PwC が AWS で AI を活用した契約分析の注目を集める
PwC と AWS の連携により、LLM を活用した契約分析ソリューション「AIDA」が発表され、手作業によるレビュー時間を最大 90% 削減する実証事例が示された。
キーポイント
AI 駆動型注釈付け(AIDA)の概要
PwC が AWS 上で構築した AIDA は、LLM とルールベース抽出を組み合わせ、複雑な契約書から構造化されたインサイトを抽出する。
自然言語による多層的検索機能
単一契約やプロジェクト内の複数文書に対して自然言語で質問し、根拠となる引用元(リンク付き)を提示しながら回答を得られる。
実装における劇的な効率化効果
顧客事例において、手動での契約レビュー時間を最大 90% 削減し、情報取得の迅速化とレビューサイクルの短縮を実現した。
影響分析・編集コメントを表示
影響分析
この記事は、LLM が単なるテキスト生成ツールではなく、実務上の複雑な業務(法務・コンプライアンス)を劇的に効率化する具体的なソリューションとして成熟したことを示しています。特に、引用元を明示する機能や人的レビューの必要性を強調している点は、企業における AI 導入の信頼性を高める重要な指針となります。
編集コメント
LLM の実務応用において、精度だけでなく「根拠の提示」と「人的レビューの重要性」を明確に定めた点は非常に高く評価できます。これは法務分野など、誤りが許されない領域での AI 導入における重要な成功モデルとなるでしょう。
*この投稿は、PwC の Yash Munsadwala 氏、Adam Hood 氏、Justin Guse 氏、Hector Hernandez 氏と共著です。*
契約分析には、法務、コンプライアンス、調達チームにとって多くの時間を要することが多く、特に重要なインサイトが長大で構造化されていない契約書の中に埋もれている場合、その傾向は顕著です。契約件数が増加するにつれて、特定の条項の特定や抽出された条項の評価をスケーラブルに行うことが次第に困難になっています。
現在、多くのチームは主にキーワードやパターンに基づく抽出や契約管理システムを利用して契約分析を行っています。これらの方法は機能する場合もありますが、スケールの一貫したインサイトを提供するにはしばしば不十分です。その結果、多くのチームが 大規模言語モデル (LLM) と自動化された抽出ワークフローを組み合わせる AI ベースのアプローチを検討し始めています。
AWS を基盤とした PwC の AI ドライブ型注釈(AIDA)ソリューションは、ルールベースの抽出と自然言語クエリを通じて契約書から構造化されたインサイトを抽出できます。LLM(大規模言語モデル)を活用することで、AIDA は複雑な法的言語を解釈し、定義されたルールに基づいてインサイトを抽出します。ユーザーは個々の契約書やプロジェクト内の複数の文書に対して自然言語で質問を行い、関連する引用文献によって裏付けられた文脈に特化した回答を受け取ることができます。契約書の言語を手動で検索・解釈する必要を減らすことで、これらの機能はレビューワークフローの効率化に貢献します。顧客への導入事例では、AIDA は手動による契約書レビュー時間を最大 90% 削減し、チームが重要な情報をより迅速に取得してレビューサイクルを短縮するのを支援しました。本稿では、AIDA がこれらの課題にどのように対応するかを示します。AIDA の背後にあるアーキテクチャを紹介し、テンプレートベースの抽出、文書レベルでのチャット、および文書間でのグローバルチャットの 3 つの中核機能をデモンストレーションします。
ソリューション概要
AIDA は、非構造化文書を構造化され検索可能なインサイトに変換し、システム間で重要な契約情報へのアクセスと再利用のプロセスを合理化するために設計されています。AIDA は、大規模言語モデル(LLM)と AWS のクラウドネイティブおよび統合サービスの組み合わせを活用し、契約からより効果的にインサイトを抽出します。このソリューションは、組織のセキュリティ、コンプライアンス、リスク管理要件をサポートする機能を提供しますが、顧客自身が特定のコンプライアンス義務を満たすためにソリューションを構成・運用する責任を負います。AIDA は潜在的に機密性の高い契約データを処理するため、AI 生成出力をビジネスまたは法的な目的で利用する前に、適切な保護措置と人的レビューのワークフローを適用する必要があります。AIDA は、既存の課題に対処するために設計された包括的な機能スイートを提供します。以下の主要機能は中核機能を強調しており、これらについては後続のセクションで詳しく解説します。
- カスタマイズされたデータ抽出:ユーザー定義のルールとカスタムテンプレートによって可能になるスケーラブルなデータの抽出。ドキュメントごとにカスタム抽出フィールドとロジックを使用し、数千件の契約を並列処理して一貫した精度でインサイトを抽出できます。
- ドキュメント間での自然言語による Q&A:自然言語で質問を行い、ソースドキュメントへのリンク付きの引用を含む文脈に特化した回答を受け取ります。
- モデルシステムとの統合:ソースデータの取得や抽出されたインサイトの提供に使用できるモデルシステム(例えば、契約管理システムやドキュメントリポジトリ)と統合します。
AIDA は、メディア・エンターテインメント (M&E) や不動産といった幅広い業界、および調達、法務、コンプライアンスといった専門分野において、スケーラブルな契約分析をサポートします。例えば、M&E 業界では、AIDA はライセンス契約から権利情報を抽出・分析することで、コンテンツプロデューサーやディストリビューターが知的財産 (IP) の全体的な価値を解き放つのを支援します。放送、ストリーミング、劇場公開、派生作品などの権利を要約し、スピンオフ、続編、グローバル展開に関する迅速で根拠のある意思決定を可能にします。ある大手映画・テレビスタジオでは、権利調査にかかる時間を 90% 削減しました。
AIDA のアーキテクチャ概要
本アーキテクチャは、スケーラブルでクラウドネイティブな AWS サービスを活用し、複雑な契約書からセキュリティを確保しながら処理・分析を行い、洞察を提供するまでの AIDA の各コンポーネントがどのように連携するかを示しています。各コンポーネントは、セキュリティ、追跡可能性、およびパフォーマンスを維持しつつ、大規模な契約書を処理できるように設計されています。
1. エッジセキュリティとアクセス管理
AIDA のエッジ層は、ユーザートラフィックに対する認証されたアクセスと制御されたルーティングを可能にします。リクエストはまず AWS WAF を通過して脅威フィルタリングが行われ、その後、ネットワークロードバランサーを経由してリバースプロキシサーバー(NGINX)へ転送されます。ここで SSL 終端処理、ルーティング、ポリシーの適用が管理され、その後 Amazon Elastic Container Service (Amazon ECS) へ転送されます。転送中のデータは TLS 1.2 以上で暗号化されており、HTTPS を通じたユーザー接続や、Amazon ECS と Amazon Relational Database Service (Amazon RDS)、Amazon Simple Storage Service (Amazon S3)、Amazon Bedrock およびその他の AWS サービス間の内部サービス間通信も含まれます。
認証は Amazon Cognito を通じて処理され、エンタープライズ ID プロバイダー(例:Microsoft Entra ID、Okta)と統合されることで、大規模なアクセスを保護します。AIDA はアプリケーションレベルおよびプロジェクトレベルのロールを通じて細粒度のアクセス制御を適用し、管理者がユーザーアクセスと権限を一元管理できるようにしています。プロジェクトレベルのロールは、管理者がユーザーの権限を制御し、各ユーザーがプロジェクト内で実行できるアクションを定義することを支援し、データや機能への安全で統制されたアクセスを提供します。
2. データストレージ
認証後、AIDA はアップロードされたドキュメント、光学式文字認識 (OCR) の出力、および関連メタデータを Amazon S3 に保存し、大量の契約データを管理するための耐久性が高くコスト効果の高い方法を提供します。構造化データ、設定情報、および抽出されたインサイトは Amazon RDS に永続化され、ユーザーが分析や統合のために効果的にクエリを実行してインサイトを取得できるようにしています。
Amazon S3 バケットは、Amazon S3 管理暗号化キー (SSE-S3) を使用して保存時に暗号化され、Amazon RDS インスタンスは AWS KMS 管理キーを使用して保存時に暗号化されます。さらに、S3 バケットの設定は、バケットレベルでのパブリックアクセスのブロックと、セキュリティ分析および監査目的のためのアクセスログの有効化を含む Amazon S3 のベストプラクティス に従っています。
3. OCR および予測処理
OCR と抽出ワークフローは、AWS Fargate を使用して Amazon ECS 上で非同期に実行され、タスクの調整には Amazon Simple Queue Service(Amazon SQS)が利用されます。このアプローチにより、ユーザーは対話処理をブロックすることなく、大量の契約書を並列で処理することが可能になります。
抽出ルールは、関連するコンテンツがどのように特定され、Amazon Bedrock 上でホストされるファウンデーションモデル(FMs)へ送信されるかを規定しており、ここで大規模言語モデル(LLM)が契約書テキストを解釈して構造化された値を抽出します。結果は Amazon RDS に書き込まれ、レビュー、ダッシュボード、および統合のために利用可能になります。
4. Retrieval Augmented Generation (RAG)
契約書を分析する際、回答の正確性と、それが元の原文にどのように遡れるかが極めて重要です。RAG は、モデルの知識のみを頼りにするのではなく、基盤となる契約書の内容に基づいてモデルの回答を裏付けることで、この課題に対処します。AIDA は RAG を活用し、回答が基盤となる契約書のテキストに基づいていることを検証します。Amazon S3 に保存された文書は Amazon Bedrock Embedding Models(埋め込みモデル)を使用してエンベディングされ、そのベクトルは Amazon OpenSearch Serverless にインデックス登録されてセマンティック検索を可能にしています。推論時には、関連データが Amazon Bedrock Knowledge Bases から取得され、ユーザーの入力と組み合わせられることで、正確で文脈を意識し、説明可能な結果が生成されます。
さらに、AIDA は Amazon Bedrock Guardrails を使用して、コンテンツフィルタリングの適用、機密情報(PII)の保護、プロンプトの安全性制御を行い、回答がセキュリティを維持し、企業および法的基準に合致していることをさらに確認しています。
5. Visualization
契約書がどのように処理されているかを示すため、AIDA は Amazon Quick Sight と統合されており、文書のボリューム、OCR の精度、抽出スループット、処理ステータスなどの指標を可視化します。
このダッシュボードは、システムパフォーマンスの可視化を提供し、時間経過に伴う効率改善のためのボトルネックや機会を特定するのに役立ちます。
6. 社内・ベンダー・サードパーティシステムにわたるシステム統合
AIDA は、AWS Lambda、Amazon EventBridge、および Amazon SQS を用いて下流のシステムと統合されます。これらの統合により、抽出されたインサイトは契約ライフサイクル管理ツール、データシステム、またはその他の運用システムへ配信されます。構成可能な人間を介在させるループ(ヒューマン・イン・ザ・ループ)レビューキューにより、下流へ転送される前に抽出結果の検証と承認を行うことができます。
組織が、現在使用されているツールに構造化された契約データをプッシュすることで、手動でのデータ処理を削減し、コンプライアンス、レポート作成、分析ワークフロー全体で契約インサイトを再利用することが可能になります。
7. 付帯およびシステムサービス
AIDA のコアシステムを支える一連の AWS 付帯サービスが、セキュリティ、観測性(observability)、自動化を提供しています。AWS Identity and Access Management (AWS IAM) と AWS Key Management Service (AWS KMS) はアクセス管理と暗号化を担い、IAM ポリシーは最小権限の原則に従って実装されています。Amazon CloudWatch と AWS X-Ray が監視機能を提供し、一方 AWS CodeBuild, AWS CodePipeline, および AWS CloudTrail はデータ操作のアクセスログを有効化することで、継続的なデプロイと監査可能性を実現しています。
では、これらの効率向上をもたらすインテリジェント機能を特に可能にする Amazon Bedrock の仕組みについて探っていきましょう。
Amazon Bedrock が AIDA のインテリジェント機能を可能にする仕組み
Amazon Bedrock は、AIDA のインテリジェントな洞察抽出、情報抽出、および対話型機能を実現します。高度なファウンデーションモデル(FMs)を AIDA の処理パイプラインに統合することで、文脈を考慮したデータ抽出、セマンティック検索、インタラクティブなチャット機能を可能にしています。AIDA は、ドキュメント処理、OCR(光学文字認識)、セマンティック検索、LLM(大規模言語モデル)による推論を統一されたワークフローでオーケストレーションし、クエリまたは事前定義されたルールに基づいて関連するセクションを検索します。また、Amazon Bedrock を活用して RAG(Retrieval-Augmented Generation:検索拡張生成)をサポートし、出典文書への明確な引用付きで回答を提供します。
主要機能を紹介するために、Contract Understanding Atticus Dataset (CUAD) からサンプル契約書を AIDA にアップロードしました。これは The Atticus Project の数十人の法律専門家と共に作成されたオープンな法的契約レビュー用データセットです。CUAD データセットは、研究および評価目的での利用と配布を許可するクリエイティブ・コモンズ表示 4.0(CC BY 4.0)ライセンスの下で一般に公開されています。
1. 再利用可能なテンプレートによるスマートかつ高速な洞察抽出
*再利用可能なテンプレート* は、一度抽出ロジックを定義し、それを複数のドキュメントに適用することで、大規模に一貫した契約属性を抽出できます。各テンプレートは、終了通知期間、更新条項、または法務・コンプライアンスチームが頻繁にレビューする権利条項など、重要な契約要素を表すラベルをグループ化しています。
テンプレートを一連の契約書に適用すると、同じ抽出ルールが文書全体で一貫して使用されます。これにより、特に大量の契約書を扱う際に、手動レビューの負担を軽減しつつ、精度と一貫性を向上させることができます。裏側では、AIDA はページやセクションのコンテキストを保持する構造化表現を用いて各契約書を処理します。抽出ルールは関連コンテンツがどのように特定されるかを指引し、大規模言語モデル(LLM)はその文脈を解釈して正確な値を抽出します。結果には引用が付与され、元の契約書テキストへとリンクするため、各インサイトがどこから得られたかを確認できます。
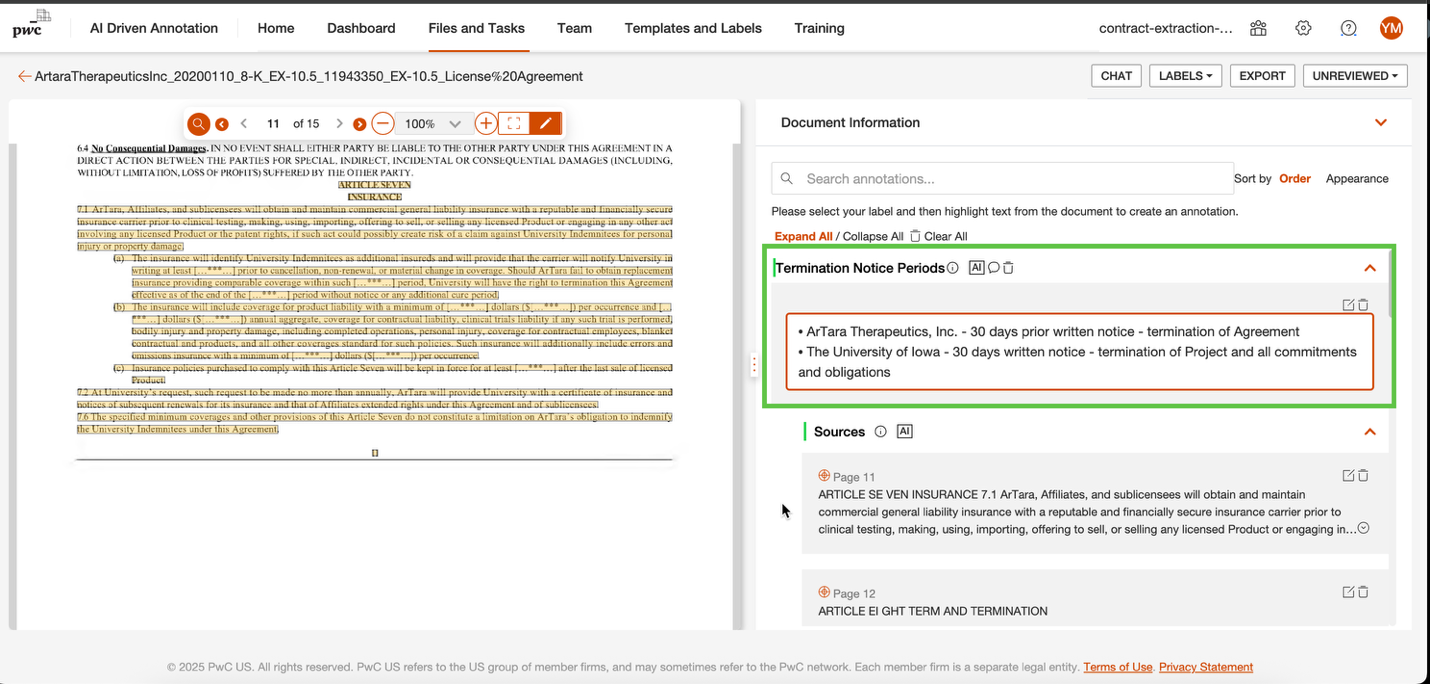
例えば、「Termination Notice Period」というラベルは、以下のスクリーンショットに示される契約書からタイムラインを直接抽出し、右側のパネルでは抽出された回答(緑色でハイライト)が表示され、契約書内の正確なソーステキストへのクリック可能な参照が含まれています。
2. ドキュメントレベルのチャット
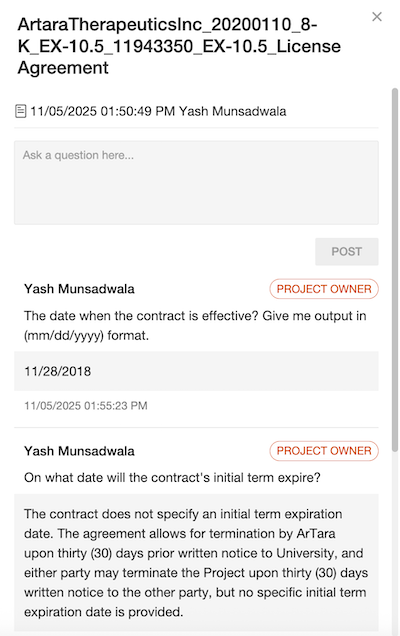
*ドキュメントレベルのチャット*機能を使用すると、単一の契約書について自然言語で質問を行い、その文書に直接根拠を置いた回答を受け取ることができます。この機能は、特定の条項、日付、または義務に関する迅速な確認が必要な場合に特に有用であり、手動で長くて複雑な契約書をスキャンする手間を防ぎます。
質問が提出されると、AIDA はドキュメントの内容のセマンティック表現に対してクエリを比較することで、契約書の中で最も関連性の高いセクションを特定します。その後、これらのセクションは Amazon Bedrock でホストされている大規模言語モデル(LLM)にコンテキストとして提供され、契約書のテキストに基づいて回答が生成されます。
3. グローバルチャット
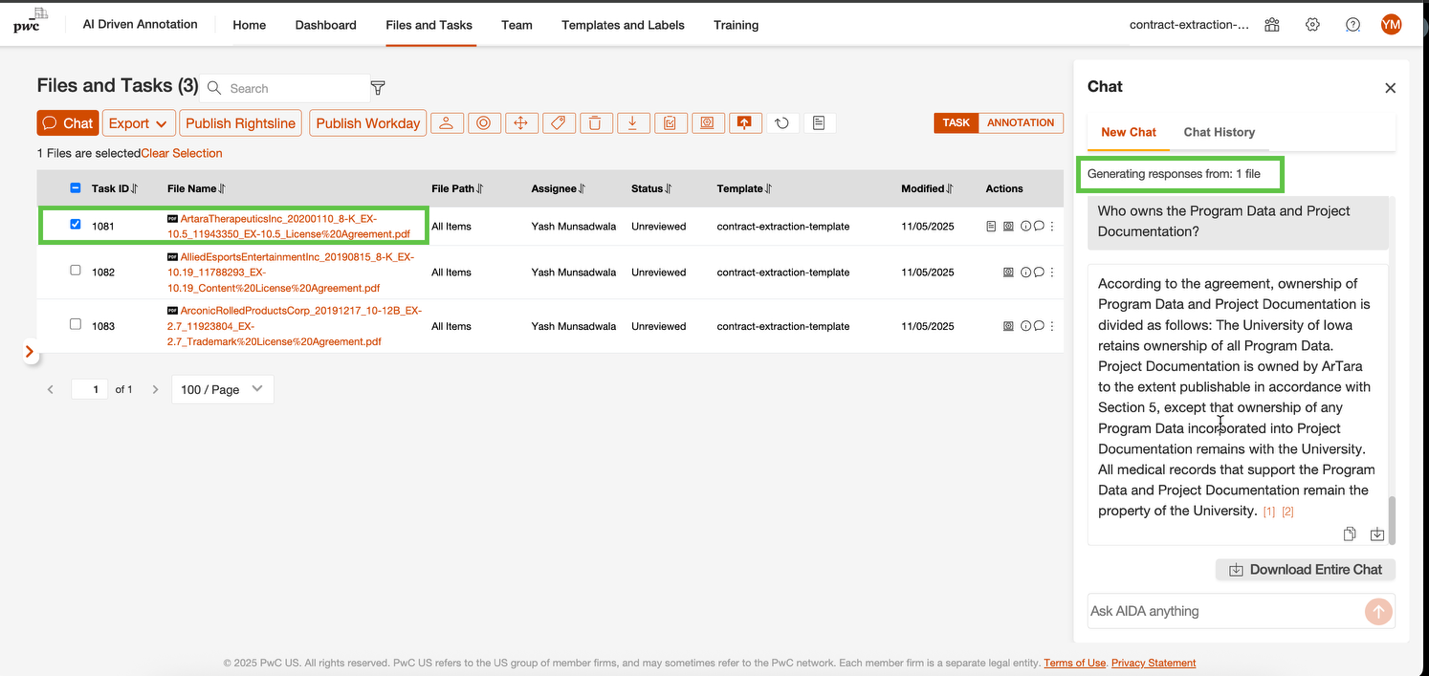
*グローバルチャット*は、ドキュメントレベルのチャット機能を拡張し、プロジェクト内の複数の契約書にわたる質問に対応できるようにした機能です。この機能は、共通条項の特定や義務の比較、関連する一連の合意事項全体における条項の要約など、より広範な視点が必要な場合に有用です。
グローバルチャットには 2 つの利用方法があります。1 つ目のシナリオでは、プロジェクト内の契約書全体に対して質問が評価され、統合されたプロジェクト全体のビューが提供されます。もう 1 つのシナリオでは、質問の対象を特定の契約書のセットに限定できるため、ユーザーは同じ会話型インターフェースを使用しながら、特定の合意事項に焦点を当てることができます。
AIDA は、Amazon Bedrock を用いて、基盤となる契約書から文書内容を抽出・埋め込み(embedding)することで、意味的な知識ベースを構築します。これらの埋め込みは Amazon OpenSearch Serverless にインデックスされ、大規模で多様な契約コレクション全体にわたるクエリをサポートできるスケーラブルな意味層が作成されます。
質問を送信すると、AIDA は暗黙的フィルタリングと明示的フィルタリングの組み合わせを用いて関連する記述部を取得します。暗黙的フィルタリングは、クエリと契約内容との間の意味的な類似性に基づき、文脈的に関連するセクションを提示します。一方、明示的フィルタリングは、契約の種類、作成日、事業部門、管轄区域などのメタデータ制約を適用し、結果を最も関連性の高いサブセットに絞り込みます。選択されたコンテキストはその後、Amazon Bedrock 上でホストされる大規模言語モデル(LLM)へ提供され、元のソース文書へのリンクを含む引用付きで統合された回答が生成されます。
AIDA システム上に構築された支援機能
以下のセクションでは、AIDA のシステム上に構築された支援機能について説明します。これには、運用ダッシュボードと外部システムとの連携が含まれます。
オペレーショナルダッシュボード
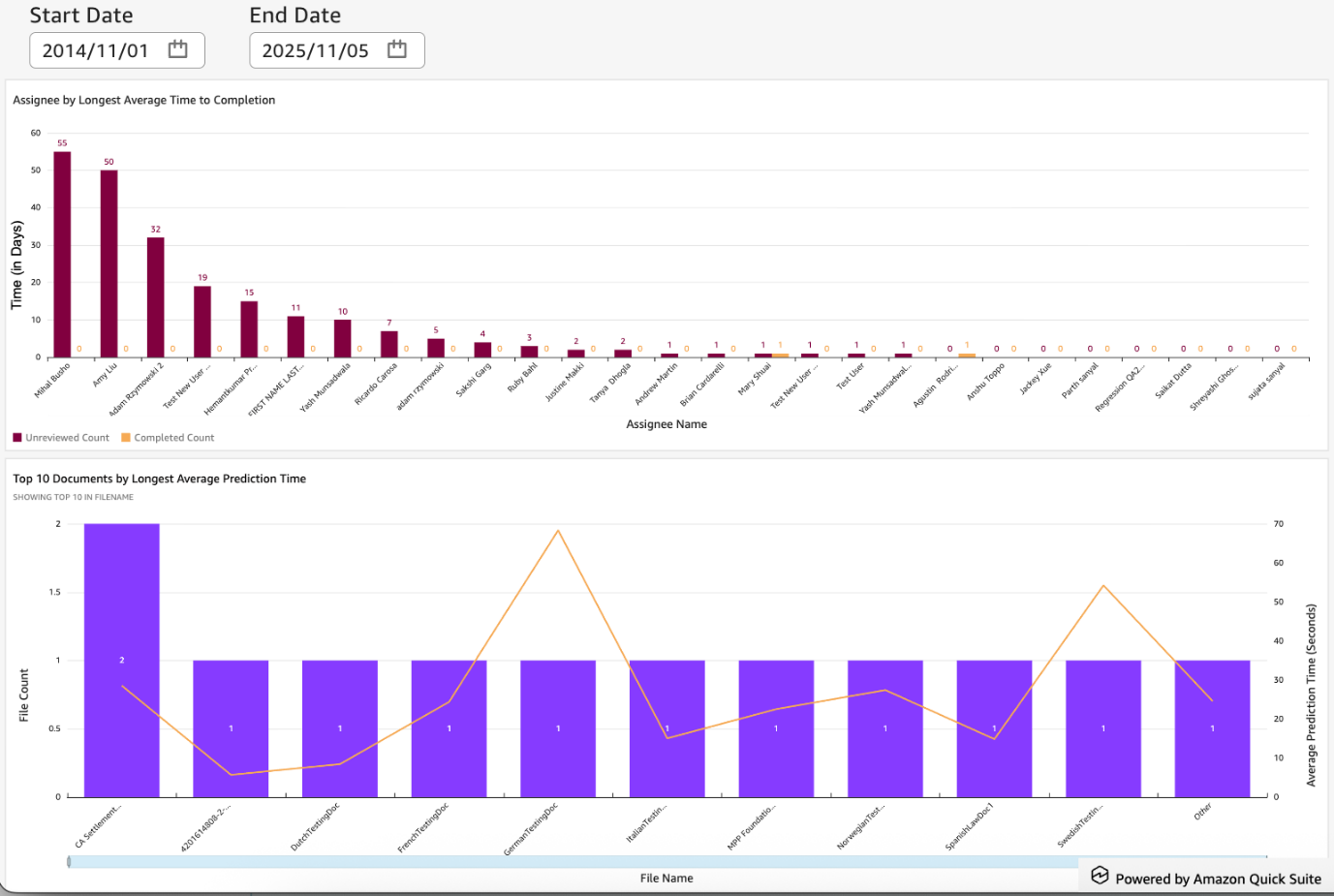
オペレーショナルダッシュボードは、プロジェクトレベルでの契約レビューパフォーマンスの統合ビューを提供し、ファイルボリューム、OCR(光学文字認識)およびインサイト抽出の完了率、エラー、抽出精度を追跡します。これにより、チームはボトルネックをすばやく特定し、レビュアーの生産性をモニタリングできます。
外部システム連携
AIDA(AI駆動型注釈)によって生成された構造化された抽出インサイトは、契約ライフサイクル管理(CLM)ツール、ERP システム、CRM、データウェアハウスなどの下流システムへすばやくプッシュできます。この統合により、高品質で機械可読な契約データを内部または外部システムに付加し、システム間での手動データ再入力や照合を削減します。これらのインサイトを直接システムに埋め込むことで、組織はコンプライアンスモニタリングの向上と、より迅速なデータ駆動型の意思決定をサポートできます。
結論
AWS を活用した PwC の AI ドライブ型注釈(AIDA)ソリューションは、組織が手動契約レビューから、より高速で信頼性が高くスケーラブルなアプローチへと移行することを支援します。OCR、ユーザー定義の抽出ルール、Amazon Bedrock を介した検索拡張生成(RAG)を統合することで、AIDA は複雑な契約内に埋もれた重要な用語、義務、およびインサイトをすばやく特定するのに役立ちます。
このソリューションは、法務および運用ワークフローの合理化を支援し、レビュー時間を短縮するとともに、大量の文書にわたる一貫性を向上させます。
原文を表示
*This post was co-written with Yash Munsadwala, Adam Hood, Justin Guse, and Hector Hernandez from PwC.*
Contract analysis often consumes significant time for legal, compliance, and procurement teams, especially when important insights are buried in lengthy, unstructured agreements. As contract volumes grow, finding specific clauses and assessing extracted terms can become increasingly difficult to scale.
Today, many teams rely primarily on keyword and pattern-based extraction or contract management systems to analyze contracts. While these methods can work, they often fall short of providing consistent insights at a scale. As a result, many teams are exploring AI-based approaches that can combine large language models (LLMs) with automated extraction workflows.
PwC’s AI-driven annotation (AIDA) solution, built on AWS, can extract structured insights from contracts through rule-based extraction and natural language queries. Using LLMs, AIDA can interpret complex legal language and extracts insights based on defined rules. Users can ask natural language questions about individual contracts or across multiple documents within a project and receive context-specific answers supported by linked citations. By reducing the need to manually search and interpret contract language, these capabilities help streamline review workflows. In customer implementations, AIDA has helped reduce manual contract review time by up to 90%, helping teams to retrieve key information more quickly and shorten review cycles. In this post, you will see how AIDA addresses these challenges. We walk through the architecture behind AIDA and demonstrate three core capabilities: template-based extraction, document-level chat, and global chat across documents.
Solution overview
AIDA is designed to convert unstructured documents into structured, searchable insights, streamlining the process to access and reuse critical contract information across systems. AIDA uses LLMs and a combination of AWS cloud-native and integrated services to help extract insights from contracts more effectively. The solution provides capabilities that can support organizational security, compliance, and risk management requirements, though customers remain responsible for configuring and operating the solution to meet their specific compliance obligations. As AIDA processes potentially sensitive contractual data, appropriate safeguards and human review workflows should be applied prior to business or legal reliance on AI-generated outputs. AIDA provides a holistic suite of capabilities designed to address existing challenges. The following key features highlight core functionality, which we explore in detail in the subsequent sections:
- Customized Data Extraction: Extract scalable data enabled by user-defined rules and custom templates. Use the custom extraction field and logic per document and extract insights from thousands of contracts in parallel with consistent accuracy.
- Natural Language Q&A Across Documents: Ask natural language questions and receive context-specific responses with linked citations to the source documents.
- Integration with Model Systems: Integrate with model systems (for example, contract management systems and document repositories) that you can use to retrieve source data and deliver extracted insights.
AIDA can support scalable contract analysis across a wide range of industries, including Media & Entertainment (M&E) and Real Estate—and competencies like Procurement, Legal, and Compliance. For instance, in the M&E sector, AIDA helps content producers and distributors unlock the overall value of their IP by extracting and analyzing rights information from license agreements. It summarizes rights such as broadcast, streaming, theatrical, and derivative enabling faster, informed decisions on spin-offs, sequels, and global distribution. One major film and TV studio reduced rights research time by 90%.
AIDA’s architecture overview
The architecture illustrates how AIDA’s components work together to securely process, analyze, and deliver insights from complex contracts using the scalable, cloud-native services of AWS. Each component is designed to help process contracts at scale while maintaining security, traceability, and performance.
1. Edge security and access
AIDA’s edge layer enables authenticated access and controlled routing for user traffic. Requests pass through AWS WAF for threat filtering, then through a Network Load Balancer to the reverse proxy server (NGINX), which manages SSL termination, routing, and policy enforcement before forwarding to Amazon Elastic Container Service (Amazon ECS). Data in transit is encrypted using TLS 1.2 or higher, including user connections through HTTPS, and internal service-to-service communication between Amazon ECS, Amazon Relational Database Service (Amazon RDS), Amazon Simple Storage Service (Amazon S3), Amazon Bedrock, and other AWS services.
Authentication is handled through Amazon Cognito, integrated with enterprise identity providers (for example, Microsoft Entra ID, Okta) to secure access at scale. AIDA applies fine-grained access control through both application-level and project-level roles, so administrators can manage user access and permissions centrally. Project-level roles help administrators to control user permissions and define what actions each user can perform within a project, providing secure and governed access to data and functionality.
2. Data storage
After authentication, AIDA stores uploaded documents, Optical Character Recognition (OCR) outputs, and associated metadata in Amazon S3 providing a durable and cost-effective way to manage large volumes of contract data. Structured data, configurations, and extracted insights persist in Amazon RDS, so users can query and retrieve insights effectively for analytics and integration.
Amazon S3 buckets are encrypted at rest using Amazon S3-managed encryption keys (SSE-S3), and Amazon RDS instances are encrypted at rest using AWS KMS-managed keys. Furthermore, S3 bucket setup follows Amazon S3 best practices including: Block Public Access enabled at the bucket level and enabling access logging for security analysis and audit purposes.
3. OCR and prediction processing
OCR and extraction workflows run asynchronously on Amazon ECS using AWS Fargate, with tasks coordinated through Amazon Simple Queue Service (Amazon SQS). With this approach, users can process large volumes of contracts in parallel without blocking user interactions.
Extraction rules guide how relevant content is identified and sent to foundation models (FMs) hosted on Amazon Bedrock, where LLMs can interpret the contract text and extract structured values. Results are written back to Amazon RDS, where they’re available for review, dashboards, and integrations.
4. Retrieval Augmented Generation (RAG)
When analyzing contracts, it’s critical that answers are accurate and traceable back to the original source text. RAG help address this by grounding model responses in the underlying contract content, rather than relying solely on the model’s knowledge. AIDA uses RAG to help verify that responses are grounded in the underlying contract text. Documents stored in Amazon S3 are embedded using Amazon Bedrock Embeddings Models, with vectors indexed in Amazon OpenSearch Serverless for semantic search. During inference, relevant data is retrieved from Amazon Bedrock Knowledge Bases and combined with user input, producing accurate, context-aware, and explainable results.
In addition, AIDA uses Amazon Bedrock Guardrails to apply content filtering, sensitive information (PII) protection, and prompt safety controls, further confirming that responses remain secure and aligned with enterprise and legal standards.
5. Visualization
To show how contracts are being processed, AIDA integrates with Amazon Quick Sight to visualize metrics such as document volumes, OCR accuracy, extraction throughput, and processing status.
This dashboard can give visibility into system performance and helps identify bottlenecks or opportunities to improve efficiency over time.
6. System integrations across internal, vendor, and third-party systems
AIDA integrates with downstream systems using AWS Lambda, Amazon EventBridge, and Amazon SQS. These integrations deliver extracted insights to contract lifecycle management tools, data systems, or other operational systems. A configurable human-in-the-loop review queue can validate and approve extracted outputs before they are forwarded downstream.
By pushing structured contract data into tools in use, organizations can reduce manual data handling and reuse contract insights across compliance, reporting, and analytics workflows.
7. Ancillary and system services
A range of ancillary AWS services support AIDA’s core system providing security, observability, and automation. AWS Identity and Access Management (AWS IAM) and AWS Key Management Service (AWS KMS) manage access and encryption, with IAM policies implemented following the principle of least privilege; Amazon CloudWatch and AWS X-Ray provide monitoring; while AWS CodeBuild, AWS CodePipeline, and AWS CloudTrail enable continuous deployment and auditability by enabling access logging for data operations.
Let’s explore how Amazon Bedrock specifically enables the intelligent features that drive these efficiency gains.
How Amazon Bedrock enables AIDA’s intelligent features
Amazon Bedrock enables AIDA’s intelligent insights, extraction and conversational capabilities. By integrating advanced FMs into AIDA’s processing pipeline, Amazon Bedrock enables context-aware data extraction, semantic retrieval, and interactive chat functionalities. AIDA orchestrates document processing, OCR, semantic retrieval, and LLM reasoning in a unified workflow retrieving relevant sections based on queries or predefined rules and using Amazon Bedrock to support RAG and provide responses with clear citations to the source documents.
To showcase the key features, we uploaded sample contracts to AIDA from the Contract Understanding Atticus Dataset (CUAD), an open legal contract review dataset created with dozens of legal experts from The Atticus Project. The CUAD dataset is publicly available under the Creative Commons Attribution 4.0 (CC BY 4.0) license, permitting use and distribution for research and evaluation purposes.
1. Smarter, faster insights extraction through reusable templates
*Reusable templates* can extract consistent contract attributes at scale by helping users to define extraction logic once and apply it across multiple documents. Each template groups together labels that represent key contract elements such as termination notice periods, renewal terms, or rights clauses that legal and compliance teams frequently review.
When a template is applied to a set of contracts, the same extraction rules are used consistently across documents. This helps reduce manual review effort while improving accuracy and consistency, especially when working with large contract volumes. Behind the scenes, AIDA processes each contract using a structured representation that preserves page and section context. Extraction rules guide how relevant content is identified, and LLMs interpret that context to extract the correct values. Results are returned with citations that link back to the original contract text, enabling you to verify where each insight came from.
For example, the Termination Notice Period label extracts timelines directly from the contract shown in the following screenshot, while the right panel displays the extracted answer (highlighted in green) with clickable references to the exact source text within the contract.
2. Document-level chat
You can use *document-level chat* to ask natural language questions about a single contract and receive answers grounded directly in that document. This capability is particularly useful when quick clarification on specific terms, dates, or obligations is needed, preventing you from manually scanning lengthy and complex agreements.
When questions are submitted, AIDA can identify the most relevant sections of the contract by comparing queries against a semantic representation of the document’s content. Those sections are then provided as context to an LLM that’s hosted on Amazon Bedrock, which generates a response based on the contract text.
3. Global chat
*Global chat* extends the document-level chat feature to support questions across multiple contracts within a project. This feature is useful when a broader view is needed, such as identifying common clauses, comparing obligations, or summarizing terms across a collection of related agreements.
Global chat can be used in two ways. In one scenario, questions are evaluated across the contracts in a project to provide a consolidated, project-wide view. In another scenario, questions can be scoped to a selected set of contracts, so users can focus on specific agreements while using the same conversational interface.
AIDA helps build a semantic knowledge base using Amazon Bedrock from the underlying contracts by extracting and embedding document content for search. These embeddings are indexed in Amazon OpenSearch Serverless, creating a scalable semantic layer that can support queries across large and diverse contract collections.
When submitting a question, AIDA can retrieve relevant passages using a combination of implicit and explicit filtering. Implicit filtering relies on semantic similarity between queries and the contract content to surface contextually relevant sections. Explicit filtering applies metadata constraints such as contract type, creation date, business unit, or jurisdiction to narrow results to the most relevant subset. The selected context is then provided to an LLM hosted on Amazon Bedrock, which generates a consolidated response with citations linking back to the original source documents.
Supporting capabilities built on AIDA’s system
The following section describes the supporting capabilities that are built on AIDA’s system: operational dashboard and external system integrations.
Operational dashboard
The operational dashboard provides a consolidated view of contract review performance at the project level tracking file volumes, OCR and insight extraction completion rates, errors, and extraction accuracy. It helps teams quickly spot bottlenecks and monitor reviewer’s productivity.
External System Integrations
The structured extracted insights generated by AIDA can be quickly pushed to downstream systems such as Contract Lifecycle Management (CLM) tools, ERP systems, CRMs, or data warehouses. This integration helps enrich internal or external systems with high-quality, machine-readable contract data, reducing manual data re-entry and reconciliation across systems. By embedding these insights directly into these systems, organizations can improve compliance monitoring and support faster, data-driven decisions.
Conclusion
PwC’s AI-driven annotation (AIDA) solution, enabled by AWS, helps move organizations beyond manual contract review to a faster, more reliable, and scalable approach. By bringing together OCR, user-defined extraction rules, and Retrieval Augmented Generation through Amazon Bedrock, AIDA helps quickly identify key terms, obligations, and insights buried within complex contracts.
The solution helps streamline legal and operational workflows, reduce review time, and improve consistency across large volumes of documents.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み