Amazon Bedrock ナレッジベースの自動同期ソリューションの構築とデプロイ
AWS Machine Learning Blogは、Amazon Bedrock Knowledge BasesにおけるS3データとナレッジベースの自動同期ソリューションについて、イベント駆動型アーキテクチャを用いた実装方法とサービスクォータの考慮事項を解説している。
キーポイント
自動同期の必要性と課題
ドキュメントの追加・更新・削除時に手動同期を行う非効率さを解消し、マルチユーザー環境やリアルタイムアプリケーション向けに自動化が必要である。
サービスクォータの制約
Amazon Bedrockは並列 ingestion ジョブ数(アカウントあたり5件、ナレッジベースあたり1件など)に厳しい制限を設けており、これを尊重する設計が必須である。
サーバーレスな解決策の提案
S3イベントを検知して ingestion ジョブをトリガーするサーバーレスアーキテクチャにより、APIへの負荷を抑えつつナレッジベースの最新状態を維持する。
クォータチェックロジック
Amazon Bedrockのデータソースに対して、現在実行中または開始待ちのインジェストジョブ数を監視し、最大同時ジョブ数を超えていないか確認する関数が実装されている。
SQSキューによるレートリミティング
可視性タイムアウトやメッセージ保持期間、デッドレターキュー(DLQ)の設定を適切に構成することで、同期処理のレートリミティングとエラーハンドリングを実現している。
堅牢なエラーハンドリングの実装
失敗したメッセージ用のデッドレターキュー、一時的な障害に対する自動リトライロジック、およびトラブルシューティングを容易にするCloudWatchによる詳細なログ記録が実装されています。
デプロイに必要なAWSサービスとツールの準備
Amazon Bedrock、Lambda、SQSなど複数のAWSサービスの権限と、AWS CLI、SAM CLI、Python 3.12以降の開発環境の準備が必要です。
影響分析・編集コメントを表示
影響分析
本記事は、大規模組織がAmazon Bedrockを運用する際の現実的な課題である「データ同期の遅延」と「API制限」に対する具体的な解決策を示している。技術的には革新的ではないものの、実務レベルでの運用効率向上とエラー防止に寄与する重要なベストプラクティスとして、開発者やアーキテクトにとって参考価値が高い。
編集コメント
Bedrockの普及に伴い、ナレッジベースのデータ管理は単なる構築から「運用・維持」へ焦点が移っている。本記事の示すクォータ管理と自動化パターンは、実務での安定稼働に直結する重要な知見である。
Amazon Bedrock Knowledge Bases を使用することで、組織のプライベートなデータソースからコンテキスト情報を取得し、より関連性が高く、正確でカスタマイズされた応答を提供する基盤モデル(FMs)やエージェントに情報を提供できます。データが増大するにつれて、Amazon Simple Storage Service(Amazon S3)とナレッジベース間のリアルタイム同期を維持することは、正確で最新の情報に基づく応答のために重要になります。本稿では、Deloitte が Amazon EKS と vCluster を活用してテストインフラストラクチャを変革した方法を探ります。
本稿では、S3 イベントを検出し、サービスクォータを尊重しながらインジェストジョブをトリガーし、包括的なモニタリングを提供する自動化されたソリューションについて解説します。このサーバーレスソリューションはイベント駆動型アーキテクチャを採用しており、Amazon Bedrock API を過負荷にすることなく、ナレッジベースを最新の状態に保ちます。
課題
Amazon Bedrock のナレッジベースでは、S3(メタデータファイルを含む)にドキュメントが追加、変更、または削除されるたびに、手動での同期が必要です。組織は、頻繁なコンテンツ更新、チームが一日中ドキュメントをアップロードするマルチユーザー環境、現在の情報への即時アクセスを必要とするカスタマーサポートシステムなどのリアルタイムアプリケーション、および遅延や見落としの可能性がある手動同期プロセスを排除して運用効率を向上させるために、自動化された同期を必要としています。信頼性の高い自動化を実現するには、組織は Amazon のサービスクォータとレート制限を尊重しつつ、同期操作を慎重に調整しなければなりません。
サービス設計上の考慮事項
自動化された同期を実装する際、顧客は Amazon Bedrock の保護制約を考慮する必要があります。Amazon Bedrock のサービスクォータでは、並行して実行できるインgestion(データ取り込み)ジョブは以下の制限があります:
- AWS アカウントごとに 5 つのジョブ(リソース枯渇を防ぐため)
- ナレッジベースごとに 1 つのジョブ(集中的な処理を容易にするため)
- データソースごとに 1 つのジョブ(データの一貫性を維持するため)
Amazon Bedrock のサービスクォータに関する詳細は、Amazon Bedrock リファレンスガイドの Amazon Bedrock サービスクォータ を参照してください。これらの制限は各 AWS リージョン に固有のものであり、将来変更される可能性があるため、最新のクォータ情報についてはドキュメントを確認してください。
ナレッジベース用の StartIngestionJob API には、サポートされている各リージョンにおいて秒あたり 0.1 リクエスト(10 秒に 1 回)というレート制限があります。
リリース中にコンテンツチームが複数のファイルを更新することを想定してください。調整がない場合、サービス制限により同期リクエストがキューに積まれ、手動の監視が必要になります。オーケストレーションされたアプローチはこれをシームレスに処理し、サービス制約を尊重しながら変更が効率的に処理されることを保証します。
ソリューションの概要
このイベント駆動型ソリューションは、Amazon S3 のドキュメントを Amazon Bedrock Knowledge Bases と自動的に同期します。S3 バケット内のドキュメント(メタデータファイルを含む)が追加、変更、または削除されると、このソリューションはサービスクォータとレート制限を尊重しながら自動的に同期ジョブをトリガーします。このソリューションは、簡素化された AWS Serverless Application Model (AWS SAM) を使用してデプロイされ、インフラストラクチャの管理を必要としない完全にサーバーレスなアーキテクチャとして動作します。
このソリューションは、Amazon S3 への変更をリアルタイムで処理し、インジェストジョブを知的に管理するために主要な AWS サービスを組み合わせたイベント駆動型アーキテクチャを実装しています。以下のコンポーネントが連携して、サービスクォータを尊重しつつ信頼性の高い同期を実現します。
- Amazon EventBridge は、Amazon S3 からのリアルタイム変更を取得します。
- AWS Lambda 関数はイベントを処理し、同期を管理します。
- Amazon Simple Queue Service (Amazon SQS) キューは、サービスクォータを尊重するためにリクエストをバッファリングします。
- AWS Step Functions は、同期ワークフローをオーケストレーションします。
- Amazon DynamoDB は、ドキュメントの変更とジョブのメタデータを追跡します。
以下の図は、このソリューションが AWS サービスを使用してイベント駆動型の同期システムを構築する方法を示しています。
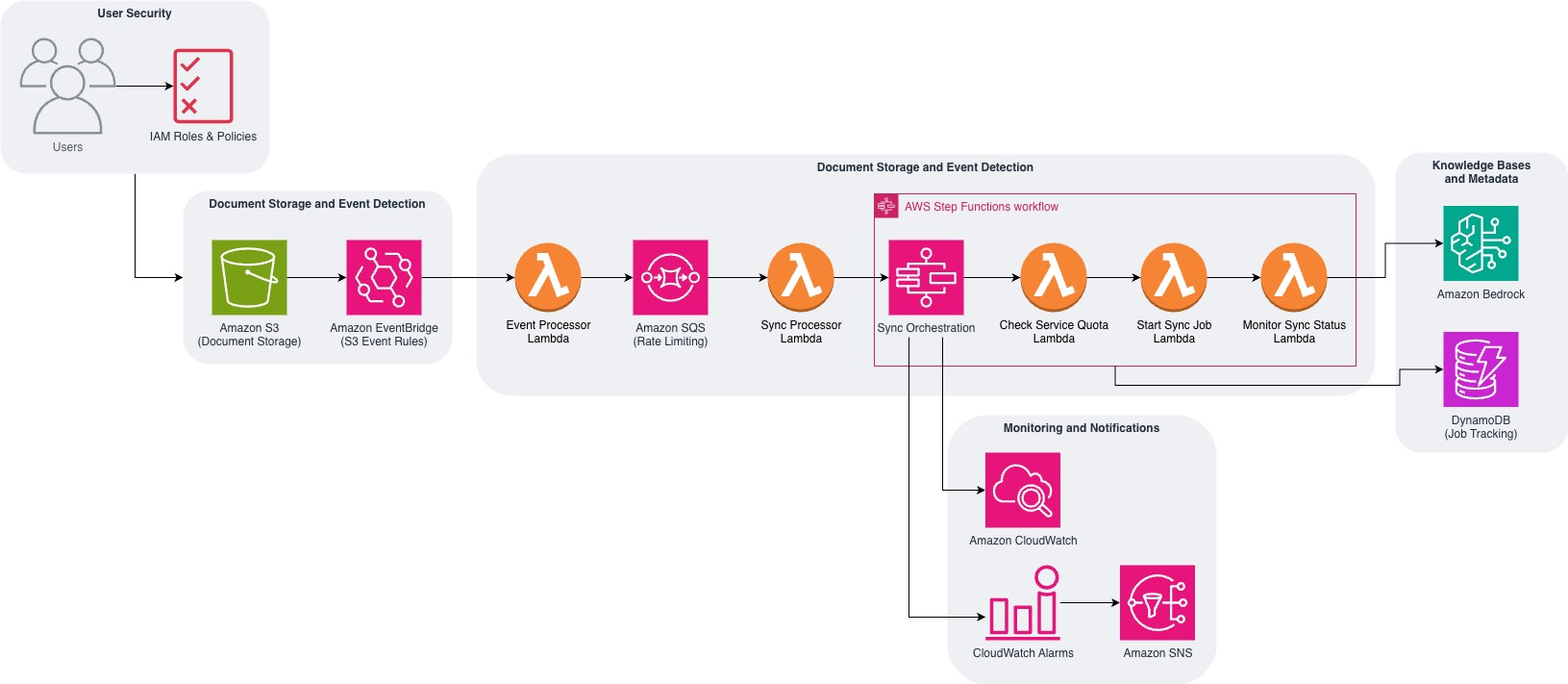
このソリューションのアーキテクチャは、完全な同期ワークフローを管理するために連携して動作する5つの相互接続されたコンポーネントで構成されています。各コンポーネントがシステム内でどのように機能するか、そしてこのデプロイ準備完了のソリューション背後にある技術的実装を示すコード例を用いて、詳しく見ていきましょう。
フェーズ1:ドキュメント変更の検出
最初のフェーズでは、S3バケット内のドキュメント変更を自動的に検出し処理する仕組みが確立されます。このフェーズで実行される主なアクションは以下の通りです。
- EventBridgeがS3イベントをキャッチする:ドキュメントのアップロード、変更、または削除が発生すると、S3は自動的にEventBridgeにイベントを送信します。
- Lambdaがイベントを順次処理する:EventBridgeはイベントプロセッサーLambda関数をトリガーし、この関数はドキュメントのメタデータ(ファイルパス、変更タイプ、タイムスタンプ)を抽出し、監査目的のためにDynamoDBに追跡エントリを作成します。
- SQSキューが同期リクエストを保持する:同じLambda関数は、Amazon SQSに即時に同期リクエストメッセージを送信し、SQSはリクエストをバッファリングしてレート制限を管理し、信頼性の高い処理を可能にします。
以下のコードは、イベントプロセッサーLambda関数が着信S3イベントを処理し、追跡およびキューイングプロセスを調整する方法を示しています。
イベントプロセッサーLambdaが変更情報を抽出する
def lambda_handler(event, context):
for record in event.get('Records', []):
# S3情報を抽出
bucket = record['s3']['bucket']['name']
key = record['s3']['object']['key']
event_name = record['eventName']
# 変更タイプを判定
change_type = get_change_type(event_name)
# DynamoDBに追跡エントリを作成
tracking_table.put_item(
Item={
'change_id': str(uuid.uuid4()),
'knowledge_base_id': kb_id,
'change_type': change_type,
'key': key,
'processed': False,
'timestamp': datetime.utcnow().timestamp()
}
)
# SQSに即時通知を送信
sqs.send_message(
QueueUrl=QUEUE_URL,
MessageBody=json.dumps({
'change_type': change_type,
'bucket': bucket,
'key': key,
'knowledge_base_id': kb_id
})
)
フェーズ2: キュー管理
一貫した処理を維持し、サービスクォータ(使用制限)を尊重するために、このソリューションはドキュメント変更リクエストを管理するキューイングメカニズムを実装しています。キュー管理フェーズには、以下の重要なステップが含まれます:
- Amazon SQS がリクエストをバッファリングします – フェーズ 1 のメッセージはキューに格納され、同期ジョブリクエスト間のレート制限が満たされるように強制されます
- Lambda がメッセージを処理します – 同期プロセッサー Lambda 関数は、SQS キューから一度に 1 つのメッセージを消費します
- ワークフローの開始 – 各メッセージは、ドキュメント変更の詳細とナレッジベース構成を含む新しい Step Functions 実行をトリガーします
このコードは、同期プロセッサー Lambda 関数が SQS メッセージを消費しオーケストレーションワークフローを開始する方法を示しています:
def lambda_handler(event, context):
for record in event.get('Records', []):
message = json.loads(record['body'])
kb_id = message['knowledge_base_id']
# データソース ID の取得または発見
data_source_id = get_data_source_id(kb_id)
# Step Functions ワークフローの開始
sfn_input = {
'knowledge_base_id': kb_id,
'data_source_id': data_source_id,
'message': message
}
response = sfn.start_execution(
stateMachineArn=STEP_FUNCTION_ARN,
name=f"sync-{kb_id}-{int(datetime.utcnow().timestamp())}",
input=json.dumps(sfn_input)
)
フェーズ 3:オーケストレーションされた同期
オーケストレーションフェーズでは、AWS Step Functions を使用して、サービスクォータの管理と障害処理を行いながら同期プロセスを調整します。このワークフローには以下が含まれます:
- クォータ検証 – 現在のリージョン内のナレッジベースにおけるアクティブな取り込みジョブを確認し、サービス制限を超えていないことを確認します。
- 条件付き実行 – クォータが許容する場合、同期ジョブを直ちに開始します。そうでない場合は、5 分待機してから再チェックを行います。
- ジョブ監視 – 同期ジョブの進行状況を追跡し、正常な完了と失敗の両方のシナリオを処理します。
- エラーハンドリング – 再試行ロジックと、失敗した同期試行に対するデッドレター処理を実装します。
以下の Step Functions ステートマシン定義は、クォータ管理とジョブ実行の意思決定ロジックを示しています:
{
"Comment": "Amazon Bedrock Knowledge Base へのドキュメント同期のワークフロー",
"StartAt": "CheckServiceQuota",
"States": {
"CheckServiceQuota": {
"Type": "Task",
"Resource": "${CheckQuotaFunctionArn}",
"Next": "EvaluateQuotaCheck"
},
"EvaluateQuotaCheck": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.quota_check.all_quotas_ok",
"BooleanEquals": true,
"Next": "StartSyncJob"
},
{
"Variable": "$.quota_check.all_quotas_ok",
"BooleanEquals": false,
"Next": "QuotaExceeded"
}
]
},
"QuotaExceeded": {
"Type": "Wait",
"Seconds": 300,
"Next": "CheckServiceQuota"
},
"StartSyncJob": {
"Type": "Task",
"Resource": "${StartSyncFunctionArn}",
"Next": "MonitorSyncJob"
}
}
}
フェーズ 4:ナレッジベースの処理
このフェーズでは、ナレッジベースが同期されたコンテンツを処理し、利用可能な状態にします。以下の手順が行われます:
- ドキュメント処理 – Amazon Bedrock は、同期ジョブ中に特定された変更済みドキュメントをスキャンします
- ベクトル変換 – ドキュメントはチャンク(分割)され、設定された埋め込みモデルを使用してベクトル埋め込みに変換されます
- インデックスの更新 – 新しい埋め込みはベクトルデータベースに保存され、古い埋め込みは削除されます
- コンテンツの可用性 – 更新されたコンテンツは、セマンティック検索および取得のために即座に利用可能になります
フェーズ 5:モニタリングとアラート
最終フェーズでは、ソリューションが確実に運用されるよう包括的なモニタリングとアラート機能を実装します。これには以下が含まれます:
- ステータスの追跡 – ジョブが正常に完了したか失敗したかに応じて、DynamoDB 内のドキュメント変更ステータスを更新します
- 通知の配信 – Amazon SNS を介して、成功または失敗のアラートを設定されたメールアドレスやエンドポイントに送信します
- パフォーマンスのモニタリング – Amazon CloudWatch メトリクスは、同期ジョブの実行時間、成功率、およびクォータの使用状況を追跡します
- 自動アラート – エラー率が閾値を超えた場合、またはジョブが停止している場合に CloudWatch アラームが発動します
主要な機能
このソリューションは、Amazon S3 とナレッジベース間の効率的かつ信頼性の高い同期を可能にする、いくつかの重要な機能を提供します。それぞれの主要な機能とその利点を見ていきましょう。
リアルタイムイベント処理
本ソリューションは、S3 への変更に対して即座に反応します。EventBridge の統合により、S3 イベントがリアルタイムでキャプチャされます。システムは S3 イベント通知を使用して、Amazon S3 オブジェクトの変更が発生するたびに自動的にインジェストジョブをトリガーすることで、変更をその場で処理します。応答は迅速であり、スケジュールされたプロセスを待つ必要はありません。
包括的なクォータ管理
本ソリューションは、Amazon Bedrock のサービスクォータを尊重します:
# サービスクォータの検証
MAX_CONCURRENT_JOBS_PER_ACCOUNT = 5
MAX_CONCURRENT_JOBS_PER_DATA_SOURCE = 1
MAX_CONCURRENT_JOBS_PER_KB = 1
MAX_FILE_SIZE_BYTES = 50 * 1024 * 1024 * 1024 # 50 GB
MAX_TOTAL_SIZE_BYTES = 100 * 1024 * 1024 * 1024 # 100 GB
def check_quotas(kb_id, data_source_id):
# 現在アクティブなジョブを取得
response = bedrock.list_ingestion_jobs(
knowledgeBaseId=kb_id,
dataSourceId=data_source_id
)
active_jobs = [job for job in response['ingestionJobSummaries']
if job['status'] in ['STARTING', 'IN_PROGRESS']]
return {
'all_quotas_ok': len(active_jobs) == 0,
'kb_quota_ok': len(active_jobs)
インテリジェントなレート制限
SQS キューの設定により、適切なレート制限が可能になります:
SyncQueue:
Type: AWS::SQS::Queue
Properties:
VisibilityTimeout: 300
MessageRetentionPeriod: 1209600 # 14 日
RedrivePolicy:
deadLetterTargetArn: !GetAtt SyncQueueDLQ.Arn
maxReceiveCount: 5
SyncProcessorFunction:
Events:
SQSEvent:
Type: SQS
Properties:
Queue: !GetAtt SyncQueue.Arn
BatchSize: 1 # Process one message at a time
堅牢なエラーハンドリング
本ソリューションは、失敗したメッセージに対するデッドレターキュー(Dead Letter Queue)、一時的な障害に対する自動リトライロジック、そして信頼性の高い運用と簡単なトラブルシューティングを可能にするCloudWatchを通じた詳細なログ記録を含む、包括的なエラーハンドリングを実装しています。
前提条件
このソリューションを展開する前に、以下の準備が整っていることを確認してください。
- Amazon Bedrock、AWS Lambda、Amazon EventBridge、Amazon SQS、AWS Step Functions、Amazon DynamoDB、Amazon S3の作成および管理を行うための権限を持つ AWS アカウント。
- AWS Identity and Access Management (IAM) ロールおよびポリシー
- 事前に設定された Amazon Bedrock ナレッジベース:
- Amazon S3 に接続された少なくとも 1 つのデータソース
- Amazon Bedrock Knowledge Bases を管理するための適切な権限
- 開発マシンにインストールされている以下のツール:
- AWS Command Line Interface (AWS CLI) バージョン 2.x 以降。インストール情報については、AWS CLI の最新バージョンへのインストールまたは更新を参照してください。
- AWS SAM CLI バージョン 1.x 以降。インストール情報については、AWS SAM CLI のインストールを参照してください。
- Python 3.12 以降。ダウンロードするには、Python Downloads を訪れてください。
インフラストラクチャのデプロイに要する推定時間:5〜10 分
ソリューションの概要
このセクションでは、AWS 環境で自動同期ソリューションを展開する手順を順を追って説明します。このソリューションを展開するには、以下の手順に従ってください:
- GitHub リポジトリをクローンします:
git clone https://github.com/aws-samples/sample-automatic-sync-for-bedrock-knowledge-bases
cd sample-automatic-sync-for-bedrock-knowledge-bases
- ソリューションをビルドしてデプロイします:
sam build
sam deploy --guided
デプロイ時に、以下のパラメータの入力を求められます:
- スタック名 [kb-auto-sync] – CloudFormationスタックの名前
- AWSリージョン [us-west-2] – Amazon Bedrockのナレッジベースが存在するリージョン
- KnowledgeBaseId – Amazon Bedrockのナレッジベース識別子
- S3BucketName – ドキュメントを含むS3バケットの名前
- S3KeyPrefix(オプション) – 同期する特定のフォルダプレフィックス(例:documents/)
- NotificationsEmail(オプション) – 同期ジョブの通知を受け取るメールアドレス
- MaxConcurrentJobs [5] – 並行して実行できる同期ジョブの最大数
- AWS SAM CLI IAMロールの作成を許可する [Y/n] – IAMロールを作成する権限
- 引数を設定ファイルに保存する [Y/n] – 将来のデプロイ用に設定を保存
以下のコードは、入力例を示しています:
sam deployのデフォルト引数の設定中
===============================
スタック名 [kb-auto-sync]: my-kb-sync
AWSリージョン [us-west-2]: us-east-1
パラメータ KnowledgeBaseId: kb-1234567890
パラメータ S3BucketName: my-document-bucket
パラメータ S3KeyPrefix: documents/
パラメータ NotificationsEmail: user@example.com
SAM CLI IAMロールの作成を許可する [Y/n]: Y
引数を設定ファイルに保存する [Y/n]: Y
デプロイが完了すると、必要なリソースが作成され、スタックの詳細が出力されます。
コストに関する考慮事項
The
原文を表示
With Amazon Bedrock Knowledge Bases, you can give foundation models (FMs) and agents contextual information from your organization’s private data sources to deliver more relevant, accurate, and customized responses. As the data grows, maintaining real-time synchronization between Amazon Simple Storage Service (Amazon S3) and your knowledge bases becomes critical for accurate, up-to-date responses.In this post, we explore how Deloitte used Amazon EKS and vCluster to transform their testing infrastructure.
In this post, we explore an automated solution that detects S3 events and triggers ingestion jobs while respecting service quotas and providing comprehensive monitoring. This serverless solution uses an event-driven architecture to keep your knowledge base current without overwhelming the Amazon Bedrock APIs.
The challenge
Knowledge bases in Amazon Bedrock require manual synchronization whenever documents are added, modified, or deleted in S3 (including metadata files). Organizations need automated synchronization for frequent content updates, multiuser environments where teams upload documents throughout the day, real-time applications such as customer support systems that require immediate access to current information, and to improve operational efficiency by removing manual sync processes that are prone to delays or being forgotten. To achieve reliable automation, organizations must carefully orchestrate sync operations while respecting the Amazon service quotas and rate limits.
Service design considerations
When implementing automated synchronization, customers must account for the protective constraints of Amazon Bedrock. Amazon Bedrock service quotas limit concurrent ingestion jobs to:
- Five jobs per AWS account (helps prevent resource exhaustion)
- One job per knowledge base (facilitates focused processing)
- One job per data source (maintains data consistency)
For more information about Amazon Bedrock service quotas, refer to Amazon Bedrock service quotas in the Amazon Bedrock Reference guide. These limits are specific to each AWS Region and might change in the future, so consult the documentation for the most current quota information.
The StartIngestionJob API for knowledge bases has a rate limit of 0.1 requests per second (one request every 10 seconds) in each supported Region.
Consider having a content team updating multiple files during a release. Without coordination, sync requests queue up due to service limits, requiring manual oversight. An orchestrated approach handles this seamlessly, making sure the changes are processed efficiently while respecting service constraints.
Solution overview
This event-driven solution automatically synchronizes your Amazon S3 documents with Amazon Bedrock Knowledge Bases. When documents are added, modified, or deleted in your S3 bucket (including metadata files), the solution automatically triggers synchronization jobs while respecting service quotas and rate limits. The solution uses the streamlined AWS Serverless Application Model (AWS SAM) deployment and operates as a fully serverless architecture without requiring infrastructure management.
This solution implements an event-driven architecture that combines key AWS services to process Amazon S3 changes in real time while intelligently managing ingestion jobs. The following components work together to facilitate reliable synchronization while respecting service quotas:
- Amazon EventBridge captures real-time changes from Amazon S3
- AWS Lambda functions process events and manage synchronization
- Amazon Simple Queue Service (Amazon SQS) queues buffer requests to respect service quotas
- AWS Step Functions orchestrate the synchronization workflow
- Amazon DynamoDB tracks document changes and job metadata
The following diagram shows how the solution uses AWS services to create an event-driven synchronization system.
The solution architecture consists of five interconnected components that work together to manage the complete synchronization workflow. Let’s explore how each component functions within the system, with code examples to illustrate the technical implementation behind this ready-to-deploy solution.
Phase 1: Document change detection
The initial phase establishes automated detection and processing of document changes in your S3 bucket. Here are the main actions performed during this phase:
- EventBridge captures S3 events – When documents are uploaded, modified, or deleted, S3 automatically sends events to EventBridge
- Lambda processes events sequentially – EventBridge triggers the event processor Lambda function, which extracts document metadata (file path, change type, and timestamp) and creates tracking entries in DynamoDB for audit purposes
- SQS queues sync requests – The same Lambda function immediately sends a sync request message to Amazon SQS, which buffers the requests to manage rate limits and facilitate reliable processing
The following code shows how the event processor Lambda function handles incoming S3 events and coordinates the tracking and queuing process:
# Event Processor Lambda extracts change information
def lambda_handler(event, context):
for record in event.get('Records', []):
# Extract S3 information
bucket = record['s3']['bucket']['name']
key = record['s3']['object']['key']
event_name = record['eventName']
# Determine change type
change_type = get_change_type(event_name)
# Create tracking entry in DynamoDB
tracking_table.put_item(
Item={
'change_id': str(uuid.uuid4()),
'knowledge_base_id': kb_id,
'change_type': change_type,
'key': key,
'processed': False,
'timestamp': datetime.utcnow().timestamp()
}
)
# Send immediate notification to SQS
sqs.send_message(
QueueUrl=QUEUE_URL,
MessageBody=json.dumps({
'change_type': change_type,
'bucket': bucket,
'key': key,
'knowledge_base_id': kb_id
})
)Phase 2: Queue management
To maintain consistent processing and respect service quotas, the solution implements a queuing mechanism that manages document change requests. The queue management phase involves these critical steps:
- Amazon SQS buffers requests – Messages from phase 1 are queued to enforce the rate limit between sync job requests are met
- Lambda processes messages – The sync processor Lambda function consumes one message at a time from the SQS queue
- Workflow initiation – Each message triggers a new Step Functions execution with the document change details and knowledge base configuration
This code demonstrates how the sync processor Lambda function consumes SQS messages and launches the orchestration workflow:
def lambda_handler(event, context):
for record in event.get('Records', []):
message = json.loads(record['body'])
kb_id = message['knowledge_base_id']
# Get or discover data source ID
data_source_id = get_data_source_id(kb_id)
# Start Step Functions workflow
sfn_input = {
'knowledge_base_id': kb_id,
'data_source_id': data_source_id,
'message': message
}
response = sfn.start_execution(
stateMachineArn=STEP_FUNCTION_ARN,
name=f"sync-{kb_id}-{int(datetime.utcnow().timestamp())}",
input=json.dumps(sfn_input)
)Phase 3: Orchestrated synchronization
The orchestration phase uses AWS Step Functions to coordinate the synchronization process while managing service quotas and handling failures. This workflow includes:
- Quota validation – Checks the active ingestion jobs in the current Region across the knowledge bases to confirm service limits aren’t exceeded
- Conditional execution – If quotas allow, starts the sync job immediately; otherwise waits 5 minutes before checking again
- Job monitoring – Tracks sync job progress and handles both successful completion and failure scenarios
- Error handling – Implements retry logic and dead letter processing for failed synchronization attempts
The following Step Functions state machine definition shows the decision logic for quota management and job execution:
{
"Comment": "Workflow for syncing documents to Amazon Bedrock Knowledge Base",
"StartAt": "CheckServiceQuota",
"States": {
"CheckServiceQuota": {
"Type": "Task",
"Resource": "${CheckQuotaFunctionArn}",
"Next": "EvaluateQuotaCheck"
},
"EvaluateQuotaCheck": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.quota_check.all_quotas_ok",
"BooleanEquals": true,
"Next": "StartSyncJob"
},
{
"Variable": "$.quota_check.all_quotas_ok",
"BooleanEquals": false,
"Next": "QuotaExceeded"
}
]
},
"QuotaExceeded": {
"Type": "Wait",
"Seconds": 300,
"Next": "CheckServiceQuota"
},
"StartSyncJob": {
"Type": "Task",
"Resource": "${StartSyncFunctionArn}",
"Next": "MonitorSyncJob"
}
}
}Phase 4: Knowledge base processing
During this phase, the knowledge base processes the synchronized content and makes it available for use. The following steps occur:
- Document processing – Amazon Bedrock scans the changed documents identified during the sync job
- Vector conversion – Documents are chunked and converted to vector embeddings using the configured embedding model
- Index updates – New embeddings are stored in the vector database while outdated embeddings are removed
- Content availability – Updated content becomes immediately available for semantic search and retrieval
Phase 5: Monitoring and alerts
The final phase implements comprehensive monitoring and alerting to make sure the solution operates reliably. This includes:
- Status tracking – Updates document change status in DynamoDB as jobs are completed successfully or fail
- Notification delivery – Sends success or failure alerts through Amazon SNS to configured email addresses or endpoints
- Performance monitoring – Amazon CloudWatch metrics track sync job duration, success rates, and quota utilization
- Automated alerting – CloudWatch alarms trigger when error rates exceed thresholds or jobs remain stuck
Key features
This solution provides several essential capabilities that facilitate efficient and reliable synchronization between Amazon S3 and your knowledge bases. Let’s explore each key feature and its benefits.
Real-time event processing
The solution immediately responds to S3 changes. EventBridge integration captures S3 events in real time. The system processes Amazon S3 object changes as they occur by using S3 event notifications to automatically trigger ingestion jobs. Response is prompt and there is no waiting for scheduled processes.
Comprehensive quota management
The solution respects the Amazon Bedrock service quotas:
# Service quotas validation
MAX_CONCURRENT_JOBS_PER_ACCOUNT = 5
MAX_CONCURRENT_JOBS_PER_DATA_SOURCE = 1
MAX_CONCURRENT_JOBS_PER_KB = 1
MAX_FILE_SIZE_BYTES = 50 * 1024 * 1024 * 1024 # 50 GB
MAX_TOTAL_SIZE_BYTES = 100 * 1024 * 1024 * 1024 # 100 GB
def check_quotas(kb_id, data_source_id):
# Get current active jobs
response = bedrock.list_ingestion_jobs(
knowledgeBaseId=kb_id,
dataSourceId=data_source_id
)
active_jobs = [job for job in response['ingestionJobSummaries']
if job['status'] in ['STARTING', 'IN_PROGRESS']]
return {
'all_quotas_ok': len(active_jobs) == 0,
'kb_quota_ok': len(active_jobs) < MAX_CONCURRENT_JOBS_PER_KB
}Intelligent rate limiting
SQS queue configuration facilitates proper rate limiting:
SyncQueue:
Type: AWS::SQS::Queue
Properties:
VisibilityTimeout: 300
MessageRetentionPeriod: 1209600 # 14 days
RedrivePolicy:
deadLetterTargetArn: !GetAtt SyncQueueDLQ.Arn
maxReceiveCount: 5
SyncProcessorFunction:
Events:
SQSEvent:
Type: SQS
Properties:
Queue: !GetAtt SyncQueue.Arn
BatchSize: 1 # Process one message at a timeRobust error handling
The solution implements comprehensive error handling with dead letter queues for failed messages, automatic retry logic for transient failures, and detailed logging through CloudWatch to facilitate reliable operation and straightforward troubleshooting.
Prerequisites
Before you deploy this solution, make sure you have the following:
- An AWS account with permissions to create and manage the following services:
Amazon Bedrock
- AWS Lambda
- Amazon EventBridge
- Amazon SQS
- AWS Step Functions
- Amazon DynamoDB
- Amazon S3
- AWS Identity and Access Management (IAM) roles and policies
- A preconfigured Amazon Bedrock knowledge base with:
At least one data source connected to Amazon S3
- Appropriate permissions to manage Amazon Bedrock Knowledge Bases
- The following tools installed on your development machine:
AWS Command Line Interface (AWS CLI) version 2.x or later. For information on installation, refer to Installing or updating to the latest version of the AWS CLI.
- AWS SAM CLI version 1.x or later. For information on installation, refer to Install the AWS SAM CLI.
- Python 3.12 or later. To download, visit Python Downloads.
Estimated time for the infrastructure deployment: 5–10 minutes
Solution walkthrough
This section walks you through the step-by-step process of deploying the automatic sync solution in your AWS environment. To deploy this solution, follow these steps:
- Clone the GitHub repository:
git clone https://github.com/aws-samples/sample-automatic-sync-for-bedrock-knowledge-bases
cd sample-automatic-sync-for-bedrock-knowledge-bases- Build and deploy the solution:
sam build
sam deploy --guidedDuring deployment, you’ll be prompted to provide these parameters:
- Stack Name [kb-auto-sync] – Name for your CloudFormation stack
- AWS Region [us-west-2] – Region where your Amazon Bedrock knowledge base exists
- KnowledgeBaseId – Your Amazon Bedrock knowledge base identifier
- S3BucketName – Name of the S3 bucket containing your documents
- S3KeyPrefix (Optional) – Specific folder prefix to sync (for example, documents/)
- NotificationsEmail (Optional) – Email address for sync job notifications
- MaxConcurrentJobs [5] – Maximum number of concurrent sync jobs
- Allow AWS SAM CLI IAM role creation [Y/n] – Permission to create IAM roles
- Save arguments to configuration file [Y/n] – Save settings for future deployments
The following code shows an example input:
Setting default arguments for sam deploy
===============================
`Stack Name [kb-auto-sync]: my-kb-sync
AWS Region [us-west-2]: us-east-1
Parameter KnowledgeBaseId: kb-1234567890
Parameter S3BucketName: my-document-bucket
Parameter S3KeyPrefix: documents/
Parameter NotificationsEmail: user@example.com
Allow SAM CLI IAM role creation [Y/n]: Y
Save arguments to configuration file [Y/n]: Y`
The deployment will create the necessary resources and output the stack details upon completion.
Cost considerations
The
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み