Liquid AI、非トランスフォーマー型「Liquid Foundation Models 2.5」を公開(230M パラメータ)
Liquid AI は、230M パラメータの軽量モデル「LFM2.5-230M」を公開し、エッジデバイスやロボット制御における高速推論とツール使用能力を証明した。
キーポイント
超軽量かつ高性能な新モデル公開
230M パラメータの「LFM2.5-230M」が Hugging Face で利用可能となり、Galaxy S25 Ultra や Raspberry Pi 5 などの低コストハードウェアでも高速推論が可能である。
ロボット制御への実証的適用
Unitree G1 ヒューマノイドロボット上でオンデバイス動作し、自然言語指令を分解して複雑な移動スキルを実行する「スキルの選択層」として機能することが実証された。
洗練された学習プロセス
32K コンテキスト拡張を含む 19T トークンの事前学習に加え、蒸留、直接選好最適化(DPO)、マルチドメイン強化学習の 3 ステージからなる軽量ポストトレーニングを適用している。
LFM2.5 モデルの性能向上
LFM2.5-350M は、前世代の LFM2-350M や競合の Granite モデルと比較して、CaseReportBench や BFCLv4 などの主要ベンチマークで顕著なスコア向上を達成しています。
特定ドメインにおける優位性
特に Telecom(通信)および Retail(小売)分野のベンチマークにおいて、LFM2.5-350M は他モデルを大きく引き離し、専門的なタスクでの強固な能力を示しています。
最適化されたユースケースと非推奨用途
大規模データ抽出や軽量オンデバイスエージェントワークロードに理想的ですが、高度な数学、コード生成、創作ライティングなどの推論重視のタスクには推奨されません。
多様なハードウェアでの高速推論
Raspberry Pi 5 や Snapdragon Gen4 などのエッジデバイスで最小限のメモリフットプリントかつ最高クラスの処理速度を実現し、GPU では SGLang ベンチマークでも低遅延を達成しています。
影響分析・編集コメントを表示
影響分析
このリリースは、大規模モデルへの依存から脱却し、エッジデバイスや自律型ロボットにおける「オンデバイス AI」の実用化を加速させる重要な転換点です。特に、230M という極小パラメータ数で高度な推論と制御を実現したことは、開発者がリソース制約の厳しい環境でも高性能なエージェントワークフローを構築できる道を開く画期的な進展と言えます。
編集コメント
230M という驚異的な小規模モデルで、ヒューマノイドロボットの複雑な制御を可能にした点は、エッジ AI の未来像を示す非常に示唆に富む事例です。
本日、私たちがこれまでで最も小型のモデルである LFM2.5-230M をリリースいたします。これは、開発者がアジェンシーワークフロー(自律型エージェントによる業務処理)において微調整し、展開するための高速かつ軽量な基盤です。LFM2 アーキテクチャをベースに構築されており、クラウド GPU から低コスト CPU まであらゆる環境で動作します。推論速度は非常に速く、Galaxy S25 Ultra では 1 秒あたり 213 トークン(token)、Raspberry Pi 5 では 42 トークンのデコード速度を記録しています。その小型サイズにもかかわらず、ツール使用やデータ抽出タスクにおいては驚くほど高い能力を発揮します。
ベースモデル(LFM2.5-230M-Base)とポストトレーニング済みモデル(LFM2.5-230M)は本日、Hugging Face で利用可能です。ローカル環境での実行や微調整方法については、私たちの ドキュメント をご確認ください。
学習と微調整
本モデルは、32K コンテキスト拡張フェーズを含む 19T トークンで事前トレーニングされました。開発者が独自のダウンストリームアプリケーションを対象とする際の柔軟性を維持するため、軽量なポストトレーニングレシピを適用しています。
このレシピは以下の 3 つのステージから構成されています:(1) LFM2.5-350M からの蒸留を用いた教師あり微調整、(2) 直接選好最適化(Direct Preference Optimization)、(3) マルチドメイン強化学習。最終チェックポイントは、優れた初期状態での能力とダウンストリーム特化への適応性をバランスよく兼ね備えつつ、より大規模なモデルとも競合できる性能を維持しています。
進行中の作業の早期概観として、LFM2.5-230M を Unitree G1 人型ロボットにデプロイし、搭載された NVIDIA Jetson Orin で完全にオンデバイスで実行しました。ここではモデルはスキル選択層として機能し、単一の自然言語指示を入力として受け取り、NVIDIA の SONIC フレームワークが提供する事前学習済み低レベルスキルを呼び出すツール呼び出しのシーケンスに分解します。このタスクのために迅速なファインチューニングを行った後、モデルは以下のような自由形式のコマンドを構造化された多段階計画に変換し、目標速度での歩行や片足膝つきなどのスキルを連鎖させます。
*"2 秒間静止したままにし、その後 1 秒間に 1 メートルの速度で 3 メーター前方へ歩き、5 秒間片足の膝つき姿勢を保ち、0.5 秒間に 0.5 メートルの速度で後方へ 3 メーター歩く"*
この段階では意図的に行動は単純なものにしていますが、これは魅力的なシグナルであると考えます。230M パラメータのモデルを迅速にファインチューニングし、オンデバイスでデプロイすることで、人型ロボットの自然言語制御インターフェースとして機能させることが可能だからです。
https://www.youtube.com/shorts/CuMOWa2y1Ho
ベンチマーク
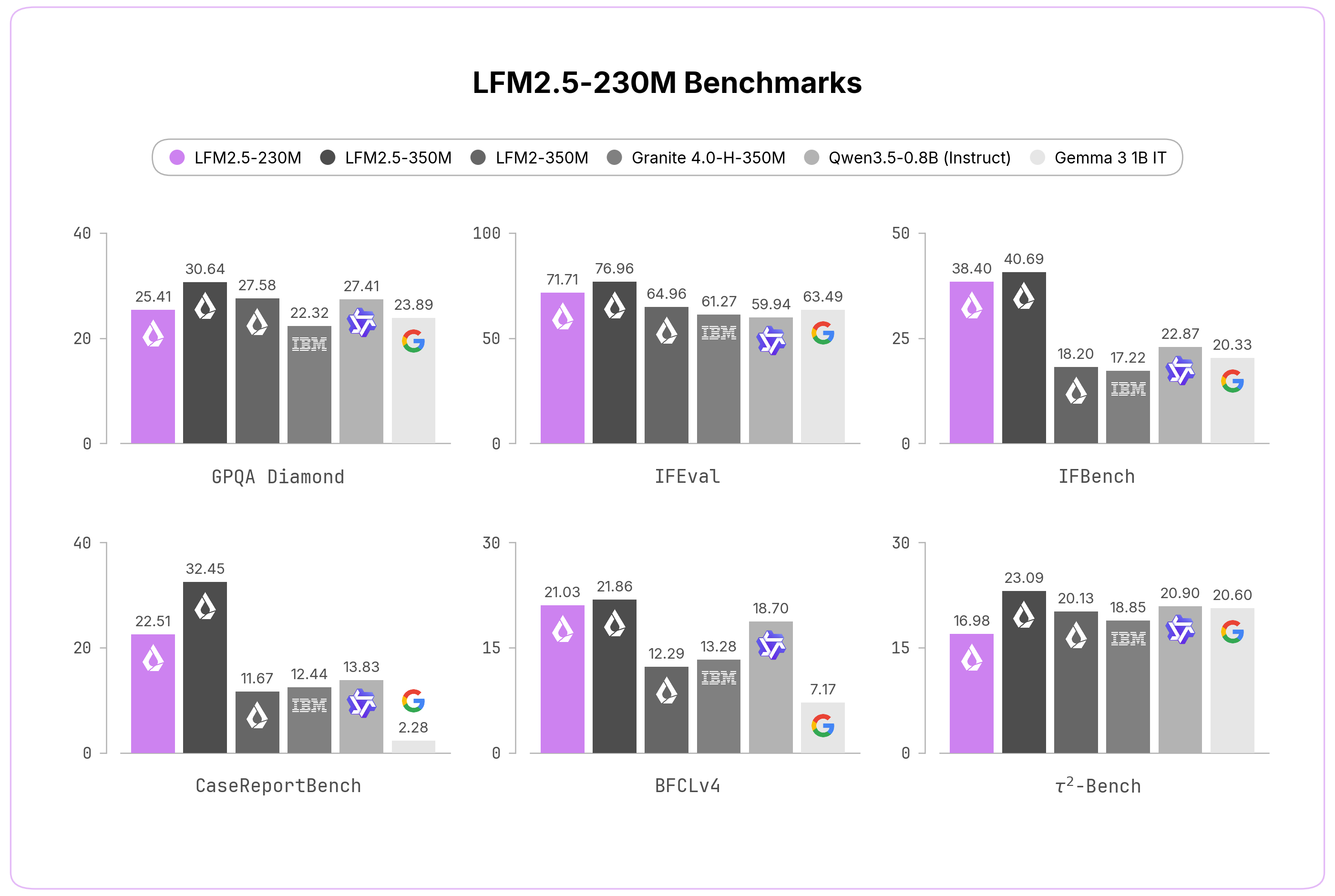
LFM2.5-230M を、コア機能と適用タスクの両方をカバーする 10 のベンチマークで評価しました。その規模にもかかわらず、このモデルは 2 倍以上大きなモデルと競合し、多くの場合それらを上回ります。対象には知識(GPQA Diamond, MMLU-Pro)、指示従順性(IFEval, IFBench, Multi-IF)、データ抽出(CaseReportBench)、ツール使用(BFCLv3, BFCLv4, τ²-Bench Telecom and Retail)が含まれます。
モデル
GPQA Diamond
MMLU-Pro
IFEval
IFBench
Multi-IF
LFM2.5-230M
25.41
20.25
71.71
38.40
37.70
LFM2.5-350M
30.64
20.01
76.96
40.69
44.92
LFM2-350M
27.58
19.29
64.96
18.20
32.92
Granite 4.0-H-350M
22.32
13.14
61.27
17.22
28.70
Granite 4.0-350M
25.91
12.84
53.48
15.98
24.21
Qwen3.5-0.8B (Instruct)
27.41
37.42
59.94
22.87
41.68
Gemma 3 1B IT
23.89
14.04
63.49
20.33
44.25
Model
CaseReportBench
BFCLv3
BFCLv4
𝜏²-Bench Telecom
𝜏²-Bench Retail
LFM2.5-230M
22.51
43.26
21.03
5.26
13.68
LFM2.5-350M
32.45
44.11
21.86
18.86
17.84
LFM2-350M
11.67
22.95
12.29
10.82
5.56
Granite 4.0-H-350M
12.44
43.07
13.28
13.74
6.14
Granite 4.0-350M
0.84
39.58
13.73
2.92
6.14
Qwen3.5-0.8B (Instruct)
13.83
35.08
18.70
12.57
6.14
Gemma 3 1B IT
2.28
16.61
7.17
9.36
6.43
これにより、LFM2.5-230M は大規模なデータ抽出パイプラインや軽量なオンデバイス・エージェントワークロードを駆動するための理想的なソリューションとなります。ただし、そのコンパクトなサイズゆえに、高度な数学、コード生成、あるいは創作ライティングといった推論集約型のワークロードには推奨しません。
どこでも高速推論
LFM2.5-230M は、推論エコシステム全体で初日サポートを提供しています:
- llama.cpp — 効率的なエッジ推論のための GGUF チェックポイント
- MLX — Apple Silicon 向けの最適化された推論
- vLLM — 生産環境のスループットのための GPU アクセラレーションによるサービング
- SGLang — 生産環境のスループットのための GPU アクセラレーションによるサービング
- ONNX — 多様なアクセラレーター間でのクロスプラットフォーム推論
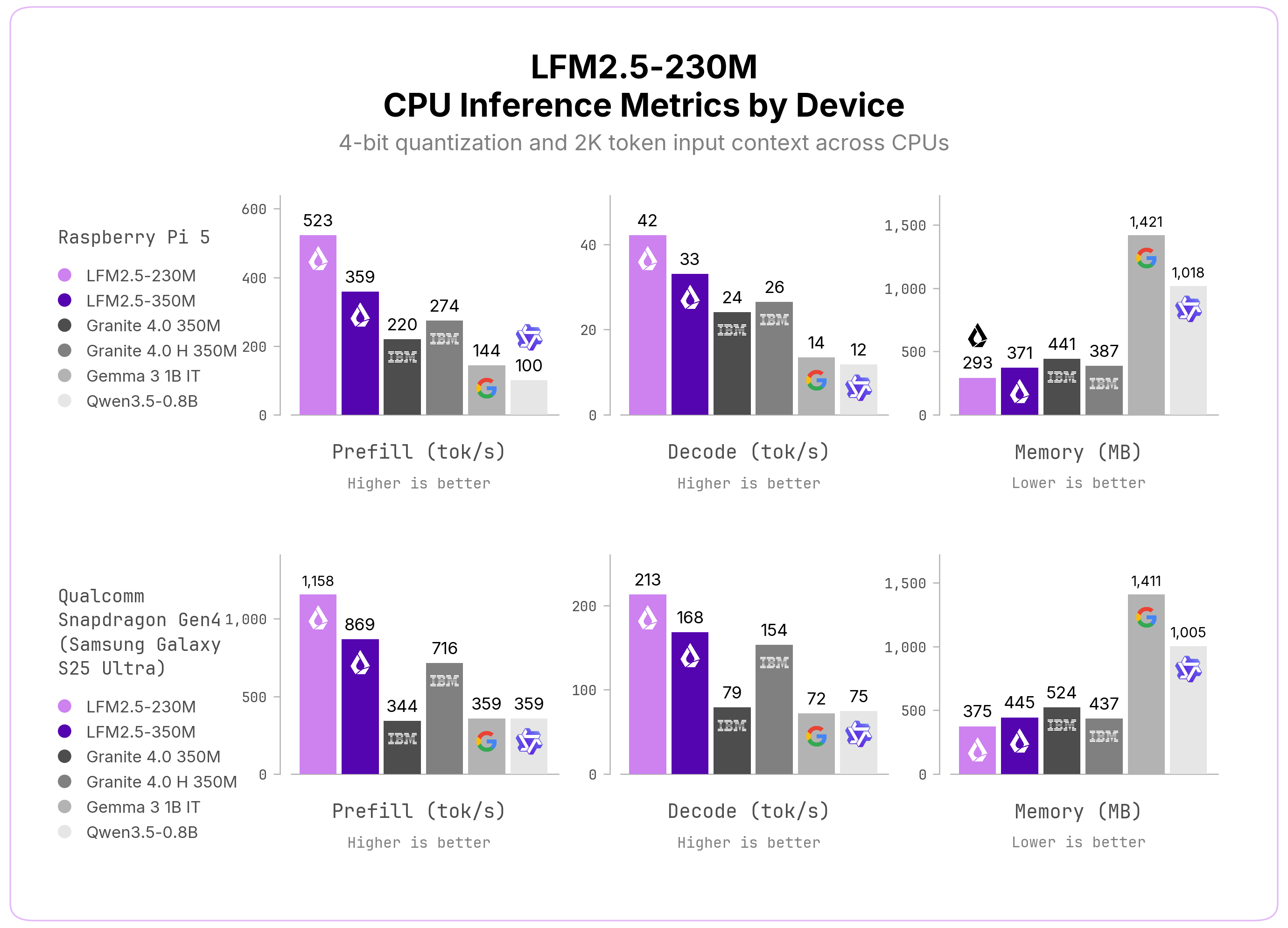
CPU 推論。効率的な LFM2 アーキテクチャのおかげで、LFM2.5-230M は SSM ハイブリッドやゲート型デルタネットワークを含む同サイズのモデルと比較して大幅に高速です。Raspberry Pi 5 および Qualcomm Snapdragon Gen4 (Samsung Galaxy S25 Ultra) の両方で、最小限のメモリフットプリントを維持しながら、クラス最高のプリフィルおよびデコードスループットを実現します。各プラットフォームでのプリフィルを最大化するため、デバイスごとにフラッシュアテンションフラグを調整しています: Raspberry Pi 5 では有効 (-fa 1)、Snapdragon Gen4 では無効 (-fa 0) です。
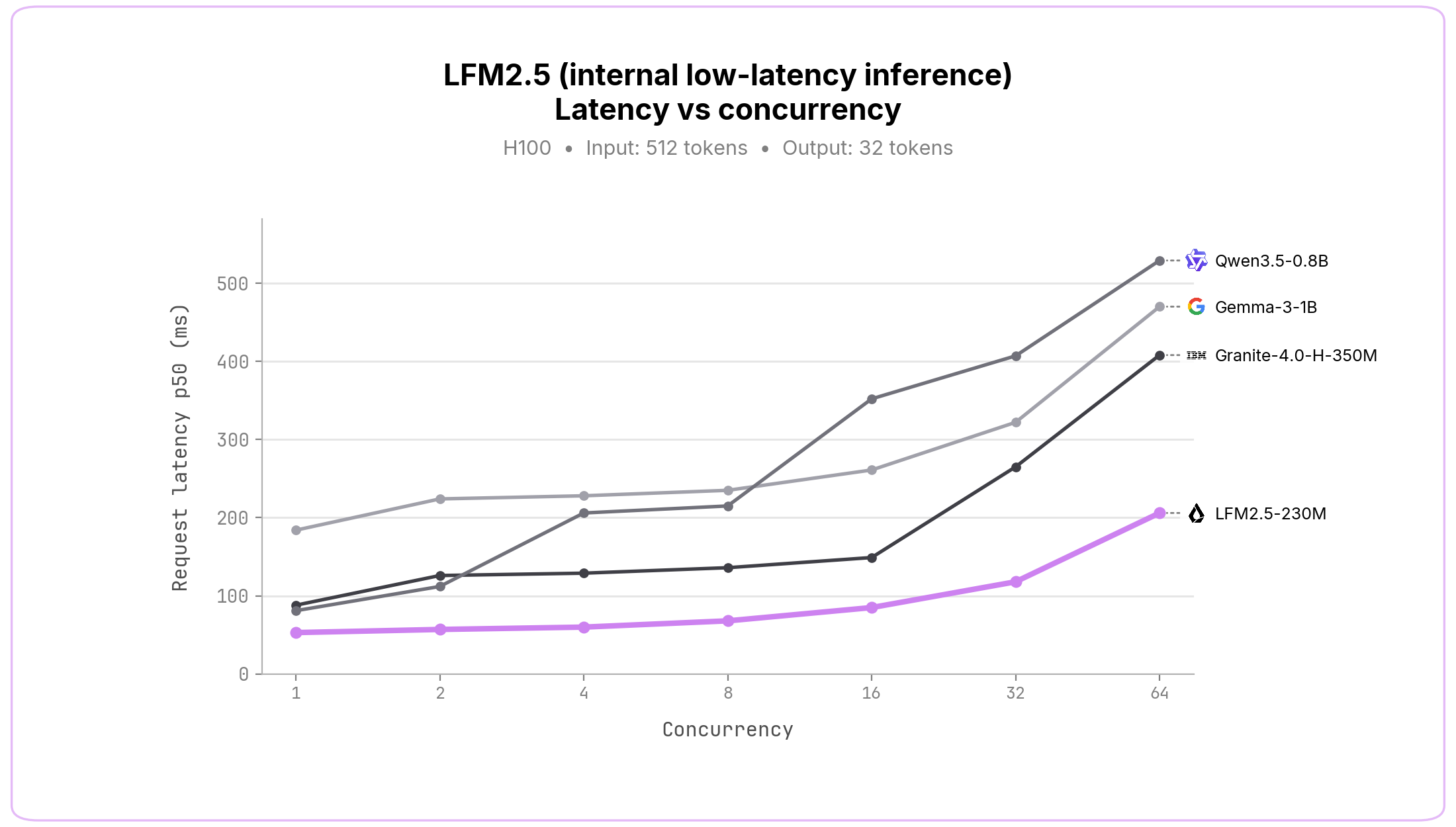
GPU 推論。 本格的な企業向けデプロイメントのために、私たちは極めて低遅延のサービスを提供する内部 GPU 推論スタックも開発しました。SGLang で動作する他の小規模モデルと比較したベンチマークでは、すべての並行処理レベルにおいて LFM2.5 モデルは著しく低いエンドツーエンドの遅延値を達成しています。
始め方
今日から LFM2.5-230M および LFM2.5-230M-Base の構築を開始しましょう。これらは Hugging Face で利用可能です。
LFM2.5 により、私たちは「どこでも動作する AI」というビジョンを実現しています。これらのモデルは以下の通りです:
- オープンウェイト — 制限なくダウンロード、ファインチューニング、デプロイが可能
- 初日から高速 — Apple、AMD、Qualcomm、Nvidia のハードウェアにおいて llama.cpp、NexaSDK、MLX、vLLM をネイティブサポート
- 完全なファミリー — カスタマイズ用のベースモデルから、特殊化されたオーディオおよびビジョンバリアントまで、一つのアーキテクチャが多様なユースケースをカバー
エッジ AI の未来はここにあります。あなたが何を作り出すか、待ちきれません。
引用
この記事を以下のように引用してください:
Liquid AI, "LFM2.5-230M: Built to Run Anywhere", *Liquid AI Blog*, Jun 2026.
または、BibTeX 引用を使用してください:
@article{liquidAI2026230M,
author = {Liquid AI},
title = {LFM2.5-230M:
どこでも実行可能に設計されたモデル},
journal = {Liquid AI Blog},
year = {2026},
note = {www.liquid.ai/blog/lfm2-5-230m}
}
原文を表示
Today, we're releasing LFM2.5-230M, our smallest model yet. It’s a fast, lightweight foundation for developers to fine-tune and deploy in agentic workflows. Built on the LFM2 architecture, it delivers exceptionally fast inference and runs everywhere, from cloud GPUs to low-cost CPUs (213 tok/s decode speed on Galaxy S25 Ultra, 42 tok/s on a Raspberry Pi 5). Despite its small size, it’s surprisingly capable at tool use and data extraction tasks.
The base (LFM2.5-230M-Base) and post-trained (LFM2.5-230M) models are available today on Hugging Face. Check out our docs on how to run and fine-tune them locally.
Training & Fine-tuning
The model was pre-trained for 19T tokens, including a 32K context extension phase. We apply a lightweight post-training recipe designed to preserve flexibility for developers targeting their own downstream applications.
The recipe consists of three stages: (1) supervised fine-tuning with distillation from LFM2.5-350M, (2) direct preference optimization, and (3) multi-domain reinforcement learning. The final checkpoint balances strong out-of-the-box capabilities with adaptability to downstream specialization, while remaining competitive with larger models.
As an early look at ongoing work, we deployed LFM2.5-230M on a Unitree G1 humanoid robot, running entirely on-device on its onboard NVIDIA Jetson Orin. Here the model acts as a skill-selection layer: it takes a single natural-language instruction and decomposes it into a sequence of tool calls that invoke pre-trained low-level skills provided by NVIDIA's SONIC framework. After a quick fine-tune for this task, the model turns a free-form command such as
"Hold still for 2 seconds, then walk forward at 1 meter per second for 3 meters, hold a forward one-leg kneel for 5 seconds, and walk backward at 0.5 meters per second for 3 meters"
into a structured, multi-step plan, chaining skills like timed walking at a target velocity and a one-legged kneel. While the behaviors are deliberately simple at this stage, we think it's a compelling signal: a 230M-parameter model can be quickly fine-tuned and deployed on-device to serve as the natural-language control interface for a humanoid.
https://www.youtube.com/shorts/CuMOWa2y1Ho
Benchmarks
We evaluated LFM2.5-230M across ten benchmarks covering both core capabilities and applied tasks. Despite its size, it competes with and often beats models more than twice as large, spanning knowledge (GPQA Diamond, MMLU-Pro), instruction following (IFEval, IFBench, Multi-IF), data extraction (CaseReportBench), and tool use (BFCLv3, BFCLv4, τ²-Bench Telecom and Retail).
Model
GPQA Diamond
MMLU-Pro
IFEval
IFBench
Multi-IF
LFM2.5-230M
25.41
20.25
71.71
38.40
37.70
LFM2.5-350M
30.64
20.01
76.96
40.69
44.92
LFM2-350M
27.58
19.29
64.96
18.20
32.92
Granite 4.0-H-350M
22.32
13.14
61.27
17.22
28.70
Granite 4.0-350M
25.91
12.84
53.48
15.98
24.21
Qwen3.5-0.8B (Instruct)
27.41
37.42
59.94
22.87
41.68
Gemma 3 1B IT
23.89
14.04
63.49
20.33
44.25
Model
CaseReportBench
BFCLv3
BFCLv4
𝜏²-Bench Telecom
𝜏²-Bench Retail
LFM2.5-230M
22.51
43.26
21.03
5.26
13.68
LFM2.5-350M
32.45
44.11
21.86
18.86
17.84
LFM2-350M
11.67
22.95
12.29
10.82
5.56
Granite 4.0-H-350M
12.44
43.07
13.28
13.74
6.14
Granite 4.0-350M
0.84
39.58
13.73
2.92
6.14
Qwen3.5-0.8B (Instruct)
13.83
35.08
18.70
12.57
6.14
Gemma 3 1B IT
2.28
16.61
7.17
9.36
6.43
This makes LFM2.5-230M an ideal solution to power large-scale data extraction pipelines or lightweight on-device agentic workloads. However, given its compact size, we do not recommend it for reasoning-heavy workloads such as advanced math, code generation, or creative writing.
Fast Inference Everywhere
LFM2.5-230M ships with day-one support across the inference ecosystem:
- llama.cpp — GGUF checkpoints for efficient edge inference
- MLX — Optimized inference for Apple Silicon
- vLLM — GPU-accelerated serving for production throughput
- SGLang — GPU-accelerated serving for production throughput
- ONNX — Cross-platform inference across diverse accelerators
CPU inference. Thanks to the efficient LFM2 architecture, LFM2.5-230M is considerably faster than similar-sized models, including SSM hybrids and Gated Delta Networks. On both a Raspberry Pi 5 and a Qualcomm Snapdragon Gen4 (Samsung Galaxy S25 Ultra), it delivers the highest prefill and decode throughput in its class while keeping the smallest memory footprint. We tune the flash-attention flag per device to maximize prefill on each platform: enabled (-fa 1) on the Raspberry Pi 5 and disabled (-fa 0) on the Snapdragon Gen4.
GPU inference. For production-grade enterprise deployments, we have also developed an internal GPU inference stack that delivers extremely low-latency serving. We benchmark it against other small models running on SGLang, and across all concurrency levels, LFM2.5 models achieve considerably lower end-to-end latency.
Get Started
Start building today with LFM2.5-230M and LFM2.5-230M-Base, available on Hugging Face.
With LFM2.5, we're delivering on our vision of AI that runs anywhere. These models are:
- Open-weight — Download, fine-tune, and deploy without restrictions
- Fast from day one — Native support for llama.cpp, NexaSDK, MLX, and vLLM across Apple, AMD, Qualcomm, and Nvidia hardware
- A complete family — From base models for customization to specialized audio and vision variants, one architecture covers diverse use cases
The edge AI future is here. We can't wait to see what you build.
Citation
Please cite this article as:
Liquid AI, "LFM2.5-230M: Built to Run Anywhere", Liquid AI Blog, Jun 2026.
Or use the BibTeX citation:
@article{liquidAI2026230M,
author = {Liquid AI},
title = {LFM2.5-230M:
Built to Run Anywhere},
journal = {Liquid AI Blog},
year = {2026},
note = {www.liquid.ai/blog/lfm2-5-230m}
}
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み