自動研究、Claude、そして制約付き最適化(13 分読了)
著者は Claude を用いた自律型エージェントが、定量化された目標と制約条件下でファイル圧縮アルゴリズムを設計・最適化できるかを実験し、その限界と可能性を検証した。
キーポイント
AI エージェントの自律的タスク定義手法
従来の機械学習や数値最適化とは異なり、定量化された指標(ファイルサイズ)とパス/フェイル制約(時間制限、完全一致)を設けることで、人間が介在しない大規模タスクへの AI 指示の可能性を探る実験を行った。
実証実験の設計:ファイル圧縮
既存ツールとのベンチマークが可能で、目的と制約が明確な「ファイル圧縮」を課題に選定し、解凍・圧縮時間の上限(300 秒)を設定して無限ループを防ぐ安全装置を備えた。
AI の最適化能力への洞察
未知の状態から成功へ至る道筋が明確な勾配最適化ではない現実世界の問題において、AI エージェントが局所最適解に陥らず、効果的な解決策を見つけられるかという直感的理解を得ようとした。
影響分析・編集コメントを表示
影響分析
この記事は、LLM エージェントが単なる情報検索やコード生成を超え、定量化された目標と制約条件下で自律的にアルゴリズムを設計・最適化する「実用的な自律化」の第一歩を示唆しています。特に、無限ループを防ぐための時間制限などの安全装置を組み合わせた実験手法は、現場での AI エージェント導入におけるリスク管理の参考となる重要な知見です。
編集コメント
AI エージェントの実用化において、単に「指示を出す」だけでなく、安全装置を備えた厳格な評価基準を設定する重要性が浮き彫りになった一報です。
イントロダクション
AI を使って数十人の人間の仕事をこなしているという主張は、どこを探しても見つかるでしょう。私は根拠のない改善の主張には常に懐疑的です。そこで、その懐疑心を実践に活かすことにしました。これは X での「ループ」に関する議論と少し重なる部分がありますが、それは偶然です。
ここ数週間で、Kaparthay の『Autoresearch』をテーマにしたプロジェクトを組み立てました。従来の機械学習や数値最適化の問題ではなく、それでも何らかの客観的な成功指標を持つ問題を選びたかったのです。
このような問題を選んだのは、私が関わってきた多くのプロジェクトや製品がそのような構造をしているからです。変更したい指標(増やすか減らすか)があり、それを測定する方法もあれば理想的です。また、何らかの制約もあるでしょう。例えば、「この機能ではページ読み込み時間が 500ms を超えないようにする」といった制約です。
未知の状態から成功に至る道筋が、機械学習のように明確な勾配最適化であるような問題にまだ取り組んだことはありません。むしろ、ある作業を完了し、『現実世界』でテストし、そのパフォーマンスを確認した上で、次のステップについて判断を下すことが一般的です。すべての変更が肯定的な結果をもたらすわけではなく、局所的に最適な結果をもたらす道へと深く入り込んでしまうのは容易です。
私は、主に監督なしの状態で AI エージェントに大きな作業を任せる方法について直感的な理解を得るための実験を望んでいました。この結果を実現しようとする既存の仕組みとして、Ralph Loops や、現在 Claude Code に組み込まれている /goal コマンドなどがあります。今回の設定との違いは、成功の主要指標として定量化可能な数値を選択し、いくつかの合格・不合格制約で問題に境界を設ける点です。
複雑化させすぎないよう、私はファイル圧縮の問題を選びました。これは目的と制約が単純だったからです。最終的なファイルサイズが小さいほど、圧縮アルゴリズムは優れています。この問題には 2 つの制約を追加しました。1 つ目は、非圧縮ファイルが完全に一致する必要があるという点で、2 つ目は圧縮もデコードもそれぞれ 300 秒を超えてはならないという点です。私は意図的に速度の最適化を行わず、時間のカットオフを設定し、タイムアウトが無限ループを検出・停止できることを踏まえて、プロセスをほぼ監督なしで実行できるようにしました。
ファイル圧縮のもう一つの優れた点は、最終的なベンチマークに使用できる既存ツールが多数存在することです。これは小規模な概念実証(PoC)だったので、新しい最上位クラスのアルゴリズムを作成できるとは期待していませんでした。
それでも、この自作版が既存のツールに対してどの程度機能したかを知ることは、ライブラリや市販ソリューションからどれほど離れる可能性があるかというデータポイントを提供するのに役立ちます。エージェントが外部依存関係によって以前解決されていた問題を迅速かつ確実に解決できるのであれば、サプライチェーン攻撃などのリスクよりも社内ソリューションの価値が上回るある時点が存在するはずです。これは単一の実験で答えが出るようなことではありませんが、これ以上検討する価値があるかどうかを判断する助けにはなるでしょう。
方法論
問題設定
まず、このアプローチが実現可能であるかを確認することが目的であり、特定のモデルのベンチマークを行うものではないことを思い出してください。
次に、本題に入る前に、このプロジェクトに関するすべてのコードは以下で利用可能です:https://github.com/smitec/agent-compression
今回の作業では、Sonnet 4.6 の Claude Code をデフォルト設定で使用しました。異なるモデルであれば別の対応をした可能性はありますが、それはまたの機会に譲ります。
エージェントが関与する前に、プロジェクトのための基本的な骨組みを構築しました。型システムを通じて「関数のシグネチャを変更しない」といった暗黙的な制約を容易に適用できるため、Rust を選択しました。圧縮と展開を行うスタブ(stub)を作成しましたが、これらは単にバイト列をコピーするだけのものです。これは「動作」しますが、データに対して何の圧縮も提供しませんでした。
その後、文字列と単純なファイルの両方に対して圧縮・展開の往復処理を検証するためのいくつかの基本的なユニットテストを実装しました。これらのテストは網羅的なものではありませんでしたが、圧縮および展開関数がビット完全な往復処理という目標を遵守していることを確認するものでした。
そこからベンチマークスクリプトを作成しました。このスクリプトは、動画、音声、テキストにわたるパブリックドメインのファイルサンプルを取得し、さまざまなサイズのランダムデータで埋められたファイルも作成します。これらのファイルの多くはすでに何らかの形で圧縮された形式であったため、より非圧縮な形式に変換するステップを追加しました。これにより、全体の圧縮ベンチマークに加えて、ファイルごとの詳細なベンチマークが可能になります。
このサンプルセットには、高エントロピーと低エントロピーのファイルフォーマットが混在していました。優れた圧縮アルゴリズムは、低エントロピーのフォーマットを縮小し、高エントロピーのフォーマットはほとんど変更しないはずです。フォーマット固有のバイトによるファイルサイズのごくわずかな変動は予想されますが、全体的に意味のある方法でファイルサイズが増加することは望ましくありません。
サンプルセットの中で最大のファイルは約 150MB でした。圧縮はさらに大きなファイルにおいてより有意義な結果をもたらす可能性がありますが、特に後続のステップでは非常に遅いテストループになってしまうため、今回はその規模には至りませんでした。
ベンチマークスクリプトは各ファイルを順にループ処理し、個別に圧縮した後に展開しました。スクリプトは、展開されたファイルが元のファイルとビット単位で一致しているかを確認し、サイズの変化と、圧縮・展開の各ステップにかかった時間を記録しました。各ファイルの処理には主に意図しない無限ループを検出するために 300 秒のタイムアウトが設定されていました。
スクリプトは、ファイルごとの変更を概説する debug.csv ファイルを生成し、改善が見られた場合は主要な指標を results.csv ファイルに書き込みました。注目すべき点の一つとして、結合圧縮指標は(総圧縮バイト数)/(総元バイト数)で計算されました。私はまた、サンプルセット全体における平均パーセンテージ圧縮率を採用することも検討しました。この選択の違いとその影響については、後ほど詳しく説明します。
これらすべての設定が整った後、スタブ実装に対してベンチマークを実行し、実験を開始する準備ができたと判断しました。
Iterations
比較的厳密に制御するために、各イテレーションの前に Claude のコンテキストをクリアし、モデルには「現在のコードベースを見直し、改善の別のイテレーションを試みてください」とプロンプトしました。Claude Code はデフォルトでプランモードに設定されているため、私はまずプランを待機し、その後簡易レビューを経てそのプランを採用し、エージェントに単独で実行させました。
私はこの実験において、計画のいずれも意図的に変更せず、完全に自律的な選択を行わせるようにしました。介入が必要だったと思われる場面がいくつかありましたが、それは今後の教訓として学びました。
10 回の反復を実行した後、一般的な圧縮ツールとの比較ベンチマークと、データ固有の最適化を制御するための新しいデータセットを用いた最終的な拡張ベンチマークを実施しました。これらの反復は約 2 週間にわたって実行され、通常は他の作業をしている間に開始して放置される形でした。この長い期間設定は実験の設計上の意図というよりは、むしろ他の作業中に Claude Code の利用制限を消費しすぎないための措置でした。
結果
反復
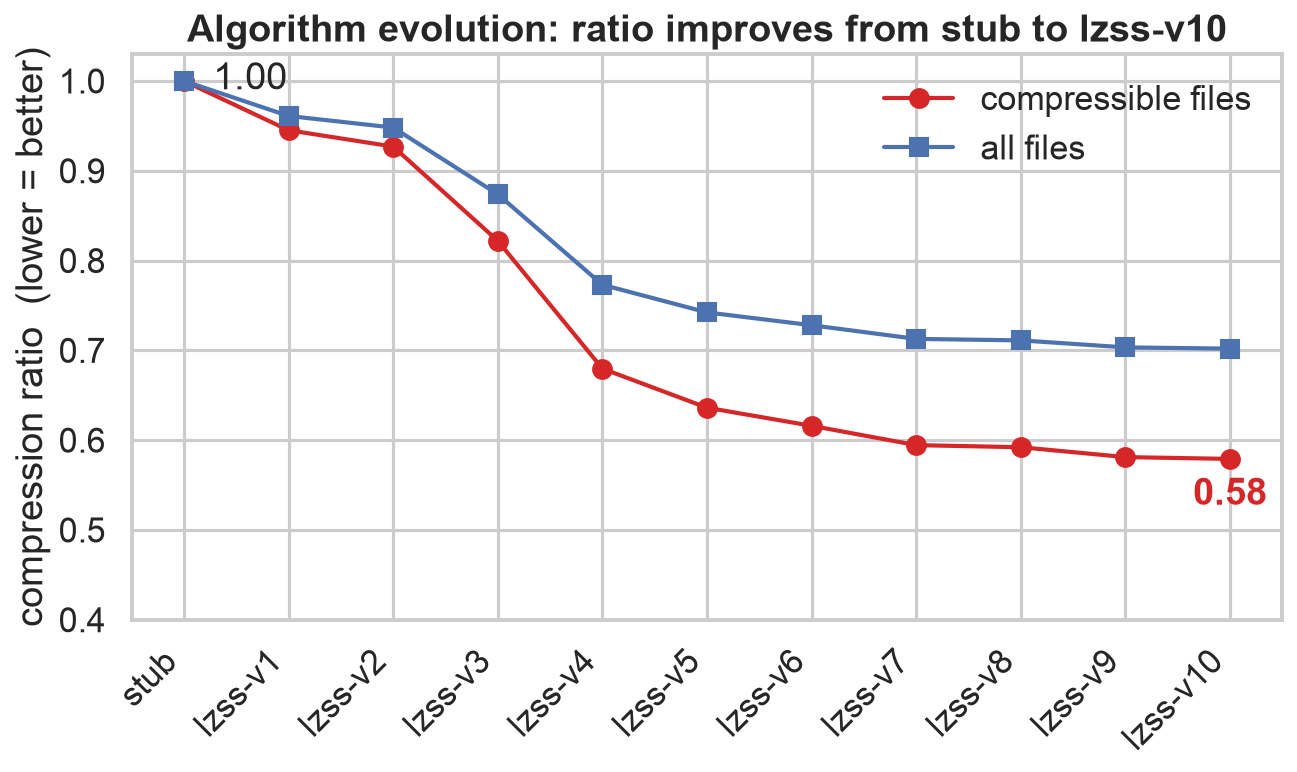
最初の反復では、エージェントが独自の実装 LZSS を生成しました。これは比較的標準的でよく知られた圧縮手法です。続く 9 回の反復は、この手法の拡張であり、エントロピーを除去しようとして新たなエントロピーチェックと符号化技術を追加するものでした。
各ループで要した時間や使用トークン数は大きくばらつきました。Claude Code の /usage コマンドに基づく平均では、1 回の反復あたりのコストは約 4 ドルでした。これはデフォルト設定での結果であり、モデルによって価格が大きく変動するため、この金額に過度な意味を見出しているわけではありません。
興味深いことに、モデルは特定の反復内で一度以上の変更セットを行うことはありませんでした。仮説を形成し、コードを追加し、ベンチマークを実行して「完了」と宣言するのみです。これはおそらく、/goal コマンドを使用しないプロンプト設定に起因するものと考えられます。
以下の結果は、モデルが圧縮率の改善を継続して行えたことを示しています。特に「圧縮可能」比率に注目すると、タスクの要件が非常に緩いにもかかわらず、私の意見では結果は非常に印象的でした。
ベンチマーク
最終結果を評価するために、同じデータセットに対して複数の圧縮ツールを実行しました。これらのツールは、たまたま既にインストールされていたものを選定したものです。これはベンチマーク選択において最も堅牢な方法ではありませんが、一般的なツールの比較という点では反映されています。
全体的に、カスタムアルゴリズムは概ね良好なパフォーマンスを示しました。音声および動画の圧縮においては特に優れており、他のカテゴリではやや劣るか同等の性能でした。音声や動画でのスコアが低かったことは、最適化に使用された指標を考慮すれば驚くべきことではありません。これらのファイルタイプが圧縮されるバイト数の大部分を占めていたため、総合スコアはそこでの勝利によって最も大きく変動しました。
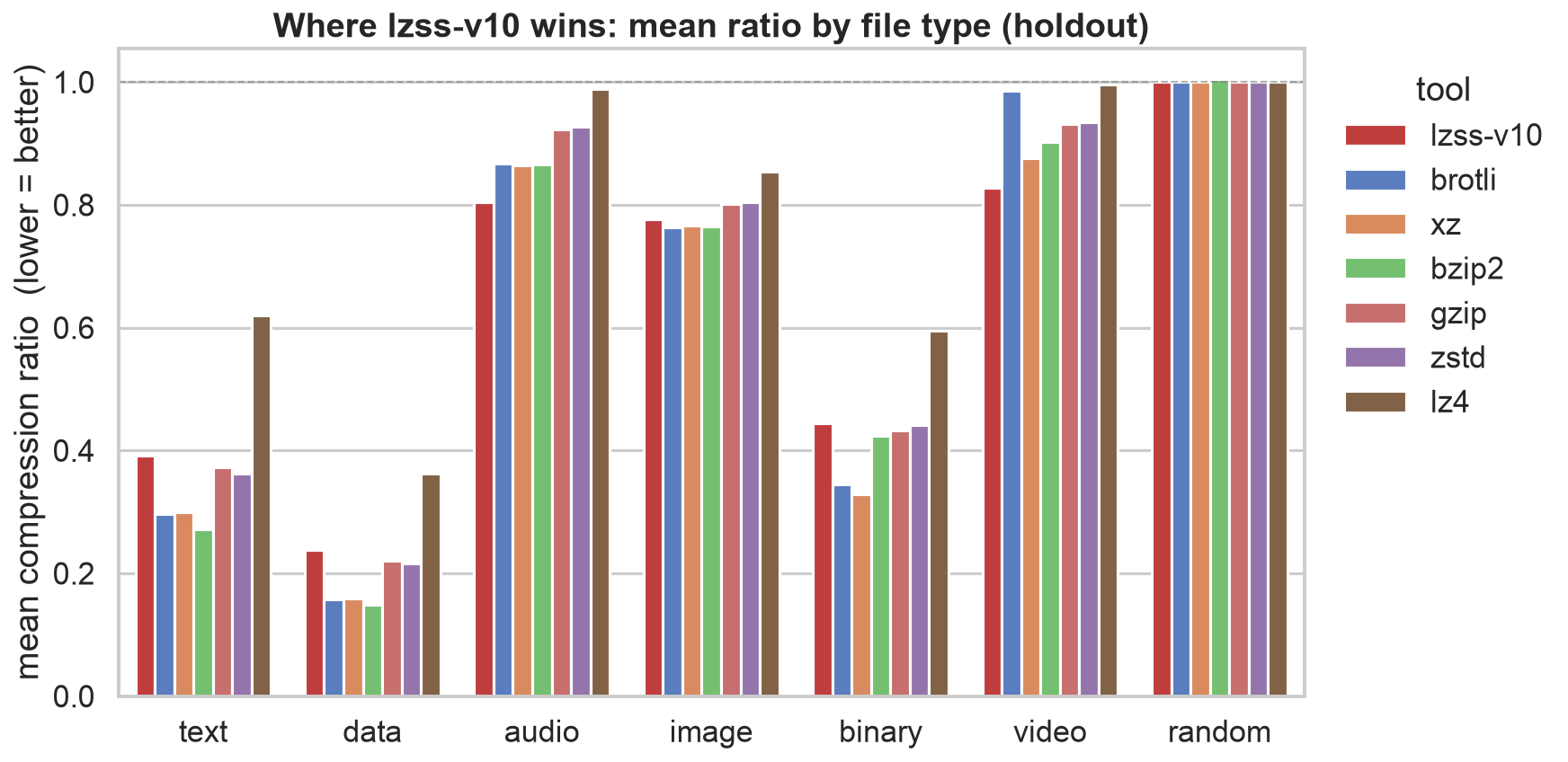 imageこのプロジェクトの目的に戻ると、これは画期的な圧縮アルゴリズムを見つけるための探求ではなく、エージェントにソフトウェア最適化を指示することに関する直感を養うことを目指したものでした。
imageこのプロジェクトの目的に戻ると、これは画期的な圧縮アルゴリズムを見つけるための探求ではなく、エージェントにソフトウェア最適化を指示することに関する直感を養うことを目指したものでした。
Learnings
このプロジェクトのまとめとして、もしこの記事が長すぎて読みたくない方のために、高レベルな教訓をいくつか挙げておきます。全体として、堅牢で測定可能かつ適切に制約された指標を見つけて最適化できるのであれば、このような自動研究/ループ型の作業は理にかなっていると私は考えます。しかし、そのような指標を見つけることは往々にして難しいものです。
Models race to be 'done'
セットアップを観察・レビューしている間、私が感じた全体的な雰囲気は、このモデルが可能な限り早く「完了」したいという欲求を持っているということでした。これを踏まえると、本番環境向けの実装においては、明示的なループ機構を設けることが重要だと考えられます。
The choice of objective function is key
もう一つの観察点は、300 秒という時間パラメータがおそらく非常に緩すぎる制約だったということです。これは変更による悪影響(ダウンサイド)を制限するには有用でしたが、モデルは常に圧縮率の最適化のみを行っていました。ミッチェル・ハシモト氏が最近 X (旧 Twitter) のスレッドで捉えた現象です:
フレームタイムとテスト測定を最小化することを目的に、レンダラーを最適化するエージェントをループさせています。結果として、実行時間は 88ms から 2ms に、アロケーション数は約 150K から 500 にまで削減されました。素晴らしい成果に見えますね?いいえ、それは間違いです。まさにこれこそが、エージェントの精神病(agent psychosis)がなぜ深刻な問題なのかを示す例なのです。
As…
— Mitchell Hashimoto (@mitchellh) May 28, 2026
この手法の実世界への適用には、最適化するより複雑な「スコア」が必要か、あるいは後で速度の最適化に切り替える必要があります。コード長やメモリ使用量などの他の二次指標についても同じことが言えます。
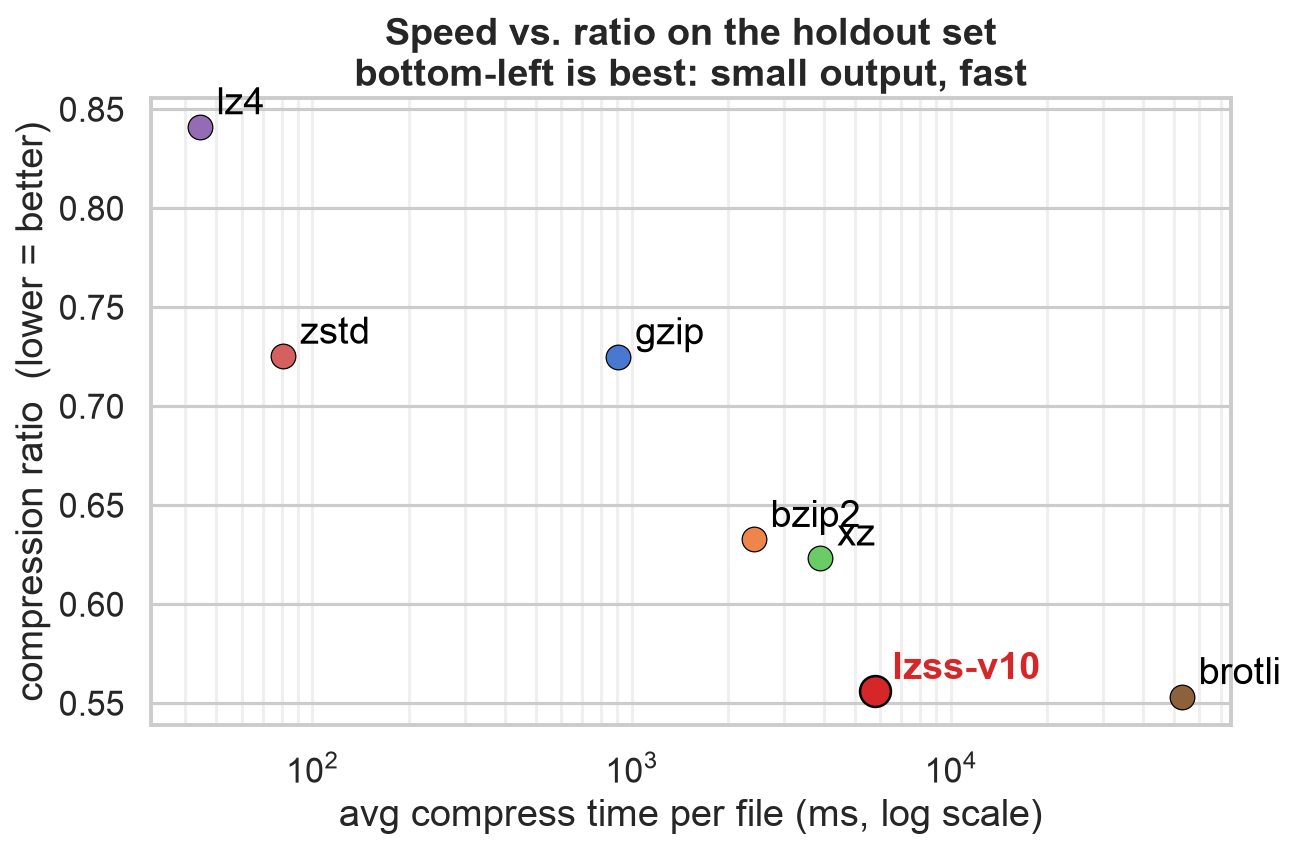 imageこれは決して新しい問題でもなく、エージェントベースのコーディングに固有のものでもありません。エンジニアリング組織において「成功」や「完了」をどう測るかという課題は古くから存在しています。現実的には、あらゆる指標または指標の組み合わせにはトレードオフが伴うものです。おそらく、この事実に慣れ、ニーズの変化に応じて焦点を時間とともにシフトしていく覚悟が必要になるでしょう。
imageこれは決して新しい問題でもなく、エージェントベースのコーディングに固有のものでもありません。エンジニアリング組織において「成功」や「完了」をどう測るかという課題は古くから存在しています。現実的には、あらゆる指標または指標の組み合わせにはトレードオフが伴うものです。おそらく、この事実に慣れ、ニーズの変化に応じて焦点を時間とともにシフトしていく覚悟が必要になるでしょう。
最近、PostHog が新製品「PostHog Code」でこの分野での取り組みを行っていることを知りました。ユーザーがプロダクト分析をコーディングエージェントの文脈に持ち込み、意思決定をより適切に導けるようにするものです。まだ試していませんが、これは正しい方向性のように感じられます。
実世界の目標は測定がそれほど単純ではないことが多い
指標について議論する際、この手法が「実世界」でどのように異なるかを考慮する価値があります。圧縮ツールには非常に短いフィードバックループがあります。ファイルを取得し、圧縮し、展開して結果を比較するだけです。もしこの変更がより広範なもので、「チェックアウトのコンバージョン率を向上させる」といった場合であれば、サンプルを集めるのに多くの時間が必要となり、データのノイズの影響を大きく受けることになります。
一つの解決策は、コンバージョン率の向上を期待・仮定して、プロキシ指標を最適化することです。例えば「ページ読み込み速度の改善」や「チェックアウトに必要なクリック数の削減」といったものが該当します。これらは確かに反復しやすくなりますが、最終目標と緩やかにしか相関しないプロキシ指標に対して過剰に最適化するリスクが生じます。複雑な指標と完全に線形相関するプロキシ指標を見つけるのは困難です。
制限事項
ここでは制限事項についてごく簡単に言及します:
- モデルの選択、これらの結果の有効期限はどれくらいか。モデルは常に変化しており(Sonnet 5 が本日リリースされた)、現実的には同じ試行を今日実施した場合の結果は大きく異なる可能性が高い。
- コスト、これは妥当だろうか。Claude の見積もりによると、各ループでトークン使用料として約 4 ドルがかかっている。「実用的な」製品でこれを行うには ROI(投資対効果)が必要だ。10 ループで 40 ドルは決して高いハードルではないが、コードベースの変更ごとにこのようなループを実行すればコストがかかる可能性がある。
- 単一マシン・スレッド単位の結果。圧縮ベンチマークは CPU によって大きく変動する。これらはすべて M2 Macbook Pro で実施されたが、他の環境では結果が異なっていたことは間違いない。
- 最適化関数の選択。これが最大の要因であり、前述の通り何度も言及されているが、もし平均値(compressed / raw)や中央値など別の指標を選んでいたなら、より良い方向への道筋は全く異なるものになっていたはずだ。私は過去に指標の選び方について多く書いてきたが、これは人間だけでなくエージェントにも当てはまる話だ。
原文を表示
Introduction
You don't need to look far to find claims that folks have been using AI to do the work of dozens of people. I tend to be skeptical of any claim that discusses improvements without evidence. I decided to take that skepticism and put it to work. This had a minor overlap with the whole 'loops' discussion on X but that's coincidental.
Over the last few weeks I have put together a project in the theme of Kaparthay's 'Autoresearch'. I wanted to choose a problem that was not a traditional machine learning or numerical optimization problem but one that still had some objective measure of success.
I chose this kind of problem because many of the projects or products I have worked on are structured that way. You have some metric that you want to change (up or down) and ideally some way to measure it. You likely also have some constraints e.g. we can't let the page load time exceed 500ms for this feature.
I have yet to work on a problem like this where the path from unknown to success is a clear, gradient optimization akin to machine learning. More often you complete some work, test it in the 'real world', look at how it performed and then make a decision about next steps. Not all changes result in a positive outcome and it's easy to go deep down a path that results in a locally optimal outcome.
I wanted an experiment that would give me some intuition about how to task AI agents with bigger pieces of work in a mostly unsupervised way. There are already other mechanisms to try and achieve this outcome, such as Ralph Loops and the /goal command that's now in Claude Code. The difference in this setup is that I would pick a quantifiable number as the primary measure of success and bound the problem with some pass-fail constraints.
Not wanting to over complicate things I chose the problem of file compression. I picked it because the objective and the constraints were simple. A compression algorithm is better if the final file size is smaller. I added two constraints to the problem, one being that the uncompressed file needed to match perfectly and the other that neither compression or decompression could exceed 300 seconds. I was deliberately not optimizing for speed but wanted to cap the time and ensure the process could run mostly unsupervised with the knowledge that a timeout would catch and infinite loops.
The other nice thing about file compression is that there are many existing tools I could use for a final benchmark. Given this was a small proof of concept I wasn't expecting to create a new top-of-the-line algorithm.
Despite that, knowing how well this home cooked version performed against existing tools also helps provide a data point on how much we might move away from libraries and off the shelf solutions. If an agent can quickly and reliably solve a problem previously solved by an external dependency there must be some point at which the value of an in house solution exceeds the risk of things like supply chain attacks. This isn't something one single experiment would answer but it would help determine if this was worth looking at more.
Methodology
Problem Setup
First, a reminder that the goal here was to see if this approach was viable rather than to benchmark any particular model.
Second, before we get into it, all the code for this project is available here: https://github.com/smitec/agent-compression
For this work I used Claude Code with default settings on Sonnet 4.6. I am certain different models would have done things differently, that's an exercise for another day.
Prior to any agent involvement I setup a basic scaffold for the project. I picked Rust because some of the implicit constraints like "don't modify the function signature" were easily enforceable via the type system. I put together a stub of the compress and decompress function which both just copied the bytes across. This 'worked' but provided zero compression to any of the data.
I then put in place a couple of basic unit tests to test the compress-decompress round trip on both a string and a simple file. These tests weren't exhaustive but did validate that the compress and decompress function were adhering to their goal of a bit perfect round trip.
From there I put together a bench-marking script. This script fetched some public domain file samples across video, audio and text as well as created some files filled with random data of various sizes. Many of these files were in formats that were already somewhat compressed so I added a step to convert them to less compressed formats. This gives a good file wise benchmark alongside the overall compression benchmarks.
Having this sample set meant that there were a mix of high and low entropy file formats. A good compression algorithm will shrink low entropy formats and leave high entropy formats mostly unchanged. You can expect some minor change in file size due to format specific bytes but overall you don't want file size to increase in a meaningful way.
The largest file in the sample set was around 150MB. While compression is likely more meaningful on even larger files it would have resulted in a very slow test loop, especially in later steps.
The bench-marking script looped through each of the files, compressed them individually and then decompressed them. The script checked the decompressed file was a bitwise match to the original and noted down the change in size and how long the compress and decompress steps took. There was a 300 second timeout applied to each file's steps mainly to check for accidental infinite loops.
The script produced a debug.csv file which outlined the changes per file and, if there was an improvement, wrote the key metrics to a results.csv file. One thing of note was that the combined compression metric was (total compressed bytes) / (total original bytes). I had also considered taking the average percentage compression across the sample set. I'll get into the differences and impact of this choice a little later.
Once all of this was setup I ran the benchmark for the stub implementation and considered the experiment ready to run.
Iterations
To keep things relatively well controlled I cleared the Claude context before each iteration and prompted the model with "Review the current codebase and attempt another iteration of improvement." I have Claude Code set to plan mode by default so I waited for the plan and then after a quick review accepted the plan and let the agent run on its own.
I intentionally didn't modify any of the plans in this experiment, wanting to let it make fully autonomous choices. There were a few times where I think an intervention would have been useful but that’s a lesson learned.
I ran ten iterations and then completed a final extended benchmark against some common compression tools and on a new dataset to control for any data-specific optimization. These iterations were run over the course of about two weeks usually kicked off and left to run while I was doing other things. This extended time period wasn't a design feature of the trial, it was mostly to avoid exhausting my Claude Code limits while working on other things.
Results
Iterations
During the first iteration the agent produced a custom LZSS implementation, a fairly standard and well known method of compression. The next nine iterations were extensions to this method, adding new entropy checks and encoding techniques to try and remove entropy.
Each loop varied a lot in time taken and tokens used. On average, based on the /usage command in Claude Code, a single iteration cost about $4 USD. Again this was on the default settings so I am not reading too much into the price given how much that varies per model.
Interestingly the model never made more than one set of changes in a given iteration. It would form a hypothesis, add the code, run the benchmark and call itself 'complete'. This may come down to the prompting setup of not using the /goal command.
The results below show that the model was able to continue to make improvements to the compression factor. Looking in particular at the 'compressible' ratio the results were, in my opinion, pretty impressive given how loose the task was.
Benchmarks
To assess the final results I ran several compression tools over the same dataset. These tools were chosen because they happened to already be installed. This is not the most robust method of choosing a benchmark but it does reflect a comparison to common tooling.
Overall the custom algorithm performed fairly well, it excelled at audio and video compression and was slightly worse or on par in other categories. The lower scores in audio and video aren't surprising given the metric used to optimise. These file types represented most of the bytes being compressed so the combined score was moved most by wins there.
Coming back to the goal of this project, this wasn't a quest to find a breakthrough compression algorithm but instead to develop some intuition about tasking an agent with optimizing software.
Learnings
To wrap this up, and give folks something to skip to if this post is too long, here are some high level take-aways from this project. Overall, I think if you can find a robust, measurable and well constrained metric to optimise then this auto-research/loop style work makes sense. Finding one of those is often tricky.
Models race to be 'done'
The overall feeling I had while watching/reviewing the setup was that it wanted to be 'done' as quickly as possible. Based on this I think having some explicit looping mechanism setup would be important for a real world version of this setup.
The choice of objective function is key
Another observation I had was that the 300 second time parameter was likely far too loose a constraint. It was useful for capping the downside of a change but the model was only ever optimising for compression. A phenomenon recently captured by Mitchell Hashimoto in this X thread:
A real world application of this method would either need a more complex 'score' to optimize or to later switch to an optimisation for speed. The same can be said for other secondary metrics like code length, memory usage etc.
This is by no means a new issue or one that is unique to agent based coding. Choosing measures of 'success' and 'done' has long been a challenge in engineering organisations. Realistically any metric or combination of metrics is going to come with trade offs. You probably just need to get comfortable with that fact and be willing to shift your focus over time as the needs change.
I saw recently that PostHog was doing some work in this space with their new PostHog Code product. Allowing users to bring product analytics into their coding agent context to better guide decisions. I'm yet to test it out but it feels like the right direction.
Real world objectives are rarely as simple to measure
While discussing metrics it's worth considering how this technique might differ in the 'real world'. A compression tool has a very fast feedback loop. You can take a file, compress it, decompress it and compare the results. If this change was more broad, say "Improve the checkout conversion rate," you'd need a lot more time to gather samples and you'd be a lot more susceptible to noise in the data.
One solution here is to optimize a proxy metric with the hope/hypotheses that it will improve the conversion rate. That might be something like 'improve page load speed' or 'reduce the number of clicks needed to checkout'. This could certainly be more easily iterated on but you then run the risk of over-optimising on a proxy metric that only loosely correlates with your final goal. It is rate to find a proxy metric that is perfectly and linearly correlated with a more complex one.
Limitations
Some very brief acknowlegements of limitations here:
- Model choice, how long are these results valid. Models change all the time (Sonnet 5 came out today), realistically the results of this same trial today will likely be quite different.
- Cost, is this sensible? Based on Claude's estimates each loop cost about $4 in tokens. You'd need an ROI to do this in a 'real' product. $40 (10 loops) isn't a high bar but running a loop like this for every change in a code base could be costly.
- Single machine, single thread results. Compression benchmarks vary wildly across CPUs, these were all done on an M2 Macbook Pro but I am sure the results would have differed in other scenarios.
- Choice of optimisation function. This is the biggest one, outlined several times above, had I chosen something like average( compressed / raw) or even median the path to better would have looked very different. I've written a lot about choosing metrics in the past and this applies to agents as much as it does to humans.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み