GoogleのTurboQuant圧縮技術、性能低下なしに高速推論と低性能ハードウェア対応を実現
Google Researchが発表したTurboQuantは、大規模言語モデルのKey-Valueキャッシュを最大6倍圧縮し、精度をほぼ維持したまま、より低性能なハードウェアで大規模コンテキストウィンドウの実行を可能にする量子化アルゴリズムである。
キーポイント
革新的な圧縮技術
TurboQuantは大規模言語モデルのKey-Valueキャッシュを最大6倍圧縮する量子化アルゴリズムで、3.5ビット圧縮を実現している。
精度維持と再学習不要
圧縮による精度損失はほぼゼロであり、モデルの再学習を必要としない点が特徴的である。
ハードウェア要件の大幅緩和
この技術により、従来よりもはるかに控えめなハードウェアで大規模なコンテキストウィンドウを実行できるようになる。
実証された効率向上
初期のコミュニティベンチマークでは、大幅な効率向上が確認されている。
影響分析・編集コメントを表示
影響分析
この技術は、大規模言語モデルの実用化における最大の課題の一つである計算リソース要件を大幅に緩和し、より広範なデバイスや環境でのLLM展開を可能にする。特にエッジデバイスやコスト制約のある環境でのAI応用を加速させる可能性が高い。
編集コメント
LLMの実用化におけるボトルネックである計算コスト問題に直接アプローチする実用的な技術革新。特に再学習不要という点が現場での導入障壁を下げる重要な要素。
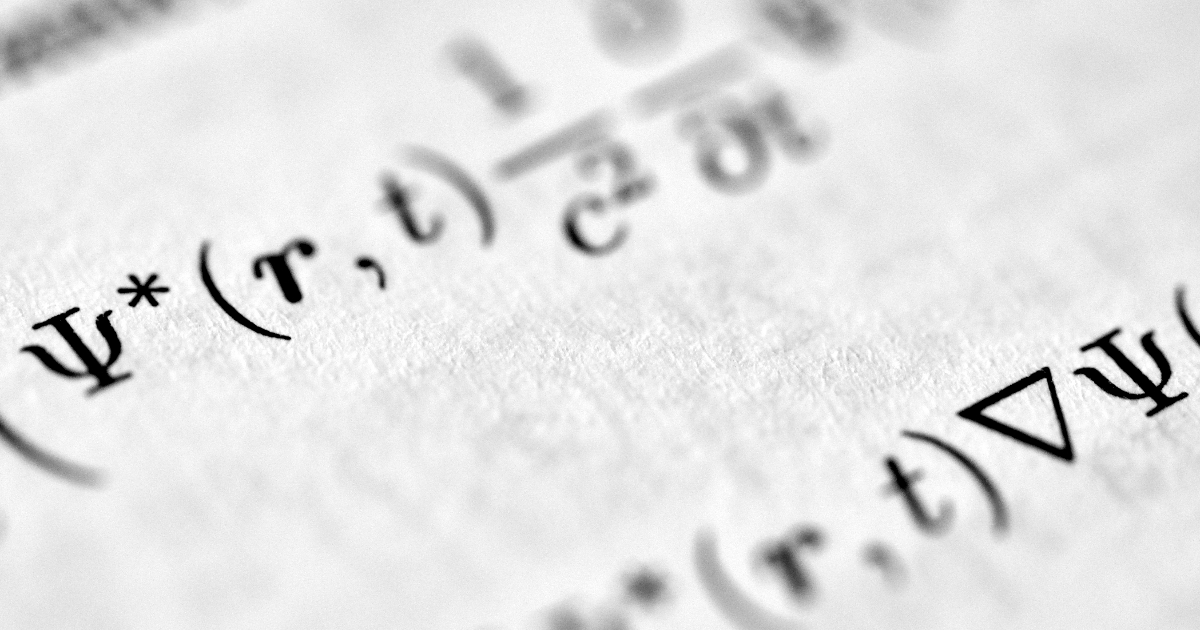 imageGoogle Researchは、大規模言語モデルのKey-Value(KV)キャッシュを最大6倍に圧縮する新しい量子化アルゴリズム「TurboQuant」を発表しました。3.5ビットの圧縮率、ほぼゼロの精度損失、再学習が不要という特徴により、以前よりもはるかに低スペックなハードウェアで、大幅に大きなコンテキストウィンドウを実行することが可能になります。初期のコミュニティベンチマークでは、顕著な効率向上が確認されています。
imageGoogle Researchは、大規模言語モデルのKey-Value(KV)キャッシュを最大6倍に圧縮する新しい量子化アルゴリズム「TurboQuant」を発表しました。3.5ビットの圧縮率、ほぼゼロの精度損失、再学習が不要という特徴により、以前よりもはるかに低スペックなハードウェアで、大幅に大きなコンテキストウィンドウを実行することが可能になります。初期のコミュニティベンチマークでは、顕著な効率向上が確認されています。
*By Bruno Couriol*
原文を表示
Google Research unveiled TurboQuant, a novel quantization algorithm that compresses large language models’ Key-Value caches by up to 6x. With 3.5-bit compression, near-zero accuracy loss, and no retraining needed, it allows developers to run massive context windows on significantly more modest hardware than previously required. Early community benchmarks confirm significant efficiency gains.
*By Bruno Couriol*
関連記事
量子化の基礎から解説
Sam Roseが大規模言語モデルの量子化の仕組みをインタラクティブな記事で解説し、浮動小数点数のバイナリ表現についても視覚的に説明している。
グリーンIT:AIの環境への影響を軽減する方法
AI研究者のLudi Akue氏は、AIが環境に与える影響(大量のエネルギー消費、GPUの短寿命など)を軽減するため、モデル圧縮や量子化などの技術を提案した。
NVIDIA推論転送ライブラリによる分散推論性能の向上
NVIDIAが大規模言語モデルの分散推論を効率化する「推論転送ライブラリ」を発表し、複数GPU間での計算負荷分散とリクエスト処理の最適化を実現した。