報酬信号の課題克服:SageMaker AI 上の GRPO を用いた検証可能報酬型強化学習
AWS は、報酬信号の信頼性課題を解決する「検証可能報酬に基づく強化学習(RLVR)」と GRPO アルゴリズムを組み合わせた手法を SageMaker AI で実装し、数学的推論やコード生成などの精度向上を実現する方法を公開した。
キーポイント
報酬ハッキングの克服と RLVR の導入
従来の強化学習で問題となる「報酬ハッキング」を防ぐため、モデルチューナーが定義するルールベースのプログラム的報酬関数を用いた検証可能報酬(RLVR)アプローチを採用し、客観的な正誤判定を可能にする。
GRPO と few-shot 学習の組み合わせ
Group Relative Policy Optimization (GRPO) アルゴリズムと few-shot 例示を組み合わせることで、報酬信号の検証性と透明性を高め、モデルの学習効率と出力精度をさらに向上させる手法を提案している。
SageMaker AI における実装事例
GSM8K(小学算数問題)データセットを用いた数学的推論タスクにおいて、この手法を実際に適用し、モデルの正答率を改善する具体的な実装手順と結果を示している。
汎用性の高い応用可能性
数学問題解決に限定されず、コード生成や記号操作など、出力の正誤が客観的に検証可能なタスク全般に対して同様の手法を適用可能であり、要件の変化にも迅速に対応できる。
Verifiable Reward System
The implementation uses a dual-reward system leveraging the inherent verifiability of math problems to provide objective feedback without human annotation.
Format and Correctness Rewards
A format reward (0.5 points) ensures correct response structure, while a correctness reward (1.0 point) verifies mathematical accuracy using regex extraction and tolerance-based comparison.
多段階報酬関数の統合
GRPOTrainer に複数の報酬関数(構フォーマットと数学的正解)を組み合わせ、最大 1.5 点の報酬を得てモデルの最適化を促進します。
影響分析・編集コメントを表示
影響分析
この記事は、LLM の強化学習における最大の課題の一つである「報酬信号の不確実性」に対して、AWS が具体的な技術的解決策(RLVR+GRPO)を提示した点で重要です。特に、人間のラベリングコストに依存せず、客観的なルールで学習を制御できる手法は、コード生成や論理的推論など高品質な出力が求められる分野での実用化を加速させる可能性があります。
編集コメント
強化学習の導入障壁を下げ、実用レベルでの LLM 最適化を可能にする具体的なプラクティスガイドとして非常に価値が高い記事です。特に「報酬ハッキング」という専門的な課題に対し、GRPO という現代的なアルゴリズムでどう対処するかを示している点が秀逸です。
大規模言語モデルのトレーニングには正確なフィードバック信号が必要ですが、従来の強化学習(RL)は報酬信号の信頼性においてしばしば課題を抱えています。これらの信号の質は、モデルがどのように学習し、意思決定を行うかに直接影響します。しかし、堅牢なフィードバックメカニズムを構築することは複雑であり、エラーが発生しやすいものです。現実世界のトレーニングシナリオでは、学習プロセスを混乱させる隠れたバイアス、意図しないインセンティブ、曖昧な成功基準が導入されることが多く、その結果、モデルが予測不能な行動をとったり、望ましい目標を満たせなくなったりします。
本記事では、報酬信号に検証と透明性をもたらしてトレーニングパフォーマンスを向上させるために、検証可能な報酬に基づく強化学習(RLVR)を実装する方法を学びます。このアプローチは、数学的推論、コード生成、または記号操作タスクなど、出力の正しさを客観的に検証できる場合に最も効果的です。また、Group Relative Policy Optimization (GRPO) や few-shot 例などの技術を組み合わせて結果をさらに改善する方法も紹介します。ここでは GSM8K データセット(Grade School Math 8K: 小学校レベルの数学問題のコレクション)を使用して、数学的問題解決の精度を向上させますが、ここで紹介された技術は他の多様なユースケースにも適応可能です。
技術的概要
実装の詳細に入る前に、このアプローチの基盤となる強化学習(RL)の概念を理解しておくことが有益です。強化学習は、報酬信号を通じて構造化されたフィードバックシステムを確立することで、モデル学習における課題に対処します。このパラダイムにより、モデルは相互作用を通じて学習し、最適な行動へと導くためのフィードバックを受信します。強化学習は、出力の品質に関する明確に定義されたシグナルに基づいてモデルが反復的に応答を改善するための枠組みを提供するため、ユーザーと対話し、結果に応じて行動を適応させる必要があるモデルのトレーニングにおいて非常に効果的です。
従来の強化学習は、重要な考慮事項を浮き彫りにしました。すなわち、報酬信号の質が極めて重要であるという点です。報酬関数が不正確または不完全な場合、モデルは「報酬ハッキング」に陥り、意図しない方法でスコアを最大化しようとしながら、望ましい行動を実現できないことがあります。この限界を認識したことが、信頼性の高い明確に定義された報酬関数の作成に焦点を当てた、より厳密なアプローチの開発へとつながりました。
RLVR は、モデルチューナーによって定義されたルールベースのフィードバックを通じて報酬ハッキングに対処します。これは、特定の基準に対して出力を自動的に採点するプログラムによる報酬関数を使用し、人間の評価を集めるというボトルネックなしに迅速な反復を可能にします。これらの「検証可能な」報酬は、客観的で再現性のあるルールに基づいているため、RLVR は進化要件に適しており、一般的な最適化戦略を学習して新しいシナリオにすばやく適応できます。GRPO は、一度にすべてのデータ全体ではなくグループ内でのパフォーマンスを比較することで AI モデルの学習を改善する強化学習アルゴリズムです。トレーニングデータを意味のあるグループに整理し、各グループのベースラインに対してパフォーマンスを最適化することで、各カテゴリに適切な注意を払います。このグループ認識型の最適化はトレーニングの変動を減らし、収束を加速し、さまざまなカテゴリで一貫してパフォーマンスを発揮するモデルを生み出す可能性があります。RLVR と GRPO を組み合わせることで、自動化された報酬が学習を導きながら、グループ相対的な最適化がバランスの取れたパフォーマンスを推進するフレームワークが構築されます。
異なるタスクの側面に対して報酬関数を定義し、GRPO はトレーニング中にこれらを別々のグループとして扱います。これにより、複数の次元にわたる同時的な改善が可能になります。この組み合わせは、迅速な適応と堅牢なパフォーマンスを実現し、トレーニング分布を超えた一般化を必要とする動的環境に理想的です。Few-shot 学習を追加することで、このフレームワークが以下の 3 つの側面で強化されます。第一に、few-shot の例はモデルに対して良好な出力のテンプレートを提供し、探索のための検索空間を絞り込みます。第二に、GRPO はこれらの例を活用して、各プロンプトに対して複数の候補応答を生成し、各グループ内での相対的なパフォーマンスに基づいて学習します。第三に、検証可能な報酬によって、どのアプローチが成功したかを即座に確認できます。この組み合わせにより学習が加速され、モデルは所望の形式の具体的な例から始め、グループベースの比較を通じて効率的に変化を探索し、正しさに関する決定的なフィードバックを受けます。
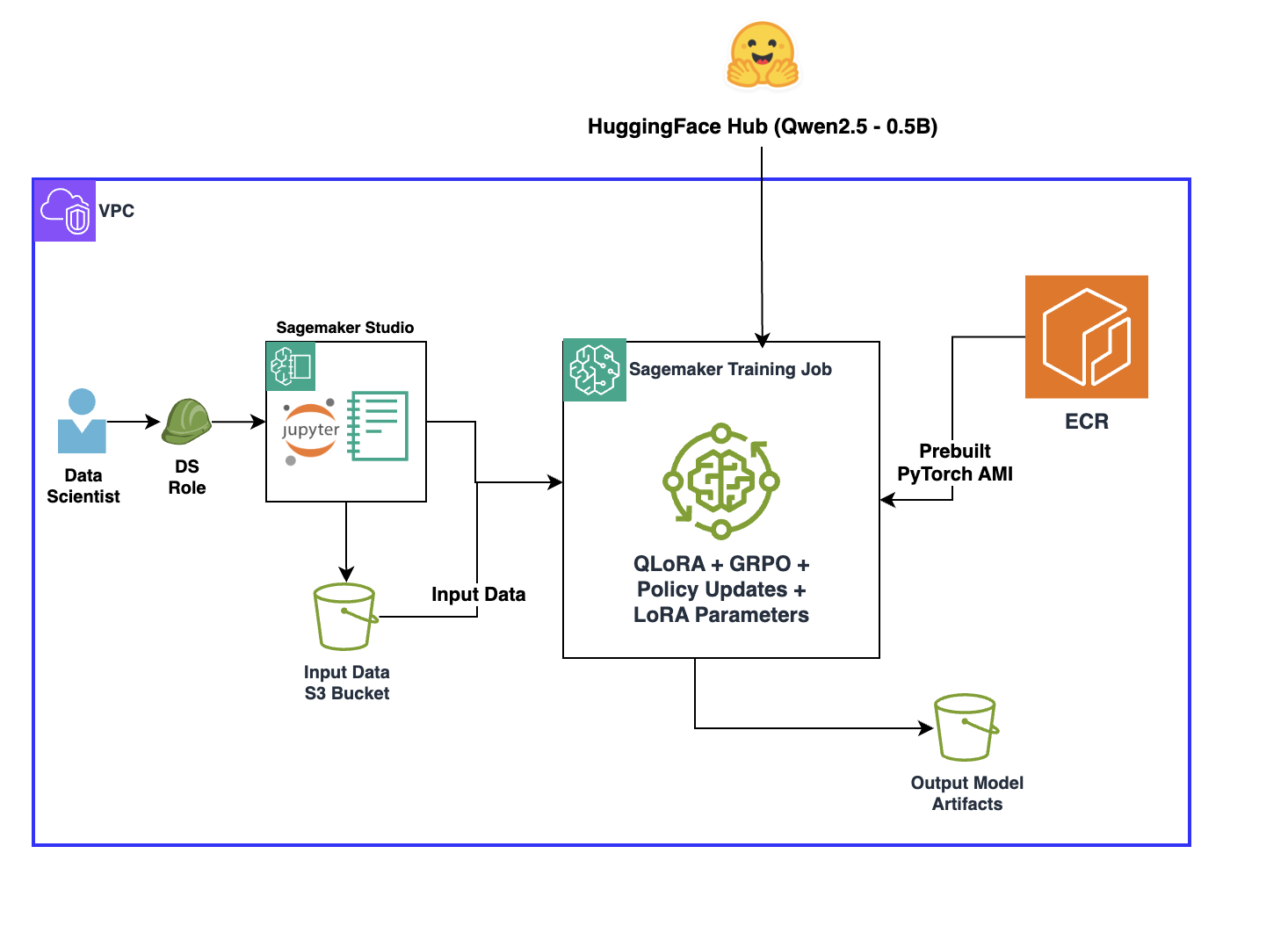
ソリューション概要
本セクションでは、Amazon Amazon SageMaker Training Jobs を使用して、SageMaker AI 上で Qwen2.5-0.5B モデルをファインチューニングする方法について順を追って説明します。Amazon SageMaker Training jobs は分散型マルチ GPU およびマルチノード構成をサポートしており、必要に応じて高性能なクラスターを即座に起動し、数十億パラメータのモデルを高速にトレーニングでき、ジョブ完了時に自動的にリソースを終了できます。
注意: このユースケースでは Qwen2.5-0.5B が選択されましたが、コード生成などの他の用途にはより大規模なモデル(例:Qwen2.5-Coder-7B)が必要となり、その結果としてより大きなトレーニングインスタンスが必要になります。
前提条件
Amazon SageMaker AI で本記事の例を実行するには、以下の前提条件を満たす必要があります:
- AWS リソースを格納する AWS アカウント。
- SageMaker AI にアクセスするための AWS Identity and Access Management (IAM) ロール。IAM が SageMaker AI とどのように連携するかについては、AWS Identity and Access Management for Amazon SageMaker AI を参照してください。
- 本記事で提供されているノートブックは、AWS 認証情報が適切に設定され、AWS アカウントへのアクセスが許可されていれば、PyCharm や Visual Studio Code などの好みの開発環境(インタラクティブ開発環境:IDE)から実行できます。ローカル環境の設定については、「AWS CLI の設定構成」を参照してください。オプションとして、SageMaker AI 上で straightforward な開発プロセスを実現するために Amazon SageMaker Studio を使用することもできます。
- 本記事の手順に従う場合、ml.p4d.24xlarge インスタンスでのトレーニングが必要です。例のトレーニングコードを実行するには、これらの SageMaker トレーニングインスタンスへのアクセス権限が必要です。不明な場合は、AWS Management Console の AWS サービスクォータを確認してください。
管理クォータで AWS サービスとして Amazon SageMaker を選択します。
- トレーニングジョブの使用に対して ml.p4d.24xlarge を選択し、アカウントレベルでの増額をリクエストします。
- GitHub リポジトリへのアクセス: https://github.com/aws-samples/amazon-sagemaker-generativeai
環境設定
VS Code や PyCharm などの好みの IDE を使用できますが、前提条件で述べた通り、ローカル環境が AWS と連携するように構成されていることを確認してください。
SageMaker Studio JupyterLab スペース を使用するには、以下の手順を実行してください。
- Amazon SageMaker AI コンソールで、ナビゲーションペインの「ドメイン」を選択し、対象のドメインを開きます。
- ナビゲーションペイン内の「アプリケーションと IDE」セクションで、「Studio」を選択します。
- 「ユーザープロファイル」タブで、自分のユーザープロファイルを見つけて、「起動」および「Studio」を選択します。
- Amazon SageMaker Studio で、少なくとも 50 GB のストレージを備えた ml.t3.medium JupyterLab ノートブックインスタンスを起動します。
大規模なノートブックインスタンスは不要です。ファインチューニングジョブは、GPU アクセラレーションを備えた別のエフェメラルトレーニングインスタンス上で実行されるためです。
- ファインチューニングを開始するには、まず GitHub リポジトリをクローンし、3_distributed_training/reinforcement-learning/grpo-with-verifiable-reward ディレクトリに移動してから、model-finetuning-grpo-rlvr.ipynb を起動します。
- Python 3.12 以降のカーネルを持つノートブック
ファインチューニング用のデータセットを準備する
RLVR(Verifiable Rewards-based Reinforcement Learning)を用いた GRPOの実行には、各質問に対する正解(最終回答)が必要で、これにより報酬を計算します。まず、各質問の最終回答を抽出してデータを準備してください。
dataset = GSM8K(split='train', include_answer=False, include_reasoning=True, few_shot=True, num_shots=8, seed=None, cot=True).dataset.shuffle(seed=42)
Dataset({
features: ['question', 'answer', 'prompt', 'final_answer'],
num_rows: 7473
})
さらに、この例ではモデルのトレーニング性能を向上させるために少数ショット例(8 例)を使用しています。強化学習における少数ショット例の詳細については、論文 「One Training Example で大規模言語モデルの推論を行うための強化学習」 を参照してください。研究論文は単一ショット例に焦点を当てていますが、本記事では単一ショットと複数ショットの両方のパフォーマンスをご紹介します。
各入力には、8 つの例が続き、その後に解決すべき問題が含まれます:
"Question: Mark has $50 and buys a toy that costs $35. How much money does he have left?
Solution: Let's think step by step. To find out how much money Mark has left, subtract the cost of the toy from the total amount of money Mark has. So, $50 - $35 = $15.
#### The final answer is 15
Question: Emily has 3 times as many pencils as Alice. If Alice has 15 pencils, how many pencils does Emily have?
Solution: Let's think step by step. To find out how many pencils Emily has, we multiply the number of pencils Alice has by 3. Alice has 15 pencils, so Emily has 15 * 3 = 45 pencils.
#### The final answer is 45
Question: Jack has collected 12 more marbles than Kevin. If Kevin has 27 marbles, how many marbles does Jack have?
Solution: Let's think step by step. To find how many marbles Jack has, we add 12 to the number of marbles Kevin has. So, Jack has 27 + 12 = 39 marbles.
#### The final answer is 39
質問:教室には24人の生徒がいます。各グループに4人ずつ入れる場合、何グループを作ることができますか?
解答:ステップバイステップで考えましょう。作ることができるグループ数を求めるには、生徒の総数を1グループあたりの生徒数で割ります。したがって、24 ÷ 4 = 6グループを作ることができます。
#### 最終的な答えは 6 です
質問:サマンサはクッキーを40個焼き、それぞれ5個ずつ等しく袋に入れることにしました。サマンサは何個の袋が必要になりますか?
解答:ステップバイステップで考えましょう。必要な袋の数を求めるには、クッキーの総数を1袋あたりのクッキー数で割ります。したがって、40 ÷ 5 = 8となります。
#### 最終的な答えは 8 です
質問:鉛筆のパックが1つ$4です。7パック買うと、合計いくらになりますか?
解答:ステップバイステップで考えましょう。総額は、1パックあたりの価格に購入するパック数を掛けることで求められます。したがって、7 × $4 = $28となります。
#### 最終的な答えは 28 です
質問:本には240ページあり、サラは毎日20ページずつ読みます。この本を読み終えるのに何日かかりますか?
解答:ステップバイステップで考えましょう。サラは1日に20ページ読むので、総ページ数を1日に読むページ数で割ります。したがって、240 ÷ 20 = 12日で本を読み終えることができます。
#### 最終的な答えは 12 です
質問:ある農家はリンゴとオレンジを合わせて80個持っています。リンゴが30個の場合、オレンジは何個ありますか?
解答:ステップバイステップで考えましょう。オレンジの数を求めるには、果物の総数からリンゴの数を引きます。したがって、オレンジの数は 80 - 30 = 50 です。
#### 最終的な答えは 50
質問:ミミはビーチで2ダース(24個)の貝殻を集めました。カイルはミミが拾った貝殻の2倍を見つけ、それをポケットに入れました。リーはカイルが見つけた貝殻の3分の1を掴みました。リーは何個の貝殻を持っていたでしょうか?
解答:ステップバイステップで考えましょう。
データ準備完了後、データの10%を検証用セットとして残し、トレーニングセットと検証セットの両方をS3にプッシュしてください。
検証可能な報酬関数
この数学的推論用のGRPO実装は、トレーニング中に客観的で検証可能なフィードバックを提供する二重報酬システムを採用しています。このアプローチは、数学的問題が持つ本質的な検証可能性を活用し、人間の注釈や主観的な評価を必要とせずに信頼性の高いトレーニングシグナルを作成します。あなたは、モデルが正しい応答フォーマットと結果の数学的精度の両方に向かって学習するように導くために、互いに補完する2つの報酬関数を実装する必要があります。
フォーマット報酬関数
この関数は、以下の方法でモデルが応答を正しく構造化することを学ぶのを検証するのに役立ちます:
- パターンマッチング:特定のフォーマット「#### The final answer is [number]」を検索します
- 一貫した採点:適切なフォーマットには 0.5 ポイント、誤ったフォーマットには 0.0 ポイントを付与します
- 学習シグナル:モデルが期待される回答構造に従うよう促します
#Format reward function
def format_reward_func_qa(completions, **kwargs):
pattern = r"\n#### The final answer is \d+"
completion_contents = [completion for completion in completions]
matches = [re.search(pattern, content) for content in completion_contents]
return [0.5 if match else 0.0 for match in matches]
Correctness Reward Function
この関数は、以下の要素を通じて核心的な数学的検証を提供します:
- 回答抽出:正規表現を使用して、フォーマットされた応答から数値の答えを抽出します
- 正規化:カンマ、通貨記号、単位などの一般的な書式文字を除去します
- 精度比較:浮動小数点の精度処理のために 1e-3 の許容誤差(tolerance)を使用します
- バイナリ採点:正解には 1.0 ポイント、不正解には 0.0 ポイントを付与します
#Correctness reward function
def correctness_reward_func_qa(completions, final_answer, **kwargs):
rewards = []
for completion, ground_truth in zip(completions, final_answer):
try:
match = re.search(r'####.*?([\d,]+(?:\.\d+)?)', completion)
if match:
answer = match.group(1)
for remove_char in [',', '$', '%', 'g']:
answer = answer.replace(remove_char, '')
if abs(float(answer)-float(ground_truth))
Integrating RLVR with GRPO
The reward functions are integrated into the GRPO training pipeline through the GRPOTrainer:
rewards_funcs = [format_reward_func_qa, correctness_reward_func_qa]
trainer = GRPOTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
processing_class=tokenizer,
peft_config=peft_config,
reward_funcs=rewards_funcs,
)
トレーニング中、GRPO はこれらの報酬関数を使用してポリシー勾配を計算します。まず、モデルは各数学問題に対して複数の完成文(completions)を生成します。次に、両方の報酬関数について各応答の報酬が計算されます。フォーマット報酬関数は適切な応答構造に対して最大 0.5 を付与し、正解度報酬関数は回答の数学的正確性に対して最大 1.0 を付与するため、完成文あたりの最大合計報酬は 1.5 となります。その後、GRPO はグループ内の完成文を比較して最良の応答を特定します。最後に、ポリシー更新ステップにおいて、損失関数は報酬の違いを使用してモデルパラメータを更新します。高い報酬を得た完成文はその確率を増加させ、低い報酬を得た完成文はその確率を減少させます。この相対的なランキングが最適化プロセスを駆動します。
以下の例は、Qwen2.5-0.5B のファインチューニング方法をデモンストレーションしています。レシピはスクリプトフォルダに提供されており、カスタマイズしたりベースモデルを変更したりすることができます。ここでは、Quantized Low-Rank Adaptation (QLoRA) を使用して検証可能な報酬を伴う GRPO を利用します。QLoRA は、精度のわずかなトレードオフと引き換えに、トレーニングリソースの要件を削減しトレーニングプロセスを高速化するための技術としてここで使用されています。
Model arguments
model_name_or_path: Qwen/Qwen2.5-0.5B
tokenizer_name_or_path: Qwen/Qwen2.5-0.5B
model_revision: main
torch_dtype: bfloat16
attn_implementation: flash_attention_2
bf16: true
tf32: true
output_dir: /opt/ml/model/Qwen2.5-0.5B-RL-VR-GRPO
データセット引数
train_dataset_id_or_path: /opt/ml/input/data/train/dataset.json
test_dataset_id_or_path: /opt/ml/input/data/val/dataset.json
dataset_splits: 'train'
max_seq_length: 2048
packing: true
LoRA 引数
use_peft: true
load_in_4bit: true
lora_target_modules: ["q_proj", "k_proj", "v_proj", "o_proj", "up_proj", "down_proj", "gate_proj"]
lora_modules_to_save: ["lm_head", "embed_tokens"]
lora_r: 16
lora_alpha: 16
学習引数
num_train_epochs: 2
per_device_train_batch_size: 16
gradient_accumulation_steps: 2
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: True
learning_rate: 1.84e-4
lr_scheduler_type: cosine
warmup_ratio: 0.1
ログ記録引数
logging_strategy: steps
logging_steps: 5
report_to:
- mlflow
save_strategy: "no"
seed: 42
レシピの概要
このレシピは、数学的推論タスクに対する Qwen2.5-0.5B モデルのファインチューニングに、検証可能な報酬(verifiable rewards)を備えたグループ相対ポリシー最適化(GRPO: Group Relative Policy Optimization)を実装したものです。本レシピでは、人間の注釈を必要とせずに、回答フォーマットと数学的な正しさの両方を客観的に評価する二重報酬システムを使用します。
重要なハイパーパラメータ:
learning_rate: 1.84e-4 – GRPO 学習用に最適化された学習率
原文を表示
Training large language models requires accurate feedback signals, but traditional reinforcement learning (RL) often struggles with reward signal reliability. The quality of these signals directly influences how models learn and make decisions. However, creating robust feedback mechanisms can be complex and error prone. Real-world training scenarios often introduce hidden biases, unintended incentives, and ambiguous success criteria that can derail the learning process, leading to models that behave unpredictably or fail to meet desired objectives.
In this post, you will learn how to implement reinforcement learning with verifiable rewards (RLVR) to introduce verification and transparency into reward signals to improve training performance. This approach works best when outputs can be objectively verified for correctness, such as in mathematical reasoning, code generation, or symbolic manipulation tasks. You will also learn how to layer techniques like Group Relative Policy Optimization (GRPO) and few-shot examples to further improve results. You’ll use the GSM8K dataset (Grade School Math 8K: a collection of grade school math problems) to improve math problem solving accuracy, but the techniques used here can be adapted to a wide variety of other use cases.
Technical overview
Before diving into implementation, it’s helpful to understand the RL concepts that underpin this approach. RL addresses challenges in model training by establishing a structured feedback system through reward signals. This paradigm enables models to learn through interaction, receiving feedback that guides them toward optimal behavior. RL provides a framework for models to iteratively improve their responses based on clearly defined signals about the quality of their outputs, making it highly effective for training models that interact with users and must adapt their behavior based on outcomes. Traditional RL has highlighted an important consideration: the quality of the reward signal matters significantly. When reward functions are imprecise or incomplete, models can engage in “reward hacking,” finding unintended ways to maximize scores without achieving the desired behavior. Recognizing this limitation has led to the development of more rigorous approaches that focus on creating reliable, well-defined reward functions.
RLVR addresses reward hacking through rule-based feedback defined by the model tuner. It uses programmatic reward functions that automatically score outputs against specific criteria, enabling rapid iteration without the bottleneck of collecting human ratings. These “verifiable” rewards come from objective, reproducible rules, making RLVR ideal for evolving requirements because it learns general optimization strategies and adapts quickly to new scenarios. GRPO is a reinforcement learning algorithm that improves AI model learning by comparing performance within groups rather than across all data at once. It organizes training data into meaningful groups and optimizes performance relative to each group’s baseline, giving appropriate attention to each category. This group-aware optimization reduces training variance, accelerates convergence, and can produce models that perform consistently across various categories. Combining RLVR with GRPO creates a framework where automated rewards guide learning while group-relative optimization helps drive balanced performance.
You define reward functions for different task aspects, and GRPO treats these as distinct groups during training, facilitating simultaneous improvement across dimensions. This combination delivers rapid adaptation and robust performance, ideal for dynamic environments requiring generalization beyond training distribution. Adding few-shot learning enhances this framework in three ways. First, few-shot examples provide templates that show the model what good outputs look like, narrowing the search space for exploration. Second, GRPO leverages these examples by generating multiple candidate responses per prompt and learning from their relative performance within each group. Third, verifiable rewards immediately confirm which approaches succeed. This combination accelerates learning: the model starts with concrete examples of the desired format, explores variations efficiently through group-based comparison, and receives definitive feedback on correctness.
Solution overview
In this section, you will walk through how to fine-tune a Qwen2.5-0.5B model on SageMaker AI using Amazon Amazon SageMaker Training Jobs. Amazon SageMaker Training jobs support distributed multi-GPU and multi-node configurations, so you can spin up high-performance clusters on demand, train billion-parameter models faster, and automatically shut down resources when the job finishes.
Note: While Qwen2.5-0.5B was selected for this use case, others like code generation will require a larger model (e.g. Qwen2.5-Coder-7B) and subsequently larger training instances.
Prerequisites
To run the example from this post on Amazon SageMaker AI, you must fulfill the following prerequisites:
- An AWS account that will contain your AWS resources.
- An AWS Identity and Access Management (IAM) role to access SageMaker AI. To learn more about how IAM works with SageMaker AI, see AWS Identity and Access Management for Amazon SageMaker AI.
- You can run the notebook provided in this post from your preferred development environment, including interactive development environments (IDEs) such as PyCharm or Visual Studio Code, provided your AWS credentials are properly set up and configured to access your AWS account. To set up your local environment, refer to Configuring settings for the AWS CLI. Optionally, you can use Amazon SageMaker Studio for straightforward development process on SageMaker AI.
- If you’re following along with this post, you will need a ml.p4d.24xlarge instance training. You will need access to these SageMaker training instances to run the example training code. If you’re unsure, you can review the AWS service quotas on the AWS Management Console:
Choose Amazon SageMaker as the AWS service under Manage Quotas.
- Select ml.p4d.24xlarge for training job usage and request an increase at account level.
- Access to the GitHub repo: https://github.com/aws-samples/amazon-sagemaker-generativeai
Environment set up
You can use your preferred IDE, such as VS Code or PyCharm, but make sure your local environment is configured to work with AWS, as discussed in the prerequisites.
To use SageMaker Studio JupyterLab spaces complete the following steps:
- On the Amazon SageMaker AI console, choose Domains in the navigation pane, then open your domain.
- In the navigation pane under Applications and IDEs, choose Studio.
- On the User profiles tab, locate your user profile, then choose Launch and Studio.
- In Amazon SageMaker Studio, launch an ml.t3.medium JupyterLab notebook instance with at least 50 GB of storage.
A large notebook instance isn’t required, because the fine-tuning job will run on a separate ephemeral training instance with GPU acceleration.
- To begin fine-tuning, start by cloning the GitHub repo and navigating to 3_distributed_training/reinforcement-learning/grpo-with-verifiable-reward directory, then launch the model-finetuning-grpo-rlvr.ipynb
- Notebook with a Python 3.12 or higher version kernel
Prepare the dataset for fine-tuning
Running GRPO with RLVR requires you to have the final answer to each question to calculate reward. First, prepare the data by extracting the final answer for each question.
dataset = GSM8K(split='train', include_answer=False, include_reasoning=True, few_shot=True, num_shots=8, seed=None, cot=True).dataset.shuffle(seed=42)
Dataset({
features: ['question', 'answer', 'prompt', 'final_answer'],
num_rows: 7473
})In addition, this example uses few-shot examples (8 shots) to improve model training performance. For more information on few-shot examples in reinforcement learning, refer to the paper “Reinforcement Learning for Reasoning in Large Language Models with One Training Example”. While the research paper focuses on single-shot examples, this post will show you both single and multi-shot performance.
Each input will contain 8 examples, followed by the problem to be solved:
"Question: Mark has $50 and buys a toy that costs $35. How much money does he have left?
Solution: Let's think step by step. To find out how much money Mark has left, subtract the cost of the toy from the total amount of money Mark has. So, $50 - $35 = $15.
#### The final answer is 15
Question: Emily has 3 times as many pencils as Alice. If Alice has 15 pencils, how many pencils does Emily have?
Solution: Let's think step by step. To find out how many pencils Emily has, we multiply the number of pencils Alice has by 3. Alice has 15 pencils, so Emily has 15 * 3 = 45 pencils.
#### The final answer is 45
Question: Jack has collected 12 more marbles than Kevin. If Kevin has 27 marbles, how many marbles does Jack have?
Solution: Let's think step by step. To find how many marbles Jack has, we add 12 to the number of marbles Kevin has. So, Jack has 27 + 12 = 39 marbles.
#### The final answer is 39
Question: There are 24 students in a classroom. If each group must have 4 students, how many groups can be formed?
Solution: Let's think step by step. To find how many groups can be formed, we divide the number of students by the number of students per group. So, 24 / 4 = 6 groups can be formed.
#### The final answer is 6
Question: Samantha baked 40 cookies and wants to divide them equally into bags, with each bag containing 5 cookies. How many bags will Samantha need?
Solution: Let's think step by step. To find the number of bags needed, divide the total number of cookies by the number of cookies per bag. Thus, 40 divided by 5 equals 8.
#### The final answer is 8
Question: A pack of pencils costs $4. If you buy 7 packs, how much will you spend in total?
Solution: Let's think step by step. The total cost is found by multiplying the cost per pack by the number of packs. Hence, you spend 7 * $4 = $28.
#### The final answer is 28
Question: A book has 240 pages, and Sarah reads 20 pages each day. How many days will it take her to finish the book?
Solution: Let's think step by step. Sarah reads 20 pages per day, so we divide the total pages by the number of pages she reads per day. Therefore, it takes her 240 / 20 = 12 days to finish the book.
#### The final answer is 12
Question: A farmer has a total of 80 apples and oranges. If he has 30 apples, how many oranges does he have?
Solution: Let's think step by step. To determine the number of oranges, we subtract the number of apples from the total number of fruits. So, the number of oranges is 80 - 30 = 50.\n
#### The final answer is 50
Question: Mimi picked up 2 dozen seashells on the beach. Kyle found twice as many shells as Mimi and put them in his pocket. Leigh grabbed one-third of the shells that Kyle found. How many seashells did Leigh have?
Solution: Let's think step by step. After the data has been prepared, keep 10 percent of the data as a validation set and push both training and validation set to S3.
The Verifiable Reward Function
This GRPO implementation for mathematical reasoning employs a dual-reward system that provides objective, verifiable feedback during training. This approach leverages the inherent verifiability of mathematical problems to create reliable training signals without requiring human annotation or subjective evaluation.You will implement two complementary reward functions that work together to guide the model toward both correct response formatting and mathematical accuracy of the result:
Format Reward Function
This function helps verify the model learns to structure its responses correctly by:
- Pattern Matching: Searches for the specific format #### The final answer is [number]
- Consistent Scoring: Awards 0.5 points for proper formatting, 0.0 for incorrect format
- Training Signal: Encourages the model to follow the expected answer structure
#Format reward function
def format_reward_func_qa(completions, **kwargs):
pattern = r"\n#### The final answer is \d+"
completion_contents = [completion for completion in completions]
matches = [re.search(pattern, content) for content in completion_contents]
return [0.5 if match else 0.0 for match in matches]Correctness Reward Function
This function provides the core mathematical verification by:
- Answer Extraction: Uses regex to extract numerical answers from formatted responses
- Normalization: Removes common formatting characters (commas, currency symbols, units)
- Precision Comparison: Uses a tolerance of 1e-3 to handle floating-point precision
- Binary Scoring: Awards 1.0 for correct answers, 0.0 for incorrect ones
#Correctness reward function
def correctness_reward_func_qa(completions, final_answer, **kwargs):
rewards = []
for completion, ground_truth in zip(completions, final_answer):
try:
match = re.search(r'####.*?([\d,]+(?:\.\d+)?)', completion)
if match:
answer = match.group(1)
for remove_char in [',', '$', '%', 'g']:
answer = answer.replace(remove_char, '')
if abs(float(answer)-float(ground_truth)) < 1e-3:
rewards.append(1.0)
else:
rewards.append(0.0)
else:
rewards.append(0.0)
except ValueError:
rewards.append(0.0)
return rewardsIntegrating RLVR with GRPO
The reward functions are integrated into the GRPO training pipeline through the GRPOTrainer:
rewards_funcs = [format_reward_func_qa, correctness_reward_func_qa]
trainer = GRPOTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
processing_class=tokenizer,
peft_config=peft_config,
reward_funcs=rewards_funcs,
)During training, GRPO uses these reward functions to compute policy gradients. First the model generates multiple completions for each mathematical problem. Next, the reward for each response is computed for both reward functions. The format reward function will grant up to 0.5 for proper response structure, and the correctness reward function will grant up to 1.0 for the mathematical accuracy of the answer for a maximum combined reward of 1.5 per completion. Then GRPO compares the completions within groups to identify the best responses. Finally, in the policy update step, the loss function uses reward differences to update model parameters. Higher-rewarded completions increase their probability, while lower-rewarded completions decrease their probability. This relative ranking drives the optimization process.The following example demonstrates how to fine-tune Qwen2.5-0.5B. The recipe is provided in the scripts folder, allowing you to customize it or change the base model. Here you will use GRPO with verifiable rewards using Quantized Low-Rank Adaptation (QLoRA). QLoRA is used here as a technique to reduce training resource requirements and speed up the training process, with a small trade off in accuracy.
# Model arguments
model_name_or_path: Qwen/Qwen2.5-0.5B
tokenizer_name_or_path: Qwen/Qwen2.5-0.5B
model_revision: main
torch_dtype: bfloat16
attn_implementation: flash_attention_2
bf16: true
tf32: true
output_dir: /opt/ml/model/Qwen2.5-0.5B-RL-VR-GRPO
# Dataset arguments
train_dataset_id_or_path: /opt/ml/input/data/train/dataset.json
test_dataset_id_or_path: /opt/ml/input/data/val/dataset.json
dataset_splits: 'train'
max_seq_length: 2048
packing: true
# LoRA arguments
use_peft: true
load_in_4bit: true
lora_target_modules: ["q_proj", "k_proj", "v_proj", "o_proj", "up_proj", "down_proj", "gate_proj"]
lora_modules_to_save: ["lm_head", "embed_tokens"]
lora_r: 16
lora_alpha: 16
# Training arguments
num_train_epochs: 2
per_device_train_batch_size: 16
gradient_accumulation_steps: 2
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: True
learning_rate: 1.84e-4
lr_scheduler_type: cosine
warmup_ratio: 0.1
# Logging arguments
logging_strategy: steps
logging_steps: 5
report_to:
- mlflow
save_strategy: "no"
seed: 42Recipe overview
This recipe implements Group Relative Policy Optimization (GRPO) with verifiable rewards for fine-tuning the Qwen2.5-0.5B model on mathematical reasoning tasks. The recipe uses a dual-reward system that objectively evaluates both answer formatting and mathematical correctness without requiring human annotation.
Important Hyperparameters:
learning_rate: 1.84e-4 – Learning rate optimized for GRPO train
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み