Amazon Bedrock や Neptune を活用した神経生物学的インスパイア型 RAG「HippoRAG」の紹介
AWS は、人間の海馬の記憶機構に着想を得た「HippoRAG」フレームワークを公開し、Amazon Bedrock と Neptune を活用して単一ステップでの多段推論型 RAG 実現を可能にした。
キーポイント
神経科学的アプローチによる RAG の進化
従来のドキュメント独立処理ではなく、海馬の連想記憶機構(ニューロコルテックスと海馬の連携)に着想を得た HipoRAG が提案され、複数ソース間の情報を統合する能力が強化される。
AWS 技術スタックによる実装
Amazon Bedrock を LLM エンジンに、Amazon Neptune と Neptune Analytics をグラフデータベースおよび Personalized PageRank アルゴリズムの実行基盤として活用し、エンタープライズ規模での展開を可能にする。
多段推論の高速化と効率化
Personalized PageRank (PPR) 算法を用いることで、複数のドキュメントにまたがる情報の接続(マルチホップ推論)を複数回の反復処理なしで単一ステップで実現し、検索精度と速度を向上させる。
LLM を活用した知識グラフの構築
Amazon Bedrock の大規模言語モデル(LLM)を使用して、生テキストから構造化された知識(主語・関係・目的語のトリプル)を抽出し、これを知識グラフのエッジとして利用する。
簡易的なトリプル生成ロジック
実装例では、テキスト内の単語列に基づいて単純なルール(例:3 語ごとのスライドウィンドウ)で主語と目的語を抽出し、「related_to」という関係性を付与してトリプルを生成している。
Neptune Bulk Loader 向けの CSV 形式変換
知識グラフを Amazon Neptune のバッチローダーが認識できる形式に変換するため、フレーズノード、パッセージノード、関係エッジ、コンテキストエッジの 4 つの CSV ファイルにデータをシリアライズします。
HotpotQA データの構造化処理
各 QA 例文からドキュメントタイトルと段落を抽出し、UUID を付与したノードとして作成すると同時に、LLM を用いて文中のトリプル(述語-対象関係)を抽出してエッジとして記録します。
影響分析・編集コメントを表示
影響分析
本記事は、RAG システムが単なる情報検索から高度な推論能力を持つシステムへ進化するための具体的なアーキテクチャを示しており、特に複雑なビジネスデータや学術文献を扱うエンタープライズ環境において重要な転換点となる。AWS の強力なインフラと組み合わせることで、実用化のハードルを下げ、業界全体で「思考する RAG」の実装が加速すると予想される。
編集コメント
脳科学の知見を AI アーキテクチャに応用した興味深い事例であり、特に「マルチホップ推論」の課題解決において AWS のグラフ技術が果たす役割が明確に示されています。
大規模言語モデル(LLM)は、情報の処理と生成の方法を変革しましたが、依然として複数のソースからの知識を効果的に統合することには苦慮しています。標準的な検索拡張生成(RAG: Retrieval Augmented Generation)手法は有用ですが、別々の文書から情報を接続する必要がある多段推論タスクに取り組む際には、しばしば不十分となります。これらの限界に対処するため、私たちは人間の脳内の海馬記憶システムに着想を得た新しい RAG フレームワークである HippoRAG を探求します。
本稿では、包括的な AWS スタックを用いて HippoRAG を実装する方法を示します。LLM の機能には Amazon Bedrock を、グラフデータベースの機能には Amazon Neptune を、高度なグラフアルゴリズム(Personalized PageRank など)には Amazon Neptune Analytics を、ベクトル表現には Amazon Titan Embeddings をそれぞれ使用します。この実装は、エンタープライズ規模のアプリケーション向けに AWS インフラストラクチャ内で HippoRAG を構築および展開する方法を示すものです。
神経生物学的インスピレーションと背景
HippoRAG は、人間の長期記憶における海馬の索引付け理論から着想を得ています。人間の脳では、新皮質が知覚入力を処理する一方、海馬は記憶間の関連性のインデックスを作成します。この二要素システムにより、人間は異なる経験にわたる情報を効率的に統合することができます。
標準的な RAG(Retrieval-Augmented Generation:検索拡張生成)アプローチでは各ドキュメントを独立して扱い、複数のソースにまたがる情報の接続が必要な質問に対して苦戦します。HippoRAG はこれに対処するために以下の機能を提供します:
- エンティティ間の関係を表現するための知識グラフ(KG: Knowledge Graph)の構築。
- 効率的なグラフの探索と関連性のランク付けのためのパーソナライズドページランク(PPR: Personalized PageRank)アルゴリズムの使用。
- 複数の反復を必要とするのではなく、単一のステップでマルチホップ検索を可能にすること。
ソリューションアーキテクチャ
当社の AWS における HippoRAG の実装には、4 つの主要コンポーネントが含まれます:
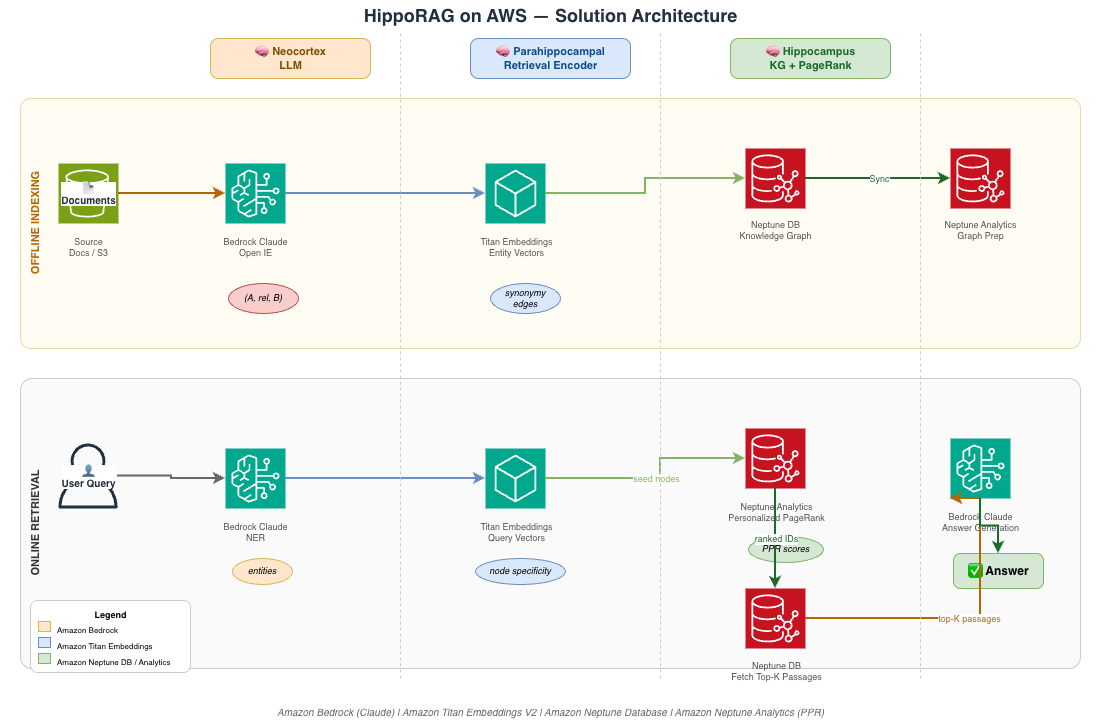
- Amazon Bedrock – 知識グラフのトリプル抽出、質問への回答、固有名詞の特定のための LLM(大規模言語モデル)機能を提供します。
- Amazon Neptune Database – 知識グラフ構造を保存し、基本的なグラフ操作を可能にします。
- Amazon Neptune Analytics – 高度なグラフアルゴリズムを実行し、特に関連性ランキング用のパーソナライズド PageRank を実行します。
- Amazon Titan Embeddings – 類似度マッチングのためのテキストのベクトル表現を作成します。
このアーキテクチャにより、AWS のマネージドサービスの拡張性と信頼性を維持しながら、パーソナライズド PageRank の全機能を活用することが可能になります。
前提条件
本実装には以下のものが必要です:
- Amazon Bedrock および Neptune サービスへのアクセス権限を持つ AWS アカウント。
- 設定済みでアクセス可能な Amazon Neptune クラスター。
- Amazon Neptune Database から作成された Amazon Neptune Analytics グラフ。
- インストール済みの AWS Command Line Interface (AWS CLI) および Python 3.8 以降。
- 以下のサービスに対する適切な IAM 権限:Amazon Bedrock | Amazon Neptune | Amazon Neptune Analytics | Amazon Simple Storage Service (Amazon S3)。
データ処理パイプライン:HotpotQA JSON から Neptune へ
HippoRAG を実装する際の必須の最初のステップは、Neptune に適した知識グラフ構造へと生データを変換することです。このセクションでは、JSON 形式から HotpotQA データをどのように処理するかを追跡します。Amazon Bedrock を用いて知識グラフのトリプル(三項関係)を抽出し、Neptune のバッチロード用 CSV ファイルを生成して Amazon S3 にアップロードした後、Neptune クラスターに読み込みます。以下の各サブセクションは、このパイプラインの各段階に対応しています。
データインポーターの設定
HotpotQANeptuneImporter クラスは、パイプラインのすべての段階を調整・管理します。JSON ソースファイルの読み込み、CSV 出力の生成、これらのファイルを Amazon S3 へのアップロード、そして Neptune バッチローダーのトリガー処理を担当します。AWS 環境の設定値を用いてこのクラスをどのように初期化するかを見てみましょう:
class HotpotQANeptuneImporter:
"""HotpotQA データを Neptune にインポートする処理を行うクラス。"""
def __init__(
self,
hotpotqa_file_path: str,
output_dir: str,
s3_bucket: str,
s3_prefix: str,
neptune_endpoint: str,
neptune_port: int,
iam_role_arn: str,
aws_region: str,
llm_endpoint: Optional[str] = None,
embedding_endpoint: Optional[str] = None,
max_workers: int = 4,
max_examples: int = 10,
max_docs_per_example: int = 2,
use_ssl: bool = False
):
"""設定を用いてインポーターを初期化する。"""
self.hotpotqa_file_path = hotpotqa_file_path
self.output_dir = output_dir
self.s3_bucket = s3_bucket
self.s3_prefix = s3_prefix
self.neptune_endpoint = neptune_endpoint
self.neptune_port = neptune_port
self.iam_role_arn = iam_role_arn
self.aws_region = aws_region
# AWS クライアントの初期化
self.s3_client = boto3.client('s3', region_name=aws_region)
self.session = boto3.Session()
# データ構造の初期化
self.phrase_dict = {} # 句テキストをノード ID にマッピングする辞書
self.phrase_embeddings = {} # 句テキストを埋め込みベクトルにマッピングする辞書
## 知識グラフ三重項抽出
パイプラインの重要な部分は、Amazon Bedrock の大規模言語モデル(LLM)の機能を用いて、生テキストから構造化された知識を抽出することです。各パッセージに対して、システムは主題 - 関係 - 対象の三重項を生成し、これらが知識グラフにおけるエッジとなります。この抽出を実装する方法は以下の通りです。
def extract_triples_with_llm(self, text: str) -> List[Tuple[str, str, str]]:
"""
Use an LLM to extract knowledge graph triples from text.
In this simplified version, just generate simple triples from the text.
"""
# Simple triple generation from text
words = text.split()
if len(words)
## Converting JSON data to CSV format
With triples in hand, we need to serialize the graph into the CSV format that Neptune's bulk loader expects. This processing method converts the HotpotQA JSON records into four CSV files: phrase_nodes.csv, passage_nodes.csv, relation_edges.csv, and context_edges.csv. Together, these files capture the full knowledge graph structure. Here's how we implement that conversion:
def process_data_to_csv(self, data: List[Dict]) -> None:
"""
Process HotpotQA data into CSV files for Neptune import.
"""
logger.info("Processing HotpotQA data to CSV files")
# Open all CSV files for writing
with open(os.path.join(self.output_dir, 'phrase_nodes.csv'), 'w', newline='', encoding='utf-8') as phrase_f, \
open(os.path.join(self.output_dir, 'passage_nodes.csv'), 'w', newline='', encoding='utf-8') as passage_f, \
open(os.path.join(self.output_dir, 'relation_edges.csv'), 'w', newline='', encoding='utf-8') as relation_f, \
open(os.path.join(self.output_dir, 'context_edges.csv'), 'w', newline='', encoding='utf-8') as context_f:
必ず JSON 形式で返してください。`translation` フィールドのみ。**他のフィールド (technical_terms 等) は一切追加しないこと** — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
# ヘッダーの作成
phrase_f.write('~id,~label,text\n')
passage_f.write('~id,~label,title,content\n')
relation_f.write('~id,~from,~to,~label\n')
context_f.write('~id,~from,~to,~label\n')
# 各例の処理
for example in tqdm(data, desc="Processing examples"):
self._process_example(example, passage_f, phrase_f, relation_f, context_f)
## 個別の例の処理
各 HotpotQA の例は、知識グラフにノードとエッジを作成するために処理されます:
def _process_example(self, example: Dict, passage_f, phrase_f, relation_f, context_f) -> None:
"""単一の HotpotQA 例を CSV データとして処理する。"""
# コンテキスト内の限られたドキュメントを処理
doc_count = 0
for doc_title, paragraphs in example['context']:
if doc_count >= self.max_docs_per_example:
break
# 各パラグラフをパスサージとして処理
for paragraph in paragraphs:
if not paragraph.strip():
continue
passage_id = f"passage_{uuid.uuid4().hex}"
# パッサージノードの書き出し
passage_f.write(f"{passage_id},passage,\"{self._escape_csv(doc_title)}\",\"{self._escape_csv(paragraph)}\"\n")
# パラグラフからトリプルを抽出
triples = self.extract_triples_with_llm(paragraph)
# トリプルごとの処理
for subject, relation, obj in triples:
# 主語ノード ID の作成または取得
if subject not in self.phrase_dict:
subject_id = f"phrase_{uuid.uuid4().hex}"
self.phrase_dict[subject] = subject_id
phrase_f.write(f"{subject_id},phrase,\"{self._escape_csv(subject)}\"\n")
else:
subject_id = self.phrase_dict[subject]
# 目的語ノード ID の作成または取得
if obj not in self.phrase_dict:
obj_id = f"phrase_{uuid.uuid4().hex}"
self.phrase_dict[obj] = obj_id
phrase_f.write(f"{obj_id},phrase,\"{self._escape_csv(obj)}\"\n")
else:
obj_id = self.phrase_dict[obj]
# 関係エッジの書き出し
relation_id = f"rel_{uuid.uuid4().hex}"
relation_f.write(f"{relation_id},{subject_id},{obj_id},\"{self._escape_csv(relation)}\"\n")
# コンテキストエッジの書き出し
context_f.write(f"ctx_{uuid.uuid4().hex},{passage_id},{subject_id},contains\n")
context_f.write(f"ctx_{uuid.uuid4().hex},{passage_id},{obj_id},contains\n")
doc_count += 1
## Neptune へのデータ読み込み
データを CSV ファイルに処理した後、システムは S3 にアップロードし、Neptune へインポートします:
def import_to_neptune(self) -> Dict:
"""バッチローダー API を使用してデータを Neptune にインポートする。"""
logger.info(f"Neptune エンドポイント {self.neptune_endpoint} へのデータインポートを開始します")
loader_endpoint = f"{self.protocol}://{self.neptune_endpoint}:{self.neptune_port}/loader"
payload = {
"source": f"s3://{self.s3_bucket}/{self.s3_prefix}/",
"format": "csv",
"formatParams": {
"delimiter": ",",
"header": "true"
},
"iamRoleArn": self.iam_role_arn,
"region": self.aws_region,
"failOnError": "FALSE"
}
try:
# リクエスト用の AWS4Auth を作成する
credentials = self.session.get_credentials()
if credentials:
auth = AWS4Auth(
credentials.access_key,
credentials.secret_key,
self.aws_region,
'neptune-db',
session_token=credentials.token
)
response = requests.post(
loader_endpoint,
data=json.dumps(payload),
headers={"Content-Type": "application/json"},
timeout=30,
auth=auth
)
response.raise_for_status()
result = response.json()
logger.info(f"Neptune のロードジョブが送信されました: {result}")
return result
except Exception as e:
logger.error(f"Neptune のロードジョブの送信に失敗しました: {e}")
raise
## フルパイプラインの実行
以下の手順で、完全なデータ処理パイプラインを実行できます:
def run_pipeline(self) -> None:
"""完全なデータ処理およびインポートパイプラインを実行する。"""
try:
# ステップ 1: Neptune の接続性をテスト
if not self.test_neptune_connection():
logger.warning("Neptune の接続性テストに失敗しましたが、パイプラインは続行します")
# ステップ 2: HotpotQA データの読み込み
data = self.load_hotpotqa_data()
# ステップ 3: データを CSV ファイルへ変換
self.process_data_to_csv(data)
# ステップ 4: 空の synonym_edges.csv ファイルを作成
with open(os.path.join(self.output_dir, 'synonym_edges.csv'), 'w', newline='', encoding='utf-8') as f:
f.write('~id,~from,~to,~label\n')
# ステップ 5: CSV ファイルを S3 にアップロード
self.upload_to_s3()
# ステップ 6: データを Neptune にインポート
load_result = self.import_to_neptune()
load_id = load_result.get("payload", {}).get("loadId")
if load_id:
# ステップ 7: インポート完了まで待機
final_status = self.wait_for_load_job(load_id)
logger.info(f"最終インポートステータス:{final_status}")
logger.info("パイプラインが正常に完了しました")
except Exception as e:
logger.error(f"パイプラインの失敗: {e}")
raise
## 実装
このセクションでは、初期設定から知識グラフの構築、検索に至るまで、HippoRAG の実装における主要な構成要素を順を追って解説します。
## 設定
まず、HippoRAG の実装のための基本的な設定を行いましょう:
from src.hipporag.utils.config_utils import BaseConfig
config = BaseConfig()
config.force_index_from_scratch = True
config.openie_mode = "online"
config.llm_name = "us.anthropic.claude-3-5-haiku-20241022-v1:0"
config.embedding_model_name = "amazon.titan-embed-text-v2:0"
config.aws_region = "us-east-1"
config.save_dir = "outputs"
config.retrieval_top_k = 3
## Neptune Analytics の統合
実装における重要な革新の一つは、パーソナライズされた PageRank(PageRank)のために Amazon Neptune Analytics との統合です。高度なグラフ解析を処理するための専用クライアントを作成します:
class NeptuneAnalyticsClient:
"""パーソナライズされた PageRank などを含む Neptune Analytics 操作用のクライアント。"""
def __init__(self, graph_id, region='us-east-1'):
"""Neptune Analytics クライアントを初期化します。"""
self.graph_id = graph_id
self.region = region
self.client = boto3.client('neptune-analytics', region_name=region)
logger.info(f"グラフ {graph_id} 用の Neptune Analytics クライアントを初期化しました")
def run_personalized_pagerank(self, seed_nodes, damping_factor=0.85, max_iterations=20, tolerance=0.0001):
"""
Neptune Analytics でパーソナライズされた PageRank アルゴリズムを実行します。
引数:
seed_nodes (list): パーソナライズド PageRank 用のシードノード ID のリスト
damping_factor (float): ダンピングファクター(デフォルト 0.85)
max_iterations (int): 最大反復回数
tolerance (float): 収束許容誤差
戻り値:
list: スコア降順にソートされた (node_id, score) タプルのリスト
"""
if not seed_nodes:
logger.warning("パーソナライズド PageRank にシードノードが提供されていません")
return []
# クエリ用のシードノードのフォーマット
seed_list = ",".join([f"'{node}'" for node in seed_nodes])
# openCypher を使用した Neptune Analytics のパーソナライズド PageRank クエリ
query = f"""
CALL neptune.algo.pagerank({{
sourceNodes: [{seed_list}],
dampingFactor: {damping_factor},
maxIterations: {max_iterations},
tolerance: {tolerance},
personalized: true
}})
YIELD nodeId, score
RETURN nodeId, score
ORDER BY score DESC
LIMIT 100
"""
try:
result = self.execute_analytics_query(query)
if result and 'results' in result:
pagerank_results = [(item['nodeId'], item['score']) for item in result['results']]
logger.info(f"パーソナライズド PageRank が {len(pagerank_results)} 件の結果を返しました")
return pagerank_results
return []
except Exception as e:
logger.error(f"Failed to run personalized PageRank: {e}")
return []
## Knowledge graph construction
HippoRAG は、Amazon Bedrock の LLM(大規模言語モデル)の機能を活用して、文書から知識グラフを構築します。このプロセスでは、テキストからエンティティと関係性を抽出します:
def index_from_neptune(self, limit=1000):
"""
Neptune データベースから直接文書をインデックス化する。
Args:
limit (int): インデックス化する文書の最大数
"""
documents = self.neptune_client.get_documents(limit=limit)
logger.info(f"Neptune データベースから {len(documents)} 件の文書をインデックス化中")
# Neptune から取得した文書を用いて、標準的なインデックス化プロセスを実行する
super().index(documents)
The indexing process involves:
- Claude LLM を用いて、パッセージから固有名称エンティティを抽出すること。
- オープン情報抽出を用いて、知識グラフのトリプル(三項関係)を作成すること。
- Amazon Titan Embeddings を使用して、エンティティの埋め込みベクトルを計算すること。
- グラフ構造を Amazon Neptune データベースに保存すること。
- 類似するエンティティ間に同義語エッジを追加すること。
Neptun のためのグラフ準備原文を表示
Large language models (LLMs) have transformed how we process and generate information, but they still struggle with effectively integrating knowledge across multiple sources. Standard Retrieval Augmented Generation (RAG) methods, although helpful, often fall short when tackling multi-hop reasoning tasks that require connecting information from separate documents. To address these limitations, we explore HippoRAG, a novel RAG framework inspired by the hippocampal memory system in human brains.
In this post, we demonstrate how to implement HippoRAG using a comprehensive AWS stack. We use Amazon Bedrock for LLM capabilities, Amazon Neptune for graph database functionality, Amazon Neptune Analytics for advanced graph algorithms including Personalized PageRank, and Amazon Titan Embeddings for vector representations. This implementation showcases how to build and deploy HippoRAG within AWS infrastructure for enterprise-scale applications.
Neurobiological inspiration and background
HippoRAG draws inspiration from the hippocampal indexing theory of human long-term memory. In human brains, the neocortex processes perceptual inputs, whereas the hippocampus creates an index of associations between memories. This dual-component system allows humans to efficiently integrate information across different experiences.
Standard RAG approaches treat each document independently, struggling with questions that require connecting information across multiple sources. HippoRAG addresses this by:
- Building a knowledge graph (KG) to represent relationships between entities.
- Using the Personalized PageRank (PPR) algorithm for efficient graph traversal and relevance ranking.
- Enabling single-step multi-hop retrieval instead of requiring multiple iterations.
Solution architecture
Our AWS implementation of HippoRAG involves four main components:
- Amazon Bedrock – Provides LLM capabilities for extracting knowledge graph triples, answering questions, and identifying named entities.
- Amazon Neptune Database – Stores the knowledge graph structure and enables basic graph operations.
- Amazon Neptune Analytics – Executes advanced graph algorithms, particularly Personalized PageRank for relevance ranking.
- Amazon Titan Embeddings – Creates vector representations of text for similarity matching.
This architecture allows us to use the full power of personalized PageRank while maintaining the scalability and reliability of AWS managed services.
Prerequisites
For this implementation, you’ll need:
- An AWS account with access to Amazon Bedrock and Neptune services.
- Amazon Neptune cluster configured and accessible.
- Amazon Neptune Analytics graph created from your Neptune Database.
- AWS Command Line Interface (AWS CLI) and Python 3.8+ installed.
- Appropriate IAM permissions for: Amazon Bedrock | Amazon Neptune | Amazon Neptune Analytics | Amazon Simple Storage Service (Amazon S3).
Data processing pipeline: From HotpotQA JSON to Neptune
A necessary first step in implementing HippoRAG is converting raw data into a knowledge graph structure suitable for Neptune. In this section, we walk through how we process HotpotQA data from JSON format. We extract knowledge-graph triples using Amazon Bedrock, generate Neptune bulk-load CSV files, upload them to Amazon S3, and load them into our Neptune cluster. Each of the following subsections corresponds to a stage of that pipeline.
Setting up the data importer
The HotpotQANeptuneImporter class orchestrates every stage of the pipeline. It handles reading the JSON source file, generating CSV outputs, uploading those files to Amazon S3, and triggering the Neptune bulk loader. Let’s look at how we initialize this class with the configuration values for our AWS environment:
class HotpotQANeptuneImporter:
"""Class to handle importing HotpotQA data into Neptune."""
def __init__(
self,
hotpotqa_file_path: str,
output_dir: str,
s3_bucket: str,
s3_prefix: str,
neptune_endpoint: str,
neptune_port: int,
iam_role_arn: str,
aws_region: str,
llm_endpoint: Optional[str] = None,
embedding_endpoint: Optional[str] = None,
max_workers: int = 4,
max_examples: int = 10,
max_docs_per_example: int = 2,
use_ssl: bool = False
):
"""Initialize the importer with configuration."""
self.hotpotqa_file_path = hotpotqa_file_path
self.output_dir = output_dir
self.s3_bucket = s3_bucket
self.s3_prefix = s3_prefix
self.neptune_endpoint = neptune_endpoint
self.neptune_port = neptune_port
self.iam_role_arn = iam_role_arn
self.aws_region = aws_region
# Initialize AWS clients
self.s3_client = boto3.client('s3', region_name=aws_region)
self.session = boto3.Session()
# Initialize data structures
self.phrase_dict = {} # Maps phrase text to node ID
self.phrase_embeddings = {} # Maps phrase text to embedding vectorKnowledge graph triple extraction
A key part of the pipeline is using Amazon Bedrock’s LLM capabilities to extract structured knowledge from raw text. For each passage, the system generates subject-relation-object triples that become edges in the knowledge graph. Here’s how we implement that extraction:
def extract_triples_with_llm(self, text: str) -> List[Tuple[str, str, str]]:
"""
Use an LLM to extract knowledge graph triples from text.
In this simplified version, just generate simple triples from the text.
"""
# Simple triple generation from text
words = text.split()
if len(words) < 5:
return []
# Generate simple triples from the words in the text
triples = []
for i in range(min(3, len(words) - 2)): # Get at most 3 triples
subject = words[i]
relation = "related_to"
obj = words[i+2]
triples.append((subject, relation, obj))
return triplesConverting JSON data to CSV format
With triples in hand, we need to serialize the graph into the CSV format that Neptune’s bulk loader expects. This processing method converts the HotpotQA JSON records into four CSV files: phrase_nodes.csv, passage_nodes.csv, relation_edges.csv, and context_edges.csv. Together, these files capture the full knowledge graph structure. Here’s how we implement that conversion:
def process_data_to_csv(self, data: List[Dict]) -> None:
"""
Process HotpotQA data into CSV files for Neptune import.
"""
logger.info("Processing HotpotQA data to CSV files")
# Open all CSV files for writing
with open(os.path.join(self.output_dir, 'phrase_nodes.csv'), 'w', newline='', encoding='utf-8') as phrase_f, \
open(os.path.join(self.output_dir, 'passage_nodes.csv'), 'w', newline='', encoding='utf-8') as passage_f, \
open(os.path.join(self.output_dir, 'relation_edges.csv'), 'w', newline='', encoding='utf-8') as relation_f, \
open(os.path.join(self.output_dir, 'context_edges.csv'), 'w', newline='', encoding='utf-8') as context_f:
# Write headers
phrase_f.write('~id,~label,text\n')
passage_f.write('~id,~label,title,content\n')
relation_f.write('~id,~from,~to,~label\n')
context_f.write('~id,~from,~to,~label\n')
# Process each example
for example in tqdm(data, desc="Processing examples"):
self._process_example(example, passage_f, phrase_f, relation_f, context_f)Processing individual examples
Each HotpotQA example is processed to create nodes and edges in the knowledge graph:
def _process_example(self, example: Dict, passage_f, phrase_f, relation_f, context_f) -> None:
"""Process a single HotpotQA example into CSV data."""
# Process limited documents in the context
doc_count = 0
for doc_title, paragraphs in example['context']:
if doc_count >= self.max_docs_per_example:
break
# Process each paragraph as a passage
for paragraph in paragraphs:
if not paragraph.strip():
continue
passage_id = f"passage_{uuid.uuid4().hex}"
# Write passage node
passage_f.write(f"{passage_id},passage,\"{self._escape_csv(doc_title)}\",\"{self._escape_csv(paragraph)}\"\n")
# Extract triples from the paragraph
triples = self.extract_triples_with_llm(paragraph)
# Process each triple
for subject, relation, obj in triples:
# Create or get subject node ID
if subject not in self.phrase_dict:
subject_id = f"phrase_{uuid.uuid4().hex}"
self.phrase_dict[subject] = subject_id
phrase_f.write(f"{subject_id},phrase,\"{self._escape_csv(subject)}\"\n")
else:
subject_id = self.phrase_dict[subject]
# Create or get object node ID
if obj not in self.phrase_dict:
obj_id = f"phrase_{uuid.uuid4().hex}"
self.phrase_dict[obj] = obj_id
phrase_f.write(f"{obj_id},phrase,\"{self._escape_csv(obj)}\"\n")
else:
obj_id = self.phrase_dict[obj]
# Write relation edge
relation_id = f"rel_{uuid.uuid4().hex}"
relation_f.write(f"{relation_id},{subject_id},{obj_id},\"{self._escape_csv(relation)}\"\n")
# Write context edges
context_f.write(f"ctx_{uuid.uuid4().hex},{passage_id},{subject_id},contains\n")
context_f.write(f"ctx_{uuid.uuid4().hex},{passage_id},{obj_id},contains\n")
doc_count += 1Loading data to Neptune
After processing the data into CSV files, the system uploads them to S3 and imports them into Neptune:
def import_to_neptune(self) -> Dict:
"""Import data into Neptune using the bulk loader API."""
logger.info(f"Importing data to Neptune endpoint {self.neptune_endpoint}")
loader_endpoint = f"{self.protocol}://{self.neptune_endpoint}:{self.neptune_port}/loader"
payload = {
"source": f"s3://{self.s3_bucket}/{self.s3_prefix}/",
"format": "csv",
"formatParams": {
"delimiter": ",",
"header": "true"
},
"iamRoleArn": self.iam_role_arn,
"region": self.aws_region,
"failOnError": "FALSE"
}
try:
# Create AWS4Auth for the request
credentials = self.session.get_credentials()
if credentials:
auth = AWS4Auth(
credentials.access_key,
credentials.secret_key,
self.aws_region,
'neptune-db',
session_token=credentials.token
)
response = requests.post(
loader_endpoint,
data=json.dumps(payload),
headers={"Content-Type": "application/json"},
timeout=30,
auth=auth
)
response.raise_for_status()
result = response.json()
logger.info(f"Neptune load job submitted: {result}")
return result
except Exception as e:
logger.error(f"Failed to submit Neptune load job: {e}")
raiseRunning the full pipeline
You can run the full data processing pipeline with the following steps:
def run_pipeline(self) -> None:
"""Run the full data processing and import pipeline."""
try:
# Step 1: Test Neptune connectivity
if not self.test_neptune_connection():
logger.warning("Neptune connectivity test failed, but proceeding with the pipeline")
# Step 2: Load HotpotQA data
data = self.load_hotpotqa_data()
# Step 3: Process data to CSV files
self.process_data_to_csv(data)
# Step 4: Create empty synonym_edges.csv file
with open(os.path.join(self.output_dir, 'synonym_edges.csv'), 'w', newline='', encoding='utf-8') as f:
f.write('~id,~from,~to,~label\n')
# Step 5: Upload CSV files to S3
self.upload_to_s3()
# Step 6: Import data to Neptune
load_result = self.import_to_neptune()
load_id = load_result.get("payload", {}).get("loadId")
if load_id:
# Step 7: Wait for import to complete
final_status = self.wait_for_load_job(load_id)
logger.info(f"Final import status: {final_status}")
logger.info("Pipeline completed successfully")
except Exception as e:
logger.error(f"Pipeline failed: {e}")
raiseImplementation
This section walks through the key components of the HippoRAG implementation, from initial configuration to knowledge graph construction and retrieval.
Configuration
First, let’s set up the basic configuration for our HippoRAG implementation:
from src.hipporag.utils.config_utils import BaseConfig
config = BaseConfig()
config.force_index_from_scratch = True
config.openie_mode = "online"
config.llm_name = "us.anthropic.claude-3-5-haiku-20241022-v1:0"
config.embedding_model_name = "amazon.titan-embed-text-v2:0"
config.aws_region = "us-east-1"
config.save_dir = "outputs"
config.retrieval_top_k = 3Neptune Analytics integration
A key innovation in our implementation is the integration with Amazon Neptune Analytics for personalized PageRank. We create a dedicated client to handle advanced graph analytics:
class NeptuneAnalyticsClient:
"""Client for Neptune Analytics operations including personalized PageRank."""
def __init__(self, graph_id, region='us-east-1'):
"""Initialize Neptune Analytics client."""
self.graph_id = graph_id
self.region = region
self.client = boto3.client('neptune-analytics', region_name=region)
logger.info(f"Initialized Neptune Analytics client for graph {graph_id}")
def run_personalized_pagerank(self, seed_nodes, damping_factor=0.85, max_iterations=20, tolerance=0.0001):
"""
Run personalized PageRank algorithm on Neptune Analytics.
Args:
seed_nodes (list): List of seed node IDs for personalized PageRank
damping_factor (float): Damping factor (default 0.85)
max_iterations (int): Maximum number of iterations
tolerance (float): Convergence tolerance
Returns:
list: List of (node_id, score) tuples sorted by score descending
"""
if not seed_nodes:
logger.warning("No seed nodes provided for personalized PageRank")
return []
# Format seed nodes for the query
seed_list = ",".join([f"'{node}'" for node in seed_nodes])
# Neptune Analytics personalized PageRank query using openCypher
query = f"""
CALL neptune.algo.pagerank({{
sourceNodes: [{seed_list}],
dampingFactor: {damping_factor},
maxIterations: {max_iterations},
tolerance: {tolerance},
personalized: true
}})
YIELD nodeId, score
RETURN nodeId, score
ORDER BY score DESC
LIMIT 100
"""
try:
result = self.execute_analytics_query(query)
if result and 'results' in result:
pagerank_results = [(item['nodeId'], item['score']) for item in result['results']]
logger.info(f"Personalized PageRank returned {len(pagerank_results)} results")
return pagerank_results
return []
except Exception as e:
logger.error(f"Failed to run personalized PageRank: {e}")
return []Knowledge graph construction
HippoRAG builds a knowledge graph from documents using LLM capabilities of Amazon Bedrock. This process extracts entities and relationships from text:
def index_from_neptune(self, limit=1000):
"""
Index documents directly from Neptune database.
Args:
limit (int): Maximum number of documents to index
"""
documents = self.neptune_client.get_documents(limit=limit)
logger.info(f"Indexing {len(documents)} documents from Neptune database")
# Use the standard indexing process with documents from Neptune
super().index(documents)The indexing process involves:
- Extracting named entities from passages using Claude LLM.
- Creating knowledge graph triples using open information extraction.
- Computing embeddings for entities using Amazon Titan Embeddings.
- Storing the graph structure in Amazon Neptune Database.
- Adding synonymy edges between similar entities.
Preparing the graph for Neptun
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み