ModaがDeep Agentsで本番環境対応のAIデザインエージェントを構築する方法
ModaはLangChainのDeep AgentsとLangGraphを用い、カスタムDSLによるコンテキストエンジニアリングでLLMの視覚設計推論を最適化し、非デザイナー向けの本格AIデザインプラットフォームを実現した。
キーポイント
3エージェント協調アーキテクチャ
デザイン、リサーチ、ブランドキットの各エージェントが役割を分担し、複雑なマルチターン設計タスクと本番品質の出力を実現する。
LLM向けカスタムDSLの採用
座標依存でトークン効率の悪いXMLやシーングラフに代わり、LLMが構造とレイアウトを推論しやすい抽象化DSLを採用した。
Deep AgentsとLangGraphの併用パターン
新規エージェントはDeep Agentsで実装し、既存デザインエージェントはLangGraphループを使用。今後はDesign Agentの移行も検討中。
LangSmithによる観測と反復開発
全エージェントに軽量トリアージ、動的コンテキスト読み込み、完全トレーシングを統合し、迅速なイテレーションと自信のあるリリースを実現。
レイアウト抽象化によるコンテキスト最適化
生の座標データではなくLLMが推論しやすいレイアウト抽象化に変換するコンテキスト表現層を採用し、トークンコストを削減しつつ出力品質を向上させている。
トライアージ→スキル→メインループのアーキテクチャ
高速なHaikuモデルでリクエストを分類し、関連するスキル(Markdown形式)を事前に読み込む。システムプロンプトとスキールブロック後にキャッシュブレークポイントを配置し、固定コンテキストの再利用と動的注入を両立させる。
ダイナミックツールローディングとコンテキストスケーリング
12〜15個のコアツールを常時コンテキストに保持し、専門的な必要がある場合のみオンデマンドで追加ツールを呼び出す。プロジェクト規模に応じてエージェントが受け取るコンテキストの解像度を動的に調整する。
影響分析・編集コメントを表示
影響分析
本記事は、LLMを視覚デザイン領域に適用する際の構造化データ表現(DSL)とマルチエージェントアーキテクチャの実践例を示しており、LangChainエコシステムにおける「Deep Agents」の採用拡大を促す。これにより、デザイン自動化市場でのAIエージェント標準化が進み、開発者は複雑なGUI生成タスクに対してより堅牢なパターンを適用できるようになる。
編集コメント
LangChain公式ブログにおける自社フレームワークの販促色が強いものの、デザイン領域におけるLLMの座標推論課題とDSL解決策は実装参考値が高い。本番環境でのエージェント構築には、観測基盤と文脈制御の組み合わせが不可欠であることが再確認できる。
 image Moda は、デザイン背景を持たないマーケター、創業者、営業担当者、小規模事業者向けに、プロフェッショナルグレードのプレゼンテーション、ソーシャルメディア投稿、パンフレット、PDF を作成できる AI ネイティブなデザインプラットフォームです。Canva や Figma のようなものですが、完全に編集可能な 2D ベクターキャンバス上で直接デザインを構築・反復する Cursor スタイルの AI サイドバーを搭載しています。
image Moda は、デザイン背景を持たないマーケター、創業者、営業担当者、小規模事業者向けに、プロフェッショナルグレードのプレゼンテーション、ソーシャルメディア投稿、パンフレット、PDF を作成できる AI ネイティブなデザインプラットフォームです。Canva や Figma のようなものですが、完全に編集可能な 2D ベクターキャンバス上で直接デザインを構築・反復する Cursor スタイルの AI サイドバーを搭載しています。
 image Moda の中核には、Deep Agents を用いて構築されたマルチエージェントシステムがあり、LangSmith が可視化(オバザビリティ)層を提供することで、チームが迅速に反復し、自信を持って製品をリリースできるようにしています。
image Moda の中核には、Deep Agents を用いて構築されたマルチエージェントシステムがあり、LangSmith が可視化(オバザビリティ)層を提供することで、チームが迅速に反復し、自信を持って製品をリリースできるようにしています。
課題:AI に優れたビジュアルデザイン能力を持たせること
AI によるコード生成が比較的うまく機能する理由の一つは、HTML や CSS にはすでに Flexbox やグリッドのようなレイアウトの抽象化が存在しているからです。ユーザーはピクセル座標ではなく、関係性や相対的なサイズを記述すればよいのです。
一方、ビジュアルデザインにはこれに相当する標準がありません。最も近いのは PowerPoint の XML 仕様ですが、これは 40 年前の形式で、冗長な絶対 XY 座標が詰め込まれており、LLM(大規模言語モデル)はこれを推論するのが特に苦手です。XML を使用するツールが生み出すデザインは、すべて他の AI 生成デッキと似た見た目になってしまいます。
Moda は、実際に美しく見えるデザインを生成できるシステムと、生産品質で複雑な多段階の対話的かつ視覚的に根拠のあるタスクを処理できるエージェントアーキテクチャが必要でした。
Agent Harness: Deep Agents を基盤に構築
Moda の AI システムは 3 つのエージェントで構成されています:
Design Agent: Cursor スタイルのサイドバーの背後にある主要エージェントで、キャンバス上でのすべてのリアルタイムなデザイン作成と反復処理を担当します
Research Agent: 外部ソース(例:企業のウェブサイト)から構造化されたコンテンツを取得し、Moda 内のユーザーごとのファイルシステムに保存します
Brand Kit Agent: ウェブサイト、アップロードされたブランドブック、または既存のスライドデッキからブランド資産(色、フォント、ロゴ、ブランドボイス)を取り込み、すべてのデザインが最初からブランドのイメージに沿ったものになるようにします
Research Agent と Brand Kit Agent はどちらも Deep Agents 上で動作しています。これらはチームが最近投入した最新のエージェントで、大規模な投資を行っています。Design Agent は、Deep Agents より前に構築された古くからの実装であるカスタム LangGraph ループ上で動作しており、チームはこれを移行することも積極的に検討中です。
これら 3 つのエージェントはすべて同じ全体的なアーキテクチャを共有しています:軽量なトリアージステップ、メインエージェントループ、動的コンテキストの読み込み、そして LangSmith による完全なトレーシングです。
Context Engineering: The Details That Matter
デザインエージェントが、単に技術的に正しいだけでなく、視覚的に一貫性がありブランドに正確な本物の優れた出力を生成できるようにするには、多くの意図的なコンテキストエンジニアリングが必要でした。
Moda が見つけた要点は以下の通りです。
生のカノンシーングラフの代わりにカスタム DSL を使用
デザインエージェントを構築する上で最も難しい部分の一つは、LLM が効果的に推論できる方法で視覚的レイアウトを表現する方法を見つけることです。生のキャンバス状態は冗長で座標に依存しすぎ、トークンコストが高く、モデルが構造やレイアウトについて考える自然な方法とは合致しません。
Moda は、キャンバス上の内容をエージェントによりクリーンかつコンパクトに把握させるためのコンテキスト表現層を開発しました。これによりトークンコストが削減され、出力品質も向上します。具体的な仕組みは機密情報ですが、その一般原則は LLM が Web 開発で効果的な理由と同じです:モデルに生数の数値座標ではなく、推論可能なレイアウト抽象化を与えることです。
「LLM は数学が苦手です。PowerPoint の XML 仕様には多数の XY 座標が含まれていますが、これはデータの表現としては適切ですが、LLM が要素をどこに配置したいかを記述する手段としては最適ではありません。」— Ravi Parikh氏、Moda.app 共同創設者
Deep Agents と LangSmith はこの点で極めて重要でした。チームは LangSmith のトレースを徹底的に活用し、異なるコンテキスト表現がエージェントの振る舞いにどう影響するかを評価しました。どの情報を含めるか、どのように構造化するか、またどこにキャッシュのブレイクポイントを設定すればコストとレイテンシに最も大きな差をもたらすかを反復して改善しています。
トリアージ → スキル → メインループ
すべてのリクエストは、メインエージェントに到達する前に軽量なトリアージノード(高速かつ低コストの Haiku モデルを使用)を通過します。このトリアージノードは出力フォーマット(スライドデッキ、PDF、LinkedIn カルーセル、ロゴなど)を分類し、関連するスキルを事前ロードします。これらのスキルは Markdown ドキュメントであり、デザインのベストプラクティス、フォーマットガイドライン、タスク固有のクリエイティブ指示を含んでいます。
スキルは人間のメッセージとして注入され、システムプロンプトの直後とスキールブロックの直後にプロンプトキャッシュのブレークポイントが設定されます。これにより、システムプロンプトは固定された状態で常にキャッシュされながら、リクエストごとに動的なコンテキスト注入が可能になります。
メインエージェントは、ループ中において必要なスキルが必要だと判断した場合に追加のスキルを引き込むこともできます。トライアージステップでは、不要な追加ターンを避けるために、高信頼度のスキルを事前に前面に出すだけです。
Dynamic Tool Loading(動的ツール読み込み)
デザインエージェントは、常に 12〜15 のコアツールをコンテキスト内に保持して実行されます。さらに約 30 のツールが、アップロードされた PowerPoint ファイルの解析など、専門的なニーズを認識した際にエージェントが呼び出せる「RequestToolActivation」ツールを通じてオンデマンドで利用可能です。
各追加ツールはプレフィックスに 50〜300 トークンを要し、新しいツールの読み込みはプロンプトキャッシュを中断します。しかし計算上は合理的です:绝大多数のリクエストには追加ツールが必要ないため、コンテキストを軽量に保つことが全体として有利になります。
「データを見ればわかる通り、ほとんどのリクエストには追加ツールの活性化は不要であり、コンテキスト内に 12〜15 のツールしかないことには非常に良い点があります。」— Ravi Parikh
Scaling Context to Canvas Size(キャンバスサイズに応じたコンテキストのスケーリング)
すべてのリクエストでプロジェクト全体を完全に可視化する必要はありません。小規模なキャンバスの場合、エージェントは現在の状態の完全なビューで動作します。一方、大規模なプロジェクト(例えば 20 スライドのプレゼンテーションなど)では、Moda は動的にエージェントが受け取るコンテキスト量を管理し、より高レベルのサマリーを提供するとともに、必要な詳細はツールを通じて随時引き出せるようにしています。
これにより、複雑で多ページにわたるプロジェクト全体において、エージェントが情報に基づいた設計判断を下す能力を損なうことなく、トークン使用量を制限することができます。LangSmith のノードごとのコスト追跡機能により、文脈の豊かさと効率性の間の適切なバランスを見つけることが容易になりました。
UX: デザインにおけるカーソル・モーメント
Moda が行った最も意図的な製品選択の一つが、インタラクションモデルです。AI が静的な出力を生成して引き渡す「生成して置き換え」フローではなく、Moda の AI は完全に編集可能な 2D ベクターキャンバス上で直接作業を行います。エージェントが作成するすべての要素は、ユーザーが即座に選択可能で、移動・サイズ変更・スタイル変更が可能です。
これは、ユーザーと AI の関係を「受け入れるか拒否するか」から、真の協働へと変えます。AI が堅牢な出発点を生成し、ユーザーがそれを洗練させます。どちらもすべての作業を担う必要はありません。
Cursor 風のサイドバーはこの考え方を強化しています。これは常に存在し、キャンバス上の内容に対して文脈的に意識しており、一度きりの生成ではなく、反復的なやり取りのために設計されています。特に非デザイナーにとって、このアプローチは空白のキャンバスに対する畏怖感を除去しつつ、最終結果を制御する権限をユーザーに保持させます。
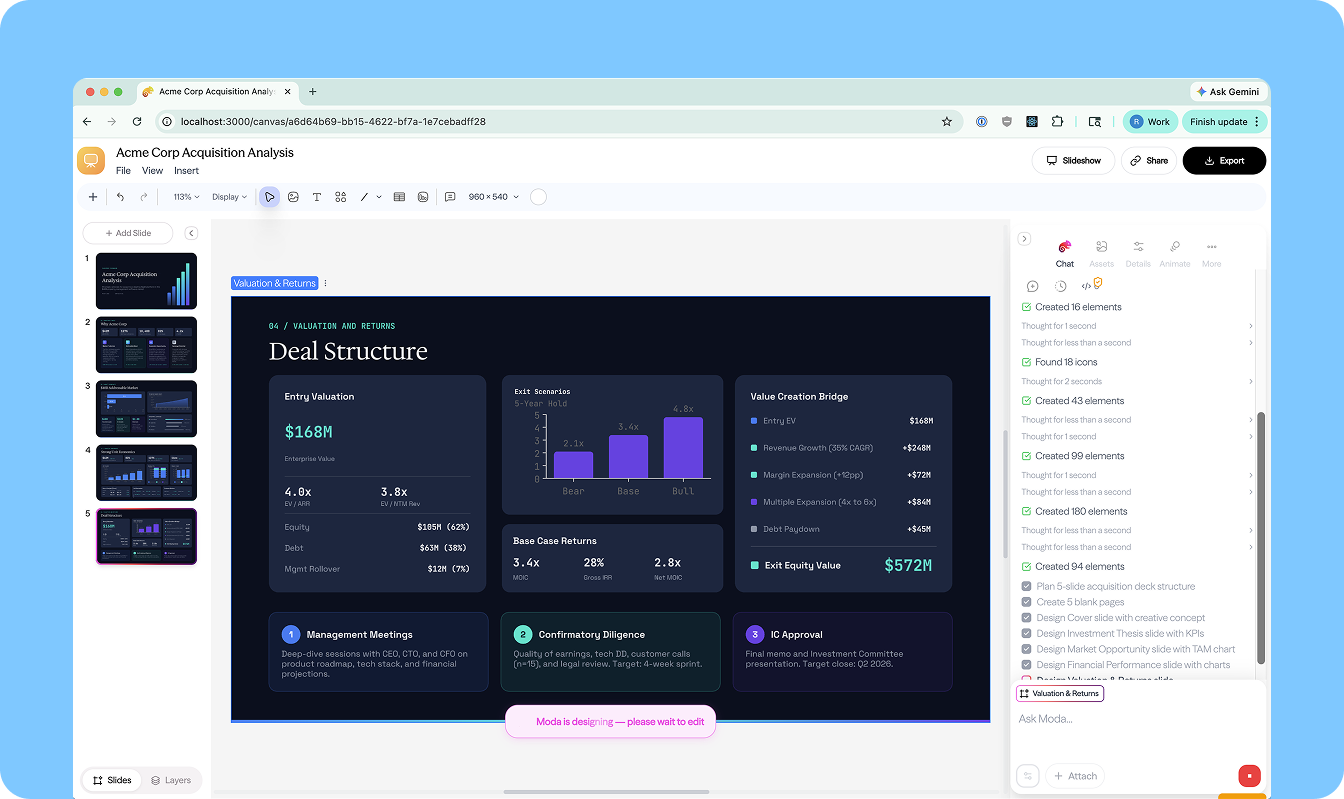
LangSmith による観測性
3 つのエージェントすべてが LangSmith を通じて追跡されるため、Ravi はすべての実行を完全に把握できます。彼は積極的に開発を行っている間は常にこれを開いておきます。
主要なワークフロー:
プロンプトとツールの反復:変更を加え、クエリを実行し、トレースを即座に呼び出して、エージェントが何を行い、なぜそう行ったのかを正確に確認する
コスト追跡:トークンコストをノードごとに内訳表示し、高コストのステップを容易に特定可能にする
キャッシュヒット分析:動的なスキルおよびツール読み込みの観点から特に重要であり、キャッシュが機能している箇所と機能していない箇所を即座に浮き彫りにする
エラー診断:ユーザー facing な問題となる前に、ツールの呼び出し失敗や予期せぬモデルの挙動を表面化させる
「プロンプトの反復を行っている際も、ツールセットの反復を行っている際も、変更を加え、クエリを実行し、その後 LangSmith でそのトレースを呼び出して何が起きたかを確認します。これにより、私たちのスピードが向上しました。」— Ravi Parikh
Moda はまだ公式の評価(evals)を実行していませんが、これはロードマップに含まれています。現時点では、LangSmith のトレースが回帰の検出と改善の検証のための主要なフィードバックループとして機能しています。
結果と今後の展望
Moda は、洗練されたブランドに準拠したピッチデッキを迅速に必要とする B2B 企業、特にエンタープライズセールスを行うチームにおいて、早期に強い製品市場適合(product-market fit)を実現しました。完全に編集可能なキャンバスと Deep Agents パワーのバックエンドを組み合わせることで、ユーザーは単なる静的な出力ではなく、実際に洗練できるプロフェッショナルな出発点を得ることができます。
次期予定:すでに実装済みのメモリプリミティブの接続、Design Agent 向けの Deep Agents 移行完了、およびマルチチーム・マルチブランドのエンタープライズ顧客をサポートするためのブランドコンテキストシステムの拡張です。
生産環境向けの AI エージェントを構築したいですか?LangChain Deep Agents で始めましょう
Interested in building production AI agents? Get started with LangChain Deep Agents
原文を表示
imageModa is an AI-native design platform for non-designers like marketers, founders, salespeople, and small business owners who need professional-grade presentations, social media posts, brochures, and PDFs without a design background. Think Canva or Figma, but with a Cursor-style AI sidebar that builds and iterates on designs directly on a fully editable 2D vector canvas.
imageAt the core of Moda is a multi-agent system built with Deep Agents, with LangSmith providing the observability layer that lets the team iterate quickly and ship with confidence.
The Challenge: Making AI Good at Visual Design
AI code generation works well partly because HTML and CSS already have layout abstractions like Flexbox and grid. You describe relationships and relative sizes, not pixel coordinates.
Visual design has no equivalent. The closest thing to a standard is PowerPoint's XML spec, a 40-year-old format packed with verbose, absolute XY coordinates that LLMs are notoriously bad at reasoning about. Tools that use XML produce designs that look like every other AI-generated deck.
Moda needed a system that could generate designs that actually look good, and an agent architecture capable of handling complex, multi-turn, visually-grounded tasks at production quality.
Agent Harness: Built on Deep Agents
Moda's AI system consists of three agents:
Design Agent: the primary agent behind the Cursor-style sidebar, handling all real-time design creation and iteration on the canvas
Research Agent: fetches and stores structured content from external sources (e.g., a company's website) into a per-user file system within Moda
Brand Kit Agent: ingests brand assets (colors, fonts, logos, brand voice) from websites, uploaded brand books, or existing slide decks, so every design feels on-brand from the start
The Research Agent and Brand Kit Agent both run on Deep Agents. These are the team's newest agents, which they've invested in heavily. The Design Agent runs on a custom LangGraph loop — an older implementation built before Deep Agents — and the team is actively evaluating migrating it as well.
All three agents share the same overall architecture: a lightweight triage step, a main agent loop, dynamic context loading, and full tracing in LangSmith.
Context Engineering: The Details That Matter
Getting a design agent to produce genuinely good output that is visually coherent and brand-accurate (not just technically correct) required a lot of intentional context engineering.
Here's what Moda figured out.
A Custom DSL Instead of Raw Scene Graph
One of the hardest parts of building a design agent is figuring out how to represent visual layouts in a way LLMs can reason about effectively. Raw canvas state is verbose, coordinate-heavy, and token-expensive — not a natural fit for how models think about structure and layout.
Moda developed a context representation layer that gives the agent a cleaner, more compact view of what's on the canvas, which reduces token cost and improves output quality. The specifics are proprietary, but the general principle is the same one that makes LLMs effective at web development: give the model layout abstractions it can reason about, rather than raw numerical coordinates.
"LLMs are not good at math. PowerPoint's XML spec has a bunch of XY coordinates — that's a fine representation of the data, but it's not a great way for an LLM to describe where it wants things to live." — Ravi Parikh, Co-Founder, Moda.app
Deep Agents and LangSmith were critical here. The team used LangSmith traces extensively to evaluate how different context representations affected agent behavior, iterating on what information to include, how to structure it, and where caching breakpoints made the biggest difference to cost and latency.
Triage → Skills → Main Loop
Every request passes through a lightweight triage node (using fast and cheap Haiku models) before reaching the main agent. The triage node classifies the output format (slide deck, PDF, LinkedIn carousel, logo, etc.) and pre-loads the relevant skills, which are Markdown documents containing design best practices, format guidelines, and task-specific creative instructions.
Skills are injected as human messages, with prompt caching breakpoints placed after the system prompt and after the skills block. This keeps the system prompt fixed and always cached while allowing dynamic context injection per request.
The main agent can also pull in additional skills mid-loop if it determines it needs them. The triage step just front-loads the high-confidence ones to avoid an unnecessary extra turn.
Dynamic Tool Loading
The design agent runs with 12–15 core tools in context at all times. An additional ~30 tools are available on demand via a RequestToolActivation tool the agent can call when it recognizes a specialized need, like parsing an uploaded PowerPoint file.
Each additional tool costs 50–300 tokens in the prefix, and loading new tools breaks prompt caching. But the math works out: the vast majority of requests don't need the extra tools, so keeping context lean wins overall.
"If I just look at the data, most requests do not need any additional tools activated, and there's something really nice about only having 12 to 15 tools in context." — Ravi Parikh
Scaling Context to Canvas Size
Not every request needs full visibility into the entire project. For smaller canvases, the agent works with a complete view of the current state. For larger projects — a 20-slide deck, for instance — Moda dynamically manages how much context the agent receives, giving it a higher-level summary and letting it pull in details as needed through tooling.
This keeps token usage bounded without sacrificing the agent's ability to make informed design decisions across complex, multi-page projects. LangSmith's cost tracking per node made it straightforward to find the right balance between context richness and efficiency.
UX: The Cursor Moment for Design
One of Moda's most deliberate product choices is the interaction model. Rather than a generate-and-replace flow, where AI produces a static output and hands it off, Moda's AI works directly on a fully editable 2D vector canvas. Every element the agent creates is immediately selectable, movable, resizable, and styleable by the user.
This changes the relationship between user and AI from "accept or reject" to genuine collaboration. The AI generates a solid starting point and the user refines it. Neither has to do all the work.
The Cursor-style sidebar reinforces this: it's always present, always contextually aware of what's on the canvas, and designed for iterative back-and-forth rather than one-shot generation. For non-designers especially, this removes the intimidation of the blank canvas while keeping them in control of the final result.
imageObservability with LangSmith
Because all three agents are traced through LangSmith, Ravi has full visibility into every execution. He keeps it open whenever he's actively developing.
Key workflows:
Prompt & tool iteration: make a change, run a query, pull up the trace immediately to see exactly what the agent did and why
Cost tracking: token cost broken down per node, making expensive steps easy to spot
Cache hit analysis: especially important given the dynamic skill and tool loading; quickly surfaces where caching is working and where it's breaking down
Error diagnosis: surfacing tool call failures and unexpected model behavior before they become user-facing issues
"If I'm iterating on the prompt, if I'm iterating on the tool set, I'm going to make a change, run a query, and then pull up that trace in LangSmith and just look at what happened... It's made us move faster." — Ravi Parikh
Moda doesn't yet run formal evals but it's on the roadmap. For now, LangSmith traces serve as the primary feedback loop for catching regressions and validating improvements.
Results & What's Next
Moda has found strong early product-market fit with B2B companies doing enterprise sales: teams that need polished, brand-accurate pitch decks fast. The combination of the fully editable canvas and the Deep Agents-powered backend means users get a professional starting point they can actually refine, not a static output they're stuck with.
Next up: wiring up the memory primitives that are already in place, completing the Deep Agents migration for the Design Agent, and expanding the brand context system to support multi-team, multi-brand enterprise customers.
Interested in building production AI agents? Get started with LangChain Deep Agents
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み