ARFBenchの紹介:実際のインシデントに基づく時系列質問応答ベンチマーク
カーネギーメロン大学とDatadogの共同研究により、実際のインシデントデータを用いた時系列質問応答(TSQA)のためのベンチマーク「ARFBench」が公開され、SREエージェントの障害原因特定能力を評価する枠組みが提示された。
キーポイント
ARFBenchの公開
Datadog内の実際のインシデントデータに基づき、時系列質問応答(TSQA)タスクを評価するためのベンチマーク「ARFBench」が導入された。
SRE業務の自動化への貢献
システム障害発生時にエンジニアが latency の上昇や異常なメトリクスを特定するプロセスを、AIモデルやSREエージェントが実行できる可能性を探る。
学術と実務の連携
カーネギーメロン大学(CMU)とDatadog AI Researchの共同研究であり、学術的な枠組みと実務現場のデータが融合している。
既存モデルの限界
主要なLLM、視覚言語モデル(VLM)、時系列基盤モデル(TSFM)は、ARFBenchにおいて大幅な改善の余地があることが示された。
ハイブリッドモデルの有効性
TSFMとVLMを組み合わせた新しいハイブリッドモデルが、最先端モデルに匹敵するパフォーマンスを発揮し、TSQAモデリングの有望な新アプローチを示した。
人間とAIの補完関係
トップTSFM-VLMモデルと人間の専門家は異なるエラープロファイルを示し、その強みが補完的であることを確認。これによりモデルと専門家の組み合わせで「超人的」な性能を実現するオラクルを提案した。
ARFBenchの構築プロセスとコンテキストの強化
内部インシデント記録から時系列ウィジェットを抽出し、人間が検証したQAペアを作成。単一の変数ではなく、時系列キャプションや多変量グループ化といった意味のあるコンテキストを用いて現実世界の複雑さを反映している。
影響分析・編集コメントを表示
影響分析
このベンチマークの公開は、単なる異常検知を超え、AIが「なぜその障害が発生したのか」という因果関係を時系列データから推論する能力を評価する点で重要である。これにより、SRE領域におけるLLMやエージェントの適用範囲が拡大し、インシデント対応の自動化と効率化に寄与する可能性がある。
編集コメント
実際のインシデントデータを用いたTSQAベンチマークは、AIのSRE適用において「検知」から「原因究明・対応提案」へのフェーズ移行を示唆する重要な一歩である。
// インジェクションによる間隔修正
jQuery('')
.prop('type', 'text/css')
.html(`
.post-authors {
padding-right: 40px;
}
`)
.appendTo('head');
const authors = [
{
name: "Stephan Xie",
affiliations: [
"Machine Learning Department, Carnegie Mellon University",
"Datadog AI Research"
]
},
{ name: "Ben Cohen", affiliations: ["Datadog AI Research"]},
{ name: "Mononito Goswami", affiliations: ["Amazon AI Research"] },
{ name: "Junhong Shen", affiliations: ["Machine Learning Department, Carnegie Mellon University"] },
{ name: "Emaad Khwaja", affiliations: ["Datadog AI Research"] },
{ name: "Chenghao Liu", affiliations: ["Datadog AI Research"] },
{ name: "David Asker", affiliations: ["Datadog AI Research"] },
{ name: "Othmane Abou-Amal", affiliations: ["Datadog AI Research"] },
{ name: "Ameet Talwalkar",
affiliations: [
"Machine Learning Department, Carnegie Mellon University",
"Datadog AI Research"
] },
];
jQuery('.post-authors').empty();
jQuery('.affiliations').empty();
jQuery('.post-authors').append('Authors
');
const affiliationMap = {};
let affiliationIndex = 1;
// 第一段階:固有の所属機関番号を割り当て
authors.forEach(author => {
author.affiliations.forEach(affiliation => {
if (!affiliationMap[affiliation]) {
affiliationMap[affiliation] = affiliationIndex++;
}
});
});
// 著者リストの構築
const authorsHtml = authors.map((author, index) => {
const affIndices = author.affiliations.map(a => affiliationMap[a]);
const superscriptParts = [...affIndices];
if (author.equalContribution) {
superscriptParts.push('*');
}
const superscript = ${superscriptParts.join(',')};
let separator = '';
if (index < authors.length - 1) {
separator = ', ';
}
return ${author.name}<sup>${superscript}</sup>${separator};
});
jQuery('.authors').html(authorsHtml.join(''));
// 所属機関リストの構築
jQuery('.affiliations').empty();
jQuery('.affiliations').append('<h3>Affiliations</h3>');
Object.entries(affiliationMap).forEach(([affiliation, index]) => {
jQuery('.affiliations').append(${index}. ${affiliation}<br>);
});
// 同等貢献の脚注
if (authors.some(a => a.equalContribution)) {
jQuery('.affiliations').append('*Equal contribution<br>');
}
jQuery('.doi').remove();
システム障害により、毎年1兆ドル以上の損失が発生しています。これらの問題を解決するためには、エンジニアはダウンタイム(停止時間)のトラブルシューティングを迅速に行う必要があります。
インシデント対応における重要なタスクの一つは、観測可能メトリクス(observability metrics)、すなわちソフトウェアシステムの健全性をスナップショットで捉えた時系列データを分析することです。例えば、あるサービスのエンジニアは Datadog を使用して、「レイテンシ(応答遅延)の上昇はいつ始まったか?」や「レイテンシ以外のどのメトリクスも異常な挙動を示しているか?」といった質問に答え、異常な振る舞いの根本原因を特定します。これらの時系列質問応答(TSQA: Time Series Question-Answering)タスクはエンジニアにとって不可欠であり、SRE(Site Reliability Engineering:サイト信頼性エンジニアリング)モデルやエージェントにとって挑戦的かつ必要なタスクです。本研究では、AI モデルが TSQA タスクをどの程度実行できるかを探ります。
そのために、私たちは Datadog 内の実際のインシデントから派生した時系列質問応答(TSQA)ベンチマークである Anomaly Reasoning Framework Benchmark (ARFBench) の導入を発表します。このベンチマークは、Datadog 独自の内部テレメトリーデータを用いて構築されています(図 1)。今回のブログ記事では、ベンチマーク実験から得られた3つの重要な知見を紹介します。
既存モデルの課題:主要な大規模言語モデル(LLM)、ビジョン・ランゲージモデル(VLM)、および時系列基盤モデル(TSFM)は、ARFBench において大幅な改善の余地があります。
ハイブリッドモデルの有効性:私たちは、ARFBench において最先端モデルと同等の全体的なパフォーマンスを発揮する新しいハイブリッド TSFM-VLM モデルを導入しました。これは、TSQA モデリングに向けた有望な新アプローチを示しています。
人間と AI の補完性:トップクラスの TSFM-VLM モデルと人間の専門家との間には、ARFBench において顕著に異なるエラープロファイルが存在することが観察されました。これらの結果は、両者の強みが補完的であることを示唆しています。私たちはモデルと専門家の組み合わせによる「オラクル」を導入し、LLM、VLM、TSFM にとって新たな超人的な最高水準を確立しました。
図1:A. ARFBenchの質問・回答生成ワークフロー。エンジニアは商用メッセージングプラットフォームを使用してインシデントに対応し、関連するメトリクスを可視化する時系列ウィジェットを送信するのが一般的です。内部で監視されているインシデントからの時系列データとインシデントタイムラインがLLMパイプラインの入力として使用され、異常のさまざまな側面をテストする8つの異なる質問テンプレートに適合します。生成された複数選択式の質問・回答ペアは、さまざまな予測モデルを評価するために使用できます。
ARFBench:実際のインシデントデータを用いた時系列質問応答(TSQA)ベンチマークの作成
ARFBenchは、Datadog内部の実際のインシデントに基づいたTSQAベンチマークであり、当社の内部テレメトリデータを使用しています。既存のベンチマークと比較して、ARFBenchは3つの主要な点で異なります。第一に、本番環境のシステムからの実際の時系列データを使用しています。第二に、各質問・回答(QA)例は専門家の注釈と追加のコンテキストに基づいています。第三に、タスクは構成推論をテストするように設計されており、質問は難易度の高い3つのティアに整理されており、上位のティアのタスクは下位ティアでの正しい推論に依存しています(図2)。
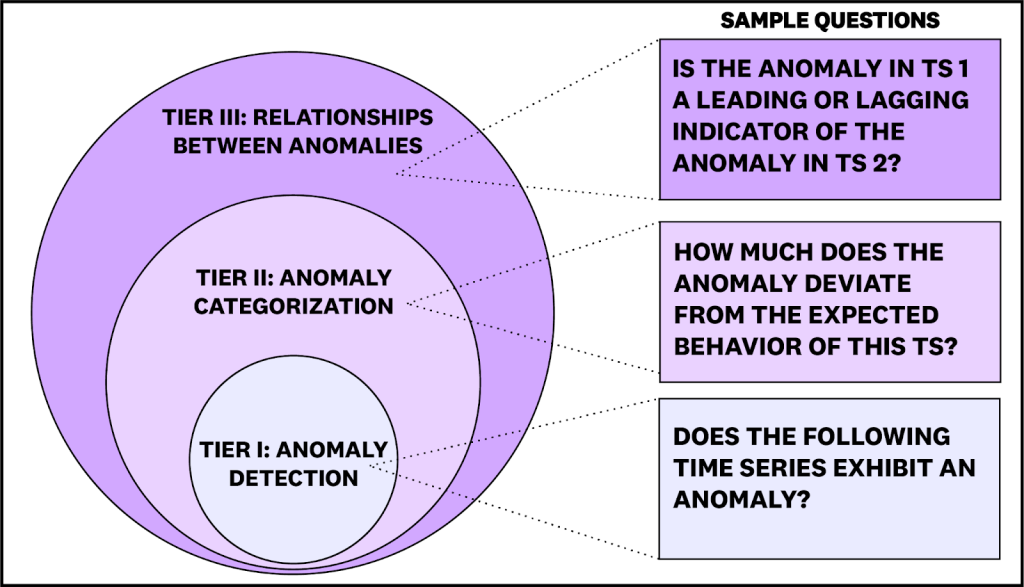 image図2:ARFBenchの各ティアからの質問例。ARFBenchの質問は、難易度の高い3つのティアで設計されており、上位のティアのタスクは下位ティアでの正しい推論に依存しています。
image図2:ARFBenchの各ティアからの質問例。ARFBenchの質問は、難易度の高い3つのティアで設計されており、上位のティアのタスクは下位ティアでの正しい推論に依存しています。
ARFBench は、142 の時系列データと 63 のインシデントから抽出された 750 組の QA(質問と回答)ペアで構成されています。ARFBench に含まれる時系列データは、最大 2283 変数(または次元)と 40,000 のタイムステップを持ち、コンテキスト制限のあるモデルにとって挑戦的な設定となっています。
ARFBench を作成するにあたり、内部のインシデント議論スレッドから時系列ウィジェットを抽出し、QA ペアの生成とフィルタリングを支援するための VLM(Vision-Language Model:ビジョン・ランゲージモデル)パイプラインを構築しました。その後、生成されたすべての質問について正確性とプライバシー上の懸念を手動で検証し、不適切と判断された質問は除外しました。
時系列や異常値に関する推論には、データ モダリティ全体にわたる意味のあるコンテキストの使用が必要です。ARFBench は、時系列データに 2 種類のコンテキストを追加しています。1 つは時系列キャプションで、これは時系列が何を表しているかを記述するものです。もう 1 つは多変量グループ化で、これは各チャネルをより広範な関連時系列チャンネルの集合に対して文脈づけるものです。例えば、サービス内の単一ポッドが失敗して再起動すること自体は常に重要ではないかもしれませんが、多数のポッドが同時に失敗して再起動する組み合わせは、重大な異常を示す可能性があります。この複雑さは、多くの既存の単一モダリティかつ合成データセットが捉えきれない現実世界の条件を反映しています(図 3)。
図 3:単独で分析した場合、時系列の変数(variates)は異常ではない場合でも、変数のグループという文脈では、同じ変数が異常と見なされることがあります。この図の多変量時系列は、特定のサービスにおける異なるクラスターおよび ID 間の平均 TLS 証明書残存寿命に基づいています。
主要な大規模言語モデル(LLM)、視覚大規模言語モデル(VLM)、時系列基礎モデル(TSFM)には、大幅な改善の余地があります。
私たちは ARFBench において、既存モデルの 3 つのカテゴリを評価しました:
時系列をテキスト入力として受け取る大規模言語モデル(LLM)
時系列プロットを画像入力として受け取る視覚大規模言語モデル(VLM)
時系列エンコーダーを大規模言語モデルのバックボーンとして使用する時系列大規模言語モデル。
これらのモデルを、2 つの人間ベースラインと比較しました。1 つは観測可能性(observability)の専門家、もう 1 つは広範な観測可能性の経験を持たない時系列研究者です。人間の専門家は、ARFBench のランダムにサンプリングされた 25% のサブセットで評価されました。
図 4:ARFBench における各種ベースラインおよび基礎モデルの全体的な精度(accuracy)と F1 スコア。モデルは精度の降順でソートされています。Toto-1.0-QA-Experimental は ARFBench で最高精度を達成し、最先端モデルと同等の F1 スコアを示しています。
既存のモデルの中で、GPT-5 (VLM) が 62.7% の精度と 51.9% の F1 スコアという最高性能を記録しました(図 4)。これはランダム選択のベースラインである 22.5% よりもはるかに高い数値ですが、ドメインの専門家には及ばず、87.2% の精度 / 82.8% の F1 スコアを持つモデル・専門家オラクルには遠く及ばない結果となりました(詳細な議論は後述)。予想通り、モデルの性能はタスクの難易度が上がるにつれて悪化する傾向があります。
また、ARFBench での評価においていくつかの傾向を観察しました。Daswani らによる 2024 年の研究をはじめとする、時系列分類や QA(質問応答)に関する先行研究を裏付けるものとして、VLM が LLM を上回る性能を示すことがわかりました。トップクラスの商用モデルとオープンソースモデルの間にも、パフォーマンスに大きな差が見られました。しかしながら、一部のオープンソースモデルは、多くの古い商用モデルや Claude シリーズのモデルよりも優れた性能を発揮することがわかりました。
ハイブリッド TSFM-VLM モデルは、専門的な TSQA(時系列質問応答)モデリングにおいて有望な可能性を示しています
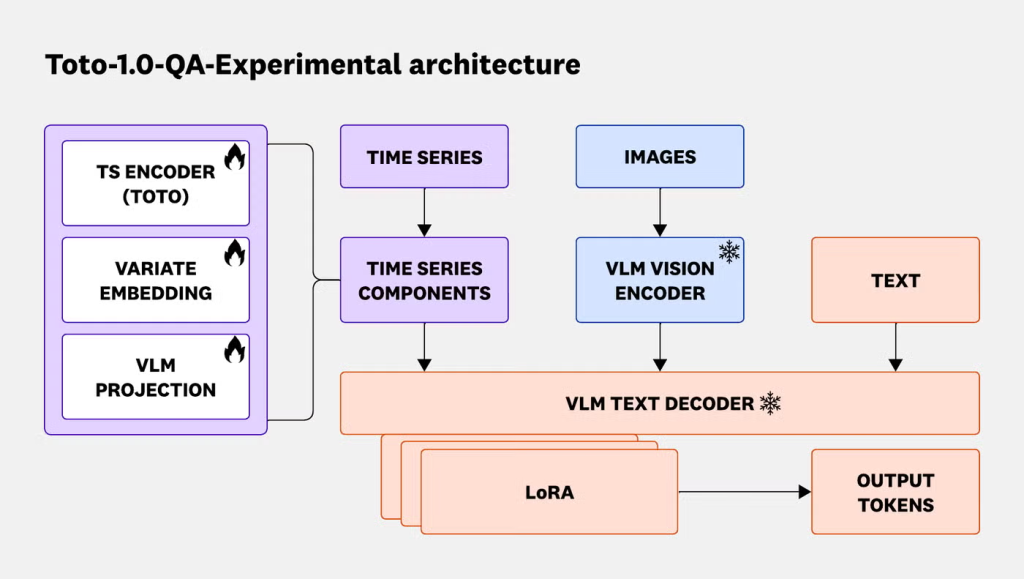 image図 5: Toto-1.0-QA-Experimental (Toto-Qwen3-VL) モデルのアーキテクチャ図。凍結された重みは雪印で、学習可能な重みは炎のマークで示されています。学習可能なパラメータの数が少ないにもかかわらず、TSFM と VLM をアライメント(整合)させることができ、新たな能力を引き出すことが可能です。
image図 5: Toto-1.0-QA-Experimental (Toto-Qwen3-VL) モデルのアーキテクチャ図。凍結された重みは雪印で、学習可能な重みは炎のマークで示されています。学習可能なパラメータの数が少ないにもかかわらず、TSFM と VLM をアライメント(整合)させることができ、新たな能力を引き出すことが可能です。
既存のモデルの中で最も高い精度とF1スコアを達成したVLM(Vision-Language Model)でしたが、プロット作成と入力表現はVLMおよびLLM(Large Language Model)の両方にとって課題であることがわかりました。例えば、変数(variates)の数が多すぎるため、異なる変数の色を繰り返したり、視覚的に重なり合ったりすることなく時系列データをプロットできないことがしばしばありました。この課題に対応するため、VLMモデルとは別に、時系列データ、プロット、テキストを統合的な入力として活用できるネイティブな時系列アプローチを採用しました。
この手法を検証するため、最先端の観測データ用時系列予測モデル(TSFM: Time Series Forecasting Model)であるTotoと、主要なオープンソースVLMであるQwen3-VL 32Bを組み合わせたハイブリッドモデル(図5)を訓練しました。私たちは、教師ありファインチューニング(SFT: Supervised Fine-Tuning)と強化学習(RL: Reinforcement Learning)の両方を含むマルチステージのポストトレーニングパイプラインにおいて、合成データ(図6)と実際のマルチモーダルデータの両方を使用しました。その結果得られたモデル「Toto-1.0-QA-Experimental」は、63.9%という最高精度スコアを達成し、最先端モデルと同等のF1スコア(48.9%)を記録しました。時系列データから異常な変数を選択する「異常識別」タスクカテゴリーでは、Toto-1.0-QA-ExperimentalはF1スコアで他のすべてのモデルを最低8.8ポイント上回り、カテゴリ別精度でも最高値を達成しました。これは、TSFMとVLMの組み合わせが特定のタスクにおいてパフォーマンスを大幅に向上させる可能性があることを示唆しています。さらに、Toto-1.0-QA-Experimentalのパラメータ数は最先端モデルの数桁少ないため、推論時の効率向上が期待できます。
 image図6:ポストトレーニング用ハイブリッドTSFM-VLM(Time Series Foundation Model - Vision Language Model)およびTSFM-LLMモデルの合成データ生成フロー。時系列は、まず異なる長さとスケールをサンプリングし、次に各データポイントを正規分布からサンプリングすることで生成されます。多様性を加えるため、時系列に季節性およびドリフト成分を追加し、異なる基本時系列(右上)を作成します。各基本時系列に対して、質問テンプレートを適用し、時系列の様々な地点で異なる異常(例:レベルシフト、季節性の変化)を注入します(右下)。最後に、VLM(Vision Language Model:ビジョン・ランゲージモデル)を用いて、質問と回答のペアに対する時系列キャプションおよび推論を生成します。
image図6:ポストトレーニング用ハイブリッドTSFM-VLM(Time Series Foundation Model - Vision Language Model)およびTSFM-LLMモデルの合成データ生成フロー。時系列は、まず異なる長さとスケールをサンプリングし、次に各データポイントを正規分布からサンプリングすることで生成されます。多様性を加えるため、時系列に季節性およびドリフト成分を追加し、異なる基本時系列(右上)を作成します。各基本時系列に対して、質問テンプレートを適用し、時系列の様々な地点で異なる異常(例:レベルシフト、季節性の変化)を注入します(右下)。最後に、VLM(Vision Language Model:ビジョン・ランゲージモデル)を用いて、質問と回答のペアに対する時系列キャプションおよび推論を生成します。
興味のある読者は、論文を参照して、より詳細な実験結果、エラー分析、およびケーススタディをご確認ください。
モデルで補完されたドメインエキスパートが、新たなスーパーヒューマン(人間を超えた性能)の境界を打ち立てました
ARFBenchにおける現在、最良のモデル(Toto-1.0-QA-ExperimentalおよびGPT-5)と2人の人間ドメインエキスパートとの間の集計ギャップは、精度で8.8ポイント、F1スコアで12.7ポイントに過ぎません。しかし、個々の質問レベルでは、GPT-5と人間エキスパートの間で顕著に異なる振る舞いが観察されます。GPT-5は、両方のエキスパートが誤答した質問の48%を正解しています。これらの質問において、人間エキスパートは指示のフォローや細粒度な知覚に関する誤りを犯す傾向があります。一方、少なくとも1人のエキスパートが、GPT-5が誤答した質問の79%を正解しています。これらのセットにおいて、モデルのエラーはハルシネーションや誤ったドメイン知識を含む傾向があります。私たちは、論文内で両方のグループのエラー例を提供しています。
エラー分布の大きな差のため、エキスパートがモデルと補完されるとき、その共同能力は単一のエキスパートやモデル alone よりもはるかに高くなると仮定しています。これを確立するために、モデル・エキスパートのオラクルを計算しました。これは、オラクルがモデルとエキスパートの間で最適な回答を完全に選択するbest-of-2指標であり、当社のデータにおいて87.2%の精度と82.8%のF1スコアをもたらします。これは既存のモデル能力を大幅に上回り、LLM(大規模言語モデル)、VLM(視覚言語モデル)、TSFM(時系列基礎モデル)が達成すべき新たなスーパーヒューマンのフロンティアを設定します。
次のステップ:エージェントの中核コンポーネントとしての時系列推論
インシデント対応のより広い文脈において、ARFBenchは診断と推論を対象とした質問のみを含んでいます。しかし、私たちは、強力な診断および推論能力が、インシデントの理解において時系列推論をサブルーチンとして必要とするエンドツーエンドのエージェントシステム(例えば、SREやインシデント対応エージェント)において大きな役割を果たすと見なしています。ARFBenchは時系列エージェントを評価するために使用できますが、現在マルチターンベンチマークではありません。しかし、単一ターンのARFBenchで良好なパフォーマンスを示す将来のエージェントやモデルは、最終的にエンドツーエンドのタスクでより優れたパフォーマンスを発揮すると信じています。
ARFBenchの使い方
もしあなたがARFBenchでモデルをテストすることに興味があるなら、ベンチマークとリーダーボード、そしてモデルの重みはHugging Faceで、コードはGitHubで見つけることができます。詳しく知りたい場合は、当社の論文をお読みください。
原文を表示
// Inject spacing fix
jQuery('')
.prop('type', 'text/css')
.html(`
.post-authors {
padding-right: 40px;
}
`)
.appendTo('head');
const authors = [
{
name: "Stephan Xie",
affiliations: [
"Machine Learning Department, Carnegie Mellon University",
"Datadog AI Research"
]
},
{ name: "Ben Cohen", affiliations: ["Datadog AI Research"]},
{ name: "Mononito Goswami", affiliations: ["Amazon AI Research"] },
{ name: "Junhong Shen", affiliations: ["Machine Learning Department, Carnegie Mellon University"] },
{ name: "Emaad Khwaja", affiliations: ["Datadog AI Research"] },
{ name: "Chenghao Liu", affiliations: ["Datadog AI Research"] },
{ name: "David Asker", affiliations: ["Datadog AI Research"] },
{ name: "Othmane Abou-Amal", affiliations: ["Datadog AI Research"] },
{ name: "Ameet Talwalkar",
affiliations: [
"Machine Learning Department, Carnegie Mellon University",
"Datadog AI Research"
] },
];
jQuery('.post-authors').empty();
jQuery('.affiliations').empty();
jQuery('.post-authors').append('Authors
');
const affiliationMap = {};
let affiliationIndex = 1;
// First pass: assign unique affiliation numbers
authors.forEach(author => {
author.affiliations.forEach(affiliation => {
if (!affiliationMap[affiliation]) {
affiliationMap[affiliation] = affiliationIndex++;
}
});
});
// Build author line
const authorsHtml = authors.map((author, index) => {
const affIndices = author.affiliations.map(a => affiliationMap[a]);
const superscriptParts = [...affIndices];
if (author.equalContribution) {
superscriptParts.push('*');
}
const superscript = ${superscriptParts.join(',')};
let separator = '';
if (index Affiliations
');
Object.entries(affiliationMap).forEach(([affiliation, index]) => {
jQuery('.affiliations').append(`${index}${affiliation}
`);
});
// Equal contribution footnote
if (authors.some(a => a.equalContribution)) {
jQuery('.affiliations').append('*Equal contribution
');
}
jQuery('.doi').remove();
More than a trillion dollars are lost every year due to system failures. To resolve them, engineers must troubleshoot outages quickly.
An important task in incident response involves analyzing observability metrics, or time series data that snapshot the health of software systems. For example, an engineer for a service may use Datadog to answer questions like “When did latency start increasing?” and “What metrics outside of latency are also behaving abnormally?” to localize the root cause of the anomalous behavior. These time series question-answering (TSQA) tasks are essential for engineers, and present challenging and necessary tasks for SRE models and agents to perform. In this work, we explore the degree to which AI models can perform TSQA tasks.
To this end, we’re excited to introduce the Anomaly Reasoning Framework Benchmark (ARFBench), a TSQA benchmark derived from real internal incidents at Datadog, using Datadog’s own internal telemetry (Figure 1). In this blog post, we’ll present three key takeaways from our benchmarking experiments:
Existing models struggle: Leading LLMs, vision-language models (VLMs), and time series foundation models (TSFMs) have substantial room for improvement on ARFBench.
Hybrid models help: We introduce a new hybrid TSFM-VLM model that yields comparable overall performance to top frontier models on ARFBench, demonstrating promising new approaches to TSQA modeling.
Human–AI complementarity: We observe markedly different error profiles between our top TSFM-VLM model and human experts on ARFBench. These results suggest that their strengths are complementary. We introduce a model–expert oracle that establishes a new superhuman frontier for LLMs, VLMs, and TSFMs.
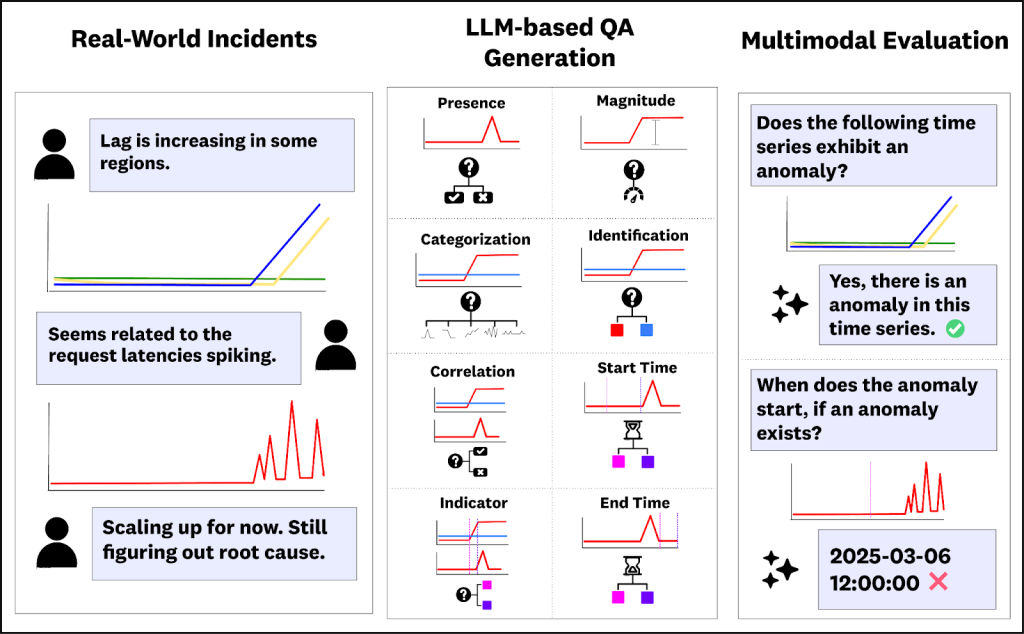 imageFigure 1: A. Workflow of ARFBench question-answer generation. Engineers use commercial messaging platforms to respond to incidents, where they typically send time series widgets that visualize relevant metrics. Time series and incident timelines from internally monitored incidents are used as input to an LLM pipeline and fit to eight different question templates testing various aspects of anomalies. The resulting multiple choice question-answer pairs can be used to evaluate various predictive models.
imageFigure 1: A. Workflow of ARFBench question-answer generation. Engineers use commercial messaging platforms to respond to incidents, where they typically send time series widgets that visualize relevant metrics. Time series and incident timelines from internally monitored incidents are used as input to an LLM pipeline and fit to eight different question templates testing various aspects of anomalies. The resulting multiple choice question-answer pairs can be used to evaluate various predictive models.
ARFBench: Using real-world incident data to create a TSQA benchmark
ARFBench is a TSQA benchmark based on real incidents internal to Datadog, using our own internal telemetry. Compared to existing benchmarks, ARFBench differs in three key aspects. First, it uses real time series data from production systems. Second, each question-answer (QA) example is grounded in expert annotations and additional context. And third, tasks are designed to test compositional reasoning: questions are organized into three tiers of increasing difficulty, with higher-tier tasks depending on correct reasoning on lower tiers (Figure 2).
imageFigure 2: Example questions from each tier of ARFBench. ARFBench questions are designed in three tiers of increasing difficulty, with higher tier tasks depending on correct reasoning on lower tiers.
ARFBench consists of 750 QA pairs drawn from 142 time series and 63 incidents. Time series in ARFBench have a maximum of 2283 variates (or dimensions) and 40k time steps, which present a challenging setting for context-limited models.
To create ARFBench, we built a VLM pipeline for extracting the time series widgets from internal incident discussion threads to help generate and filter question-answer pairs. We then manually verified every generated question for correctness and privacy concerns, and threw away questions that we found unsuitable.
Reasoning about time series and anomalies requires usage of meaningful context across data modalities. ARFBench enriches time series with two types of context: time series captions, which describe what the time series represent, and multivariate groupings, which contextualize each channel relative to a larger relevant collection of time series channels. For instance, while it may not always matter that a single pod fails and restarts in a service, the combination of many pods failing and restarting simultaneously could indicate a significant anomaly. This level of complexity reflects real-world conditions that many existing unimodal, synthetic datasets fail to capture (Figure 3).
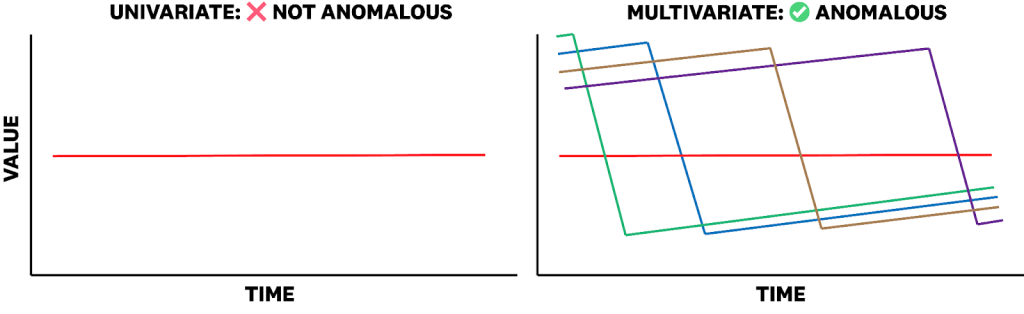 imageFigure 3: When analyzed alone, variates of a time series may not be anomalous. However, in the context of a grouping of variates, the same variate may be considered anomalous. The multivariate time series in this figure is based on the average remaining TLS certificate lifetime across different clusters and IDs of a particular service.
imageFigure 3: When analyzed alone, variates of a time series may not be anomalous. However, in the context of a grouping of variates, the same variate may be considered anomalous. The multivariate time series in this figure is based on the average remaining TLS certificate lifetime across different clusters and IDs of a particular service.
Leading LLMs, VLMs, and TSFMs have substantial room for improvement
We evaluated three categories of existing models on ARFBench:
LLMs, which take time series as text input
VLMs, which take time series plots as image input
Time series LLMs. which use a time series encoder with an LLM backbone.
We compared the models to two human baselines: observability experts, and time series researchers without extensive observability experience. The human experts were evaluated on a randomly sampled 25% subset of ARFBench.
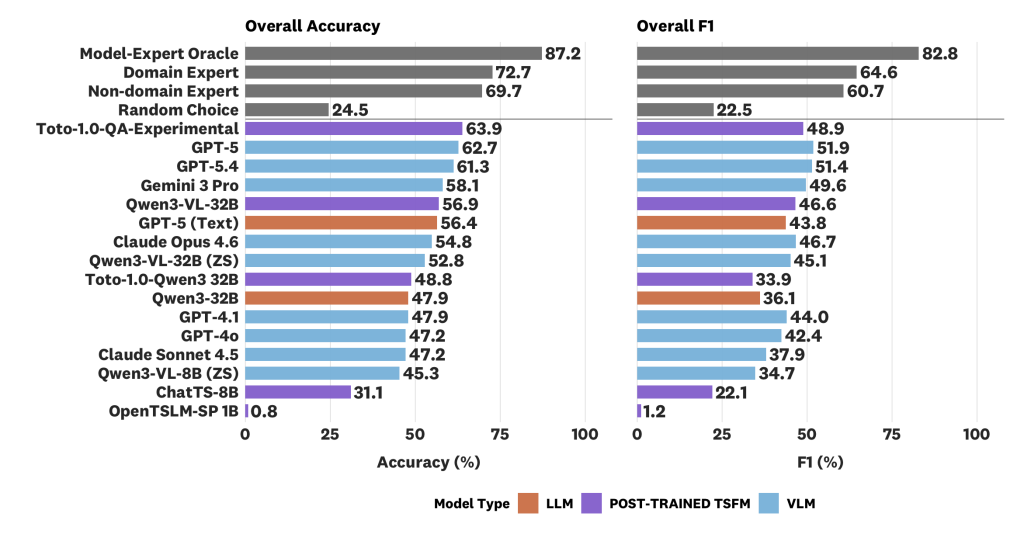 imageFigure 4: Overall accuracy and F1 of various baselines and foundation models on ARFBench. Models are sorted by decreasing accuracy. The Toto-1.0-QA-Experimental achieves the top accuracy on ARFBench and yields comparable F1 to top frontier models.
imageFigure 4: Overall accuracy and F1 of various baselines and foundation models on ARFBench. Models are sorted by decreasing accuracy. The Toto-1.0-QA-Experimental achieves the top accuracy on ARFBench and yields comparable F1 to top frontier models.
Among existing models, GPT-5 (VLM) yielded the top performance at 62.7% accuracy and 51.9% F1 (Figure 4). This is much higher than the random choice baseline at 22.5%, but still underperforms domain experts and is far below a model-expert oracle at 87.2% accuracy / 82.8% F1 (see below for further discussion). As expected, model performance tends to worsen as the tier difficulty increases.
We also observe several trends with our evaluations on ARFBench. Corroborating previous works in time series classification and QA such as Daswani et al. 2024, we find that VLMs outperform LLMs. The top proprietary models and open-source models also showed a substantial gap in performance. However, we find that some open-source models perform better than many older proprietary models or models from the Claude family.
Hybrid TSFM-VLM models show promise for specialized TSQA modeling
imageFigure 5: Architecture diagram of the Toto-1.0-QA-Experimental (Toto-Qwen3-VL) model. Frozen weights are denoted with a snowflake, while trainable weights are marked with a flame. With a small number of trainable parameters, we can align TSFMs and VLMs and yield novel abilities.
Though VLMs yielded the highest accuracy and F1 score among existing models, we found that plotting and input representation was a challenge for both VLMs and LLMs. For example, due to the high number of variates, we often could not plot the time series without repeating colors for or occluding different variates. This motivated a native time series approach alongside the VLM model in which we could utilize time series, plots, and text as joint input.
To test this, we trained a hybrid model (Figure 5) by combining Toto, a state-of-the-art observability TSFM, with Qwen3-VL 32B, a leading open-source VLM. We used both synthetic (Figure 6) and real multimodal data in a multi-stage post-training pipeline incorporating both supervised fine-tuning (SFT) and reinforcement learning (RL). The resulting model, Toto-1.0-QA-Experimental, yielded the top accuracy score of 63.9%, and comparable F1 to top frontier models (48.9%). In the Anomaly Identification task category, where a model selects anomalous variates in the time series, Toto-1.0-QA-Experimental outperforms all models by at least 8.8 percentage points in F1 and achieves best per-category accuracy, suggesting that TSFM-VLM modeling can highly benefit performance on particular tasks. Furthermore, Toto-1.0-QA-Experimental’s parameter count is several magnitudes lower than frontier models, thus providing potential efficiency gains at inference time.
imageFigure 6: Synthetic data generation flow for post-training hybrid TSFM-VLM and TSFM-LLM models. Time series are generated by first sampling different lengths and scales and second by sampling each datapoint from a normal distribution. To add variation, we add seasonality and drift components into the time series, yielding different base time series (top right). For each base time series, we apply question templates and inject different anomalies (e.g. level shift, change in seasonality) at various points of the time series (bottom right). Finally, we generate time series captions and reasoning for the question-answer pair using a VLM.
We refer interested readers to the paper for more experimental details, error analysis, and case studies.
Domain experts complemented with models set a new superhuman frontier
The current aggregate gap on ARFBench between the best models (Toto-1.0-QA-Experimental & GPT-5) and the two human domain experts is only 8.8 percentage points in accuracy and 12.7 percentage points in F1. However, at the individual question level, we observe noticeably different behavior between GPT-5 and the human experts. GPT-5 answers 48% of questions correctly that both experts get incorrect; on these questions, the human experts tend to make errors in instruction-following or fine-grained perception. Meanwhile, at least one expert correctly answers 79% of questions that GPT-5 gets incorrect. On these sets of questions, model errors tend to involve hallucination and incorrect domain knowledge. We provide examples of both groups of errors in the paper.
Due to the large difference in error distribution, we hypothesize that when experts are complemented with models, their joint capability becomes much higher than any single expert or model alone. To establish this, we compute a model-expert oracle, a best-of-2 metric where an oracle perfectly chooses the best answer between the model and the expert, which yields 87.2% accuracy and 82.8% F1 on our data. This is far above existing model capabilities and sets a new superhuman frontier for LLMs, VLMs, and TSFMs to achieve.
What’s next: time series reasoning as a core component of agents
In the broader scope of incident response, ARFBench only contains questions targeting diagnosis and reasoning. However, we envision that strong diagnosis and reasoning abilities will play a large part in end-to-end agentic systems (e.g., SRE or incident response agents) that require time series reasoning as a subroutine in understanding the incident. While ARFBench can be used to evaluate time series agents, it is not currently a multi-turn benchmark. However, we believe that future agents and models that perform well on the single-turn ARFBench will ultimately perform better on end-to-end tasks.
Getting started with ARFBench
If you are interested in testing your model on ARFBench, you can find the benchmark and leaderboard, and model weights on Hugging Face, and the code on GitHub. To learn more, read our paper.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み