HexagonがAmazon SageMaker HyperPodでAIモデル生産を加速
HexagonはAWSと協力し、Amazon SageMaker HyperPodのトレーニング基盤を活用して最先端のセグメンテーションモデルを事前学習し、AIモデル生産を拡大しました。
キーポイント
HexagonがAWS SageMaker HyperPodを活用してAIモデル生産を拡大
点群データ向けの専門的セグメンテーションモデルを事前学習
産業向けAIモデルの効率化と精度向上を実現
建設・都市計画・自動運転など多分野への応用可能性
汎用AIではなく特定課題に特化したモデルの有効性を示す
影響分析・編集コメントを表示
影響分析
この記事は、産業向けAIの実用化において、汎用モデルではなく特定課題に特化した専門モデルの開発と、クラウド基盤を活用した効率的な学習プロセスの重要性を示している。HexagonとAWSの連携は、測量技術とAIインフラの融合による産業変革の可能性を提示しており、建設・製造・都市計画など現実世界の課題解決へのAI応用を加速させる事例と言える。
編集コメント
汎用AIブームの中で、特定産業課題に特化したAIモデルの開発とクラウドインフラ活用の具体例として注目。実世界データの処理効率化におけるベストプラクティスを示している。
Amazon SageMaker HyperPod を活用した Hexagon における AI モデル生産の加速
このブログ記事は、Hexagon の Johannes Maunz、Tobias Bösch Borgards、Aleksander Cisłak、Bartłomiej Gralewicz と共著です。
Hexagon は計測技術の世界リーダーであり、重要な産業が信頼を寄せることで、構築・航行・革新が可能となる確信を提供しています。マイクロメートルから火星まで、Hexagon のソリューションは航空宇宙、農業、自動車、建設、製造、鉱業の各分野において、生産性、品質、安全性、持続可能性を推進します。
これらの産業におけるアプリケーションでは、Hexagon の計測技術を用いて膨大な量の高精度なポイントクラウドデータを記録し、現実を捉えることがよくあります。ポイントクラウドとは、3 次元空間内のデータ点の集合であり、通常は物体またはシーンの外部表面を表すものです。ポイントクラウドは、3D モデリング、コンピュータビジョン、ロボティクス、自律走行車、地理空間分析などのアプリケーションで一般的に使用されています。
Hexagon は、顧客がアプリケーションにおいて生産性、品質、安全性、あるいは持続可能性を確保できるよう支援するために、専用の AI モデルを提供しています。これらの AI モデルは特定のドメイン向けに特別に設計されており、通常は構築された環境の理解に焦点を当てています。
本ブログ記事では、Amazon SageMaker HyperPod のモデルトレーニングインフラストラクチャ(infrastructure)を活用して最先端のセグメンテーションモデル(segmentation models)を事前学習させることで、Hexagon が Amazon Web Services と協力し、AI モデル生産をどのようにスケーリングしたかを示します。
AI の影響と機会
Hexagon が顧客に提供する AI モデルは、複雑な課題の解決を支援します。これらの課題は、大規模で汎用的なモデルよりも効果的なことが多い、専門化された AI モデルによって解決されます。地理空間アプリケーションでスキャンされた点群データを使用する前に、前処理や点群のクリーニング操作を実行することが不可欠です。単一の AI モデルを使ってデータセット全体を分類することに依存するのではなく、特定の操作に取り組むターゲット型の AI モデルが開発されています。例えば、1 つは塵やセンサーノイズによる不要な点を効率的に除去し、別の 1 つは複雑な環境でも土地の種類を分離し、さらに別の 1 つは移動中の物体(自動車や歩行者)を検出して排除しつつ、シーン内の固定された物体は保持します。この AI アプローチは、精度と効率性を向上させるだけでなく、処理要件を削減し、より迅速かつ正確な 3D モデルの作成につながります。
以下の図は、Hexagon が開発している点群分類モデルなどの専門化された AI モデルの実践的な応用例を示しています。
最初の図は、モバイルマッピング道路モデルがどのようにして都市全体のデジタルツイン(Digital Twin)の作成を可能にするかを示しています。

2 つ目の図は、現場での意思決定を可能にする重機建設モデルです。

堅牢でスケーラブル、かつ高性能なインフラストラクチャを実装することで、Hexagon の AI 革新と市場投入までの期間を大幅に短縮する大きな機会があります。これにより、効率的かつ迅速なモデルのトレーニングや開発が可能となり、新しい専門的な AI ユースケースを数ヶ月ではなく数日で実現できるようになります。
Hexagon と Amazon SageMaker HyperPod: 成功事例
スケーラブルな計算リソースへのアクセス、最新 GPU の利用、そして合理化されたトレーニングパイプラインという Hexagon のニーズに対応するため、Hexagon チームはモデルトレーニング要件に対して Amazon SageMaker HyperPod の主要機能を評価しました。
レジリエントなアーキテクチャ: SageMaker HyperPod は、プロアクティブなノードヘルスチェックと自動クラスタ監視を通じて運用を合理化しました。組み込まれた自己修復機能とジョブの自動再開により、トレーニング実行を数週間から数ヶ月にわたって中断なく継続することが可能になります。ノード障害が発生した場合、自動的に検知して故障したノードを交換し、最新のチェックポイントからトレーニングを再開します。
スケーラブルなインフラストラクチャ: シングルスパインノードトポロジーと事前設定済みの Elastic Fabric Adapter (EFA) を使用することで、SageMaker HyperPod は最適なノード間通信を実現します。柔軟な計算容量割り当てにより、パフォーマンスを損なうことなくシームレスにスケーリングが可能で、複数のノードにわたる増加するワークロードに理想的です。
多様なデプロイメント:SageMaker HyperPod は、幅広い生成 AI ソフトウェアスタックと互換性があり、ライフサイクルスクリプトおよび Helm カスタマイズを通じてデプロイを簡素化します。NVIDIA Blackwell GPU によって加速された P6-B200 や P6e-GB200 など、主要な Amazon Elastic Compute Cloud (Amazon EC2) インスタンスをサポートし、実装における柔軟性を提供しています。
効率的な運用:インテリジェントなタスクガバナンスと統合された SageMaker ツールを通じて、SageMaker HyperPod はクラスター利用率を自動的に最適化します。互換性のあるドライバーとライブラリを備えた事前設定済みの Deep Learning Amazon Machine Images (DLAMI) と、クイックスタートトレーニングレシピを組み合わせることで、最大限の運用効率を確保できます。
ソリューション概要
Hexagon は、以下の図に示すように、Amazon SageMaker HyperPod 管理インフラストラクチャを活用した堅牢な学習環境を実装しました。これには、統合されたデータパイプライン、コンピュータークラスターの管理、および MLOps モニタリングスタックが含まれています。
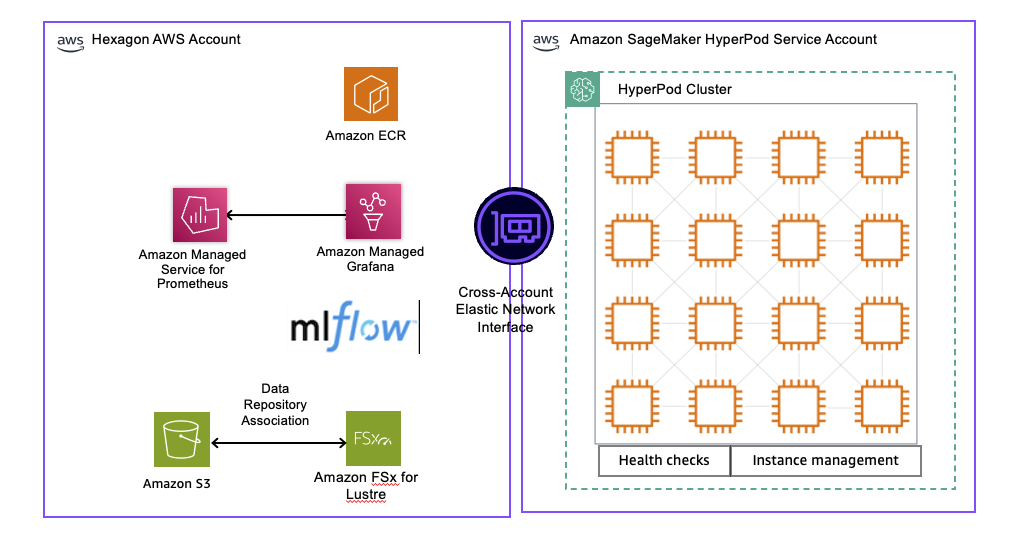
ソリューションアーキテクチャ図
データパイプラインとストレージ
トレーニングデータは、Hexagon の AWS アカウント内の Amazon Simple Storage Service (Amazon S3) に保存されており、高性能な並列ファイルシステム機能を提供するために Amazon FSx for Lustre が利用されています。この Amazon FSx for Lustr ファイルシステムには、S3 バケットと自動的に同期するデータリポジトリ関連付け(DRA)が設定されており、これによりトレーニングデータの遅延読み込みが可能になり、モデルのチェックポイントが自動的に Amazon S3 へエクスポートされます。
この構成により、テラバイト単位のトレーニングデータをマルチ GB/秒のスループットレートで GPU アクセラレータ付きコンピューティングノードに直接ストリーミングすることが可能となり、モデルトレーニング中のデータ転送ボトルネックを解消します。DRA は、データサイエンティストがトレーニング中に並列ファイルシステムの性能上の利点を享受しつつも、慣れ親しんだ Amazon S3 インターフェースで作業できることを保証する役割を果たしています。
コンピューティングクラスターの管理
SageMaker HyperPod クラスターは、組み込みのヘルスチェックと自動化されたインスタンス管理機能でプロビジョニングされています。Amazon SageMaker Training Plans を通じて、Hexagon は 1 日から 6 ヶ月までの柔軟な GPU キャパシティを予約することができ、短期間の実験的実行から拡張されたトレーニングキャンペーンに至るまで、リソースの可用性を確保するのに役立ちます。これらのトレーニングプランは予測可能な価格設定と専用キャパシティを提供し、重要なモデル開発におけるオンデマンドリソースの可用性の不確実性を排除します。クラスターはノード障害やジョブの再開を自動的に処理し、手動介入なしにトレーニングの継続性を維持します。
MLOps および監視スタック
この環境は、Amazon SageMaker HyperPod から提供されるワンクリック観測ソリューションと統合されており、包括的なメトリクスを自動的に Amazon Managed Service for Prometheus に公開し、基盤モデル開発に最適化された事前構築済みの Amazon Managed Grafana ダッシュボードを通じて可視化します。
この統一された観測機能は、NVIDIA Data Center GPU Manager、Kubernetes ノードエクスポートラー、EFA(Elastic Fabric Adapter)、統合ファイルシステム、および SageMaker HyperPod タスクオペレーターからのヘルスとパフォーマンスデータを統合し、リソース利用率、GPU メモリ、FLOPs に関する GPU レベルごとの監視を可能にします。
実験追跡については、Amazon SageMaker AI 上の MLflow が、Hexagon のトレーニングコンテナに対する最小限のコード修正のみで済む完全マネージド型ソリューションを提供します。この統合により、すべての実験実行においてトレーニングパラメータ、メトリクス、モデルアーティファクト、および系譜(ラインジ)が自動的に追跡され、モデルパフォーマンスの比較や結果の信頼できる再現が可能になります。
Hexagon における SageMaker HyperPod の利用による主要な成果
Hexagon による SageMaker HyperPod の導入は、デプロイ速度、トレーニング効率、モデルパフォーマンスのすべての面で測定可能な改善をもたらしました。
迅速な統合とデプロイメント:Hexagon は SageMaker HyperPod をトレーニングに成功裡に統合し、数時間以内に最初のトレーニングデプロイを完了しました。これはセットアップの容易さと、機械学習(ML)開発者にとって向上したエンドユーザー体験を反映しています。モデルトレーニングに必要なすべてのサービスを単一のエコシステム内で利用可能にしたことが、セキュリティおよびガバナンス要件の満たしにつながりました。
トレーニング時間の短縮:Hexagon は、特定のネットワークと構成におけるオンプレミスでのトレーニング時間を 80 日から削減しました。AWS では、各インスタンスに 8 つの NVIDIA H100 GPU を搭載した ml.p5.48xlarge インスタンスを 6 台使用し、約 4 日で完了しています。EFA(Elastic Fabric Adapter)ネットワークインターフェースは、マルチノード GPU トレーニングにおける低遅延・高スループットなネットワーキングを通じて分散トレーニングの効率を向上させます。
パフォーマンスの強化:SageMaker HyperPod は、トレーニング中により大きなバッチサイズを可能にし、これによりトレーニングパフォーマンスが向上しました。その結果、トレーニングされた AI モデルの精度スコアが高まりました。
AWS Enterprise Support は、Hexagon による Amazon SageMaker HyperPod の成功した導入において決定的な役割を果たしました。先行的なガイダンス、深い技術的専門知識、そして専任のパートナーシップを通じて、AWS Enterprise Support チームは Hexagon が初期の AWS 採用から高度な生成 AI 実装に至るまでのクラウド移行を支援しました。包括的なサポートにはベストプラクティスに関するガイダンス、コスト最適化戦略、継続的なアーキテクチャアドバイスが含まれており、Hexagon のチームが運用上の卓越性を維持しながらイノベーションに集中できる環境を提供しました。この戦略的パートナーシップは、AWS Enterprise Support が従来のサポートサービスを超え、顧客のビジネス変革を加速し、クラウド上で望ましい成果を達成するよう支援する信頼できるアドバイザーとなっていることを示しています。
Hexagon と Amazon Web Services の協力により、Amazon SageMaker HyperPod を通じてトレーニング時間の驚異的な 95% の短縮が実現しました。柔軟なトレーニングプランにより、Hexagon チームは各モデルトレーニングプロジェクトに必要な加速された計算リソースの正確な量を、完全な柔軟性と自由度をもってプロビジョニングできるようになりました。この柔軟性、スケーラビリティ、そしてパフォーマンスの組み合わせは、Hexagon におけるモデル開発に変革的なアプローチをもたらすものであり、イノベーションを加速させ、顧客が重要な産業分野で構築・ナビゲート・革新を行うのを支援する次世代の AI 搭載製品のパワーソースとなっています。
著者について
原文を表示
Accelerating AI model production at Hexagon with Amazon SageMaker HyperPod
This blog post was co-authored with Johannes Maunz, Tobias Bösch Borgards, Aleksander Cisłak, and Bartłomiej Gralewicz from Hexagon.
Hexagon is the global leader in measurement technologies and provides the confidence that vital industries rely on to build, navigate, and innovate. From microns to Mars, Hexagon’s solutions drive productivity, quality, safety, and sustainability across aerospace, agriculture, automotive, construction, manufacturing, and mining.
Applications in these industries often rely on capturing the reality by recording vast amounts of highly accurate point cloud data with Hexagon measurement technology. A point cloud is a collection of data points in 3D space, typically representing the external surface of an object or a scene. Point clouds are commonly used in applications like 3D modeling, computer vision, robotics, autonomous vehicles, and geospatial analysis.
Hexagon provides specialized AI models to its customers to help them ensure productivity, quality, safety, or sustainability in their applications. These AI models are purpose built for a given domain and usually focus on understanding the built environment.
In this blog post, we demonstrate how Hexagon collaborated with Amazon Web Services to scale their AI model production by pretraining state-of-the-art segmentation models, using the model training infrastructure of Amazon SageMaker HyperPod.
AI impact and opportunity
AI models provided by Hexagon to its customers help them solve complex challenges. These challenges are solved by specialized AI models that are often more effective than large, general-purpose ones. Before using scanned point clouds in geospatial applications, it’s essential to perform preprocessing and point cloud cleaning operations. Instead of relying on a single AI model to classify an entire dataset, targeted AI models have been developed that tackle distinct operations: one efficiently removes stray points from dust or sensor noise, another helps separate land types even in complex environments, and another detects and eliminates moving objects like cars and pedestrians while keeping fixed objects in the scene. This AI approach not only improves precision and efficiency, but also reduces processing demands and leads to faster creation of and more accurate 3D models.
The following figures illustrate the practical application of specialized AI models, such as the point cloud classification models that Hexagon is developing.
The first figure shows how mobile mapping road models enable the creation of digital twins of entire cities.
The second figure is a heavy construction model that enables on-site decision making.
There’s a significant opportunity to accelerate Hexagon’s AI innovation and time-to-market by implementing a robust, scalable, and high-performance infrastructure that enables efficient and fast model training and development of new, specialized AI use cases in days rather than months.
Hexagon and Amazon SageMaker HyperPod: A success story
To address Hexagon’s need for scalable compute resources, access to the latest GPUs, and streamlined training pipelines, the Hexagon team evaluated the key features of Amazon SageMaker HyperPod for their model training requirements:
Resilient architecture: SageMaker HyperPod streamlined operations through proactive node health checks and automated cluster monitoring. With built-in self-healing capabilities and automated job resumption, it enables training runs to run for weeks or months without interruptions. In the event of a node failure, it will automatically detect the failure, replace the faulty node, and resume the training from the most recent checkpoint.
Scalable infrastructure: Using single-spine node topology and pre-configured Elastic Fabric Adapter (EFA), SageMaker HyperPod delivers optimal inter-node communication. Its flexible compute capacity allocation enables seamless scaling without compromising performance, making it ideal for growing workloads spanning multiple nodes.
Versatile deployment: Compatible with a wide range of generative AI software stacks, SageMaker HyperPod simplifies deployment through lifecycle scripts and Helm customization. It supports leading Amazon Elastic Compute Cloud (Amazon EC2) instances like the P6-B200 and P6e-GB200, which are accelerated by NVIDIA Blackwell GPUs, offering versatility in implementation.
Efficient operations: Through intelligent task governance and integrated SageMaker tools, SageMaker HyperPod automatically optimizes cluster utilization. Pre-configured Deep Learning Amazon Machine Images (DLAMI) with compatible drivers and libraries, combined with quick start training recipes, help to ensure maximum operational efficiency.
Solution overview
Hexagon implemented a robust training environment using Amazon SageMaker HyperPod managed infrastructure, shown in the following figure. It includes an integrated data pipeline, compute cluster management, and MLOps monitoring stack.
Solution Architecture Diagram
Data pipeline and storage
Training data is stored in Amazon Simple Storage Service (Amazon S3) within Hexagon’s AWS account, with Amazon FSx for Lustre providing high-performance parallel file system capabilities. The Amazon FSx for Lustre file system is configured with a data repository association (DRA) that automatically synchronizes with the S3 bucket, enabling lazy loading of training data and automatic export of model checkpoints back to Amazon S3.
This configuration enables streaming of terabytes of training data directly to GPU accelerated compute nodes at multi-GBs per second throughput rates, eliminating data transfer bottlenecks during model training. The DRA helps ensure that data scientists can work with familiar Amazon S3 interfaces while benefiting from the performance advantages of a parallel file system during training.
Compute cluster management
SageMaker HyperPod cluster provisioned with built-in health checks and automated instance management. Through Amazon SageMaker Training Plans, Hexagon can flexibly reserve GPU capacity from 1 day to 6 months, helping to ensure resource availability for both short experimental runs and extended training campaigns. These training plans provide predictable pricing and dedicated capacity, eliminating the uncertainty of on-demand resource availability for critical model development. The cluster automatically handles node failures and job resumption, maintaining training continuity without manual intervention.
MLOps and monitoring stack
The environment integrates with a one-click observability solution from Amazon SageMaker HyperPod, which automatically publishes comprehensive metrics to Amazon Managed Service for Prometheus and visualizes them through pre-built Amazon Managed Grafana dashboards optimized for foundation model development.
This unified observability consolidates health and performance data from NVIDIA Data Center GPU Manager, Kubernetes node exporters, EFA, integrated file systems, and SageMaker HyperPod task operators, enabling per-GPU level monitoring of resource utilization, GPU memory, and FLOPs.
For experiment tracking, MLflow on Amazon SageMaker AI provides a fully managed solution that requires minimal code modifications to Hexagon’s training containers. This integration enables automatic tracking of training parameters, metrics, model artifacts, and lineage across all experiment runs, with the ability to compare model performance and reproduce results reliably.
Key outcomes from using SageMaker HyperPod at Hexagon
Hexagon’s implementation of SageMaker HyperPod delivered measurable improvements across deployment speed, training efficiency, and model performance.
Quick integration and deployment: Hexagon successfully integrated SageMaker HyperPod for training and achieved their first training deployment within hours, reflecting the ease of set-up and enhanced end-user experience for machine learning (ML) developers. Having all the services required for training models under a single ecosystem helped meet security and governance needs.
Training time reduction: Hexagon reduced their training time from 80 days on-premises for a given network and configuration to approximately 4 days on AWS using 6x ml.p5.48xlarge instances each containing eight NVIDIA H100 GPUs, with EFA network interface that boosts distributed training efficiency through low-latency, high throughput networking for multi-node GPU training.
Performance enhancement: SageMaker HyperPod enabled larger batch sizes during training, which led to better training performance, resulting in higher accuracy scores for the trained AI models.
AWS Enterprise Support played a crucial role in Hexagon’s successful implementation of Amazon SageMaker HyperPod. Through proactive guidance, deep technical expertise, and dedicated partnership, the AWS Enterprise Support team helped Hexagon navigate their cloud journey from initial AWS adoption to advanced generative AI implementations. The comprehensive support included best practices guidance, cost optimization strategies, and continuous architectural advice, so that Hexagon’s team could focus on innovation while maintaining operational excellence. This strategic partnership demonstrates how AWS Enterprise Support goes beyond traditional support services, becoming a trusted advisor that helps customers accelerate their business transformation and achieve their desired outcomes in the cloud.
Hexagon’s collaboration with Amazon Web Services delivered a remarkable 95% reduction in training time through Amazon SageMaker HyperPod. With flexible training plans, Hexagon teams can now provision the exact amount of accelerated compute capacity needed for each model training project with complete flexibility and freedom. This combination of flexibility, scalability, and performance unlocks a transformative approach to model development at Hexagon, accelerating innovation and powering the next generation of AI-enabled products that help customers build, navigate, and innovate across critical industries.
About the Authors
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み