Amazon Bedrockを活用したテキストからSQLへのソリューション
AWSはAmazon Bedrockを活用したテキストからSQLへの変換ソリューションを紹介し、ビジネスユーザーが複雑なデータスキーマに対して自然言語で問い合わせ可能にすることで、データアクセスのボトルネックを解消する方法を提案している。
キーポイント
データアクセスボトルネックの解消
ビジネスユーザーがSQLの専門知識なしにデータにアクセスできるようになり、技術チームの負荷を軽減しながら迅速な意思決定を可能にする。
従来BIツールの限界を超える
事前設定されたダッシュボードでは対応できない複雑なマルチテーブルスキーマやドメイン固有の用語を含むワンタイム質問に対応できる。
実用的なアーキテクチャと実装
自然言語の質問をSQLクエリに変換し、実行結果を自然言語のナラティブとして数秒で返す完全なソリューションの構築方法を解説している。
組織的価値の創出
技術リソースを高価値な複雑なイニシアチブに集中させながら、日常的な分析質問をビジネスユーザー自身で解決できる環境を提供する。
影響分析・編集コメントを表示
影響分析
この記事は、生成AIを実務に統合する具体的なユースケースを示しており、データ分析の民主化と組織効率化の両立を実現する可能性がある。AWSのプラットフォーム戦略の一環として、Bedrockの実用性をアピールする内容となっている。
編集コメント
実務志向の技術解説記事で、生成AIの具体的なビジネス応用例として参考になるが、AWS製品のプロモーション色が強い点に注意が必要。
Amazon Bedrock を活用した Text-to-SQL ソリューションの構築は、データ駆動型組織における最も持続的なボトルネックの一つを軽減できます。それは、ビジネス上の質問を投げかけてから、明確でデータに基づく回答を得るまでの遅延です。単発の質問が、よりインパクトの大きい作業のキューの後方に回されている間に、競合する優先順位への対応に苦戦している経験があるかもしれません。Text-to-SQL ソリューションは既存のチームを補完し、ビジネスユーザーが日常的な分析質問をセルフサービスで処理できるようにすることで、組織全体の技術リソースを複雑かつ高価値なイニシアチブに集中させることができます。「顧客セグメント別の前年比売上高成長率はいくらか?」といった質問も、技術チームに追加の負担をかけずに、誰でもアクセス可能になります。
多くの組織は、データインサイトへのアクセスがビジネス意思決定プロセスにおいて依然として大きなボトルネックとなっていることに気づいています。従来のアプローチでは、SQL 構文を学ぶか、技術リソースの到着を待つ必要があります。あるいは、特定の質問に答えてくれない事前構築済みのダッシュボードに頼らざるを得ない場合もあります。
この投稿では、ビジネス上の質問をデータベースクエリに変換し、実行可能な回答を返す自然言語のText-to-SQLソリューションをAmazon Bedrockを使用して構築する方法を示します。このモデルは生SQLだけでなく、数時間ではなく数秒で明確な自然言語のナラティブに合成された実行結果も返します。私たちは、このソリューションを大規模にデプロイする際のアーキテクチャ、実装戦略、そして得られた教訓について順を追って解説します。最終的には、ビジネス上の質問とデータへのアクセス可能性のギャップを埋める独自のText-to-SQLシステムを作成する方法を理解していただけるでしょう。
従来のビジネスインテリジェンスが抱える課題
Amazon QuickSightのようなツールは、ダッシュボードの自然言語クエリや自動インサイト生成など、多くのセルフサービス分析ニーズを効果的に処理することに言及する価値があります。これらのツールは、分析要件が構造化されたダッシュボード、キュレーション済みのデータセット、そして管理されたレポートワークフローと一致する場合に最適です。ユーザーが複雑なマルチテーブルスキーマ、組織固有のビジネスロジック、ドメイン固有の用語、そして事前に設定されたダッシュボードデータセットでは対応できない一時的な質問に対してクエリを実行する必要がある場合、カスタムのText-to-SQLソリューションが価値を発揮します。
Text-to-SQLソリューションを構築することで、従来のビジネスインテリジェンス(BI)ツールを超えた必要性を駆動する3つの根本的な課題が浮き彫りになります:
- SQLの専門知識が障壁となり、迅速な分析を阻害しています。多くのビジネスユーザーは、複雑なデータにアクセスするために必要な技術的なSQLの知識を持っていません。単純な質問であっても、複数のテーブルを結合したり、時系列計算を行ったり、階層的な集計を行ったりする必要があることがよくあります。この依存関係により、ビジネスユーザーがカスタムレポートを待つ間に長時間の待ち時間が発生し、アナリストが戦略的な分析ではなく反復的なクエリリクエストに貴重な時間を費やすというボトルネックが生じます。
- 最新のBIシステムにも柔軟性の限界があります。現代のBIツールは、自然言語クエリやセルフサービス分析において大きな進歩を遂げました。しかし、これらの機能は通常、事前にキュレーションされたセマンティックレイヤー、管理されたデータセット、または事前モデリングされたダッシュボード内でのみ最も効果的に機能します。ビジネスユーザーがキュレーションされた境界を超えて探索する必要がある場合、ワンタイムの結合、オンザフライでの組織固有の計算、またはセマンティックレイヤー外の生データウェアハウステーブルへのクエリなど、技術的な介入を必要とする制約に直面します。カスタムのText-to-SQLソリューションは、事前構成されたセマンティックモデルに依存するのではなく、動的に取得されたビジネスコンテキストを使用してデータウェアハウスのスキーマに対して直接動作することで、このギャップを埋めます。
- コンテキストとセマンティックな理解の欠如が翻訳のギャップを生み出します。SQLへのアクセスがあっても、ビジネス用語を正確なデータベースクエリに変換するのは困難です。「達成率(attainment)」、「パイプライン(pipeline)」、「予測(forecast)」といった用語は、それぞれ固有の計算ロジック、特定のデータソース要件、そして組織間で異なるビジネスルールを持っています。どのテーブルを結合すべきか、指標がどのように定義されているか、そしてどのようなフィルターを適用するべきかは、ほとんどのユーザーにとって容易にアクセスできない深い組織固有の知識を理解する必要があります。
独自のソリューションを構築する際は、システムがどのようにこの深いビジネスコンテキスト(戦略原則、顧客セグメンテーションルール、運用プロセス)をエンコードするかを検討し、複雑なデータベーススキーマやSQL構文を理解することなく、ユーザーがより迅速でデータ駆動型の意思決定を行えるようにしてください。
仕組み:ユーザー体験
アーキテクチャの詳細に入る前に、ユーザー視点での体験についてご紹介します。
ビジネスユーザーは会話型インターフェースに質問を入力します。例えば、「今年の上位顧客セグメントにおける収益の推移は、昨年と比較してどのようになっているか?」といった質問です。裏側では、システムが数秒以内に以下の処理を行います:
- 質問を理解します。これが単一のステップで参照できるものか、それとも複数の部分に分解する必要がある複雑な質問かを判断します。この場合、「収益の推移」、「前年比比較」、「主要顧客セグメント」それぞれが異なるデータ取得ステップを必要とすることを認識します。
- ビジネスコンテキストを取得します。システムは、組織固有の指標定義、ビジネス用語、テーブル間の関係、データルールをエンコードしたナレッジグラフを検索します。その環境において「収益」が何を意味するか、それがどのテーブルに含まれているか、そして顧客セグメントがどのように定義されているかを理解しています。
- SQLを生成し、検証します。システムは構造化されたSQLクエリを生成し、決定論的なチェックを用いてその正確性と安全性を検証した後、データウェアハウスに対して実行します。検証で問題が検出された場合、人間の介入を必要とせずに自動的に修正し再試行します。
- 回答を統合します。生のクエリ結果は、裏付けデータ付きの自然言語によるナラティブに変換され、ユーザーに洞察と信頼性を支える透明性の両方を提供します。
その結果、ビジネスユーザーは複雑な分析質問に対する回答を数秒から数分で得られ、背後にあるロジックを完全に可視化できます。アナリストは反復的なクエリ作業から解放され、より高価値な戦略的分析に集中できます。
ソリューションの概要
この体験を提供するために、本ソリューションは3つの主要な機能を組み合わせています。
- Amazon Bedrock の自然言語理解および SQL 生成のためのファウンデーションモデル(FMs)
- ビジネスコンテキストの取得のためのグラフ検索拡張生成(GraphRAG)
- 高速クエリ実行のための高性能データウェアハウス。
このアーキテクチャにおいて、Amazon Bedrock は大規模言語モデル(LLM)の推論レイヤーとエージェントオーケストレーションランタイムの両方を提供することで中心的な役割を果たします。Amazon Bedrock は幅広いファウンデーションモデル(FMs)へのアクセスを提供するため、チームはシステムを再構築することなく、変化するパフォーマンス、コスト、レイテンシの要件に基づいてモデルを選択および切り替えることができます。
アーキテクチャ図に示されているように、
- Amazon Bedrock AgentCore Runtime は中央のオーケストレーション層として機能し、エンドツーエンドのワークフローを調整するスーパーバイザーエージェントをホストします。これはユーザーからの質問を受付け、コンテキスト取得のために GraphRAG Search Tool を呼び出し、行レベルセキュリティ(Row-Level Security)を適用し、SQL の生成と検証をトリガーし、データベース(Amazon Redshift)に対してクエリを実行します。このランタイムは MCP や HTTP プロトコルなど複数のエントリーポイントをサポートしており、AWS QuickSight などの埋め込み型アナリティクス画面やカスタム Web インターフェースとの統合を可能にします。
- Amazon Bedrock AgentCore は、エージェントの実行トレースやパフォーマンスメトリクスを Amazon CloudWatch にフィードする組み込みの観測性(observability)も提供しており、モニタリング、デバッグ、継続的な最適化に役立てます。このマネージドランタイムは、カスタムエージェントインフラストラクチャの構築に伴う「差異化のない重労働(undifferentiated heavy lifting)」を軽減するため、チームはビジネスロジック、プロンプトのチューニング、ドメイン知識の強化に集中できます。
次の図は、このワークフローがどのように動作するかを示しています:
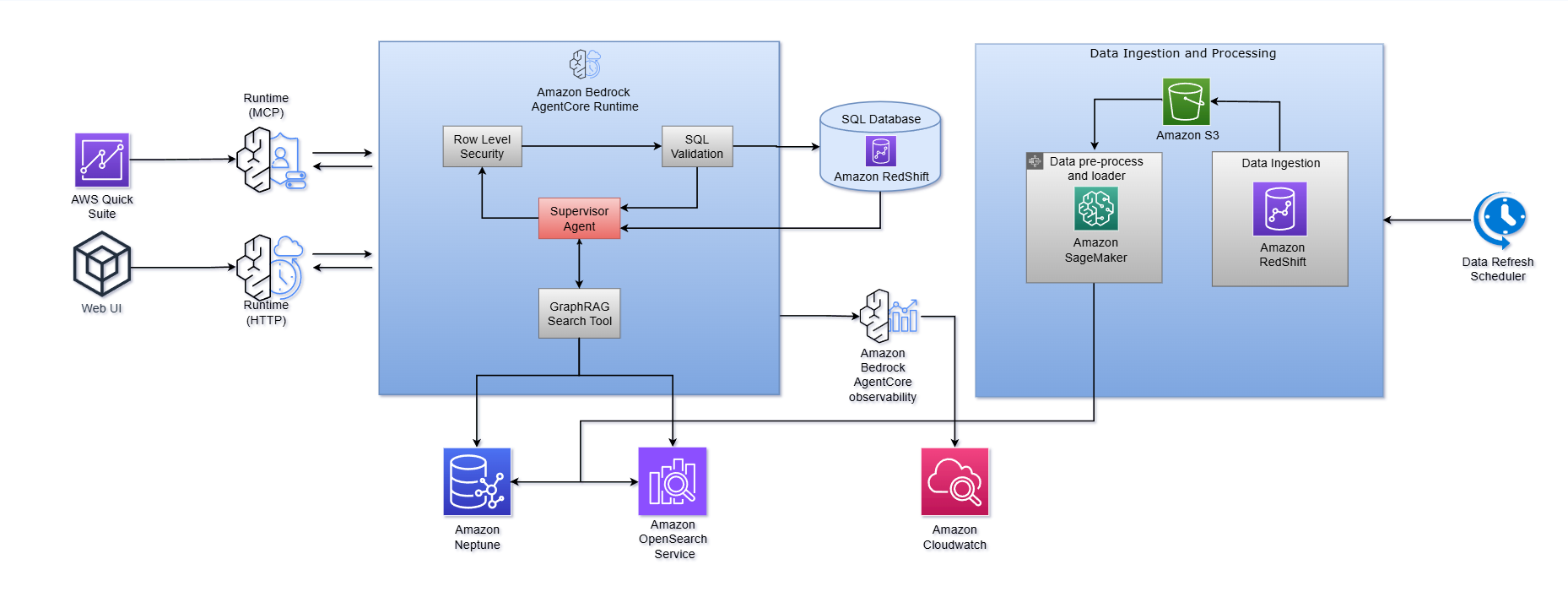
このアーキテクチャは、5 つの主要なステージを持つオーケストレーションされたマルチエージェントシステムとして動作します:
ステージ 1:質問の分析と分解
質問が入力されると、まず質問プロセッサーによってそれが分類されます。「第4四半期の総収益はいくらですか?」のような単純で原子性のある事実ベースの質問は、データ取得パイプラインに直接ルーティングされます。複雑な、または複数部分からなる質問は、個別のエージェントチームによって並列処理できる独立したサブ質問に分解されます。この分解ステップこそが、複数のデータドメイン、時間期間、またはビジネス次元にまたがる高度な分析質問をシステムが処理可能にする理由です。
ステージ 2:ナレッジグラフと GraphRAG コンテキストの取得
ここでシステムはコンテキストの壁を解決し、単純な Text-to-SQL アプローチとの最も重要な差異点となります。
Amazon Neptune と Amazon OpenSearch Service を基盤としたナレッジグラフは、セマンティックな基盤として機能します。これは組織のテーブルオントロジーを保存し、ビジネスエンティティ、指標、用語、および組織階層間の関係性を捉えます。重要なのは、このグラフがテーブル所有者や分野の専門知識からのドメイン知識で強化されており、構造化された設定ファイルからロードされたビジネス固有の説明、指標の定義、用語のマッピング、分類タグが含まれていることです。
システムが質問を処理する際、3つのフェーズで動作する軽量な GraphRAG 検索を実行します:
- ベクトル検索(Amazon OpenSearch Service を使用):ユーザーの質問に含まれる概念と一致する、意味的に関連性の高いカラム値、カラム名、およびテーブル説明を検出します。
- グラフ Traverse(Amazon Neptune を使用):マッチした値から親カラム、さらにその親テーブルへと知識グラフ内の関係を追跡し、関連するデータ資産がどれであり、それらがどのように接続しているかという完全な図像を構築します。
- 関連スコアリングとフィルタリング:取得されたコンテキストをランク付けして構造化し、SQL 生成器が正確に必要な情報(適切なテーブル、適切なカラム、結合パス、およびビジネスロジック)を受け取れるようにします。
知識グラフおよび関連データは、スキーマの変更、新しいテーブルの追加、変化するビジネス定義を反映するために定期的に更新されます。このコンテキスト層が豊かであればあるほど、その後の SQL 生成の精度は高くなります。
ステージ 3:構造化された SQL の生成と検証
システムは、Amazon Bedrock の 関数呼び出し 機能を使用して、SQL クエリを構造化データとして生成します。これにより厳格な出力形式が強制され、脆弱な後処理や複雑な正規表現の必要性が軽減され、信頼性が大幅に向上します。
生成されたクエリは、抽象構文木(Abstract Syntax Tree: AST)レベルで動作する決定論的な SQL 検証プログラムを通過します。これらの検証プログラムは、構文的には正しいが意味的に危険なクエリ(例えば、境界のないスキャン、フィルターの欠如、不正な集計ロジックなど)を含む潜在的にリスクのある操作を事前に検出します。検証プログラムが問題を指摘した場合、問題の説明と修正案を含む詳細なフィードバックを返します。
さらに堅牢性を高めるため、有効で実行可能なクエリが生成されるか、構成可能な再試行制限に達するまで自動的に反復処理を行う軽量な SQL 生成エージェントによって、一連の処理全体がラップされます。このアプローチは、プロンプトエンジニアリング単独よりも大幅に優れた信頼性の提供を目指しています。
ステージ 4: テスト時の並列計算
曖昧な、または複雑な質問に対しては、同じ質問を複数の並列エージェントに送信することで、システムが複数の潜在的な回答や推論パスを同時に生成できます。結果は多数決によって統合され、最も信頼性の高い出力が選択されます。これは複数の解釈が可能である質問にとって特に価値が高く、精度と堅牢性の両方に有意な向上をもたらします。
ステージ 5:レスポンスの合成
最後に、数値、データフレーム、実行ログを含む生のクエリ結果は、ユーザーが行動可能な回答として受け取る自然言語のナラティブに合成されます。完全なクエリの透明性が維持され、ユーザーはいつでも生成された SQL とその基盤となるデータを検査でき、システム出力への信頼を構築します。
本番環境品質の結果のための主要な戦略
アーキテクチャだけでは不十分です。このソリューションを大規模にデプロイすることで得られた以下の戦略は、本番利用が求める精度、安全性、応答性を達成するために不可欠です。
エンドユーザーがプロンプトを設計する
経験豊富なユーザーの間でさえ、個人は曖昧な用語に対するデフォルトの解釈が異なり、不明確な質問への回答に対する期待も異なります。テーブル所有者や指定されたパワーユーザーが管理された範囲内でプロンプトをカスタマイズできるように、カスタマイズインターフェース(ウェブアプリケーションなど)を構築することをお勧めします。カスタマイズは、コンテンツポリシーを適用し、プロンプトインジェクションの試みを制限し、変更が承認されたテンプレートとパラメータ内に留まることを確認する検証ガードレールを通過する必要があります。これにより、ドメイン知識やユーザーの好みをシステムに取り入れながら、無制限の自由テキストによる変更を防ぐことができます。このカスタマイズ機能は、異なるビジネスドメインが必要とする細かな理解を実現するために不可欠です。ソリューションは、画一的なアプローチを強制するのではなく、これらの多様性に対応できるものであるべきです。
SQL 検証を安全上重要な層として扱う
プロンプトエンジニアリングだけでは、構文は正しいが意味的に誤った SQL を生成するエラーを排除できません。これらのエラーは、一見妥当な結果を返すため、ユーザーの信頼を静かに損なったり誤った意思決定を招いたりする可能性があり、特に危険です。SQL は明確に定義された言語であるため、決定論的なバリデーター(検証ツール)を用いて、クエリがデータベースに到達する前に此类のエラーの広範なクラスを検出できます。社内テストでは、この検証レイヤーが生成されたクエリ内の重大なエラーを効果的に回避しました。これを交渉の余地のない安全メカニズムとして優先してください。
レイテンシに対して積極的に最適化する
会話型 AI に慣れ親しんだユーザーは、ほぼ瞬時の応答を期待します。生データの取得や計算の実行には、静的なナレッジベースからの回答よりも本質的に時間がかかりますが、レイテンシは第一級のユーザーエクスペリエンス課題として積極的に管理する必要があります。パフォーマンス分析によると、このワークフローには複数のステップが含まれており、それらのステップ全体にわたる累積時間は、SQL 実行時間単体と比較して最大の改善機会を表しています。
最適化のために、以下に焦点を当てます:
- 並列エージェント実行 – 複数の質問を逐次ではなく並行して処理します。これにより、複雑なクエリの総所要時間を大幅に短縮できます。
- 高性能分析用ストレージ – ビジネスインテリジェンスで典型的な集計処理の重いワークロードに優れた、列指向データベースを使用します。
- トークン最適化 – プロンプトの最適化とレスポンス形式の標準化を通じて、エージェントとの対話ごとにインプットおよびアウトプットのトークン数を最小限に抑えます。コンテキストが肥大化するたびにエージェントが再読み込みを強要されるツール呼び出し型エージェントフレームワークへの依存度を減らします。
これらの最適化により、当社のデプロイメントでは、単純なSQLクエリは通常約3〜5秒で生成されます。実際のレスポンス時間は、データウェアハウスのパフォーマンス、クエリの複雑さ、モデルの選択、知識グラフのサイズなどの要因によって異なります。インタラクティブなビジネス分析に対して現実的なレイテンシ目標を設定するため、ご自身の環境でベンチマークを行うことを推奨します。
初期段階からのセキュリティとガバナンスの構築
Row-Level Security (RLS) の統合を実装し、ユーザーがアクセス権限を持つデータのみを表示するようにします。このシステムは、既存の組織システムからアクセス制御ポリシーを適用する複合エンタイトルメントテーブルを維持します。ユーザーがクエリを送信すると、実行前に生成された SQL に適切な RLS フィルターが自動的に挿入されます。これらはユーザーには透過的ですが、適用は厳格です。このレイヤーを設計する際は、ユーザー体験に摩擦を加えることなく、厳格なデータガバナンス基準を維持できるようにしてください。
実装結果と影響
この投稿で概説したアーキテクチャと戦略に従うことで、Text-to-SQL ソリューションはデータアクセシビリティと分析生産性の大幅な向上をもたらすことができます:
- 従来の手法では数時間から数日かかっていた複雑なビジネス質問への回答を、分単位で提供することで速度の向上を実現します。複数のテーブル結合、時系列計算、階層集計を必要とする質問は、以前はカスタムSQLの開発が必要でしたが、自然言語による操作が可能になりました。
- 営業部門、財務計画、経営陣など、非技術系のビジネスユーザーがSQLの専門知識を持たずに高度なデータ分析を行えるようになり、分析の民主化が進んでいます。これにより、データエンジニアリングチームの分析的な負担が軽減され、反復的なクエリ要求ではなく戦略的なイニシアチティブに注力できるようになります。
- 複雑なクエリの処理は、以下の機能を持つ多次元の収益分析をサポートします:
自動セグメンテーション
- 前年比および前月比のトレンドと、その変動要因の説明
- 使用パターンに基づく細粒度レベルでの顧客インテリジェンス
- 目標比較による予測変動分析
- 期間および事業部門間のクロスファンクショナルベンチマーク
今後の展望
Amazon Bedrockを活用したText-to-SQLソリューションは、データ
原文を表示
Building a text-to-SQL solution using Amazon Bedrock can alleviate one of the most persistent bottlenecks in data-driven organizations: the delay between asking a business question and getting a clear, data-backed answer. You might be familiar with the challenge of navigating competing priorities when your one-time question is waiting in the queue behind higher-impact work. A text-to-SQL solution augments your existing team—business users self-serve routine analytical questions, freeing up technical capacity across the organization for complex, high-value initiatives. Questions like “What is our year-over-year revenue growth by customer segment?” become accessible to anyone, without creating an additional workload for technical teams.
Many organizations find that accessing data insights remains a significant bottleneck in business decision-making processes. The traditional approach requires either learning SQL syntax, waiting for technical resources, or settling for pre-built dashboards that might not answer your specific questions.
In this post, we show you how to build a natural text-to-SQL solution using Amazon Bedrock that transforms business questions into database queries and returns actionable answers. The model returns not only raw SQL, but executed results synthesized into clear, natural language narratives in seconds rather than hours. We walk you through the architecture, implementation strategies, and lessons learned from deploying this solution at scale. By the end, you will understand how to create your own text-to-SQL system that bridges the gap between business questions and data accessibility.
Why traditional business intelligence falls short
It’s worth noting that tools like Amazon Quick already address many self-service analytics needs effectively, including natural language querying of dashboards and automated insight generation. These tools are an excellent fit when your analytics requirements align with structured dashboards, curated datasets, and governed reporting workflows. A custom text-to-SQL solution becomes valuable when users must query across complex, multi-table schemas with deep organizational business logic, domain-specific terminology, and one-time questions beyond what pre-configured dashboard datasets support.
Building a text-to-SQL solution surfaces three fundamental challenges that drive the need beyond traditional Business Intelligence (BI) tools:
- The SQL expertise barrier blocks rapid analysis. Most business users lack the technical SQL knowledge needed to access complex data. Simple questions often require multi-table joins, temporal calculations, and hierarchical aggregations. This dependency creates bottlenecks where business users wait extended periods for custom reports, while analysts spend valuable time on repetitive query requests rather than strategic analysis.
- Even modern BI systems have flexibility boundaries. Modern BI tools have made significant strides in natural language querying and self-service analytics. However, these capabilities typically work best within pre-curated semantic layers, governed datasets, or pre-modeled dashboards. When business users need to explore beyond curated boundaries, one-time joins, on-the-fly organization-specific calculations, or querying raw warehouse tables outside the semantic layer, they still face constraints that require technical intervention. A custom text-to-SQL solution fills this gap by operating directly against your data warehouse schema with dynamically retrieved business context, rather than depending on pre-configured semantic models.
- Context and semantic understanding create translation gaps. Even with SQL access, translating business terminology into correct database queries proves to be challenging. Terms like attainment, pipeline, and forecast each have unique calculation logic, specific data source requirements, and business rules that vary across organizations. Understanding which tables to join, how metrics are defined, and which filters to apply requires deep institutional knowledge that isn’t readily accessible to most users.
When building your own solution, consider how your system will encode this deep business context (strategic principles, customer segmentation rules, and operational processes), so users can make faster, data-driven decisions without understanding complex database schemas or SQL syntax.
How it works: The experience
Before diving into architecture, here’s what the experience looks like from a user’s perspective.
A business user enters a question into a conversational interface asking something like, *“How is revenue trending this year compared to last year across our top customer segments?”* Behind the scenes, the system does the following in a matter of seconds:
- Understands the question. It determines whether this is a single-step lookup or a complex question that must be broken into parts. In this case, it recognizes that “revenue trending,” “year-over-year comparison,” and “top customer segments” each require distinct data retrieval steps.
- Retrieves business context. The system searches a knowledge graph that encodes your organization’s specific metric definitions, business terminology, table relationships, and data rules. It knows what revenue means in your environment, which tables contain it, and how customer segment is defined.
- Generates and validates SQL. The system produces a structured SQL query, validates it for correctness and safety using deterministic checks, and executes it against your data warehouse. If validation catches an issue, it automatically revises and retries without requiring human intervention.
- Synthesizes the answer. Raw query results are translated back into a natural language narrative with supporting data, giving users both the insight and the transparency to trust it.
The result is that business users get answers to complex analytical questions in seconds to minutes, with full visibility into the underlying logic. Analysts are relieved from repetitive query work to focus on higher-value strategic analysis.
Solution overview
To deliver this experience, the solution combines three core capabilities:
- Foundation models (FMs) in Amazon Bedrock for natural language understanding and SQL generation
- Graph Retrieval-Augmented Generation (GraphRAG) for business context retrieval
- High-performance data warehouses for fast query execution.
Amazon Bedrock plays a central role in this architecture by providing both the large language model (LLM) inference layer and the agent orchestration runtime. Amazon Bedrock offers access to a broad selection of FMs, so teams can choose and swap models based on evolving performance, cost, and latency requirements without re-architecting the system.
As shown in the architecture diagram,
- Amazon Bedrock AgentCore Runtime serves as the central orchestration layer, hosting a supervisor Agent that coordinates the end-to-end workflow. It routes user questions, invoking the GraphRAG Search Tool for context retrieval, enforcing Row-Level Security, triggering SQL generation and validation, and executing queries against a database (Amazon Redshift). The runtime supports multiple entry points, including MCP and HTTP protocols, enabling integration with both embedded analytics surfaces like AWS Quick Sight and custom web interfaces.
- Amazon Bedrock AgentCore also provides built-in observability, feeding agent execution traces and performance metrics into Amazon CloudWatch for monitoring, debugging, and continuous optimization. This managed runtime alleviates the undifferentiated heavy lifting of building custom agent infrastructure, so teams can focus on business logic, prompt tuning, and domain knowledge enrichment.
The following diagram illustrates how this workflow operates:
The architecture operates as an orchestrated multi-agent system with five key stages:
Stage 1: Question analysis and decomposition
When a question arrives, the question processor first classifies it. Straightforward, atomic, fact-based questions like *“What was total revenue in Q4?”*, are routed directly to the data retrieval pipeline. Complex or multi-part questions are decomposed into self-contained, independent subquestions that can be processed in parallel by separate agent teams. This decomposition step is what allows the system to handle sophisticated analytical questions that span multiple data domains, time periods, or business dimensions.
Stage 2: Knowledge graph and GraphRAG context retrieval
This is where the system solves the context barrier, and it’s the most critical differentiator from naive text-to-SQL approaches.
A knowledge graph built on Amazon Neptune and Amazon OpenSearch Service serves as the semantic foundation. It stores your organization’s table ontology and captures the relationships between business entities, metrics, terminology, and organizational hierarchies. Crucially, this graph is enriched with domain knowledge from table owners and subject matter experts for business-specific descriptions, metric definitions, terminology mappings, and classification tags loaded from structured configuration files.
When the system processes a question, it performs a lightweight GraphRAG search that works in three phases:
- Vector search (using Amazon OpenSearch Service): Finds semantically relevant column values, column names, and table descriptions that match the concepts in the user’s question.
- Graph traversal (using Amazon Neptune): Follows the relationships in the knowledge graph, from matched values to their parent columns to their parent tables, to build a complete picture of which data assets are relevant and how they connect.
- Relevance scoring and filtering: Ranks and structures the retrieved context so the SQL generator receives precisely the information it needs, the right tables, the right columns, the right join paths, and the right business logic.
The knowledge graph and its associated data are refreshed regularly to reflect schema changes, new tables, and evolving business definitions. The richer this contextual layer, the more accurate the downstream SQL generation becomes.
Stage 3: Structured SQL generation and validation
The system uses the function calling capabilities of Amazon Bedrock to produce SQL queries as structured data. This enforces strict output formats, alleviates the need for fragile post-processing or complex regular expressions, and significantly improves reliability.
Generated queries then pass through deterministic SQL validators operating at the Abstract Syntax Tree (AST) level. These validators proactively flag potentially risky operations, queries that are syntactically correct but semantically dangerous (for example, unbounded scans, missing filters, incorrect aggregation logic). When a validator flags an issue, it returns detailed feedback explaining the problem and suggesting a revision.
To further enhance robustness, the entire cycle is wrapped in a lightweight SQL generation agent that automatically iterates until it produces a valid, executable query or exhausts a configurable retry limit. This approach aims to deliver significantly better reliability than prompt engineering alone.
Stage 4: Test-time parallel compute
For ambiguous or complex questions, the system can generate multiple potential answers or reasoning paths simultaneously by submitting the same question to parallel agents. Results are synthesized through majority voting, selecting the most reliable output. This is particularly valuable for questions that can be interpreted in multiple ways, and it meaningfully improves both accuracy and robustness.
Stage 5: Response synthesis
Finally, raw query results including numbers, data frames, and execution logs are synthesized into natural language narratives that users receive as actionable answers. Full query transparency is maintained: users can inspect the generated SQL and underlying data at any time, building trust in the system’s outputs.
Key strategies for production-quality results
Architecture alone isn’t enough. The following strategies, learned from deploying this solution at scale, are essential for achieving the accuracy, safety, and responsiveness that production use demands.
Let end users shape the prompts
Even among experienced users, individuals often have differing default interpretations of ambiguous terms and varying expectations regarding responses to vague questions. We recommend building a customization interface, such as a web application, so table owners and designated power users can customize prompts within governed boundaries. Customizations should pass through validation guardrails that enforce content policies, restrict prompt injection attempts, and make sure modifications stay within approved templates and parameters. This helps prevent unrestricted free-text modifications while still incorporating domain knowledge and preferences into the system. This customization capability proves essential for achieving the nuanced understanding that different business domains require. Your solution should accommodate these variations rather than enforcing a one-size-fits-all approach.
Treat SQL validation as a safety-critical layer
Prompt engineering alone can’t remove errors that produce syntactically valid but semantically incorrect SQL. These errors are particularly dangerous because they return plausible-looking results that can silently erode user trust or drive incorrect decisions. Because SQL is a well-defined language, deterministic validators can catch a broad class of these errors before the query reaches your database. In internal testing, this validation layer effectively avoided serious errors in generated queries. Prioritize it as a non-negotiable safety mechanism.
Optimize aggressively for latency
Users accustomed to conversational AI expect near-instant responses. While retrieving live data and performing calculations inherently takes longer than answering from a static knowledge base, latency must still be actively managed as a first-class user experience concern. Performance analysis reveals that the workflow involves multiple steps, and the cumulative time across those steps represents the largest opportunity relative to SQL execution time alone.
To optimize, focus on:
- Parallel agent execution – Process multi-part questions concurrently rather than sequentially. This can dramatically reduce total time for complex queries.
- High-performance analytical storage – Use column-oriented databases that excel at the aggregation-heavy workloads typical in business intelligence.
- Token optimization – Minimize input and output tokens per agent interaction through prompt optimization and response format standardization. Reduce reliance on tool-calling agentic frameworks where each call forces the agent to re-ingest growing context.
With these optimizations, in our deployment, simple SQL queries are typically generated in approximately 3–5 seconds. Actual response times will vary based on factors such as data warehouse performance, query complexity, model selection, and knowledge graph size. We recommend benchmarking against your own environment to establish realistic latency targets for interactive business analysis.
Build security and governance in from the start
Implement Row-Level Security (RLS) integration so that users only ever see data they are authorized to access. The system maintains composite entitlement tables that enforce access control policies from your existing organizational systems. When a user submits a query, appropriate RLS filters are automatically injected into the generated SQL before execution. They’re transparent to the user, but rigorous in enforcement. Design this layer to uphold strict data governance standards without adding friction to the user experience.
Implementation results and impact
After you follow the architecture and strategies outlined in this post, a text-to-SQL solution can deliver significant improvements in data accessibility and analytical productivity:
- Speed improvements deliver answers to complex business questions in minutes, compared to hours or days with traditional approaches. Questions requiring multi-table joins, temporal calculations, and hierarchical aggregations that previously required custom SQL development become accessible through natural language.
- Analytical democratization helps non-technical business users across sales operations, financial planning, and executive leadership perform sophisticated data analysis without SQL expertise. This typically reduces analytical workload on data engineering teams, allowing them to focus on strategic initiatives rather than repetitive query requests.
- Complex query handling supports multi-dimensional revenue analysis with the following capabilities:
automatic segmentation
- year-over-year and month-over-month trending with variance explanations
- customer intelligence at granular levels with usage patterns
- forecast variance analysis with target comparisons
- cross-functional benchmarking across time periods and business units
Looking forward
Text-to-SQL solutions powered by Amazon Bedrock represent a significant step forward in making d
関連記事
Pococha開発環境をEKS上で再設計:ブランチ単位の開発とPull Request単位の検証 [DeNAインフラSRE]
DeNAのインフラSREチームが、Pocochaの開発環境をAmazon EC2からAmazon EKSへ移行し、ブランチ単位の開発とPull Request単位の検証を可能にするコンテナベースの環境を構築した。
Amazon Bedrock AgentCoreでReactアプリにライブAIブラウザエージェントを組み込む
Amazonは、Bedrock AgentCoreのブラウザツールを提供し、開発者がReactアプリにAIエージェントを組み込めるようにした。これにより、ユーザーはAIエージェントのウェブ操作を可視化でき、信頼性と制御性を向上させる。
大規模エージェント管理の未来:AWS Agent Registryがプレビュー公開
AWSがAWS Agent Registryを発表し、組織内でエージェント・ツール・スキルを発見・共有・再利用できる機能をAmazon Bedrock AgentCoreで提供開始した。