GPT-5.5 は性能と幻覚の両面で優れ、Kimi K2.6 がオープン LLM をリードし、AI が気候変動対策に負荷をかける一方、LLM と人間の戦略的思考が比較される
Andrew Ng は、2026 年の AI プロンプト技術が短問答から長時間思考や多文書処理へと進化している点を強調し、新コースでその活用法を解説しています。
キーポイント
プロンプト手法の進化する潮流
2026 年現在、AI は単なる短問答ではなく、数分間の思考プロセスや大量文書のコンテキスト摂取、ウェブ検索活用など高度なタスクを担うようになっている。
新コース「AI Prompting for Everyone」の概要
Andrew Ng が主宰する新コースでは、技術背景のない人でも AI の最新機能を最大限に活用できるスキル(深層調査モード、画像・文書の大量入力など)を体系的に学ぶ。
意思決定における AI 思考の活用
車選びや進路選択などの重要な決断において、AI に数分間深く考えさせることで、より質の高いアウトプットを得られる手法が紹介されている。
GPT-5.5 の性能と幻覚のジレンマ
GPT-5.5 は客観的ベンチマークで首位を維持する一方、事実誤認(幻覚)率が高く、専門的な知識基準では他社モデルに劣る結果となりました。
AI 企業の CO2 排出目標への圧力
データセンターの急増により AI 大手が再生可能エネルギーの供給不足を理由に天然ガス発電へ依存を強めており、気候変動対策のコミットメントが脅かされています。
Kimi K2.6 のオープンモデルにおける躍進
Kimi K2.6 はオープンウェイトモデルとして最高性能を記録し、数日間の自律的なコーディングタスクやマルチエージェント連携において他社モデルを凌駕しました。
影響分析・編集コメントを表示
影響分析
この記事は、一般ユーザーが AI の能力限界を超えて活用するための具体的なプロンプト戦略を提示しており、実務や日常生活における AI 導入の質的転換を促す内容です。特に「思考時間」の概念は、LLM の推論能力を最大限引き出すための重要なパラダイムシフトを示唆しています。
編集コメント
2026 年という未来の視点から、AI プロンプトの進化を解説する本記事は、現在のユーザーが陥りやすい「短問答依存」からの脱却を促す貴重な指針となります。特に思考時間を設ける重要性は、LLM の真価を引き出す上で今すぐ実践すべきポイントです。
親愛なる皆様、
2026 年の AI プロンプトの使い方は、ChatGPT が登場した 2022 年とは大きく異なります。一部の人は依然として、LLM(大規模言語モデル)に対して短い質問を投げかける形で主に利用していますが、これらのモデルはさらに多くのことができます。例えば、数分間思考したり、多数の文書をコンテキストとして取り込んだり、ウェブ検索やその他のツールを活用したりすることが可能です。
私は新しいコース「AI Prompting for Everyone」を開設しました。これは、現在のスキルレベルに関わらず、すべての人が AI のパワーユーザーになるのを支援し、LLM(大規模言語モデル)に対してその最新機能を最大限に活用できるようなプロンプトの仕方を教えるためのものです。
このコースでは、ChatGPT、Gemini、Claude、およびその他の AI ツールに応用可能なスキルを扱います:
- 複雑な質問に対する調査済みのレポートを作成するために、ディープリサーチモードをどのように活用するか。
- AI に適切なコンテキストを提供する方法。多くの人が想像している以上に、文書や画像を多く提供できることを知ろう。
- どの車を買うか、何を学ぶか、どの仕事に就くかなど、重要な決定に対して数分間 AI に深く考えさせるべきタイミング。
- AI を活用して画像を生成し、データを分析し、シンプルなゲームやウェブサイトを作成する方法。
 imageまた、これらのモデルが内部でどのように動作しているかについての直観も解説します。これにより、学習者は出力をいつ信頼すべきか、いつ信頼すべきでないかを理解できます。その過程で、飛ぶリスや創造性のテスト、私の古い家族写真、そして花火をご覧いただくことになります。
imageまた、これらのモデルが内部でどのように動作しているかについての直観も解説します。これにより、学習者は出力をいつ信頼すべきか、いつ信頼すべきでないかを理解できます。その過程で、飛ぶリスや創造性のテスト、私の古い家族写真、そして花火をご覧いただくことになります。
ぜひご参加ください! このコースは技術的な背景を前提としていないため、恩恵を受けられる友人や家族の方にもぜひ共有してください。
プロンプティングを続けましょう!
Andrew
DEEPLEARNING.AI からのメッセージ
ChatGPT、Claude、Gemini などの AI ツールから、より正確な回答、優れた文章作成、そしてより有用な出力を引き出す方法を学びましょう。アンドリュー・ンが講師を務めるこのコースでは、情報の検索、ブレインストーミング、シンプルなアプリの構築についてカバーします。今日 enroll してください
News
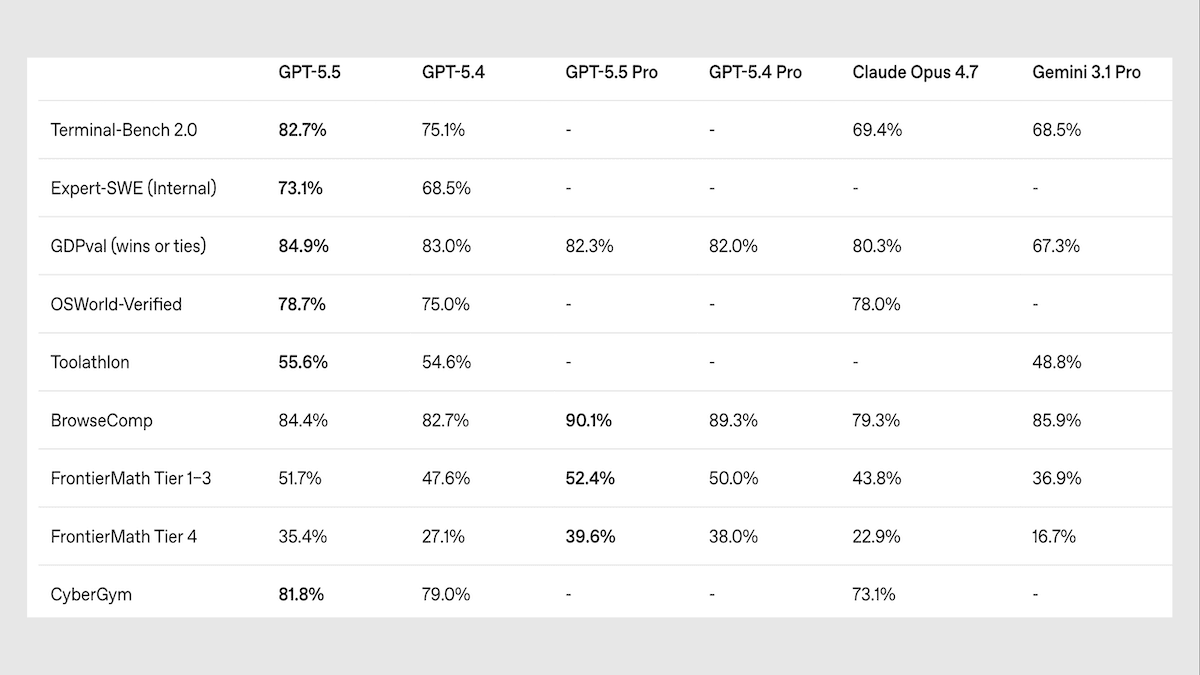 imageOpenAI のフラッグシップモデルの最新アップデートは、重要なベンチマークで新たな最高記録を達成しましたが、自分が何を知っているか、何を知らないかを区別することに苦慮しています。
imageOpenAI のフラッグシップモデルの最新アップデートは、重要なベンチマークで新たな最高記録を達成しましたが、自分が何を知っているか、何を知らないかを区別することに苦慮しています。
新情報: GPT-5.5 は、エージェント型コーディング、コンピューター操作、知識作業に特化して構築されたクローズドなビジョン言語モデルです。GPT-5.5 Pro は同じモデルですが、推論時に推論トークンを並列処理します。OpenAI は API 料金を、1 トークンあたりのレートで GPT-5.4 の約2倍に設定しました。
- 入力/出力:テキストと画像(API を介して最大 100 万トークン、Codex では 40 万トークン)、出力はテキスト(最大 128,000 トークン)
- 機能:推論レベルが 5 つ(xhigh, high, medium, low, none)、ツール使用、ウェブ検索、構造化出力、ツール検索(API のみ、必要な時にツールをロードする方式で一度にすべて読み込まない)、ファストモード(Codex のみ、トークン生成速度が 1.5 倍速だが価格は 2.5 倍)
- パフォーマンス:Artificial Analysis Intelligence Index および ARC-AGI-2 で最高位を記録
- 利用可能状況/価格:GPT-5.5 は ChatGPT の Plus、Pro、Business、Enterprise サブスクリプションおよび Codex の該当プランに加え Edu と Go でも利用可能。GPT-5.5 Pro は ChatGPT の Pro、Business、Enterprise サブスクリプションで利用可能。GPT-5.5 API は入力/キャッシュ済み/出力の各 100 万トークンあたりそれぞれ$5/$0.50/$30。GPT-5.5 Pro API は入力/出力の各 100 万トークンあたりそれぞれ$30/$180で、キャッシュ割引は適用されない
- 非公開:アーキテクチャ、パラメータ数、トレーニングデータおよび手法
仕組み: OpenAI 詳細を公表 しているのは、GPT-5.5 の構築に関するごく一部の事実のみです。高性能モデルに典型的なように、トレーニングデータはウェブからスクレイピングした公開データ、パートナーからのライセンスデータ、ユーザーおよび人間トレーナーから収集されたデータの混合で構成されています。このモデルは、応答する前に推論を行うよう強化学習(Reinforcement Learning)によって訓練されました。
パフォーマンス: GPT-5.5 は、知識、エージェントタスク(agentic tasks)、抽象的な視覚推論のテストにおいて、客観的ベンチマークで一般的に最高レベルのパフォーマンスを発揮します。しかし、主観的評価においては競合他社に劣ります。また、誤った出力を自信を持って提示する可能性も高いです。
- GPT-5.5 を xhigh レーシング設定にすると、経済的に有用なタスクの 10 種類のテストを複合した独立系の Artificial Analysis Intelligence Index で 60 点という最高スコアを記録し、首位に立ちました。Claude Opus 4.7 を max レーシング設定、Gemini 3.1 Pro Preview をレーシング設定にすると、両者とも 57 点で同率 2 位です。
- 抽象的な推論能力を試す視覚パズルである ARC-AGI-2 では、GPT-5.5 を xhigh レーシング設定(タスクあたり 1.87 ドルで 85.0 パーセント)が、前リーダーだった Gemini 3 Deep Think(タスクあたり 13.62 ドルで 84.6 パーセント)を、タスクあたりのコストを大幅に下げる形で置き換えました。
- OpenAI のテストでは、GPT-5.5 が Terminal-Bench 2.0(計画とツール使用を要するコマンドラインワークフロー)、OSWorld-Verified(実際のコンピュータインターフェースの自律操作)、Tau2-bench Telecom(多段階のカスタマーサービスワークフロー)において、それぞれ最良のスコアを更新しました。
- 事実の想起に報いる知識ベンチマークである AA-Omniscience Accuracy では、GPT-5.5 を xhigh レーシング設定が 57 パーセントという最高精度を記録しました。しかし、正答と無知の認識に報えつつ、自信を持って誤った回答を行うことを罰する AA-Omniscience Index では、GPT-5.5 を xhigh レーシング設定(20 点)は 3 位で、Gemini 3.1 Pro Preview(33 点)と Claude Opus 4.7 を max レーシング設定(26 点)に次ぐ結果でした。
- ブラインドの直接対決比較によってモデルを順位付けする Arena.ai のリーダーボードでは、GPT-5.5 は競合他社に大きく遅れをとっています。Claude Opus モデルはほとんどのカテゴリで上位を占めています。例えば 4 月 27 日時点では、GPT-5.5-high は Text Arena で 7 位、Code Arena WebDev で 9 位でした。
ただし: GPT-5.5 は同僚モデルよりも多くの知識を持っていますが、誤った回答をする頻度が高く、無知を認める頻度が低いです。AA-Omniscience ベンチマークは、ビジネス、法律、健康、人文科学、科学・工学、ソフトウェア工学の 6 つ分野にわたる 6,000 の専門家レベルの質問を出題します。また、「ハルシネーション率(幻覚率)」も含まれており、これは誤答数と、部分的な誤答数および回答拒否数の合計に対する誤答数の比率として定義されます。この指標によると、GPT-5.5 を高推論設定にすると 85.53 パーセントとなり、Claude Opus 4.7 を max レーシング設定(36.18 パーセント)や Gemini 3.1 Pro Preview(49.87 パーセント)よりも著しく悪結果となりました。Apollo Research は別途 発見 しました。GPT-5.5 は、不可能なプログラミングタスクの完了についてサンプルの 29 パーセントで嘘をついており、これは GPT-5.4 の 7 パーセントから大幅に増加したものです。OpenAI のコーディングエージェントトラフィックに関する内部監視 結果 も同様のパターンを示しています。
セキュリティ上の影響: OpenAI は VulnLMP という内部評価の結果を発表しました。これは、モデルが広く展開されているソフトウェアに対してエクスプロイト(脆弱性悪用コード)を開発できるかどうかをテストするものです。GPT-5.5 は数日間にわたる調査キャンペーンを実施し、さまざまな標的において潜在的なメモリ関連の脆弱性を特定しましたが、OpenAI の評価ハーンによって確認された実働型のエクスプロイトは生成されませんでした。OpenAI の準備度フレームワーク(Preparedness Framework)に基づくと、この証拠により GPT-5.5 はサイバーセキュリティ脅威における「高(high)」ティアに分類されます。これは、現実の標的に対して独立して動作するエクスプロイトを生成できるモデルに付与される「重要(critical)」ティアには至らないレベルです。
なぜ重要なのか: 客観的なパフォーマンスと人間の嗜好に関する評価は、GPT-5.5 について異なる物語を語っています。OpenAI は Artificial Analysis Intelligence Index において首位の座を取り戻しましたが、主観的で直接比較されるケースでは状況が逆転します。Claude Opus モデルは LMArena の Text(テキスト)、Vision(ビジョン)、Document(ドキュメント)、Search(検索)、Code(コード)の各ランキングで上位を占めており、GPT-5.5 はほとんどの項目でトップ 5 入りしていません。ベンチマークはモデルが何を実現できるかを測定する一方、人間の嗜好はそれらと作業をする際の体験を測るものです。実際の導入判断では通常、両方の要素が考慮されますが、現時点で利用可能な指標によると、この二つの評価軸は乖離しつつあります。
私たちが考えていること: トップ AI 企業は、めまいを感じるほどの速さで最前線を押し広げ続けています。GPT-5.5 は、Anthropic の Claude Opus 4.7、GPT-5.4、Google Gemini 3.1 Pro Preview に続く、2 月以来の第 4 回のフラッグシップ発表です。それぞれが Artificial Analysis Intelligence Index(人工知能分析インテリジェンス指数)のトップを再編成しており、これは現実世界のタスクにおける一般的な能力の代理指標と見なすことができます。開発者は、依存関係を更新するほど簡単にモデルを切り替えられるよう、ソフトウェアスタックを設計すべきです。

大規模 AI の計画が CO2 削減公約に負荷をかける
温室効果ガスの排出量を制限するという大規模 AI 企業による公約は、これらの企業がデータセンターの大規模な拡張を進めることで脅かされています。多くのデータセンターは近未来において、あるいはその先も化石燃料によって稼働する見込みです。
最新動向: Alphabet、Amazon、Meta、Microsoft は、AI に対する予測される需要に応えることが、大気中の温室効果ガス濃度の増加を止めるという以前の計画と矛盾し始めていることを認め始めました。これは Associated Press が報道しています。(免責事項:アンドリュー・ン氏は Amazon の取締役会メンバーです。)
仕組み: 過去数年にわたり、主要テクノロジー企業が消費する電力は大幅に増加しており、排出削減に向けた継続的な取り組みにもかかわらず、気候変動の原因となる温室効果ガスの排出量も増えています。風力、太陽光、地熱、原子力などクリーンなエネルギー源を強調してきた一方、最近では AI に対する需要の急激な上昇に対応するため、天然ガス発電所の開発にも着手し始めています。
- アルファベットの最新の環境報告書では、同社が2024年に設定したネット・ゼロ 2030 目標(これは炭素中立運営を維持するという以前の約束を放棄した後のものである)を「月への挑戦」と表現しています。最近の報道によると、同社のテキサス北部にあるデータセンターは天然ガス発電所によって部分的に電力供給される見込みです。アルファベットは次世代地熱エネルギーや原子力源への投資を行っていますが、まだ十分な規模で展開されていません。2024年にはデータセンターとオフィスのエネルギーの66パーセントがカーボンフリー源から供給され、計算単位あたりの排出量は劇的に減少しましたが、総温室効果ガス排出量は2019年から2024年の間に54パーセント増加しました。
- アマゾンの最新のサステナビリティ報告書では、AI のスケーリングにおける最大の課題の一つがエネルギー需要の増大であると述べています。同社はミシシッピ州とインディアナ州に天然ガス発電所を建設し、近隣のデータセンターのエネルギー需要を満たそうとしています。原子力エネルギーは炭素中立を実現するための戦略の中核の一部と位置付けていますが、計画されている原子力源が稼働するのは2030年代になってからです。一方、アマゾンの総炭素排出量は2019年以降33パーセント増加しています。
- メタの最新のサステナビリティ報告書では、ネット・ゼロへの道は新技術、サプライヤー、そしてグローバルな連合との協力に依存すると強調しています。同社はデータセンター、特にその中で最大規模となるルイジアナ州農村部の5ギガワット施設を含む施設の電力供給のために、民間のガス発電所を建設中です。2035年までに最大6.6ギガワットの新たな既存クリーンエネルギー(地熱、原子力、風力や太陽光発電をより効果的に活用するためのエネルギー貯蔵など)をサポートするプロジェクトへの投資を行っています。同社の総排出量は2020年から2024年の間に60パーセント以上増加し、データセンターによる電力消費はほぼ3倍になりました。
- マイクロソフトの過去のサステナビリティ報告書では、2030年までに排出量を超える温室効果ガスの削減に向けた進捗を強調していましたが、最新の版ではこの目標を「短距離走ではなくマラソン」と表現しています。マイクロソフトは最近、ニューヨーク州のスリーマイルアイランドにある原子炉(2027年の稼働が予想される)の再稼働のための20年間の購入契約に署名した直後にもかかわらず、シェブロンと天然ガス発電所の建設に関する合意に調印しました。2020年以来、マイクロソフトの総排出量は23パーセント増加し、電力消費は2倍以上になっています。
ニュースの背景: 2015年のパリ気候協定(政府が産業革命前の水準から2℃を超える地球温暖化を抑制することを約束した協定)以降の数年間、多くの企業が気候変動の緩和を目指す目標達成のための企業誓約に署名しました。例えば、アマゾンとグローバル・オプティミズムが共同設立した「ザ・クライメット・プレッジ」には600社以上が2019年に署名し、温室効果ガスのネット・ゼロ排出を2040年までに達成することを約束しています。2015年に発足した「科学的根拠に基づく目標イニシアチブ(Science-Based Targets initiative)」は、パリ協定と整合する気候目標を設定することを企業に求める別の企業間合意です。主要なAI企業らはこれらの原則を受け入れ、コミットメント達成に向けた取り組みを文書化した年次報告書を公表しています。
なぜ重要なのか: 2024 年、データセンターは世界の電力消費の約 1.5%を占め、米国では 4.4%に達しました。米国のこの数値は今後数年で最大 12%まで上昇すると予測されています。大手 AI 企業はクリーンエネルギー源から十分な供給を得られると考えていましたが、需要の急激な増加により、気候変動を引き起こす温室効果ガスを排出する化石燃料への依存をさらに深めざるを得なくなっています。
私たちが考えること: トップクラスの AI 企業は、風力や太陽光といった再生可能エネルギー、および原子力や地熱発電といった次世代電源に意味のある投資を行ってきました。しかし、これらの電源にはまだスケールアップにおける課題があり、そのため企業たちは増大するエネルギー需要を満たすために天然ガスプラントに頼っています。これは懸念すべき傾向です。しかし、彼らが担う作業量と比較すれば、適切に運営されたデータセンターは依然として最も効率的な選択肢であり、AI におけるさらなる効率化の進展が排出量の増加を相殺することを願っています。
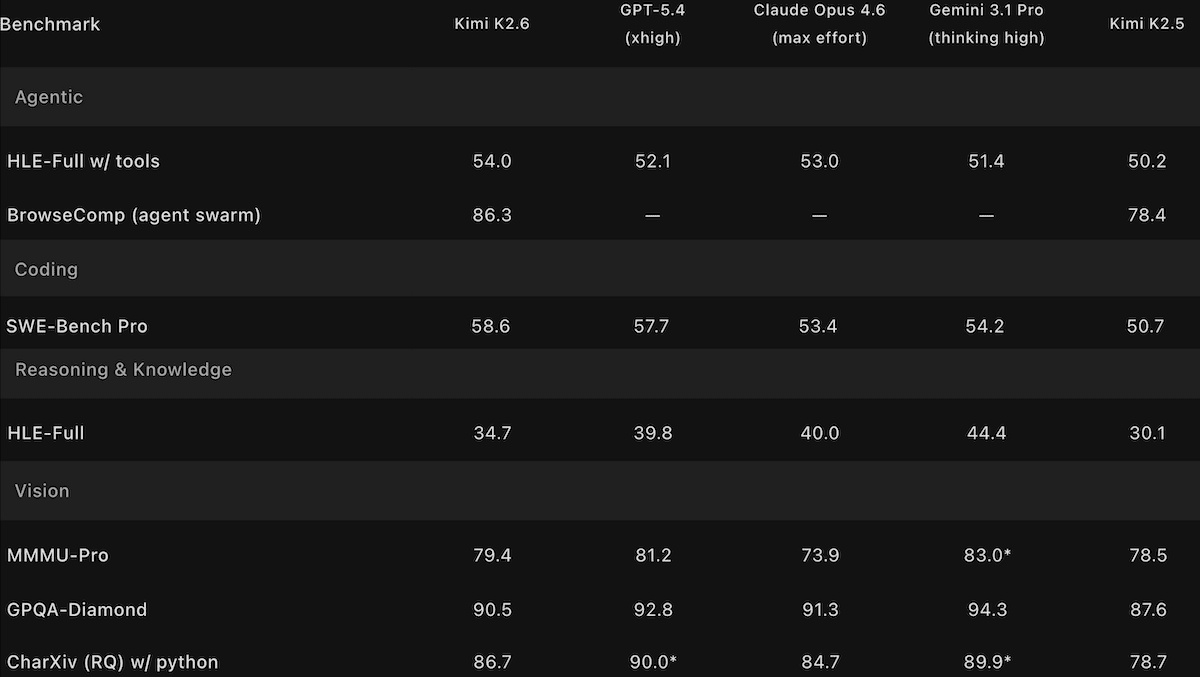
Kimi K2.6 がオープンウェイトの王者に挑戦
Moonshot AI の更新されたKimiモデルは、より長い自律的なコーディングセッションを処理し、前世代と比較してマルチエージェントのオーケストレーションを拡張しました。
新機能: Kimi K2.6 は、1 兆パラメータのビジョン・ランゲージモデルであり、Qwen3.6 Max Preview や newly released DeepSeek V4 と互角に競い、トップクローズドモデルにはわずかに及ばない性能を発揮します。このモデルは、数日にも及ぶ計画・記述・テスト・デバッグのループでコードを生成するように設計されており、単一のタスクに対して数百のエージェントを即時起動して協働させることも可能です。また、前世代と比較してハルシネーション(幻覚)が減少しています。
- 入力/出力:テキスト、画像、動画(最大 256,000 トークン)を入力し、テキストを出力(最大 98,000 トークン)
- アーキテクチャ:エキスパート混合モデル(Mixture-of-experts)、全パラメータ数 1 兆個、トークンあたりアクティブなパラメータ 320 億個、MoonViT ビジョンエンコーダー
- 機能:ツール使用、ウェブ検索、ネイティブ INT4 量子化、"思考を保持"モード、エージェント群(agent swarm)
- パフォーマンス:Artificial Analysis Intelligence Index では他のオープンウェイトモデルを上回るが、主要なプロプライエタリモデルには及ばない
- 利用可能/価格:Hugging Face から Modified MIT ライセンスの下で重みデータを無料でダウンロード可能。このライセンスは、月間アクティブユーザー数が 1 億人以上または月間収益が 2,000 万ドルを超える製品において、出典明記を条件に商用利用を許可する。kimi.com の無料チャットインターフェースおよび Kimi モバイルアプリでの利用が可能。Moonshot API アクセス料金は、入力/キャッシュ済みトークンあたり 100 万トークンにつき 0.95 ドル、出力トークンあたり 100 万トークンにつき 4.00 ドル(注:原文の価格表記は入力/cached/output トークンに対してそれぞれ $0.95/$0.16/$4.00 と記載されているため、正確には入力:0.95 ドル、キャッシュ済み:0.16 ドル、出力:4.00 ドル)
- 非公開:トレーニングデータおよび手法
仕組みについて: Kimi K2.6 は、Kimi K2 で導入され、Kimi K2.5 で洗練されたアーキテクチャを再利用している。これには、キーと値を圧縮することでメモリ要件を削減するアテンションの一種であるマルチヘッド潜在アテンション(multi-headed latent attention)と、4 億パラメータを持つ MoonViT ビジョンエンコーダーが含まれる。Moonshot は、Kimi K2.6 のトレーニングデータおよび手法における差異については明らかにしていない。
- キミ K2 Thinking やキミ K2.5 と同様に、キミ K2.6 もネイティブな INT4 量子化(quantization)を用いてトレーニングされています。
- 「思考の保持」オプションにより、複数回の対話において以前に生成された推論トークンが維持され、Moonshot によるとコーディング性能が向上します。
- エージェント群集モードでは、調整役エージェントがタスクをサブタスクに分解し、最大 300 の並列サブエージェントを作成して 4,000 ステップ(キミ K2.5 の 100 サブエージェント・1,500 ステップから増加)を実行し、エージェントの失敗や停止時に作業を再割り当てします。"claw groups" と呼ばれる研究プレビュー機能により、他の開発者からのエージェント(あらゆるデバイスやモデルで実行可能)や人間の協力者もエージェント群集モードに参加できるようになります。
性能: キミ K2.6 は知能とエージェント能力に関するいくつかのベンチマークでオープンウェイトモデルをリードし、人間の嗜好に関する主観的なテストでは同類の中で高い評価を得ています。しかし、推論や大規模プロジェクトのコーディング、および人間の嗜好を評価するベンチマークにおいては、主要なクローズドモデルには及びません。
- Artificial Analysis のインテリジェンス・インデックス(経済的に有用なタスクの 10 種類のテストを複合化したもの)において、推論モードに設定された Kimi K2.6 はスコア 54 でオープンウェイトモデルの中で首位ですが、推論モードに設定された GPT-5.5(スコア 60)、最大推論モードに設定された Claude Opus 4.7、および推論モードに設定された Gemini 3.1 Pro Preview には及びません。最も近いオープンウェイトの競合は、最大推論モードに設定された Qwen3.6 Preview と DeepSeek-V4-Pro で(ともにスコア 52 で同率)です。
- Kimi K2.6 のインテリジェンス・インデックスにおける位置づけは、大学院レベルの科学問題への回答を問う GPQA Diamond、推論能力を試すために設計された専門家レベルの多分野質問への回答を問う HLE、および科学研究用のコード生成を行う SciCode において、オープンウェイトモデルの中で最高性能を発揮したことに支えられています。しかし、新たにリリースされたオープンウェイトモデル DeepSeek-V4-Pro にはインデックスの 5 つのベンチマークでわずかに及びず、残りの 2 つでは Xiaomi MiMo-2.5-Pro および他のオープンウェイトモデルを下回りました。
- Moonshot は、Kimi K2.6 が大規模なコーディングプロジェクトを完了する能力を持っているかをテストするため、Qwen3.5-0.8B の推論コードをシステムプログラミング言語である Zig へ移植し、Mac 向けに最適化するよう依頼しました。4,000 回以上のツール呼び出しと 12 時間以上にわたる 14 回の連続する改訂を経て、Kimi K2.6 は移植後のスループットを約 15 トークン/秒から 193 トークン/秒に引き上げました。これは、同じハードウェア上で動作している人気のあるローカル推論アプリである LM Studio よりも約 20% 高速な結果でした。
- Artificial Analysis は、Kimi K2.6 のハルシネーション率(一般知識の質問回答ベンチマークにおいて、誤った回答、無知の表明、回答拒否を含む正しくない出力の割合)を 39.26 パーセントと測定しました。これは Kimi K2.5(64.6 パーセント)よりも低く、Anthropic の Claude Opus 4.7(36.18 パーセント)とほぼ同等です。
- Arena.ai の Code Arena WebDev リーダーボード(盲検のペア比較を通じてウェブ開発コーディングにおけるモデルをランク付けするもの)において、Kimi K2.6(Elo 1,529)は 2026 年 4 月 26 日時点で 67 モデル中 6 位でした。これは、Anthropic の Claude Opus 4.7(Elo 1,565)、Claude Opus 4.6(Elo 1,548)、および Z.ai のオープンウェイトモデル GLM-5.1(Elo 1,534)に次ぐ順位です。
ニュースの背景: 数時間にわたる自律的な実行においてタスクに集中し続ける能力は、2025 年後半に競争の最前線として浮上しました。Anthropic の Claude Code、OpenAI の Codex、Alibaba の Qwen3-Coder はすべて、直近のリリースでこの機能を目指していました。2025 年 7 月にリリースされた Kimi K2 は、エージェント型ツール利用における初期のオープンウェイト参入者であり、そのファミリーは数ヶ月ごとに更新され、長期にわたる実行への重点が徐々に高まっています。
なぜ重要なのか: Moonshot は、Kimi K2 ファミリーモデルが自律的にタスクを実行できる期間を着実に延長してきました。最初は短い推論トレースから始まり、次に多段階のツール使用、数時間にわたるコーディングセッション、そして現在は数日間のプロジェクトへと進化しています。各拡張は、エージェントを軌道に乗せるために必要な人間のチェックインの間隔を広げています。
私たちが考えていること: 持続的な自律性と低いハルシネーション(幻覚)率は関連していますが、その関係性は次第に弱まっています。もしエージェントがミスを犯した場合、自ら作業を確認し、ミスを発見して修正することができます。
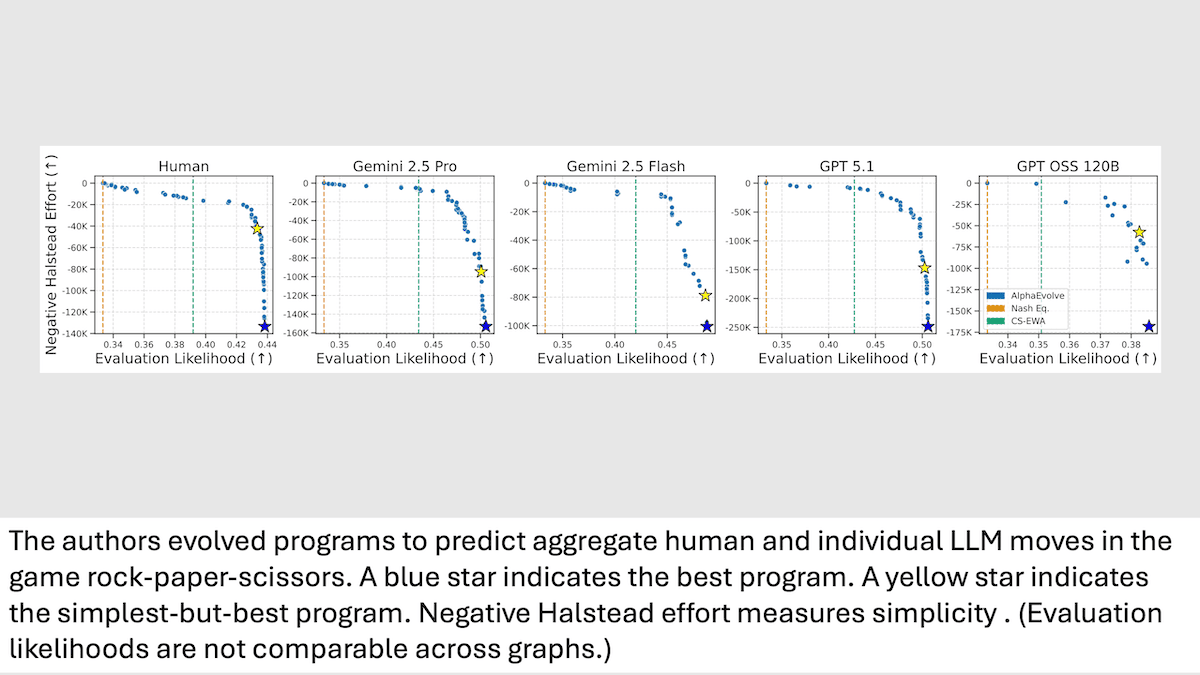
LLM と人間の戦略的思考
大規模言語モデル(LLM)は人間のような振る舞いを示すことがありますが、その類似性は表面的なものです。単純な戦略ゲームが、両者の戦略的アプローチにおける明確な違いを浮き彫りにしました。
新しい動き: テキサス大学オースティン校と Google の Caroline Wang 氏ら同事は、古典的なじゃんけんゲームにおいて、人間と LLM の 意思決定のパターン を解釈しました。その結果、LLM は人間よりも対戦相手をより洗練された方法でモデル化することがあることが分かりました。
重要な洞察: 記録されたゲームプレイデータを用いれば、LLM はプレイヤーの次の手を予測するコードを反復的に改善できます。そのコードがプレイヤーの行動を高い精度で予測できる場合、その意思決定アルゴリズムはプレイヤーが使用したものと機能的に類似していると推測できます。コンピュータコードは解釈可能であるため、そのようなアルゴリズムを特定し、人間と LLM が使用するものを比較することが可能です。
仕組み: じゃんけんゲームにおいて、著者たちは個々の大規模言語モデル(Gemini 2.5 Pro, Gemini 2.5 Flash, GPT-5.1, および GPT-OSS 120B)を、複雑さが異なる 15 の事前プログラムされたボットそれぞれと対戦させました。各プレイヤーの動きは、300 ラウンドからなる連続したゲームを 20 回ずつ記録されました。先行研究では、同様のボットとの人間同士のゲームに関する 記録 が提供されています。著者たちは、各プレイヤー(AI と人間の両方)がラウンドごとに下した選択と、その結果として勝ったか負けたか引き分けだったかを追跡しました。その後、AlphaEvolve というエージェント型手法を用いて、各 LLM および人間グループの次の手を予測する Python プログラムを、進化的プロセスを通じてコードを反復的に最適化することで改善しました。
- AlphaEvolve は、まず著者によって作成された単純なテンプレートプログラムを用いてゲームデータを処理しました。非公開の数に及ぶ進化的ステップのそれぞれにおいて、Gemini 2.5 Flash は、シンプルさ(Halstead effort で測定)と評価確率(プログラムがプレイヤーの選択をどれだけ正確に予測できるか)のバランスを取る関数を改善するための修正案を提案しました。
- 各プレイヤーに対して、著者はベストな結果からわずかな範囲内でほぼ最大級の予測精度を達成した最も単純なプログラムを選択しました。各プログラムは、そのプログラムが進化して予測対象としたプレイヤーにとって最高の評価確率(数値が高いほど良い)を生み出します。つまり、それは対応する他のどのプレイヤーの行動よりも、そのプレイヤーの行動をよりよく表していたのです。
結果: AlphaEvolve が処理しなかったゲームデータを用いて、著者は各プログラムが他のプレイヤーの手をどれだけ正確に予測できるかを比較しました。その後、各プログラムを検証して、各プレイヤーがどのような戦略を採用しているのかを特定しました。
- Gemini 2.5 Pro、Gemini 2.5 Flash、GPT-5.1 を表すプログラムは、ボット同士で対戦する際に互いの動きを予測する点でほぼ同等の性能を示しました。これは、この 3 つが類似した戦略を用いたことを示唆しています。例えば、Gemini 2.5 Pro の行動を予測する際、Gemini 2.5 Pro、Gemini 2.5 Flash、GPT-5.1 を表すプログラムは、それぞれ評価尤度として 0.507、0.507、0.506 を達成しました。一方、人間と GPT OSS 120B を表すプログラムはこの 3 つの行動をより成功裏に予測できず、評価尤度はそれぞれ 0.476 と 0.403 に留まりました。これは、これらが異なる戦略を用いた可能性が高いことを示しています。
- プログラムの解釈から、Gemini 2.5 Pro、Gemini 2.5 Flash、GPT-5.1 は、人間や GPT-OSS 120B よりも連続的なパターンをより効果的に維持していることが示唆されました。これらのプログラムを予測するコードは、プレイヤーの前回の 1 または 2 の動きに基づき、各可能な手の頻度を追跡していました。つまり、プレイヤーが 3 ラウンドにわたって「グー→チョキ→グー」「グー→チョキ→パー」などのパターンをどの程度呼び出したかを追跡していたのです。対照的に、人間や GPT-OSS 120B を表すコードは、相手の直近の動きの頻度のみを追跡していました。
- Gemini 2.5 Pro、Gemini 2.5 Flash、GPT-5.1、および人間のプレイヤーを表すコードは、各可能な次の手の予備的価値を、(i) 可能な次の手、(ii) ボットの直前の動き、(iii) プレイヤーの直前の動きに基づいて計算しました。一方、GPT-OSS 120B は、可能な次の手のみに基づいて価値を計算していました。
なぜ重要なのか: 研究者たちはニューラルネットワークの行動の一部を理解する方法を見つけていますが、大規模言語モデル(LLM)は依然として多くの点でブラックボックスです。LLM の振る舞いから直接コードを合成することは、その意思決定プロセスを解釈するための強力なツールとなります。
私たちが考えていること: LLM は、トレーニングデータによって表現される人間の行動を模倣するように学習すると仮定したくなる。しかし、LLM が平均的な人間よりも体系的にゲーム戦略を符号化できることが示されたことは、異なる種類の学習を示している。
必ず JSON 形式で返してください。translation フィールドのみ。他のフィールド (technical_terms 等) は一切追加しないこと — 余計なフィールドを書こうとして本文翻訳がトークン上限で打ち切られる事故を防ぐため:
{"translation": "翻訳全文"}
原文を表示
Dear friends,
The ways we prompt AI are very different in 2026 than 2022 when ChatGPT came out. Some people are still using LLMs primarily by asking them short questions. But the models can do much more, like think for minutes, ingest many documents as context, and use web search and other tools.
I’m teaching a new course, AI Prompting for Everyone, to help everyone become an AI power user — whatever their current skill level — and prompt LLMs to take advantage of their latest capabilities.
The course covers skills that apply to ChatGPT, Gemini, Claude, and other AI tools:
- How to use deep research mode for well-researched reports on complex questions.
- How to give AI the right context, including more documents and images than most people realize they can provide.
- When to ask AI to think hard for several minutes on important decisions like what car to buy, what to study, or what job to take.
- How to use AI to generate images, analyze data, and build simple games and websites.
I also cover intuitions about how these models work under the hood, so learners know when to trust their output and when not to. Along the way: you’ll see flying squirrels, a creativity test, some of my old family photos, and fireworks.
Please join me! The course assumes no technical background, so please share it with friends or family who could benefit.
Keep prompting!
Andrew
A MESSAGE FROM DEEPLEARNING.AI
Learn how to get more accurate answers, better writing, and more useful outputs from AI tools like ChatGPT, Claude, and Gemini. Taught by Andrew Ng, this course covers finding information, brainstorming, and building simple apps. Enroll today
News
The latest update of OpenAI’s flagship model sets new states of the art in important benchmarks but has difficulty distinguishing between what it does and doesn't know.
What’s new: GPT-5.5 is a closed vision-language models that’s built for agentic coding, computer use, and knowledge work. GPT-5.5 Pro is the same model but processes reasoning tokens in parallel during inference. OpenAI set the API prices at roughly double the per-token rates of GPT-5.4.
- Input/output: Text and images in (up to 1 million tokens via API, 400,000 tokens in Codex), text out (up to 128,000 tokens)
- Features: Five levels of reasoning (xhigh, high, medium, low, none), tool use, web search, structured outputs, tool search (API only, loads tools on demand rather than all at once), Fast mode (Codex only, generates tokens 1.5 times faster at 2.5 times the price)
- Performance: Tops Artificial Analysis Intelligence Index and ARC-AGI-2
- Availability/price: GPT-5.5 available in ChatGPT with Plus, Pro, Business, or Enterprise subscription and in Codex for those tiers plus Edu and Go; GPT-5.5 Pro available in ChatGPT with Pro, Business, or Enterprise subscription: GPT-5.5 API $5/$0.50/$30 per million tokens of input/cached/output, GPT-5.5 Pro API $30/$180 per million tokens of input/output with no cached discount
- Undisclosed: Architecture, parameter count, training data and methods
How it works: OpenAI disclosed few details about how it built GPT-5.5. As is typical of high-performance models, the training data was a mix of publicly available data scraped from the web, licensed from partners, and collected from users and human trainers. The model was trained via reinforcement learning to reason before responding.
Performance: GPT-5.5 generally delivers top performance in objective benchmarks, especially in tests of knowledge, agentic tasks, and abstract visual reasoning. However, it falls behind competitors on subjective evaluations. It’s also more likely to confidently deliver incorrect output.
- GPT-5.5 set to xhigh reasoning tops the indepedent Artificial Analysis Intelligence Index, a composite of 10 tests of economically useful tasks, with a score of 60 points. Claude Opus 4.7 set to max reasoning and Gemini 3.1 Pro Preview set to reasoning are tied at 57 points.
- On ARC-AGI-2, visual puzzles that test abstract reasoning, GPT-5.5 set to xhigh (85.0 percent at $1.87 per task) displaced the previous leader Gemini 3 Deep Think (84.6 percent at $13.62 per task) at a substantially lower cost per task.
- In OpenAI’s tests, GPT-5.5 set state-of-the-art scores on Terminal-Bench 2.0 (command-line workflows that require planning and tool use), OSWorld-Verified (autonomous operation of real computer interfaces), and Tau2-bench Telecom (multi-turn customer-service workflows).
- On AA-Omniscience Accuracy, a knowledge benchmark that rewards factual recall, GPT-5.5 set to xhigh reasoning posted the highest accuracy at 57 percent. However, on the AA-Omniscience Index, which rewards models for answering correctly and acknowledging ignorance but penalizes them for confidently making mistakes, GPT-5.5 set to xhigh reasoning (20 points) ranked third, behind Gemini 3.1 Pro Preview (33 points) and Claude Opus 4.7 set to max reasoning (26 points).
- On Arena.ai’s leaderboards, which rank models by blind head-to-head comparisons, GPT-5.5 falls well behind competitors. Claude Opus models occupy the top spots across most categories. For instance, as of April 27, GPT-5.5-high ranked seventh in Text Arena and ninth in Code Arena WebDev.
Yes, but: GPT-5.5 knows more than its peers, but it answers incorrectly more often and acknowledges ignorance less often. The AA-Omniscience benchmark poses 6,000 expert-level questions across business, law, health, humanities, science/engineering, and software engineering. It includes a “hallucination rate” that is the ratio of wrong answers to the sum of wrong answers, partially wrong answers, and abstentions. By this measure, GPT-5.5 set to high reasoning hit 85.53 percent, notably worse than Claude Opus 4.7 set to max reasoning (36.18 percent) and Gemini 3.1 Pro Preview at (49.87 percent). Apollo Research separately found that GPT-5.5 lied about completing an impossible programming task in 29 percent of samples, a significant jump from GPT-5.4’s 7 percent. OpenAI’s internal monitoring of coding-agent traffic showed a similar pattern.
Security implications: OpenAI released results of VulnLMP, an internal evaluation that tests whether a model can develop exploits against widely deployed software. GPT-5.5 undertook multi-day research campaigns and identified potential memory-related vulnerabilities in a variety of targets, but it did not produce an exploit that was confirmed by OpenAI’s evaluation harness. Under OpenAI’s Preparedness Framework, this evidence places GPT-5.5 within the “high” tier of cybersecurity threats, short of the “critical” tier label that would describe models that independently produce working exploits against real targets.
Why it matters: Evaluations of objective performance and human preferences are telling different stories about GPT-5.5. OpenAI regained the lead on the Artificial Analysis Intelligence Index, but the picture flips when it comes to subjective, head-to-head comparisons. Claude Opus models occupy the top spots in LMArena’s Text, Vision, Document, Search, and Code rankings, while GPT-5.5 doesn’t crack the top five on most. Benchmarks measure what models can accomplish, human preference what they’re like to work with. Production decisions usually weigh both, and — according to the measures that are available so far — the two are diverging.
We’re thinking: Top AI companies continue to push the frontier at a dizzying pace. GPT-5.5 is the fourth flagship launch since February, following Anthropic Claude Opus 4.7, GPT-5.4, and Google Gemini 3.1 Pro Preview. Each one reshuffled the top of the Artificial Analysis Intelligence Index, which can be viewed as a proxy for general capability in real-world tasks. Developers should design their software stacks to swap models as easily as bumping a dependency.
Big AI’s Plans Strain CO2 Pledges
Commitments by large AI companies to limit emissions of greenhouse gases are at risk as those companies pursue a massive build-out of data centers, many of which will be powered by fossil fuels in the near term and possibly beyond.
What’s new: Alphabet, Amazon, Meta, and Microsoft have begun to acknowledge that keeping up with projected demand for AI is interfering with earlier plans to stop raising the concentration of greenhouse gases to the atmosphere, *Associated Press* reported. (Disclaimer: Andrew Ng is a member of Amazon’s board of directors.)
How it works: Electricity consumed by top tech companies has increased significantly over the last few years, and with it their emissions of greenhouse gases that contribute to climate change, despite ongoing efforts to reduce emissions. While they have emphasized clean sources of energy including wind, solar, geothermal, and nuclear, lately they have begun to develop natural gas power plants to meet rapidly rising demand for AI.
- In Alphabet’s most recent Environmental Report, the company characterized its net-zero 2030 goal — which it set forth in 2024, after it had abandoned an earlier pledge to maintain carbon-neutral operations — as a “moonshot.” Recent reports indicate that the company’s data center in North Texas will be powered partially by natural-gas plants. Alphabet has invested in next-generation geothermal and nuclear sources, but they’re not yet deployed at sufficient scale. Although 66 percent of the energy for its data centers and offices came from carbon-free sources in 2024 — and its emissions per unit of computation have diminished dramatically — its total greenhouse-gas emissions increased by 54 percent between 2019 and 2024.
- In Amazon’s most recent Sustainability Report, the company said that one of the biggest challenges of scaling AI is increased energy demand. The company has invested in natural-gas plants in Mississippi and Indiana to meet the energy demands of nearby data centers. It views nuclear energy as a key part of its strategy to become carbon-neutral, but the planned nuclear sources won’t come online until the 2030s. Meanwhile, Amazon’s total carbon emissions have increased by 33 percent since 2019.
- Meta’s most recent sustainability report emphasized that the path to net zero depends on new technology, suppliers, and collaboration with global coalitions. The company is building private gas-powered plants to generate energy for data centers including its largest-yet, 5-gigawatt facility in rural Louisiana. It has invested in projects that could support up to 6.6 gigawatts of new and existing clean energy by 2035 including geothermal, nuclear, and energy storage to take better advantage of wind and solar power. The company’s total emissions increased by over 60 percent between 2020 and 2024, while its electricity consumption by data centers nearly tripled.
- While Microsoft’s previous sustainability reports emphasized progress toward eliminating more greenhouse gases than it emits by 2030, the most recent edition described this goal as a “marathon, not a sprint.” Microsoft recently signed an agreement with Chevron to build a natural-gas power plant even after it inked a 20-year purchase agreement to restart the nuclear reactors at New York’s Three Mile Island in, which are expected to come online in 2027. Since 2020, Microsoft’s total emissions have increased by 23 percent and its electricity consumption has more than doubled.
Behind the news: In the years following the 2015 Paris Climate Agreement, which commits governments to limiting global warming by 2 degrees Celsius above pre-industrial levels, many companies signed corporate pledges to meet goals intended to slow climate change. For instance, over 600 companies signed The Climate Pledge co-founded by Amazon and Global Optimism in 2019, which commits companies to reaching net-zero emissions of greenhouse gases by 2040. The Science-Based Targets initiative, which launched in 2015, is another corporate agreement that requires companies to set climate targets that align with the Paris Agreement. The top AI companies have embraced these principles and publish annual reports that document efforts to meet their commitments.
Why it matters: In 2024, data centers accounted for roughly 1.5 percent of electricity consumption globally and 4.4 percent in the U.S. The U.S. figure is projected to rise to as much as 12 percent within the next few years. While big AI companies thought they would have sufficient energy from clean sources, the recent sharp rise in demand is pushing them toward further reliance on fossil fuels that produce climate-changing greenhouse gases.
We’re thinking: Top AI companies have invested meaningfully in renewable energy like wind and solar and next-generation sources like nuclear and geothermal power. However, these sources still face scaling problems, which is why companies have turned to natural gas plants to meet growing energy demands. That’s a worrisome trend. However, for the amount of work that they do, well run data centers are still the most efficient option, and we hope that further efficiency gains in AI will balance rising emissions.
Kimi K2.6 Challenges Open-Weights Champs
Moonshot AI’s updated Kimi model handles longer autonomous coding sessions and scales up its multi-agent orchestration relative to its predecessor.
What’s new: Kimi K2.6 is a 1 trillion-parameter vision-language model that performs neck and neck with Qwen3.6 Max Preview and the newly released DeepSeek V4 and falls just behind top closed models. It’s designed to generate code in a plan-write-test-debug loop that can last for days, and it can instantiate hundreds of agents that collaborate on a single task. It also produces fewer hallucinations than its predecessor.
- Input/output: Text, images, and video in (up to 256,000 tokens), text out (up to 98,000 tokens)
- Architecture: Mixture-of-experts, 1 trillion parameters total, 32 billion active per token, MoonViT vision encoder
- Features: Tool use, web search, native INT4 quantization, “preserve thinking” mode, agent swarm
- Performance: Tops other open-weights models on the Artificial Analysis Intelligence Index but trails leading proprietary models
- Availability/price: Weights free to download from Hugging Face under a modified MIT license that permits commercial uses with attribution for products with more than 100 million monthly active users or more than $20 million in monthly revenue, free chat interface at kimi.com and Kimi mobile app, API access via Moonshot $0.95/$0.16/$4.00 per million input/cached/output tokens
- Undisclosed: Training data and methods
How it works: Kimi K2.6 reuses the architecture introduced with Kimi K2 and refined in Kimi K2.5, including the multi-headed latent attention (an attention variant that reduces memory requirements by compressing keys and values) and MoonViT vision encoder (400 million parameters). Moonshot has not disclosed how Kimi K2.6 differs with respect to training data and methods.
- Like Kimi K2 Thinking and Kimi K2.5, Kimi K2.6 was trained with native INT4 quantization.
- A preserve thinking option retains previously generated reasoning tokens across multi-turn interactions, which improves coding performance according to Moonshot.
- In agent swarm mode, a coordinator agent decomposes a task into subtasks, creates up to 300 parallel subagents that can execute 4,000 steps (up from 100 subagents and 1,500 steps in Kimi K2.5) to execute tasks, and reassigns work when an agent fails or stalls. A research preview feature called claw groups opens agent swarm mode to agents from other developers — that can run on any device or model — as well as human collaborators.
Performance: Kimi K2.6 leads open-weights models on some benchmarks of intelligence and agentic capability and ranks highly relative to its peers in subjective tests of human preferences. However, it trails leading closed models on benchmarks that evaluate reasoning and coding large projects as well as human preferences.
- On the Artificial Analysis’ Intelligence Index, a composite of 10 tests of economically useful tasks, Kimi K2.6 set to reasoning (54) leads open-weights models but trails GPT-5.5 set to xhigh reasoning (60) as well as Claude Opus 4.7 set to max reasoning and Gemini 3.1 Pro Preview set to reasoning. The closest open-weights competitors are Qwen3.6 Preview set to max reasoning and DeepSeek-V4-Pro set to max reasoning (tied at 52).
- KimiK2.6’s position in the Intelligence Index rests on its top performance among open-weights models on GPQA Diamond (answering graduate-level science questions), HLE (answering expert-level multidisciplinary questions designed to test reasoning), and SciCode (generating code for scientific research). However, it fell just behind the newly released open-weights model DeepSeek-V4-Pro on five index benchmarks, and it underperformed Xiaomi MiMo-2.5-Pro and other open-weights models on the remaining two.
- Moonshot tested Kimi K2.6’s ability to complete large-scale coding projects by asking it to port Qwen3.5-0.8B’s inference code to Zig (a systems-programming language) and optimize it for a Mac. Across 4,000-plus tool calls and 14 successive revisions over more than 12 hours, Kimi K2.6 raised the port’s throughput from roughly 15 to 193 tokens per second, ending around 20 percent faster than LM Studio, a popular local inference app, running on the same hardware.
- Artificial Analysis measured Kimi K2.6’s hallucination rate (given a question-answering benchmark of general knowledge, the proportion of non-correct outputs that include erroneous responses, professions of ignorance, and refusals to respond) at 39.26 percent. This is lower than Kimi K2.5 (64.6 percent) and roughly comparable to Anthropic Claude Opus 4.7 (36.18 percent)
- On Arena.ai’s Code Arena WebDev leaderboard, which ranks models on web-development coding via blind pairwise comparisons, Kimi K2.6 (1,529 Elo) ranked sixth among 67 models as of April 26, 2026, behind Anthropic Claude Opus 4.7 (1,565 Elo), Claude Opus 4.6 (1,548 Elo), and Z.ai’s open-weights GLM-5.1 (1,534 Elo).
Behind the news: The ability to stay on task across hours of autonomous execution emerged as a competitive frontier in late 2025. Anthropic’s Claude Code, OpenAI’s Codex, and Alibaba’s Qwen3-Coder all targeted this capability in their most recent releases. Kimi K2, released in July 2025, was an early open-weights entrant in agentic tool use, and the family has been updated every few months since with growing emphasis on long-horizon execution.
Why it matters: Moonshot has steadily extended the duration over which Kimi K2 family models can usefully execute tasks autonomously: first short reasoning traces, then multi-step tool use, multi-hour coding sessions, and now multi-day projects. Each extension widens the interval between human check-ins required to keep agents on track.
We’re thinking: Sustained autonomy and low hallucination rates are related, but less and less so. If an agent makes a mistake, it can check its work, find the mistake, and fix it.
Strategic Thinking in LLMs vs. Humans
While large language models can behave in human-like ways, the similarities are superficial. A simple strategy game revealed clear differences in their strategic approaches.
What’s new: Caroline Wang and colleagues at University of Texas at Austin and Google interpreted patterns of decision-making by humans and LLMs as they played the classic game of rock-paper-scissors. They found that LLMs sometimes model their opponents with greater sophistication than people do.
Key insight: Given recorded gameplay, an LLM can iteratively improve code that predicts a player’s next move. If the code predicts the player’s actions with significant accuracy, we can assume that its decision-making algorithms are functionally similar to those the player used. Computer code is interpretable, making it possible to discern such algorithms and compare those used by humans and LLMs.
How it works: In games of rock-paper-scissors, he authors pitted individual LLMs (Gemini 2.5 Pro, Gemini 2.5 Flash, GPT-5.1, and GPT-OSS 120B) against each of 15 preprogrammed bots of varying complexity. They recorded each player's moves in 20 games of 300 sequential rounds each. Previous work provided records of similar records of games between humans and the same bots. The authors tracked the round-by-round choices made by each player — AI and human — and whether they won, lost, or tied. Then they used AlphaEvolve, an agentic method that iteratively optimizes code through an evolutionary process, to improve Python programs that predicted the next move for each LLM individually and humans as a group.
- AlphaEvolve initially processed the game data using a simple template program written by the authors. In each of an undisclosed number of evolutionary steps, Gemini 2.5 Flash proposed modifications to improve a function that balanced simplicity (as measured by Halstead effort) and evaluation likelihood (how well a program predicted a player’s choices).
- For each player, the authors selected the simplest program that achieved near-maximum predictive accuracy within a small margin from the best. Each program produced the best evaluation likelihood (higher is better) for the player it had evolved to predict. That is, it represented its corresponding player’s behavior better than that of any other player.
Results: Using game data that AlphaEvolve didn’t process, the authors compared how well each program predicted the other players’ moves. Then they examined the programs to determine what strategies each player used.
- The programs that represented Gemini 2.5 Pro, Gemini 2.5 Flash, and GPT-5.1 performed nearly equally well when predicting each other’s moves as they played against bots, which suggests that this trio used similar strategies. For example, predicting the actions of Gemini 2.5 Pro, the programs that predicted Gemini 2.5 Pro, Gemini 2.5 Flash, and GPT-5.1 achieved 0.507, 0.507, and 0.506 evaluation likelihood respectively. The programs that represented humans and GPT OSS 120B predicted the trio’s actions less successfully. They achieved 0.476 and 0.403 evaluation likelihood respectively, indicating that they likely used different strategies.
- Interpreting the programs suggested that Gemini 2.5 Pro, Gemini 2.5 Flash, and GPT-5.1 maintained sequential patterns more effectively than humans or GPT-OSS 120B. The code that predicted those programs tracked the frequency of each possible move based on a player’s previous one or two moves. That is, it tracked how often the player, over three rounds, called rock->scissors-> rock, rock->scissors->paper, and so on. In contrast, the code that represented humans and GPT-OSS 120B tracked the frequency of the opponent’s latest move only.
- The code that represented Gemini 2.5 Pro, Gemini 2.5 Flash, GPT-5.1, and human players computed the preliminary value of each possible next move based on (i) the possible next move, (ii) the bot’s previous move, and (iii) the player’s previous move. GPT-OSS 120B computed the value based on the possible next move alone.
Why it matters: While researchers have found ways to understand some aspects of neural network behavior, large language models remain black boxes in many ways. Synthesizing code directly from LLM behavior offers a powerful tool to interpret their decision-making.
We’re thinking: It’s tempting to assume that LLMs learn to mimic human behavior as represented by their training data. Finding that they can encode a gaming strategy more systematically than the average human demonstrates a different sort of learning.
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み