Nova Forge SDKを使用したNovaカスタマイズ実験の開始
AWSはNova Forge SDKを発表し、Amazon Novaモデルのカスタマイズを簡素化し、SageMaker AI Training Jobsを活用した教師ありファインチューニングと強化学習ファインチューニングの実装プロセスをStack Overflow質問分類のケーススタディで実証した。
キーポイント
Nova Forge SDKによるLLMカスタマイズの簡素化
従来複雑だった大規模言語モデルのカスタマイズを、依存関係管理やインフラ設定の課題を解消し、チームが容易に活用できるようにするSDKを提供。
Amazon SageMakerを活用した実践的カスタマイズプロセス
Amazon NovaモデルをSageMaker AI Training Jobsでトレーニングし、教師ありファインチューニングと強化学習ファインチューニングを段階的に適用して性能向上を実証。
Stack Overflow質問分類の実世界ケーススタディ
60,000件の質問データセットを用いて、高品質投稿、編集が必要な低品質投稿、閉鎖すべき投稿の3カテゴリへの自動分類システムを構築する実用例を示した。
カスタマイズの継続的評価とデプロイメント
各ファインチューニング段階後にモデル性能を評価し、最終的にカスタマイズされたモデルをAmazon SageMaker AI Inferenceエンドポイントにデプロイする完全なワークフローを提供。
影響分析・編集コメントを表示
影響分析
この記事はAWSのNovaモデルエコシステムの実用化を加速するツールの提供を示しており、企業が独自データでLLMをカスタマイズする際の参入障壁を下げる可能性がある。特に実践的なケーススタディを通じて、技術的な概念だけでなく実際のビジネス応用への道筋を示している点が特徴的である。
編集コメント
AWSの自社ブログによる製品紹介記事であり、営業PR色が強いが、具体的な技術実装プロセスと実世界ケーススタディを詳細に示している点で実用的な参考情報となっている。
Nova には幅広いカスタマイズ機能がありますが、従来、カスタマイズへの取り組みやプラットフォーム間の移行は、技術的専門知識、インフラストラクチャのセットアップ、多大な時間投資を必要とする複雑なプロセスでした。この可能性と実用性の間の隔たりこそ、私たちが解決を目指した課題です。Nova Forge SDK は大規模言語モデル (LLM) のカスタマイズを容易にし、依存関係の管理、イメージの選択、レシピの設定といった課題を気にすることなく、チームが言語モデルの可能性を最大限に引き出せるようにします。私たちはカスタマイゼーションをスケーリングの連続体の中にあるものと捉えているため、Nova Forge SDK は Amazon SageMaker AI に基づく適応から Amazon Nova Forge の機能を活用した高度なカスタマイゼーションまで、あらゆるカスタマイズオプションをサポートしています。
前回の投稿では、Nova Forge SDK と、その前提条件、セットアップ手順を含む始め方を紹介しました。この投稿では、Amazon SageMaker AI トレーニングジョブを使用して Amazon Nova モデルをトレーニングするために Nova Forge SDK を使用するプロセスを説明します。Stack Overflow データセットでモデルのベースラインパフォーマンスを評価し、教師ありファインチューニング (SFT) を使用してそのパフォーマンスを改善し、その後、カスタマイズされたモデルに強化学習ファインチューニング (RFT) を適用して応答品質をさらに向上させます。各タイプのファインチューニング後、カスタマイゼーションプロセス全体での改善を示すためにモデルを評価します。最後に、カスタマイズされたモデルを Amazon SageMaker AI 推論エンドポイントにデプロイします。
次に、Stack Overflow の質問を 3 つの明確なカテゴリ (HQ、LQ EDIT、LQ CLOSE) に自動分類する現実のシナリオを通じて、Nova Forge SDK の利点を理解しましょう。
ケーススタディ: 与えられた質問を正しいクラスに分類する
Stack Overflow には数千の質問があり、その品質は大きく異なります。質問の品質を自動的に分類することで、モデレーターは取り組みを優先順位付けし、ユーザーが投稿を改善するよう導くことができます。このソリューションは、Amazon Nova Forge SDK を使用して、高品質の投稿、編集が必要な低品質の投稿、閉じられるべき投稿を区別できる自動品質分類器を構築する方法を示しています。2016年から2020年までの 60,000 件の質問を含む Stack Overflow Question Quality データセットを使用し、3つのカテゴリに分類されています:
HQ(高品質): 編集なしでよく書かれた投稿LQ_EDIT(低品質 - 編集済み): ネガティブスコアと複数のコミュニティ編集があるが、開いたままの投稿LQ_CLOSE(低品質 - 閉鎖済み): コミュニティによって編集なしで閉鎖された投稿
私たちの実験では、4700 件の質問をランダムにサンプリングし、以下のように分割しました:
| 分割 | サンプル数 | 割合 | 目的 |
|---|---|---|---|
| トレーニング (SFT) | 3,500 | ~75% | 教師ありファインチューニング |
| 評価 | 500 | ~10% | ベースラインおよびトレーニング後評価 |
| RFT | 700 + (SFTからの3,500) | ~15% | 強化学習ファインチューニング |
RFT では、強化学習シグナルから学習しながら教師あり能力の破滅的忘却 (catastrophic forgetting) を防ぐために、700 件の RFT 固有サンプルにすべての 3,500 件の SFT サンプルを追加しました (合計: 4,200 サンプル)。
実験は 4 つの主要段階で構成されます:ベースライン評価で箱出しのパフォーマンスを測定し、教師ありファインチューニング (SFT) でドメイン固有のパターンを教え、SFT チェックポイントに対して強化学習ファインチューニング (RFT) を適用して特定の品質指標を最適化し、最後に Amazon SageMaker AI にデプロイします。ファインチューニングでは、各段階が前の段階を基盤とし、各ステップで測定可能な改善が見られます。
すべてのデータセットに共通のシステムプロンプトを使用しました:
`これは2016年から2020年までの Stack Overflow の質問であり、3つのカテゴリに分類できます:
- HQ: 編集なしの高品質投稿。
- LQ_EDIT: ネガティブスコアと複数のコミュニティ編集がある低品質投稿。ただし、それらの変更後も開いたままです。
- LQ_CLOSE: コミュニティによって編集なしで閉鎖された低品質投稿。
あなたは技術アシスタントであり、ユーザーからの質問を上記3つのカテゴリのいずれかに分類します。カテゴリ名のみで応答してください:HQ、LQ_EDIT、または LQ_CLOSE。
説明を追加せず、カテゴリのみを出力として与えてください。`
ステージ 1: ベースラインパフォーマンスの確立
ファインチューニング前に、事前トレーニング済みの Nova 2.0 モデルを評価セットで評価することでベースラインを確立します。これにより、将来の改善を測定するための具体的なベースラインが得られます。ベースライン評価は、モデルの箱出しの能力を理解し、パフォーマンスギャップを特定し、測定可能な改善目標を設定し、ファインチューニングが必要であることを検証するために重要です。
SDK のインストール
簡単な pip コマンドで SDK をインストールできます:
pip install amzn-nova-forge主要モジュールをインポートします:
from amzn_nova_forge import (
NovaModelCustomizer,
SMTJRuntimeManager,
TrainingMethod,
EvaluationTask,
CSVDatasetLoader,
Model,
)評価データの準備
Amazon Nova Forge SDK は、検証と変換を自動的に処理する強力なデータローディングユーティリティを提供します。評価データセットをロードし、Nova モデルが期待する形式に変換することから始めます:
CSVDatasetLoader クラスは、データ検証と形式変換の重い作業を処理します。query パラメータは入力テキスト (Stack Overflow の質問) にマッピングされ、response は正解ラベルにマッピングされ、system はモデルの動作を導く分類指示を含みます。
# 一般的な設定
MODEL = Model.NOVA_LITE_2
INSTANCE_TYPE = 'ml.p5.48xlarge'
EXECUTION_ROLE = '<YOUR_EXECUTION_ROLE_ARN>'
TRAIN_INSTANCE_COUNT = 4
EVAL_INSTANCE_COUNT = 1
S3_BUCKET = '<YOUR_S3_BUCKET>'
S3_PREFIX = 'stack-overflow'
EVAL_DATA = './eval.csv'
# データのロード
# 注: 'query' は質問に、'response' は分類ラベルにマッピング
loader = CSVDatasetLoader(
query='Body', # 質問テキスト列
response='Y', # 分類ラベル列 (HQ、LQ_EDIT、LQ_CLOSE)
system='system' # システムプロンプト列
)
loader.load(EVAL_DATA)次に、CSVDatasetLoader を使用して生データを Nova モデル評価に期待される形式に変換します:
# Nova 形式に変換loader.load('sft.csv')
loader.transform(method=TrainingMethod.SFT_LORA, model=Model.NOVA_LITE_2)
loader.show(n=3)
この変換後、データセットの各行は、次の画像に示すように、Converse API 形式で構成されます。
{
"system": [
{"text": "<system prompt>"}
],
"messages": [
{
"role": "user",
"content": [
{"text": "<input data>"}
]
},
{
"role": "assistant",
"content": [
{"text": "<output data>"}
]
}
]
}
また、データセットを検証して、トレーニングに必要な形式に適合していることを確認します。
loader.validate(method=TrainingMethod.SFT_LORA, model=Model.NOVA_LITE_2)
データが適切に整形され、正しい形式になったので、トレーニングデータ、検証データ、テストデータに分割し、トレーニングジョブが参照できるように 3 つすべてを Amazon S3 にアップロードできます。
Save to S3
train_path = loader.save_data(f"s3://{S3_BUCKET}/{S3_PREFIX}/data/train.jsonl")
教師ありファインチューニングジョブの開始
データを準備して Amazon S3 にアップロードしたので、教師ありファインチューニング (SFT) ジョブを開始します。
Nova Forge SDK は、トレーニングのインフラストラクチャ (Amazon SageMaker Training Jobs または Amazon SageMaker Hyperpod) の指定を支援することでプロセスを効率化します。また、必要なインスタンスをプロビジョニングし、トレーニングジョブの起動を容易にし、レシピ構成や API 形式について心配する必要をなくします。
SFT トレーニングでは、引き続き Amazon SageMaker Training Jobs を、4 つの ml.p5.48xlarge インスタンスで使用します。SDK は、トレーニングジョブを開始しようとする際に、選択したモデルに対してサポートされている値に対して環境とインスタンス構成を検証し、ジョブが送信された後にエラーが発生するのを防ぎます。
runtime = SMTJRuntimeManager(
insta
原文を表示
With a wide array of Nova customization offerings, the journey to customization and transitioning between platforms has traditionally been intricate, necessitating technical expertise, infrastructure setup, and considerable time investment. This disconnect between potential and practical applications is precisely what we aimed to address. Nova Forge SDK makes large language model (LLM) customization accessible, empowering teams to harness the full potential of language models without the challenges of dependency management, image selection, and recipe configuration. We view customization as a continuum within the scaling ladder, therefore, the Nova Forge SDK supports all customization options, ranging from adaptations based on Amazon SageMaker AI to deep customization using Amazon Nova Forge capabilities.
In the last post, we introduced the Nova Forge SDK and how to get started with it along with the prerequisites and setup instructions. In this post, we walk you through the process of using the Nova Forge SDK to train an Amazon Nova model using Amazon SageMaker AI Training Jobs. We evaluate our model’s baseline performance on a StackOverFlow dataset, use Supervised Fine-Tuning (SFT) to refine its performance, and then apply Reinforcement Fine Tuning (RFT) on the customized model to further improve response quality. After each type of fine-tuning, we evaluate the model to show its improvement across the customization process. Finally, we deploy the customized model to an Amazon SageMaker AI Inference endpoint.
Next, let’s understand the benefits of Nova Forge SDK by going through a real-world scenario of automatic classification of Stack Overflow questions into three well-defined categories (HQ, LQ EDIT, LQ CLOSE).
Case study: classify the given question into the correct class
Stack Overflow has thousands of questions, varying greatly in quality. Automatically classifying question quality helps moderators prioritize their efforts and guide users to improve their posts. This solution demonstrates how to use the Amazon Nova Forge SDK to build an automated quality classifier that can distinguish between high-quality posts, low-quality posts requiring edits, and posts that should be closed. We use the Stack Overflow Question Quality dataset containing 60,000 questions from 2016-2020, classified into three categories:
- HQ (High Quality): Well-written posts without edits
- LQ_EDIT (Low Quality – Edited): Posts with negative scores and multiple community edits, but remain open
- LQ_CLOSE (Low Quality – Closed): Posts closed by the community without edits
For our experiments, we randomly sampled 4700 questions and split them as follows:
Split
Samples
Percentage
Purpose
Training (SFT)
3,500
~75%
Supervised fine-tuning
Evaluation
500
~10%
Baseline and post-training evaluation
RFT
700 + (3,500 from SFT)
~15%
Reinforcement fine-tuning
For RFT, we augmented the 700 RFT-specific samples with all 3,500 SFT samples (total: 4,200 samples) to prevent catastrophic forgetting of supervised capabilities while learning from reinforcement signals.
The experiment consists of four main stages: baseline evaluation to measure out-of-the-box performance, supervised fine-tuning (SFT) to teach domain-specific patterns, and reinforcement fine-tuning (RFT) on SFT checkpoint to optimize for specific quality metrics and finally deployment to Amazon SageMaker AI. For fine-tuning, each stage builds upon the previous one, with measurable improvements at every step.
We used a common system prompt for all the datasets:
`*This is a stack overflow question from 2016-2020 and it can be classified into three categories:
- HQ: High-quality posts without a single edit.
- LQ_EDIT: Low-quality posts with a negative score, and multiple community edits. However, they remain open after those changes.
- LQ_CLOSE: Low-quality posts that were closed by the community without a single edit.
You are a technical assistant who will classify the question from users into any of above three categories. Respond with only the category name: HQ, LQ_EDIT, or LQ_CLOSE.
Do not add any explanation, just give the category as output.*`
Stage 1: Establish baseline performance
Before fine-tuning, we establish a baseline by evaluating the pre-trained Nova 2.0 model on our evaluation set. This gives us a concrete baseline for measuring future improvements. Baseline evaluation is critical because it helps you understand the model’s out-of-the-box capabilities, identify performance gaps, set measurable improvement goals, and validate that fine-tuning is necessary.
Install the SDK
You can install the SDK with a simple pip command:
pip install amzn-nova-forge Import the key modules:
rom amzn_nova_forge import (
NovaModelCustomizer,
SMTJRuntimeManager,
TrainingMethod,
EvaluationTask,
CSVDatasetLoader,
Model,
)Prepare evaluation data
The Amazon Nova Forge SDK provides powerful data loading utilities that handle validation and transformation automatically. We begin by loading our evaluation dataset and transforming it to the format expected by Nova models:
The CSVDatasetLoader class handles the heavy lifting of data validation and format conversion. The query parameter maps to your input text (the Stack Overflow question), response maps to the ground truth label, and system contains the classification instructions that guide the model’s behavior.
# General Configuration
MODEL = Model.NOVA_LITE_2
INSTANCE_TYPE = 'ml.p5.48xlarge'
EXECUTION_ROLE = ''
TRAIN_INSTANCE_COUNT = 4
EVAL_INSTANCE_COUNT = 1
S3_BUCKET = ''
S3_PREFIX = 'stack-overflow'
EVAL_DATA = './eval.csv'
# Load data
# Note: 'query' maps to the question, 'response' to the classification label
loader = CSVDatasetLoader(
query='Body', # Question text column
response='Y', # Classification label column (HQ, LQ_EDIT, LQ_CLOSE)
system='system' # System prompt column
)
loader.load(EVAL_DATA)
Next, we use the CSVDatasetLoader to transform your raw data into the expected format for Nova model evaluation:
# Transform to Nova format
loader.transform(method=TrainingMethod.EVALUATION, model=MODEL)
loader.show(n=3)
The transformed data will have the following format:
{
"query": "",
"response": "",
"system": ""
}
Before uploading to Amazon Simple Storage Service (Amazon S3), validate the transformed data by running the loader.validate() method. This helps you to catch any formatting issues early, rather than waiting until they interrupt the actual evaluation.
# Validate data format
loader.validate(method=TrainingMethod.EVALUATION, model=MODEL)
Finally, we can save the dataset to Amazon S3 using the loader.save_data() method, so that it can be used by the evaluation job.
# Save to S3
eval_s3_uri = loader.save_data(
f"s3://{S3_BUCKET}/{S3_PREFIX}/data/eval.jsonl"
)
Run baseline evaluation
With our data prepared, we initialize our SMTJRuntimeManager to configure the runtime infrastructure. We then initialize a NovaModelCustomizer object and call baseline_customizer.evaluate() to launch the baseline evaluation job:
# Configure runtime infrastructure
runtime_manager = SMTJRuntimeManager(
instance_type=INSTANCE_TYPE,
instance_count=EVAL_INSTANCE_COUNT,
execution_role=EXECUTION_ROLE
)
# Create baseline evaluator
baseline_customizer = NovaModelCustomizer(
model=MODEL,
method=TrainingMethod.EVALUATION,
infra=runtime_manager,
data_s3_path=eval_s3_uri,
output_s3_path=f"s3://{S3_BUCKET}/{S3_PREFIX}/baseline-eval"
)
# Run evaluation
# GEN_QA task provides metrics like ROUGE, BLEU, F1, and Exact Match
baseline_result = baseline_customizer.evaluate(
job_name="blogpost-baseline",
eval_task=EvaluationTask.GEN_QA # Use GEN_QA for classification
)
For classification tasks, we use the GEN_QA evaluation task, which treats classification as a generative task where the model generates a class label. The exact_match metric from GEN_QA directly corresponds to classification accuracy, the percentage of predictions that exactly match the ground truth label. The full list of benchmark tasks can be retrieved from the EvaluationTask enum, or seen in the Amazon Nova User Guide.
Understanding the baseline results
After the job completes, results are saved to Amazon S3 at the specified output path. The archive contains per-sample predictions with log probabilities, aggregated metrics across the entire evaluation set, and raw model predictions for detailed analysis.
In the following table, we see the aggregated metrics for all the evaluation samples from the output of the evaluation job (note that BLEU is on a scale of 0-100):
Metric
Score
ROUGE-1
0.1580 (±0.0148)
ROUGE-2
0.0269 (±0.0066)
ROUGE-L
0.1580 (±0.0148)
Exact Match (EM)
0.1300 (±0.0151)
Quasi-EM (QEM)
0.1300 (±0.0151)
F1 Score
0.1380 (±0.0149)
F1 Score (Quasi)
0.1455 (±0.0148)
BLEU
0.4504 (±0.0209)
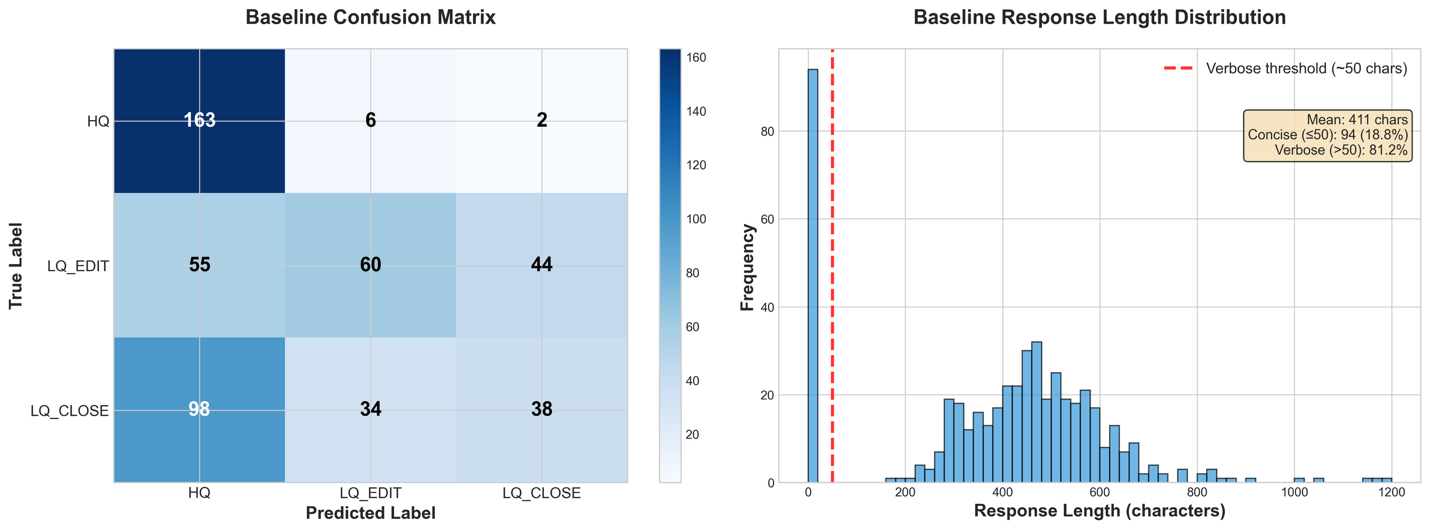
The base model achieves only 13.0% exact-match accuracy on this 3-class classification task, whereas random guessing would yield 33.3%. This clearly demonstrates the need for fine-tuning and establishes a quantitative baseline for measuring improvement.
As we see in the next section, this is largely due to the model ignoring the formatting requirements of the problem, where a verbose response including explanations and analyses is considered invalid. We can derive the format-independent classification accuracy by parsing our three labels from the model’s output text, using the following classification_accuracy utility function.
def classification_accuracy(samples):
"""Extract predicted class via substring match and compute accuracy."""
correct, total, no_pred = 0, 0, 0
for s in samples:
gold = s["gold"].strip().upper()
pred_raw = s["inference"][0] if isinstance(s["inference"], list) else s["inference"]
pred_cat = extract_category(pred_raw)
if pred_cat is None:
no_pred += 1
continue
total += 1
if pred_cat == gold:
correct += 1
acc = correct / total if total else 0
print(f"Classification Accuracy: {correct}/{total} ({acc*100:.1f}%)")
print(f" No valid prediction: {no_pred}/{total + no_pred}")
return acc
print("???? Baseline Classification Accuracy (extracted class labels):")
baseline_accuracy = classification_accuracy(baseline_samples)
However, even with a permissive metric, which ignores verbosity, we get only a 52.2% classification accuracy. This clearly indicates the need for fine-tuning to improve the performance of the base model.
Conduct baseline failure analysis
The following image shows a failure analysis on the baseline. From the response length distribution, we observe that all responses included verbose explanations and reasoning despite the system prompt requesting only the category name. In addition, the baseline confusion matrix compares the true label (y axis) with the generated label (x axis); the LLM has a clear bias towards classifying messages as High Quality regardless of their actual classification.
Given these baseline results of both instruction-following failures and classification bias toward HQ, we now apply Supervised Fine-Tuning (SFT) to help the model understand the task structure and output format, followed by Reinforcement Learning (RL) with a reward function that penalizes the undesirable behaviors.
Stage 2: Supervised fine-tuning
Now that we have completed our baseline and conducted the failure space analysis, we can use Supervised Fine Tuning to improve our performance. For this example, we use a Parameter Efficient Fine-Tuning approach, because it’s a technique that gives us initial signals on models learning capability.
Data preparation for supervised fine-tuning
With the Nova Forge SDK, we can bring our datasets and use the SDKs data preparation helper functions to curate the SFT datasets with in-build data validations.
As before, we use the SDK’s CSVDatasetLoader to load our training CSV data and transform it into the required format:
loader = CSVDatasetLoader(
question='Body', # Stack Overflow question text
answer='Y', # Classification label (HQ, LQ_EDIT, LQ_CLOSE)
system='system' # System prompt column
)
loader.load('sft.csv')
loader.transform(method=TrainingMethod.SFT_LORA, model=Model.NOVA_LITE_2)
loader.show(n=3)
After this transformation, each row of our dataset will be structured in the Converse API format, as shown in the following image:
{
"system": [
{"text": ""}
],
"messages": [
{
"role": "user",
"content": [
{"text": ""}
]
},
{
"role": "assistant",
"content": [
{"text": ""}
]
}
]
}
We also validate the dataset to confirm that it fits the required format for training:
loader.validate(method=TrainingMethod.SFT_LORA, model=Model.NOVA_LITE_2)
Now that we have our data well-formed and in the correct format, we can split it into training, validation, and test data, and upload all three to Amazon S3 for our training jobs to reference.
# Save to S3
train_path = loader.save_data(f"s3://{S3_BUCKET}/{S3_PREFIX}/data/train.jsonl")Start a supervised fine-tuning job
With our data prepared and uploaded to Amazon S3, we initiate the Supervised Fine-tuning (SFT) job.
The Nova Forge SDK streamlines the process by helping us to specify the infrastructure for training, whether it’s Amazon SageMaker Training Jobs or Amazon SageMaker Hyperpod. It also provisions the necessary instances and facilitates the launch of training jobs, removing the need to worry about recipe configurations or API formats.
For our SFT training, we continue to use Amazon SageMaker Training Jobs, with 4 ml.p5.48xlarge instances. The SDK validates your environment and instance configuration against supported values for the chosen model when attempting to start a training job, preventing errors from occurring after the job is submitted.
runtime = SMTJRuntimeManager(
insta
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み