Stable Virtual Cameraの紹介:3Dカメラ制御によるマルチビュー動画生成
Stability AI が公開した「Stable Virtual Camera」は、単一または複数の画像から複雑な再構築を要さずに、ユーザー定義の軌道を含む多様なカメラ動きで没入感のある 3D ビデオを生成する画期的なマルチビュー拡散モデルである。
キーポイント
高度なカメラ制御機能
ユーザーが定義した軌道に加え、360 度、レムニスケート(∞字)、スパイラル、ドリーズームなど 14 種類の動的なカメラパスをサポートし、精密な視点操作を可能にする。
柔軟な入力と出力形式
単一画像から最大 32 枚の画像を入力として受け付け、正方形や縦長など任意のアスペクト比に対応した 1,000 フレームまでの一貫性のある 3D ビデオを生成できる。
技術的革新と性能
従来の複雑な事前処理や大規模画像セットを必要とせず、ViewCrafter や CAT3D を上回る新視点合成(NVS)ベンチマークで SOTA 性能を発揮する。
研究コミュニティ向け公開
現在リサーチプレビューとして非商用ライセンスの下で提供されており、論文、モデル重み、コードがそれぞれ Hugging Face や GitHub で入手可能である。
柔軟なサンプリングプロセス
固定長の学習データとは異なり、二段階の手順的サンプリング(アンカービュー生成→ターゲットビューの断片化レンダリング)により、任意の入力・出力ビュー数を処理可能。
品質と精度の評価
LPIPS(知覚品質)とPSNR(精度)を指標として主要な3D動画モデルと比較ベンチマークされ、異なるデータセットや入力設定での性能が測定されている。
利用制限と課題
人間や動物が含まれる画像、動的テクスチャ(水など)、複雑なカメラパスでは品質低下やフリッカーが発生する可能性があり、研究目的の非商用ライセンスでの提供となる。
影響分析・編集コメントを表示
影響分析
この発表は、3D コンテンツ制作における従来の複雑なワークフロー(大規模画像セットや専用最適化の必要性)を根本から簡素化する可能性を秘めています。特に映画制作やゲーム開発において、単なる静止画から即座に没入感のある 3D シーンを生成できる技術は、クリエイティブなプロダクション効率を劇的に向上させるでしょう。ただし、現時点では非商用ライセンスであるため、商業利用への普及にはさらなる展開が期待されます。
編集コメント
従来の 3D ビデオ生成モデルが抱えていた「複雑な前処理」や「大量の画像入力」という課題を、単一画像と直感的なカメラ制御で解決した点は非常に注目すべき進展です。クリエイターにとってのハードルが下がる一方で、商用利用への道が開かれるかどうかが今後の鍵となります。
キーポイント
Stable Virtual Camera の紹介。現在は研究プレビュー版です。このマルチビュー拡散モデルは、複雑な再構築やシーン固有の最適化を必要とせず、2D 画像から現実的な奥行きと視点を持つ没入型 3D ビデオに変換します。
本モデルは、単一の入力画像または最大 32 枚の画像から、ユーザーが定義したカメラ軌道に加え、360°、レムニスケート(無限大記号)、螺旋、ドリーズーム、移動、パン、ロールを含む 14 の他の動的なカメラパスに沿って 3D ビデオを生成します。
Stable Virtual Camera は非商用ライセンスの下で研究利用が可能です。論文はここから、重み付けデータは Hugging Face からダウンロードでき、コードは GitHub でアクセスできます。
今日、私たちは Stable Virtual Camera をリリースしました。現在は研究プレビュー版です。このマルチビュー拡散モデルは、複雑な再構築やシーン固有の最適化を必要とせず、2D 画像から現実的な奥行きと視点を持つ没入型 3D ビデオに変換します。研究コミュニティの皆様には、その機能を探求し、開発に貢献していただくことを歓迎いたします。
バーチャルカメラは、映画制作や 3D アニメーションで使用されるデジタルツールで、リアルタイムでデジタルシーンを撮影・移動するために用いられます。Stable Virtual Camera はこの概念を基盤とし、従来のバーチャルカメラの familiar な操作性と生成 AI の力を組み合わせることで、3D ビデオ出力に対する精密かつ直感的な制御を提供します。
従来の大規模な入力画像セットや複雑な前処理に依存する 3D ビデオモデルとは異なり、Stable Virtual Camera は、ユーザーが指定したカメラ角度から 1 つ以上の入力画像を用いて、シーンの新規ビューを生成します。このモデルは、一貫性があり滑らかな 3D ビデオ出力を生み出し、動的なカメラ経路全体でシームレスな軌道動画を配信します。
このモデルは、非商用ライセンスの下で研究利用が可能です。論文はこちらで読むことができ、重み(weights)は Hugging Face でダウンロードでき、コードは GitHub でアクセスできます。
機能
Stable Virtual Camera は、3D ビデオの生成に関する高度な機能を備えています。以下が含まれます:
ダイナミックカメラ制御:ユーザー定義のカメラ経路および複数の動的カメラ経路をサポートします。具体的には、360°、レムニスケート(∞字形の経路)、螺旋、ドリーズームイン、ドリーズームアウト、ズームイン、ズームアウト、前方移動、後方移動、パンアップ、パンダウン、パン左、パン右、ロールです。
柔軟な入力:1 つの入力画像のみ、または最大 32 枚から 3D ビデオを生成します。
複数のアスペクト比:追加のトレーニングなしで、正方形(1:1)、縦長(9:16)、横長(16:9)、およびその他のカスタムアスペクト比のビデオを生成可能です。
長時間動画の生成:最大 1,000 フレームまでのビデオにおいて 3D の一貫性を確保し、同じ視点に再訪する場合でも、シームレスなループと滑らかなトランジションを実現します。
研究およびモデルアーキテクチャ
Stable Virtual Camera は、新規視点合成(NVS)ベンチマークにおいて最先端の結果を達成し、ViewCrafter や CAT3D といったモデルを上回っています。これは、生成能力を重視する大規模視点の NVS と、時間的な滑らかさを優先する小規模視点の NVS の両方で卓越した性能を発揮します。
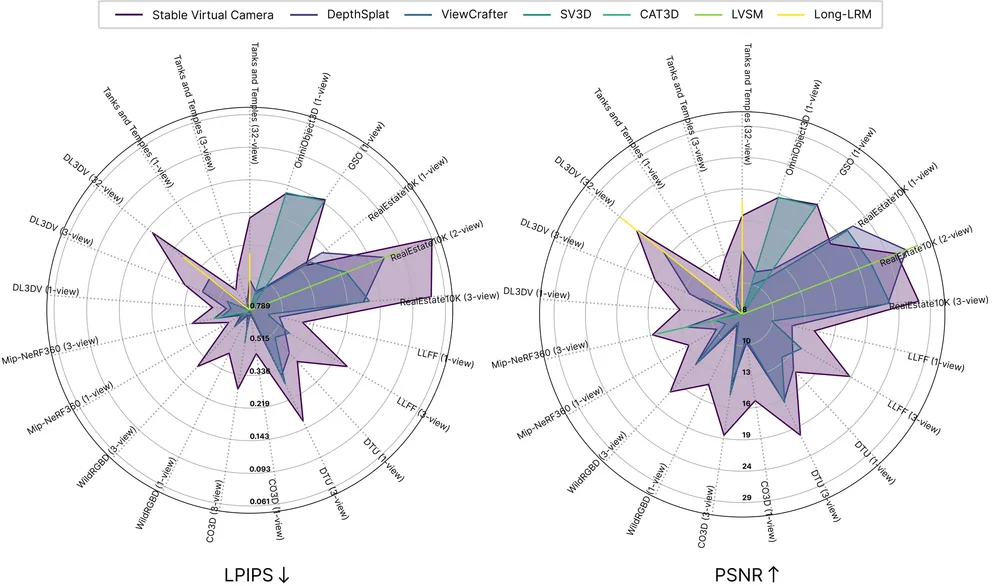
これらのチャートは、主要な 3D ビデオモデルをデータセット間でベンチマークし、知覚的品質(LPIPS)と精度(PSNR)を測定しています。各軸は異なるデータセットおよび入力設定を反映しています。
Stable Virtual Camera は、固定されたシーケンス長で訓練されたマルチビュー拡散モデルとして動作し、特定の数の入力視点とターゲット視点(M-in, N-out)を受け取ります。
Stable Virtual Camera は、固定されたシーケンス長を持つマルチビュー拡散モデルとして訓練されており、入力とターゲットのビューの数(M-in, N-out)が一定に設定されています。サンプリング時には、柔軟な生成レンダラーとして機能し、可変の入力および出力長(P-in, Q-out)に対応します。これは、2 段階の手順的サンプリングプロセスによって実現されます。まずアンカービューを生成し、その後ターゲットビューをチャンク単位でレンダリングすることで、滑らかで一貫性のある結果を保証します。
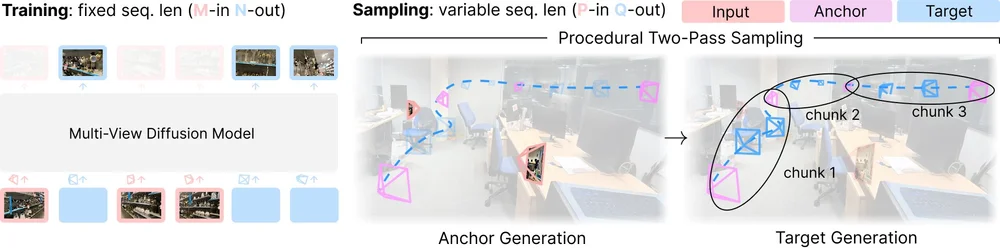
Stable Virtual Camera は、手順的な 2 段階サンプリングを採用することで、任意の入力数およびターゲット数を処理します。
モデルのアーキテクチャとパフォーマンスの詳細については、こちらで完全な研究論文をお読みいただけます。
Model limitations
初期バージョンでは、Stable Virtual Camera は特定のシナリオにおいて品質の低い結果を生成する可能性があります。人間や動物、水のような動的なテクスチャを含む入力画像は、出力の劣化につながることがよくあります。さらに、非常に曖昧なシーン、物体や表面と交差する複雑なカメラパス、不規則な形状の物体は、特にターゲット視点が入力画像から大きく異なる場合に、フリッカーアーティファクトを引き起こす原因となります。
Stable Virtual Camera は、非商用ライセンスの下で研究目的に限り無料で利用できます。論文の閲覧や重み付けデータのダウンロードは Hugging Face で、コードは GitHub で入手可能です。
当プロジェクトの進捗を最新の状態でお知りになりたい場合は、X、LinkedIn、Instagram のアカウントをフォローするか、Discord コミュニティにご参加ください。
原文を表示
Key Takeaways
Introducing Stable Virtual Camera, currently in research preview. This multi-view diffusion model transforms 2D images into immersive 3D videos with realistic depth and perspective—without complex reconstruction or scene-specific optimization.
The model generates 3D videos from a single input image or up to 32, following user-defined camera trajectories as well as 14 other dynamic camera paths, including 360°, Lemniscate, Spiral, Dolly Zoom, Move, Pan, and Roll.
Stable Virtual Camera is available for research use under a Non-Commercial License. You can read the paper here, download the weights on Hugging Face, and access the code on GitHub.
Today, we're releasing Stable Virtual Camera, currently in research preview. This multi-view diffusion model transforms 2D images into immersive 3D videos with realistic depth and perspective—without complex reconstruction or scene-specific optimization. We invite the research community to explore its capabilities and contribute to its development.
A virtual camera is a digital tool used in filmmaking and 3D animation to capture and navigate digital scenes in real-time. Stable Virtual Camera builds upon this concept, combining the familiar control of traditional virtual cameras with the power of generative AI to offer precise, intuitive control over 3D video outputs.
Unlike traditional 3D video models that rely on large sets of input images or complex preprocessing, Stable Virtual Camera generates novel views of a scene from one or more input images at user specified camera angles. The model produces consistent and smooth 3D video outputs, delivering seamless trajectory videos across dynamic camera paths.
The model is available for research use under a Non-Commercial License. You can read the paper here, download the weights on Hugging Face, and access the code on GitHub.
Capabilities
Stable Virtual Camera offers advanced capabilities for generating 3D videos, including:
Dynamic Camera Control: Supports user-defined camera trajectories as well as multiple dynamic camera paths, including: 360°, Lemniscate (∞ shaped path), Spiral, Dolly Zoom In, Dolly Zoom Out, Zoom In, Zoom Out, Move Forward, Move Backward, Pan Up, Pan Down, Pan Left, Pan Right, and Roll.
Flexible Inputs: Generates 3D videos from just one input image or up to 32.
Multiple Aspect Ratios: Capable of producing videos in square (1:1), portrait (9:16), landscape (16:9), and other custom aspect ratios without additional training.
Long Video Generation: Ensures 3D consistency in videos up to 1,000 frames, enabling seamless loops and smooth transitions, even when revisiting the same viewpoints.
Research & model architecture
Stable Virtual Camera achieves state-of-the-art results in novel view synthesis (NVS) benchmarks, outperforming models like ViewCrafter and CAT3D. It excels in both large-viewpoint NVS, which emphasizes generation capacity, and small-viewpoint NVS, which prioritizes temporal smoothness.
image
These charts benchmark leading 3D video models across datasets, measuring perceptual quality (LPIPS) and accuracy (PSNR). Each axis reflects a different dataset and input setup.
Stable Virtual Camera is trained with a fixed sequence length as a multi-view diffusion model, taking a set number of input and target views (M-in, N-out).
Stable Virtual Camera is trained as a multi-view diffusion model with a fixed sequence length, using a set number of input and target views (M-in, N-out). During sampling, it functions as a flexible generative renderer, accommodating variable input and output lengths (P-in, Q-out). This is achieved through a two-pass procedural sampling process—first generating anchor views, then rendering target views in chunks to ensure smooth and consistent results.
image
Stable Virtual Camera uses procedural two-pass sampling to handle any number of input and target views.
For a deeper dive into the model’s architecture and performance, you can read the full research paper here.
Model limitations
In its initial version, Stable Virtual Camera may produce lower-quality results in certain scenarios. Input images featuring humans, animals, or dynamic textures like water often lead to degraded outputs. Additionally, highly ambiguous scenes, complex camera paths that intersect objects or surfaces, and irregularly shaped objects can cause flickering artifacts, especially when target viewpoints differ significantly from the input images.
Get started
Stable Virtual Camera is free to use for research purposes under a Non-Commercial License. You can read the paper and download the weights on Hugging Face and code on GitHub.
To stay updated on our progress, follow us on X, LinkedIn, Instagram, and join our Discord Community.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み