最新オープンアーティファクト(#21):Gemma 4、DeepSeek V4、Kimi K2.6、MiMo 2.5、GLM-5.1 など。CAISI の V4 評価について
CAISI と Epoch AI の最新評価により、オープンソースモデルとクローズドモデルの性能差が拡大していることが示された一方、ベンチマーク手法の限界も指摘され、真の能力比較にはより高度な評価環境が必要であると結論付けられています。
キーポイント
オープン vs クローズドの格差拡大
CAISI の V4 評価および Epoch AI の ECI 指標によると、中国発のオープンモデル(DeepSeek V4 など)は米国のフロンティアモデルとの性能差が時間とともに広がっており、数ヶ月分の遅れが生じていると分析されています。
ベンチマーク手法の限界とバイアス
今回の評価で使用された単純化されたセットアップ(固定トークン予算や標準的な bash 環境など)は、実際の開発現場でモデルが訓練されている複雑な環境を反映しておらず、能力差を過大評価する可能性があると指摘されています。
真の性能比較への提言
オープンとクローズドのモデルを公平に比較するためには、Claude Code や OpenCode などの専用ハーンネスを使用し、モデル固有のプロンプトを適用した評価が必要であると主張されています。
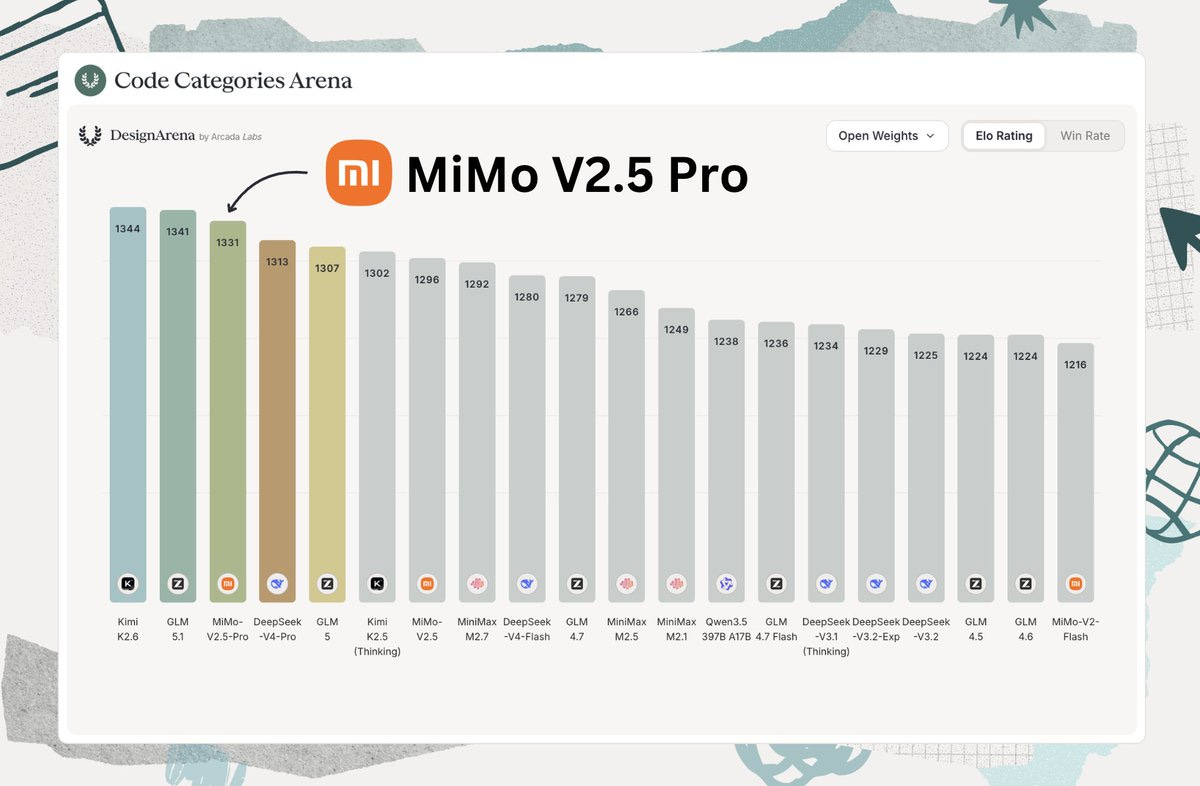
MiMo-V2.5-Pro の台頭
Xiaomi が Apache 2.0 ライセンスの下でリリースした MiMo-V2.5 Pro は、Kimi K2.6 や GLM-5.1 と並び、ベンチマークと実世界での使用において最高峰のモデルと互角の性能を示しています。
Gemma 4 のライセンス変更
Google は Gemma シリーズに Apache 2.0 ライセンスを採用し、カスタムライセンスによる解釈の不確実性や法的課題を解消しました。
DeepSeek-V4-Flash の性能評価
DeepSeek-V4 シリーズの Flash モデル(284B-13B)は、サイズに対して相対的に強力なパフォーマンスを発揮し、Pro モデルよりも注目を集めています。
Qwen3.6-35B-A3B の登場
Qwen 3.5 シリーズの更新版であり、最も広く使用されているサイズの一つをターゲットにしています。
影響分析・編集コメントを表示
影響分析
この記事は、業界内で進行中の「オープンソース vs クローズド」の性能競争に関する議論に重要な視点を提供しており、単なるベンチマークスコアの比較ではなく、評価手法そのものの再考を促しています。特に、実際の開発現場での実用性を無視した評価が誤った結論を導く可能性を指摘することで、研究者やエンジニアにとって今後のモデル選定や評価基準のアップデートに向けた示唆に富んでいます。
編集コメント
ベンチマークスコアに踊らされず、実際の開発環境での挙動を重視するべきだという指摘は、現場のエンジニアにとって非常に示唆に富んでいます。モデル選定においては、単純な数値比較だけでなく、評価手法の文脈を理解することが重要であることが再確認されました。
今月は非常に忙しく、DeepSeek を含むすべてのオープンフロンティアラボが新しいモデルをリリースしました。これを受けて、AI 基準とイノベーションセンター(CAISI)が評価を行いました。同機関は過去にもオープンモデルとそのリスクについて評価を行ってきました。その結果、オープンモデルは米国のフロンティアモデルに遅れをとっており、その差は時間とともに広がっていることが示されました。
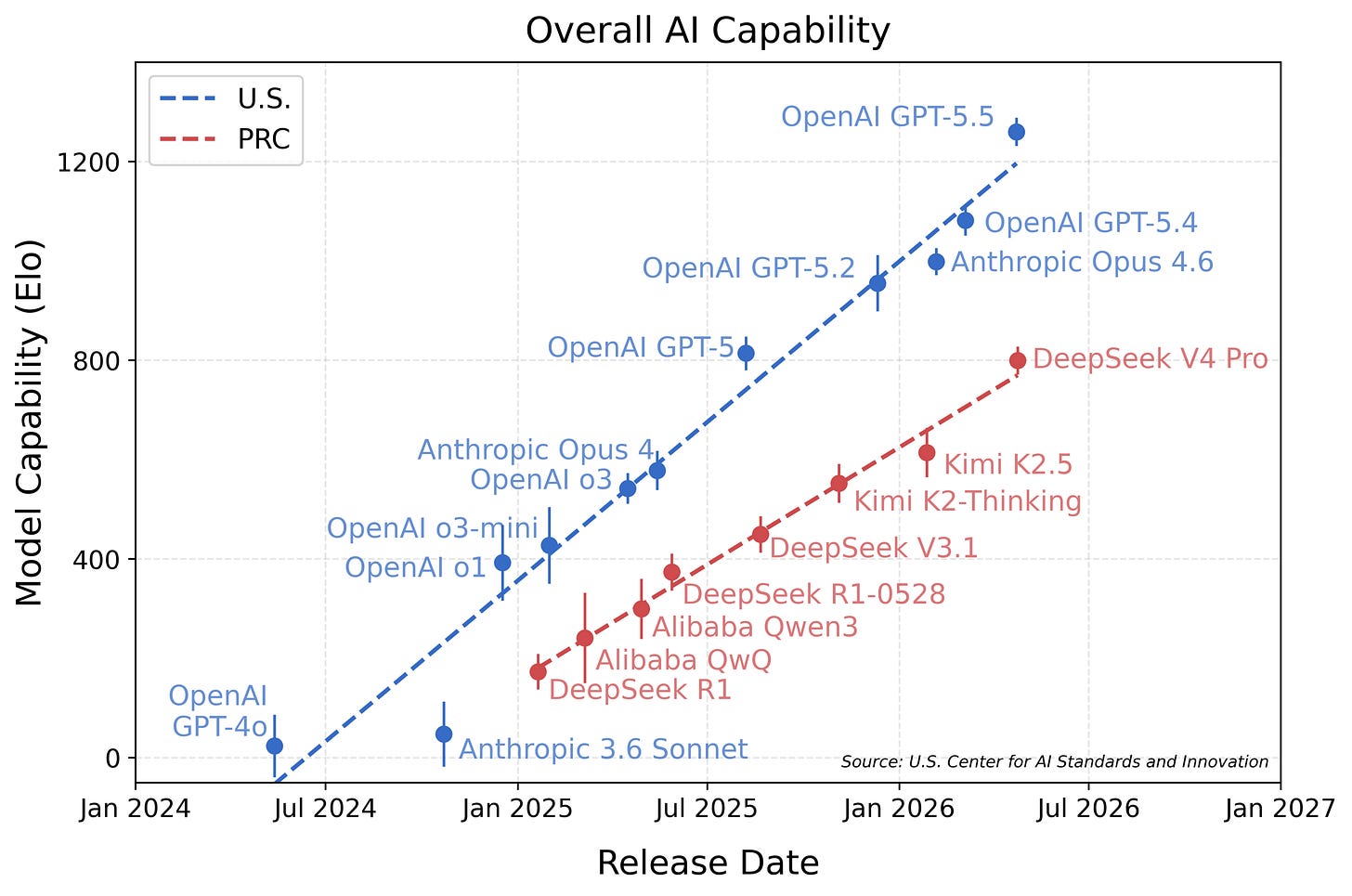
レポートでは、異なるベンチマークセットでテストされたモデル間でも比較可能であるため一般的に使用される項目反応理論(Item Response Theory)に基づいて Elo スコアが計算されています。V4 版において、CAISI は9つの異なるベンチマークを使用しました。
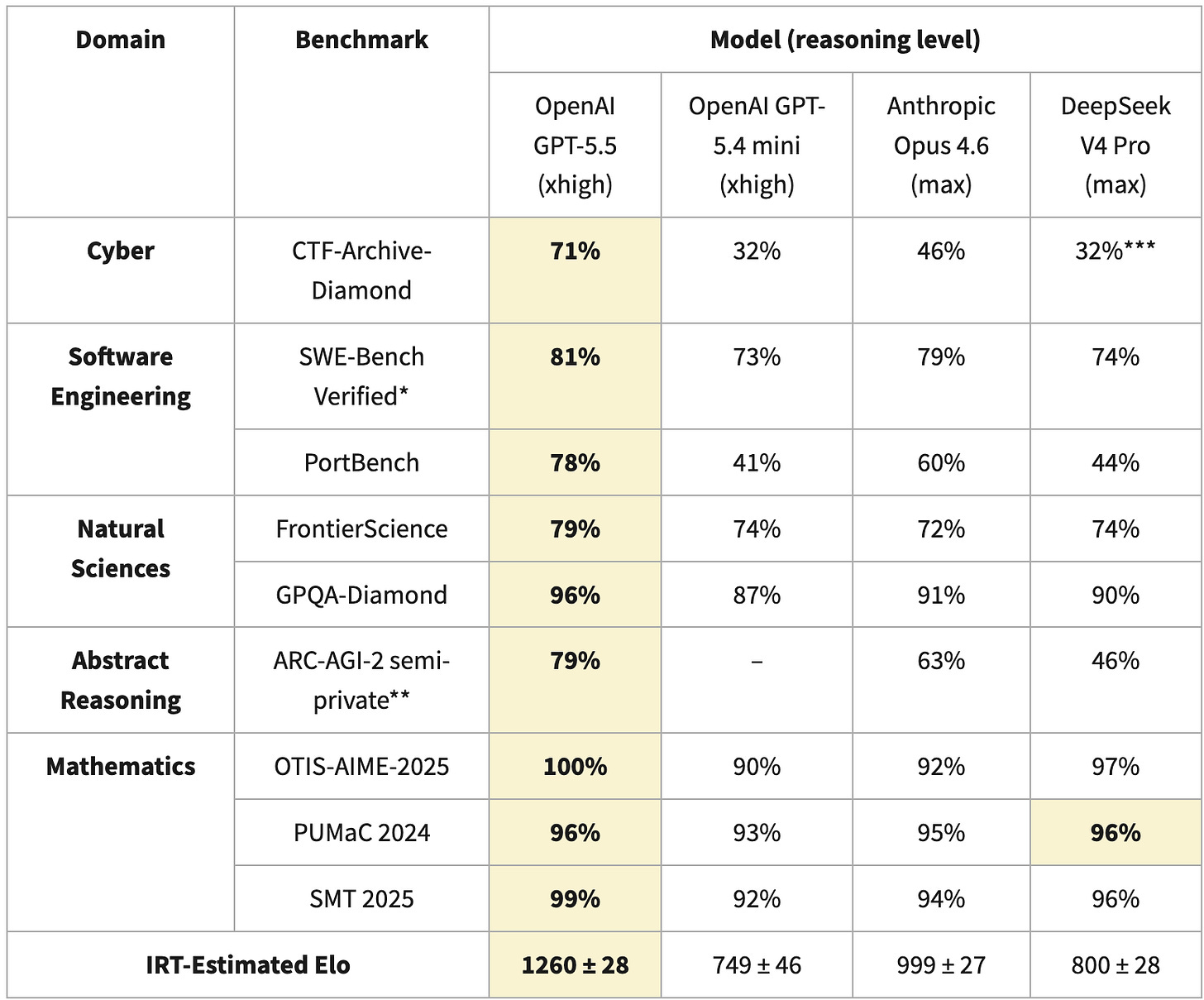
Elo スコアの大きな差は、DeepSeek V4 の CTF-Archive-Diamond(V4 についてはベンチマークの一部のみが実行され、IRT を用いて外挿された)、PortBench(CAISI 独自の非公開ベンチマーク)、および ARC-AGI-2(パブリックリーダーボードとは異なる採点方法が採用されている)における低いスコアによって説明されます。これらのベンチマークにおける差は全体の Elo に大きな影響を与え、能力の格差をさらに拡大させる可能性があります。
Epoch AI の ECI(インテリジェンス・キャパビリティ・インデックス)を使用すると、これは異なるベンチマークセット上で IRT(項目反応理論)も活用していますが、R1 以降のギャップは概ね 3〜7 ヶ月の範囲で維持されていることがわかります。
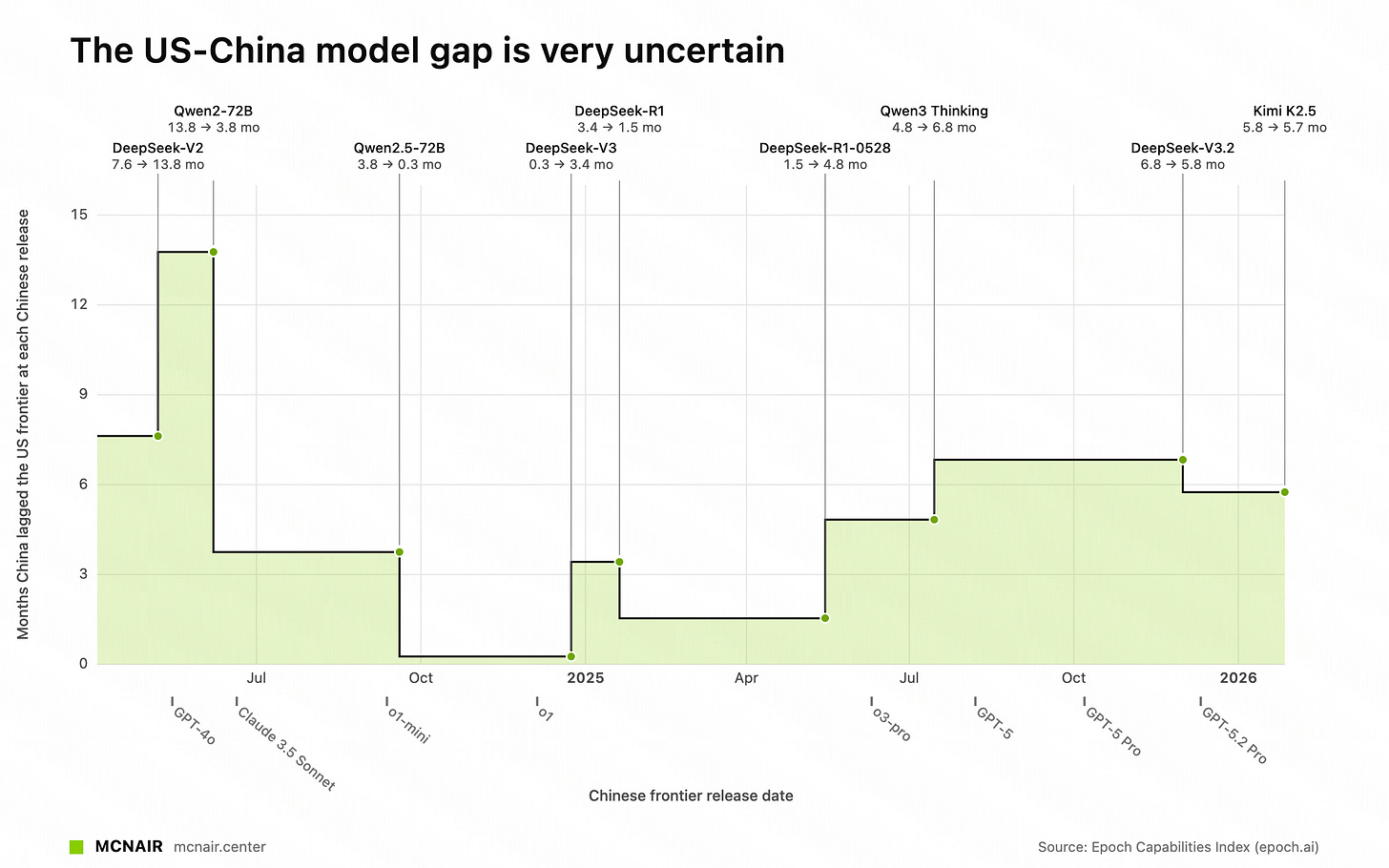
ECI におけるオープンソースとクローズドモデルのギャップ(出典:https://mcnair.center/china/)
しかし、CAISI と ECI の両方は不完全な絵を描いています。なぜなら、どちらもモデルの能力を比較するために標準化された(かつ単純な)設定を使用しているからです。より具体的に言えば、コーディングタスクは、bash へのアクセスと固定トークン予算を持つ for ループを使用して評価されますが、Claude Code や OpenCode のようなハーンネス(訓練環境)では行われません。実際、モデルはこれらのハーンネスで訓練されています!こうした設定の結果、別の言語へのアプリケーション移植は現在不可能であると主張するベンチマークが存在しますが、Bun は Zig から Rust へ 100 万行の LOC(ソースコード行数)変更を伴って移植済みです。
したがって、オープンモデルとクローズドモデルの最前線比較を行うには、すべてのモデルの能力をより適切に引き出す必要があり、そのためには優先されるハーンネスの使用およびモデル固有のプロンプトングが必要であると主張します。
このセクションは主にフローリアンによって執筆されました。Interconnects 内の興味深いダイナミクスの一つは、フローリアンがオープンフロンティアモデルとクローズドな代替案との真のパフォーマンスにおける近接性をより信じている点です。ネイサンもベンチマークが不完全であると考えていますが、クローズドモデルの方がさらに先行していると見ています。私たちは今後のコンテンツでこの点を引き続き掘り下げていきます。
シェアする
私たちが選ぶモデル
Xiaomi による MiMo-V2.5-Pro: Avid Artifacts の読者ならご存知の通り、Xiaomi はオープンモデルの開発を長年行っており、そのデビューはちょうど一年前でした。そのリリースの進捗は目覚ましく、2.5 Pro(Apache 2.0 ライセンスの下で公開)は、ベンチマークと実世界での使用の両方において、Kimi K2.6 や GLM-5.1 といった他のフラッグシップモデルと互角の性能を示しています。
google による gemma-4-26B-A4B-it(Interconnects の完全な投稿はこちら): 長らく待たれていた Gemma シリーズのアップデートで、複数のサイズを提供します:4B、9B、31B の密集型モデルに加え、26B-A4B モデル(MoE: Mixture of Experts)です。さらに重要なのは、Gemma 4 を通じて Google が Apache 2.0 ライセンスを採用したことで、独自ライセンスの解釈に伴う不確実性や法的課題が解消された点です。
moonshotai による Kimi-K2.6:Kimi シリーズのアップデートであり、全体的にパフォーマンスを強化し、再び最も優れたオープンモデルの一つとなっています。また、長期的なタスク実行能力にも注力しており、オープンモデルが数時間にわたるタスクの完了やパフォーマンス最適化を実行できることを示しています。誰もが autoresearch 型のシステム構築に注力している中、オープンモデルが追いついてきたことは重要です。
poolside による Laguna-XS.2:Poolside AI は、オープンウェイトの XS.2 を含む、初の公開コーディング特化モデルをリリースしました。そのサイズ(33B-A3B)はローカル利用に適しており、同サイズの他のモデルと同等のパフォーマンスを発揮します。関連するブログ記事や、コード評価における報酬ハッキングに関する詳細な分析も読む価値があります。
DeepSeek-V4-Flash by deepseek-ai: DeepSeek はついに、数ヶ月にわたり更新を続けてきた V3 シリーズの後継モデルを発表しました。このモデルは 2 つのサイズで提供されます:Pro は 1.6T-A49B の MoE(Mixture of Experts)であり、Flash は 284B-13B のモデルです。他の事例に基づくと、後者の Flash モデルが本当の注目すべき存在であるようです。その性能は相対的に強く、一方 Pro モデルはその規模に対して期待されたほどの成果を上げていないように見えます。技術レポートでは、より安価で優れた長文コンテキスト処理を実現するために採用されたアーキテクチャの変更点などについて、非常に詳細に説明されています。
Models
General Purpose
Qwen3.6-35B-A3B by Qwen: 最も広く使用されているサイズの一つを対象とした、Qwen 3.5 シリーズのアップデートです。
LFM2.5-350M by LiquidAI: パラメータ数 3.5 億に対して 28T トークンで学習されたこのモデルは、おそらく現在存在する中で最も過剰に訓練されたモデルかもしれません。
Trinity-Large-Thinking by arcee-ai: 西部のオープンモデルの中で最高峰の一つである Trinity の推論バージョンです。OpenRouter のランキングでは長期間トップを維持しており、OpenClaw などのエージェント型アプリケーションのパワーソースとしても機能します。
GLM-5.1 by zai-org: GLM-5 のアップデート版で、あらゆる分野でのスコアが向上しています。今回の更新の焦点は、長期にわたるタスク(long-horizon tasks)への対応です。
Read more
原文を表示
This month was packed, with all open frontier labs, including DeepSeek, releasing new models. The latter prompted an evaluation by the Center for AI Standards and Innovation (CAISI), which has evaluated open models and their risks in the past. Their result is that open models lag behind the American frontier, with the gap becoming wider over time:
For the report, they calculate an Elo score based on Item Response Theory, which is commonly used to compare different models, even when they were tested on a different set of benchmarks. For V4, CAISI used nine different benchmarks:
The huge Elo difference is explained by DeepSeek V4s bad score in CTF-Archive-Diamond (which was only run with a subset of the benchmark and extrapolated with IRT for V4), PortBench (a CAISI-private benchmark) and ARC-AGI-2 (with a different scoring method than the public leaderboards). The differences in these benchmark have a huge impact on the overall Elo, which can exacerbate the difference in capabilities.
When using Epoch AI’s ECI, which also uses IRT over a set of different benchmarks, we see that the gap roughly stays between 3-7 months since R1:
The open<>closed gap in ECI (from https://mcnair.center/china/)
However, both CAISI and ECI paint an incomplete picture, as both use standardized (and simple) setups to compare the capabilities of models. To be more concrete: Coding tasks are evaluated using access to bash and a for-loop with a fixed budget of tokens, not with a harness such as Claude Code or OpenCode, which models are trained in! These setups result in benchmarks claiming that porting applications to another language is currently not possible, while Bun has been ported from Zig to Rust with 1 million LOC changes1.
Therefore, we would argue that a frontier comparison of open and closed models would also need to elicit the capabilities of all models better, which means the usage of the preferred harnesses, as well as model-specific prompting.
This section was written primarily by Florian. An interesting dynamic within Interconnects is that Florian believes more in the proximity of open frontier models to closed alternatives in true performance. Nathan thinks the benchmarks are imperfect as well, but thinks the closed models are ahead by more. We’re going to continue to unpack this in our future content.
Share
Our Picks
MiMo-V2.5-Pro by XiaomiMiMo: Avid Artifacts readers know that Xiaomi has been working on open models for a while; its debut was exactly one year ago. The progress of its releases is remarkable, with 2.5 Pro (released under Apache 2.0) being neck and neck with other flagship models such as Kimi K2.6 and GLM-5.1 in both benchmarks and real-world usage.
gemma-4-26B-A4B-it by google (full Interconnects post here): The long-awaited update to the Gemma series, featuring multiple sizes: 4B, 9B, and 31B dense models, as well as a 26B-A4B MoE. Even more importantly, with Gemma 4, Google has decided to use Apache 2.0 as its license, which removes the uncertainty and legal challenges around interpreting custom licenses.
Kimi-K2.6 by moonshotai: An update to the Kimi series, delivering stronger performance across the board and making it one of the best open models out there yet again. They also focus on long-horizon performance, showing that open models are capable of running over hours to complete tasks or optimize performance. Given the focus of everyone to build autoresearch-like systems, seeing open models catch up is important.
Laguna-XS.2 by poolside: Poolside AI has released its first public coding-focused models, including the open-weight XS.2. Its size (33B-A3B) makes it attractive for local use, with performance on par with other models in that size range. The accompanying blog post is worth a read, as is the deep dive into reward hacking during coding evaluations.
DeepSeek-V4-Flash by deepseek-ai: DeepSeek has finally released its successor to the V3 series, which it kept updating for months. It comes in two sizes: Pro, which is a 1.6T-A49B MoE, and Flash, a 284B-13B model. Based on others’ experience, the latter model seems to be the real star of the show, as its performance is relatively strong, while Pro seems to underdeliver relative to its size. The tech report goes into great detail, including the architectural changes used to achieve better and cheaper long-context performance.
Models
General Purpose
Qwen3.6-35B-A3B by Qwen: An update to the Qwen 3.5 series targeting one of the most widely used sizes.
LFM2.5-350M by LiquidAI: With 28T tokens for 350M parameters, this model might be the most overtrained model out there.
Trinity-Large-Thinking by arcee-ai: The reasoning version of Trinity, one of the best Western open models. It has topped the OpenRouter charts for a while and can power agentic applications such as OpenClaw.
GLM-5.1 by zai-org: An update to GLM-5, improving scores across the board. The focus for this update is on long-horizon tasks.
Read more
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み