AIエージェントキャッチアップ #67 - Harbor を開催
サンドボックス環境でAIエージェントを評価するフレームワーク「Harbor」についての勉強会を開催し、その概要と関連リソースを紹介しました。
キーポイント
Harborはサンドボックス環境でAIエージェントを評価するためのオープンソースフレームワークである
Terminal-Bench 2.0やSWE-benchなど複数のベンチマークデータセットに対応し、独自のエージェントやデータセット評価も可能
コンテナ環境でエージェントを実行するため、コーディングエージェントのようなファイル操作・コマンド実行を含む評価に適している
影響分析・編集コメントを表示
影響分析
HarborはAIエージェントの実用的評価環境を提供することで、特にコーディングエージェントなどの実世界タスク実行能力の客観的測定を可能にする。オープンソースフレームワークとして公開されているため、研究コミュニティでの標準化と比較可能性向上に寄与する可能性がある。
編集コメント
AIエージェントの実用化が進む中、標準化された評価環境の整備は重要な課題。Harborはそのための具体的なツールとして注目される。
「AIエージェントキャッチアップ #67 - Harbor」を開催しました
ジェネラティブエージェンツの大嶋です。
「AIエージェントキャッチアップ #67 - Harbor」という勉強会を開催しました。
generative-agents.connpass.com
www.youtube.com
今回は、サンドボックス環境でエージェントを評価するためのフレームワーク「Harbor」をキャッチアップしました。
HarborのGitHubリポジトリはこちらです。
公式ドキュメントはこちらです。
harborframework.com
Harborは、Terminal-Benchの作成者が公開したフレームワークです。
コンテナなどのサンドボックス環境でエージェントを実行するため、コーディングエージェントのようにコマンド実行やファイル変更を含むエージェントの評価に適しています。
Harborは、LangChainがDeepAgents CLIをTerminalBench 2.0で評価した解説記事でも紹介されています。
blog.langchain.com
Harborの主要概念を紹介します。
エージェント:タスクを遂行するプログラム
タスク:instruction(指示)・environment(コンテナ環境)・test(評価スクリプト)などから成る評価単位
コンテナ環境:Docker、Daytona、 Modal、E2Bなどのランタイム
エージェントもデータセットもカスタマイズ可能であり、独自のエージェントや独自のデータセットの評価にも使用可能です。
harborframework.com
対応ベンチマーク・データセット
Harborは、Terminal-Bench 2.0やSWE-benchなど、多数のベンチマーク・データセットに対応しています。
もともとTerminal-Bench 2.0向けに開発されているため、Terminal-Bench 2.0のデータセットはそのまま使用できます。
その他のベンチマークについては、Harborの形式への変換とアダプターの実装が必要となります。
https://github.com/laude-institute/harbor-datasets/tree/main/datasets/swebench-verified
https://github.com/laude-institute/harbor/tree/main/adapters/swebench
Harborのデータセット(タスク)の形式は以下のようになります。
<タスク名>/ ├── instruction.md # エージェントへの指示 ├── task.toml # タスクの設定・メタデータ ├── environment/ │ ├── Dockerfile # コンテナ環境の定義 │ └── ... ├── solution/ │ ├── solve.sh # 参考解答スクリプト(オプション) │ └── ... └── tests/ ├── test.sh # 評価スクリプト └── ...
harborframework.com
実際にHarborをインストールし、Claude Code × Terminal-Bench 2.0で動かしてみました。
uv tool install harbor
harbor run \ --dataset terminal-bench@2.0 \ --agent claude-code \ --model anthropic/claude-opus-4-1 \ --n-tasks 1
実行すると、Terminal-Bench 2.0に含まれるタスクの1つ(gpt2-codegolf)が処理されました。
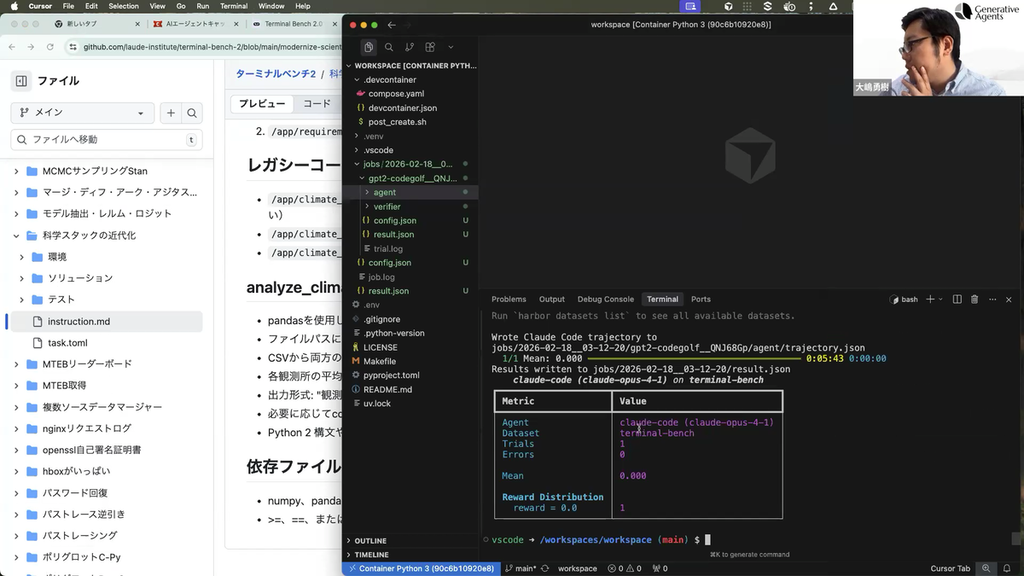
Harborでは、独自のエージェントを評価対象として使うこともできます。
Harborのライブラリが提供するBaseAgentクラスを継承することで、独自のエージェントを評価対象にできます。 また、Claude CodeのようなCLIのエージェントを使用するための、BaseInstalledAgentというクラスも用意されています。
harborframework.com
実際にLangChainは、Deep Agents CLIをHarborで評価するためのラッパーを実装しています。
以上、今回は「Harbor」をキャッチアップしました。
次回は「AIエージェントキャッチアップ #68 - AI-DLC」ということで、AWSが公開したソフトウェア開発ワークフロー「AI-DLC(AI-Driven Development Life Cycle)」がテーマです!
generative-agents.connpass.com
ご興味・お時間ある方はぜひご参加ください!
また、その次の回以降のテーマも募集しているので、気になるエージェントのOSSなどあれば教えてください!
原文を表示
ジェネラティブエージェンツの大嶋です。
「AIエージェントキャッチアップ #67 - Harbor」という勉強会を開催しました。
generative-agents.connpass.com
www.youtube.com
今回は、サンドボックス環境でエージェントを評価するためのフレームワーク「Harbor」をキャッチアップしました。
HarborのGitHubリポジトリはこちらです。
公式ドキュメントはこちらです。
harborframework.com
Harborは、Terminal-Benchの作成者が公開したフレームワークです。
コンテナなどのサンドボックス環境でエージェントを実行するため、コーディングエージェントのようにコマンド実行やファイル変更を含むエージェントの評価に適しています。
Harborは、LangChainがDeepAgents CLIをTerminalBench 2.0で評価した解説記事でも紹介されています。
blog.langchain.com
Harborの主要概念を紹介します。
エージェント:タスクを遂行するプログラム
タスク:instruction(指示)・environment(コンテナ環境)・test(評価スクリプト)などから成る評価単位
コンテナ環境:Docker、Daytona、 Modal、E2Bなどのランタイム
エージェントもデータセットもカスタマイズ可能であり、独自のエージェントや独自のデータセットの評価にも使用可能です。
harborframework.com
対応ベンチマーク・データセット
Harborは、Terminal-Bench 2.0やSWE-benchなど、多数のベンチマーク・データセットに対応しています。
もともとTerminal-Bench 2.0向けに開発されているため、Terminal-Bench 2.0のデータセットはそのまま使用できます。
その他のベンチマークについては、Harborの形式への変換とアダプターの実装が必要となります。
https://github.com/laude-institute/harbor-datasets/tree/main/datasets/swebench-verified
https://github.com/laude-institute/harbor/tree/main/adapters/swebench
Harborのデータセット(タスク)の形式は以下のようになります。
<task-name>/ ├── instruction.md # エージェントへの指示 ├── task.toml # タスクの設定・メタデータ ├── environment/ │ ├── Dockerfile # コンテナ環境の定義 │ └── ... ├── solution/ │ ├── solve.sh # 参考解答スクリプト(オプション) │ └── ... └── tests/ ├── test.sh # 評価スクリプト └── ...
harborframework.com
実際にHarborをインストールし、Claude Code × Terminal-Bench 2.0で動かしてみました。
uv tool install harbor
harbor run \ --dataset terminal-bench@2.0 \ --agent claude-code \ --model anthropic/claude-opus-4-1 \ --n-tasks 1
実行すると、Terminal-Bench 2.0に含まれるタスクの1つ(gpt2-codegolf)が処理されました。
Harborでは、独自のエージェントを評価対象として使うこともできます。
Harborのライブラリが提供するBaseAgentクラスを継承することで、独自のエージェントを評価対象にできます。 また、Claude CodeのようなCLIのエージェントを使用するための、BaseInstalledAgentというクラスも用意されています。
harborframework.com
実際にLangChainは、Deep Agents CLIをHarborで評価するためのラッパーを実装しています。
以上、今回は「Harbor」をキャッチアップしました。
次回は「AIエージェントキャッチアップ #68 - AI-DLC」ということで、AWSが公開したソフトウェア開発ワークフロー「AI-DLC(AI-Driven Development Life Cycle)」がテーマです!
generative-agents.connpass.com
ご興味・お時間ある方はぜひご参加ください!
また、その次の回以降のテーマも募集しているので、気になるエージェントのOSSなどあれば教えてください!
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み