差分表示のパフォーマンス向上への挑戦
GitHubは大規模プルリクエストでのパフォーマンス低下問題に対処するため、Reactベースの新しい「Files changed」タブを導入し、差分行コンポーネントの最適化、仮想化による段階的機能制限、基盤コンポーネントの改善という3つの戦略的アプローチで応答性とメモリ使用量を大幅に改善した。
キーポイント
大規模プルリクエストでのパフォーマンス問題
GitHubでは大規模プルリクエスト(数千ファイル、数百万行)のレビュー時に、JavaScriptヒープが1GB超、DOMノード40万超、INPスコア悪化など深刻なパフォーマンス低下が発生していた。
3つの戦略的アプローチ
単一の解決策ではなく、差分行コンポーネントの最適化、仮想化による段階的機能制限、基盤コンポーネントの改善という3つの戦略をサイズと複雑さに応じて適用した。
Reactベースの新体験導入
GitHubはReactベースの新しい「Files changed」タブを全ユーザー向けにデフォルト化し、レンダリング最適化、インタラクション遅延、メモリ消費の改善に注力した。
パフォーマンス指標の改善
最適化により、特に大規模プルリクエストでの応答性とメモリ圧力が全体的に改善され、ユーザーが体感できる入力遅延が解消された。
v1 diff linesのパフォーマンス問題
v1では各diff lineのレンダリングコストが高く、unified viewで10個、split viewで15個のDOM要素が必要で、構文ハイライトによりさらに多くのspanタグが追加されていた。Reactコンポーネントも多く、イベントハンドラーが大量に付与されていた。
v2への移行の背景
大規模なプルリクエストではv1戦略が持続不可能となり、INPの遅延やJavaScriptヒープ使用量の増加が観測されたため、改善が必要となった。
コンポーネント構造の大幅な簡素化
v1では8つのコンポーネントから構成されていたdiff行を、v2では2つのコンポーネントに削減。SplitビューとUnifiedビューの間でコードを共有するための抽象化を廃止し、各ビュー専用のコンポーネントを作成することで、パフォーマンスを向上させた。
影響分析・編集コメントを表示
影響分析
この記事は、大規模コードベースでの開発プラットフォームのパフォーマンス最適化に関する実践的な知見を提供しており、同様の課題に直面する開発チームにとって貴重な参考事例となる。GitHubが自社プラットフォームの核心機能であるプルリクエストの体験改善に継続的に投資していることを示し、開発者向けツールの品質向上へのコミットメントを明確にしている。
編集コメント
AI業界との直接的な関連性は低いが、大規模アプリケーションのパフォーマンス最適化手法はAIツール開発にも応用可能な知見が豊富。開発者体験向上の実践例として、AI開発プラットフォーム運営者にも参考になる内容。
プルリクエストは GitHub の中核をなす存在です。エンジニアにとって、ここが私たちの時間の多くを費やす場所です。そして GitHub のスケール——プルリクエストは小さな 1 行の修正から、数千ファイル、数百万行にわたる変更まで多岐にわたります——において、プルリクエストのレビュー体験は常に高速で応答性が高いものでなければなりません。
私たちは最近、[Files changed] タブ(現在すべてのユーザーのデフォルト体験)のための新しい React ベースの体験をリリースしました。私たちの主な目標の一つは、特に大規模なプルリクエストにおいて、全体的により高性能な体験を確保することでした。つまり、最適化されたレンダリング、インタラクションレイテンシ、メモリ消費といった難しい問題に投資し、一貫して優先順位をつけることを意味しました。
最適化以前、ほとんどのユーザーにとって体験は高速で応答性がありました。しかし、大規模なプルリクエストを表示する際、パフォーマンスは顕著に低下しました。例えば、極端なケースでは JavaScript ヒープが 1 GB を超え、DOM ノード数が 400,000 を超え、ページのインタラクションが極端に遅くなったり、使用不能になったりすることが観察されました。Interaction to Next Paint (INP) スコア(応答性を判断する主要な指標)が許容範囲を超え、ユーザーが入力遅延を定量的に感じられる体験となっていました。
最近の「変更済みファイル」タブに対する改善により、いくつかのコアなパフォーマンス指標が有意義に向上しました。これらの変更のいくつかは最近の変更履歴で簡潔に触れましたが、ここではより詳細に解説します。なぜこれらが重要だったのか、何を測定したのか、そしてそれらの更新が全体的な応答性とメモリ負荷、特に大規模なプルリクエストにおいてどのように改善されたのかについて、続きをお読みください。
プルリクエストのサイズと複雑さによるパフォーマンスの改善
これらのパフォーマンス問題の改善に向けた次のステップを調査・計画し始めた際、初期段階から明白だったのは、万能薬となる単一の解決策が存在しないということです。すべての機能やブラウザネイティブの動作を保持する手法でも、極端なケースでは頭打ちになる可能性があります。一方、最悪のケースが破綻しないように設計された緩和策は、日常的なレビューには不適切なトレードオフになる場合があります。
単一の解決策を探すのではなく、一連の戦略を開発し始めました。私たちは複数のターゲットを絞ったアプローチを選択し、それぞれが特定のプルリクエストのサイズと複雑さに対応するように設計されました。
これらの戦略は以下のテーマに焦点を当てました:
Diff行コンポーネントの集中的な最適化。主要なdiff体験を、ほとんどのプルリクエストに対して効率的にします。中規模および大規模なレビューでは、ネイティブのページ内検索などの期待される動作を犠牲にすることなく高速な状態を維持します。
バーチャライゼーションを用いて段階的に機能低下させる。最大のプルリクエストでも操作性を維持する。同時に描画される内容を制限し、応答性と安定性を優先する。
基盤となるコンポーネントとレンダリングの改善に投資する。これらは、ユーザーが最終的にどのモードを使用するかに関わらず、すべてのプルリクエストのサイズに対して複合的な効果をもたらす。
これらの戦略を念頭に置き、これらの課題に対処するために私たちが取った具体的なステップと、その初期の試行がその後の改善への道を開いた方法を探っていこう。
最初のステップ:diff 行の最適化
プルリクエストのパフォーマンス向上というチームの目標に向け、私たちは3つの主要な目的を定めた。
メモリとJavaScriptヒープサイズの削減。
DOMノード数の削減。
平均INPの削減、およびp95およびp99測定値の大幅な改善。
これらの目標を達成するため、私たちは簡素化に注力した。状態の削減、要素数の削減、JavaScriptコード量の削減、そしてReactコンポーネント数の削減である。結果と新しいアーキテクチャを見る前に、起点となった当初の状況を確認しよう。
v1での成功と失敗
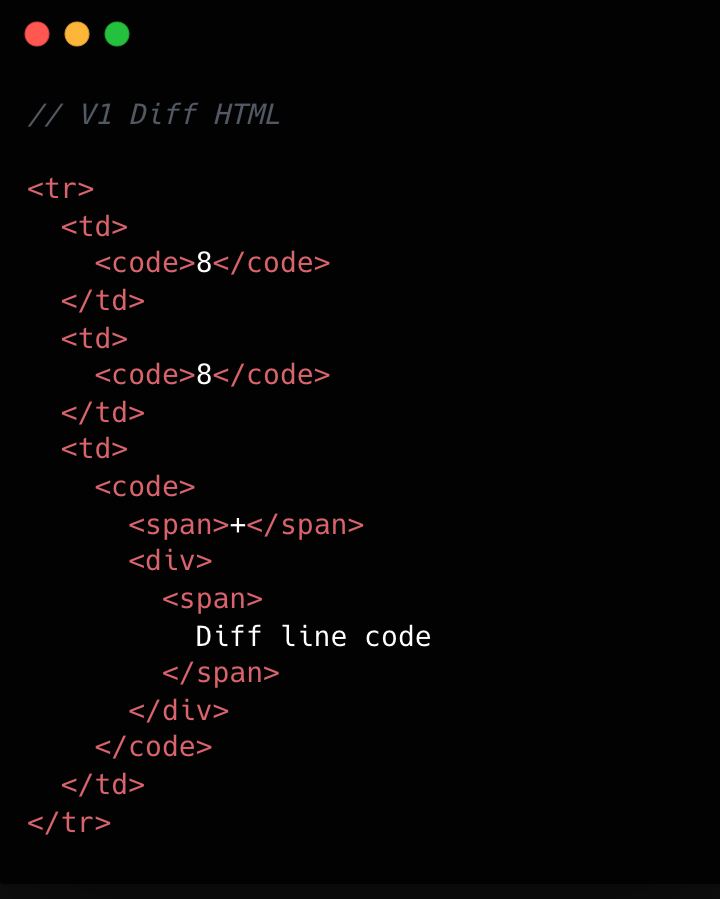
v1では、各diff行のレンダリングコストが高かった。統一ビューでは1行あたり約10個のDOM要素が必要であり、分割ビューではさらに15個近くに達した。これらは構文強調表示を行う前の話であり、構文強調表示はさらに多くのタグを追加し、DOM数をさらに押し上げる。
以下は、v1のdiffにおけるReactコンポーネント構造とDOMツリー要素を混合した簡略化された視覚図である。
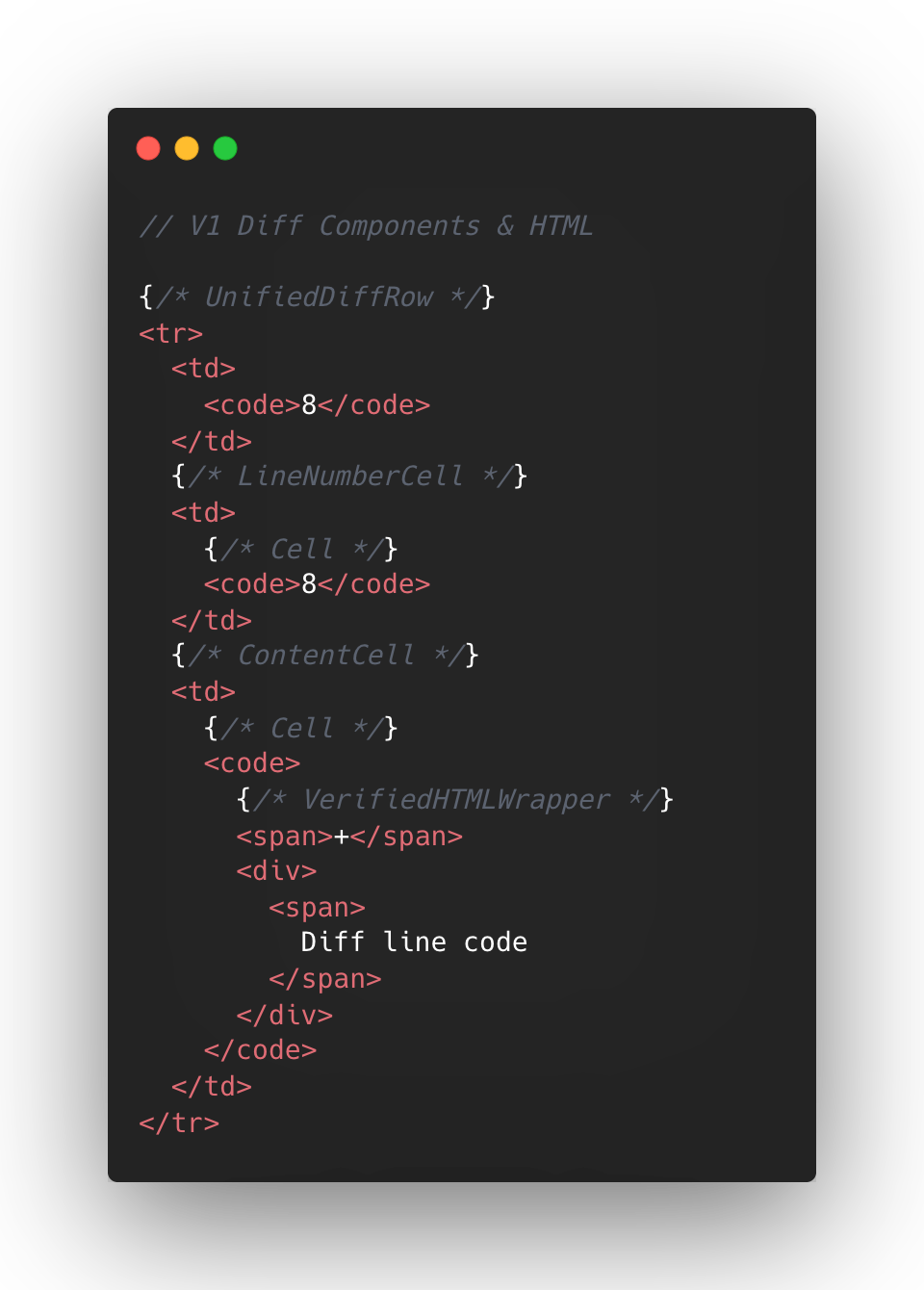
React レイヤにおいて、統一差分(unified diffs)は通常、1 行あたり少なくとも 8 つのコンポーネントを含み、分割ビュー(split view)では最小で 13 個となります。これらの数字は基本となるカウントを示すものであり、コメント、ホバー、フォーカスなどの追加 UI 状態が存在すれば、さらに多くのコンポーネントが加わります。
このアプローチは、当時の v1 において、古典的な Rails ビューから差分行を React に初めて移植した際に、私たちに理にかなっているように思えました。当初の計画は、多くの小さく再利用可能な React コンポーネントを作成し、DOM ツリーの構造を維持することに焦点を当てていました。
しかし、結果として、小さなコンポーネントに多くの React イベントハンドラをアタッチすることになりました。コンポーネントあたり 5〜6 個程度が一般的でした。小規模なスケールでは問題ありませんでしたが、大規模になるとその影響は急速に蓄積しました。1 行の差分が 20 以上のイベントハンドラを持ち、それが数千行にわたって掛け合わされることになります。
パフォーマンスへの影響だけでなく、開発者にとっても複雑さが増しました。これはよくあるシナリオです。初期デザインを実装した後、無制限のデータという要求に直面した時点で、その限界を発見することになります。
要約すると、v1 の差分行 1 行あたりには以下の要素が含まれていました:
- DOM ツリー要素が最小で 10〜15 個
- React コンポーネントが最小で 8〜13 個
- React イベントハンドラが最小で 20 個
- 多くの小さく再利用可能な React コンポーネント
この v1 の戦略は、最も大きなプルリクエスト(pull requests)には持続可能ではありませんでした。私たちが一貫して観察したところ、大きなプルリクエストのサイズは直接的に INP(Interaction to Next Paint)の低下と JavaScript ヒープ使用量の増加につながっていました。この構成を改善するための最善の方法を特定する必要がありました。
小さな変更が大きな影響をもたらす:v2
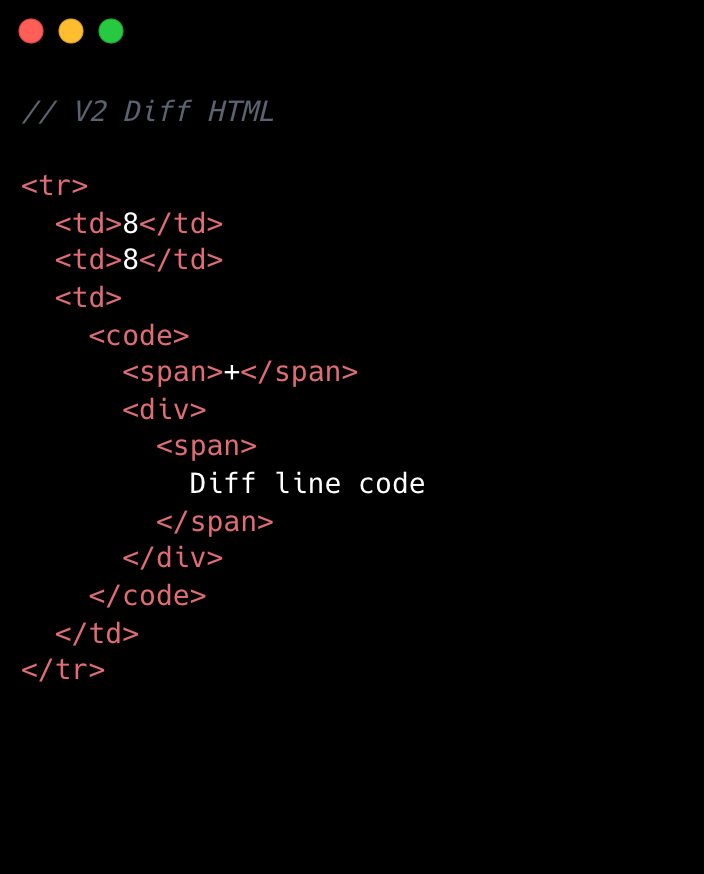
パフォーマンスの観点からは、小さな変更でも無視できません。特に大規模なスケールではなおさらです。例えば、行番号セルから不要なタグを削除しました。差分行ごとに2つのDOMノードを削減するのは一見些細に思えるかもしれませんが、10,000行にわたれば、DOM内のノード数が20,000個減少することになります。こうした狙いを定めた段階的な最適化は、どれほど小さくても積み重なり、より高速で効率的な体験を生み出します。これらの詳細を見落とさないことで、改善の機会をすべて捉え、最大のプルリクエスト全体への影響を増幅させることができました。
v1とv2の比較は以下の画像をご覧ください。
このHTMLの背後にあるコンポーネント構造を見ると、より明確になります。
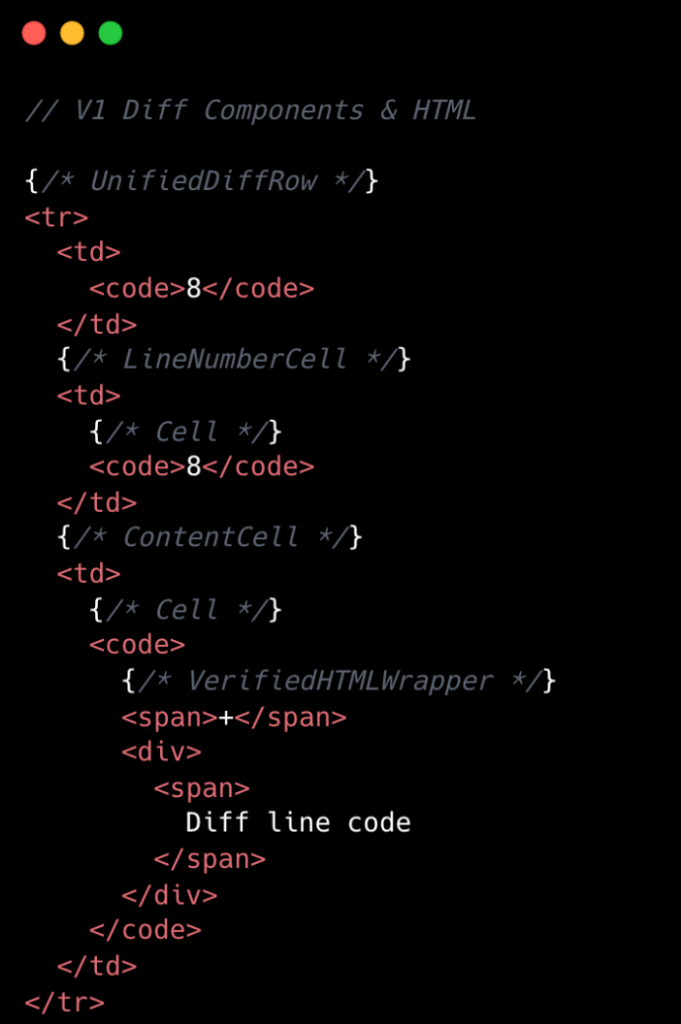
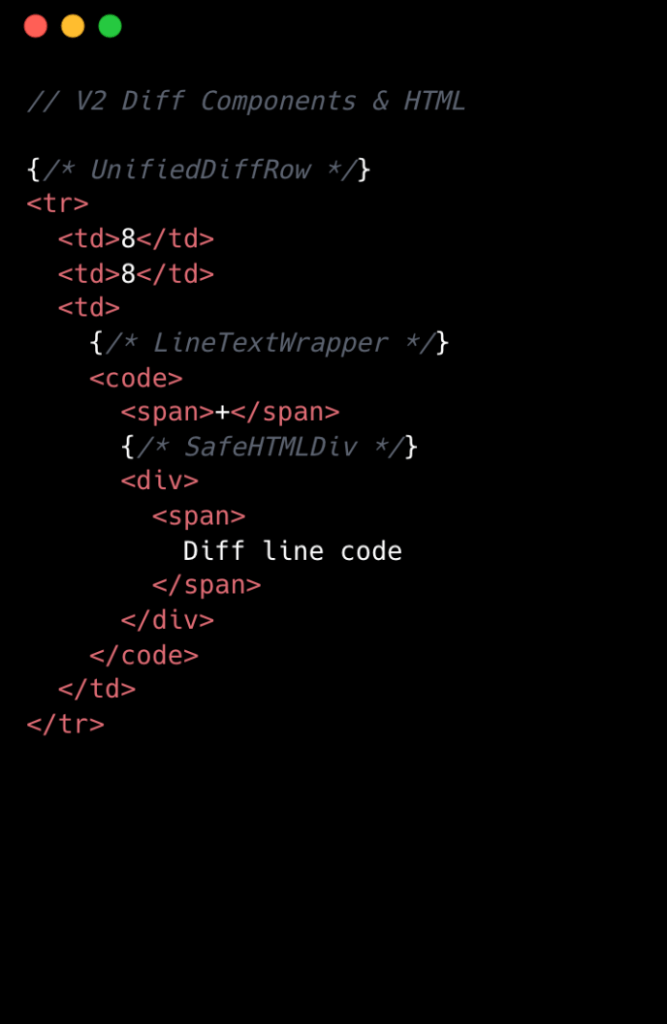
Diff 行あたりのコンポーネント数を8つから2つに削減しました。v1 のほとんどのコンポーネントは、Split 表示と Unified 表示の間でコードを共有できるようにする薄いラッパーでした。しかし、この抽象化にはコストがかかりました:各ラッパーは両方の表示のロジックを保持していましたが、一度にレンダリングされるのは片方だけでした。v2 では、各表示に専用のコンポーネントを割り当てました。一部のコードは重複していますが、結果としてシンプルかつ高速になりました。
コンポーネントツリーの簡素化
v2 では、深くネストされたコンポーネントツリーを削除し、各 Split 行および Unified 行に専用のコンポーネントを採用しました。これによりコードの重複が生じましたが、データアクセスが簡素化され、複雑さが軽減されました。
イベント処理は、data-attribute 値を使用する単一のトップレベルハンドラによって管理されるようになりました。例えば、複数の Diff 行を選択するためにクリックしてドラッグする場合、ハンドラは各イベントの data-attribute をチェックしてハイライトする行を決定し、各行が独自のマウスエンター関数を持つ必要はありません。このアプローチはコードの簡素化とパフォーマンス向上の両方を実現します。
複雑な状態を条件付きでレンダリングされる子コンポーネントへ移動
v1 から v2 への最もインパクトの大きい変更は、コメントやコンテキストメニューのためのアプリケーション状態をそれぞれのコンポーネントへ移動させたことです。GitHub の規模では、一部のプルリクエストが数千行のコードを超えることもあり、コメントやメニューが開かれるのはごく一部の一部の行に過ぎないため、すべての行が複雑なコメント状態を保持することは現実的ではありません。各 diff 行のネストされたコンポーネントへコメント状態を移動させることで、diff-line コンポーネントの主な責任はコードのレンダリングのみであることを保証し、これは単一責任の原則(Single Responsibility Principle)により近いものとなりました。
O(1) データアクセスと「useEffect」フックの削減
v1 では、共有データストアやコンポーネント状態全体にわたって O(n) のルックアップが徐々に蓄積されました。また、diff-line コンポーネントツリー全体に散在する useEffect フックを通じて、余分な再レンダリングも導入されました。
v2 ではこれに対処するため、2 つの部分からなる戦略を採用しました。まず、useEffect の使用を diff ファイルの最上位レベルに厳格に制限しました。さらに、行ラッピング React コンポーネントにおいて useEffect フックが導入されないよう防止するリンティングルール(linting rules)を確立しました。このアプローチにより、diff 行コンポーネントの正確なメモ化(memoization)が可能になり、信頼性が高く予測可能な動作が保証されます。
次に、JavaScript の Map を活用し、O(1) の定数時間でのルックアップを実現するよう、グローバルおよび差分状態機械を再設計しました。これにより、行の選択やコメント管理など、コードベース全体で共通する操作に対して高速かつ一貫性のあるセレクターを構築できました。これらの変更により、平坦化されたマップデータ構造を維持することで、コード品質の向上、パフォーマンスの改善、そして複雑さの削減を実現しました。
現在、任意の差分行は、ファイルパスと行番号をマップに渡すことで、その行にコメントが存在するかどうかを判定します。アクセス例は以下のようになります:commentsMap['path/to/file.tsx']['L8']
効果はあったでしょうか?
間違いなくあります。ページは以前よりも高速に動作し、JavaScript ヒープと INP(Interaction to Next Paint)の数値は大幅に削減されました。数値的な結果を確認するには、以下のデータをご覧ください。これらの指標は、差分比較で 10,000 行の変更を含む分割表示設定のプルリクエストを使用して評価されました。
Metricv2 改善率
総コード行数 2,000 行 27% 減少
総ユニークコンポーネントタイプ数 10 47% 減少
総レンダリング済みコンポーネント数 ~50,004 74% 減少
総 DOM ノード数 ~180,000 10% 減少
総メモリ使用量 ~80-120 MB ~50% 減少
大型プルリクエストでの INP(m1 MacBook Pro、4倍の遅延シミュレーション): ~100 ms 78% 高速化
ご覧の通り、この取り組みは大きな影響をもたらしましたが、改善はそこで終わりではありません。
最大規模のプルリクエストに対する仮想化
巨大なプルリクエスト、特にp95+(diff行が10,000行以上で、その周辺のコンテキスト行も含むもの)を扱う場合、通常の性能最適化手法は通用しません。最も効率的なコンポーネントであっても、数万個を一度にレンダリングしようとすれば、処理は重くなります。ここで登場するのがウィンドウ・バーチャライゼーション(window virtualization)です。
フロントエンド開発において、ウィンドウ・バーチャライゼーションとは、ある時点で見えている領域のデータのみをDOMに保持する技術です。すべてのデータをロードするとメモリが圧迫され処理速度が劇的に低下するため、この手法では画面上に表示されている部分のみを動的にレンダリングし、スクロールに応じて新しい要素を入れ替えます。これはデータの上に動く「窓」があるようなもので、ブラウザが画面外のコンテンツで重くなるのを防ぎます。
これを実現するために、私たちはdiffビューにTanStack Virtualを導入し、常にDOM内にはdiffリストの表示部分のみが存在するようにしました。その効果は大きく、p95+のプルリクエストにおいてJavaScriptヒープの使用量とDOMノード数が10分の1に減少しました。また、インタラクティブ・ネス・パーセンタイル(INP: Interaction to Next Paint)は、これらの大きなプルリクエストにおいて275〜700ミリ秒(ms)から40〜80msまで低下しました。必要なものだけを表示することで、体験は大幅に高速化されました。
さらなるパフォーマンス最適化
パフォーマンスをさらに向上させるため、スタック全体にわたる複数の主要な領域に取り組み、速度とレスポンス性において意味のある成果を上げました。不要なReactの再レンダリングを削減し、状態管理(state management)を最適化することに注力することで、無駄な計算を減らし、UIの更新を大幅に高速化し、インタラクションを滑らかにしました。
スタイリング面では、重いCSSセレクター(例::has(...))を置き換え、GPUトランスフォーム(GPU transforms)を用いてドラッグおよびリサイズ処理を再設計しました。これにより、強制レイアウト(forced layouts)と遅延が排除され、複雑な操作に対してユーザーはシャープで効率的なインターフェースを利用できるようになりました。
また、インタラクションレベルのINP(Interaction to Next Paint)追跡、差分サイズ(segmentation)によるセグメンテーション、メモリタグ付け(memory tagging)を導入し、Datadogダッシュボードで可視化しました。これにより、開発者はボトルネックが問題になる前に特定し、解消するためのリアルタイムで実行可能なメトリクスを継続的に得ています。
サーバーサイドでは、表示される差分行(diff lines)のみをハイドレート(hydrate)するようにレンダリングを最適化しました。これによりインタラクティブになるまでの時間(time-to-interactive)が短縮され、メモリ使用量が抑制されました。その結果、巨大なプルリクエスト(pull request)であっても、読み込み時に高速かつレスポンシブに感じられるようになりました。
最後に、プログレッシブな差分読み込み(progressive diff loading)とスマートなバックグラウンドフェッチ(smart background fetches)により、ユーザーはコンテンツをより早く表示し、操作できるようになりました。もはや、大量の差分が読み込み完了するまで待つ必要はありません。
これら一連の targeted な最適化により、私たちのUIはより軽量で高速になり、ユーザーがどのような要求を投げかけても対応できる準備が整いました。
間違いなく改善:ストリーラインドなパフォーマンスの力
この、diff line アーキテクチャの簡素化に向けたエキサイティングな旅は、パフォーマンス、効率性、保守性の大幅な向上をもたらしました。不要な DOM ノードを削減し、React コンポーネント ツリーを単純化し、複雑な状態管理を条件付きでレンダリングされる子コンポーネントへ移動させることで、より高速なレンダリング時間と低いメモリ消費量を実現しました。O(1) のデータアクセスパターンを採用し、状態管理に関する厳格なルールを導入したことで、パフォーマンスがさらに最適化されました。これにより、UI の応答性(INP の高速化!)が向上し、推論も容易になりました。
これらの測定可能な成果は、大規模で成熟したコードベース内でのターゲットを絞ったリファクタリングでも、すべてのユーザーに意味のある恩恵をもたらすことができること、そして時には小さくシンプルな改善に焦点を当てることが最大のインパクトを生む可能性があることを示しています。パフォーマンスの向上を実際にご覧いただくには、オープンなプルリクエストをご確認ください。
「The uphill climb of making diff lines performant」という記事は、最初に GitHub ブログ に掲載されました。
原文を表示
Pull requests are the beating heart of GitHub. As engineers, this is where we spend a good portion of our time. And at GitHub’s scale—where pull requests can range from tiny one-line fixes to changes spanning thousands of files and millions of lines—the pull request review experience has to stay fast and responsive.
We recently shipped the new React-based experience for the Files changed tab (now the default experience for all users). One of our main goals was to ensure a more performant experience across the board, especially for large pull requests. That meant investing in, and consistently prioritizing, the hard problems like optimized rendering, interaction latency, and memory consumption.
For most users before optimization, the experience was fast and responsive. But when viewing large pull requests, performance would noticeably decline. For example, we observed that in extreme cases, the JavaScript heap could exceed 1 GB, DOM node counts surpassed 400,000, and page interactions became extremely sluggish or even unusable. Interaction to Next Paint (INP) scores (a key metric in determining responsiveness) were above acceptable levels, resulting in an experience where users could quantifiably feel the input lag.
Our recent improvements to the Files changed tab have meaningfully improved some of these core performance metrics. While we covered several of these changes briefly in a recent changelog, we’re going to cover them in more detail here. Read on for why they mattered, what we measured, and how those updates improved responsiveness and memory pressure across the board and especially in large pull requests.
Performance improvements by pull request size and complexity
As we started to investigate and plan our next steps for improving these performance issues, it became clear early on that there wouldn’t be one silver bullet. Techniques that preserve every feature and browser-native behavior can still hit a ceiling at the extreme end. Meanwhile, mitigations designed to keep the worst-case from tipping over can be the wrong tradeoff for everyday reviews.
Instead of looking for a single solution, we began developing a set of strategies. We selected multiple targeted approaches, each designed to address a specific pull request size and complexity.
Those strategies focused on the following themes:
Focused optimizations for diff-line components. Make the primary diff experience efficient for most pull requests. Medium and large reviews stay fast without sacrificing expected behavior, like native find-in-page.
Gracefully degrade with virtualization. Keep the experience usable for the largest pull requests. Prioritize responsiveness and stability by limiting what is rendered at any moment.
Invest in foundational components and rendering improvements. These compound across every pull request size, regardless of which mode a user ends up in.
With these strategies in mind, let’s explore the specific steps we took to address these challenges and how our initial iterations set the stage for the improvements that followed.
First steps: Optimizing diff lines
With our team’s goal of improving pull request performance, we had three main objectives:
Reduce memory and JavaScript heap size.
Reduce the DOM node count.
Reduce our average INP and significantly improve our p95 and p99 measurements
To hit these goals, we focused on simplification: less state, fewer elements, less JavaScript, and fewer React components. Before we look at the results and new architecture, let’s take a step back and look at where we started.
What worked and what didn’t with v1
In v1, each diff line was expensive to render. In unified view, a single line required roughly 10 DOM elements; in split view, closer to 15. That’s before syntax highlighting, which adds many more <span> tags and drives the DOM count even higher.
The following is a simplified visual of the React Component structure mixed with the DOM tree elements for v1 diffs.
At the React layer, unified diffs typically contain at least eight components per line, while the split view contain a minimum of 13. And these numbers represent baseline counts; extra UI states like comments, hover, and focus could add more components on top.
This approach made sense to us in v1, when we first ported the diff lines to React from our classic Rails view. Our original plan centered around lots of small reusable React components and maintaining DOM tree structure.
But we also ended up attaching a lot of React event handlers in our small components, often five to six per component. On a small scale, that was fine, but on a large scale that compounded quickly. A single diff line could carry 20+ event handlers multiplied across thousands of lines.
Beyond performance impact, it also increased complexity for developers. This is a familiar scenario where you implement an initial design, only to discover later its limitations when faced with the demands of unbounded data.
To summarize, for every v1 diff line there would be:
Minimum of 10-15 DOM tree elements
Minimum of 8-13 React Components
Minimum of 20 React Event Handlers
Lots of small re-usable React Components
This v1 strategy proved unsustainable for our largest pull requests, as we consistently observed that larger pull request sizes directly led to slower INP and increased JavaScript heap usage. We needed to determine the best path for improving this setup.
Small changes make a large impact: v2
No change is too small when it comes to performance, especially at scale. For example, we removed unnecessary <code> tags from our line number cells. While dropping two DOM nodes per diff line might appear minor, across 10,000 lines, that’s 20,000 fewer nodes in the DOM. These kinds of targeted, incremental optimizations, no matter how small, compound to create a much faster and more efficient experience. By not overlooking these details, we ensured that every opportunity for improvement was captured, amplifying the overall impact on our largest pull requests.
Refer to the images below to see how v1 looks compared to v2.
This becomes clearer if we look at the component structure behind this HTML:
We went from eight components per diff line to two. Most of the v1 components were thin wrappers that let us share code between Split and Unified views. But that abstraction had a cost: each wrapper carried logic for both views, even though only one rendered at a time. In v2, we gave each view its own dedicated component. Some code is duplicated, but the result is simpler and faster.
Simplifying the component tree
For v2, we removed deeply nested component trees, opting for dedicated components for each split and unified diff line. While this led to some code duplication, it simplified data access and reduced complexity.
Event handling is now managed by a single top-level handler using data-attribute values. So, for instance, when you click and drag to select multiple diff lines, the handler checks each event’s data-attribute to determine which lines to highlight, instead of each line having its own mouse enter function. This approach streamlines both code and improves performance.
Moving complex state to conditionally rendered child components
The most impactful change from v1 to v2 was moving app state for commenting and context menus into their respective components. Given GitHub’s scale, where some pull requests exceed thousands of lines of code, it isn’t practical for every line to carry complex commenting state when only a small subset of lines will ever have comments or menus open. By moving the commenting state into the nested components for each diff line, we ensured that the diff-line component’s main responsibility is just rendering code—aligning more closely with the Single Responsibility Principle.
O(1) data access and less “useEffect” hooks
In v1, we gradually accumulated a lot of O(n) lookups across shared data stores and component state. We also introduced extra re-rendering through useEffect hooks scattered throughout the diff-line component tree.
To address this in v2, we adopted a two-part strategy. First, we restricted useEffect usage strictly to the top level of diff files. We also established linting rules to prevent the introduction of useEffect hooks in line-wrapping React components. This approach enables accurate memoization of diff line components and ensures reliable, predictable behavior.
Next, we redesigned our global and diff state machines to utilize O(1) constant time lookups by employing JavaScript Map. This let us build fast, consistent selectors for common operations throughout our codebase, such as line selection and comment management. These changes have enhanced code quality, improved performance, and reduced complexity by maintaining flattened, mapped data structures.
Now, any given diff line simply checks a map by passing the file path and the line number to determine whether or not there are comments on that line. An access might look like: commentsMap[‘path/to/file.tsx’][‘L8’]
Did it work?
Definitely. The page runs faster than it ever did, and JavaScript heap and INP numbers are massively reduced. For a numeric look, check out the results below. These metrics were evaluated on a pull request using a split diff setting with 10,000 line changes in the diff comparison.
Metricv2Improvement
Total lines of code 2,000 27% less
Total unique omponent types 10 47% fewer
Total components rendered ~50,004 74% fewer
Total DOM nodes ~180,000 10% fewer
Total memory usage ~80-120 MB ~50% less
INP on a large pull request using m1 MacBook pro with 4x slowdown: ~100 ms ~78% faster
As you can see, this effort had a massive impact, but the improvements didn’t end there.
Virtualization for our largest pull requests
When you’re working with massive pull requests—p95+ (those with over 10,000 diff lines and surrounding context lines)—the usual performance tricks just don’t cut it. Even the most efficient components will struggle if we try to render tens of thousands of them at once. That’s where window virtualization steps in.
In front-end development, window virtualization is a technique that keeps only the visible portion of a large list or dataset in the DOM at any given time. Instead of loading everything (which would crush memory and slow things to a crawl), it dynamically renders just what you see on screen, and swaps in new elements as you scroll. This approach is like having a moving “window” over your data, so your browser isn’t bogged down by off-screen content.
To make this happen, we integrated TanStack Virtual into our diff view, ensuring that only the visible portion of the diff list is present in the DOM at any time. The impact was huge: we saw a 10X reduction in JavaScript heap usage and DOM nodes for p95+ pull requests. INP fell from 275–700+ milliseconds (ms) to just 40–80 ms for those big pull requests. By only showing what’s needed, the experience is much faster.
Further performance optimizations
To push performance even further, we tackled several major areas across our stack, each delivering meaningful wins for speed and responsiveness. By focusing on trimming unnecessary React re-renders and honing our state management, we cut down wasted computation, making UI updates noticeably faster and interactions smoother.
On the styling front, we swapped out heavy CSS selectors (e.g. :has(...)) and re-engineered drag and resize handling with GPU transforms, eliminating forced layouts and sluggishness and giving users a crisp, efficient interface for complex actions.
We also stepped up our monitoring game with interaction-level INP tracking, diff-size segmentation, and memory tagging, all surfaced in a Datadog dashboard. This continues to give our developers real-time, actionable metrics to spot and squash bottlenecks before they become issues.
On the server side, we optimized rendering to hydrate only visible diff lines. This slashed our time-to-interactive and keeps memory usage in check, ensuring that even huge pull requests feel fast and responsive on load.
Finally, with progressive diff loading and smart background fetches, users are now able to see and interact with content sooner. No more waiting for a massive number of diffs to finish loading.
All together, these targeted optimizations made our UI feel lighter, faster, and ready for anything our users throw at it.
Diff-initely better: The power of streamlined performance
This exciting journey to streamline the diff line architecture yielded substantial improvements in performance, efficiency and maintainability. By reducing unnecessary DOM nodes, simplifying our React component tree, and relocating complex state to conditionally rendered child components, we achieved faster rendering times and lower memory consumption. The adoption of more O(1) data access patterns and stricter rules for state management further optimized performance. This made our UI more responsive (faster INP!) and easier to reason with.
These measurable gains demonstrate that targeted refactoring, even within our large and mature codebase, can deliver meaningful benefits to all users—and that sometimes focusing on small, simple improvements can have the largest impact. To see the performance gains in action, go check out your open pull requests.
The post The uphill climb of making diff lines performant appeared first on The GitHub Blog.
関連記事
表示速度を飛躍的に向上させるHTML/CSS仕様「content-visibility」「Lazy loading」「contain」をコード付き簡単解説
岡部和氏が、ウェブページの表示速度を向上させるHTML/CSS仕様「content-visibility」「Lazy loading」「contain」をコード付きで解説している。
プレゼンテーション:スケールにおける速度:最大級のCXプラットフォームを最適化する
Matheus Albuquerqueが、React 15とWebpack 1から最新標準への移行を含む大規模CXプラットフォームの最適化戦略を共有し、ASTベースのコードモッドによる大規模移行、モジュール/ノンモジュールを用いた差分配信、Preactによるフットプリント縮小について説明している。
CVE-2026-23869の概要
React Server Componentsの深刻な脆弱性(CVSS 7.5)がサービス拒否を引き起こす可能性がある。VercelはWAFに新ルールを導入したが、パッチ適用版への即時アップグレードが必要。