Fastlyがメトリクス基盤をGKEに移行し精度を改善した事例
CyberAgentのインターン生が、Fastly CDNメトリクス基盤をCloud RunからGKEに移行し、Datadog Agentによる直接スクレイプ構成に変更することで精度を改善した実践的な技術経験を紹介している。
キーポイント
インフラ構成の移行背景と目的
既存のCloud Run上のPrometheus Fastly ExporterをGKEに移行し、OTel CollectorとGoogle Managed Prometheusを介さずDatadog Agentが直接スクレイプするシンプルな構成に変更することで、メトリクス収集の精度改善を目指した。
技術的な課題と解決策
Helm Chartで複数のFastly Service IDを渡す際の非直感的な記述問題を解決するためにOSSコントリビューションを行い、Prometheus Autodiscovery採用時に発生した意図しないカスタムメトリクス課金問題に対処した。
実践的なインフラ移行プロセス
TerraformによるSecret Manager連携、Helm Chartを用いたデプロイ、dev→stg→prdの段階的展開など、実際のプロダクション環境での移行手順を詳細に記述している。
OSSコントリビューションの経験
prometheus-fastly-exporterのHelm Chart改善PRを提出し、バージョン0.10.2としてリリースされるなど、実務を通じたオープンソース貢献の実践例を示している。
技術的成長とサポート体制
インターン生はKubernetesやTerraformの実務経験がなかったが、チームのサポートを受けながら複数リポジトリの構成を理解し、prd環境へのリリースを達成した。
組織文化とキャリア視野の拡大
技術的な実務だけでなく、複数事業部との交流を通じて組織文化やキャリア観に触れ、視野を広げる貴重な経験を得た。
影響分析・編集コメントを表示
影響分析
この記事は、特定企業のインフラ改善事例として実践的な技術的価値はあるが、業界全体に影響を与えるような革新的な技術やトレンドを扱っているわけではない。クラウドネイティブ環境での監視構成の最適化事例として、同様の課題に直面するエンジニアにとって参考になる実用的な知見を提供している。
編集コメント
実務レベルのインフラ移行事例として技術的詳細が豊富で参考になるが、AI/テクノロジーニュースとしての業界全体への影響度は限定的。エンジニア向けの実践的な技術記事としての価値が高い。
こんにちは!2026年2月に CA Tech Job インターン生として就業させて頂いた、立命館大学 情報理工学部 4年 の 仮屋薗 純(X:@zonozono0013、GitHub:@zono0013) です。WinTicket のサーバーチームに配属され、インフラ構成の改善タスクに取り組みました。この記事では、Fastly CDN メトリクス基盤の Cloud Run → GKE 移行のタスクについて、どのような経験をしたのか紹介します。
普段はサーバーサイドや Web フロント、Unity などアプリケーション寄りの開発をしていましたが、インフラ領域だけはほとんど触れてこなかったため、この機会に挑戦したいと考えていました。WinTicket は ToC サービスとして非常に多くのユーザーに利用されており、社員の方との面談で投票システムや決済基盤のお話を伺う中で関心を持ちました。投票という性質上、レースの開催スケジュールに連動してトラフィックが大きく波打つ環境での設計・運用は、なかなか体験できない領域であり、非常に面白そうだと感じたのが決め手です。
WinTicket では、Fastly CDN のメトリクスを Datadog のダッシュボードで可視化しています。メトリクスの取得には Prometheus Fastly Exporter を使い、Fastly の API から取得したメトリクスを Prometheus 形式で公開しています。
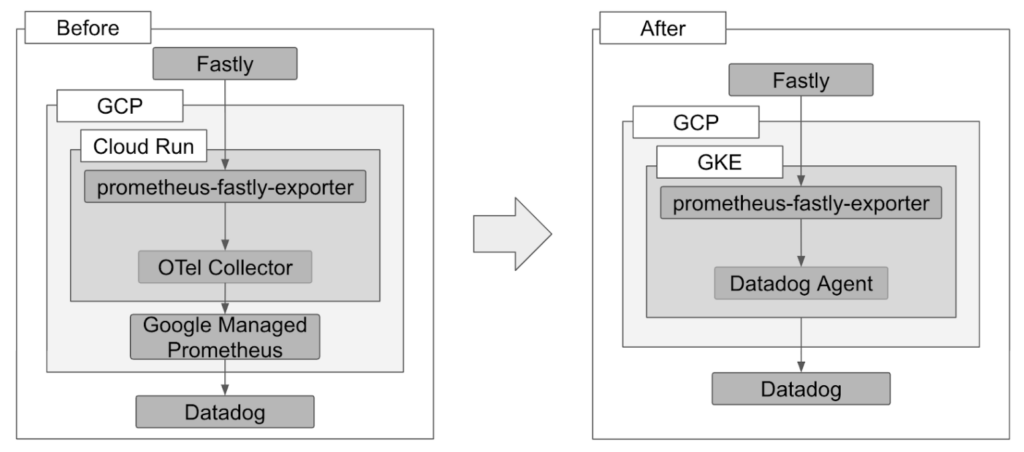
既存の構成では、この Prometheus Fastly Exporter が Cloud Run 上で動いており、サイドカーの OTel Collector(OpenTelemetry Collector)が /metrics をスクレイプして Google Managed Prometheus(GMP)に Push、そこから Datadog の Google Cloud Integration 経由で Datadog に連携するという構成でした。
今回のインターンでは、Cloud Run 上のアプリケーションを GKE に移行する方針に伴い、Prometheus Fastly Exporter を GKE に移行し、Datadog Agent が直接スクレイプする構成に変更するタスクに取り組みました。
移行後は OTel Collector と GMP を介さず、Datadog Agent が Pod を直接スクレイプするシンプルな構成になります。
最初に取り組んだのは、既存の構成の読み解きです。複数のリポジトリにまたがるコードを追い、Terraform によるインフラ定義から Cloud Run の構成と OTel Collector のスクレイプ設定を確認しました。結果として、30秒ごとに Prometheus Fastly Exporter の /metrics を Pull する設定になっていることがわかりました。また、既存の Datadog ダッシュボードで使われているメトリクスを洗い出し、移行後も同じ表示を維持できるよう目標を設定しました。
全体像を把握したうえで、Prometheus Fastly Exporter を Cloud Run から GKE に移行するための基盤を整えていきました。
Kubernetes Secret の準備
Fastly の API キーは Google Cloud の Secret Manager で管理されています。これを Kubernetes Secret として GKE クラスタに配布する必要がありました。そのため、Terraform で Google Cloud の Secret Manager からキーを取得し、Kubernetes Secret として各クラスタに配布する構成にしました。
Prometheus Fastly Exporter を GKE にデプロイ
prometheus-community が公開している Helm Chart を使う形で各環境に Prometheus Fastly Exporter をデプロイしました。ここで詰まったのが、複数の Fastly Service ID を引数として渡す方法です。Helm Chart の option フィールドでは、(–service)を複数個指定する場合、service という同じ名前の key を複数並べると最後の一つしか適応されないという問題が生じました。この問題は key に value の内容も含める形で渡すことで解決できました。
この方法は、非直感的な書き方で分かりにくいと感じたため、Helm Chart の upstream に PR を出して解消しました。この PR は prometheus-fastly-exporter-0.10.2 としてリリースされ、OSS コントリビューション初体験として良い経験になりました。
yaml # Before: フラグ名をキーに含める非直感的な書き方 option: service=example-service-id-1: "" service=example-service-id-2: "" # After: 配列で直感的に指定可能に option: service: - example-service-id-1 - example-service-id-2
dev → stg → prd と展開する過程で、いくつかの問題が発生しました。
GKE 上の Prometheus Fastly Exporter のメトリクスを Datadog Agent に収集させる方法として、Datadog の公式ドキュメント (Kubernetes Prometheus and OpenMetrics Metrics Collection) に記載されている Prometheus Autodiscovery を採用しました。DD Agent の Helm values に prometheusScrape.enabled: true を追加するだけで、prometheus.io/scrape: "true" アノテーションが付いた Pod のメトリクスを自動的にスクレイプしてくれる仕組みです。
しかし、この方法では Prometheus Fastly Exporter だけでなく、同じアノテーションが付いた全 Pod のメトリクスまで収集され、意図しないカスタムメトリクス課金が発生しました。
本当に必要なのは Prometheus Fastly Exporter のメトリクスだけなので、自動スクレイプを無効化し、ad.datadoghq.com の Autodiscovery アノテーションで OpenMetrics チェック(OpenMetrics Check)を明示的に設定する方式に切り替えました。さらに、ダッシュボードで実際に使っているメトリクスのみに絞り込み、不要なメトリクスの送信を防いでコストを削減しました。
host タグによるメトリクス膨張
empty_default_hostname: true を設定していなかったため、DD Agent が host タグ(数十個の infrastructure タグ)を自動継承し、カスタムメトリクス数が膨張する問題も発生しました。Cloud Run + OTel 経由では host 紐付けがなくタグは少数だったため、移行前には気づけない問題でした。解決策として OpenMetrics チェックの設定に empty_default_hostname: true を追加し、不要な host タグの継承を止めることでこの問題は解消しました。
メトリクスが prd で届かない
prd 環境では DD Agent が nodeAffinity(ノードアフィニティ)で特定のノードプールを除外して配置されていましたが、Prometheus Fastly Exporter にはその制約がありませんでした。結果として DD Agent が存在しないノードに Prometheus Fastly Exporter が配置され、メトリクスが Datadog に届かないという問題が発生しました。解決策として Prometheus Fastly Exporter にも同じ nodeAffinity を設定することでこの問題は解消しました。
prd 環境では datacenter × service × status_code 等のラベルの組み合わせにより数千時系列(時系列データ)が発生していましたが、Datadog Agent の OpenMetrics チェックにはデフォルト 2,000 時系列の上限があります。dev 環境ではラベルの組み合わせが少なく上限に達しなかったため、prd で初めてこの問題が顕在化しました。解決策として max_returned_metrics を引き上げて対処しました。
GKE への移行自体は完了しましたが、ダッシュボードのレイテンシ値(avg, p99, p95)が旧構成の値と乖離していました。「移行したらダッシュボードが同じように見える」がゴールだったので、この差異の原因を突き止める必要がありました。
最初はスクレイピング間隔の違いや、histogram の _sum / _count が送信されていない可能性を疑い、いくつかの設定変更を試しましたが、根本的な解決には至りませんでした。3 日間かけて調査した結果、移行後の DDSketch(DD Sketch)の値が正しく、旧 GMP(Google Metrics Pipeline)経由の値の方が不正確だったことがわかりました。
原因: パーセンタイル集約方法の根本的な違い
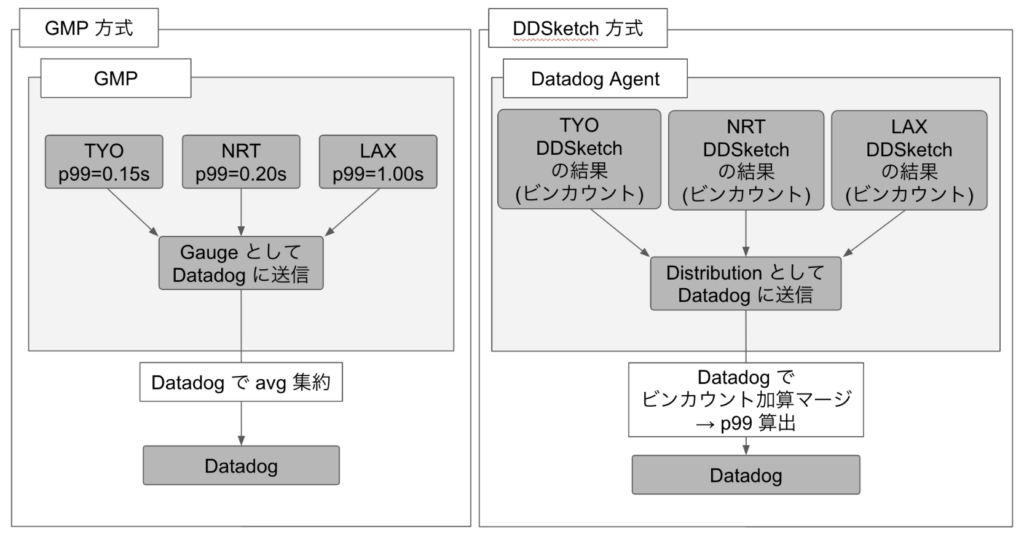
原因は、GMP → Datadog の Google Cloud Integration のパイプラインと DDSkarch で、datacenter 横断のパーセンタイル集約方法が根本的に異なっていたことです。
GMP を経由して(旧・不正確な方法)、Google Cloud 側でデータセンターごとにパーセンタイルを事前計算し、Gauge として Datadog に送信します。Datadog 上ではこの Gauge の avg 集約が行われるため、各データセンターの p99 が等しい重みで平均されます。リクエスト量が全体の 2% しかないデータセンターの高い p99 が、90% を占めるデータセンターと同じ重みで扱われてしまいます。
DDSketch は「完全にマージ可能(fully mergeable)」なデータ構造として設計されており(DDSketch 論文, VLDB 2019)、同じインデックスのビンカウントを加算するだけでマージできます。各データセンターの分布がそのまま結合されるため、リクエスト量の偏りに関係なく統計的に正確なパーセンタイルが算出されます。
GMP→Datadog(等重み平均)
(0.15 + 0.20 + 1.00) / 3
全リクエストの分布から p99
この問題は avg にも p99/p95 にも同様に影響していました。つまり、GKE 移行によってメトリクスの値が変わったのではなく、移行をきっかけにより正確な値が得られるようになったということです。
Datadog のメトリクス課金モデル
prometheusScrape のような便利機能を安易に有効化すると、意図しない Pod のメトリクスまで課金対象になります。今回は多数の Pod が意図せずスクレイプされていました。Autodiscovery アノテーションでの個別制御と empty_default_hostname の設定が基本だと学びました。
パーセンタイルの集約は統計的に難しい
データセンターごとに事前計算したパーセンタイルを平均しても、正確な値にはなりません。DDSketch のようなマージ可能なデータ構造を使うか、生の histogram bucket をマージしてからパーセンタイルを計算する必要があります。「ダッシュボードの数字が合わない」という現象の裏に、こうした統計的な落とし穴があることを身をもって学びました。
Pod のスケジューリングはインフラ全体を見る
DD Agent の nodeAffinity と Prometheus Fastly Exporter の配置先が一致しないとメトリクスが届かない、という問題は Pod 単体の設定だけでは気づけません。同一ノード上の他のコンポーネントとの依存関係まで意識する必要があると感じました。
今回のインターンを通して、Prometheus Fastly Exporter の Cloud Run → GKE 移行を完了しました。単純な移行作業にとどまらず、DD Agent の OpenMetrics チェックの設定調整、パーセンタイル集約の統計的な正確性の検証まで幅広く取り組みました。
移行前後でダッシュボードの値に乖離がありましたが、調査の結果、DDSketch による新しい値の方が正確であることがわかり、むしろ移行によってメトリクスの精度が向上しました。
インターンシップ開始時点では、Kubernetes や Terraform を実務で触った経験がなく、複数リポジトリにまたがる構成を読み解き、それぞれの用語や役割を調べるところから始まりました。最初は Helm Chart の values や Terraform の state(状態)を追うだけでも時間がかかりましたが、トレーナーのヤドンさんをはじめ、server チームや platform チームの皆さんにレビュー・サポートしていただいたおかげで、最終的には prd 環境へのリリースまで完遂できました。
技術的な実務だけでなく、複数の事業部の方々とのランチの機会も作っていただき、事業部ごとの文化や開発への向き合い方、キャリアや普段の暮らしなど幅広いお話を聞くことができました。視野が広がる貴重な経験をいただいたことに感謝しています。
技術的に成長できたことはもちろん、WinTicket で働く人たちの雰囲気を肌で感じられたことも含め、とても充実したインターンシップ期間を過ごせました。ありがとうございました。
原文を表示
こんにちは!2026年2月に CA Tech Job インターン生として就業させて頂いた、立命館大学 情報理工学部 4年 の 仮屋薗 純(X:@zonozono0013、GitHub:@zono0013) です。WinTicket のサーバーチームに配属され、インフラ構成の改善タスクに取り組みました。この記事では、Fastly CDN メトリクス基盤の Cloud Run → GKE 移行のタスクについて、どのような経験をしたのか紹介します。
普段はサーバーサイドや Web フロント、Unity などアプリケーション寄りの開発をしていましたが、インフラ領域だけはほとんど触れてこなかったため、この機会に挑戦したいと考えていました。WinTicket は ToC サービスとして非常に多くのユーザーに利用されており、社員の方との面談で投票システムや決済基盤のお話を伺う中で関心を持ちました。投票という性質上、レースの開催スケジュールに連動してトラフィックが大きく波打つ環境での設計・運用は、なかなか体験できない領域であり、非常に面白そうだと感じたのが決め手です。
WinTicket では、Fastly CDN のメトリクスを Datadog のダッシュボードで可視化しています。メトリクスの取得には Prometheus Fastly Exporter を使い、Fastly の API から取得したメトリクスを Prometheus 形式で公開しています。
既存の構成では、この Prometheus Fastly Exporter が Cloud Run 上で動いており、サイドカーの OTel Collector が /metrics をスクレイプして Google Managed Prometheus(GMP)に Push、そこから Datadog の Google Cloud Integration 経由で Datadog に連携するという構成でした。
今回のインターンでは、Cloud Run 上のアプリケーションを GKE に移行する方針に伴い、Prometheus Fastly Exporter を GKE に移行し、Datadog Agent が直接スクレイプする構成に変更するタスクに取り組みました。
移行後は OTel Collector と GMP を介さず、Datadog Agent が Pod を直接スクレイプするシンプルな構成になります。
最初に取り組んだのは、既存の構成の読み解きです。複数のリポジトリにまたがるコードを追い、Terraform によるインフラ定義から Cloud Run の構成と OTel Collector のスクレイプ設定を確認しました。結果として、30秒ごとに Prometheus Fastly Exporter の /metrics を Pull する設定になっていることがわかりました。また、既存の Datadog ダッシュボードで使われているメトリクスを洗い出し、移行後も同じ表示を維持できるよう目標を設定しました。
全体像を把握したうえでPrometheus Fastly Exporter を Cloud Run から GKE に移行するための基盤を整えていきました。
Kubernetes Secret の準備
Fastly の API キーは Google Cloudの Secret Manager で管理されています。これを Kubernetes Secret として GKE クラスタに配布する必要がありました。そのため、Terraform で Google Cloud の Secret Manager からキーを取得し、Kubernetes Secret として各クラスタに配布する構成にしました。
Prometheus Fastly Exporter を GKE にデプロイ
prometheus-community が公開している Helm Chart を使う形で各環境にPrometheus Fastly Exporterをデプロイしました。ここで詰まったのが、複数の Fastly Service ID を引数として渡す方法です。Helm Chart の option フィールドでは、(–service)を複数個指定する場合、serviceと言う同じ名前のkeyを複数か並べると最後の一つしか適応されないと言う問題が生じました。この問題はkeyにvalueの内容も含める形で渡すことで解決できました。
この方法は、非直感的な書き方で分かりにくいと感じたため、Helm Chart の upstream に PR を出して解消しました。この PR は prometheus-fastly-exporter-0.10.2 としてリリースされ、OSS コントリビューション初体験として良い経験になりました。
yaml # Before: フラグ名をキーに含める非直感的な書き方 option: service=example-service-id-1: "" service=example-service-id-2: "" # After: 配列で直感的に指定可能に option: service: - example-service-id-1 - example-service-id-2
dev → stg → prd と展開する過程で、いくつかの問題が発生しました。
GKE 上の Prometheus Fastly Exporter のメトリクスを Datadog Agent に収集させる方法として、Datadog の公式ドキュメント(Kubernetes Prometheus and OpenMetrics Metrics Collection)に記載されている Prometheus Autodiscovery を採用しました。DD Agent の Helm values に prometheusScrape.enabled: true を追加するだけで、prometheus.io/scrape: “true” アノテーションが付いた Pod のメトリクスを自動的にスクレイプしてくれる仕組みです。
しかし、この方法では Prometheus Fastly Exporter だけでなく、同じアノテーションが付いた全 Pod のメトリクスまで収集され、意図しないカスタムメトリクス課金が発生しました。
本当に必要なのは Prometheus Fastly Exporter のメトリクスだけなので、自動スクレイプを無効化し、ad.datadoghq.com の Autodiscovery アノテーションで OpenMetrics チェックを明示的に設定する方式に切り替えました。さらに、ダッシュボードで実際に使っているメトリクスのみに絞り込み、不要なメトリクスの送信を防いでコストを削減しました。
host タグによるメトリクス膨張
empty_default_hostname: true を設定していなかったため、DD Agent が host タグ(数十個の infrastructure タグ)を自動継承し、カスタムメトリクス数が膨張する問題も発生しました。Cloud Run + OTel 経由では host 紐付けがなくタグは少数だったため、移行前には気づけない問題でした。解決策として OpenMetrics チェックの設定に empty_default_hostname: true を追加し、不要な host タグの継承を止めることでこの問題は解消しました。
メトリクスが prd で届かない
prd 環境では DD Agent が nodeAffinity で特定のノードプールを除外して配置されていましたが、Prometheus Fastly Exporter にはその制約がありませんでした。結果として DD Agent が存在しないノードに Prometheus Fastly Exporter が配置され、メトリクスが Datadog に届かないという問題が発生しました。解決策としてPrometheus Fastly Exporter にも同じ nodeAffinity を設定することでこの問題は解消しました。
prd 環境では datacenter × service × status_code 等のラベルの組み合わせにより数千時系列が発生していましたが、Datadog Agent の OpenMetrics チェックにはデフォルト 2,000 時系列の上限があります。dev 環境ではラベルの組み合わせが少なく上限に達しなかったため、prd で初めてこの問題が顕在化しました。解決策としてmax_returned_metrics を引き上げて対処しました。
GKE への移行自体は完了しましたが、ダッシュボードのレイテンシ値(avg, p99, p95)が旧構成の値と乖離していました。「移行したらダッシュボードが同じように見える」がゴールだったので、この差異の原因を突き止める必要がありました。
最初はスクレイピング間隔の違いや、histogram の _sum / _count が送信されていない可能性を疑い、いくつかの設定変更を試しましたが、根本的な解決には至りませんでした。3 日間かけて調査した結果、 移行後の DDSketch の値が正しく、旧 GMP 経由の値の方が不正確だった ことがわかりました。
原因: パーセンタイル集約方法の根本的な違い
原因は、GMP → Datadog の Google Cloud Integration のパイプラインと DDSketch で、datacenter 横断のパーセンタイル集約方法が根本的に異なっていたことです。
GMP 経由(旧・不正確) Google Cloud 側で datacenter ごとにパーセンタイルを事前計算し、Gauge として Datadog に送信します。Datadog 上ではこの Gauge の avg 集約が行われるため、各 datacenter の p99 が等しい重みで平均されます。リクエスト量が 2% しかない datacenter の高い p99 が、90% を占める datacenter と同じ重みで扱われてしまいます。
DDSketch は “fully mergeable” なデータ構造として設計されており(DDSketch 論文, VLDB 2019)、同じインデックスのビンカウントを加算するだけでマージできます。各 datacenter の分布がそのまま結合されるため、リクエスト量の偏りに関係なく統計的に正確なパーセンタイルが算出されます。
GMP→Datadog(等重み平均)
(0.15 + 0.20 + 1.00) / 3
全リクエストの分布から p99
この問題は avg にも p99/p95 にも同様に影響していました。つまり、GKE 移行によってメトリクスの値が変わったのではなく、移行をきっかけにより正確な値が得られるようになったということです。
Datadog のメトリクス課金モデル
prometheusScrape のような便利機能を安易に有効化すると、意図しない Pod のメトリクスまで課金対象になります。今回は多数の Pod が意図せずスクレイプされていました。Autodiscovery アノテーションでの個別制御と empty_default_hostname の設定が基本だと学びました。
パーセンタイルの集約は統計的に難しい
datacenter ごとに事前計算したパーセンタイルを平均しても、正確な値にはなりません。DDSketch のような mergeable なデータ構造を使うか、生の histogram bucket をマージしてからパーセンタイルを計算する必要があります。「ダッシュボードの数字が合わない」という現象の裏に、こうした統計的な落とし穴があることを身をもって学びました。
Pod のスケジューリングはインフラ全体を見る
DD Agent の nodeAffinity と Prometheus Fastly Exporter の配置先が一致しないとメトリクスが届かない、という問題は Pod 単体の設定だけでは気づけません。同一ノード上の他のコンポーネントとの依存関係まで意識する必要があると感じました。
今回のインターンを通して、Prometheus Fastly Exporter の Cloud Run → GKE 移行を完了しました。単純な移行作業にとどまらず、DD Agent の OpenMetrics チェックの設定調整、パーセンタイル集約の統計的な正確性の検証まで幅広く取り組みました。
移行前後でダッシュボードの値に乖離がありましたが、調査の結果、DDSketch による新しい値の方が正確であることがわかり、むしろ移行によってメトリクスの精度が向上しました。
インターン開始時点では Kubernetes や Terraform を実務で触った経験がなく、複数リポジトリにまたがる構成を読み解き、それぞれの用語や役割を調べるところから始まりました。最初は Helm Chart の values や Terraform の state を追うだけでも時間がかかりましたが、トレーナーのヤドンさんをはじめ、server チームや platform チームの皆さんにレビュー・サポートしていただいたおかげで、最終的には prd 環境へのリリースまで完遂できました。
技術的な実務だけでなく、複数の事業部の方々とのランチの機会も作っていただき、事業部ごとの文化や開発への向き合い方、キャリアや普段の暮らしなど幅広いお話を聞くことができました。視野が広がる貴重な経験をいただいたことに感謝しています。
技術的に成長できたことはもちろん、WinTicket で働く人たちの雰囲気を肌で感じられたことも含め、とても充実したインターン期間を過ごせました。ありがとうございました。
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み