectural details, a great way to learn is by implementing the model from scratch and loading pretrained weights as a sanity check. I have a GitHub repository with a from-scratch implementation that converts GPT-2 to Llama 2, Llama 3, Llama 3.1, and Llama 3.2.
GPT-2 to Llama 2, Llama 3, Llama 3.1, and Llama 3.2 conversion from the bonus material of my Build a Large Language from Scratch book
7.3 Llama 3 training
Another noteworthy update over Llama 2 is that Llama 3 has now been trained on 15 trillion tokens.
Comparison of the training set sizes of various models.
The pre-training process is now multi-staged. The paper primarily focuses on Llama 3.1, and for the sake of brevity, I have summarized its pre-training techniques in the figure below.
Summary of techniques used in pre-training Llama 3.1.
In post-training, a notable change from Llama 2 is the switch from RLHF-PPO to DPO. These methods are also summarized in the figure below.
Summary of techniques used in pre-training Llama 3.1.
For the interest of brevity, since there are 5 more papers to be covered in this article, I will defer the additional details and comparisons to other models to one of my previous articles. New LLM Pre-training and Post-training Paradigms.
Ahead of AI is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
7.4 Multimodal Llamas
Note that Llama 3.2 models were also released with multimodal support. However, I haven't observed widespread use of these models in practice, and they aren't widely discussed. We'll revisit multimodal techniques in the September section later in this article.
7.5 Llama 3 impact and usage
While it's been over half a year since Llama 3 was released, Llama models continue to be among the most widely recognized and used open-weight LLMs (based on my personal perception, as I don’t have a specific source to cite). These models are relatively easy to understand and use. The reason for their popularity is likely the Llama brand recognition coupled with robust performance across a variety of general tasks, and making it easy to finetune them.
Meta AI has also maintained momentum by iterating on the Llama 3 model, releasing versions 3.1, 3.2, and now 3.3, which span a variety of sizes to cater to diverse use cases, from on-device scenarios (1B) to high-performance applications (400B).
Although the field now includes many competitive open-source and open-weight LLMs like Olmo 2, Qwen 2.5, Gemma 2, and Phi-4, and many others, I believe Llama will remain the go-to model for most users, much like ChatGPT has retained its popularity despite competition from options like Anthropic Claude, Google Gemini, DeepSeek, and others.
Personally, I’m excited for Llama 4, which I hope will be released sometime in 2025.
- August: Improving LLMs by scaling inference-time compute
My pick for this month is Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters (August 2024) because it is a very well-written and detailed paper that offers some interesting insights into improving LLM responses during inference time (i.e., deployment).
8.1 Improve outputs by using more test-time computation
The main premise of this paper is to investigate if and how increased test-time computation can be used to improve LLM outputs. As a rough analogy, suppose that humans, on hard tasks, can generate better responses if they are given more time to think. Analogously, LLMs may be able to produce better outputs given more time/resources to generate their responses. In more technical terms, the researchers try to find out how much better models can perform than they are trained to do if additional compute is used during inference.
In addition, the researchers also looked into whether, given a fixed compute budget, spending more compute on test time can improve the results over spending that compute for further pre-training a model. But more on that later.
8.2 Optimizing test-time computation techniques
The paper describes techniques for increasing and improving and test-time compute in great detail, and if you are serious about deploying LLMs in practice (e.g., the aforementioned Llama models), I highly recommend giving this paper a full read.
In short, the 2 main methods to scale test-time compute are
- Generating multiple solutions and using a process-based verifier reward model (it has to be separately trained) to select the best response
- Updating the model's response distribution adaptively, which essentially means revising the responses during inference generation (this also requires a separate model).
To provide a simple example for category 1: One naive way to improve test time compute is to use best-of-N sampling. This means that we let the LLM generate multiple answers in parallel and then pick the best one based on a verifier reward model. Best of N is also just one example. Multiple search algorithms fall into this category: beam-search, lookahead-search, and best-of-N, as shown in the figure below.
Different search-based methods rely on a process-reward-based model to select the best answer. Annotated figure from the LLM Test-Time Compute paper, https://arxiv.org/abs/2408.03314
Another approach, which falls into category 2, is sequentially revising the model's response, as illustrated in the figure below.
Sequential revision approaches. Annotated figure from the LLM Test-Time Compute paper, https://arxiv.org/abs/2408.03314
Which approach works better? Unfortunately, there is no one-size-fits-all answer. It depends on the base LLM and the specific problem or query. For example, revision-based approaches perform better on harder questions, and they can actually harm performance on easy questions.
In the paper, they developed an "optimal" strategy based on a model that assesses the query's difficulty level and then chooses the right strategy appropriately.
8.3 Test-time computation versus pretraining a larger model
An interesting question to answer is, given a fixed compute budget, what gives the bigger bang for the buck: using a larger model or using an increased inference-time budget?
Here, suppose the price you pay for a query is the same because running a large model in inference is more costly than a small one.
They found that for challenging questions, larger models outperform smaller models that get additional inference compute via the inference scaling strategies discussed earlier.
However, for easy and medium questions, inference time compute can be used to match the performance of 14x larger models at the same compute budget!
8.4 Future relevance of test-time compute scaling
When using open-weight models like Llama 3 and others, we often let them generate responses as-is. However, as this paper highlights, response quality can be significantly enhanced by allocating more inference compute. (If you are deploying models, this is definitely THE paper to read.)
Of course, increasing the inference-compute budget for large, expensive models makes them even costlier to operate. Yet, when applied selectively based on the difficulty of the queries, it can provide a valuable boost in quality and accuracy for certain responses, which is something most users would undoubtedly appreciate. (It’s safe to assume that OpenAI, Anthropic, and Google already leverage such techniques behind the scenes.)
Another compelling use case is enhancing the performance of smaller, on-device LLMs. I think this will remain a hot topic in the months and years ahead as we've also seen with the big announcements and investments in Apple Intelligence and Microsoft’s Copilot PCs.
- September: Comparing multimodal LLM paradigms
Multimodal LLMs were one of the major things I thought would make big leaps in 2024. And yes, we got some more open-weight LLMs this year!
An illustration of a multimodal LLM that can accept different input modalities (audio, text, images, and videos) and returns text as the output modality.
One paper that particularly stood out to me was NVIDIA's NVLM: Open Frontier-Class Multimodal LLMs (September 2024) by Dai and colleagues, because it nicely compares the two leading multimodal paradigms.
9.1 Multimodal LLM paradigms
There are two main approaches to building multimodal LLMs:
Method A: Unified Embedding Decoder Architecture approach;
Method B: Cross-modality Attention Architecture approach.
The two main approaches to developing multimodal LLM architectures.
As illustrated in the figure above, the Unified Embedding-Decoder Architecture (Method A) relies on a single decoder model, resembling an unmodified LLM architecture such as GPT-2 or Llama 3.2. This method converts images into tokens that share the same embedding size as text tokens, enabling the LLM to process concatenated text and image input tokens.
In contrast, the Cross-Modality Attention Architecture (Method B) incorporates a cross-attention mechanism to integrate image and text embeddings within the attention layer directly.
If you are interested in additional details, I dedicated a whole article to multimodal LLMs earlier this year that goes over these two methods step by step: Understanding Multimodal LLMs -- An introduction to the main techniques and latest models.
9.2 Nvidia's hybrid approach
Given all the multimodal developments this year, to me, NVIDIA's paper NVLM: Open Frontier-Class Multimodal LLMs stands out for its comprehensive apples-to-apples comparison of these multimodal approaches. Rather than focusing on a single method, they directly compared:
Method A: The Unified Embedding Decoder Architecture ("decoder-only architecture," NVLM-D),
Method B: The Cross-Modality Attention Architecture ("cross-attention-based architecture," NVLM-X),
A hybrid approach (NVLM-H).
Overview of the three multimodal approaches. (Annotated figure from the NVLM: Open Frontier-Class Multimodal LLMs paper: https://arxiv.org/abs/2409.11402)
As summarized in the figure above, NVLM-D aligns with Method A, and NVLM-X corresponds to Method B, as discussed earlier. The hybrid model (NVLM-H) combines the strengths of both approaches: it first accepts an image thumbnail as input, followed by a dynamic number of patches processed through cross-attention to capture finer high-resolution details.
In summary, the key findings are as follows:
NVLM-X: Offers superior computational efficiency for high-resolution images.
NVLM-D: Delivers higher accuracy for OCR-related tasks.
NVLM-H: Combines the strengths of both approaches for optimal performance.
9.3 Multimodal LLMs in 2025
Multimodal LLMs are an interesting one. I think they are the next logical development up from regular text-based LLMs. Most LLM service providers like (OpenAI, Google, and Anthropic) support multimodal inputs like images. Personally, I need multimodal capabilities maybe 1% of the time (usually, it's something like: "extract the table in markdown format" or something like that). I do expect the default of open-weight LLMs to be purely text-based because it adds less complexity. At the same time I do think we will see more options and widespread use of open-weight LLMs as the tooling and APIs evolve.
- October: Replicating OpenAI o1's reasoning capabilities
My pick for October is the O1 Replication Journey: A Strategic Progress Report -- Part 1. (October 2024) by Quin and colleagues.
OpenAI ChatGPT's o1 (and now o3) have gained significant popularity, as they seem to represent a paradigm shift in improving LLMs' performance on reasoning tasks.
The exact details of OpenAI's o1 remain undisclosed, and several papers have attempted to describe or replicate it. So, why did I choose this one? Its unusual structure and broader philosophical arguments about the state of academic research resonated with me. In other words, there was something distinctive about it that stood out and made it an interesting choice.
10.1 Shortcut learning vs journey learning
One of the key points of this paper is the researchers' hypothesis that O1 employs a process called journey learning as opposed to shortcut learning, as illustrated in the figure below.
Traditionally, LLMs are trained on the correct solution path (shortcut learning); in journey learning, the supervised finetuning encompasses the whole trial-and-error correction process. Annotated figure from the O1 Replication Report, https://arxiv.org/abs/2410.18982
It's worth noting that the journey learning approach is somewhat similar to the tree-based or beam-search methods with revisions, as discussed earlier in the "8. August: Improving LLMs by Scaling Inference-Time Compute" section of this article.
The subtle difference, however, is that the researchers create journey learning training examples for model finetuning, rather than simply applying this technique during inference. (It's worth noting that I couldn't find any information on the techniques they used to augment the inference process.)
10.2 Constructing long thoughts
The researchers constructed a reasoning tree to derive an extended thought process from it, emphasizing trial and error. This approach diverges from traditional methods that prioritize finding a direct path to the correct answer with valid intermediate steps. In their framework, each node in the reasoning tree was annotated with a rating provided by a reward model, indicating whether the step was correct or incorrect, along with reasoning to justify this evaluation.
Next, they trained a deepseek-math-7b-base model via supervised finetuning and DPO. Here, they trained two models.
- First they used the traditional shortcut training paradigm where only the correct intermediate steps were provided.
- Second, they trained the model with their proposed journey learning approach that included the thought process three with correct and incorrect answers, backtracking, and so forth.
(Sidenote: They only used 327 examples in each case!)
As shown in the figure below, the journey learning process outperformed shortcut learning by quite a wide margin on the MATH500 benchmark dataset.
LLMs trained with shortcut and journey learning. Annotated figure from the O1 Replication Report, https://arxiv.org/abs/2410.18982
10.3 Distillation -- the quick fix?
One month later, the team released another report: O1 Replication Journey -- Part 2: Surpassing O1-preview through Simple Distillation, Big Progress or Bitter Lesson? (November 2024) by Huang and colleagues.
Here, they used a distillation approach, meaning they used careful prompting to extract the thought processes from o1 to train a model to reach the same performance. Since this is a long article, I won't go over the details, but I wanted to share an interesting figure from that paper that summarizes the cost trade-offs of collecting long-thought data.
![image](https://su
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み