Sun Finance、AWS上で生成AIを活用しID抽出と不正検出を自動化
Sun Finance は AWS の生成 AI と OCR サービスを組み合わせることで、ID 抽出精度と処理速度を劇的に向上させ、手動レビューの必要性を大幅に削減した。
キーポイント
圧倒的な効率化の実現
ドキュメントあたりのコストを 91% 削減し、処理時間を最大 20 時間から 5 秒未満に短縮することに成功した。
高精度なデータ抽出
従来の OCR に加えて生成 AI を活用した構造化により、ID 情報抽出の精度を 79.7% から 90.8% へ引き上げた。
短期間での実装とローンチ
AWS 生成 AI イノベーションセンターとの連携を経て、35 ビジネス日で本番環境への導入を完了させた。
影響分析・編集コメントを表示
影響分析
この記事は、生成 AI が単なる実験段階を超え、金融機関のような高リスク・高負荷な現場で即座に効果を実証できることを示す重要な事例です。特に、コスト削減と処理速度の劇的な向上は、業界全体における ID 検証プロセスの標準化や、人手不足解消への大きな転換点となるでしょう。
編集コメント
生成 AI の実装事例として、数値目標の達成度と導入期間の短さが際立つ素晴らしいケーススタディです。特に「20時間→5秒」という処理時間の劇的変化は、ビジネスインパクトを如実に物語っています。
*この投稿は、Sun Finance Group の Krišjānis Kočāns 氏、Kaspars Magaznieks 氏、Sergei Kiriasov 氏との共著です*
スケーラブルな身分証明書の処理(ローン申請、口座開設、コンプライアンスチェックなど)を行っている場合、おそらく同じ壁にぶつかったことがあるでしょう。従来の光学式文字認識 (OCR: Optical Character Recognition) はある程度まで対応できますが、抽出エラーにより申請の大きな割合が依然として手動レビューキューへ送られてしまいます。ここに不正検知を組み合わせると、手作業による負荷はさらに増幅します。
2017 年に設立されたラトビアのフィンテック企業である Sun Finance は、9 カ国にわたるテクノロジーファースト型のオンライン貸付マーケットプレイスとして運営されています。同社は 0.63 秒ごとに新しいローンリクエストを処理し、月間 400 万件以上の評価を提供しています。その中でも特に高ボリュームな業界の一つであるマイクロローンの分野では、月間 8 万件の申請のうち約 60% がオペレーターによる手動レビューを必要としていました。Sun Finance は AWS ジェネレーティブ AI イノベーションセンター と提携してパイプラインの再構築を行いました。引き渡しから 35 ビジネス日以内に、本番環境での稼働が完了しました。以下のタイムラインは、キックオフから本番リリースまでのプロジェクト全体の経緯を示しています。
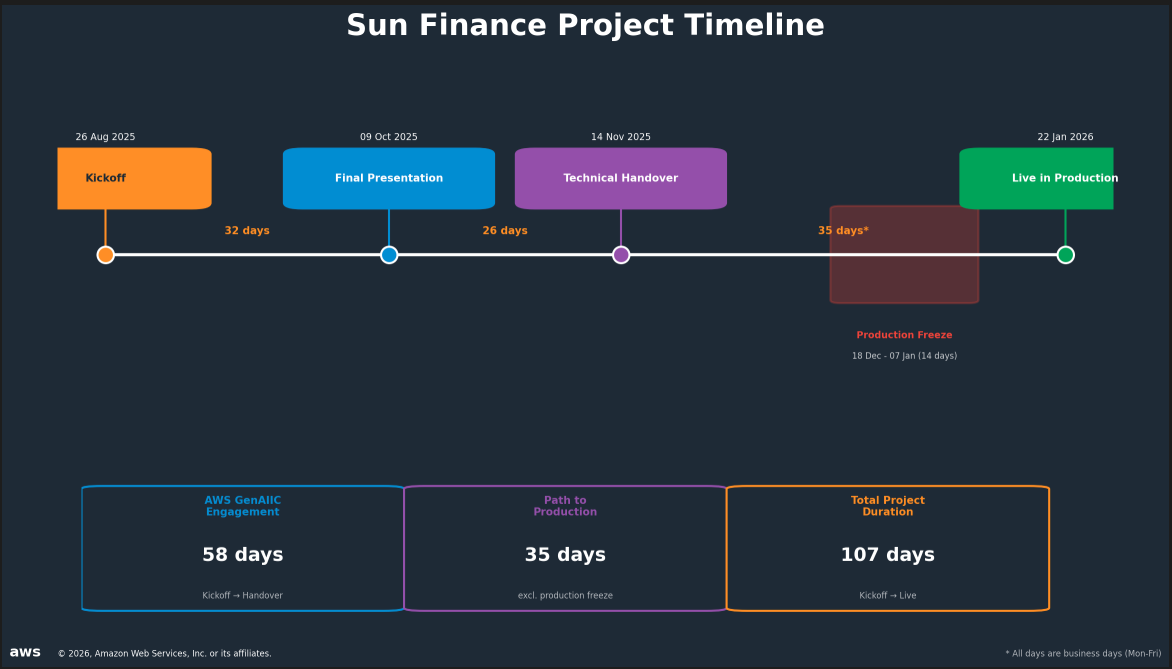
*Sun Finance のプロジェクトタイムライン:キックオフから本番稼働まで*
プロジェクトは107営業日かけて4つのマイルストーンを通過しました。AWS 生成AIイノベーションセンターとの連携期間は、キックオフ(2025年8月26日)から最終プレゼンテーション(2025年10月9日)までの32日間でした。その後、技術引き渡しに26日間(2025年11月14日まで)を要しました。Sun Financeはその後、生産環境への移行に35営業日を要し、その中には祝祭期間中の14日間の生産凍結(2025年12月18日~2026年1月7日)も含まれていました。そして2026年1月22日に本番稼働を開始しました。
本稿では、Sun FinanceがAmazon Bedrock、Amazon Textract、およびAmazon Rekognitionを活用して、AI駆動の本人確認(IDV: Identity Verification)パイプラインを構築した方法をご紹介します。このソリューションにより、抽出精度は79.7%から90.8%に向上し、文書あたりのコストは91%削減され、処理時間は最大20時間から5秒未満に短縮されました。専門的なOCR(光学文字認識)と大規模言語モデル(LLM: Large Language Model)による構造化を組み合わせることで、単独でいずれかのツールを使用する場合よりも優れた結果が得られる仕組みについて解説します。また、ベクトル類似度検索を活用したサーバーレスの不正検知システムのアーキテクチャ構築方法についても学びます。
本人確認における課題
Sun Financeは2019年にAmazon RekognitionとAmazon Textractを用いて最初のIDV自動化システムを構築しました。しかし、同社が開発途上地域へ展開するにつれ、このシステムの限界は無視できなくなってきました。
この地域は言語と文書の複雑さにおいて独自の課題を提示していました。英語と現地語の両方で文書を処理することは、従来の OCR システムにとって困難でした。現地語のテキストは従来の OCR 学習データセットで十分にカバーされておらず、頻繁な抽出エラーの原因となっていました。Sun Finance はまた、レイアウトやフォーマットが異なる 7 種類の異なる ID タイプを扱う必要もありました。
手作業による負荷の主な原因は OCR エラーでした。手動レビューが必要な申請の 60% のうち、約 80% のケースは抽出された情報と顧客が入力したデータとの不一致に起因していました。重要なのは、これらの不一致の 60% が顧客のミスではなく OCR エラーであったことです。残りの 20% の手動介入は、不正検出フラグに関連するものでした。
不正検出はさらに複雑な層を追加しました。毎日のリクエストの約 10% は実際の不正申請でした。詐欺師たちは基本的な制御を回避するために、特徴的なパターンを持つ類似画像を使用しながら複数のローン申請を提出していました。これらのパターンを特定するには、多数の画像にわたる時間のかかる手動レビューが必要でした。
コストと速度の制約が拡大を阻んでいました。この地域だけで文書あたりのコストと手動検証に専念した約 3 つのフルタイム相当(FTEs)という事実が、低価値マイクロローンを持つ業界への拡大における単位経済性を妨げていました。処理時間は、自動化されたケースでは 10 分未満から、営業時間外の手動レビューでは 20 時間に及んでいました。
ソリューション概要
AWS ジェネレーティブ AI イノベーションセンターは、2025 年 9 月から 10 月までの 6 週間にわたり、高ボリュームの特定業界に焦点を当てた概念実証(Proof of Concept: PoC)を実施しました。チームは、ID 抽出システムと不正検出システムの 2 つの AI 駆動型ソリューションを開発しました。両方とも AWS 上で完全にサーバーレスアーキテクチャとしてデプロイされています。
本ソリューションでは、以下の主要サービスを使用しています:
- Amazon Bedrock – Anthropic の Claude Sonnet 4 を用いた AI 構造化および視覚分析、および Amazon Titan Multimodal Embeddings を用いたベクトル生成を行います。
- Amazon Textract – 身分証明書からの主要な OCR テキスト抽出を担当します。
- Amazon Rekognition – フォールバック OCR、顔検出、および顔のマスク処理を担当します。
- Amazon S3 Vectors – 既知の不正パターンに対するサーバーレス型のベクトル類似度検索を行います。
- AWS Step Functions – 並列化する不正検出ワークフローをオーケストレーションします。
- AWS Lambda – 両パイプライン全体でサーバーレスコンピューティングを提供します。
以下の図は、本ソリューションのアーキテクチャを示しています。
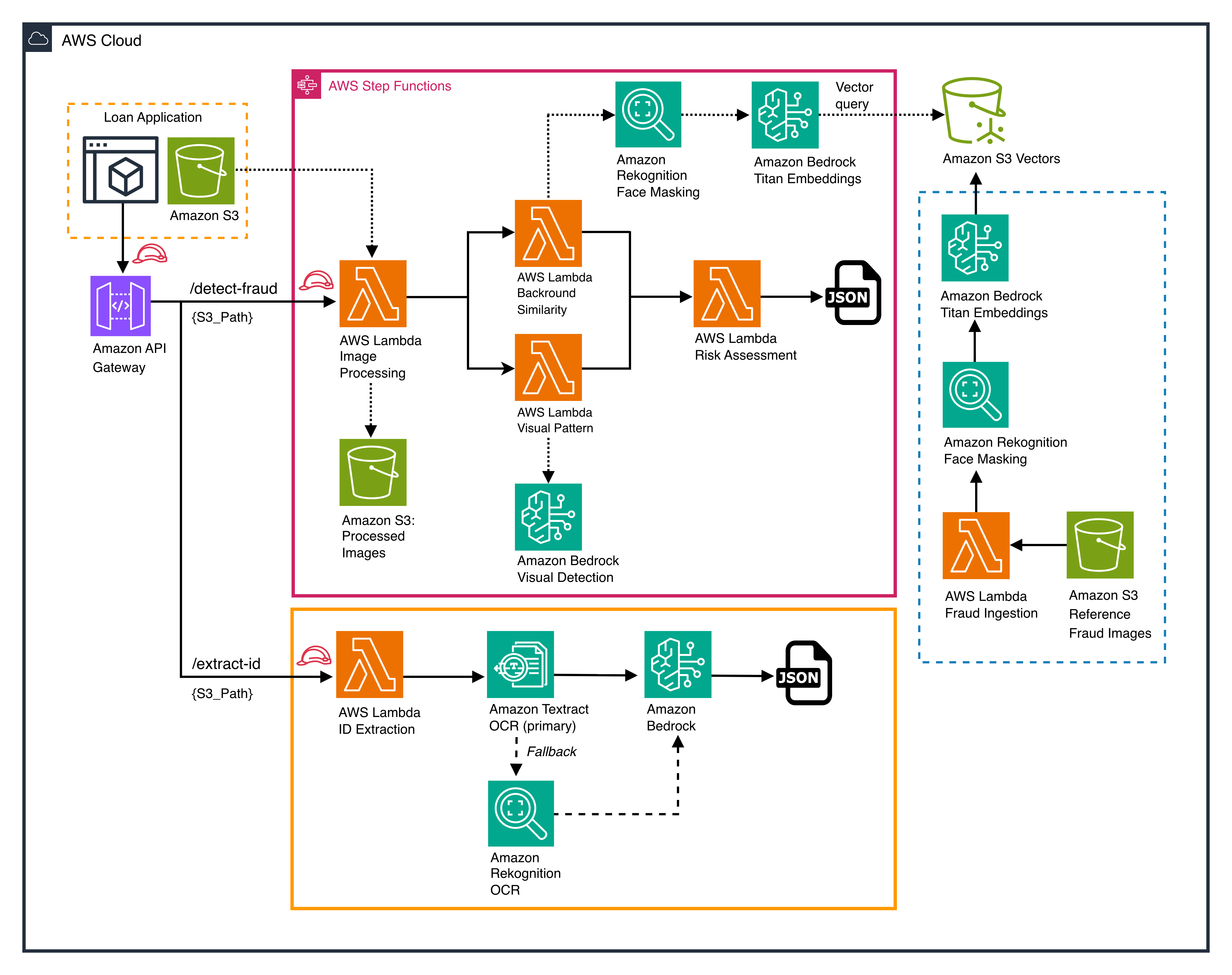
*ID 抽出と不正検出ルートを示す Sun Finance API アーキテクチャ*
本アーキテクチャは、Amazon API Gateway を通じて 2 つの API ルートを公開しており、ローン申請データは Amazon Simple Storage Service(Amazon S3)に保存されます。
/extract-idルート(ID 抽出)。AWS Lambda 関数が ID 画像を受け取り、Amazon Textract に送信して主要な OCR を実行します。もし Amazon Textract が低信頼度の結果を返した場合、システムは Amazon Rekognition を用いた OCR にフォールバックします。その後、抽出されたテキストは Amazon Bedrock(Claude Sonnet 4)に渡され、標準化された JSON フィールドへと構造化されます。
/detect-fraudルート(不正検出)。AWS Lambda 関数が AWS Step Functions ワークフローをトリガーし、2 つのチェックを並列で実行します:
背景類似性 — Amazon Rekognition がセルフィー画像から顔をマスクし、その後 Amazon Bedrock Titan Multimodal Embeddings が背景のベクトル表現を生成します。このベクトルは Amazon S3 Vectors に対して照会され、既知の不正パターンとの一致を検索します。
- ビジュアルパターン検出 — Amazon Bedrock(Claude Sonnet 4)が画像を分析し、画面撮影によるアーティファクトやデジタル改ざんを検出します。
両方の結果は Lambda ベースのリスク評価関数に投入され、JSON 形式で統合された不正スコアを生成します。
- 不正データ取り込みパイプライン(右側)。確認済みの不正画像は Amazon S3 から Lambda 関数を介して取り込まれます。画像は Amazon Rekognition によって顔のマスク処理を受け、Amazon Bedrock Titan Embeddings によってベクトル化され、Amazon S3 Vectors に保存されます。これにより、参照データベースは時間とともに拡張されていきます。
前提条件
同様のソリューションを実装するには、以下のものが必要です:
- AWS Lambda、AWS Step Functions、Amazon Bedrock、Amazon Textract、Amazon Rekognition、および Amazon S3 Vectors リソースの作成と管理を行う権限を持つ AWS アカウントが必要です。
- 使用している AWS リージョンにおいて、Anthropic Claude Sonnet 4 および Amazon Titan Multimodal Embeddings へのアクセスが有効になっている必要があります。
- インフラストラクチャのデプロイには Terraform がインストールされていること。
- Python とサーバーレスアーキテクチャに関する知識があること。
- テストおよび検証用の身元証明書類画像のデータセットを用意すること。
ソリューションの概要解説
このセクションでは、ID 抽出と不正検出という 2 つのコアパイプラインについて順を追って説明します。
ID 抽出パイプライン
ID 抽出システムは、初日から最終的な設計に至ったわけではありません。チームは 4 週間にわたり 3 つの異なるアプローチを反復し、それぞれの失敗が次の改善へとつながりました。以下の図は、Amazon Bedrock を介した単一の Claude Sonnet 4 によるアプローチ(精度 61.8%)から、最終的な多層構造設計(精度 90.8%)に至るまでのパイプラインの進化を示しています。
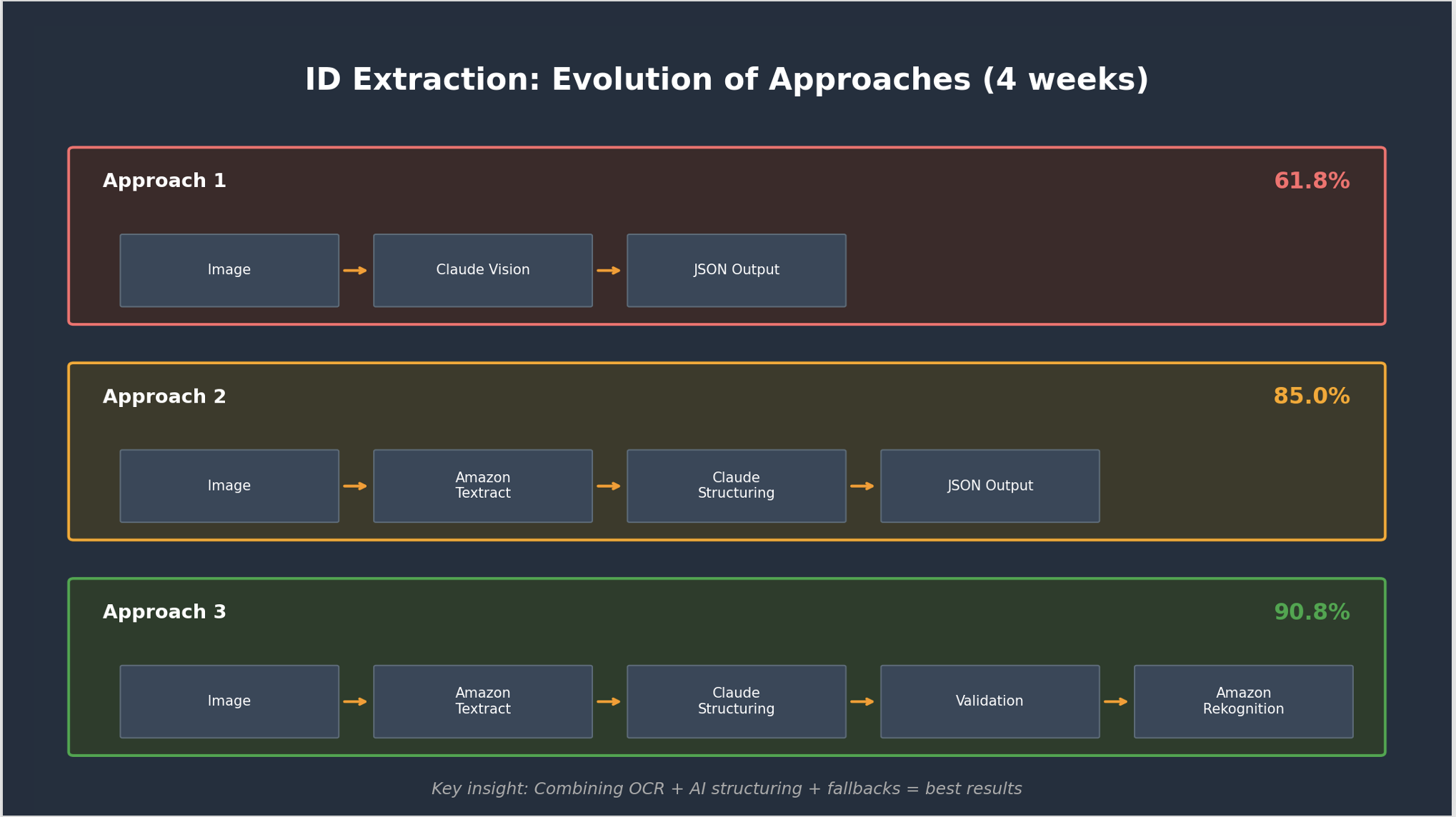
*ID 抽出:61.8% から 90.8% の精度に至るまでの 3 つの反復を示すアプローチの進化*
アプローチ1:Claude Sonnet 4 のみ(精度61.8%)。チームの最初の試みでは、ID画像を Amazon Bedrock を経由して Anthropic の Claude Sonnet 4 に直接送信し、JSON 形式でフィールドを抽出するよう指示しました。しかし結果は期待外れで、全体の精度は61.8%に留まり、ID番号の抽出精度に至ってはわずか43%でした。根本的な問題は、個人識別情報(PII)の処理に関するモデルに組み込まれたセキュリティプロトコルです。Claude は、運転免許証やパスポート、国民IDなどの身分証明書に見られる機密性の高い PII の処理を制限するように訓練されています。実際の ID 画像が提示されると、このプライバシー保護機能が作動し、一部のファイルからの情報抽出を拒否しました。これがパフォーマンスに直接的な悪影響を与えました。さらに、抽出が成功した場合でも、特定のフィールド(ID番号など)の精度は低く、モデルが機密文書上の正確な文字認識よりも安全性を優先したことが原因です。
教訓:Claude は一般的なドキュメント分析や OCR 作業においては卓越していますが、PII を含む身分証明書からの直接抽出には、組み込まれたプライバシー保護機能のために適していません。
アプローチ2:Amazon Textract と Claude を組み合わせた構造化(精度85%)。 画期的な転換点は、OCR(光学文字認識)と構造化の処理を分離したことです。Amazon Textract が ID 画像からの生テキスト抽出を担当し、Claude Sonnet 4 がその出力を7つの標準化されたフィールドに構造化しました:文書タイプ、生年月日、名、姓、ミドルネーム、ID 番号、有効期限です。この単一の変更により、精度は11.6%向上しました。
このアプローチが機能した理由は、Amazon Textract が専門的な OCR サービスであるため、Claude が持つ PII(個人識別情報)拒否メカニズムのような制約を持たず、安全プロトコルをトリガーすることなく ID 画像から確実にテキストを抽出できる点にあります。一度テキストが抽出されると、Claude は得意とする分野に集中できます:知的な構造化です。Claude は、アクセント記号を含む現地言語の処理、文脈からの欠落情報の推論、および文書固有の抽出ルールの適用において卓越した能力を発揮します。これらは従来の OCR 単体では対応できないタスクです。生 ID 画像ではなく、すでに抽出されたテキストを扱うことで、Claude は安全制約を回避できました。
教訓:関心の分離により、各ツールが設計パラメータ内で最適に機能できるようになりました。Amazon Textract が信頼性の高い OCR を担当し、Claude が知的な構造化を担当します。
アプローチ3:多層OCR+検証(精度90.8%)。 最終版では、Amazon Textract が苦手とする画像(通常は低品質なスキャン、不自然な文書角度、または損傷したID)に対するフォールバックとして Amazon Rekognition を追加し、ID番号のフォーマット、日付の標準化、ドキュメントタイプの正規化に関する検証ルールを実装しました。
この多層アーキテクチャは以下の通り動作します。Amazon Textract が主要なOCRを担当し、Amazon Textract の信頼度が低い場合に Amazon Rekognition がバックアップとして抽出を行います。Claude が統合された出力を構造化し、検証ルールがすり抜けたフォーマットエラーを検出します。ID番号はドキュメントタイプに基づいて適切な長さにパディングされ、日付は YYYY-MM-DD 形式に標準化されます。これらの検証ルールは極めて重要でした。OCR は正しい文字列を抽出したものの、一貫性のないフォーマットで出力されてしまうエッジケースを捕捉できたのです。
以下のチャートは、585枚のテスト画像における週ごとの精度推移を示しています。チームがベースラインを上回ったのは、Amazon Textract を追加した第4週になってからでした。各反復を通じて新たな失敗モードが明らかになり、それが次のアーキテクチャ改善に反映されました。
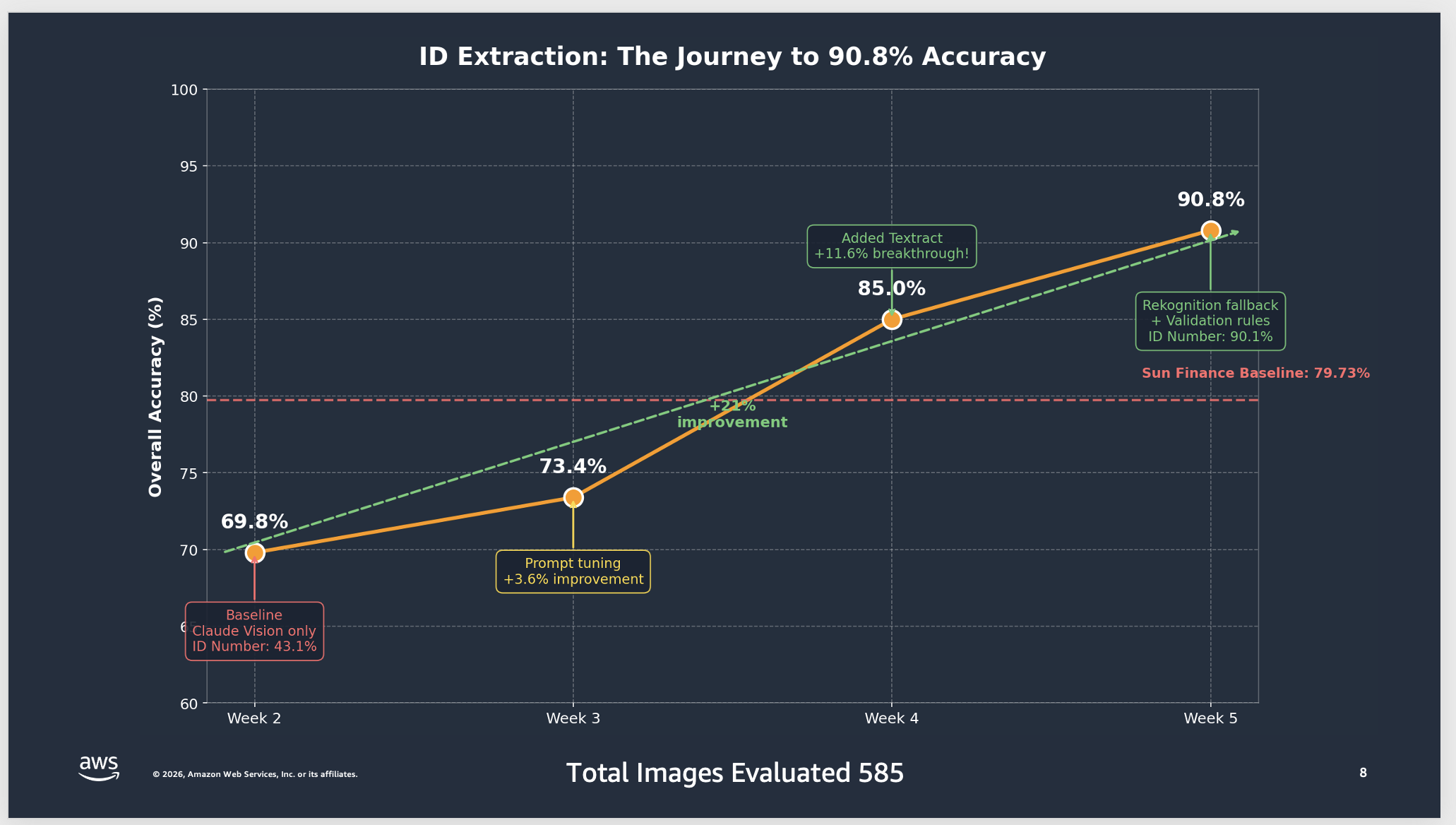
*ID 抽出:90.8% の精度に至るまでの道のりと週ごとの進捗*
要点:文書抽出において、単一のツールを使用するよりも、専門的な OCR ツール(Amazon Textract + Amazon Rekognition)を LLM による構造化(Claude)および検証ルールと組み合わせる方が優れています。
不正検出パイプライン
不正検出システムは AWS Step Functions を使用して、2 つの検出手法を並列で実行し、そのスコアを組み合わせて最終的なリスク評価を行います。
ビジュアルパターン検出。Claude Sonnet 4 は Amazon Bedrock を介して、提出されたセルフィー画像に不正の兆候がないか分析します。具体的には、画面撮影(ベゼルや走査線、モアレパターンの可視化)、画面の glare および反射、デジタル操作によるアーティファクトです。信頼度が 85% 以上の画像はフラグが立ちます。システムは、誤検知を減らすために、通常のぼかし、圧縮アーティファクト、標準的な切り抜きなどの特性は無視します。画面撮影の検出はよく機能しており、既知のパターンに対して 95% 以上の信頼度を示します。
背景類似性分析。このコンポーネントは、不正グループ(同じ場所からセルフィー画像を提出する詐欺師の集団)を検出します。パイプラインは 3 つのステップで動作します。まず、Amazon Rekognition が顔をマスクして背景に焦点を当てます。次に、Amazon Titan のマルチモーダル埋め込みが背景の 1024 次元ベクトルを生成します。最後に、Amazon S3 Vectors が既知の不正パターンに対して一致を検索します。
チームは、類似性検索のためにテキストベースの埋め込みとビジュアル埋め込みの両方をテストしました。テキスト埋め込み(Claude に背景を記述させた後、その記述を比較する手法)は 91% の精度を達成しましたが、適合率は 27.8%、再現率は 21.7% にとどまりました。一方、ビジュアル埋め込みははるかに優れた結果を示し、精度は 96%、適合率は 80%、再現率は 52% でした。
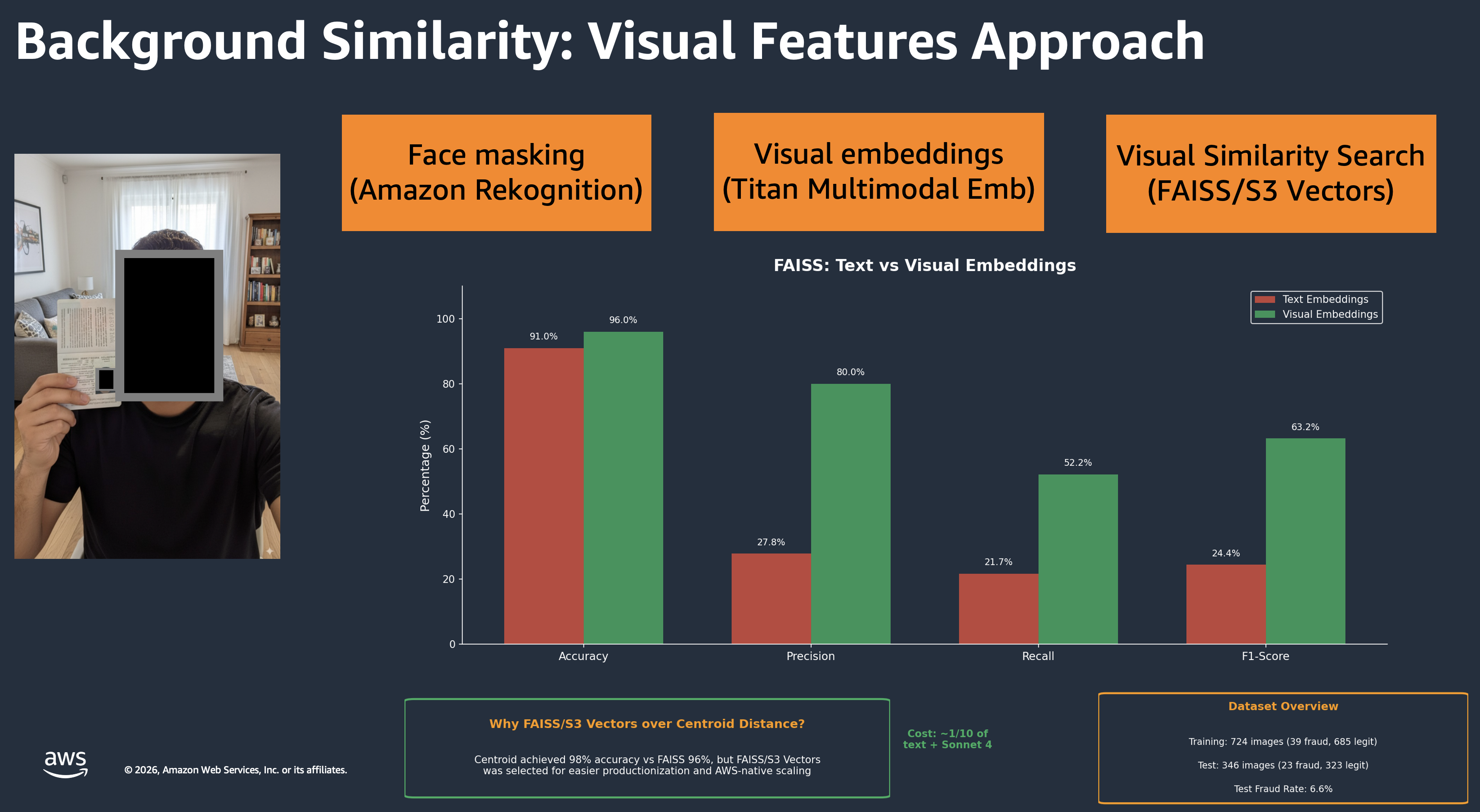
*背景の類似性:パイプラインを示すビジュアル特徴のアプローチと、テキスト埋め込み対ビジュアル埋め込みの比較*
リスク評価。スコアリングアルゴリズムは、視覚パターン検出(50%)と背景の類似性(50%)を同率で重み付けします。75 以上のスコアは高信頼度の詐欺を示し、38〜74 は中程度の信頼度、38 未満は正規のものとして分類されます。並列実行アーキテクチャにより、画像処理時間は従来の順次実行時の 6〜8 秒から 3〜5 秒に短縮されました。
サーバーレスアーキテクチャ
本ソリューション全体は AWS Lambda、AWS Step Functions、および Amazon API Gateway 上で稼働しています。この設計により、チームは個々の Lambda 関数を修正し、変更を即座にテストし、ダウンタイムなしでアップデートをデプロイできます。これは、アプローチが週次で変化した 6 週間のエンゲージメント期間中において極めて重要でした。
認証には、AWS SigV4 リクエスト署名を備えた Amazon Cognito が使用されています。AWS WAF は一般的なウェブセキュリティの問題から保護します。データは、AWS Key Management Service (KMS) を用いて保存時に暗号化されます。
原文を表示
*This post was co-authored with Krišjānis Kočāns, Kaspars Magaznieks, Sergei Kiriasov from Sun Finance Group*
If you process identity documents at scale—loan applications, account openings, compliance checks—you’ve likely hit the same wall: traditional optical character recognition (OCR) gets you partway there, but extraction errors still push a large share of applications into manual review queues. Add fraud detection to the mix, and the manual workload compounds.
Sun Finance, a Latvian fintech founded in 2017, operates as a technology-first online lending marketplace across nine countries. The company processes a new loan request every 0.63 seconds and delivers more than 4 million evaluations monthly. In one of their highest-volume industries, with 80,000 monthly applications for microloans, approximately 60% of applications required manual operator review. Sun Finance partnered with the AWS Generative AI Innovation Center to rebuild the pipeline. Within 35 business days of handover, the solution was live in production. The following timeline shows the full project journey from kickoff to production launch.
*Sun Finance project timeline from kickoff to production*
The project moved through four milestones over 107 business days. The AWS Generative AI Innovation Center engagement ran 32 days from kickoff (August 26, 2025) to final presentation (October 9, 2025), followed by 26 days for technical handover (November 14, 2025). Sun Finance then took 35 business days to move the solution into production, including a 14-day production freeze over the holiday period (December 18 – January 7), and went live on January 22, 2026.
In this post, we show how Sun Finance used Amazon Bedrock, Amazon Textract, and Amazon Rekognition to build an AI-powered identity verification (IDV) pipeline. The solution improved extraction accuracy from 79.7% to 90.8%, cut per-document costs by 91%, and reduced processing time from up to 20 hours to under 5 seconds. You’ll learn how combining specialized OCR with large language model (LLM) structuring outperformed using either tool alone. You’ll also learn how to architect a serverless fraud detection system using vector similarity search.
The Identity Verification Challenge
Sun Finance had built its first IDV automation in 2019 using Amazon Rekognition and Amazon Textract. As the company expanded into developing regions, the system’s limitations became hard to ignore.
This region presented unique challenges with language and document complexity. Processing documents in both English and a local language proved difficult for traditional OCR systems. The local language text remains underrepresented in traditional OCR training datasets, causing frequent extraction errors. Sun Finance also needed to handle 7 different ID types, each with different layouts and formats.
The manual workload was primarily driven by OCR errors. Of the 60% of applications requiring manual review, approximately 80% of cases stemmed from mismatches between extracted information and customer-entered data. Critically, 60% of these mismatches were OCR errors, not customer mistakes. The remaining 20% of manual interventions related to fraud detection flags.
Fraud detection added another layer of complexity. About 10% of daily requests were actual fraudulent applications. Fraudsters used similar images with distinctive patterns to bypass basic controls while submitting multiple loan applications. Identifying these patterns required time-intensive manual review across numerous images.
Cost and speed constraints blocked expansion. The per-document cost and approximately 3 full-time equivalents (FTEs) dedicated to manual verification in this region alone meant the unit economics blocked expansion into industries with lower-value microloans. Processing times ranged from under 10 minutes for automated cases to 20 hours for manual reviews outside business hours.
Solution overview
The AWS Generative AI Innovation Center ran a 6-week proof-of-concept (September–October 2025) focused on one high-volume industry. The team built two AI-powered solutions: an ID extraction system and a fraud detection system. Both were deployed as a fully serverless architecture on AWS.The solution uses the following key services:
- Amazon Bedrock – For AI structuring and visual analysis using Anthropic’s Claude Sonnet 4, and vector generation using Amazon Titan Multimodal Embeddings.
- Amazon Textract – For primary OCR text extraction from identity documents.
- Amazon Rekognition – For fallback OCR, face detection, and face masking.
- Amazon S3 Vectors – For serverless vector similarity search against known fraud patterns.
- AWS Step Functions – For orchestrating parallel fraud detection workflows.
- AWS Lambda – For serverless compute across both pipelines.
The following diagram illustrates the solution architecture.
*Sun Finance API architecture showing ID extraction and fraud detection routes*
The architecture exposes two API routes through Amazon API Gateway, with loan application data stored in Amazon Simple Storage Service (Amazon S3):
/extract-idroute (ID extraction). An AWS Lambda function receives the ID image and sends it to Amazon Textract for primary OCR. If Amazon Textract returns low-confidence results, the system falls back to Amazon Rekognition for OCR. The extracted text is then passed to Amazon Bedrock (Claude Sonnet 4), which structures it into standardized JSON fields.
/detect-fraudroute (fraud detection). An AWS Lambda function triggers an AWS Step Functions workflow that runs two checks in parallel:
Background similarity — Amazon Rekognition masks the face from the selfie image, then Amazon Bedrock Titan Multimodal Embeddings generates a vector representation of the background. This vector is queried against Amazon S3 Vectors to find matches with known fraud patterns.
- Visual pattern detection — Amazon Bedrock (Claude Sonnet 4) analyzes the image for screen photo artifacts and digital manipulation.
Both results feed into a Lambda-based risk assessment function that produces a combined fraud score as JSON.
- Fraud ingestion pipeline (right side). Confirmed fraud images are ingested from Amazon S3 through a Lambda function. The images are processed by Amazon Rekognition for face masking, vectorized by Amazon Bedrock Titan Embeddings, and stored in Amazon S3 Vectors. This grows the reference database over time.
Prerequisites
To implement a similar solution, you need the following:
- An AWS account with permissions to create and manage AWS Lambda, AWS Step Functions, Amazon Bedrock, Amazon Textract, Amazon Rekognition, and Amazon S3 Vectors resources.
- Amazon Bedrock model access enabled for Anthropic Claude Sonnet 4 and Amazon Titan Multimodal Embeddings in your AWS Region.
- Terraform installed for infrastructure deployment.
- Familiarity with Python and serverless architectures.
- A dataset of identity document images for testing and validation.
Solution walkthrough
This section walks through the two core pipelines: ID extraction and fraud detection.
ID extraction pipeline
The ID extraction system didn’t arrive at its final design on day one. The team iterated through three distinct approaches over four weeks, and each failure pointed toward the next improvement. The following diagram shows how the pipeline evolved from a single Claude Sonnet 4 via Amazon Bedrock approach at 61.8% accuracy to the final multi-tier design at 90.8%.
*ID extraction: evolution of approaches showing three iterations from 61.8% to 90.8% accuracy*
Approach 1: Claude Sonnet 4 alone (61.8% accuracy). The team’s first attempt sent ID images directly to Anthropic’s Claude Sonnet 4 via Amazon Bedrock and asked it to extract fields as JSON. The results were disappointing: 61.8% overall accuracy, with ID number extraction at only 43%. The core issue was the model’s built-in safety protocols for handling personally identifiable information (PII). Claude is trained to limit processing of sensitive PII found on identity documents like driver’s licenses, passports, and national IDs. When presented with real ID images, the model triggered these privacy safeguards and refused to extract information from some files, which directly impacted performance. Additionally, even when extraction succeeded, certain fields (like ID numbers) showed poor accuracy because the model prioritized safety over precise character recognition on sensitive documents.
The takeaway: while Claude excels at general document analysis and OCR tasks, its built-in privacy protections make it unsuitable for direct extraction from identity documents containing PII.
Approach 2: Amazon Textract + Claude structuring (85% accuracy). The breakthrough came when the team separated OCR from structuring. Amazon Textract handled raw text extraction from ID images. Claude Sonnet 4 then structured the output into 7 standardized fields: document type, date of birth, name, surname, middle name, ID number, and expiry date. This single change produced an 11.6% accuracy jump.
This approach worked because Amazon Textract, as a specialized OCR service, doesn’t have the same PII refusal mechanisms as Claude, so it reliably extracted text from every ID image without triggering safety protocols. Once the text was extracted, Claude could focus on what it does best: intelligent structuring. Claude excelled at handling local language text with diacritical marks, inferring missing information from context, and applying document-specific extraction rules. These are tasks that traditional OCR alone couldn’t handle. By working with already-extracted text rather than raw ID images, Claude avoided its safety constraints.
The takeaway: separating concerns allowed each tool to operate within its design parameters: Amazon Textract for reliable OCR and Claude for intelligent structuring.
Approach 3: Multi-tier OCR + validation (90.8% accuracy). The final iteration added Amazon Rekognition as a fallback for images where Amazon Textract struggled (typically low-quality scans, unusual document angles, or damaged IDs) plus validation rules for ID number formatting, date standardization, and document type normalization.
The multi-tier architecture works as follows. Amazon Textract handles primary OCR. Amazon Rekognition provides backup extraction when Amazon Textract confidence is low. Claude structures the combined output, and validation rules catch formatting errors that slip through. ID numbers get padded to the correct length based on document type, and dates are standardized to YYYY-MM-DD format. These validation rules proved critical. They caught edge cases where OCR extracted correct characters but in inconsistent formats.
The following chart shows the weekly accuracy progression across 585 test images. The team didn’t beat the baseline until Week 4, when they added Amazon Textract. Each iteration revealed new failure modes that informed the next architectural improvement.
*ID extraction: the journey to 90.8% accuracy showing weekly progress*
The takeaway: combining specialized OCR tools (Amazon Textract + Amazon Rekognition) with LLM structuring (Claude) and validation rules beats using a single tool alone for document extraction.
Fraud detection pipeline
The fraud detection system uses AWS Step Functions to run two detection methods in parallel, then combines their scores into a final risk assessment.
Visual pattern detection. Claude Sonnet 4 via Amazon Bedrock analyzes submitted selfie images for signs of fraud: screen photos (visible bezels, scan lines, moiré patterns), screen glare and reflections, and digital manipulation artifacts. Images scoring 85% confidence or higher are flagged. The system ignores normal characteristics like blur, compression artifacts, and standard cropping to reduce false positives. Screen photo detection works well, with 95%+ confidence on known patterns.
Background similarity analysis. This component catches fraud rings, which are groups of fraudsters submitting selfies from the same location. The pipeline works in three steps. First, Amazon Rekognition masks faces to focus on the background. Then, Amazon Titan Multimodal Embeddings generates a 1024-dimensional vector of the background. Finally, Amazon S3 Vectors searches for matches against known fraud patterns.
The team tested both text-based and visual embeddings for similarity search. Text embeddings (having Claude describe the background, then comparing descriptions) achieved 91% accuracy but only 27.8% precision and 21.7% recall. Visual embeddings performed far better: 96% accuracy, 80% precision, and 52% recall.
*Background similarity: visual features approach showing the pipeline and text vs visual embedding comparison*
Risk assessment. The scoring algorithm weighs visual pattern detection (50%) and background similarity (50%) equally. Scores of 75+ indicate high-confidence fraud, 38–74 indicate medium confidence, and below 38 is classified as legitimate. The parallel execution architecture processes images in 3–5 seconds, down from 6–8 seconds when run sequentially.
Serverless architecture
The entire solution runs on AWS Lambda, AWS Step Functions, and Amazon API Gateway. This design lets the team modify individual Lambda functions, test changes immediately, and deploy updates without downtime. This was critical during a 6-week engagement where the approach changed weekly.
Authentication uses Amazon Cognito with AWS SigV4 request signing. AWS WAF protects against common web security issues. Data is encrypted at rest with AWS Key Manage
関連記事
今日のまとめ
AI日報で今日の重要ニュースをまとめ読み